
Lernpfad
Dateningenieur in Python
40 Std.
Wenndu den Aufschwung des Cloud Computing kennst, hast du sicher schon von Kubernetes gehört. In der modernen Anwendungsentwicklung ist es ein wichtiges Werkzeug, das du für die Verwaltung verschiedener Infrastrukturen lernen musst.
In diesem Einführungsartikel geben wir dir einen Überblick über Kubernetes und seine Komponenten sowie eine umfassende Anleitung zur lokalen Implementierung. Wenn du ergänzend zu diesem Tutorium eine praktische Lernerfahrung suchst, schau dir unseren Kurs Einführung in Kubernetes an.
Kubernetes ist eine Open-Source-Plattform zur Orchestrierung von Containern, die die Bereitstellung, Skalierung und Verwaltung von containerisierten Anwendungen automatisiert. Ursprünglich von Google entwickelt, hat es sich zum De-facto-Standard für den Betrieb von Containern im großen Maßstab entwickelt.
Es abstrahiert die Komplexität der Verwaltung einzelner Container und ermöglicht es Entwicklern, sich auf die Erstellung und Bereitstellung ihrer Anwendungen zu konzentrieren.
Hier sind einige der wichtigsten Vorteile von Kubernetes:
Kubernetes ist nützlich für verschiedene Anwendungen wie:
Um zu verstehen, wie Kubernetes funktioniert, brauchst du ein gutes Verständnis der wichtigsten Konzepte.
Dazu gehören 4 Hauptkonzepte:
Wir werden weiter unten mehr darüber erfahren.
Kubernetes-Cluster sind Gruppen von Nodes, also einzelnen Maschinen, auf denen die Kubernetes-Software läuft. Der Cluster fungiert als Kontrollebene für die Verwaltung von Anwendungen und Diensten.
In einer typischen Konfiguration hat ein Cluster einen Master-Knoten und mehrere Worker-Knoten. Der Master-Knoten ist für die Koordinierung aller Aktivitäten innerhalb des Clusters zuständig, während die Worker-Knoten die Ausführung und Verwaltung der Container übernehmen.
Pods sind die kleinste Einheit für die Bereitstellung in Kubernetes. Sie können einen oder mehrere Container enthalten, zusammen mit gemeinsamen Speicherressourcen und Netzwerkeinstellungen.
Jeder Pod hat eine eigene, eindeutige IP-Adresse und kann über diese Adresse mit anderen Pods im selben Cluster kommunizieren. Dies ermöglicht eine effiziente Kommunikation zwischen verschiedenen Komponenten einer Anwendung.
Pods gibt es entweder als Einzel- oder als Multicontainer-Pods und jeder hat seinen eigenen Anwendungsfall.
Namespaces bieten eine Möglichkeit, Ressourcen innerhalb eines Clusters logisch zu partitionieren. Dies ermöglicht eine bessere Organisation und Verwaltung der Ressourcen sowie strengere Sicherheitskontrollen.
Namespaces können auch verwendet werden, um verschiedene Umgebungen zu verwalten, z. B. Entwicklung, Staging und Produktion. Dadurch wird sichergestellt, dass die Ressourcen isoliert sind und nicht durch Änderungen in anderen Umgebungen beeinträchtigt werden.
Um die Namespaces in deinem Cluster anzuzeigen, kannst du diesen Befehl verwenden:
kubectl get namespacesUm zwischen den Namespaces zu wechseln, kannst du Folgendes tun
kubectl config set-context --current --namespace <namespace name>Operatoren sind Software-Erweiterungen, die dabei helfen, die Verwaltung von Kubernetes-Ressourcen zu automatisieren. Sie verwenden benutzerdefinierte Controller und API-Erweiterungen, um komplexe Aufgaben effizienter und automatisch zu verwalten.
Einige beliebte Anbieter sind:
Die Verwendung von Operatoren kann die Verwaltung von Anwendungen und Ressourcen innerhalb deines Clusters erheblich vereinfachen. Dank ihrer Fähigkeit, Aufgaben zu automatisieren und erweiterte Funktionen bereitzustellen, werden sie bei Kubernetes-Nutzern immer beliebter.
In den meisten Kubernetes-Umgebungen gibt es eine Reihe von Kernkomponenten.
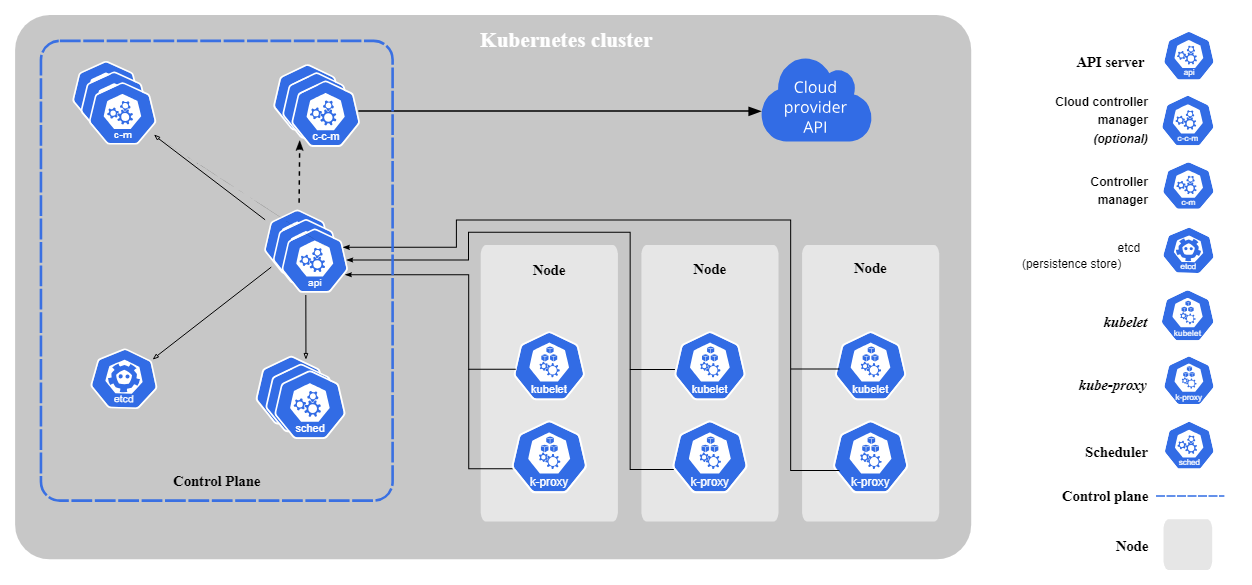
Quelle: Kubernetes
Hier ist eine Liste der Komponenten und ihrer Funktionen:
Wie wir bereits festgestellt haben, automatisiert Kubernetes die Bereitstellung, Skalierung und Verwaltung von containerisierten Anwendungen in Clustern. Sie sorgt für hohe Verfügbarkeit, effiziente Ressourcennutzung und Selbstheilung ohne manuelle Eingriffe.
Anstatt einzelne Container zu verwalten, fasst Kubernetes sie in Pods zusammen und verteilt sie auf Worker Nodes, die mit der Control Plane kommunizieren, um den gewünschten Zustand des Systems aufrechtzuerhalten.
So funktioniert Kubernetes, kurz und bündig:
Da Kubernetes die Komplexität der Infrastruktur bewältigt, können sich die Teams auf die Entwicklung von Anwendungen konzentrieren, anstatt die Bereitstellung zu verwalten. Das macht Kubernetes zu einem unverzichtbaren Werkzeug für skalierbare, belastbare Workloads in allen Branchen.
Schauen wir uns einige der wichtigsten Begriffe an, die du kennen musst, und ihre Definitionen:
Die Arbeit mit Kubernetes kann entmutigend wirken, vor allem wenn es darum geht, die verschiedenen Begriffe und Konzepte zu verstehen. Wenn du diese grundlegenden Begriffe jedoch erst einmal verstanden hast, wird es viel einfacher, sich auf der Plattform zurechtzufinden.
Schauen wir uns zunächst einige Tools an, die mit Kubernetes verwendet werden.
Als Kubernetes-Anfänger ist man mit der Bereitstellung von Anwendungen in der Cloud oft überfordert. Du kannst also auf einige gängige Tools zurückgreifen, um sie lokal einzusetzen.
Hier sind 2 der am häufigsten verwendeten Werkzeuge:
Minikube ist eine leichtgewichtige Kubernetes-Implementierung, die auf einem einzigen Host-Rechner laufen kann. Normalerweise läuft ein Single-Node-Cluster in einer virtuellen Maschine (VM) auf deinem Laptop oder deiner Workstation.
Warum es verwenden:
So installierst du Minikube (Beispiel unter Windows):
# Install via Windows Package Manager
winget install Kubernetes.minikubeDu solltest die folgende Installationsmeldung sehen können. Stimme den Geschäftsbedingungen zu, wenn du mit "J" gefragt wirst.
Um einen einfachen Cluster auf minikube zu starten, verwende den folgenden start Befehl:
# Start a single-node cluster
minikube startUm zu überprüfen, ob der Clusterknoten erfolgreich gestartet wurde, führe den Befehl get aus:
# Verify the cluster is running
kubectl get nodesHinweis: Du musst den kubectl API Server auf deinem lokalen Rechner installiert haben (er wird in vielen Fällen automatisch mit Minikube installiert).
Kind steht für Kubernetes in Docker. Es verwendet Docker-Container als "Knoten" in einem Kubernetes-Cluster und bietet eine einfache, containerbasierte lokale Cluster-Umgebung.
Warum es verwenden:
So installierst du Kind (Beispiel unter Windows):
# Install Kind with Windows Package Manager
winget install Kubernetes.kindNach der Installation kannst du mit dem Befehl create cluster einen einfachen Cluster erstellen und ihm einen Namen geben.
# Create a basic cluster
kind create cluster --name example-clusterUm zu überprüfen, ob dein Kubernetes-Art-Cluster gestartet ist, verwende den folgenden get Befehl.
# Check running clusters
kind get clustersDu kannst auch über die Schnittstelle kubectl mit dem Cluster interagieren:
# Interact with your Kind cluster using kubectl
kubectl get nodesHinweis: Stelle sicher, dass du Docker installiert hast und es läuft.
Wenn du Kubernetes in der Cloud betreiben willst, gibt es einige Cloud-Anbieter, die du auswählen kannst:
Amazon EKS ist ein verwalteter Service, der den Betrieb von Kubernetes auf AWS vereinfacht, ohne dass du deine eigene Control Plane oder Worker Nodes verwalten musst. Es lässt sich in andere AWS-Services integrieren, um zusätzliche Funktionen wie Lastverteilung, Speicherung, automatische Skalierung und Überwachung zu nutzen.
Einige zusätzliche Funktionen sind:
Google GKE ist ein vollständig verwalteter Service für den Betrieb von Kubernetes auf der Google Cloud Platform. Sie bietet automatische Skalierung, Selbstheilungsfunktionen und die Integration mit anderen Google Cloud-Diensten.
Einige zusätzliche Funktionen sind:
Azure AKS bietet serverlose Kubernetes-Cluster, die vollständig mit anderen Azure-Diensten wie Storage, Networking und Load Balancing integriert sind. Außerdem bietet es integrierte Unterstützung für DevOps-Tools wie Helm und Prometheus.
Einige zusätzliche Funktionen sind:
Kubernetes zum ersten Mal zu lernen, kann überwältigend erscheinen, aber es gibt viele Ressourcen, die dir den Einstieg erleichtern.
Hier sind einige empfohlene Ressourcen:
Um Anwendungen in Kubernetes auszuführen, folgst du einem strukturierten Arbeitsablauf, der das Einrichten eines Clusters, die Bereitstellung einer containerisierten Anwendung, die Bereitstellung als Dienst und die Skalierung nach Bedarf umfasst.
Wir haben diesen Prozess in unserem Kubernetes-Tutorial ausführlich beschrieben, aber hier ist eine kurze Zusammenfassung:
Verwende Minikube, um einen lokalen Cluster für Tests und Entwicklung zu erstellen. Installiere Minikube und starte deinen Cluster mit:
minikube start --driver=dockerkubectl get nodesDefiniere den gewünschten Zustand deiner Anwendung in einer Deployment YAML-Datei. Die Einrichtung eines Nginx-Webservers sieht zum Beispiel so aus:
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-deployment
spec:
replicas: 1
selector:
matchLabels:
app: hello
template:
metadata:
labels:
app: hello
spec:
containers:
- name: hello-container
image: nginx:latest
ports:
- containerPort: 80Wende den Einsatz mit an:
kubectl apply -f hello-deployment.yamlUm die Anwendung zugänglich zu machen, erstelle einen Dienst mit:
kubectl expose deployment hello-deployment --type=NodePort --port=80 --name=hello-serviceRufe die externe URL ab und öffne die App in deinem Browser:
minikube service hello-serviceKubernetes ermöglicht es dir, Anwendungen mühelos zu skalieren. Um die Anzahl der Replikate zu erhöhen:
kubectl scale deployment hello-deployment --replicas=3Prüfe laufende Pods:
kubectl get podsSieh dir die Protokolle für die Fehlersuche an:
kubectl logs -f <pod-name>Hier sind einige Beispiele, die du für fortgeschrittene Projekte weiter untersuchen kannst:
Kubernetes ist eine leistungsstarke Plattform für die Bereitstellung und Verwaltung von containerisierten Anwendungen im großen Maßstab und damit ein unverzichtbares Werkzeug für Dateningenieure, die elastische, zuverlässige Umgebungen für die Datenverarbeitung benötigen.
Wenn du mehr über Kubernetes erfahren möchtest, kannst du unseren Kurs Einführung in Kubernetes ist der perfekte Ort, um damit anzufangen.
Top DataCamp Kurse
Lernpfad
Lernpfad
Kurs
Blog
Tutorial
Sejal Jaiswal
Tutorial
Allan Ouko
Tutorial
Javier Canales Luna
Tutorial
Matt Crabtree

