
Track
Data Engineer in Python
40 hr
If you’re aware of the rise in cloud computing, you must have heard of Kubernetes. In modern application development, it’s a key tool to learn for managing various infrastructure setups.
In this introductory article, we’ll provide an overview of Kubernetes and its components, as well as a comprehensive tutorial on implementing it locally. If you’re looking for a hands-on learning experience to complement this tutorial, check out our Introduction to Kubernetes course.
Kubernetes is an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications. Originally developed by Google, it has become the de-facto standard for running containers at scale.
It abstracts away the complexity of managing individual containers and allows developers to focus on building and deploying their applications.
Here are some key benefits of using Kubernetes:
Kubernetes is useful in varied applications like:
To understand how Kubernetes works, you’ll need to have a good understanding of its key concepts.
These include 4 main concepts:
We’ll explore more about this below.
Kubernetes clusters are groups of nodes, which are individual machines that run the Kubernetes software. The cluster acts as the control plane for managing applications and services.
In a typical setup, a cluster will have a master node and multiple worker nodes. The master node is responsible for coordinating all activities within the cluster, while the worker nodes handle running and managing containers.
Pods are the smallest unit of deployment in Kubernetes. They can hold one or more containers, along with shared storage resources and networking settings.
Each pod has its own unique IP address and can communicate with other pods in the same cluster through this address. This allows for efficient communication between different components of an application.
Pods can come in either single or multi-container pods and each comes with their own use case.
Namespaces provide a way to logically partition resources within a single cluster. This allows for better organization and management of resources, as well as tighter security controls.
Namespaces can also be used to manage different environments, such as development, staging, and production. This ensures that resources are isolated and not affected by changes made in other environments.
To view the namespaces in your cluster, you can use this command:
kubectl get namespacesTo switch between namespaces, use the following
kubectl config set-context --current --namespace <namespace name>Operators are software extensions that help automate the management of Kubernetes resources. They use custom controllers and API extensions to manage complex tasks more efficiently and automatically.
Some popular operators include:
Using operators can greatly simplify the management of applications and resources within your cluster. With their ability to automate tasks and provide advanced features, they are becoming increasingly popular among Kubernetes users.
In most Kubernetes environments there is a set of core components.
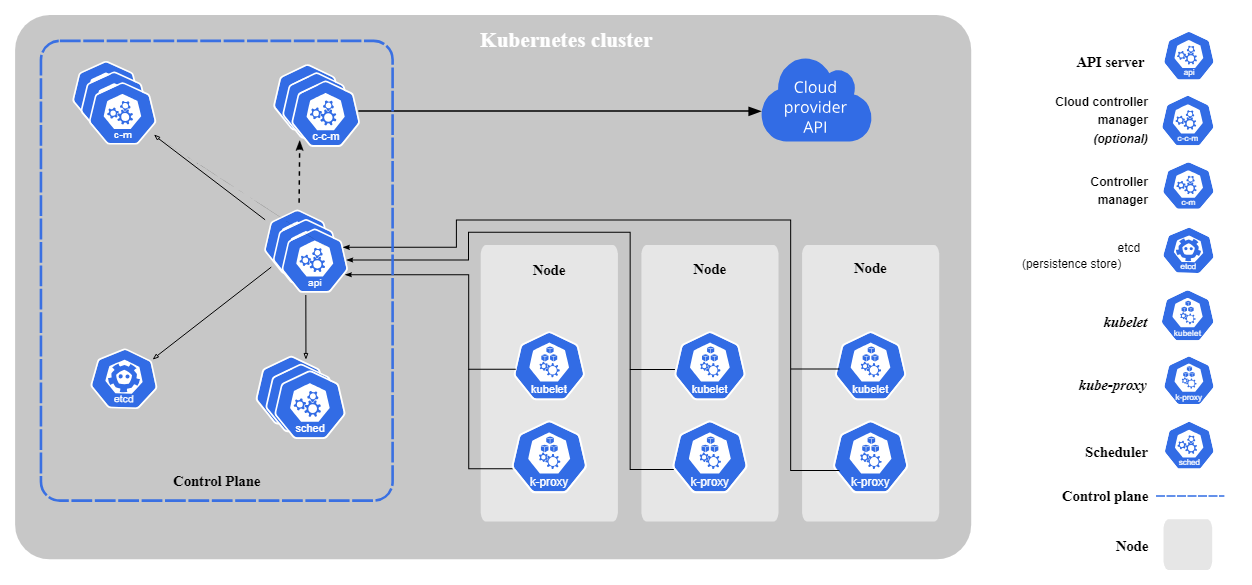
Source: Kubernetes
Here is a list of components and what they do:
As we’ve established, Kubernetes automates the deployment, scaling, and management of containerized applications across clusters. It ensures high availability, efficient resource use, and self-healing without manual intervention.
Instead of managing individual containers, Kubernetes groups them into Pods and distributes them across worker nodes, which communicate with the control plane to maintain the system's desired state.
Here’s how Kubernetes works, in brief:
By handling infrastructure complexity, Kubernetes enables teams to focus on building applications rather than managing deployments, making it essential for scalable, resilient workloads across industries.
Let’s look at some of the key terms you need to know and their definitions:
Working with Kubernetes can seem daunting, especially when it comes to understanding the various terminology and concepts. However, once you have a solid understanding of these essential terms, navigating through the platform will become much easier.
Let’s start by looking at some tools used with Kubernetes.
As a beginner to Kubernetes, having to deploy applications on the cloud can be too much to handle. As such, you can look to some common tools to deploy locally.
Here are 2 most commonly used tools:
Minikube is a lightweight Kubernetes implementation that can run on a single host machine. It usually runs a single-node cluster in a virtual machine (VM) on your laptop or workstation.
Why use it:
How to Install Minikube (Example on Windows):
# Install via Windows Package Manager
winget install Kubernetes.minikubeYou should be able to see the following installation message. Agree to the terms and conditions if prompted using “Y”.
Next, to start up a simple cluster on minikube, use the following start command:
# Start a single-node cluster
minikube startTo check that the cluster node has started successfully, run the get command:
# Verify the cluster is running
kubectl get nodesNote: You need to have the kubectl API server installed on your local machine (It is installed with Minikube automatically in many cases).
Kind stands for Kubernetes in Docker. It uses Docker containers as "nodes" in a Kubernetes cluster, providing a simple, container-based local cluster environment.
Why use it:
How to Install Kind (Example on Windows):
# Install Kind with Windows Package Manager
winget install Kubernetes.kindOnce installed, you can create a simple cluster using the create cluster command and give it a name.
# Create a basic cluster
kind create cluster --name example-clusterTo check to see if your Kubernetes kind cluster has started, use the following get command.
# Check running clusters
kind get clustersYou can also interact with the cluster through kubectl interface:
# Interact with your Kind cluster using kubectl
kubectl get nodesNote: Make sure you have Docker installed and running.
When running Kubernetes on the cloud, here are some cloud providers to choose from:
Amazon EKS is a managed service that makes it easy to run Kubernetes on AWS without the need to manage your own control plane or worker nodes. It integrates with other AWS services for additional features such as load balancing, storage, auto-scaling, and monitoring.
Some additional features include:
Google GKE is a fully managed service for running Kubernetes on the Google Cloud Platform. It offers automatic scaling, self-healing capabilities, and integration with other Google Cloud services.
Some additional features include:
Azure AKS provides serverless Kubernetes clusters that are fully integrated with other Azure services like Storage, Networking, and Load Balancing. It also has built-in support for DevOps tools like Helm and Prometheus.
Some additional features include:
Learning Kubernetes for the first time can seem overwhelming, but there are many resources available to help you get started.
Here are some recommended resources:
To run applications in Kubernetes, you follow a structured workflow that involves setting up a cluster, deploying a containerized application, exposing it as a service, and scaling it as needed.
We’ve covered this process in detail in our Kubernetes tutorial but here’s a high-level breakdown:
Use Minikube to create a local cluster for testing and development. Install Minikube and start your cluster using:
minikube start --driver=dockerkubectl get nodesDefine your application’s desired state in a Deployment YAML file. For example, deploying an Nginx web server looks like this:
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-deployment
spec:
replicas: 1
selector:
matchLabels:
app: hello
template:
metadata:
labels:
app: hello
spec:
containers:
- name: hello-container
image: nginx:latest
ports:
- containerPort: 80Apply the deployment with:
kubectl apply -f hello-deployment.yamlTo make the application accessible, create a Service using:
kubectl expose deployment hello-deployment --type=NodePort --port=80 --name=hello-serviceRetrieve the external URL and open the app in your browser:
minikube service hello-serviceKubernetes allows you to scale applications effortlessly. To increase replicas:
kubectl scale deployment hello-deployment --replicas=3Check running Pods:
kubectl get podsView logs for debugging:
kubectl logs -f <pod-name>Here are some examples for further exploration for advanced projects:
Kubernetes is a powerful platform for deploying and managing containerized applications at scale, making it an essential tool for data engineers who need elastic, reliable environments for data processing.
If you’re interested in learning more about Kubernetes, our Introduction to Kubernetes course would be the perfect place to start.
Top DataCamp Courses
Track
Track
Course
blog
Moez Ali
15 min
blog
Josep Ferrer
11 min
blog
Benito Martin
15 min
Tutorial
Patrick Brus
Tutorial
Rajesh Kumar
Tutorial
Kenny Ang
