Kurs
Einführung in R
4 Std.
3M

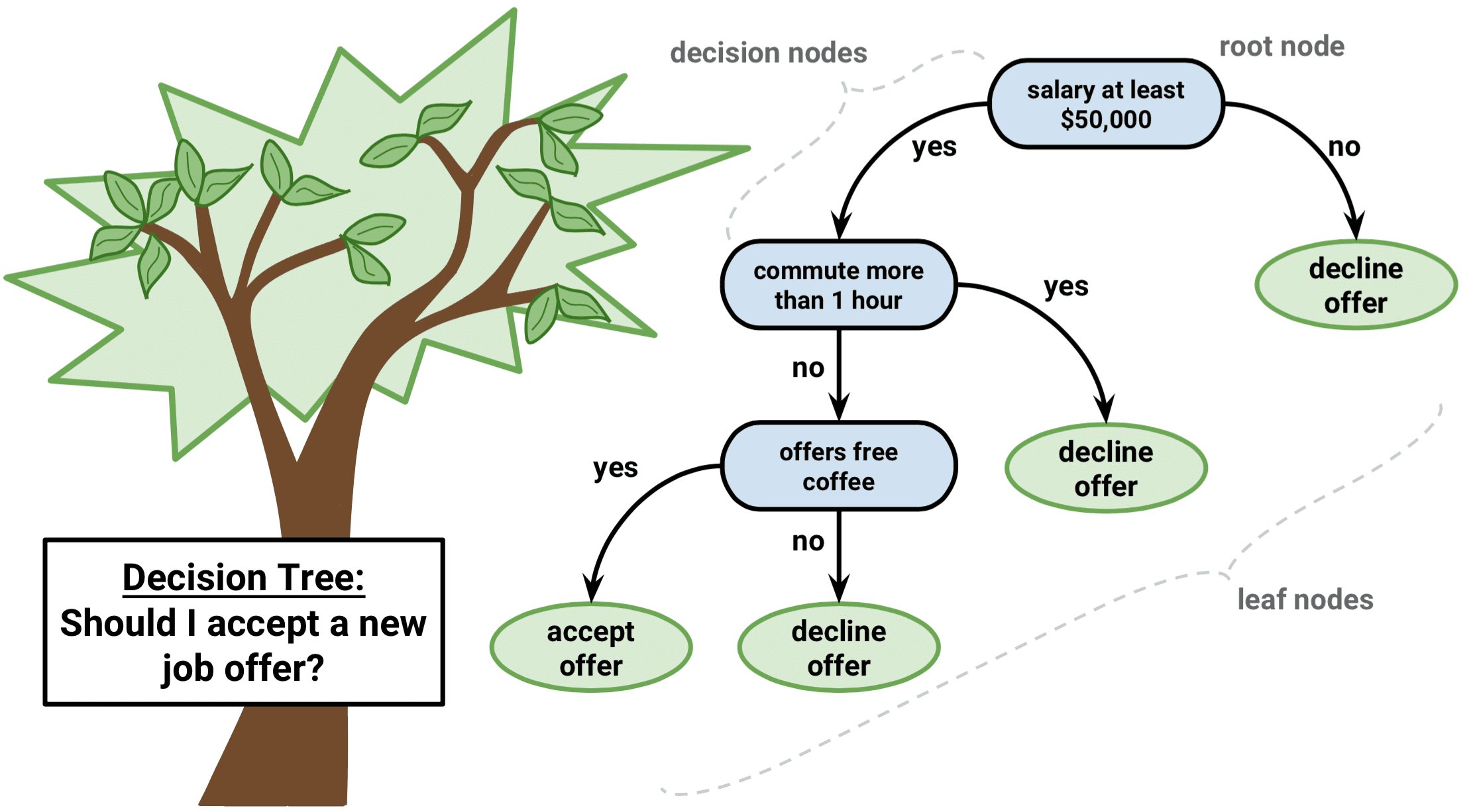
Stell dir vor, du navigierst durch ein Labyrinth. Mit jedem Schritt stehst du vor einer Entscheidung, die dich näher zum Ausgang oder tiefer in das Labyrinth führt. Dies ist vergleichbar mit einem Entscheidungsbaum-Algorithmus, einer leistungsstarken und intuitiven Methode des maschinellen Lernens, die uns hilft, komplexe Daten zu verstehen und die beste Vorgehensweise zu wählen.
Ein Entscheidungsbaum-Algorithmus zerlegt einen Datensatz anhand bestimmter Bedingungen in immer kleinere Teilmengen. Wie ein verzweigter Baum mit Blättern und Knoten beginnt er mit einem einzigen Wurzelknoten und erweitert sich in mehrere Zweige, von denen jeder eine Entscheidung auf der Grundlage eines Merkmalswerts darstellt. Die letzten Blätter des Baums sind die möglichen Ergebnisse oder Vorhersagen.
Dieser Artikel führt dich in die Welt der Entscheidungsbäume mit Hilfe der Programmiersprache R ein. Wir besprechen die Grundlagen, gehen auf gängige Arten von Entscheidungsbaumalgorithmen ein, erkunden baumbasierte Methoden und führen dich Schritt für Schritt durch ein Beispiel. Am Ende wirst du in der Lage sein, die Macht der Entscheidungsbäume zu nutzen, um bessere datengestützte Entscheidungen zu treffen.
Entscheidungsbäume sind aufgrund ihrer Einfachheit, Interpretierbarkeit und Vielseitigkeit etwas Besonderes im maschinellen Lernen.
Es ist ein überwachter maschineller Lernalgorithmus, der sowohl für Regressions- (Vorhersage kontinuierlicher Werte) als auch für Klassifizierungsprobleme (Vorhersage kategorischer Werte) verwendet werden kann. Außerdem dienen sie als Grundlage für fortgeschrittenere Techniken wie Bagging, Boosting und Random Forests.
Das folgende Diagramm veranschaulicht die Terminologie der Entscheidungsbäume:
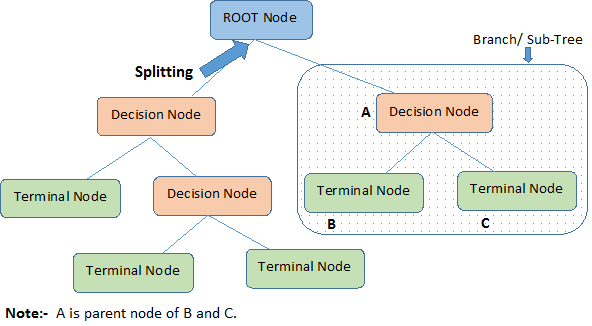
Ein Entscheidungsbaum beginnt mit einem Wurzelknoten, der die gesamte Grundgesamtheit oder Stichprobe darstellt, die dann mit einer Methode namens Splitting in zwei oder mehr einheitliche Gruppen aufgeteilt wird. Wenn Unterknoten eine weitere Teilung erfahren, werden sie als Entscheidungsknoten bezeichnet, während diejenigen, die sich nicht teilen, Endknoten oder Blätter genannt werden. Ein Segment eines vollständigen Baums wird als Zweig bezeichnet.
Wir haben festgestellt, dass Entscheidungsbäume sowohl für Regressions- als auch für Klassifizierungsaufgaben verwendet werden können; also lass uns den Algorithmus hinter den Typen von Entscheidungsbäumen verstehen.
Wir wollen intuitiv verstehen, was Regressions- und Klassifizierungsentscheidungsbäume sind, welche Gemeinsamkeiten und Unterschiede sie haben und wie die Fehlerfunktionen aussehen.
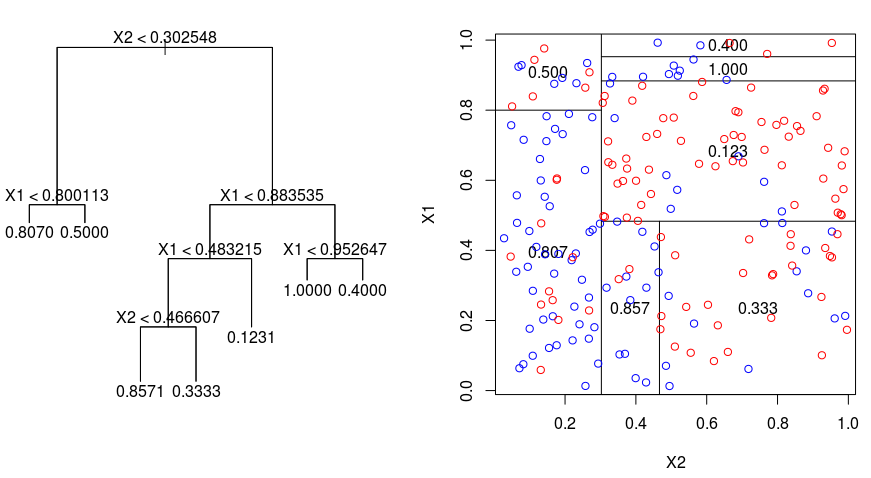
Schauen wir uns das folgende Bild an, das die Art der Partitionierung durch einen Regressionsbaum veranschaulicht. Hier siehst du einen nicht beschnittenen Baum und einen Regressionsbaum, der an einen zufälligen Datensatz angepasst wurde. Beide Visualisierungen zeigen eine Reihe von Aufteilungsregeln, beginnend an der Spitze des Baums. Beachte, dass jeder Split des Bereichs an einer der Merkmalsachsen ausgerichtet ist. Das Konzept der achsparallelen Aufteilung lässt sich problemlos auf Dimensionen größer als zwei übertragen. Für einen Merkmalsraum der Größe $p$, eine Teilmenge von $\mathbb{R}^p$, wird der Raum in $M$ Regionen, $R_{m}$, unterteilt, von denen jede ein $p$-dimensionaler "Hyperblock" ist.
Um einen Regressionsbaum zu erstellen, verwendest du zunächst ein rekursives binäres Splitting, um einen großen Baum auf den Trainingsdaten wachsen zu lassen, wobei du nur dann anhältst, wenn jeder Endknoten weniger als eine Mindestanzahl von Beobachtungen hat. Recursive Binary Splitting ist ein gieriger Top-Down-Algorithmus zur Minimierung der Residual Sum of Squares (RSS), ein Fehlermaß, das auch in der linearen Regression verwendet wird. Die RSS ist im Falle eines partitionierten Merkmalsraums mit M Partitionen gegeben durch:
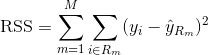
Du beginnst an der Spitze des Baumes und teilst ihn in 2 Äste auf, so dass eine Teilung von 2 Räumen entsteht. Dann führst du diesen bestimmten Split an der Spitze des Baums mehrmals durch und wählst den Split der Merkmale, der die (aktuelle) RSS minimiert.
Als Nächstes wendest du das Cost Complexity Pruning auf den großen Baum an, um eine Folge der besten Teilbäume in Abhängigkeit von $\alpha$ zu erhalten. Die Grundidee besteht darin, einen zusätzlichen Abstimmungsparameter einzuführen, der mit $\alpha$ bezeichnet wird und die Tiefe des Baums und seine Anpassungsfähigkeit an die Trainingsdaten ausgleicht.
Du kannst die K-fache Kreuzvalidierung verwenden, um $\alpha$ auszuwählen. Bei dieser Technik werden die Trainingsbeobachtungen einfach in K Foldings unterteilt, um die Testfehlerrate der Teilbäume zu schätzen. Dein Ziel ist es, diejenige auszuwählen, die zur niedrigsten Fehlerquote führt.
Ein Klassifikationsbaum ist einem Regressionsbaum sehr ähnlich, nur dass er zur Vorhersage einer qualitativen statt einer quantitativen Antwort verwendet wird.
Erinnere dich daran, dass bei einem Regressionsbaum die vorhergesagte Antwort für eine Beobachtung durch die mittlere Antwort der Trainingsbeobachtungen gegeben ist, die zum selben Endknoten gehören. Im Gegensatz dazu sagst du bei einem Klassifikationsbaum voraus, dass jede Beobachtung zu der am häufigsten vorkommenden Klasse der Trainingsbeobachtungen in der Region gehört, zu der sie gehört.
Wenn du die Ergebnisse eines Klassifizierungsbaums interpretierst, bist du oft nicht nur an der Klassenvorhersage für eine bestimmte Endknotenregion interessiert, sondern auch an den Klassenanteilen unter den Trainingsbeobachtungen, die in diese Region fallen.
Die Aufgabe, einen Klassifikationsbaum zu erstellen, ist der Aufgabe, einen Regressionsbaum zu erstellen, sehr ähnlich. Genau wie bei der Regression verwendest du rekursives binäres Splitting, um einen Klassifikationsbaum zu erstellen. Bei der Klassifizierung kann die Residual Sum of Squares jedoch nicht als Kriterium für die binäre Aufteilung verwendet werden. Stattdessen kannst du eine der 3 folgenden Methoden anwenden:
E = 1 - argmaxc($\hat{\pi}_{mc}$)
wobei $\hat{\pi}_{mc}$ den Anteil der Trainingsdaten in der Region Rm darstellt, die zur Klasse c gehören.
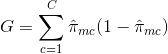
Die Kreuzentropie nimmt einen Wert nahe Null an, wenn die Werte von $\hat{\pi}_{mc}$ alle nahe 0 oder nahe 1 sind. Wie der Gini-Index nimmt also auch die Kreuzentropie einen kleinen Wert an, wenn der m-te Knoten rein ist. Tatsächlich stellt sich heraus, dass der Gini-Index und die Kreuzentropie numerisch recht ähnlich sind.
Bei der Erstellung eines Klassifizierungsbaums werden in der Regel entweder der Gini-Index oder die Kreuzentropie verwendet, um die Qualität eines bestimmten Splits zu bewerten, da sie empfindlicher auf die Knotenreinheit reagieren als die Klassifizierungsfehlerrate. Jeder dieser 3 Ansätze kann beim Beschneiden des Baums verwendet werden, aber die Klassifizierungsfehlerrate ist vorzuziehen, wenn die Vorhersagegenauigkeit des endgültigen beschnittenen Baums das Ziel ist.
So gerne wir den Algorithmus und seine Stärken verstehen würden, so wichtig ist es auch, seine Schwächen zu kennen. Die Wahrheit ist, dass Entscheidungsbäume nicht für alle Arten von maschinellen Lernalgorithmen am besten geeignet sind, was auch für alle maschinellen Lernalgorithmen gilt.
Hier sind die Vor- und Nachteile:
Trotz dieser Nachteile sind Entscheidungsbäume aufgrund ihrer Einfachheit, Interpretierbarkeit und Vielseitigkeit nach wie vor eine beliebte Wahl in vielen Anwendungen.
Sehen wir uns die baumbasierten Ensemble-Methoden an, die die Stärken von Entscheidungsbäumen nutzen und gleichzeitig einige ihrer Einschränkungen ausgleichen: Bagging, Boosting und Random Forests.
Die oben besprochenen Entscheidungsbäume leiden unter einer hohen Varianz, d.h. wenn du die Trainingsdaten nach dem Zufallsprinzip in zwei Teile aufteilst und einen Entscheidungsbaum auf beide Hälften anwendest, können die Ergebnisse sehr unterschiedlich ausfallen. Im Gegensatz dazu wird ein Verfahren mit geringer Varianz ähnliche Ergebnisse liefern, wenn es wiederholt auf verschiedene Datensätze angewendet wird.
Bagging oder Bootstrap-Aggregation ist eine Technik, mit der du die Varianz deiner Vorhersagen reduzieren kannst, indem du die Ergebnisse mehrerer Klassifikatoren kombinierst, die auf verschiedenen Unterstichproben desselben Datensatzes modelliert wurden. Hier ist die Gleichung für das Absacken:
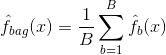
in dem du $B$ verschiedene Bootstrap-Trainingsdatensätze erzeugst. Dann trainierst du deine Methode auf der $b-ten$ Bootstrap-Trainingsmenge, um $\hat{f}_{b}(x)$ zu erhalten, und bildest schließlich den Durchschnitt der Vorhersagen.
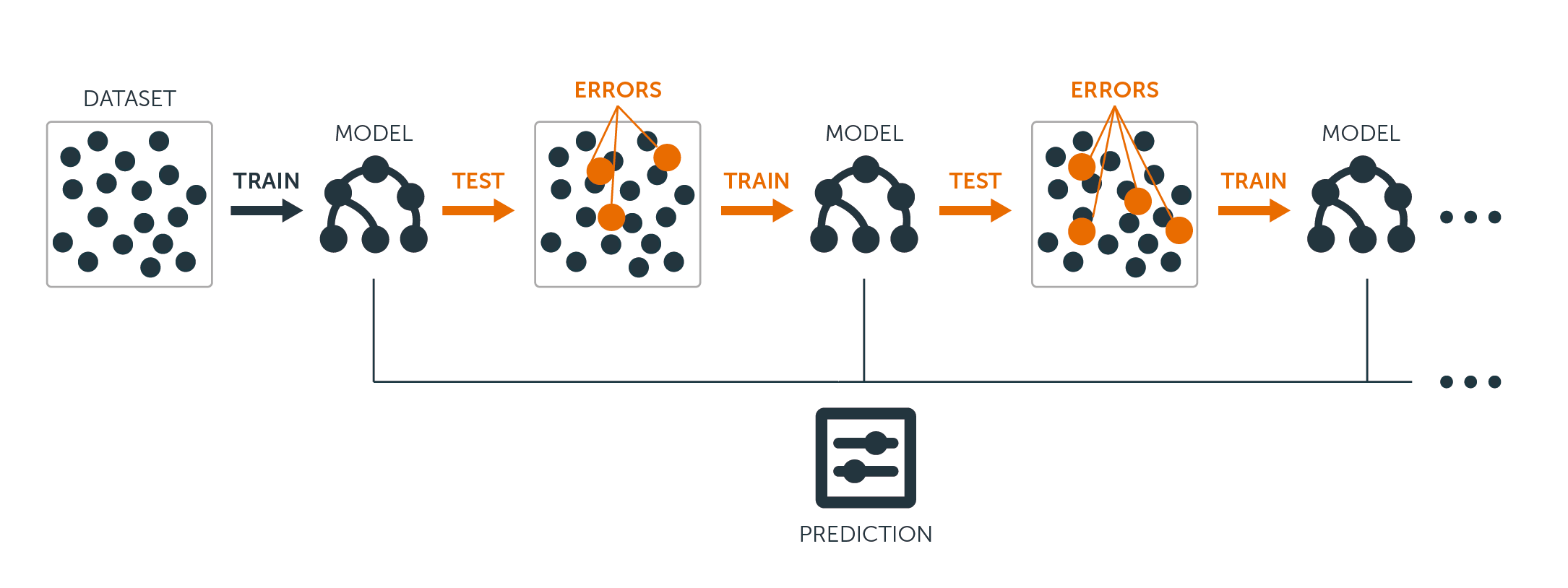
Die folgende Grafik zeigt die 3 verschiedenen Schritte beim Absacken:
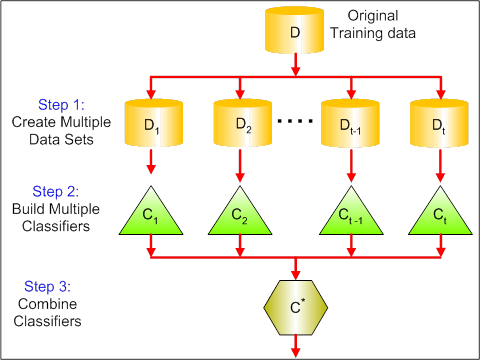
Schritt 1: Hier ersetzt du die ursprünglichen Daten durch neue Daten. Die neuen Daten haben in der Regel einen Bruchteil der Spalten und Zeilen der ursprünglichen Daten, die dann als Hyperparameter im Bagging-Modell verwendet werden können.
Schritt 2: Du erstellst Klassifikatoren für jeden Datensatz. In der Regel kannst du denselben Klassifikator für die Erstellung von Modellen und Vorhersagen verwenden.
Schritt 3: Schließlich verwendest du einen Durchschnittswert, um die Vorhersagen aller Klassifikatoren zu kombinieren, je nach Problemstellung. Im Allgemeinen sind diese kombinierten Werte robuster als ein einzelnes Modell.
Während Bagging die Vorhersagen für viele Regressions- und Klassifizierungsmethoden verbessern kann, ist es für Entscheidungsbäume besonders nützlich. Um Bagging auf Regressions-/Klassifikationsbäume anzuwenden, erstellst du einfach $B$ Regressions-/Klassifikationsbäume mit $B$ Bootstrap-Trainingsmengen und bildest den Durchschnitt der resultierenden Vorhersagen. Diese Bäume sind tief gewachsen und werden nicht zurückgeschnitten. Daher hat jeder einzelne Baum eine hohe Varianz, aber eine geringe Verzerrung. Die Mittelung dieser $B$-Bäume reduziert die Varianz.
Im Großen und Ganzen hat sich gezeigt, dass Bagging eine beeindruckende Verbesserung der Genauigkeit bringt, indem es Hunderte oder sogar Tausende von Bäumen in einem einzigen Verfahren zusammenfasst.
Random Forests ist eine vielseitige maschinelle Lernmethode, die sowohl Regressions- als auch Klassifizierungsaufgaben erfüllen kann. Es führt auch Methoden zur Dimensionsreduktion durch, behandelt fehlende Werte, Ausreißerwerte und andere wichtige Schritte der Datenexploration und leistet dabei recht gute Arbeit.
Random Forests verbessert Bagged Trees durch eine kleine Änderung, die die Bäume dekoriert. Wie beim Bagging erstellst du eine Reihe von Entscheidungsbäumen auf Basis von Bootstrap-Trainingsstichproben. Bei der Erstellung dieser Entscheidungsbäume wird jedoch jedes Mal, wenn ein Split in einem Baum in Betracht gezogen wird, eine Zufallsstichprobe von m Prädiktoren als Split-Kandidaten aus dem vollständigen Satz von $p$ Prädiktoren ausgewählt. Der Split darf nur einen dieser $m$ Prädiktoren verwenden. Das ist der Hauptunterschied zwischen Random Forests und Bagging; denn wie beim Bagging ist die Wahl des Prädiktors $m = p$.
Um einen Zufallswald wachsen zu lassen, solltest du:
Nimm zunächst an, dass die Anzahl der Fälle in der Trainingsmenge K beträgt. Ziehe dann eine Zufallsstichprobe aus diesen K Fällen und verwende diese Stichprobe als Trainingsmenge für das Wachstum des Baums.
Wenn es $p$ Eingangsvariablen gibt, gib eine Zahl $m < p$ an, so dass du an jedem Knoten $m$ Zufallsvariablen aus den $p$ auswählen kannst. Der beste Split auf diesen $m$ wird verwendet, um den Knoten zu teilen.
Jeder Baum wird anschließend so weit wie möglich angewachsen und es ist kein Rückschnitt nötig.
Schließlich fasst du die Vorhersagen der Zielbäume zusammen, um neue Daten vorherzusagen.
Random Forests sind sehr effektiv, wenn es darum geht, fehlende Daten zu schätzen und die Genauigkeit beizubehalten, wenn ein großer Teil der Daten fehlt. Sie kann auch Fehler in Datensätzen ausgleichen, in denen die Klassen unausgewogen sind. Am wichtigsten ist, dass sie mit riesigen Datensätzen mit hoher Dimensionalität umgehen kann. Ein Nachteil bei der Verwendung von Random Forests ist jedoch, dass du verrauschte Datensätze leicht überanpassen kannst, vor allem wenn du eine Regression durchführst.
Boosting ist ein weiterer Ansatz, um die Vorhersagen eines Entscheidungsbaums zu verbessern. Wie Bagging und Random Forests ist es ein allgemeiner Ansatz, der auf viele statistische Lernmethoden zur Regression oder Klassifizierung angewendet werden kann. Erinnere dich daran, dass beim Bagging mehrere Kopien des ursprünglichen Trainingsdatensatzes mithilfe des Bootstraps erstellt werden, jeder Kopie ein eigener Entscheidungsbaum zugeordnet wird und dann alle Bäume kombiniert werden, um ein einziges Vorhersagemodell zu erstellen. Jeder Baum wird auf einem Bootstrap-Datensatz aufgebaut, unabhängig von den anderen Bäumen.
Boosting funktioniert auf ähnliche Weise, nur dass die Bäume nacheinander wachsen: Jeder Baum wird anhand der Informationen der zuvor gewachsenen Bäume gezüchtet. Beim Boosting werden keine Bootstrap-Stichproben gezogen. Stattdessen wird jeder Baum an eine modifizierte Version des ursprünglichen Datensatzes angepasst.
Sowohl bei Regressions- als auch bei Klassifikationsbäumen funktioniert das Boosting wie folgt:
Im Gegensatz zur Anpassung eines einzelnen großen Entscheidungsbaums an die Daten, was auf eine harte Anpassung der Daten hinausläuft und möglicherweise zu einer Überanpassung führt, lernt der Boosting-Ansatz stattdessen langsam.
Anhand des aktuellen Modells passt du einen Entscheidungsbaum an die Residuen des Modells an. Das heißt, du passt einen Baum an, der die aktuellen Residuen und nicht das Ergebnis $Y$ als Antwort verwendet.
Anschließend fügst du diesen neuen Entscheidungsbaum in die angepasste Funktion ein, um die Residuen zu aktualisieren. Jeder dieser Bäume kann recht klein sein, mit nur wenigen Endknoten, die durch den Parameter $d$ im Algorithmus bestimmt werden. Indem du kleine Bäume an die Residuen anpasst, verbesserst du langsam $\hat{f}$ in Bereichen, in denen es nicht gut funktioniert.
Der Schrumpfungsparameter $\nu$ verlangsamt den Prozess noch weiter, sodass mehr und anders geformte Bäume die Residuen angreifen können.
Boosting ist sehr nützlich, wenn du eine große Datenmenge hast und davon ausgehst, dass die Entscheidungsbäume sehr komplex sind. Boosting wurde zur Lösung vieler anspruchsvoller Klassifizierungs- und Regressionsprobleme eingesetzt, darunter Risikoanalyse, Stimmungsanalyse, prädiktive Werbung, Preismodellierung, Umsatzschätzung und Patientendiagnose, um nur einige zu nennen.
Diese Algorithmen kombinieren im Wesentlichen die Vorhersagen mehrerer Entscheidungsbäume, um die Gesamtleistung und Stabilität zu verbessern. Nachdem wir die fortgeschrittenen Algorithmen verstanden haben, werden wir in diesem Lernprogramm mit den einfachen Entscheidungsbaummodellen fortfahren.
Wir haben viel über die Theorie und die Intuition hinter Entscheidungsbaummodellen und ihren Variationen gelernt, aber nichts ist besser, als selbst Hand anzulegen und diese Modelle zu bauen und ihre Leistung Schritt für Schritt zu bewerten.
Für die folgenden Beispiele verwenden wir den beliebten Boston Housing Dataset.
Der Datensatz Boston Housing enthält Informationen über den Wohnungsmarkt in Boston, Massachusetts, in den 1970er Jahren. Sie hat 506 Beobachtungen und 14 Variablen, darunter 13 Merkmale und 1 Zielvariable.
Die Merkmale im Boston Housing-Datensatz sind:
Die Zielvariable ist MEDV, die den Medianwert von Eigenheimen in 1000er Dollar angibt.
Ziel ist es, den Medianwert von Eigenheimen (in Tausend Dollar) anhand der vorgegebenen Merkmale vorherzusagen.
In R werden die Daten in einem Paket namens "MASS" bereitgestellt. Für dieses Lernprogramm musst du mehrere Pakete installieren und laden. Da dies eine Wiederholung wäre, demonstrieren wir diesen Prozess einmal mit dem MASS-Paket und du wiederholst ihn jedes Mal, wenn du in diesem Leitfaden ein neues Paket verwendest.
# install the package
install.packages("MASS")
# Load the MASS package
library(MASS)
# Load the Boston Housing dataset
data(Boston)Bevor du mit der Modellierung beginnst, ist es oft notwendig, die Daten durch Visualisierungen zu erkunden und Datenvorverarbeitungsschritte durchzuführen. Werfen wir einen Blick auf die Verteilung der Variablen anhand von Histogrammen.
Hier ist der Code, um sie zu erstellen:
# Load the library
library(tidymodels)
library(tidyr)
# Prepare the dataset for ggplot2
boston_data_long <- Boston %>%
pivot_longer(cols = everything(),
names_to = "variable",
values_to = "value")
# Create a histogram for all numeric variables in one plot
boston_histograms <- ggplot(boston_data_long, aes(x = value)) +
geom_histogram(bins = 30, color = "black", fill = "lightblue") +
facet_wrap(~variable, scales = "free", ncol = 4) +
labs(title = "Histograms of Numeric Variables in the Boston Housing Dataset",
x = "Value",
y = "Frequency") +
theme_minimal()
# Plot the histograms
print(boston_histograms)Und die Ausgabe sieht so aus:
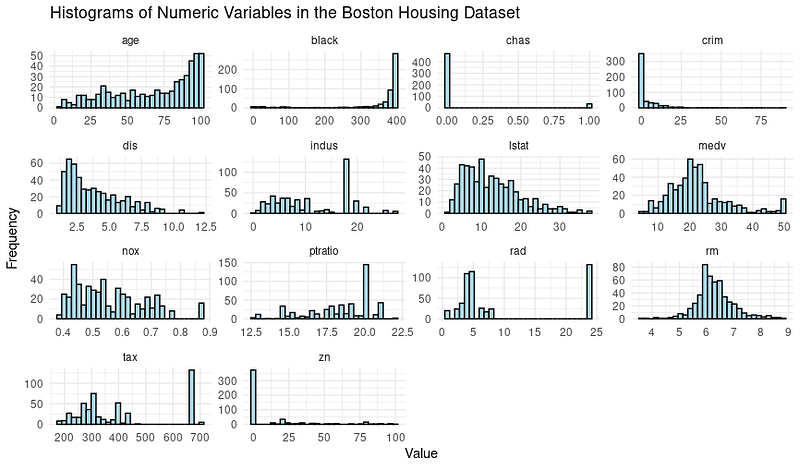
Wir stellen einige Ausreißer fest, vor allem in den Spalten RAD, TAX und NOX. In diesem Tutorial wollen wir uns auf die Phase der Entscheidungsbaummodellierung konzentrieren und teilen daher den Datensatz in einen Trainings- und einen Testdatensatz auf.
# Split the data into training and testing sets
set.seed(123)
data_split <- initial_split(Boston, prop = 0.75)
train_data <- training(data_split)
test_data <- testing(data_split)Jetzt geht es an die Modellierung und Bewertung der Modellleistung.
Mit der Funktion decision_tree() aus dem Tidymodels-Paket in R ist es ganz einfach, zuerst eine Spezifikation für ein Entscheidungsbaummodell zu erstellen und das Modell dann an die Trainingsdaten anzupassen.
# Create a decision tree model specification
tree_spec <- decision_tree() %>%
set_engine("rpart") %>%
set_mode("regression")
# Fit the model to the training data
tree_fit <- tree_spec %>%
fit(medv ~ ., data = train_data)Wir verwenden hier das "Regressions"-Modell. Für einen Klassifizierungsentscheidungsbaum müssten wir den Modus "Klassifizierung" verwenden.
Um die Leistung des Modells zu bewerten, verwenden wir das Tidymodels-Paket, um den mittleren quadratischen Fehler (RMSE) und den R-Quadrat-Wert für unser Entscheidungsbaummodell anhand der Testdaten zu berechnen.
# Make predictions on the testing data
predictions <- tree_fit %>%
predict(test_data) %>%
pull(.pred)
# Calculate RMSE and R-squared
metrics <- metric_set(rmse, rsq)
model_performance <- test_data %>%
mutate(predictions = predictions) %>%
metrics(truth = medv, estimate = predictions)
print(model_performance)Du erhältst eine Ausgabe mit zwei Leistungskennzahlen: Root Mean Squared Error (RMSE) und R-squared (R²).
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rmse standard 5.22
2 rsq standard 0.689Sind unsere Modellergebnisse also gut genug?
Wir können auch die Hyper-Parameter optimieren, um die Leistung zu steigern, oder komplexere Modelle wie Random Forests und XGBoost verwenden, die allerdings auf Kosten der Interpretierbarkeit des Modells gehen.
Wenn du mit dem Modell zufrieden bist, ist es an der Zeit, das Modell Vorhersagen machen zu lassen.
Das ist das Gleiche, was wir mit den Testdaten mit der Funktion predict() gemacht haben, aber wir müssen einen neuen Datensatz bereitstellen, der Informationen über ein neues Haus in Boston nachahmt. Das ist ein mögliches Szenario, wenn das Modell in einer Produktionsumgebung in Betrieb genommen wird.
# Make predictions on new data
new_data <- tribble(
~crim, ~zn, ~indus, ~chas, ~nox, ~rm, ~age, ~dis, ~rad, ~tax, ~ptratio, ~black, ~lstat,
0.03237, 0, 2.18, 0, 0.458, 6.998, 45.8, 6.0622, 3, 222, 18.7, 394.63, 2.94
)
predictions <- predict(tree_fit, new_data)
print(predictions)Und du erhältst den voraussichtlichen mittleren Wert (in 1000 $) für dieses Haus:
# A tibble: 1 × 1
.pred
<dbl>
1 37.8Damit kennst du die Schritte zur Erstellung eines Entscheidungsbaummodells. Jetzt wollen wir uns darauf konzentrieren, wie wir die Inhalte des Modells für uns selbst und für die Stakeholder, die die gerade erstellte Lösung nutzen, interpretieren können.
Der wichtigste Vorteil ist, wie wir bereits erwähnt haben, die Interpretierbarkeit der Entscheidungsbaummodelle. Lass uns den Entscheidungsbaum visualisieren, um das Modell besser zu verstehen:
# Load the library
library(rpart.plot)
# Plot the decision tree
rpart.plot(tree_fit$fit, type = 4, extra = 101, under = TRUE, cex = 0.8, box.palette = "auto")Du wirst ein Bild wie dieses sehen:
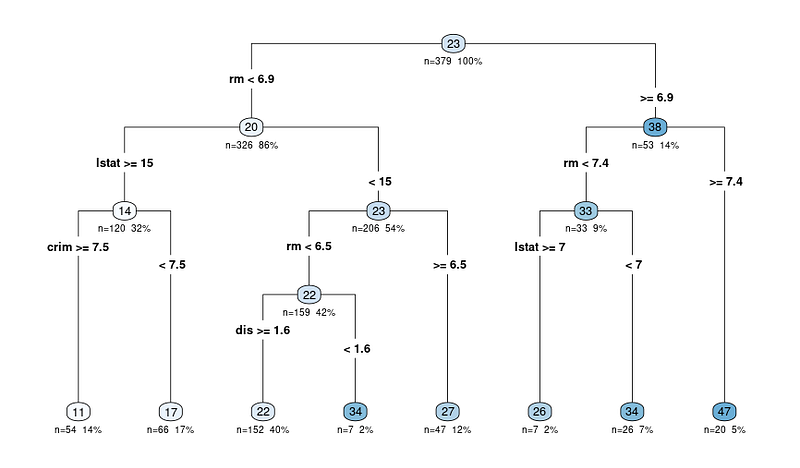
Das Ausgangsdiagramm der Funktion rpart.plot zeigt eine Entscheidungsbaumdarstellung des Modells. In diesem Diagramm steht jeder Knoten für eine Aufteilung im Entscheidungsbaum auf der Grundlage der Prädiktoren. Das Ausgabediagramm enthält mehrere Informationen, die uns bei der Interpretation des Entscheidungsbaums helfen können:
Die Knoten werden durch Kreise dargestellt und sind durch Linien verbunden, was die hierarchische Struktur des Entscheidungsbaums zeigt. Der Baum beginnt mit einem Wurzelknoten an der Spitze und verzweigt sich in interne Knoten, die schließlich zu den Endknoten oder Blättern am unteren Ende führen.
Jeder interne Knoten zeigt das Aufteilungskriterium an, d.h. die Vorhersagevariable und den Wert, der zur Aufteilung der Daten in zwei Teilmengen verwendet wird.
Ein Knoten könnte zum Beispiel "RM < 6,8" anzeigen, was bedeutet, dass Beobachtungen mit einer durchschnittlichen Anzahl von Zimmern pro Wohnung (RM) von weniger als 6,8 dem linken Zweig folgen, während Beobachtungen mit RM größer oder gleich 6,8 dem rechten Zweig folgen.
Der Wert n in jedem Knoten stellt die Anzahl der Beobachtungen im Datensatz dar, die in diesen bestimmten Knoten fallen. Wenn ein Knoten zum Beispiel "n = 100" anzeigt, bedeutet das, dass 100 Beobachtungen im Datensatz die Kriterien der übergeordneten Knoten dieses Knotens erfüllen.
Der Prozentwert hilft dir, die relative Größe jedes Knotens im Vergleich zum gesamten Datensatz zu verstehen und zeigt, wie die Daten im Baum aufgeteilt und verteilt sind. Ein höherer Prozentsatz bedeutet, dass ein größerer Anteil der Daten dem Entscheidungspfad gefolgt ist, der zu dem bestimmten Knotenpunkt führt, während ein niedrigerer Prozentsatz bedeutet, dass ein kleinerer Anteil der Daten diesen Knotenpunkt erreicht hat.
Der vorhergesagte Wert an jedem Knoten wird als Zahl in einem farbigen Kreis (Knoten) angezeigt. In einem Regressionsbaum ist dies der durchschnittliche Zielvariablenwert für alle Beobachtungen, die in diesen Knoten fallen.
Wenn zum Beispiel der letzte Leitknoten 47 anzeigt, bedeutet das, dass der durchschnittliche Wert der Zielvariablen (in unserem Fall der Medianwert der Eigenheime) für alle Beobachtungen in diesem Knoten 47 beträgt.
Wenn du also ein Ergebnis auswertest, beginnst du am Wurzelknoten und folgst den Zweigen anhand der Aufteilungskriterien, bis du einen Endknoten erreichst. Der vorhergesagte Wert im Endknoten gibt die Vorhersage des Modells für eine bestimmte Beobachtung und die Begründung für die Entscheidung an.
Wenn du es vorziehst, die Regeln in Textform zu extrahieren (anstatt das Diagramm zu durchlaufen), kannst du auch das tun, indem du dieselbe Bibliothek verwendest, die wir für die Darstellung des Diagramms benutzt haben.
Hier ist der Code dafür:
rules <- rpart.rules(tree_fit$fit)
print(rules)Du siehst dann eine Ausgabe mit den vorhergesagten Werten und den Regeln, die sie befolgen, um zu diesem Wert zu kommen:
medv
11 when rm < 6.9 & lstat >= 15 & crim >= 7.5
17 when rm < 6.9 & lstat >= 15 & crim < 7.5
22 when rm < 6.5 & lstat < 15 & dis >= 1.6
26 when rm is 6.9 to 7.4 & lstat >= 7
27 when rm is 6.5 to 6.9 & lstat < 15
34 when rm < 6.5 & lstat < 15 & dis < 1.6
34 when rm is 6.9 to 7.4 & lstat < 7
47 when rm >= 7.4Jetzt, wo du die Regeln siehst, fragst du dich vielleicht, wie die Entscheidung mit 3-4 Variablen getroffen werden kann, wenn wir viel mehr Variablen in den Entscheidungsbaum eingeben.
Nun, es hat sich herausgestellt, dass einige Variablen wichtiger sind als andere. Lass uns dieses Konzept besser verstehen.
Wir haben bereits das Baumdiagramm aufgedeckt und wie das Modell funktioniert. Ein letzter Aspekt der Interpretation ist das Verständnis der wichtigen Variablen aus dem Datensatz.
Hier ist der Grund, warum das so wichtig ist:
In Entscheidungsbäumen wird die Wichtigkeit der Variablen in der Regel durch die Merkmale bestimmt, die für die Aufteilung an den Knotenpunkten verwendet werden. Merkmale, die weiter oben im Baum zum Splitten verwendet oder häufiger genutzt werden, können als wichtiger angesehen werden.
Die Wichtigkeit einer Variable kann durch die Verringerung des Verunreinigungsmaßes (z. B. Gini-Index oder mittlerer quadratischer Fehler) quantifiziert werden, die sie mit sich bringt, wenn sie für die Aufteilung verwendet wird. Das "VIP"-Paket in R hat die ganze Komplexität beseitigt und die Grafik kann mit dem folgenden Code erstellt werden:
# Load the necessary library
library(vip)
# Create a variable importance plot
var_importance <- vip::vip(tree_fit, num_features = 10)
print(var_importance)Dann erhältst du das untenstehende Diagramm zur Bedeutung der Variablen:
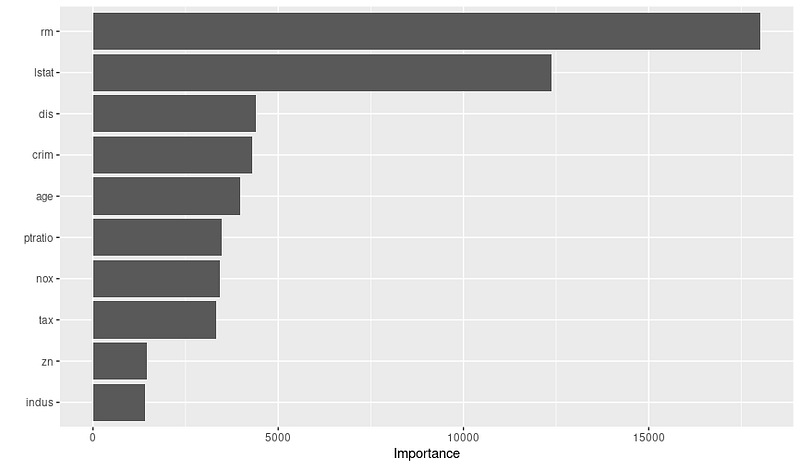
Sobald du das Diagramm siehst, kannst du in Zusammenarbeit mit Fachleuten weiter untersuchen, warum diese Variablen wichtig sind. Aus der obigen Grafik können wir zum Beispiel die 3 wichtigsten Variablen und die Gründe dafür ableiten:
Vergiss also nicht, die Variablenbedeutung zu überprüfen, bevor du dein Modell fertigstellst; dies kann dir helfen, bessere Merkmale zu erstellen und auszuwählen, um die Leistung zu optimieren.
In diesem Tutorium haben wir uns mit den grundlegenden Konzepten von Entscheidungsbäumen beschäftigt und uns nicht nur mit der Erstellung von Modellen, sondern auch mit deren Interpretation auseinandergesetzt. Entscheidungsbäume sind leistungsfähige und interpretierbare Modelle für Klassifizierungs- und Regressionsaufgaben und damit ein unverzichtbares Werkzeug im Arsenal eines Datenwissenschaftlers.
Wenn du deine Fähigkeiten weiter ausbaust, ermutigen wir dich, tiefer in die Welt der Entscheidungsbäume einzutauchen, alternative Algorithmen zu erforschen und deine R-Programmierkenntnisse zu verbessern. Hier sind einige Ressourcen für deinen nächsten Schritt:
Es besteht kein Zweifel daran, dass die Erweiterung deines Wissens und das Experimentieren mit neuen Werkzeugen und Techniken dich in die Lage versetzen wird, verschiedene Herausforderungen zu meistern und wertvolle Einblicke in deine Projekte zu erhalten.
R Kurse
Kurs
Kurs
Kurs