
Kurs
Konzepte großer Sprachmodelle (LLMs)
2 Std.
99.8K
Für diesen Lehrgang werden wir Kaggle als Programmierumgebung verwenden. Um loszulegen, erstelle ein neues Notizbuch.
Wir werden auch die OpenAI API verwenden. Um fortzufahren, erstelle einen API-Schlüssel. Richte dann die Umgebungsvariable für den OpenAI-API-Schlüssel ein, indem du die Funktion "Secrets" von Kaggle verwendest.
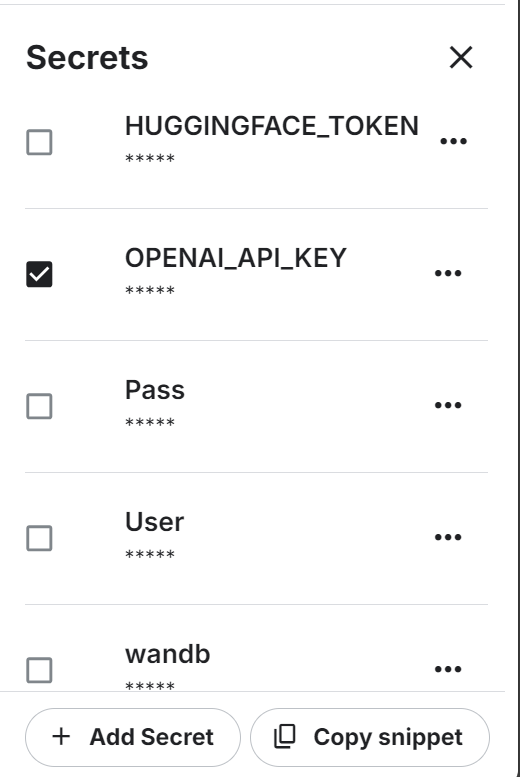
Danach installierst du die Python-Freiheit von DeepEval und BitsandBytes mit dem Befehl pip:
%%capture
%pip install -U deepeval
%pip install -U bitsandbytesLade den OpenAI API-Schlüssel von secrets:
import os
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
secret_value_0 = user_secrets.get_secret("OPENAI_API_KEY")
os.environ['OPENAI_API_KEY'] = secret_value_0Schreibe die folgende Python-Datei mit der Magiefunktion von Jupyter Notebook.
In der Datei test_relevancy.py ist eine Testfunktion definiert, die die Relevanz der Ergebnisse eines LLM mit dem GPT-4o-Modell bewertet. Dazu vergleicht es die Reaktion des Modells auf eine bestimmte Eingabe mit einem Abfragekontext und stellt so sicher, dass die Ausgabe mit den bereitgestellten Informationen übereinstimmt.
%%file test_relevancy.py
from deepeval import assert_test
from deepeval.test_case import LLMTestCase
from deepeval.metrics import AnswerRelevancyMetric
def test_relevancy():
relevancy_metric = AnswerRelevancyMetric(threshold=0.5, model="gpt-4o")
test_case_1 = LLMTestCase(
input="Can I return these shoes after 30 days?",
actual_output="Unfortunately, returns are only accepted within 30 days of purchase.",
retrieval_context=[
"All customers are eligible for a 30-day full refund at no extra cost.",
"Returns are only accepted within 30 days of purchase.",
],
)
assert_test(test_case_1, [relevancy_metric])Führe den Relevanztest im Terminal aus:
!deepeval test run test_relevancy.pyDas folgende Testergebnis zeigt, dass der LLM-Testfall den Test erfolgreich bestanden hat und einen perfekten Relevanzwert von 1,0 erreicht hat, was bedeutet, dass die Antwort des Modells vollständig relevant war.
Die Bewertung wurde in 3,04 Sekunden abgeschlossen, wobei die geschätzten Gesamtkosten des Tokens bei 0,0027425 USD lagen:
Evaluating 1 test case(s) in parallel: |█|100% (1/1) [Time Taken: 00:03, 3.00s/
.Running teardown with pytest sessionfinish...
============================= slowest 10 durations =============================
3.03s call test_relevancy.py::test_relevancy
(2 durations < 0.005s hidden. Use -vv to show these durations.)
1 passed, 2 warnings in 3.04s
Test Results
┏━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ ┃ ┃ ┃ ┃ Overall Success ┃
┃ Test case ┃ Metric ┃ Score ┃ Status ┃ Rate ┃
┡━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ test_relevancy │ │ │ │ 100.0% │
│ │ Answer │ 1.0 │ PASSED │ │
│ │ Relevancy │ (threshold=0.... │ │ │
│ │ │ evaluation │ │ │
│ │ │ model=gpt-4o, │ │ │
│ │ │ reason=The │ │ │
│ │ │ score is 1.00 │ │ │
│ │ │ because the │ │ │
│ │ │ response was │ │ │
│ │ │ perfectly │ │ │
│ │ │ relevant and │ │ │
│ │ │ addressed the │ │ │
│ │ │ question │ │ │
│ │ │ directly │ │ │
│ │ │ without any │ │ │
│ │ │ irrelevant │ │ │
│ │ │ information. │ │ │
│ │ │ Great job!, │ │ │
│ │ │ error=None) │ │ │
└────────────────┴─────────────────┴────────────────┴────────┴─────────────────┘
Total estimated evaluation tokens cost: 0.0027425 USD
✓ Tests finished 🎉! Run 'deepeval login' to save and analyze evaluation results
on Confident AI.
‼️ Friendly reminder 😇: You can also run evaluations with ALL of deepeval's
metrics directly on Confident AI instead.Du kannst LLMs auch mit dem Hugging Face-Ökosystem bewerten, indem du der HumanEval folgst: A Benchmark for Evaluating LLM Code Generation Capabilities guide.
G-Eval ist ein LLM-Evaluierungsrahmen, der das Chain-of-Thought (CoT) Reasoning nutzt, um LLM-Outputs anhand von benutzerdefinierten Kriterien zu bewerten. Als DeepEvals anpassungsfähigste Metrik kann G-Eval fast jeden Anwendungsfall mit menschenähnlicher Genauigkeit bewältigen, was es zu einem unverzichtbaren Werkzeug für die Bewertung der LLM-Leistung macht.
In diesem Abschnitt werden wir den Datensatz der LLM-Antworten mithilfe der G-Eval-Metrik bewerten.
Wir erstellen die G-eval-Metrik und stellen die benutzerdefinierte Anweisung zur Verfügung, um zu testen, ob das Modell auf sachliche Widersprüche reagiert, Auslassungen bestraft und sich auf die Hauptidee konzentriert, während es vage Formulierungen oder abweichende Meinungen toleriert:
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCaseParams
correctness_metric = GEval(
name="Correctness",
model="gpt-4o",
evaluation_params=[
LLMTestCaseParams.EXPECTED_OUTPUT,
LLMTestCaseParams.ACTUAL_OUTPUT],
evaluation_steps=[
"Check whether the facts in 'actual output' contradicts any facts in 'expected output'",
"You should also lightly penalize omission of detail, and focus on the main idea",
"Vague language, or contradicting OPINIONS, are OK"
],
)Erstelle drei LLM-Testfälle zu verschiedenen Themen. Jeder Testfall hat eine Eingabeaufforderung, eine tatsächlich erzeugte Ausgabe und eine erwartete Ausgabe. Das GPT-4o Modell vergleicht sie und liefert am Ende detaillierte Ergebnisse:
from deepeval.test_case import LLMTestCase
from deepeval.dataset import EvaluationDataset
first_test_case = LLMTestCase(input="What are the main causes of deforestation?",
actual_output="The main causes of deforestation include agricultural expansion, logging, infrastructure development, and urbanization.",
expected_output="The main causes of deforestation include agricultural expansion, logging, infrastructure development, and urbanization.")
second_test_case = LLMTestCase(input="Define the term 'artificial intelligence'.",
actual_output="Artificial intelligence is the simulation of human intelligence by machines.",
expected_output="Artificial intelligence refers to the simulation of human intelligence in machines that are programmed to think and learn like humans, including tasks such as problem-solving, decision-making, and language understanding.")
third_test_case = LLMTestCase(input="List the primary colors.",
actual_output="The primary colors are green, orange, and purple.",
expected_output="The primary colors are red, blue, and yellow.")Wir erstellen den Bewertungsdatensatz, indem wir alle drei Testfälle kombinieren:
test_cases = [first_test_case, second_test_case, third_test_case]
dataset = EvaluationDataset(test_cases=test_cases)Führe den G-Eval Bewertungstest mit dem Datensatz durch:
evaluation_output = dataset.evaluate([correctness_metric])Ausgabe:
Die Testergebnisse für jeden Test enthalten eine Zusammenfassung der Metriken, den Testfall und das Gesamtergebnis der bestandenen Metriken.
Evaluating 3 test case(s) in parallel: |██████████|100% (3/3) [Time Taken: 00:02, 1.08test case/s]
======================================================================
Metrics Summary
- ✅ Correctness (GEval) (score: 1.0, threshold: 0.5, strict: False, evaluation model: gpt-4o, reason: The actual output matches the expected output exactly with no contradictions or omissions., error: None)
For test case:
- input: What are the main causes of deforestation?
- actual output: The main causes of deforestation include agricultural expansion, logging, infrastructure development, and urbanization.
- expected output: The main causes of deforestation include agricultural expansion, logging, infrastructure development, and urbanization.
- context: None
- retrieval context: None
======================================================================
Metrics Summary
- ✅ Correctness (GEval) (score: 0.7, threshold: 0.5, strict: False, evaluation model: gpt-4o, reason: The main idea of AI as the simulation of human intelligence is present, but details like problem-solving, decision-making, and language understanding are omitted., error: None)
For test case:
- input: Define the term 'artificial intelligence'.
- actual output: Artificial intelligence is the simulation of human intelligence by machines.
- expected output: Artificial intelligence refers to the simulation of human intelligence in machines that are programmed to think and learn like humans, including tasks such as problem-solving, decision-making, and language understanding.
- context: None
- retrieval context: None
======================================================================
Metrics Summary
- ❌ Correctness (GEval) (score: 0.01681606382274469, threshold: 0.5, strict: False, evaluation model: gpt-4o, reason: The actual output directly contradicts the expected output by listing green, orange, and purple as primary colors instead of red, blue, and yellow., error: None)
For test case:
- input: List the primary colors.
- actual output: The primary colors are green, orange, and purple.
- expected output: The primary colors are red, blue, and yellow.
- context: None
- retrieval context: None
======================================================================
Overall Metric Pass Rates
Correctness (GEval): 66.67% pass rate
======================================================================Lerne, wie du LLMs mit einem beliebten Tool, MLflow, auswerten kannst, indem du dem Tutorial Evaluating LLMs with MLflow folgst.
Die Auswertung von drei Testfällen mit der G-Eval-Metrik ergab eine Erfolgsquote von 66,67 %, mit einer perfekten Übereinstimmung, einer teilweisen Übereinstimmung aufgrund fehlender Details und einem Fehlschlag aufgrund eines direkten Widerspruchs. Dies verdeutlicht die Stärken des Modells in Bezug auf die Faktengenauigkeit, aber auch seine Grenzen bei der Handhabung nuancierter oder detaillierter Ergebnisse.
MMLU (Massive Multitask Language Understanding) ist ein weit verbreiteter Benchmark für die Bewertung großer Sprachmodelle durch Multiple-Choice-Fragen. Er umfasst 57 verschiedene Fächer, darunter Mathematik, Geschichte, Recht und Ethik, und ist damit ein umfassender Test für das Wissen und die Argumentationsfähigkeit eines LLMs. Aufgrund der breiten Themenabdeckung und der hohen Qualität der Fragen hat sich die MMLU zu einem Standard für die Bewertung von LLM-Leistungen entwickelt.
Wir werden einen weiteren Schritt nach vorne machen und unsere benutzerdefinierte LLM (Qwen 2.5 7B) auf dem MMLU-Datensatz testen. Der Datensatz enthält Eingabeaufforderungen und Ergebnisse (A, B, C, D). Am Ende wird anhand der richtig beantworteten Punkte ein Prozentsatz der Genauigkeit ermittelt.
Wir werden eine benutzerdefinierte Klasse namens QwenModel definieren, die DeepEvalBaseLLM erweitert, um Antworten unter Verwendung des Sprachmodells und des Tokenizers zu erzeugen.
Unser Ziel ist es, kurze Ausgaben von zwei Token auf der Grundlage einer vorgegebenen Aufforderung zu produzieren. Außerdem kümmern wir uns um die Gerätezuweisung und die Vorverarbeitung der Eingabeaufforderung und des Ausgabetextes.
from deepeval.models.base_model import DeepEvalBaseLLM
import torch, logging
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
class QwenModel(DeepEvalBaseLLM):
def __init__(self, model, tokenizer):
self.model = model
self.tokenizer = tokenizer
self.device = "cuda"
def load_model(self):
return self.model
def generate(self, prompt: str) -> str:
prompt = prompt.replace("Output 'A', 'B', 'C', or 'D'. Full answer not needed.","")
model_inputs = self.tokenizer([prompt], return_tensors="pt").to(self.device)
generated_ids = self.model.generate(
**model_inputs,
max_new_tokens=2,
do_sample=True,
pad_token_id=self.tokenizer.eos_token_id
)
prompt_length = len(model_inputs[0])
generated_tokens = generated_ids[0][prompt_length:]
clean_output = tokenizer.decode(generated_tokens, skip_special_tokens=True).strip()
return clean_output.replace(".","")
async def a_generate(self, prompt: str) -> str:
return self.generate(prompt)
def get_model_name(self):
return "Qwen2.5 7B"Wir werden die beiden Funktionen erstellen, die das LLM-Modell und den Tokenizer direkt aus dem Local laden. Wir laden das Modell in 8 Bit und initialisieren einen Tokenizer für dasselbe Modell, indem wir Padding und spezielle Token-Konfigurationen einstellen:
def load_model(model_name: str):
quant_config = BitsAndBytesConfig(
load_in_8bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=False
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=quant_config,
device_map="auto"
)
model.config.use_cache = False
model.config.pretraining_tp = 1
return model
def load_tokenizer(model_name):
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
return tokenizerFüge das Qwen 2.4 7b Lehrmodell zum Kaggle-Notizbuch hinzu, indem du die Schaltfläche "+ Eingabe hinzufügen" betätigst.
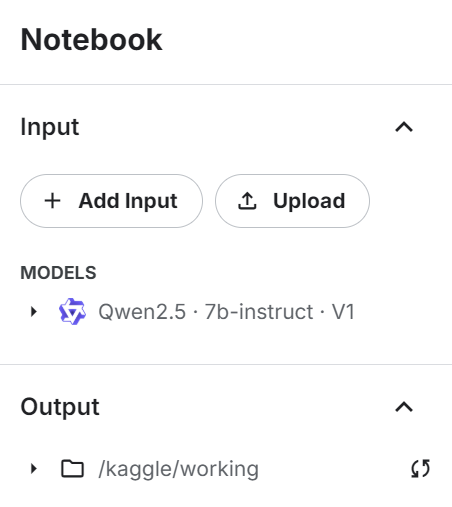
Verwende das Modell direkt, um das Modell und das Token zu laden, und stelle es dann der benutzerdefinierten LLM-Klasse zur Verfügung, um einen LLM-Antwortgenerator zu erstellen:
# Load model and tokenizer
qwen_model_name = "/kaggle/input/qwen2.5/transformers/7b-instruct/1"
model = load_model(qwen_model_name)
tokenizer = load_tokenizer(qwen_model_name)
custom_model = QwenModel(model, tokenizer)Teste das benutzerdefinierte LLM, bevor du die Benchmarking-Ergebnisse generierst:
# Test model generation
prompt = """
The following are multiple choice questions (with answers) about abstract algebra.
Find all c in Z_3 such that Z_3[x]/(x^2 + c) is a field.
A. 0
B. 1
C. 2
D. 3
Answer:"""
print(custom_model.generate(prompt))Wir haben dem LLM eine Probeaufforderung aus dem Datensatz gegeben, und er hat genau mit einem Buchstaben geantwortet.
CJetzt laden wir den MMLU-Benchmark, definieren die Aufgaben und führen den Benchmark mit dem benutzerdefinierten Modell durch:
from deepeval.benchmarks import MMLU
from deepeval.benchmarks.tasks import MMLUTask
# Define benchmark with specific tasks and shots
benchmark = MMLU(
tasks=[MMLUTask.HIGH_SCHOOL_COMPUTER_SCIENCE, MMLUTask.ASTRONOMY],
n_shots=5
)
benchmark.evaluate(model=custom_model, batch_size=5)Wir haben mit 83% Genauigkeit hervorragende Ergebnisse erzielt!
Processing astronomy: 100%|██████████| 152/152 [01:51<00:00, 1.36it/s]
MMLU Task Accuracy (task=astronomy): 0.8157894736842105
Overall MMLU Accuracy: 0.8293650793650794Schauen wir uns die Ergebnisse der einzelnen Aufgaben an:
benchmark.task_scores
Du kannst dir auch die vollständigen Ergebnisse ansehen, die zeigen, welche Probe das richtige Ergebnis erzielt hat und welche nicht. Dies ermöglicht eine detaillierte Analyse der Leistung des Modells.
benchmark.predictions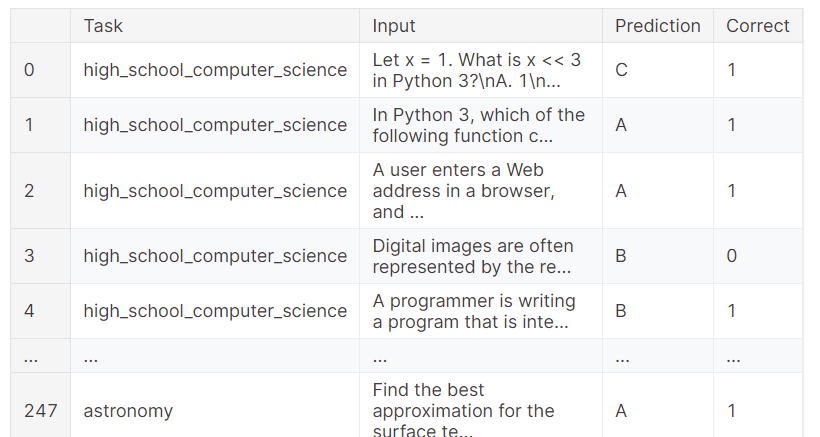
Wenn du Probleme beim Ausführen des obigen Codes hast,lies bitte das Kaggle-Notebook Evaluating LLMs with DeepEval . Sie enthält Code-Quellen, Datensätze und Bewertungsergebnisse.
Die Bewertung von Sprachmodellen kann eine Herausforderung sein, besonders in einer Produktionsumgebung. Manchmal sind einfache Bewertungsmaßstäbe nicht ausreichend. Es ist wichtig, eine Reihe von Benchmarks und Tests durchzuführen, um die Leistung deines LLM in verschiedenen Aufgaben und Funktionen zu bewerten, um ein umfassendes Verständnis zu erlangen und Bereiche mit Verbesserungspotenzial zu identifizieren.
In diesem Tutorial haben wir DeepEval in einem Kaggle-Notebook eingerichtet und LLM-Tests ähnlich wie Pytests durchgeführt. Dann haben wir G-Eval mit Hilfe von benutzerdefinierten Anweisungen erstellt und mit dem Evaluierungsdatensatz ausgeführt. Schließlich haben wir das Qwen 2.5 7B-Modell mit dem MMLU-Benchmark getestet, um seine Leistung in den Fächern Informatik und Astronomie zu analysieren.
Der nächste Schritt auf deiner Lernreise besteht darin, LLMOps-Tools und -Methoden zu erkunden und zu lernen, wie du ein LLM problemlos in der Produktion einsetzen kannst. Wenn du mehr wissen willst, solltest du den Kurs LLMOps-Konzepte besuchen.
Erfahre mehr über LLMs mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.