
Curso
Conceitos de Grandes Modelos de Linguagem (LLMs)
2 h
100.1K
Para este tutorial, usaremos o Kaggle como nosso ambiente de codificação. Para começar, crie um novo notebook.
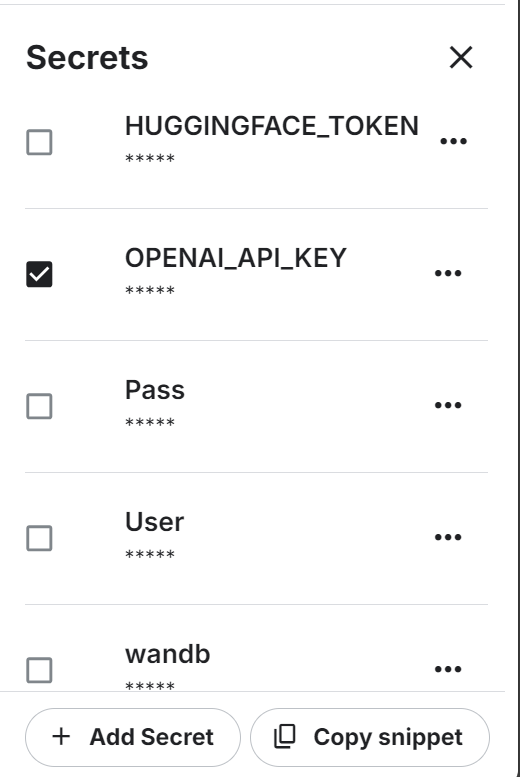
Também usaremos a API da OpenAI. Para continuar, crie uma chave de API. Em seguida, configure a variável de ambiente para a chave da API do OpenAI usando o recurso "Secrets" do Kaggle.
Depois disso, instale a liberdade do DeepEval e do BitsandBytes Python usando o comando pip:
%%capture
%pip install -U deepeval
%pip install -U bitsandbytesCarregue a chave da API da OpenAI dos segredos:
import os
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
secret_value_0 = user_secrets.get_secret("OPENAI_API_KEY")
os.environ['OPENAI_API_KEY'] = secret_value_0Escreva o seguinte arquivo Python usando a função mágica do Jupyter Notebook.
O arquivo test_relevancy.py define uma função de teste que avalia a relevância da saída de um LLM usando o modelo GPT-4o. Ele faz isso comparando a resposta do modelo a uma determinada entrada com um contexto de recuperação, garantindo que a saída esteja alinhada com as informações fornecidas.
%%file test_relevancy.py
from deepeval import assert_test
from deepeval.test_case import LLMTestCase
from deepeval.metrics import AnswerRelevancyMetric
def test_relevancy():
relevancy_metric = AnswerRelevancyMetric(threshold=0.5, model="gpt-4o")
test_case_1 = LLMTestCase(
input="Can I return these shoes after 30 days?",
actual_output="Unfortunately, returns are only accepted within 30 days of purchase.",
retrieval_context=[
"All customers are eligible for a 30-day full refund at no extra cost.",
"Returns are only accepted within 30 days of purchase.",
],
)
assert_test(test_case_1, [relevancy_metric])Execute o teste de relevância no terminal:
!deepeval test run test_relevancy.pyO resultado do teste a seguir mostra que o caso de teste do LLM foi aprovado no teste e obteve uma pontuação de relevância perfeita de 1,0, indicando que a resposta do modelo foi totalmente relevante.
A avaliação foi concluída em 3,04 segundos, com um custo total de token estimado em US$ 0,0027425:
Evaluating 1 test case(s) in parallel: |█|100% (1/1) [Time Taken: 00:03, 3.00s/
.Running teardown with pytest sessionfinish...
============================= slowest 10 durations =============================
3.03s call test_relevancy.py::test_relevancy
(2 durations < 0.005s hidden. Use -vv to show these durations.)
1 passed, 2 warnings in 3.04s
Test Results
┏━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ ┃ ┃ ┃ ┃ Overall Success ┃
┃ Test case ┃ Metric ┃ Score ┃ Status ┃ Rate ┃
┡━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ test_relevancy │ │ │ │ 100.0% │
│ │ Answer │ 1.0 │ PASSED │ │
│ │ Relevancy │ (threshold=0.... │ │ │
│ │ │ evaluation │ │ │
│ │ │ model=gpt-4o, │ │ │
│ │ │ reason=The │ │ │
│ │ │ score is 1.00 │ │ │
│ │ │ because the │ │ │
│ │ │ response was │ │ │
│ │ │ perfectly │ │ │
│ │ │ relevant and │ │ │
│ │ │ addressed the │ │ │
│ │ │ question │ │ │
│ │ │ directly │ │ │
│ │ │ without any │ │ │
│ │ │ irrelevant │ │ │
│ │ │ information. │ │ │
│ │ │ Great job!, │ │ │
│ │ │ error=None) │ │ │
└────────────────┴─────────────────┴────────────────┴────────┴─────────────────┘
Total estimated evaluation tokens cost: 0.0027425 USD
✓ Tests finished 🎉! Run 'deepeval login' to save and analyze evaluation results
on Confident AI.
‼️ Friendly reminder 😇: You can also run evaluations with ALL of deepeval's
metrics directly on Confident AI instead.Você também pode avaliar os LLMs usando os ecossistemas Hugging Face seguindo o endereço HumanEval: Uma referência para avaliar os recursos de geração de código LLM guide.
O G-Eval é uma estrutura de avaliação do LLM que usa raciocínio de cadeia de raciocínio (CoT) para avaliar os resultados do LLM com base em critérios personalizados. Como a métrica mais adaptável do DeepEval, o G-Eval pode lidar com praticamente qualquer caso de uso com precisão semelhante à humana, tornando-o uma ferramenta essencial para avaliar o desempenho do LLM.
Nesta seção, avaliaremos o conjunto de dados de respostas LLM usando a métrica G-Eval.
Criaremos a métrica G-eval e forneceremos as instruções personalizadas para testar o modelo quanto a contradições factuais, penalizar omissões e concentrar-se na ideia principal, tolerando linguagem vaga ou opiniões divergentes:
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCaseParams
correctness_metric = GEval(
name="Correctness",
model="gpt-4o",
evaluation_params=[
LLMTestCaseParams.EXPECTED_OUTPUT,
LLMTestCaseParams.ACTUAL_OUTPUT],
evaluation_steps=[
"Check whether the facts in 'actual output' contradicts any facts in 'expected output'",
"You should also lightly penalize omission of detail, and focus on the main idea",
"Vague language, or contradicting OPINIONS, are OK"
],
)Crie três casos de teste LLM em tópicos diferentes. Cada caso de teste tem um prompt de entrada, uma saída real gerada e uma saída esperada. O modelo GPT-4o os comparará e gerará resultados detalhados no final:
from deepeval.test_case import LLMTestCase
from deepeval.dataset import EvaluationDataset
first_test_case = LLMTestCase(input="What are the main causes of deforestation?",
actual_output="The main causes of deforestation include agricultural expansion, logging, infrastructure development, and urbanization.",
expected_output="The main causes of deforestation include agricultural expansion, logging, infrastructure development, and urbanization.")
second_test_case = LLMTestCase(input="Define the term 'artificial intelligence'.",
actual_output="Artificial intelligence is the simulation of human intelligence by machines.",
expected_output="Artificial intelligence refers to the simulation of human intelligence in machines that are programmed to think and learn like humans, including tasks such as problem-solving, decision-making, and language understanding.")
third_test_case = LLMTestCase(input="List the primary colors.",
actual_output="The primary colors are green, orange, and purple.",
expected_output="The primary colors are red, blue, and yellow.")Criaremos o conjunto de dados de avaliação combinando os três casos de teste:
test_cases = [first_test_case, second_test_case, third_test_case]
dataset = EvaluationDataset(test_cases=test_cases)Execute o teste de avaliação G-Eval no conjunto de dados:
evaluation_output = dataset.evaluate([correctness_metric])Saída:
Os resultados de cada teste vêm com um resumo da métrica, caso de teste e resultado geral de aprovação da métrica.
Evaluating 3 test case(s) in parallel: |██████████|100% (3/3) [Time Taken: 00:02, 1.08test case/s]
======================================================================
Metrics Summary
- ✅ Correctness (GEval) (score: 1.0, threshold: 0.5, strict: False, evaluation model: gpt-4o, reason: The actual output matches the expected output exactly with no contradictions or omissions., error: None)
For test case:
- input: What are the main causes of deforestation?
- actual output: The main causes of deforestation include agricultural expansion, logging, infrastructure development, and urbanization.
- expected output: The main causes of deforestation include agricultural expansion, logging, infrastructure development, and urbanization.
- context: None
- retrieval context: None
======================================================================
Metrics Summary
- ✅ Correctness (GEval) (score: 0.7, threshold: 0.5, strict: False, evaluation model: gpt-4o, reason: The main idea of AI as the simulation of human intelligence is present, but details like problem-solving, decision-making, and language understanding are omitted., error: None)
For test case:
- input: Define the term 'artificial intelligence'.
- actual output: Artificial intelligence is the simulation of human intelligence by machines.
- expected output: Artificial intelligence refers to the simulation of human intelligence in machines that are programmed to think and learn like humans, including tasks such as problem-solving, decision-making, and language understanding.
- context: None
- retrieval context: None
======================================================================
Metrics Summary
- ❌ Correctness (GEval) (score: 0.01681606382274469, threshold: 0.5, strict: False, evaluation model: gpt-4o, reason: The actual output directly contradicts the expected output by listing green, orange, and purple as primary colors instead of red, blue, and yellow., error: None)
For test case:
- input: List the primary colors.
- actual output: The primary colors are green, orange, and purple.
- expected output: The primary colors are red, blue, and yellow.
- context: None
- retrieval context: None
======================================================================
Overall Metric Pass Rates
Correctness (GEval): 66.67% pass rate
======================================================================Saiba como avaliar LLMs com uma de suas ferramentas favoritas, o MLflow, seguindo o tutorial Avaliando LLMs com o MLflow.
A avaliação de três casos de teste usando a métrica G-Eval atingiu uma taxa de aprovação de 66,67%, com uma correspondência perfeita, uma correspondência parcial devido à falta de detalhes e uma falha causada por uma contradição direta. Isso destaca os pontos fortes do modelo em termos de precisão factual, mas também suas limitações em lidar com resultados matizados ou detalhados.
O MMLU (Massive Multitask Language Understanding) é um benchmark amplamente usado para avaliar grandes modelos de linguagem por meio de perguntas de múltipla escolha. Ela abrange 57 assuntos diferentes, incluindo matemática, história, direito e ética, o que a torna um teste abrangente das habilidades de conhecimento e raciocínio de um LLM. Devido à sua ampla cobertura de assuntos e perguntas de alta qualidade, o MMLU se tornou um padrão para avaliar o desempenho do LLM.
Daremos mais um passo adiante e avaliaremos nosso LLM personalizado (Qwen 2.5 7B) no conjunto de dados MMLU. O conjunto de dados contém prompts de entrada e resultados (A, B, C, D). No final, ele usa a pontuação das respostas corretas para gerar uma porcentagem de precisão.
Definiremos uma classe personalizada chamada QwenModel que estende DeepEvalBaseLLM para gerar respostas usando o modelo de linguagem e o tokenizador.
Nosso objetivo é produzir resultados curtos de dois tokens com base em um determinado prompt. Além disso, gerenciaremos a alocação de dispositivos e trataremos do pré-processamento do prompt de entrada e do texto de saída.
from deepeval.models.base_model import DeepEvalBaseLLM
import torch, logging
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
class QwenModel(DeepEvalBaseLLM):
def __init__(self, model, tokenizer):
self.model = model
self.tokenizer = tokenizer
self.device = "cuda"
def load_model(self):
return self.model
def generate(self, prompt: str) -> str:
prompt = prompt.replace("Output 'A', 'B', 'C', or 'D'. Full answer not needed.","")
model_inputs = self.tokenizer([prompt], return_tensors="pt").to(self.device)
generated_ids = self.model.generate(
**model_inputs,
max_new_tokens=2,
do_sample=True,
pad_token_id=self.tokenizer.eos_token_id
)
prompt_length = len(model_inputs[0])
generated_tokens = generated_ids[0][prompt_length:]
clean_output = tokenizer.decode(generated_tokens, skip_special_tokens=True).strip()
return clean_output.replace(".","")
async def a_generate(self, prompt: str) -> str:
return self.generate(prompt)
def get_model_name(self):
return "Qwen2.5 7B"Criaremos as duas funções que carregam o modelo LLM e o tokenizador diretamente do local. Carregamos o modelo em 8 bits e inicializamos um tokenizador para o mesmo modelo, definindo configurações de preenchimento e token especial:
def load_model(model_name: str):
quant_config = BitsAndBytesConfig(
load_in_8bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=False
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=quant_config,
device_map="auto"
)
model.config.use_cache = False
model.config.pretraining_tp = 1
return model
def load_tokenizer(model_name):
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
return tokenizerAdicione o modelo de instrução Qwen 2.4 7b ao notebook do Kaggle usando o botão "+ Add Input".
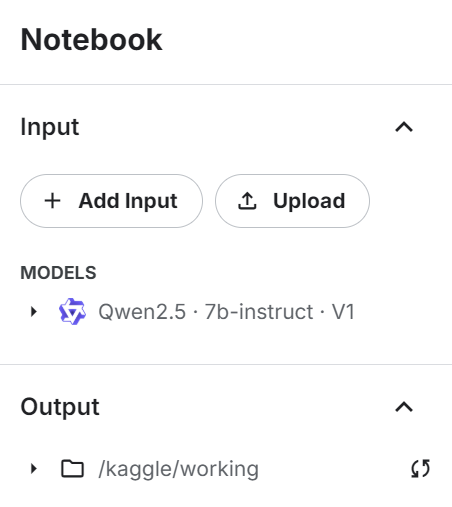
Use o modelo diretamente para carregar o modelo e o token e, em seguida, forneça-o à classe LLM personalizada para criar um gerador de resposta LLM:
# Load model and tokenizer
qwen_model_name = "/kaggle/input/qwen2.5/transformers/7b-instruct/1"
model = load_model(qwen_model_name)
tokenizer = load_tokenizer(qwen_model_name)
custom_model = QwenModel(model, tokenizer)Teste o LLM personalizado antes de gerar os resultados de benchmarking:
# Test model generation
prompt = """
The following are multiple choice questions (with answers) about abstract algebra.
Find all c in Z_3 such that Z_3[x]/(x^2 + c) is a field.
A. 0
B. 1
C. 2
D. 3
Answer:"""
print(custom_model.generate(prompt))Fornecemos ao LLM um exemplo de solicitação do conjunto de dados, e ele respondeu com precisão com uma letra.
CAgora, carregaremos o benchmark MMLU, definiremos as tarefas e, em seguida, executaremos o benchmark no modelo personalizado:
from deepeval.benchmarks import MMLU
from deepeval.benchmarks.tasks import MMLUTask
# Define benchmark with specific tasks and shots
benchmark = MMLU(
tasks=[MMLUTask.HIGH_SCHOOL_COMPUTER_SCIENCE, MMLUTask.ASTRONOMY],
n_shots=5
)
benchmark.evaluate(model=custom_model, batch_size=5)Obtivemos excelentes resultados com 83% de precisão!
Processing astronomy: 100%|██████████| 152/152 [01:51<00:00, 1.36it/s]
MMLU Task Accuracy (task=astronomy): 0.8157894736842105
Overall MMLU Accuracy: 0.8293650793650794Vamos analisar os resultados de cada tarefa individual:
benchmark.task_scores
Você também pode verificar os resultados completos, que mostram qual amostra obteve o resultado correto e qual falhou. Isso fornece uma análise granular do desempenho do modelo.
benchmark.predictions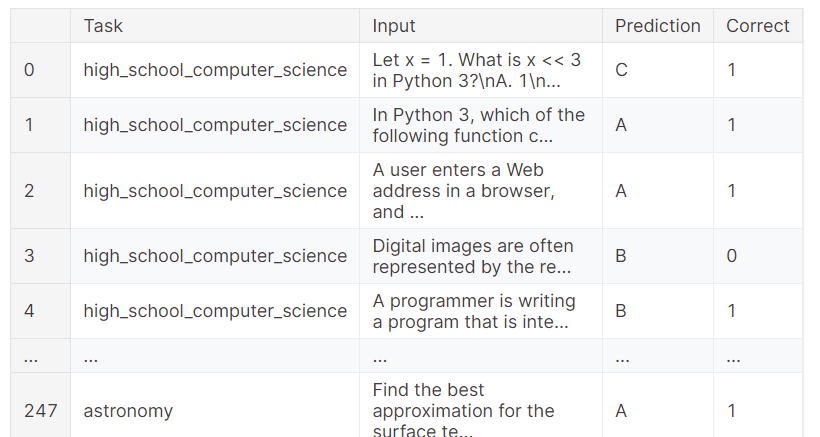
Se você tiver algum problema ao executar o código acima, consulte o notebook do Kaggle Evaluating LLMs with DeepEval . Ele contém fontes de código, conjuntos de dados e resultados de avaliação.
A avaliação de modelos de linguagem pode ser um desafio, especialmente em um ambiente de produção. Às vezes, métricas de avaliação simples não são suficientes. É essencial executar um conjunto de benchmarks e testes para avaliar o desempenho do seu LLM em várias tarefas e funções, a fim de obter uma compreensão abrangente e identificar as áreas que precisam ser aprimoradas.
Neste tutorial, configuramos o DeepEval em um notebook do Kaggle e realizamos testes LLM semelhantes aos do Pytests. Em seguida, criamos o G-Eval usando instruções personalizadas e o executamos no conjunto de dados de avaliação. Por fim, testamos o modelo Qwen 2.5 7B com o benchmark de avaliação MMLU para analisar seu desempenho em ciência da computação e astronomia no ensino médio.
A próxima etapa de sua jornada de aprendizado é explorar as ferramentas e metodologias do LLMOps e aprender como implantar um LLM facilmente na produção. Para obter mais informações, considere fazer o curso Conceitos de LLMOps.
Saiba mais sobre LLMs com estes cursos!
Curso
Curso
Curso
blog
Stanislav Karzhev
9 min
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Moez Ali

