
Curso
Conceptos de grandes modelos lingüísticos (LLM)
2 h
99.8K
Para este tutorial, utilizaremos Kaggle como entorno de codificación. Para empezar, crea una libreta nueva.
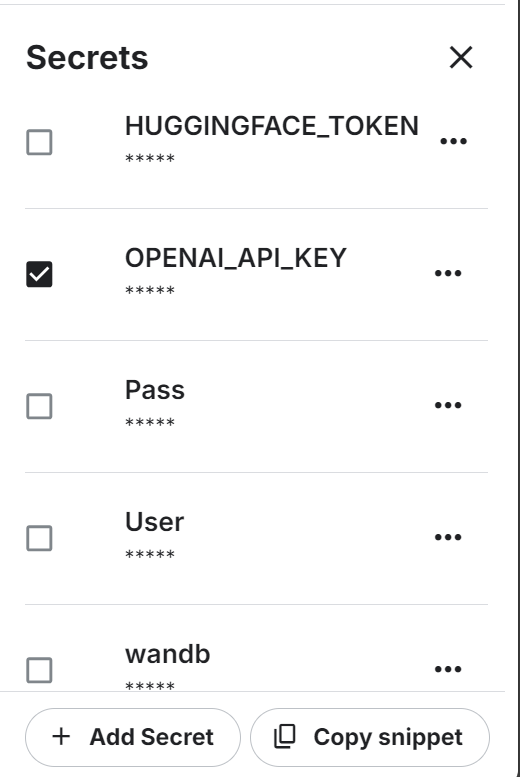
También utilizaremos la API OpenAI. Para continuar, crea una clave API. A continuación, configura la variable de entorno para la clave API de OpenAI utilizando la función "Secretos" de Kaggle.
Después, instala la libertad de Python de DeepEval y BitsandBytes utilizando el comando pip:
%%capture
%pip install -U deepeval
%pip install -U bitsandbytesCarga la clave de la API de OpenAI desde secretos:
import os
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
secret_value_0 = user_secrets.get_secret("OPENAI_API_KEY")
os.environ['OPENAI_API_KEY'] = secret_value_0Escribe el siguiente archivo Python utilizando la función mágica de Jupyter Notebook.
El archivo test_relevancy.py define una función de prueba que evalúa la relevancia de la salida de un LLM utilizando el modelo GPT-4o. Lo hace comparando la respuesta del modelo a una entrada dada con un contexto de recuperación, asegurándose de que la salida se ajusta a la información proporcionada.
%%file test_relevancy.py
from deepeval import assert_test
from deepeval.test_case import LLMTestCase
from deepeval.metrics import AnswerRelevancyMetric
def test_relevancy():
relevancy_metric = AnswerRelevancyMetric(threshold=0.5, model="gpt-4o")
test_case_1 = LLMTestCase(
input="Can I return these shoes after 30 days?",
actual_output="Unfortunately, returns are only accepted within 30 days of purchase.",
retrieval_context=[
"All customers are eligible for a 30-day full refund at no extra cost.",
"Returns are only accepted within 30 days of purchase.",
],
)
assert_test(test_case_1, [relevancy_metric])Ejecuta la prueba de relevancia en el terminal:
!deepeval test run test_relevancy.pyEl siguiente resultado de la prueba muestra que el caso de prueba LLM ha superado con éxito la prueba y ha obtenido una puntuación de relevancia perfecta de 1,0, lo que indica que la respuesta del modelo era completamente relevante.
La evaluación se completó en 3,04 segundos con un coste total estimado del token de 0,0027425 USD:
Evaluating 1 test case(s) in parallel: |█|100% (1/1) [Time Taken: 00:03, 3.00s/
.Running teardown with pytest sessionfinish...
============================= slowest 10 durations =============================
3.03s call test_relevancy.py::test_relevancy
(2 durations < 0.005s hidden. Use -vv to show these durations.)
1 passed, 2 warnings in 3.04s
Test Results
┏━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ ┃ ┃ ┃ ┃ Overall Success ┃
┃ Test case ┃ Metric ┃ Score ┃ Status ┃ Rate ┃
┡━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ test_relevancy │ │ │ │ 100.0% │
│ │ Answer │ 1.0 │ PASSED │ │
│ │ Relevancy │ (threshold=0.... │ │ │
│ │ │ evaluation │ │ │
│ │ │ model=gpt-4o, │ │ │
│ │ │ reason=The │ │ │
│ │ │ score is 1.00 │ │ │
│ │ │ because the │ │ │
│ │ │ response was │ │ │
│ │ │ perfectly │ │ │
│ │ │ relevant and │ │ │
│ │ │ addressed the │ │ │
│ │ │ question │ │ │
│ │ │ directly │ │ │
│ │ │ without any │ │ │
│ │ │ irrelevant │ │ │
│ │ │ information. │ │ │
│ │ │ Great job!, │ │ │
│ │ │ error=None) │ │ │
└────────────────┴─────────────────┴────────────────┴────────┴─────────────────┘
Total estimated evaluation tokens cost: 0.0027425 USD
✓ Tests finished 🎉! Run 'deepeval login' to save and analyze evaluation results
on Confident AI.
‼️ Friendly reminder 😇: You can also run evaluations with ALL of deepeval's
metrics directly on Confident AI instead.También puedes evaluar a los LLM utilizando los ecosistemas de Cara Abrazada siguiendo el enlace HumanEval: Un punto de referencia para evaluar las capacidades de generación de código LLM guide.
G-Eval es un marco de evaluación de LLM que utiliza el razonamiento de la cadena de pensamiento (CoT) para evaluar los resultados de LLM basándose en criterios personalizados. Como métrica más adaptable de DeepEval, G-Eval puede manejar casi cualquier caso de uso con una precisión similar a la humana, lo que la convierte en una herramienta esencial para evaluar el rendimiento de los LLM.
En esta sección, evaluaremos el conjunto de datos de respuestas LLM utilizando la métrica G-Eval.
Crearemos la métrica G-eval y proporcionaremos la instrucción personalizada para probar el reposo del modelo ante las contradicciones fácticas, penalizar las omisiones y concentrarse en la idea principal, tolerando al mismo tiempo el lenguaje vago o las opiniones divergentes:
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCaseParams
correctness_metric = GEval(
name="Correctness",
model="gpt-4o",
evaluation_params=[
LLMTestCaseParams.EXPECTED_OUTPUT,
LLMTestCaseParams.ACTUAL_OUTPUT],
evaluation_steps=[
"Check whether the facts in 'actual output' contradicts any facts in 'expected output'",
"You should also lightly penalize omission of detail, and focus on the main idea",
"Vague language, or contradicting OPINIONS, are OK"
],
)Crea tres casos de prueba LLM sobre temas diferentes. Cada caso de prueba tiene una pregunta de entrada, una salida real generada y una salida esperada. El modelo GPT-4o los comparará y generará resultados detallados al final:
from deepeval.test_case import LLMTestCase
from deepeval.dataset import EvaluationDataset
first_test_case = LLMTestCase(input="What are the main causes of deforestation?",
actual_output="The main causes of deforestation include agricultural expansion, logging, infrastructure development, and urbanization.",
expected_output="The main causes of deforestation include agricultural expansion, logging, infrastructure development, and urbanization.")
second_test_case = LLMTestCase(input="Define the term 'artificial intelligence'.",
actual_output="Artificial intelligence is the simulation of human intelligence by machines.",
expected_output="Artificial intelligence refers to the simulation of human intelligence in machines that are programmed to think and learn like humans, including tasks such as problem-solving, decision-making, and language understanding.")
third_test_case = LLMTestCase(input="List the primary colors.",
actual_output="The primary colors are green, orange, and purple.",
expected_output="The primary colors are red, blue, and yellow.")Crearemos el conjunto de datos de evaluación combinando los tres casos de prueba:
test_cases = [first_test_case, second_test_case, third_test_case]
dataset = EvaluationDataset(test_cases=test_cases)Ejecuta la prueba de evaluación G-Eval en el conjunto de datos:
evaluation_output = dataset.evaluate([correctness_metric])Salida:
Los resultados de cada prueba vienen con un resumen de métricas, un caso de prueba y un resultado global de aprobación de métricas.
Evaluating 3 test case(s) in parallel: |██████████|100% (3/3) [Time Taken: 00:02, 1.08test case/s]
======================================================================
Metrics Summary
- ✅ Correctness (GEval) (score: 1.0, threshold: 0.5, strict: False, evaluation model: gpt-4o, reason: The actual output matches the expected output exactly with no contradictions or omissions., error: None)
For test case:
- input: What are the main causes of deforestation?
- actual output: The main causes of deforestation include agricultural expansion, logging, infrastructure development, and urbanization.
- expected output: The main causes of deforestation include agricultural expansion, logging, infrastructure development, and urbanization.
- context: None
- retrieval context: None
======================================================================
Metrics Summary
- ✅ Correctness (GEval) (score: 0.7, threshold: 0.5, strict: False, evaluation model: gpt-4o, reason: The main idea of AI as the simulation of human intelligence is present, but details like problem-solving, decision-making, and language understanding are omitted., error: None)
For test case:
- input: Define the term 'artificial intelligence'.
- actual output: Artificial intelligence is the simulation of human intelligence by machines.
- expected output: Artificial intelligence refers to the simulation of human intelligence in machines that are programmed to think and learn like humans, including tasks such as problem-solving, decision-making, and language understanding.
- context: None
- retrieval context: None
======================================================================
Metrics Summary
- ❌ Correctness (GEval) (score: 0.01681606382274469, threshold: 0.5, strict: False, evaluation model: gpt-4o, reason: The actual output directly contradicts the expected output by listing green, orange, and purple as primary colors instead of red, blue, and yellow., error: None)
For test case:
- input: List the primary colors.
- actual output: The primary colors are green, orange, and purple.
- expected output: The primary colors are red, blue, and yellow.
- context: None
- retrieval context: None
======================================================================
Overall Metric Pass Rates
Correctness (GEval): 66.67% pass rate
======================================================================Aprende a evaluar LLMs con una herramienta favorita, MLflow, siguiendo el tutorial Evaluar LLMs con MLflow.
La evaluación de tres casos de prueba mediante la métrica G-Eval alcanzó un porcentaje de aprobados del 66,67%, con una coincidencia perfecta, una coincidencia parcial por falta de detalles y un fallo causado por una contradicción directa. Esto pone de manifiesto los puntos fuertes del modelo en cuanto a la precisión de los hechos, pero también sus limitaciones a la hora de manejar resultados matizados o detallados.
MMLU (Massive Multitask Language Understanding) es un punto de referencia muy utilizado para evaluar grandes modelos lingüísticos mediante preguntas de opción múltiple. Abarca 57 materias diversas, como matemáticas, historia, derecho y ética, lo que la convierte en una prueba exhaustiva de los conocimientos y la capacidad de razonamiento de un LLM. Debido a su amplia cobertura temática y a la alta calidad de sus preguntas, el MMLU se ha convertido en un estándar para evaluar el rendimiento en LLM.
Daremos un paso más y evaluaremos nuestro LLM personalizado (Qwen 2.5 7B) en el conjunto de datos MMLU. El conjunto de datos contiene preguntas de entrada y resultados (A, B, C, D). Al final, utiliza la puntuación de las respuestas correctas para generar un porcentaje de precisión.
Definiremos una clase personalizada llamada QwenModel que extiende DeepEvalBaseLLM para generar respuestas utilizando el modelo de lenguaje y el tokenizador.
Nuestro objetivo es producir salidas cortas de dos fichas a partir de una indicación dada. Además, gestionaremos la asignación de dispositivos y nos encargaremos del preprocesamiento del texto de entrada y salida.
from deepeval.models.base_model import DeepEvalBaseLLM
import torch, logging
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
class QwenModel(DeepEvalBaseLLM):
def __init__(self, model, tokenizer):
self.model = model
self.tokenizer = tokenizer
self.device = "cuda"
def load_model(self):
return self.model
def generate(self, prompt: str) -> str:
prompt = prompt.replace("Output 'A', 'B', 'C', or 'D'. Full answer not needed.","")
model_inputs = self.tokenizer([prompt], return_tensors="pt").to(self.device)
generated_ids = self.model.generate(
**model_inputs,
max_new_tokens=2,
do_sample=True,
pad_token_id=self.tokenizer.eos_token_id
)
prompt_length = len(model_inputs[0])
generated_tokens = generated_ids[0][prompt_length:]
clean_output = tokenizer.decode(generated_tokens, skip_special_tokens=True).strip()
return clean_output.replace(".","")
async def a_generate(self, prompt: str) -> str:
return self.generate(prompt)
def get_model_name(self):
return "Qwen2.5 7B"Crearemos las dos funciones que cargan el modelo LLM y el tokenizador directamente desde el local. Cargamos el modelo en 8 bits e inicializamos un tokenizador para el mismo modelo, estableciendo el relleno y las configuraciones especiales de los tokens:
def load_model(model_name: str):
quant_config = BitsAndBytesConfig(
load_in_8bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=False
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=quant_config,
device_map="auto"
)
model.config.use_cache = False
model.config.pretraining_tp = 1
return model
def load_tokenizer(model_name):
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
return tokenizerAñade el modelo de instrucción Qwen 2.4 7b al cuaderno Kaggle utilizando el botón "+ Añadir entrada".
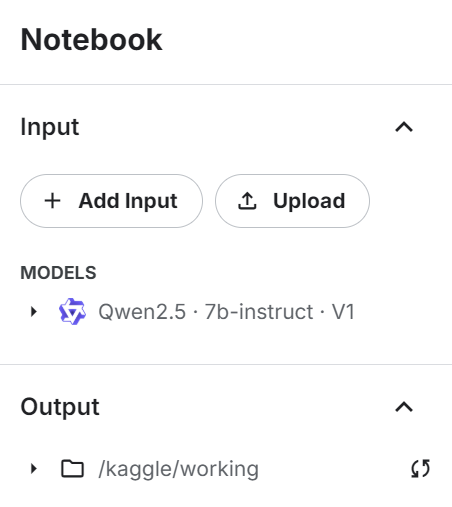
Utiliza el modelo directamente para cargar el modelo y el token, y luego proporciónalo a la clase LLM personalizada para crear un generador de respuestas LLM:
# Load model and tokenizer
qwen_model_name = "/kaggle/input/qwen2.5/transformers/7b-instruct/1"
model = load_model(qwen_model_name)
tokenizer = load_tokenizer(qwen_model_name)
custom_model = QwenModel(model, tokenizer)Prueba el LLM personalizado antes de generar los resultados de la evaluación comparativa:
# Test model generation
prompt = """
The following are multiple choice questions (with answers) about abstract algebra.
Find all c in Z_3 such that Z_3[x]/(x^2 + c) is a field.
A. 0
B. 1
C. 2
D. 3
Answer:"""
print(custom_model.generate(prompt))Proporcionamos a la LLM un ejemplo de pregunta del conjunto de datos, y respondió correctamente con una letra.
CAhora, cargaremos el banco de pruebas MMLU, definiremos las tareas y, a continuación, ejecutaremos el banco de pruebas en el modelo personalizado:
from deepeval.benchmarks import MMLU
from deepeval.benchmarks.tasks import MMLUTask
# Define benchmark with specific tasks and shots
benchmark = MMLU(
tasks=[MMLUTask.HIGH_SCHOOL_COMPUTER_SCIENCE, MMLUTask.ASTRONOMY],
n_shots=5
)
benchmark.evaluate(model=custom_model, batch_size=5)Obtuvimos excelentes resultados, ¡con un 83% de precisión!
Processing astronomy: 100%|██████████| 152/152 [01:51<00:00, 1.36it/s]
MMLU Task Accuracy (task=astronomy): 0.8157894736842105
Overall MMLU Accuracy: 0.8293650793650794Repasemos los resultados de cada tarea individual:
benchmark.task_scores
También puedes consultar los resultados completos, que muestran qué muestra obtuvo el resultado correcto y cuál falló. Esto proporciona un análisis granular del rendimiento del modelo.
benchmark.predictions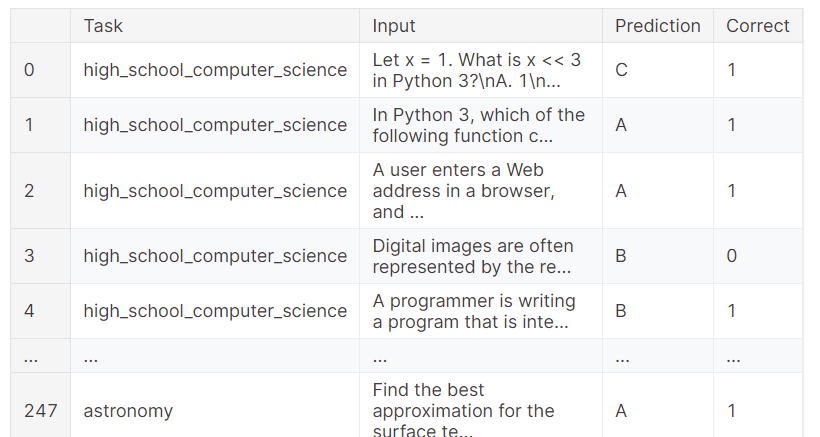
Si tienes algún problema al ejecutar el código anterior, consulta el cuaderno de Kaggle Evaluación de LLMs con DeepEval . Contiene fuentes de código, conjuntos de datos y resultados de evaluación.
Evaluar modelos lingüísticos puede ser un reto, sobre todo en un entorno de producción. A veces, las simples métricas de evaluación no son suficientes. Es esencial ejecutar un conjunto de puntos de referencia y pruebas para evaluar el rendimiento de tu LLM en diversas tareas y funciones, a fin de obtener una comprensión global e identificar áreas de mejora.
En este tutorial, configuramos DeepEval en un cuaderno Kaggle y realizamos pruebas LLM similares a Pytests. A continuación construimos G-Eval utilizando instrucciones personalizadas y lo ejecutamos en el conjunto de datos de evaluación. Por último, probamos el modelo Qwen 2.5 7B con el punto de referencia de evaluación MMLU para analizar su rendimiento en informática y astronomía de enseñanza secundaria.
El siguiente paso en tu viaje de aprendizaje es explorar las herramientas y metodologías LLMOps y aprender a desplegar un LLM fácilmente en producción. Para obtener más información, considera la posibilidad de seguir el curso Conceptos LLMOps.
¡Aprende más sobre los LLM con estos cursos!
Curso
Curso
Curso
blog
Stanislav Karzhev
9 min
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Moez Ali

