
Course
Large Language Models (LLMs) Concepts
2 hr
99.8K
For this tutorial, we will use Kaggle as our coding environment. To get started, create a new notebook.
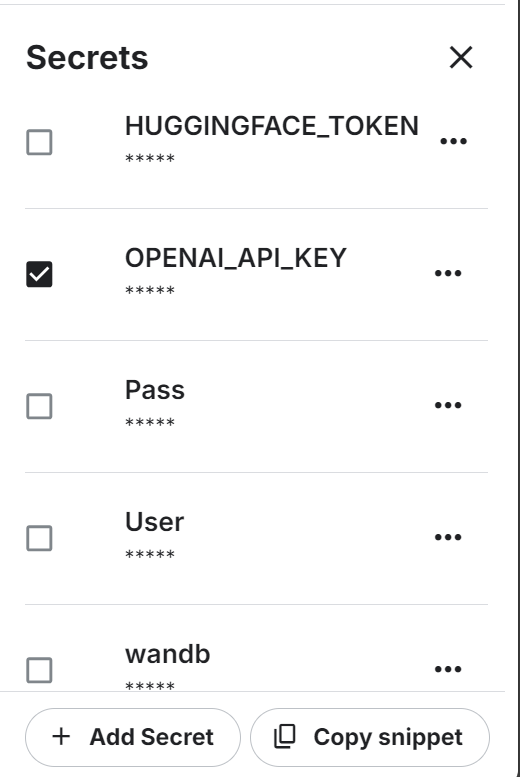
We will also use the OpenAI API. To continue, create an API key. Then, set up the environment variable for the OpenAI API key using Kaggle's "Secrets" feature.
After that, install the DeepEval and BitsandBytes Python liberty using the pip command:
%%capture
%pip install -U deepeval
%pip install -U bitsandbytesLoad the OpenAI API key from secrets:
import os
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
secret_value_0 = user_secrets.get_secret("OPENAI_API_KEY")
os.environ['OPENAI_API_KEY'] = secret_value_0Write the following Python file using the Jupyter Notebook magic function.
The test_relevancy.py file defines a test function that evaluates the relevancy of an LLM's output using the GPT-4o model. It does this by comparing the model's response to a given input against a retrieval context, ensuring that the output aligns with the provided information.
%%file test_relevancy.py
from deepeval import assert_test
from deepeval.test_case import LLMTestCase
from deepeval.metrics import AnswerRelevancyMetric
def test_relevancy():
relevancy_metric = AnswerRelevancyMetric(threshold=0.5, model="gpt-4o")
test_case_1 = LLMTestCase(
input="Can I return these shoes after 30 days?",
actual_output="Unfortunately, returns are only accepted within 30 days of purchase.",
retrieval_context=[
"All customers are eligible for a 30-day full refund at no extra cost.",
"Returns are only accepted within 30 days of purchase.",
],
)
assert_test(test_case_1, [relevancy_metric])Run the relevance test in the terminal:
!deepeval test run test_relevancy.pyThe following test result shows that the LLM test case has successfully passed the test and achived a perfect relevancy score of 1.0, indicating that the model's response was completely relevant.
The evaluation was completed in 3.04 seconds with a total estimated token cost of $0.0027425 USD:
Evaluating 1 test case(s) in parallel: |█|100% (1/1) [Time Taken: 00:03, 3.00s/
.Running teardown with pytest sessionfinish...
============================= slowest 10 durations =============================
3.03s call test_relevancy.py::test_relevancy
(2 durations < 0.005s hidden. Use -vv to show these durations.)
1 passed, 2 warnings in 3.04s
Test Results
┏━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ ┃ ┃ ┃ ┃ Overall Success ┃
┃ Test case ┃ Metric ┃ Score ┃ Status ┃ Rate ┃
┡━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ test_relevancy │ │ │ │ 100.0% │
│ │ Answer │ 1.0 │ PASSED │ │
│ │ Relevancy │ (threshold=0.... │ │ │
│ │ │ evaluation │ │ │
│ │ │ model=gpt-4o, │ │ │
│ │ │ reason=The │ │ │
│ │ │ score is 1.00 │ │ │
│ │ │ because the │ │ │
│ │ │ response was │ │ │
│ │ │ perfectly │ │ │
│ │ │ relevant and │ │ │
│ │ │ addressed the │ │ │
│ │ │ question │ │ │
│ │ │ directly │ │ │
│ │ │ without any │ │ │
│ │ │ irrelevant │ │ │
│ │ │ information. │ │ │
│ │ │ Great job!, │ │ │
│ │ │ error=None) │ │ │
└────────────────┴─────────────────┴────────────────┴────────┴─────────────────┘
Total estimated evaluation tokens cost: 0.0027425 USD
✓ Tests finished 🎉! Run 'deepeval login' to save and analyze evaluation results
on Confident AI.
‼️ Friendly reminder 😇: You can also run evaluations with ALL of deepeval's
metrics directly on Confident AI instead.You can also evaluate LLMs using the Hugging Face ecosystems by following the HumanEval: A Benchmark for Evaluating LLM Code Generation Capabilities guide.
G-Eval is an LLM evaluation framework that uses chain-of-thought (CoT) reasoning to evaluate LLM outputs based on custom criteria. As DeepEval's most adaptable metric, G-Eval can handle nearly any use case with human-like accuracy, making it an essential tool for evaluating LLM performance.
In this section, we will evaluate the dataset of LLM responses using the G-Eval metric.
We will create the G-eval metric and provide the custom instruction to test the model's repose on factual contradictions, penalize omissions, and concentrate on the main idea while tolerating vague language or differing opinions:
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCaseParams
correctness_metric = GEval(
name="Correctness",
model="gpt-4o",
evaluation_params=[
LLMTestCaseParams.EXPECTED_OUTPUT,
LLMTestCaseParams.ACTUAL_OUTPUT],
evaluation_steps=[
"Check whether the facts in 'actual output' contradicts any facts in 'expected output'",
"You should also lightly penalize omission of detail, and focus on the main idea",
"Vague language, or contradicting OPINIONS, are OK"
],
)Create three LLM test cases on different topics. Each test case has an input prompt, an actual generated output, and an expected output. The GPT-4o model will compare them and generate detailed results at the end:
from deepeval.test_case import LLMTestCase
from deepeval.dataset import EvaluationDataset
first_test_case = LLMTestCase(input="What are the main causes of deforestation?",
actual_output="The main causes of deforestation include agricultural expansion, logging, infrastructure development, and urbanization.",
expected_output="The main causes of deforestation include agricultural expansion, logging, infrastructure development, and urbanization.")
second_test_case = LLMTestCase(input="Define the term 'artificial intelligence'.",
actual_output="Artificial intelligence is the simulation of human intelligence by machines.",
expected_output="Artificial intelligence refers to the simulation of human intelligence in machines that are programmed to think and learn like humans, including tasks such as problem-solving, decision-making, and language understanding.")
third_test_case = LLMTestCase(input="List the primary colors.",
actual_output="The primary colors are green, orange, and purple.",
expected_output="The primary colors are red, blue, and yellow.")We will create the evaluation data set by combining all three test cases:
test_cases = [first_test_case, second_test_case, third_test_case]
dataset = EvaluationDataset(test_cases=test_cases)Run the G-Eval evaluation test on the dataset:
evaluation_output = dataset.evaluate([correctness_metric])Output:
The test results for each test come with a metric summary, test case, and overall metrics pass result.
Evaluating 3 test case(s) in parallel: |██████████|100% (3/3) [Time Taken: 00:02, 1.08test case/s]
======================================================================
Metrics Summary
- ✅ Correctness (GEval) (score: 1.0, threshold: 0.5, strict: False, evaluation model: gpt-4o, reason: The actual output matches the expected output exactly with no contradictions or omissions., error: None)
For test case:
- input: What are the main causes of deforestation?
- actual output: The main causes of deforestation include agricultural expansion, logging, infrastructure development, and urbanization.
- expected output: The main causes of deforestation include agricultural expansion, logging, infrastructure development, and urbanization.
- context: None
- retrieval context: None
======================================================================
Metrics Summary
- ✅ Correctness (GEval) (score: 0.7, threshold: 0.5, strict: False, evaluation model: gpt-4o, reason: The main idea of AI as the simulation of human intelligence is present, but details like problem-solving, decision-making, and language understanding are omitted., error: None)
For test case:
- input: Define the term 'artificial intelligence'.
- actual output: Artificial intelligence is the simulation of human intelligence by machines.
- expected output: Artificial intelligence refers to the simulation of human intelligence in machines that are programmed to think and learn like humans, including tasks such as problem-solving, decision-making, and language understanding.
- context: None
- retrieval context: None
======================================================================
Metrics Summary
- ❌ Correctness (GEval) (score: 0.01681606382274469, threshold: 0.5, strict: False, evaluation model: gpt-4o, reason: The actual output directly contradicts the expected output by listing green, orange, and purple as primary colors instead of red, blue, and yellow., error: None)
For test case:
- input: List the primary colors.
- actual output: The primary colors are green, orange, and purple.
- expected output: The primary colors are red, blue, and yellow.
- context: None
- retrieval context: None
======================================================================
Overall Metric Pass Rates
Correctness (GEval): 66.67% pass rate
======================================================================Learn how to evaluate LLMs with a favorite tool, MLflow, by following the Evaluating LLMs with MLflow tutorial.
The evaluation of three test cases using the G-Eval metric achieved a 66.67% pass rate, with one perfect match, one partial match due to missing details, and one failure caused by a direct contradiction. This highlights the model's strengths in factual accuracy but also its limitations in handling nuanced or detailed outputs.
MMLU (Massive Multitask Language Understanding) is a widely used benchmark for evaluating large language models through multiple-choice questions. It spans 57 diverse subjects, including math, history, law, and ethics, making it a comprehensive test of an LLM's knowledge and reasoning abilities. Due to its broad subject coverage and high-quality questions, MMLU has become a standard for assessing LLM performance.
We will take another step forward and evaluate our custom LLM (Qwen 2.5 7B) on the MMLU dataset. The dataset contains input prompts and results (A, B, C, D). In the end, it uses the correctly answered score to generate a percentage of accuracy.
We will define a custom class called QwenModel that extends DeepEvalBaseLLM to generate responses using the language model and tokenizer.
Our goal is to produce short outputs of two tokens based on a given prompt. Additionally, we will manage device allocation and handle preprocessing the input prompt and output text.
from deepeval.models.base_model import DeepEvalBaseLLM
import torch, logging
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
class QwenModel(DeepEvalBaseLLM):
def __init__(self, model, tokenizer):
self.model = model
self.tokenizer = tokenizer
self.device = "cuda"
def load_model(self):
return self.model
def generate(self, prompt: str) -> str:
prompt = prompt.replace("Output 'A', 'B', 'C', or 'D'. Full answer not needed.","")
model_inputs = self.tokenizer([prompt], return_tensors="pt").to(self.device)
generated_ids = self.model.generate(
**model_inputs,
max_new_tokens=2,
do_sample=True,
pad_token_id=self.tokenizer.eos_token_id
)
prompt_length = len(model_inputs[0])
generated_tokens = generated_ids[0][prompt_length:]
clean_output = tokenizer.decode(generated_tokens, skip_special_tokens=True).strip()
return clean_output.replace(".","")
async def a_generate(self, prompt: str) -> str:
return self.generate(prompt)
def get_model_name(self):
return "Qwen2.5 7B"We will create the two functions that load the LLM model and tokenizer directly from the local. We load the model in 8 bits and initialize a tokenizer for the same model, setting padding and special token configurations:
def load_model(model_name: str):
quant_config = BitsAndBytesConfig(
load_in_8bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=False
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=quant_config,
device_map="auto"
)
model.config.use_cache = False
model.config.pretraining_tp = 1
return model
def load_tokenizer(model_name):
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
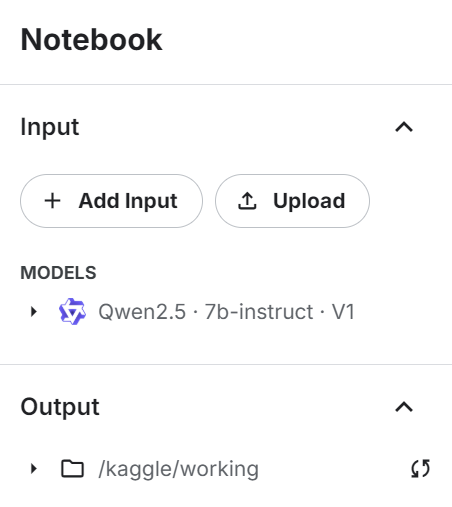
return tokenizerAdd the Qwen 2.4 7b instruct model to the Kaggle notebook using the “+ Add Input” button.
Use the model directly to load the model and token, then provide it to the custom LLM class to create an LLM response generator:
# Load model and tokenizer
qwen_model_name = "/kaggle/input/qwen2.5/transformers/7b-instruct/1"
model = load_model(qwen_model_name)
tokenizer = load_tokenizer(qwen_model_name)
custom_model = QwenModel(model, tokenizer)Test the custom LLM before generating the benchmarking results:
# Test model generation
prompt = """
The following are multiple choice questions (with answers) about abstract algebra.
Find all c in Z_3 such that Z_3[x]/(x^2 + c) is a field.
A. 0
B. 1
C. 2
D. 3
Answer:"""
print(custom_model.generate(prompt))We provided the LLM with a sample prompt from the dataset, and it responded accurately with one letter.
CNow, we will load the MMLU benchmark, define the tasks, and then run the benchmark on the custom model:
from deepeval.benchmarks import MMLU
from deepeval.benchmarks.tasks import MMLUTask
# Define benchmark with specific tasks and shots
benchmark = MMLU(
tasks=[MMLUTask.HIGH_SCHOOL_COMPUTER_SCIENCE, MMLUTask.ASTRONOMY],
n_shots=5
)
benchmark.evaluate(model=custom_model, batch_size=5)We got excellent results with 83% accuracy!
Processing astronomy: 100%|██████████| 152/152 [01:51<00:00, 1.36it/s]
MMLU Task Accuracy (task=astronomy): 0.8157894736842105
Overall MMLU Accuracy: 0.8293650793650794Let’s review the results of each individual task:
benchmark.task_scores
You can also check the full results, which show which sample got the correct result and which failed. This provides a granular analysis of the model's performance.
benchmark.predictions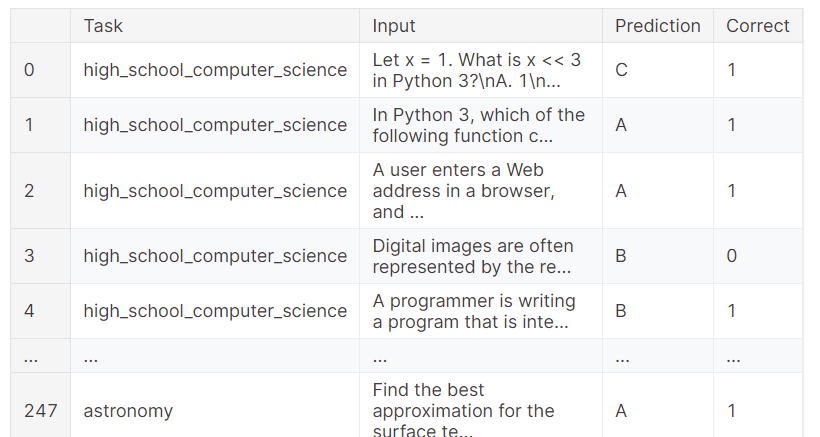
If you face any issues running the above code, please refer to the Evaluating LLMs with DeepEval Kaggle notebook. It contains code sources, datasets, and evaluation results.
Evaluating language models can be challenging, especially in a production environment. Sometimes, simple evaluation metrics are not sufficient. It is essential to run a suite of benchmarks and tests to assess the performance of your LLM across various tasks and functions to gain a comprehensive understanding and identify areas for improvement.
In this tutorial, we set up DeepEval in a Kaggle notebook and conducted LLM tests similar to Pytests. We then built G-Eval using custom instructions and ran it on the evaluation dataset. Finally, we tested the Qwen 2.5 7B model against the MMLU evaluation benchmark to analyze its performance in high school computer science and astronomy.
The next step in your learning journey is to explore LLMOps tools and methodologies and learn how to deploy an LLM easily into production. For more insights, consider taking the course LLMOps Concepts.
Learn more about LLMs with these courses!
Course
Course
Course
Tutorial
Abid Ali Awan
Tutorial
Maria Eugenia Inzaugarat
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
code-along
Josh Reini
code-along
Andrea Valenzuela

