
Kurs
Konzepte großer Sprachmodelle (LLMs)
2 Std.
99.8K
Große Sprachmodelle (Large Language Models, LLMs) sind bei der Entwicklung von Modellen für das maschinelle Lernen sehr wichtig geworden, insbesondere um die Fähigkeiten von Algorithmen zur Verarbeitung natürlicher Sprache zu verbessern. Von Chatbots bis zu Inhaltsgeneratoren - diese Modelle verändern die Art und Weise, wie wir mit Technologie interagieren.
Mit der zunehmenden Zahl und Komplexität der LLMs wird die Bewertung ihrer Leistung jedoch immer wichtiger. Ohne eine angemessene und genaue Bewertung ist es schwierig herauszufinden, ob ein Modell wie erwartet funktioniert oder angepasst werden muss.
Hier kommt MLflow ins Spiel. MLflow ist ein Open-Source-Tool, das die Verwaltung von Experimenten zum maschinellen Lernen erleichtert. Es hilft uns, die Ergebnisse der verschiedenen Experimente zu verfolgen, Modelle zu verwalten und alles zu organisieren!
In diesem Tutorium werden wir die Rolle von MLflow bei der Verbesserung von LLM-Workflows untersuchen. Ich führe dich durch die Einrichtung und zeige dir, wie du Metriken protokollieren und Parameter in LLM-Experimenten verfolgen kannst. Schließlich werden wir sehen, wie MLflow eine effektive Modellverwaltung und -bereitstellung unterstützt.
MLflow ist eine Open-Source-Plattform, die entwickelt wurde, um den gesamten Lebenszyklus des maschinellen Lernens zu verwalten. Es bietet Werkzeuge, um den Prozess der Entwicklung, Verfolgung und Bereitstellung von Machine Learning-Modellen zu optimieren.
Egal, ob wir an einem kleinen Projekt arbeiten oder komplexe Experimente mit großen Modellen verwalten, MLflow kann uns helfen, organisiert und effizient zu bleiben.
Zu den Vorteilen der Verwendung von MLflow im Lebenszyklus des maschinellen Lernens gehören:
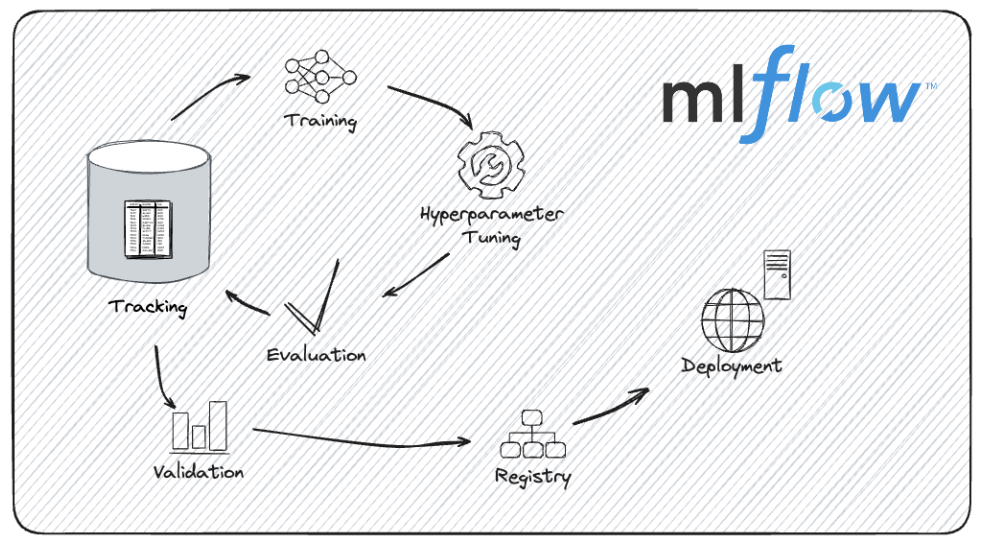
Der Lebenszyklus der Modellentwicklung mit MLflow. Bildquelle: MLflow-Dokumentation.
MLflow wurde entwickelt, um die Verwaltung von Machine-Learning-Projekten reibungsloser und transparenter zu gestalten. Das ist besonders nützlich, wenn du mit komplexen Modellen wie LLMs arbeitest, wie wir gleich sehen werden.
Die Verwendung von MLflow für die LLM-Evaluierung hat mehrere Vorteile, z. B. die Nachverfolgung von Modellversionen, die Protokollierung von Evaluierungsmetriken und den Leistungsvergleich zwischen verschiedenen Bereichen.
Sehen wir uns diese Vorteile im Detail an.
Die Entwicklung von LLMs beinhaltet häufige Iterationen und Verbesserungen. Jede neue Version bringt kleine Verbesserungen oder Verhaltensänderungen mit sich. MLflow verwaltet diese verschiedenen Iterationen, indem es die Modellversionen systematisch verfolgt. So können wir die Ergebnisse reproduzieren, verschiedene Versionen effektiv vergleichen und eine klare Historie der Modellentwicklung erhalten.
Nehmen wir an, wir experimentieren mit verschiedenen Feinabstimmungstechniken. MLflow kann uns dabei helfen, die Ergebnisse jeder Version zu verwalten und zu überprüfen, damit wir leichter feststellen können, welche Iteration die beste Leistung bringt.
Da MLflow garantiert, dass jedes Experiment und die dazugehörigen Ergebnisse vollständig protokolliert werden, können wir unsere Ergebnisse getrost weitergeben und wissen, dass andere unsere Ergebnisse genau reproduzieren können.
Wenn wir in unserem Projekt mit verschiedenen LLM-Architekturen oder Trainingsmethoden experimentieren, erleichtern die Nachverfolgungsfunktionen von MLflow die Dokumentation und den Austausch unserer Arbeit.
Bei der Bewertung von LLMs werden verschiedene Metriken überwacht, wie z. B. die Genauigkeit, die Komplexität und der F1-Score.
Die Logging-Funktion von MLflow ermöglicht es uns, diese Kennzahlen effizient und übersichtlich aufzuzeichnen. Die Analyse dieser Metriken gibt uns ein gutes Bild von der Leistung unseres Modells.
Wir möchten zum Beispiel vergleichen, wie sich verschiedene Hyperparameter oder Trainingsdatensätze auf die Leistungskennzahlen des Modells auswirken. Mit MLflow können wir diese Metriken protokollieren und visualisieren, um verwertbare Erkenntnisse zu gewinnen.
Wenn Modelle eingesetzt und in realen Anwendungen verwendet werden, kann es zu einer Modelldrift kommen, bei der sich ihre Leistung aufgrund von Änderungen der Daten oder der Umgebung verschlechtert. Wir können MLflow nutzen, um die Modelldrift zu überwachen und zu steuern, indem wir die Modellleistung im Laufe der Zeit verfolgen.
Wir können regelmäßige Auswertungen einrichten und mit MLflow protokollieren und analysieren, wie sich die Leistungskennzahlen verändern, um in Echtzeit umsetzbare Entscheidungen zu treffen.
Einer der wichtigsten Vorteile von MLflow ist seine Fähigkeit, umfassende Modellvergleiche zu vereinfachen. Indem MLflow detaillierte Aufzeichnungen verschiedener Experimente speichert, können wir die Leistung verschiedener LLMs und Hyperparameter-Konfigurationen nebeneinander vergleichen.
Bei der Entwicklung von LLMs kann die Wahl der richtigen Hyperparameter über den Erfolg eines Modells entscheiden.
Stell dir vor, dass wir ein LLM feinabstimmen und die Auswirkungen verschiedener Hyperparametereinstellungen bewerten wollen. Mit MLFlow können wir die Ergebnisse verschiedener Lernraten, Batch-Größen oder Dropout-Raten protokollieren und vergleichen, um festzustellen, welche Konfiguration die beste Leistung erbringt und unseren Modellentwicklungsprozess optimiert.
Die Modellregistrierungs- und Verfolgungsfunktionen von MLflow kommen ins Spiel, wenn mehrere LLMs für den Einsatz evaluiert werden.
Angenommen, wir haben mehrere Versionen eines Sprachmodells, das wir für eine Produktionsumgebung in Betracht ziehen. MLflow kann uns dabei helfen, die Leistungskennzahlen der einzelnen Modelle zu protokollieren, sie zu vergleichen und eine fundierte Entscheidung zu treffen, die auf empirischen Erkenntnissen und nicht nur auf Intuition beruht.
Jetzt, wo wir ein klareres Bild von MLflow und seinen Vorteilen haben, können wir selbst aktiv werden!
Lerne, wie du mit LLMs in Python direkt in deinem Browser arbeiten kannst

Bevor wir LLMs mit MLflow auswerten können, müssen wir die Plattform richtig einrichten. Dazu gehört die Installation von MLflow, die optionale Konfiguration eines Tracking-Servers für die Fernprotokollierung und die Sicherstellung, dass unsere Umgebung für die Verwaltung der Experimente und die Nachverfolgung der Ergebnisse bereit ist.
Mal sehen, wie man das macht.
1. Stelle sicher, dass Python installiert ist:
Zuerst müssen wir sicherstellen, dass wir Python auf unserem Rechner installiert haben. MLflow ist mit Python 3.6 und höher kompatibel (Python 3.8 ist inzwischen veraltet, daher wird Python >= 3.9 empfohlen). Wir können unsere Python-Version mit überprüfen:
python --version2. Erstelle eine virtuelle Umgebung (optional, aber empfohlen):
Es ist eine gute Praxis, eine virtuelle Umgebung zu verwenden, wenn wir Experimente mit MLFlow verfolgen, besonders wenn wir mit Mac OS X arbeiten. Wir können eine solche mit venv oder virtualenv erstellen.
python -m venv mlflow-envWir aktivieren die virtuelle Umgebung:
Unter Windows:
mlflow-env\Scripts\activateAuf Mac/Linux:
source mlflow-env/bin/activate3. Installiere MLflow mit pip:
Wenn die virtuelle Umgebung aktiviert ist (falls verwendet), können wir MLflow über pip installieren:
pip install mlflow4. Installiere zusätzliche Abhängigkeiten:
MLflow hat ein paar optionale Abhängigkeiten für erweiterte Funktionen. Wenn wir bestimmte Funktionen nutzen wollen, wie z.B. die Serving Model-Funktionen von MLflow, müssen wir gunicorn installieren.
pip install gunicornWenn wir Bibliotheken wie TensorFlow oder PyTorch verwenden, müssen wir möglicherweise die entsprechenden MLflow-Integrationen installieren:
pip install mlflow[extras]4. Überprüfe die Installation:
Dann müssen wir sicherstellen, dass MLflow korrekt installiert ist, indem wir seine Version überprüfen:
mlflow --versionWenn wir in einer kollaborativen Umgebung arbeiten oder wenn wir eine Fernprotokollierung durchführen müssen, sollten wireinen MLflow-Tracking-Server einrichten. Diese Funktion ermöglicht es uns, die Verfolgung und Verwaltung unserer Experimente zu zentralisieren.
1. Starte den Tracking Server:
Wir können den MLflow-Server starten, indem wir den Backend-Store und den Speicherort der Artefakte angeben.
mlflow server --backend-store-uri sqlite:///mlruns.db --default-artifact-root ./mlruns--backend-store-uri gibt an, wo die Experimentdaten gespeichert werden. Wir können jedes Datenbanksystem verwenden (PostgreSQL, MySQL, etc.).--default-artifact-root gibt das Verzeichnis an, in dem die Artefakte, z. B. die Modelldateien, gespeichert werden.2. Konfiguriere den Tracking-Server:
Wir müssen sicherstellen, dass unsere MLflow-Clients so konfiguriert sind, dass sie sich beim Tracking-Server anmelden. Wir können die Umgebungsvariable MLFLOW_TRACKING_URI so setzen, dass sie auf unseren Server zeigt.
export MLFLOW_TRACKING_URI=http://localhost:50003. Rufe die Tracking-Benutzeroberfläche auf:
Jetzt können wir einen Webbrowser öffnen undzu http://localhost:5000 navigieren, um auf die MLflow-Benutzeroberfläche zuzugreifen. Über diese Schnittstelle können wir Experimente ansehen, Ergebnisse vergleichen und deine MLflow-Projekte verwalten, wie wir später sehen werden.
Wenn MLflow eingerichtet und bereit ist, ist es an der Zeit, sich mit den Kernaufgaben des Ladens und Auswertens von LLMs zu beschäftigen. Sehen wir uns an, wie wir ein vortrainiertes LLM auswählen, es mit verschiedenen Bibliotheken laden und einen Evaluierungsdatensatz vorbereiten können, um die Leistung des Modells zu messen.
Bei der Auswahl eines vortrainierten LLMs bieten Bibliotheken wie Hugging Face Transformers viele Möglichkeiten. Wir können zum Beispiel ein vortrainiertes Modell wie GPT (für die Texterstellung) oder BERT (für die Textklassifizierung und andere Aufgaben) laden.
1. Umarmende Gesichtstransformatoren installieren
Zuerst stellen wir sicher, dass wir die Hugging Face Transformers-Bibliothek installiert haben. Dies können wir mit pip erreichen.
pip install transformers2. Lade ein vortrainiertes Modell und einen Tokenizer
Jetzt laden wir das BERT-Modell mit der Bibliothek transformers, einschließlich des Modells und des Tokenizers, die für die Textverarbeitung und die Erstellung von Vorhersagen notwendig sind.
from transformers import (
BertForSequenceClassification,
BertTokenizer
)
# Load pre-trained model and tokenizer
model_name = "textattack/bert-base-uncased-yelp-polarity"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name)Das Modell bert-base-uncased wird verwendet, wenn die Textdaten, mit denen wir arbeiten, größtenteils in Klein- und Großbuchstaben vorliegen, wir das Modell aber nicht brauchen, um zwischen Wörtern in Groß- und Kleinbuchstaben zu unterscheiden.
Um ein LLM zu bewerten, brauchen wir einen geeigneten Datensatz, der zu der Aufgabe passt, die wir bewerten wollen. Sehen wir uns an, wie man einen textbasierten Bewertungsdatensatz für die Stimmungsanalyse vorbereitet:
1. Den Datensatz laden oder erstellen und vorverarbeiten
Unsere Daten können an verschiedenen Orten gespeichert werden: auf der Festplatte unseres lokalen Rechners, in einem Github-Repository oder in The Hugging Face Hub, einer umfangreichen Sammlung von gemeinschaftlich kuratierten und beliebten Forschungsdatensätzen.
Für dieses Tutorial werden wir einen großen Filmkritik-Datensatznamens IMDBfür die Stimmungsanalyse verwenden. Wirwerden die Bibliothek datasets verwenden, um den vorgefertigten Datensatz zu laden:
Installiere die Datensatzbibliothek:
pip install datasetsLaden eines Datensatzes:
from datasets import load_dataset
# Load the dataset IMDb for sentiment analysis
dataset = load_dataset("imdb")2. Vorverarbeitung für die Stimmungsanalyse
Wir werden den zuvor geladenen BERT-Tokenizer verwenden, um den Datensatz für die Sentiment-Analyse vorzuverarbeiten.
def preprocess_function(examples):
return tokenizer(examples['text'], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(preprocess_function, batched=True)Jetzt, da unsere LLMs geladen und unser Evaluierungsdatensatz vorbereitet ist, ist es an der Zeit, die Evaluierungen durchzuführen und die Metriken zu protokollieren.
1. MLflow importieren und ein neues Experiment starten
Um Experimente mit MLflow zu verfolgen, müssen wir zunächst ein neues Experiment starten und relevante Metadaten wie den Modellnamen, die Version und die Auswertungsparameter protokollieren.
import mlflow
import mlflow.pytorch
# Start a new experiment
mlflow.set_experiment("LLM_Evaluation")
with mlflow.start_run() as run:
# Log experiment metadata
mlflow.log_param("model_name", "bert")
mlflow.log_param("model_version", "v1.0")
mlflow.log_param("evaluation_task", "sentiment_analysis")2. Parameter für die Log-Auswertung
Wir können nun alle Parameter im Zusammenhang mit dem Evaluierungsprozess protokollieren, z. B. die Größe des Evaluierungsdatensatzes oder bestimmte Konfigurationen, die während der Evaluierung verwendet wurden.
with mlflow.start_run() as run:
mlflow.log_param("dataset_size", len(dataset['test']))Sobald wir unser Modell trainiert und die entsprechenden Vorhersagen gemacht haben, können wir das LLM bewerten und verschiedene Metriken protokollieren, die seine Leistung widerspiegeln.
Da es sich bei der Sentimentanalyse um ein Klassifizierungsproblem handelt, können wir unser Modell anhand von Metriken wie Genauigkeit und F1-Score bewerten. Für die Texterstellung werden häufig Metriken wie BLEU-Score oder Perplexität verwendet.
from sklearn.metrics import accuracy_score, f1_score
# Assuming y_true and y_pred are true labels and model predictions
accuracy = accuracy_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred, average='weighted')
with mlflow.start_run() as run:
mlflow.log_metric("accuracy", accuracy)
mlflow.log_metric("f1_score", f1)Wenn mehrere Auswertungsläufe mit MLflow verfolgt werden, ist der Vergleich ihrer Leistung wichtig, um die besten Modelle und Konfigurationen zu ermitteln.
Wir wollen verstehen, wie du mehrere Läufe verfolgen und die Benutzeroberfläche von MLflow nutzen kannst, um die Ergebnisse effektiv zu visualisieren und zu vergleichen.
Erstens müssen wir mehrere Läufe innerhalb desselben Experiments oder über verschiedene Experimente hinweg verfolgen, um die Leistung verschiedener LLM-Versionen zu vergleichen.
1. Mehrere Läufe protokollieren
Wir können mehrere Läufe unter einem einzigen Experiment protokollieren, indem wir für jedes Modell oder jede Konfiguration, die wir bewerten wollen, neue Läufe starten.
models = [("bert-base-cased", "v1.0"), ("bert-base-uncased", "v1.0")]
y_pred_dict = {
"bert-base-cased": y_pred_case,
"bert-base-uncased": y_pred_uncase
}
for model_name, model_version in models:
with mlflow.start_run() as run:
# Log model and version
mlflow.log_param("model_name", model_name)
mlflow.log_param("model_version", model_version)
# Perform evaluation and log metrics
y_pred = y_pred_dict[model_name]
accuracy = accuracy_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred, average='weighted')
mlflow.log_metric("accuracy", accuracy)
mlflow.log_metric("f1_score", f1)2. Versuche mit verschiedenen Modellen verfolgen
Stellen wir uns vor, wir wollen verschiedene Arten von Modellen bewerten. Zu diesem Zweck können wir mit MLFlow ein Experiment erstellen und die Modelle zusammen protokollieren.
Die Modellprotokollierung in MLFlow ist dasselbe wie die Versionskontrolle für Machine Learning-Modelle. Die Aufzeichnung von Modell- und Umgebungsdetails garantiert Reproduzierbarkeit.
Zuerst werden wir ein Experiment durchführen. Dann protokollieren wir jedes Modell in einem separaten MLFlow-Lauf, einschließlich der Lauf-IDs und Artefaktpfade.
# Create an experiments for the different models
mlflow.set_experiment("sentiment_analysis_comparison")
model_names = ["bert-base-cased", "bert-base-uncased"]
run_ids = []
artifact_paths = []
for model, name in zip([betcased, bertuncased], model_names):
with mlflow.start_run(run_name=f"log_model_{name}"):
artifact_path = f"models/{name}"
mlflow.pyfunc.log_model(
artifact_path=artifact_path,
python_model=model,
)
run_ids.append(mlflow.active_run().info.run_id)
artifact_paths.append(artifact_path)Jetzt können wir die Modelle auswerten und die Ergebnisse protokollieren. MLflow bietet eine API, mlflow.evaluate(), die bei der Auswertung unserer LLMs hilft.
for i in len(model_names):
with mlflow.start_run(run_id=run_ids[i]):
# reopen the run with the stored run ID
evaluation_results = mlflow.evaluate(
model=f"runs:/{run_ids[i]}/{artifact_paths[i]}",
model_type="text",
data=dataset['test'],
)Nachdem wir die verschiedenen Metriken und Modelle in MLFlow erfasst haben, können wir einen Vergleich anstellen. Mit der benutzerfreundlichen MLflow-Oberfläche können wir die Bewertungsmetriken verschiedener Läufe visualisieren und vergleichen. Dazu müssen wir den MLflow-Server starten, falls er noch nicht läuft
mlflow server --backend-store-uri sqlite:///mlruns.db --default-artifact-root ./mlrunsDann öffnen wir einen Webbrowser und navigieren zu http://localhost:5000, um überauf die MLflow-Benutzeroberfläche zuzugreifen. In der MLflow-Benutzeroberfläche gehen wir auf die Seite "Experimente", um alle unsere Experimente anzusehen. Wir klicken auf den Namen des Experiments, um eine Liste der dazugehörigen Läufe zu sehen.
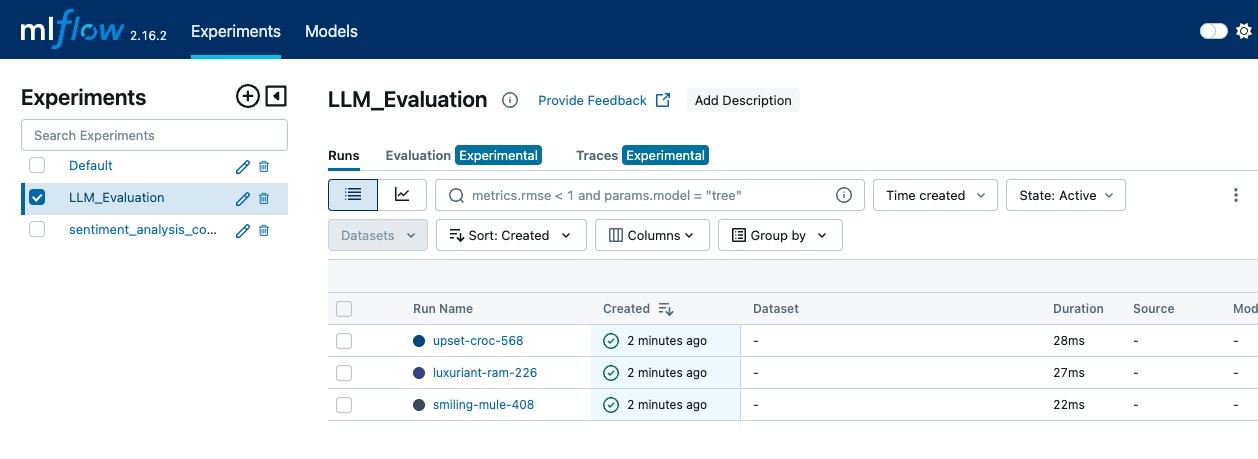
Die MLFLow-Benutzeroberfläche zeigt die Registerkarte Experimente, auf der die verschiedenen Läufe und Log-Ereignisse zu sehen sind - Bild nach Autor.
Innerhalb eines Experiments kannst du verschiedene Läufe vergleichen, indem du mehrere Läufe auswählst und ihre Metriken nebeneinander anschaust.
Die Benutzeroberfläche ermöglicht uns eine visuelle Darstellung von Kennzahlen wie Genauigkeit, F1-Score und anderen Bewertungskennzahlen. Wir können auch die in MLflow integrierten Visualisierungen nutzen, um Diagramme und Grafiken für detailliertere Vergleiche zu erstellen.
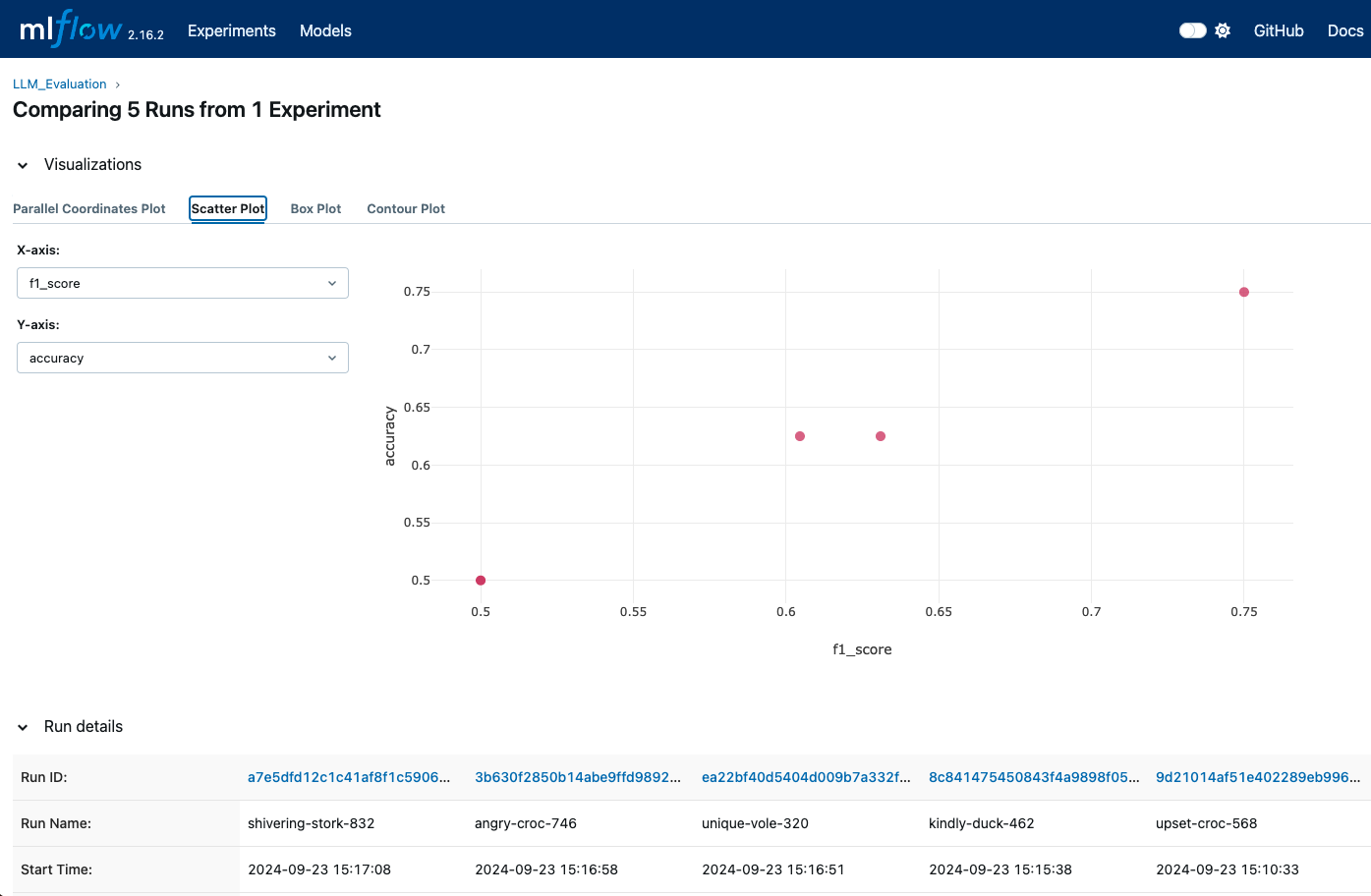
MLFlow-Visualisierungen können uns zeigen, wann verschiedene Läufe protokolliert werden, so dass wir verschiedene Metriken vergleichen können - Bild für Bild für Autor.
Die MLflow-Benutzeroberfläche bietet detaillierte Diagramme und Protokolle für jeden Lauf. Wir können auf diese Protokolle und Visualisierungen zugreifen, um zu verstehen, welches Modell oder welche Konfiguration anhand der protokollierten Metriken am besten abschneidet.
Für eine tiefergehende und umfassendere Bewertung von LLMs bietet MLflow fortschrittliche Techniken, die das Tracking und die Analyse verbessern. Wir werden uns ansehen, wie man Modellartefakte protokolliert, um sie genau zu verfolgen, und nutzen MLflow zur Abstimmung der Hyperparameter, um die LLM-Leistung zu optimieren.
Die Protokollierung von Modellartefakten ist sehr wichtig, um die Details unserer Experimente zu erhalten und zu analysieren. Artefakte können ein vollständiges Bild unserer Modellleistung vermitteln und helfen, Ergebnisse zu reproduzieren.
Unter den Artefakten, die wir protokollieren können, finden wir:
joblib für scikit-learn oder das TensorFlow SavedModel Format).Hier ist ein Beispiel:
import matplotlib.pyplot as plt
from sklearn.metrics import ConfusionMatrixDisplay
with mlflow.start_run() as run:
# Log the model
mlflow.pytorch.save_model(model, "model")
# Log the model weights
joblib.dump(model, "model_weights.pkl")
mlflow.log_artifact("model", artifact_path="model")
# Log the confusion matrix as image
confusion_matrix = pd.DataFrame(confusion_matrix(y_test, predictions))
cm = ConfusionMatrixDisplay(confusion_matrix=cm)
plt.savefig("confusion_matrix.png")
mlflow.log_artifact("confusion_matrix.png")
# Generate predictions
outputs = dataset['test']
outputs['prediction'] = model.predict(dataset['test'])
with open("generated_outputs.txt", "w") as f:
for output in outputs:
f.write(output + "\n")
# Log the file
mlflow.log_artifact("generated_outputs.txt")Die Abstimmung der Hyperparameter ist ein wichtiger Bestandteil der Optimierung der LLM-Leistung. In unseren Experimenten können wir mit MLflow verschiedene Hyperparameterkonfigurationen protokollieren. So können wir die Auswirkungen der verschiedenen Einstellungen vergleichen und die optimale Konfiguration finden.
from transformers import Trainer, TrainingArguments
def train_and_log_model(model, lr, bs):
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
learning_rate=learning_rate,
evaluation_strategy="epoch")
trainer = Trainer(model=model,
args=training_args,
train_dataset=(X_train, y_train)
eval_dataset=(X_test, y_test))
with mlflow.start_run() as run:
# Log hyperparameters
mlflow.log_param("learning_rate", lr)
mlflow.log_param("batch_size", bs)
trainer.train()
eval_result = trainer.evaluate()
mlflow.log_metric("eval_accuracy",
eval_result['eval_accuracy'])
hyperparameter_grid = [{"learning_rate": 5e-5, "batch_size": 8},
{"learning_rate": 3e-5, "batch_size": 16}]
for params in hyperparameter_grid:
train_and_log_model(params["learning_rate"],
params["batch_size"])Ein weiterer Vorteil von MLflow ist, dass es mit Hyperparameter-Optimierungsbibliotheken wie Optuna oder Ray Tune verwendet werden kann, um den Abstimmungsprozess zu automatisieren.
Zu einer genauen Bewertung von LLMs gehört mehr als nur die Durchführung von Tests und die Aufzeichnung von Metriken. Es erfordert einen strategischen Ansatz, um Konsistenz, Genauigkeit und Effizienz zu gewährleisten. Die Übernahme von Best Practices kann die Zuverlässigkeit und Wirksamkeit des Bewertungsprozesses erhöhen.
Die Verwendung stabiler und repräsentativer Datensätze ist einer der ersten Punkte, die zu einer effektiven Bewertung beitragen. Indem wir sicherstellen, dass unsere Evaluierungsdatensätze stabil und repräsentativ für die Aufgaben sind, die unser LLM erfüllen soll, erhalten wir aussagekräftige Vergleiche im Laufe der Zeit und zwischen verschiedenen Modellen oder Versionen. Wenn sich der Datensatz ändert, kann es schwierig sein, die Leistungsänderungen dem Modell zuzuschreiben und nicht dem Datensatz selbst.
Nicht nur der Datensatz, sondern auch die Art und Weise, wie wirihnvorverarbeiten ist wichtig. Wir müssen für alle Auswertungsdatensätze die gleichen Vorverarbeitungsschritte durchführen, um vergleichbare Ergebnisse zu gewährleisten. Dazu gehören Tokenisierung, Normalisierung und die Behandlung von Sonderfällen. Eine einheitliche Vorverarbeitung stellt sicher, dass Unterschiede in der Modellleistung nicht auf eine unterschiedliche Behandlung der Daten zurückzuführen sind.
Wie wir oben gesehen haben, hilft uns die Modellregistrierung von MLflow dabei, verschiedeneVersionen unserer LLMs zu verfolgen. Das erleichtert es, die Leistung der Modelle zu vergleichen und bei Bedarf auf frühere Versionen zurückzugreifen. Wir sollten alle Details protokollieren und die an den Modellen vorgenommenen Änderungen nachverfolgen, einschließlich Änderungen an der Architektur, den Hyperparametern oder den Trainingsdaten.
Schließlich kann die Automatisierung des Bewertungsprozesses durch die Integration in kontinuierliche Integrations- und Bereitstellungspipelines (CI/CD) dazu beitragen, dass die Modelle bei jeder Aktualisierung konsistent und zeitnah bewertet werden. Wir sollten regelmäßige Evaluierungen einrichten, um die Leistung des Modells regelmäßig zu bewerten. So können wir die Modelldrift überwachen und sicherstellen, dass die Modelle im Laufe der Zeit die Leistungsstandards erfüllen.
Die effektive Bewertung von LLMs erfordert einen strukturierten und systematischen Ansatz, und MLflow bietet einen Rahmen, der diesen Prozess unterstützt.
In diesem Lernprogramm haben wir MLflow installiert und einen Tracking-Server eingerichtet. Dann haben wir unser LLM evaluiert, indem wir wichtige Metriken protokolliert haben, mehrere Läufe verfolgt haben, um sie zu vergleichen, und die Benutzeroberfläche von MLflow genutzt haben, um diese Vergleiche effektiv zu visualisieren und zu analysieren.
Wenn du deine MLflow-Kenntnisse auf die nächste Stufe heben willst, schau dir unseren Kurs Einführung in MLflow an!
Erfahre mehr über LLMs mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
