
Cours
Concepts des grands modèles de langage (LLM)
2 h
100.3K
Pour ce tutoriel, nous utiliserons Kaggle comme environnement de codage. Pour commencer, créez un nouveau carnet.
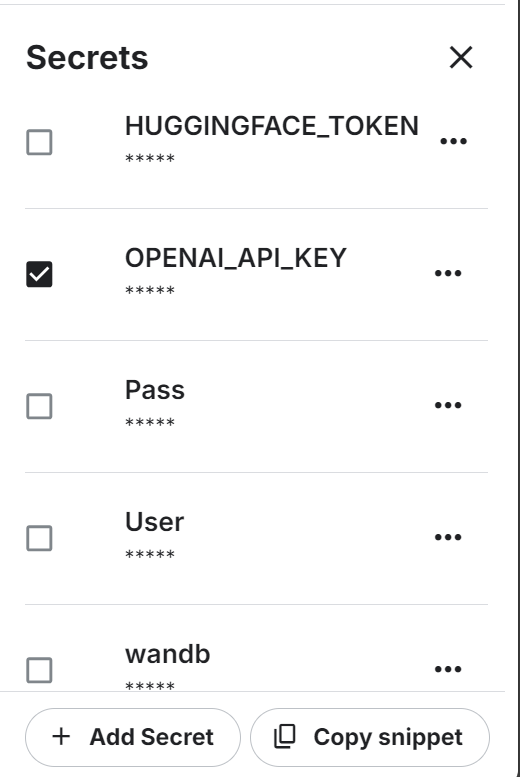
Nous utiliserons également l'API OpenAI. Pour continuer, créez une clé API. Ensuite, configurez la variable d'environnement pour la clé API OpenAI à l'aide de la fonction "Secrets" de Kaggle.
Ensuite, installez les libertés DeepEval et BitsandBytes Python à l'aide de la commande pip:
%%capture
%pip install -U deepeval
%pip install -U bitsandbytesChargez la clé API OpenAI à partir de secrets :
import os
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
secret_value_0 = user_secrets.get_secret("OPENAI_API_KEY")
os.environ['OPENAI_API_KEY'] = secret_value_0Écrivez le fichier Python suivant en utilisant la fonction magique du carnet de notes Jupyter.
Le fichier test_relevancy.py définit une fonction de test qui évalue la pertinence de la sortie d'un LLM à l'aide du modèle GPT-4o. Pour ce faire, il compare la réponse du modèle à une entrée donnée par rapport à un contexte de recherche, en veillant à ce que la sortie corresponde à l'information fournie.
%%file test_relevancy.py
from deepeval import assert_test
from deepeval.test_case import LLMTestCase
from deepeval.metrics import AnswerRelevancyMetric
def test_relevancy():
relevancy_metric = AnswerRelevancyMetric(threshold=0.5, model="gpt-4o")
test_case_1 = LLMTestCase(
input="Can I return these shoes after 30 days?",
actual_output="Unfortunately, returns are only accepted within 30 days of purchase.",
retrieval_context=[
"All customers are eligible for a 30-day full refund at no extra cost.",
"Returns are only accepted within 30 days of purchase.",
],
)
assert_test(test_case_1, [relevancy_metric])Exécutez le test de pertinence dans le terminal :
!deepeval test run test_relevancy.pyLe résultat du test suivant montre que le scénario de test LLM a passé le test avec succès et a obtenu un score de pertinence parfait de 1,0, ce qui indique que la réponse du modèle était tout à fait pertinente.
L'évaluation a été réalisée en 3,04 secondes pour un coût total estimé à 0,0027425 USD :
Evaluating 1 test case(s) in parallel: |█|100% (1/1) [Time Taken: 00:03, 3.00s/
.Running teardown with pytest sessionfinish...
============================= slowest 10 durations =============================
3.03s call test_relevancy.py::test_relevancy
(2 durations < 0.005s hidden. Use -vv to show these durations.)
1 passed, 2 warnings in 3.04s
Test Results
┏━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ ┃ ┃ ┃ ┃ Overall Success ┃
┃ Test case ┃ Metric ┃ Score ┃ Status ┃ Rate ┃
┡━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ test_relevancy │ │ │ │ 100.0% │
│ │ Answer │ 1.0 │ PASSED │ │
│ │ Relevancy │ (threshold=0.... │ │ │
│ │ │ evaluation │ │ │
│ │ │ model=gpt-4o, │ │ │
│ │ │ reason=The │ │ │
│ │ │ score is 1.00 │ │ │
│ │ │ because the │ │ │
│ │ │ response was │ │ │
│ │ │ perfectly │ │ │
│ │ │ relevant and │ │ │
│ │ │ addressed the │ │ │
│ │ │ question │ │ │
│ │ │ directly │ │ │
│ │ │ without any │ │ │
│ │ │ irrelevant │ │ │
│ │ │ information. │ │ │
│ │ │ Great job!, │ │ │
│ │ │ error=None) │ │ │
└────────────────┴─────────────────┴────────────────┴────────┴─────────────────┘
Total estimated evaluation tokens cost: 0.0027425 USD
✓ Tests finished 🎉! Run 'deepeval login' to save and analyze evaluation results
on Confident AI.
‼️ Friendly reminder 😇: You can also run evaluations with ALL of deepeval's
metrics directly on Confident AI instead.Vous pouvez également évaluer les MFR à l'aide des écosystèmes de Hugging Face en suivant le site HumanEval : Une référence pour évaluer les capacités de génération de code LLM guide.
G-Eval est un cadre d'évaluation du LLM qui utilise le raisonnement par chaîne de pensée (CoT) pour évaluer les résultats du LLM sur la base de critères personnalisés. En tant que mesure la plus adaptable de DeepEval, G-Eval peut traiter presque tous les cas d'utilisation avec une précision comparable à celle d'un humain, ce qui en fait un outil essentiel pour évaluer la performance des LLM.
Dans cette section, nous évaluerons l'ensemble de données des réponses LLM à l'aide de la métrique G-Eval.
Nous créerons la métrique G-eval et fournirons les instructions personnalisées pour tester le modèle sur les contradictions factuelles, pénaliser les omissions et se concentrer sur l'idée principale tout en tolérant les formulations vagues ou les opinions divergentes :
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCaseParams
correctness_metric = GEval(
name="Correctness",
model="gpt-4o",
evaluation_params=[
LLMTestCaseParams.EXPECTED_OUTPUT,
LLMTestCaseParams.ACTUAL_OUTPUT],
evaluation_steps=[
"Check whether the facts in 'actual output' contradicts any facts in 'expected output'",
"You should also lightly penalize omission of detail, and focus on the main idea",
"Vague language, or contradicting OPINIONS, are OK"
],
)Créez trois cas de test LLM sur des sujets différents. Chaque scénario de test comporte une invite d'entrée, une sortie réelle générée et une sortie attendue. Le modèle GPT-4o les compare et génère des résultats détaillés à la fin :
from deepeval.test_case import LLMTestCase
from deepeval.dataset import EvaluationDataset
first_test_case = LLMTestCase(input="What are the main causes of deforestation?",
actual_output="The main causes of deforestation include agricultural expansion, logging, infrastructure development, and urbanization.",
expected_output="The main causes of deforestation include agricultural expansion, logging, infrastructure development, and urbanization.")
second_test_case = LLMTestCase(input="Define the term 'artificial intelligence'.",
actual_output="Artificial intelligence is the simulation of human intelligence by machines.",
expected_output="Artificial intelligence refers to the simulation of human intelligence in machines that are programmed to think and learn like humans, including tasks such as problem-solving, decision-making, and language understanding.")
third_test_case = LLMTestCase(input="List the primary colors.",
actual_output="The primary colors are green, orange, and purple.",
expected_output="The primary colors are red, blue, and yellow.")Nous créerons l'ensemble de données d'évaluation en combinant les trois cas de test :
test_cases = [first_test_case, second_test_case, third_test_case]
dataset = EvaluationDataset(test_cases=test_cases)Exécutez le test d'évaluation G-Eval sur l'ensemble de données :
evaluation_output = dataset.evaluate([correctness_metric])Sortie :
Les résultats de chaque test sont accompagnés d'un résumé des mesures, du cas de test et du résultat global de la réussite des mesures.
Evaluating 3 test case(s) in parallel: |██████████|100% (3/3) [Time Taken: 00:02, 1.08test case/s]
======================================================================
Metrics Summary
- ✅ Correctness (GEval) (score: 1.0, threshold: 0.5, strict: False, evaluation model: gpt-4o, reason: The actual output matches the expected output exactly with no contradictions or omissions., error: None)
For test case:
- input: What are the main causes of deforestation?
- actual output: The main causes of deforestation include agricultural expansion, logging, infrastructure development, and urbanization.
- expected output: The main causes of deforestation include agricultural expansion, logging, infrastructure development, and urbanization.
- context: None
- retrieval context: None
======================================================================
Metrics Summary
- ✅ Correctness (GEval) (score: 0.7, threshold: 0.5, strict: False, evaluation model: gpt-4o, reason: The main idea of AI as the simulation of human intelligence is present, but details like problem-solving, decision-making, and language understanding are omitted., error: None)
For test case:
- input: Define the term 'artificial intelligence'.
- actual output: Artificial intelligence is the simulation of human intelligence by machines.
- expected output: Artificial intelligence refers to the simulation of human intelligence in machines that are programmed to think and learn like humans, including tasks such as problem-solving, decision-making, and language understanding.
- context: None
- retrieval context: None
======================================================================
Metrics Summary
- ❌ Correctness (GEval) (score: 0.01681606382274469, threshold: 0.5, strict: False, evaluation model: gpt-4o, reason: The actual output directly contradicts the expected output by listing green, orange, and purple as primary colors instead of red, blue, and yellow., error: None)
For test case:
- input: List the primary colors.
- actual output: The primary colors are green, orange, and purple.
- expected output: The primary colors are red, blue, and yellow.
- context: None
- retrieval context: None
======================================================================
Overall Metric Pass Rates
Correctness (GEval): 66.67% pass rate
======================================================================Apprenez à évaluer les LLM avec votre outil favori, MLflow, en suivant le tutoriel Evaluating LLMs with MLflow.
L'évaluation de trois cas de test à l'aide de la métrique G-Eval a permis d'obtenir un taux de réussite de 66,67 %, avec une correspondance parfaite, une correspondance partielle due à des détails manquants et un échec causé par une contradiction directe. Cela met en évidence les points forts du modèle en matière d'exactitude factuelle, mais aussi ses limites en ce qui concerne le traitement des résultats nuancés ou détaillés.
MMLU (Massive Multitask Language Understanding) est un test de référence largement utilisé pour évaluer de grands modèles linguistiques à l'aide de questions à choix multiples. Il couvre 57 sujets différents, dont les mathématiques, l'histoire, le droit et l'éthique, ce qui en fait un test complet des connaissances et des capacités de raisonnement d'un LLM. Grâce à sa large couverture des sujets et à la qualité de ses questions, le MMLU est devenu une référence pour l'évaluation des performances en matière de LLM.
Nous ferons un autre pas en avant et évaluerons notre LLM personnalisé (Qwen 2.5 7B) sur l'ensemble de données MMLU. L'ensemble de données contient des invites de saisie et des résultats (A, B, C, D). Enfin, il utilise le score des réponses correctes pour générer un pourcentage d'exactitude.
Nous définirons une classe personnalisée appelée QwenModel qui étend DeepEvalBaseLLM pour générer des réponses à l'aide du modèle linguistique et du tokenizer.
Notre objectif est de produire de courtes sorties de deux jetons sur la base d'une invite donnée. En outre, nous gérerons l'attribution des appareils et nous nous occuperons du prétraitement de l'invite d'entrée et du texte de sortie.
from deepeval.models.base_model import DeepEvalBaseLLM
import torch, logging
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
class QwenModel(DeepEvalBaseLLM):
def __init__(self, model, tokenizer):
self.model = model
self.tokenizer = tokenizer
self.device = "cuda"
def load_model(self):
return self.model
def generate(self, prompt: str) -> str:
prompt = prompt.replace("Output 'A', 'B', 'C', or 'D'. Full answer not needed.","")
model_inputs = self.tokenizer([prompt], return_tensors="pt").to(self.device)
generated_ids = self.model.generate(
**model_inputs,
max_new_tokens=2,
do_sample=True,
pad_token_id=self.tokenizer.eos_token_id
)
prompt_length = len(model_inputs[0])
generated_tokens = generated_ids[0][prompt_length:]
clean_output = tokenizer.decode(generated_tokens, skip_special_tokens=True).strip()
return clean_output.replace(".","")
async def a_generate(self, prompt: str) -> str:
return self.generate(prompt)
def get_model_name(self):
return "Qwen2.5 7B"Nous allons créer les deux fonctions qui chargent le modèle LLM et le tokenizer directement à partir du local. Nous chargeons le modèle en 8 bits et initialisons un tokenizer pour le même modèle, en définissant des configurations de padding et de token spéciales :
def load_model(model_name: str):
quant_config = BitsAndBytesConfig(
load_in_8bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=False
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=quant_config,
device_map="auto"
)
model.config.use_cache = False
model.config.pretraining_tp = 1
return model
def load_tokenizer(model_name):
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
return tokenizerAjoutez le modèle d'instruction Qwen 2.4 7b au carnet Kaggle en utilisant le bouton "+ Add Input".
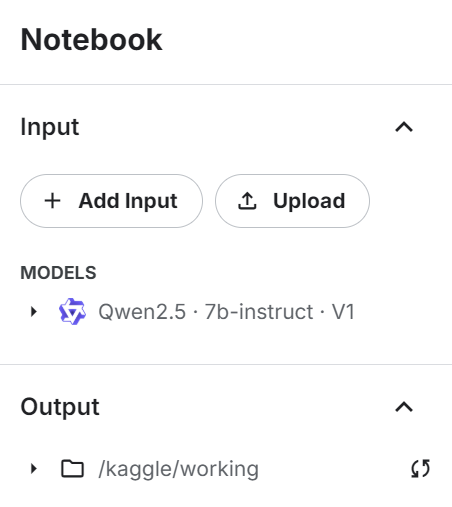
Utilisez le modèle directement pour charger le modèle et le jeton, puis fournissez-les à la classe LLM personnalisée pour créer un générateur de réponse LLM :
# Load model and tokenizer
qwen_model_name = "/kaggle/input/qwen2.5/transformers/7b-instruct/1"
model = load_model(qwen_model_name)
tokenizer = load_tokenizer(qwen_model_name)
custom_model = QwenModel(model, tokenizer)Testez le LLM personnalisé avant de générer les résultats de l'analyse comparative :
# Test model generation
prompt = """
The following are multiple choice questions (with answers) about abstract algebra.
Find all c in Z_3 such that Z_3[x]/(x^2 + c) is a field.
A. 0
B. 1
C. 2
D. 3
Answer:"""
print(custom_model.generate(prompt))Nous avons fourni au LLM un exemple d'invite provenant de l'ensemble de données, et il a répondu avec précision par une lettre.
CNous allons maintenant charger le benchmark MMLU, définir les tâches, puis exécuter le benchmark sur le modèle personnalisé :
from deepeval.benchmarks import MMLU
from deepeval.benchmarks.tasks import MMLUTask
# Define benchmark with specific tasks and shots
benchmark = MMLU(
tasks=[MMLUTask.HIGH_SCHOOL_COMPUTER_SCIENCE, MMLUTask.ASTRONOMY],
n_shots=5
)
benchmark.evaluate(model=custom_model, batch_size=5)Nous avons obtenu d'excellents résultats avec une précision de 83% !
Processing astronomy: 100%|██████████| 152/152 [01:51<00:00, 1.36it/s]
MMLU Task Accuracy (task=astronomy): 0.8157894736842105
Overall MMLU Accuracy: 0.8293650793650794Examinons les résultats de chaque tâche individuelle :
benchmark.task_scores
Vous pouvez également consulter les résultats complets, qui indiquent les échantillons qui ont obtenu le bon résultat et ceux qui ont échoué. Cela permet une analyse granulaire de la performance du modèle.
benchmark.predictions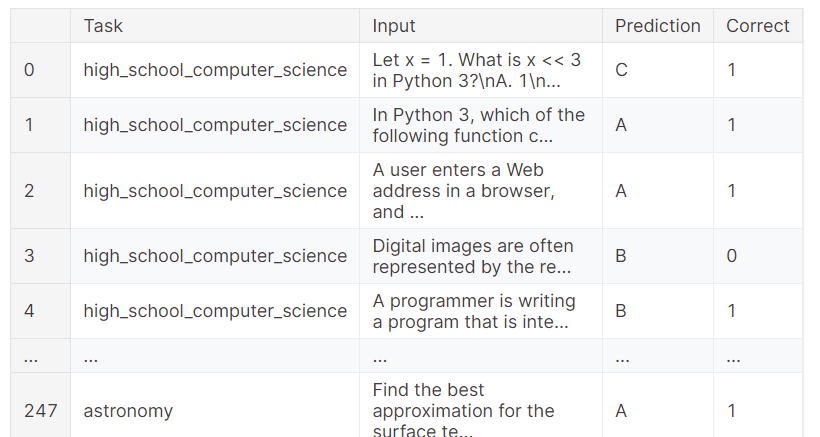
Si vous rencontrez des problèmes lors de l'exécution du code ci-dessus, veuillezvous référer au carnet Kaggle Evaluating LLMs with DeepEval . Il contient des sources de code, des ensembles de données et des résultats d'évaluation.
L'évaluation des modèles linguistiques peut s'avérer difficile, en particulier dans un environnement de production. Parfois, de simples mesures d'évaluation ne suffisent pas. Il est essentiel d'effectuer une série d'analyses comparatives et de tests pour évaluer les performances de votre LLM dans différentes tâches et fonctions afin d'obtenir une compréhension globale et d'identifier les domaines à améliorer.
Dans ce tutoriel, nous avons configuré DeepEval dans un carnet Kaggle et effectué des tests LLM similaires à Pytests. Nous avons ensuite construit G-Eval à l'aide d'instructions personnalisées et l'avons exécuté sur l'ensemble de données d'évaluation. Enfin, nous avons testé le modèle Qwen 2.5 7B par rapport au benchmark d'évaluation MMLU afin d'analyser ses performances dans les domaines de l'informatique et de l'astronomie au lycée.
L'étape suivante de votre apprentissage consiste à explorer les outils et les méthodologies LLMOps et à apprendre comment déployer facilement un LLM en production. Pour en savoir plus, vous pouvez suivre le cours LLMOps Concepts.
Apprenez-en plus sur les LLM grâce à ces cours !
Cours
Cours
Cours