

Lernpfad
MLOps-Grundlagen
14 Std.
Da generative KI die Softwareentwicklung immer weiter verändert, ist mir eine ständige Herausforderung aufgefallen: KI-Modelle lokal zu betreiben, ist immer noch komplizierter, als es sein sollte.
Entwickler haben mit uneinheitlichen Tools, Problemen mit der Hardwarekompatibilität und Arbeitsabläufen zu kämpfen, die sich von ihrer normalen Entwicklungsumgebung total unterscheiden. Docker Model Runner kam im April 2025 raus, um diese Probleme zu lösen. Damit ist es einfacher, KI-Modelle lokal in bestehenden Docker-Workflows zu nutzen und zu testen.
Docker Model Runner ist der Wechsel von Cloud-basierter KI zu lokalen, containerisierten Workflows. Das bringt Vorteile wie Datenschutz, geringere Kosten und schnellere Iterationen, und das alles in Verbindung mit dem Docker-Ökosystem. Aus meiner Erfahrung mit KI-Implementierungen sind diese Vorteile echt wichtig für Teams, die produktionsreife Anwendungen entwickeln und dabei die Kontrolle über sensible Daten behalten wollen.
Wenn du noch keine Erfahrung mit Docker hast, empfehle ich dir, diesen Einführungskurs zu Docker zu machen.
Das traditionelle AI-Modell bringt ein paar Probleme mit sich, die ich selbst erlebt habe.
KI-Modelle haben mathematische Gewichte, die im Gegensatz zu normalen Docker-Images nicht von Komprimierung profitieren. Das führt zu Speicherineffizienzen, wenn Modelle zusammen mit ihrer Laufzeitumgebung gepackt werden. Außerdem macht das Einrichten von Inferenz-Engines, das Verwalten von Hardwarebeschleunigung und das Pflegen separater Tools für Modelle und Anwendungscontainer alles unnötig kompliziert.
Genau hier kommt Docker Model Runner ins Spiel. Anstatt noch ein weiteres Tool zu deinem Stack hinzuzufügen, kannst du große Sprachmodelle (LLMs) einfach direkt aus dem Docker Hub in einem OCI-konformen (Open Container Initiative) Format () oder aus Hugging Face herunterladen, ausführen und verteilen, wenn die Modelle im GPT-Generated Unified Format verfügbar sind.im GPT-Generated Unified Format (GGUF) verfügbar sind. Die Plattform löst das Problem der Fragmentierung, indem sie die Modellverwaltung in denselben Workflow integriert, den Entwickler für Container nutzen.
Der historische Hintergrund ist hier echt wichtig. Mit der zunehmenden Verbreitung generativer KI hat sich in der Branche ein Trend zu sicheren, lokal ausgerichteten KI-Workflows entwickelt. Unternehmen machen sich immer mehr Sorgen um Datenschutz, API-Kosten und die Bindung an bestimmte Anbieter, die mit Cloud-basierten KI-Diensten einhergehen.
Docker hat sich mit ein paar großen Namen aus der KI- und Softwareentwicklung zusammengetan, darunter Google, Continue, Dagger, Qualcomm Technologies, Hugging Face, Spring AI und VMware Tanzu AI Solutions. Sie haben erkannt, dass Entwickler eine bessere Möglichkeit brauchen, lokal mit KI-Modellen zu arbeiten, ohne auf die Vorteile moderner Entwicklungspraktiken verzichten zu müssen.
Bevor wir uns mit Docker Model Runner beschäftigen, zeig ich dir mal, welche Systemvoraussetzungen du brauchst. Die gute Nachricht ist: Wenn du Docker schon benutzt, bist du schon halb am Ziel. Docker Model Runner ist jetzt allgemein verfügbar und läuft auf allen Docker-Versionen, die macOS-, Windows- und Linux-Plattformen unterstützen.
Docker Model Runner kam zwar zuerst nur für Docker Desktop raus, aber seit Dezember 2025 läuft es auf jeder Plattform, die Docker Engine unterstützt.
Hier ist, was du auf den verschiedenen Plattformen brauchst:
|
Komponente |
Anforderung |
Anmerkungen |
|
Betriebssystem |
macOS, Windows, Linux |
Alle großen Plattformen werden unterstützt. |
|
Docker-Version |
Docker Desktop Docker-Engine |
Desktop für macOS/Windows Engine für Linux |
|
RAM |
Mindestens 8 GB 16 GB+ wird empfohlen |
Größere Modelle brauchen mehr Speicherplatz. |
|
GPU (optional) |
Apple-Silizium NVIDIA ARM/Qualcomm |
Bietet eine 2- bis 3-fache Leistungssteigerung |
Systemanforderungen für Docker Model Runner
Für die GPU-Beschleunigung unterstützt Docker Model Runner jetzt mehrere Backends:
Apple Silicon (M1/M2/M3/M4): Nutzt die Metal-API für GPU-Beschleunigung, die automatisch konfiguriert wird.
NVIDIA GPUs: Braucht NVIDIA Container Runtime und unterstützt CUDA-Beschleunigung.
ARM/Qualcomm: Hardwarebeschleunigung ist auf kompatiblen Geräten verfügbar.
Außerdem unterstützt Docker Model Runner Vulkan, was die Hardwarebeschleunigung auf einer viel größeren Auswahl an GPUs ermöglicht, darunter integrierte GPUs und solche von AMD, Intel und anderen Anbietern.
Du kannst Modelle zwar auch nur auf einer CPU laufen lassen, aber die GPU-Unterstützung macht die Inferenzleistung echt besser. Wir reden hier über den Unterschied zwischen 10 Sekunden und 3 Sekunden Wartezeit auf Antworten.
Ein wichtiger Hinweis: Einige Funktionenvon llama.cpp werden auf den GPUs der 6xx-Serie möglicherweise nicht vollständig unterstützt, und die Unterstützung für zusätzliche Engines wie MLX oder vLLM wird in Zukunft noch hinzugefügt.
Jetzt wird's richtig spannend. Das Design von Docker Model Runner ist anders als das, was man normalerweise von Containern kennt, und das vielleicht auf überraschende Weise. Ich erkläre dir mal, wie das Ganze im Hintergrund funktioniert.
Der Docker Model Runner nutzt einen hybriden Ansatz, der die Orchestrierungsfunktionen von Docker mit der nativen Host-Leistung für KI-Inferenz kombiniert. Was macht diese Architektur so besonders? Es überdenkt komplett, wie wir KI-Workloads machen.
Anders als bei normalen Docker-Containern läuft die Inferenz-Engine eigentlich gar nicht in einem Container. Stattdessen nutzt der Inferenzserver llama.cpp als Engine, läuft als nativer Host-Prozess, lädt Modelle nach Bedarf und führt die Inferenz direkt auf deiner Hardware durch.
Warum ist das wichtig? Diese Designentscheidung ermöglicht den direkten Zugriff auf Apples Metal-API für die GPU-Beschleunigung und vermeidet den Performance-Overhead, der durch die Ausführung von Inferenzvorgängen in virtuellen Maschinen entsteht. Die Trennung von Modellspeicherung und -ausführung ist so gewollt: Modelle werden separat gespeichert und nur bei Bedarf in den Speicher geladen, um dann nach einer Zeit der Inaktivität wieder entladen zu werden.
Jetzt schauen wir mal aus der Vogelperspektive, wie die Teile zusammenpassen. Auf einer höheren Ebene besteht Docker Model Runner aus drei übergeordneten Komponenten: dem Model Runner, den Model Distribution Tooling und dem Model CLI Plugin. Diese modulare Architektur macht schnellere Iterationen und klarere API-Grenzen zwischen verschiedenen Bereichen möglich.
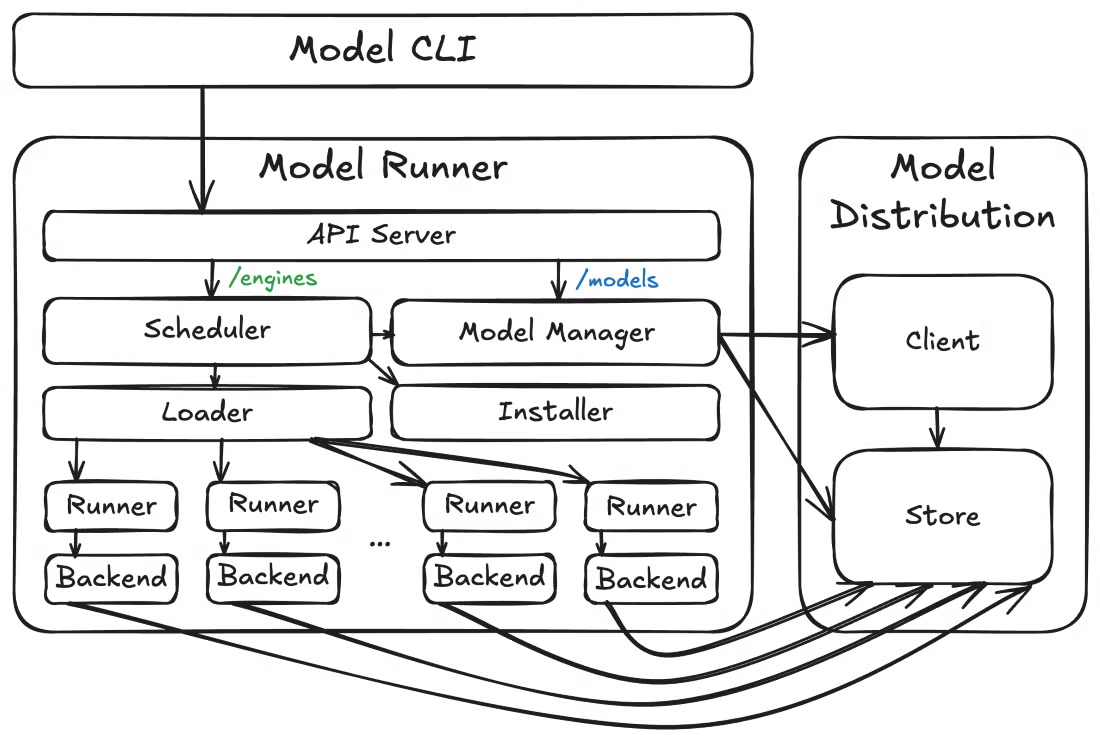
Docker-Modell-Runner-Architektur
Neben der Kernarchitektur denkt Docker Model Runner auch an die betrieblichen Anforderungen. Der Model Runner zeigt Metrik-Endpunkte unter /metrics an, sodass du die Modellleistung überwachen, Statistiken abfragen und die Ressourcennutzung verfolgen kannst. Diese eingebaute Beobachtbarkeit ist super wichtig für Produktionsumgebungen, wo du einen Überblick über das Modellverhalten und den Ressourcenverbrauch brauchst.
Da die Architektur Sinn ergibt, fragst du dich wahrscheinlich: Was kann ich mit diesem Ding eigentlich machen? Ich zeig dir mal die Funktionen, die Docker Model Runner für meine KI-Entwicklungsabläufe so interessant machen.
Hier ein kurzer Überblick über die herausragenden Funktionen:
|
Feature |
Vorteil |
Perfekt für |
|
Open Source & kostenlos |
Keine Lizenzkosten Völlige Transparenz |
Experimentieren Lernen Produktionsnutzung |
|
Docker-CLI-Integration |
Bekannte Befehle (Docker-Modell ziehen/ausführen/auflisten) |
Docker-Nutzer, die keine neuen Tools lernen wollen |
|
OCI-konforme Verpackung |
Standardmäßige Modellverteilung über Register |
Versionskontrolle Zugriffsverwaltung |
|
OpenAI-API-Kompatibilität |
Einfacher Ersatz für Cloud-APIs |
Einfache Migration von der Cloud auf den lokalen Rechner |
|
Sandbox-Ausführung |
Abgeschirmte Umgebung für mehr Sicherheit |
Compliance-Anforderungen für Unternehmen |
|
GPU-Beschleunigung |
2-3x schnellere Inferenz |
Echtzeitanwendungen Hoher Durchsatz |
Docker Model Runner – Die wichtigsten Funktionen
Die Befehlszeilenschnittstelle lässt sich super in bestehende Docker-Workflows einbauen. Du wirst Befehle wie „ docker model pull “, „ docker model run “ und „ docker model list “ benutzen und dabei die gleichen Muster anwenden, die du schon von der Arbeit mit Containern kennst.
Die grafische Benutzeroberfläche von Docker Desktop bietet eine geführte Einweisung, die auch AI-Entwicklern, die zum ersten Mal damit arbeiten, dabei hilft, Modelle reibungslos bereitzustellen, wobei verfügbare Ressourcen wie RAM und GPU automatisch verwaltet werden.
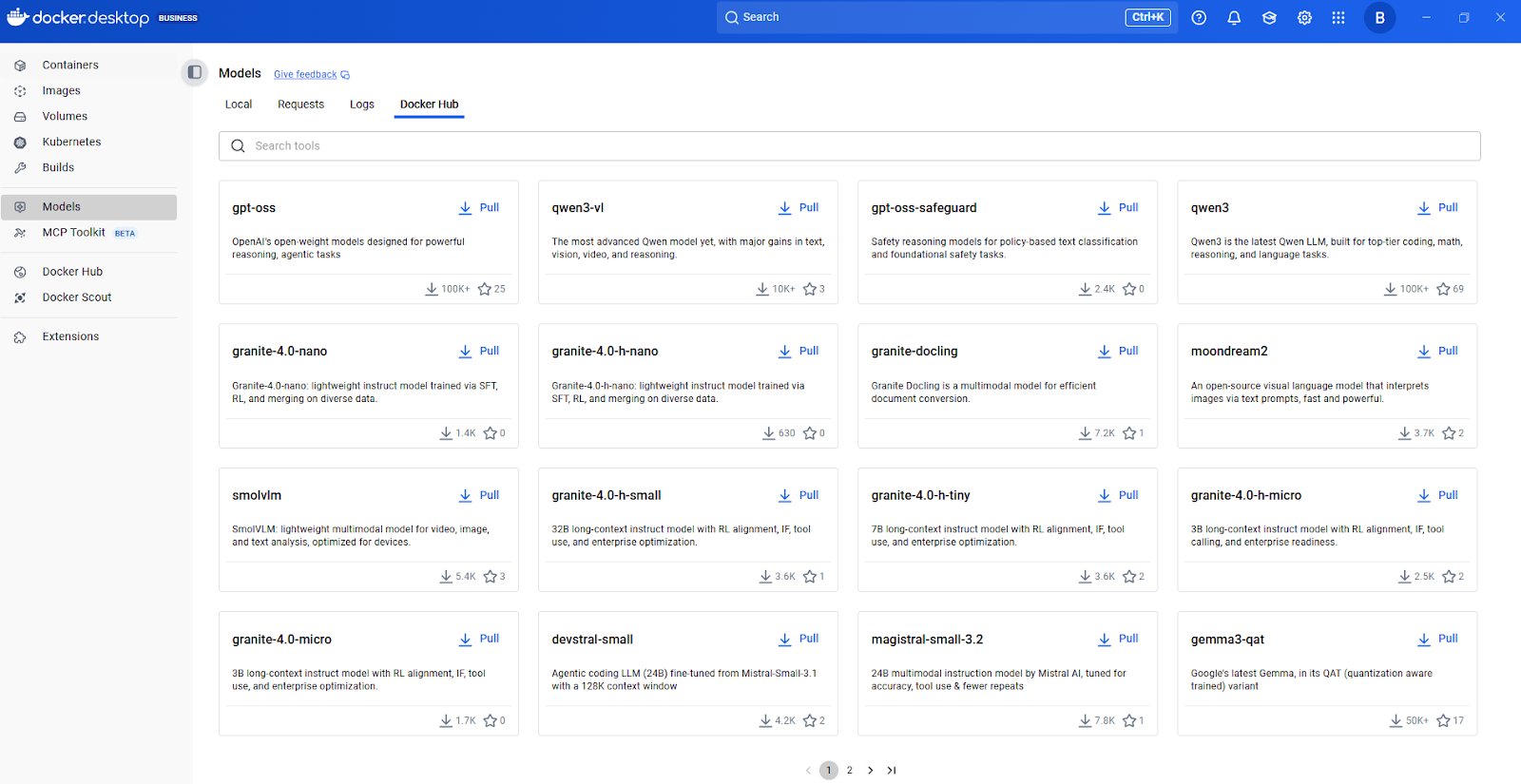
Docker-Modell-Hub
Jetzt reden wir mal darüber, wie Modelle verpackt und verteilt werden. Docker Model Runner unterstützt OCI-verpackte Modelle, sodass du Modelle über jede OCI-kompatible Registrierungsstelle, einschließlich Docker Hub, speichern und verteilen kannst. Mit diesem standardisierten Verpackungsansatz kannst du die gleichen Versions-, Zugriffskontroll- und Verteilungsmuster wie bei Container-Images nutzen.
Wenn es um die Integration mit Anwendungen geht, sind die REST-API-Funktionen besonders nützlich für die Anwendungsintegration. Docker Model Runner hat eine Inferenz-Engine, die auf llama.cpp basiert und über die bekannte OpenAI-API erreichbar ist.
Dank dieser OpenAI-Kompatibilität kann bestehender Code, der für die API von OpenAI geschrieben wurde, mit minimalen Änderungen mit lokalen Modellen verwendet werden – du musst deine Anwendung einfach auf den lokalen Endpunkt statt auf die Cloud-API verweisen. Allein diese Flexibilität kann wochenlange Überarbeitungen sparen.
Ich zeig dir, wie du Docker Model Runner auf deinem System installierst und zum Laufen bringst. Die Installation ist einfach, aber es gibt ein paar plattformspezifische Sachen, die man vorher wissen sollte.
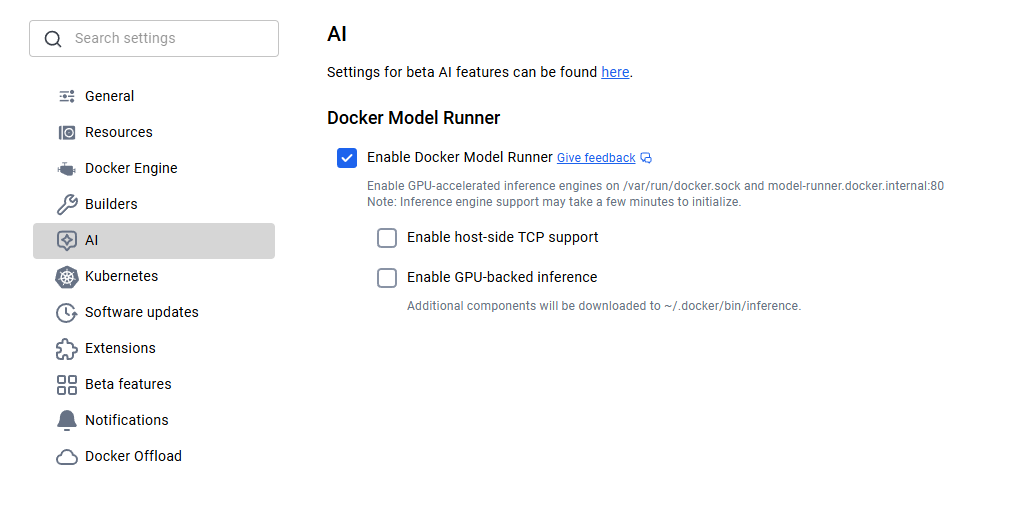
Für Leute, die macOS oder Windows nutzen, ist Docker Model Runner in Docker Desktop 4.40 oder höher schon dabei. Lade einfach die neueste Version von der offiziellen Website von Docker runter und installiere sie. Nach der Installation musst du Docker Model Runner in den Einstellungen aktivieren. Geh zu „Einstellungen“ > „KI“ und wähl die Option „Docker Model Runner“ und „GPU-Backend-Inferenz“, falls dein Computer NVIDIA-GPUs unterstützt.
Aktivierung des Docker-Modell-Runners
Linux-Nutzer kriegen ein noch optimierteres Erlebnis. Aktualisiere dein System und installiere das Docker Model Runner-Plugin mit den folgenden Befehlen.
sudo apt-get update
sudo apt-get install docker-model-pluginNach der Installation check mal, ob alles klappt, indem du „ docker model version “ ausführst.
Wenn du Apple Silicon nutzt, wird die GPU-Beschleunigung über Metal automatisch eingerichtet und du musst nichts weiter machen. Für NVIDIA-GPUs musst du sicherstellen, dass die NVIDIA Container Runtime installiert ist.
Dank der Vulkan-Unterstützung kannst du jetzt die Hardwarebeschleunigung auf AMD-, Intel- und anderen GPUs nutzen, die die Vulkan-API unterstützen. Das System erkennt deine Hardware automatisch und passt die Beschleunigung entsprechend an.
Sobald das Programm installiert ist, ist das Herunterladen eines Modells echt einfach. Du musst nur das Modell erst mal laden und dann starten, um damit zu arbeiten:
docker model pull ai/smollm2
docker model run ai/smollm2Wenn alles richtig eingerichtet wurde, solltest du das Modell in der Liste sehen:
docker model listMODEL NAME
ai/smollm2Nachdem du Docker Model Runner installiert hast und weißt, wie man Modelle abruft, kommt natürlich die nächste Frage: Woher kommen diese Modelle und wie kann ich sie in großem Maßstab verwalten? Hier zeigt sich der Ansatz von Docker Model Runner als besonders elegant.
Docker packt Modelle als OCI-Artefakte, einen offenen Standard, der die Verteilung über dieselben Register und Workflows ermöglicht, die auch für Container genutzt werden. Teams, die schon private Docker-Registries nutzen, können dieselbe Infrastruktur auch für KI-Modelle verwenden. Docker Hub hat coole Unternehmensfunktionen wie die Verwaltung des Registrierungszugriffs für richtlinienbasierte Zugriffskontrollen.
Die Integration mit Hugging Face ist echt erwähnenswert. Entwickler können Docker Model Runner als lokale Inferenz-Engine nutzen, um Modelle auf Hugging Face auszuführen und direkt in der Hugging Face-Oberfläche nach unterstützten Modellen (GGUF-Format ist erforderlich) zu filtern. Das macht die Modellfindung echt einfacher.
docker model pull hf.co/bartowski/Llama-3.2-1B-Instruct-GGUFDas wirklich Clevere daran ist, wie diese Integration im Hintergrund funktioniert. Wenn du ein Modell im GGUF-Format von Hugging Face holst, packt Docker Model Runner es automatisch als OCI-Artefakt. Diese nahtlose Konvertierung macht manuelle Verpackungsschritte überflüssig und beschleunigt den Weg von der Modellfindung bis zur Bereitstellung.
Es ist super, den Verteilungsmechanismus zu verstehen, aber welche Modelle kannst du tatsächlich ausführen? Ich zeig dir mal, was du direkt nach dem Auspacken nutzen kannst und wie du mehr findest.
Docker Model Runner hat eine coole Auswahl an Modellen, die du sofort nutzen kannst. SmolLM2 ist echt beliebt und mit seinen 360 Millionen Parametern super für Chat-Assistenten, Textextraktion, Umschreiben und Zusammenfassungen. Ich finde dieses Modell echt praktisch für die Entwicklung und das Testen, weil es so klein ist und schnell Schlussfolgerungen zieht.
Um weitere Modelle zu entdecken, empfehle ich, mit dem KI-Modellkatalog von Docker Hub anzufangen. Schau dir die verfügbaren Modelle an, check ihre Dokumentation für unterstützte Aufgaben und Hardwareanforderungen und hol sie dir dann mit einem einfachen Befehl „ docker model pull “.
Modelle werden bei der ersten Nutzung von Docker Hub geholt und lokal gespeichert. Sie werden nur zur Laufzeit in den Speicher geladen, wenn eine Anfrage kommt, und wieder entladen, wenn sie nicht gebraucht werden, um die Ressourcen zu optimieren.
Mit diesem Ansatz bleibt dein System auch dann reaktionsschnell, wenn du mehrere Modelle heruntergeladen hast. Du musst nicht alles gleichzeitig im RAM behalten.
Jede Modellbeschreibung hat Infos zu Quantisierungsstufen (wie Q4_0, Q8_0), die die Modellgröße und die Inferenzqualität beeinflussen.
|
Quantisierungsebene |
Beschreibung |
Dateigröße |
Qualität |
Am besten geeignet für |
|
Q8_0 |
8-Bit-Quantisierung |
Größter |
Top Qualität |
Einsatz in der Produktion, Aufgaben, bei denen es auf Genauigkeit ankommt |
|
Q5_0 |
5-Bit-Quantisierung |
Mittel |
Gute Balance |
Allzweck, ausgewogene Leistung |
|
Q4_0 |
4-Bit-Quantisierung |
Kleinster |
In Ordnung |
Entwicklung, Test, Umgebungen mit begrenzten Ressourcen |
Modellquantisierung
Ein wichtiger Punkt ist die Versionierung von Modellen. Du kannst genaue Versionen mit Tags angeben (wie Q4_0 oder latest), ähnlich wie bei Docker-Images. Das sorgt für reproduzierbare Bereitstellungen und verhindert unerwartete Änderungen, wenn Modelle aktualisiert werden.
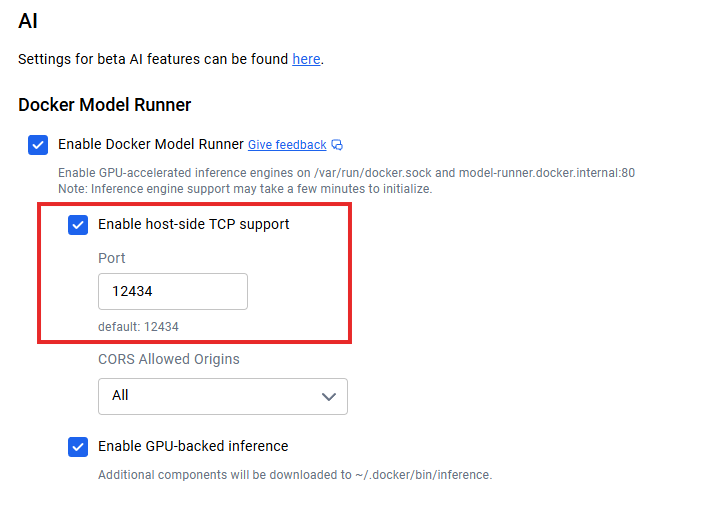
Sobald du die Modelle lokal laufen hast, stellt sich die Frage: Wie verbinde ich meine Anwendungen? Wenn die TCP-Unterstützung auf der Host-Seite aktiviert ist (z. B. über die TCP-Einstellungen von Docker Desktop), läuft der Standard-API-Endpunkt unter localhost:12434 und stellt OpenAI-kompatible Endpunkte bereit.
Docker Model Runner API-Integration
Hier ist ein einfaches Beispiel für eine Anfrage:
curl http://localhost:12434/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/smollm2",
"messages": [{"role": "user", "content": "Explain containerization"}],
"stream": false
}'Bei Microservice-Architekturen können deine Anwendungscontainer über Standard-HTTP-Protokolle mit dem Modelldienst kommunizieren – du brauchst dafür keine speziellen SDKs. Für Echtzeit-Apps wird das Response-Streaming unterstützt, indem man ` "stream": true` einstellt.
Die REST-API-Dokumentation hat alle Endpunktspezifikationen, Parameteroptionen und Antwortschemata. Ich empfehle, die offizielle Docker-Dokumentation zu checken, um die aktuellsten API-Details zu erfahren, da sich die Plattform ständig weiterentwickelt.
Um Docker Model Runner optimal nutzen zu können, musst du ein paar wichtige Strategien verstehen. Ich erzähl dir mal, was ich bei der Arbeit mit lokalen Modellbereitstellungen gelernt habe.
Model Runner läuft als Prozess auf Host-Ebene mit direktem Zugriff auf die GPU und erreicht dadurch eine bessere Leistungsoptimierung als Lösungen mit Containern. Diese architektonische Entscheidung zahlt sich in Sachen Durchsatz und Latenz aus, aber du musst trotzdem alles richtig einstellen, um das Beste rauszuholen.
Hardwarebeschleunigung ist dein erster Optimierungshebel. Wenn man die GPU-Unterstützung einschaltet, wird die Leistung im Vergleich zur reinen CPU-Inferenz normalerweise um das 2- bis 3-fache verbessert. Neben der Hardware ist die Modellquantisierung dein zweiter wichtiger Regler. Normalerweise fange ich mit Q8_0 an, weil das die beste Qualität hat, und wechsle dann zu Q5_0 oder Q4_0, wenn ich mehr Leistung brauche.
Der eingebaute Metrik-Endpunkt unter /metrics macht es möglich, mit Prometheus oder deinem bestehenden Monitoring-Stack zu überwachen. Für die Skalierung solltest du die Kontextlänge nach dem tatsächlichen Bedarf einstellen, statt die Maximalwerte zu nehmen. Wenn deine Anwendung nur 2048 Kontexttoken braucht, dann konfiguriere sie nicht für 8192.
Einer der größten Vorteile von Docker Model Runner ist, wie gut es mit dem ganzen Docker-Ökosystem zusammenarbeitet.
Docker Model Runner unterstützt Docker Compose. Das heißt, du kannst Multi-Service-Anwendungen machen, bei denen ein Service ein KI-Modell ist, und den ganzen Stack mit den bekannten Docker Compose-Dateien verwalten. So sieht das aus:
services:
app:
image: my-app:latest
models:
- llm
- embedding
models:
llm:
model: ai/smollm2
embedding:
model: ai/embeddinggemmaDu kannst auch CI/CD-Workflows automatisieren: Modelle in deiner Testumgebung starten, Integrationstests durchführen und alles wieder abbauen – und das alles innerhalb deiner bestehenden Pipeline-Infrastruktur. Damit ist das Problem „Auf meinem Rechner funktioniert es“ bei KI-Funktionen gelöst.
Eine weitere coole Integration ist Docker Offload, das deinen lokalen Arbeitsablauf bei Bedarf auf die Cloud ausweitet. Auch wenn es noch eine Beta-Funktion ist, kannst du damit lokal mit Docker Model Runner entwickeln und dann ressourcenintensive Inferenzaufgaben an die Cloud-Infrastruktur auslagern, wenn die Anforderungen die lokalen Kapazitäten übersteigen.
Docker-Auslagerung
Unterstützung für die Ausführung in Kubernetes gibt's auch als Helm-Chart und als statische YAML-Datei. Das eröffnet Möglichkeiten für den Einsatz in der Produktion, wo du horizontale Skalierung, Lastenausgleich und hohe Verfügbarkeit brauchst.
Die Kubernetes-Integration ist zwar noch im Versuchsstadium, zeigt aber, wie sich Docker Model Runner zu einer Lösung für Unternehmen entwickelt, wo man Tausende von Anfragen pro Sekunde über mehrere Replikate bedienen kann.
Bei all diesen Integrationsmöglichkeiten fragst du dich vielleicht: Aber ist das auch sicher? Der Docker Model Runner läuft in einer isolierten, kontrollierten Umgebung und bietet Sandboxing für mehr Sicherheit. Diese Isolierung verhindert, dass Modelle auf sensible Systemressourcen zugreifen können, die über die explizit bereitgestellten Ressourcen hinausgehen.
Der wichtigste Sicherheitsvorteil ist der Datenschutz. Deine Abfragen verlassen nie deine Infrastruktur, sodass keine Gefahr besteht, dass Daten abgezogen werden. Für Unternehmen, die mit sensiblen Daten arbeiten, ist dieses lokale Ausführungsmodell super wichtig, um die DSGVO, HIPAA und andere Datenschutzbestimmungen einzuhalten.
Admins können die TCP-Unterstützung auf der Host-Seite und CORS für eine detaillierte Sicherheitskontrolle einrichten. Metadaten zur Modelllizenzierung in Registern machen es möglich, die Einhaltung von Vorschriften zu verfolgen und Prüfpfade für die Unternehmensführung zu erstellen.
Mittlerweile fragst du dich vielleicht: Wie schneidet das im Vergleich zu den Tools ab, die ich schon benutze? Hier ist ein Vergleich zwischen Docker Model Runner und Ollama sowie NVIDIA NIM:
|
Feature |
Docker-Modell-Runner |
Ollama |
NVIDIA NIM |
|
Leistung |
1,00-1,12-mal schneller als Ollama |
Grundleistung |
Super optimiert für NVIDIA-GPUs |
|
Ökosystemintegration |
Eigener Docker-Workflow, OCI-Artefakte |
Eigenständiges Tool, separater Arbeitsablauf |
Containerisiert, speziell für NVIDIA |
|
Modellanpassung |
Vorkonfigurierte Modelle von Docker Hub |
Benutzerdefinierte Modelldateien, GGUF/Safetensors-Import |
Nur NVIDIA-optimierte Modelle |
|
Plattform-Support |
macOS, Windows, Linux |
macOS, Windows, Linux, Docker |
Nur Linux mit NVIDIA-GPUs |
|
Hardware-Anforderungen |
Jede GPU (Metal, CUDA, Vulkan) oder CPU |
Jede beliebige GPU oder CPU |
NVIDIA-GPUs sind nötig |
|
Community & SDKs |
Wachstum, Fokus auf das Docker-Ökosystem |
Reif, umfangreich |
NVIDIA-Ökosystem, auf Unternehmen ausgerichtet |
|
Am besten geeignet für |
Teams mit Docker-Infrastruktur |
Einzelne KI-Projekte, schnelle Experimente |
Produktionsbereitstellungen mit Schwerpunkt auf NVIDIA |
Das Hauptmerkmal von Docker Model Runner ist die Integration in das Ökosystem. Es behandelt KI-Modelle genauso wichtig wie Container und reduziert so die Anzahl der Tools für Teams, die mit Docker arbeiten.
Ollama bietet mehr Möglichkeiten zur Modellanpassung und eine ausgereifte Community mit umfangreichen SDKs. NVIDIA NIM bietet die beste Leistung für NVIDIA-GPUs, aber es fehlt die Flexibilität und die plattformübergreifende Unterstützung der anderen Optionen.
Bevor wir zum Schluss kommen, lass uns noch mal darüber reden, was passiert, wenn es nicht klappt.
Dieser Fehler zeigt meistens an, dass die Docker-CLI die ausführbare Datei des Plugins nicht finden kann.
Grund: Docker kann das Plugin nicht im erwarteten CLI-Plugin-Verzeichnis finden.
Lösung: Du musst wahrscheinlich einen symbolischen Link (Symlink) zur ausführbaren Datei erstellen. Die genauen Befehle findest du im Abschnitt zur Installation.
Im Moment kann es sein, dass das Abrufen oder Referenzieren von Modellen mit bestimmten Digests nicht klappt.
Workaround: Beziehe dich auf Modelle anhand ihres Tag-Namens (z. B. model:v1) und nicht anhand ihres Digests.
Status: Das Entwicklerteam arbeitet gerade daran, die richtige Unterstützung für Digest in einer zukünftigen Version hinzukriegen.
Wenn deine Modelle langsam laufen oder die GPU nicht nutzen, mach mal die folgenden Checks:
Treiber überprüfen: Stell sicher, dass die GPU-Treiber deines Host-Rechners auf dem neuesten Stand sind.
Berechtigungen überprüfen: Stell sicher, dass Docker die Berechtigungen hat, auf GPU-Ressourcen zuzugreifen.
Linux (NVIDIA): Stell sicher, dass die NVIDIA Container Runtime installiert und eingerichtet ist.
Überprüfung: Mach mal den folgenden Befehl, um zu checken, ob die GPU vom System erkannt wird: nvidia-smi
Wenn du auf ein Problem stößt, das hier nicht aufgeführt ist:
Ein Problem melden: Melde Fehler oder schick uns Feature-Wünsche über das offizielle GitHub-Repository.
Community: Es gibt 'ne aktive Community, die oft schnelle Lösungen für Sonderfälle findet.
Docker Model Runner ist ein wichtiger Schritt, um die KI-Entwicklung zugänglicher zu machen. Durch die Integration des Modellmanagements in das Docker-Ökosystem werden die Probleme beseitigt, die bisher die Einführung von KI gebremst haben.
Die strategische Bedeutung geht über die Bequemlichkeit hinaus. In einer Zeit, in der Datenschutz, Kostenkontrolle und Entwicklungsgeschwindigkeit wichtiger denn je sind, wird die lokale KI-Ausführung immer wichtiger. Mit Docker Model Runner kannst du einfacher experimentieren und KI-Anwendungen erstellen, indem du die gleichen Docker-Befehle und -Workflows nutzt, die Entwickler schon jeden Tag verwenden.
Für die Zukunft ist geplant, die Plattform weiter zu verbessern, mit Unterstützung für zusätzliche Inferenzbibliotheken, erweiterten Konfigurationsoptionen und Funktionen für den verteilten Einsatz. Die Verbindung von Containerisierung und KI zeigt, wohin sich die Branche entwickelt, und Docker Model Runner ist genau da, wo das passiert. Damit wird die datenschutzorientierte, kostengünstige KI-Entwicklung für Millionen von Entwicklern, die Docker schon nutzen, zur Realität.
Jetzt, wo du Modelle in deiner lokalen Docker-Umgebung laufen hast, geht's darum, eine zuverlässige Pipeline drum herum aufzubauen. Lerne die Grundlagen der Modellversionierung, Bereitstellung und Lebenszyklusverwaltung mit dem MLOps Fundamentals Skill Track auf DataCamp.
Docker-Kurse
Lernpfad
Lernpfad
Kurs
Blog
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Matt Crabtree
Tutorial
Stephen Gruppetta
Tutorial
Moez Ali
