

Cursus
Principes de base des MLOps
14 h
Alors que l'IA générative continue de transformer le développement logiciel, j'ai remarqué un défi persistant : l'exécution locale de modèles d'IA reste plus complexe qu'elle ne devrait l'être.
Les développeurs sont confrontés à des outils fragmentés, à des problèmes de compatibilité matérielle et à des flux de travail qui semblent déconnectés de leur environnement de développement quotidien. Docker Model Runner a été lancé en avril 2025 pour relever ces défis, facilitant l'exécution et le test de modèles d'IA localement dans les workflows Docker existants.
Docker Model Runner représente une transition de l'IA basée sur le cloud vers des workflows locaux et conteneurisés, offrant des avantages tels que la confidentialité des données, la réduction des coûts et une itération plus rapide, tout en s'intégrant à l'écosystème Docker. D'après mon expérience dans le domaine du déploiement de l'IA, ces avantages sont essentiels pour les équipes qui développent des applications prêtes à être mises en production tout en conservant le contrôle des données sensibles.
Si vous débutez avec Docker, je vous recommande de suivre ce cours d'introduction à Docker.
Le modèle traditionnel d'IA présente plusieurs défis auxquels j'ai été confronté personnellement.
Les modèles d'IA contiennent des poids mathématiques qui ne bénéficient pas de la compression, contrairement aux images Docker traditionnelles. Cela entraîne des inefficacités de stockage lorsque les modèles sont intégrés à leur environnement d'exécution. De plus, la configuration de moteurs d'inférence, la gestion de l'accélération matérielle et la maintenance d'outils distincts pour les modèles et les conteneurs d'applications génèrent une complexité inutile.
C'est précisément là qu'intervient Docker Model Runner. Au lieu d'ajouter un nouvel outil à votre pile, il facilite le téléchargement, l'exécution et la distribution de modèles linguistiques volumineux (LLM) directement depuis Docker Hub dans un format compatible OCI (Open Container Initiative) ou depuis Hugging Face si les modèles sont disponibles dans un format unifié généré par GPT.(GGUF) (GGUF). La plateforme résout le problème de fragmentation en intégrant la gestion des modèles dans le même flux de travail que celui utilisé par les développeurs pour les conteneurs.
Le contexte historique est ici important. Avec l'accélération de l'adoption de l'IA générative, le secteur a observé une tendance croissante vers des flux de travail IA sécurisés et privilégiant le local. Les organisations se sont montrées de plus en plus préoccupées par la confidentialité des données, les coûts des API et la dépendance vis-à-vis des fournisseurs associés aux services d'IA basés sur le cloud.
Docker s'est associé à des acteurs influents dans le domaine de l'IA et du développement logiciel, notamment Google, Continue, Dagger, Qualcomm Technologies, Hugging Face, Spring AI et VMware Tanzu AI Solutions, conscient que les développeurs avaient besoin d'une meilleure solution pour travailler avec des modèles d'IA en local sans compromettre les avantages des pratiques de développement modernes.
Avant de nous plonger dans Docker Model Runner, permettez-moi de vous présenter la configuration système requise. La bonne nouvelle est que si vous utilisez déjà Docker, vous avez déjà fait la moitié du chemin. Docker Model Runner est désormais disponible et fonctionne avec toutes les versions de Docker, prenant en charge les plateformes macOS, Windows et Linux.
Bien que Docker Model Runner ait été initialement lancé exclusivement sur Docker Desktop, depuis décembre 2025, il est compatible avec toutes les plateformes prenant en charge Docker Engine.
Voici ce dont vous aurez besoin sur différentes plateformes :
|
Composant |
Exigence |
Remarques |
|
Système d'exploitation |
macOS, Windows, Linux |
Toutes les principales plateformes sont prises en charge. |
|
Version Docker |
Docker Desktop Moteur Docker |
Bureau pour macOS/Windows Moteur pour Linux |
|
RAM |
8 Go minimum 16 Go ou plus recommandés |
Les modèles plus grands nécessitent davantage de mémoire. |
|
GPU (facultatif) |
Silicium Apple NVIDIA ARM/Qualcomm |
Offre des performances 2 à 3 fois supérieures |
Configuration système requise pour Docker Model Runner
Pour l'accélération GPU, Docker Model Runner prend désormais en charge plusieurs backends :
Apple Silicon (M1/M2/M3/M4) : Utilise l'API Metal pour l'accélération GPU, configurée automatiquement.
Processeurs graphiques NVIDIA : Nécessite NVIDIA Container Runtime, prend en charge l'accélération CUDA.
ARM/Qualcomm : Accélération matérielle disponible sur les appareils compatibles.
De plus, Docker Model Runner prend en charge Vulkan depuis octobre 2025, ce qui permet l'accélération matérielle sur une gamme beaucoup plus large de GPU, y compris les GPU intégrés et ceux d'AMD, d'Intel et d'autres fournisseurs.
Bien qu'il soit possible d'exécuter des modèles sur un processeur seul, la prise en charge du processeur graphique améliore considérablement les performances d'inférence. Nous discutons de la différence entre attendre 10 secondes et 3 secondes pour obtenir une réponse.
Remarque importante : Certaines fonctionnalités de fonctionnalitésde llama.cpp pourraient ne pas être entièrement prises en charge sur les GPU de la série 6xx, et la prise en charge de moteurs supplémentaires tels que MLX ou vLLM sera ajoutée à l'avenir.
C'est là que les choses deviennent vraiment intéressantes. La conception architecturale de Docker Model Runner rompt avec la conteneurisation traditionnelle d'une manière qui pourrait vous surprendre. Permettez-moi de vous expliquer comment cela fonctionne concrètement.
Docker Model Runner met en œuvre une approche hybride qui combine les capacités d'orchestration de Docker avec les performances natives de l'hôte pour l'inférence IA. Qu'est-ce qui rend cette architecture distinctive ? Il repense fondamentalement la manière dont nous gérons les charges de travail liées à l'IA.
Contrairement aux conteneurs Docker standard, le moteur d'inférence ne s'exécute pas réellement à l'intérieur d'un conteneur. Au lieu de cela, le serveur d'inférence utilise llama.cpp comme moteur, fonctionnant comme un processus hôte natif qui charge les modèles à la demande et effectue l'inférence directement sur votre matériel.
Pourquoi est-ce important ? Ce choix de conception permet un accès direct à l'API Metal d'Apple pour l'accélération GPU et évite la surcharge de performance liée à l'exécution de l'inférence dans des machines virtuelles. La séparation entre le stockage et l'exécution des modèles est intentionnelle : les modèles sont stockés séparément et chargés en mémoire uniquement lorsque cela est nécessaire, puis déchargés après une période d'inactivité.
Maintenant, prenons un peu de recul et examinons comment ces éléments s'articulent entre eux. À un niveau supérieur, Docker Model Runner se compose de trois éléments principaux : le modèle d'exécution, l'outil de distribution du modèle et le plugin CLI du modèle. Cette architecture modulaire permet une itération plus rapide et des limites d'API plus claires entre les différentes préoccupations.
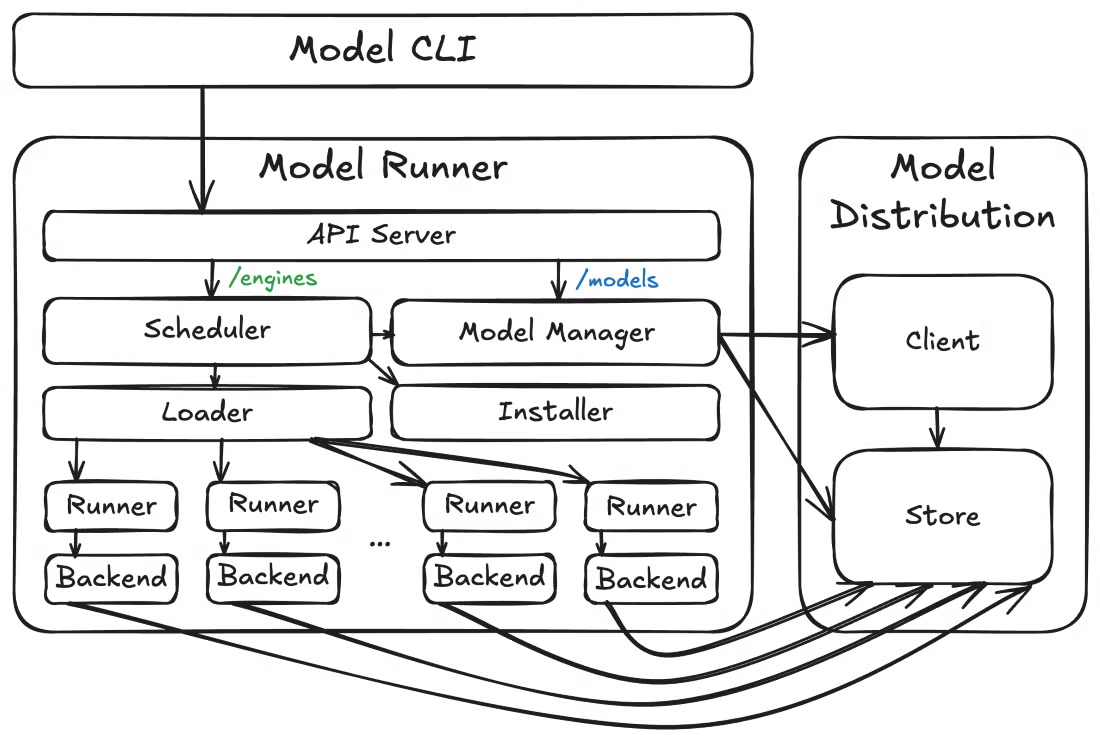
Architecture du modèle Docker Runner
Au-delà de l'architecture de base, Docker Model Runner anticipe également les besoins opérationnels. Le Model Runner expose les points de terminaison des métriques à l'adresse /metrics, ce qui vous permet de surveiller les performances du modèle, de demander des statistiques et de suivre l'utilisation des ressources. Cette observabilité intégrée est essentielle pour les déploiements en production où il est nécessaire d'avoir une visibilité sur le comportement des modèles et la consommation des ressources.
Maintenant que l'architecture est claire, vous vous demandez probablement : que puis-je réellement faire avec cet outil ? Permettez-moi de vous présenter les fonctionnalités qui ont rendu Docker Model Runner incontournable dans mes processus de développement d'IA.
Voici un aperçu rapide des fonctionnalités les plus remarquables :
|
Caractéristique |
Avantage |
Idéal pour |
|
Open Source et gratuit |
Aucun frais de licence Transparence totale |
Expérimentation Apprentissage Utilisation en production |
|
Intégration de l'interface CLI Docker |
Commandes familières (modèle Docker pull/run/list) |
Les utilisateurs de Docker qui ne souhaitent pas acquérir de nouveaux outils |
|
Emballage conforme à la norme OCI |
Distribution du modèle standard via les registres |
Contrôle de version Gestion des accès |
|
Compatibilité avec l'API OpenAI |
Remplacement direct des API cloud |
Transition aisée du cloud vers un environnement local |
|
Exécution en mode sandbox |
Environnement isolé pour la sécurité |
Exigences de conformité de l'entreprise |
|
Accélération GPU |
Inférence 2 à 3 fois plus rapide |
Applications en temps réel Débit élevé |
Fonctionnalités principales de Docker Model Runner
L'interface de ligne de commande s'intègre parfaitement aux flux de travail Docker existants. Vous utiliserez des commandes telles que docker model pull, docker model run et docker model list, en suivant les mêmes modèles que ceux que vous connaissez déjà pour travailler avec des conteneurs.
L'interface utilisateur graphique de Docker Desktop offre une intégration guidée afin d'aider même les développeurs IA débutants à commencer à utiliser des modèles en toute simplicité, avec une gestion automatique des ressources disponibles telles que la RAM et le GPU.
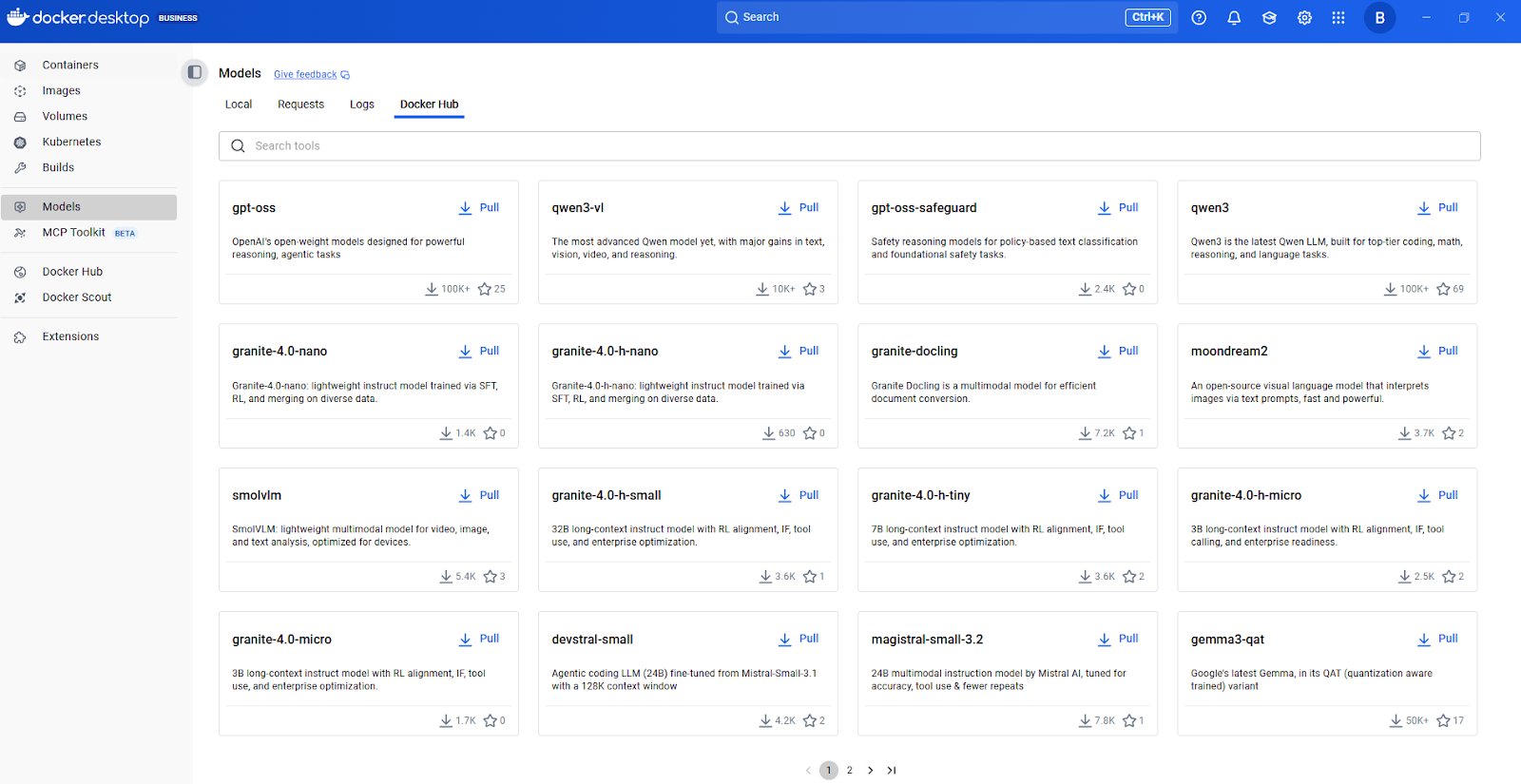
Centre de modèles Docker
À présent, nous allons aborder la manière dont les modèles sont packagés et distribués. Docker Model Runner prend en charge les modèles packagés OCI, ce qui vous permet de stocker et de distribuer des modèles via n'importe quel registre compatible OCI, y compris Docker Hub. Cette approche standardisée de l'empaquetage vous permet d'appliquer les mêmes modèles de gestion des versions, de contrôle d'accès et de distribution que ceux utilisés pour les images de conteneurs.
En matière d'intégration avec des applications, les fonctionnalités de l'API REST sont particulièrement utiles pour l'intégration d'applications. Docker Model Runner comprend un moteur d'inférence basé sur llama.cpp et accessible via l'API OpenAI familière.
Cette compatibilité avec OpenAI signifie que le code existant écrit pour l'API d'OpenAI peut fonctionner avec des modèles locaux avec un minimum de modifications. Il suffit de diriger votre application vers le point de terminaison local au lieu de l'API cloud. Cette flexibilité peut à elle seule permettre d'économiser plusieurs semaines de refonte.
Permettez-moi de vous guider dans l'installation et la mise en service de Docker Model Runner sur votre système. Le processus d'installation est simple, mais il existe certaines considérations spécifiques à la plateforme qu'il est important de connaître à l'avance.
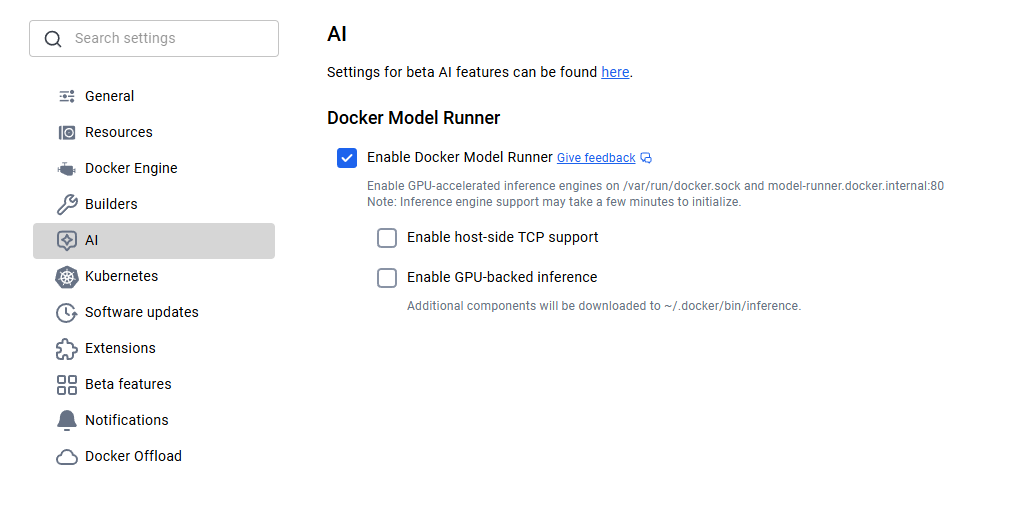
Pour les utilisateurs de macOS et Windows, Docker Model Runner est inclus dans Docker Desktop 4.40 ou version ultérieure. Veuillez télécharger la dernière version depuis le site officiel de Docker et procéder à son installation. Une fois installé, il sera nécessaire d'activer Docker Model Runner dans les paramètres. Veuillez vous rendre dans Paramètres > IA, puis sélectionnez l'option Docker Model Runner et l'inférence GPU-backend si votre ordinateur prend en charge le GPU NVIDIA.
Activation du modèle Docker Runner
Les utilisateurs Linux bénéficient d'une expérience encore plus optimisée. Veuillez mettre à jour votre système et installer le plugin Docker Model Runner à l'aide des commandes suivantes.
sudo apt-get update
sudo apt-get install docker-model-pluginAprès l'installation, veuillez vérifier son bon fonctionnement en exécutant docker model version.
Si vous utilisez Apple Silicon, l'accélération GPU via Metal est automatiquement configurée et aucune configuration supplémentaire n'est nécessaire. Pour les GPU NVIDIA, veuillez vous assurer que NVIDIA Container Runtime est correctement installé.
Grâce à la prise en charge de Vulkan, vous pouvez désormais tirer parti de l'accélération matérielle sur les GPU AMD, Intel et autres qui prennent en charge l'API Vulkan. Le système détecte intelligemment votre matériel et applique l'accélération appropriée.
Une fois installé, le téléchargement d'un modèle devient extrêmement simple. Il vous suffit de télécharger le modèle, puis de l'exécuter pour interagir avec lui :
docker model pull ai/smollm2
docker model run ai/smollm2Si tout a été configuré correctement, vous devriez voir le modèle dans la liste :
docker model listMODEL NAME
ai/smollm2Une fois que vous avez installé Docker Model Runner et que vous comprenez comment extraire des modèles, la question suivante qui se pose naturellement est la suivante : d'où proviennent ces modèles et comment puis-je les gérer à grande échelle ? C'est là que l'approche de Docker Model Runner se révèle particulièrement efficace.
Docker regroupe les modèles sous forme d'artefacts OCI, une norme ouverte permettant la distribution via les mêmes registres et workflows que ceux utilisés pour les conteneurs. Les équipes qui utilisent déjà des registres Docker privés peuvent employer la même infrastructure pour les modèles d'IA. Docker Hub offre des fonctionnalités d'entreprise telles que la gestion des accès au registre pour les contrôles d'accès basés sur des politiques.
L'intégration avec Hugging Face mérite une mention spéciale. Les développeurs peuvent utiliser Docker Model Runner comme moteur d'inférence local pour exécuter des modèles sur Hugging Face et filtrer les modèles pris en charge (format GGUF requis) directement dans l'interface Hugging Face. Cela facilite considérablement la découverte de modèles.
docker model pull hf.co/bartowski/Llama-3.2-1B-Instruct-GGUFCe qui est particulièrement ingénieux, c'est la manière dont cette intégration fonctionne en arrière-plan. Lorsque vous récupérez un modèle depuis Hugging Face au format GGUF, Docker Model Runner le compile automatiquement en tant qu'artefact OCI à la volée. Cette conversion transparente élimine les étapes manuelles d'empaquetage et accélère le processus, de la découverte du modèle à son déploiement.
Comprendre le mécanisme de distribution est très utile, mais quels modèles pouvez-vous réellement utiliser ? Permettez-moi de vous présenter les fonctionnalités disponibles dès l'installation et comment en découvrir davantage.
Docker Model Runner propose une sélection de modèles prêts à l'emploi. SmolLM2 est un choix populaire, idéal pour les assistants de chat, l'extraction de texte, la réécriture et les tâches de synthèse, avec 360 millions de paramètres. J'ai trouvé ce modèle particulièrement utile pour le développement et les tests en raison de sa petite taille et de sa rapidité d'inférence.
Pour découvrir d'autres modèles, je vous recommande de commencer par consulter le catalogue de modèles d'IA de Docker Hub. Veuillez consulter les modèles disponibles, vérifier leur documentation pour connaître les tâches prises en charge et la configuration matérielle requise, puis les récupérer à l'aide d'une simple commande docker model pull.
Les modèles sont extraits de Docker Hub lors de leur première utilisation et sont stockés localement. Ils ne sont chargés en mémoire qu'au moment de l'exécution, lorsqu'une requête est effectuée, et sont déchargés lorsqu'ils ne sont pas utilisés afin d'optimiser les ressources.
Cette approche permet à votre système de rester réactif même lorsque vous avez téléchargé plusieurs modèles. Vous n'êtes pas obligé de tout conserver simultanément dans la mémoire vive.
Chaque fiche modèle contient des informations sur les niveaux de quantification (comme Q4_0 et Q8_0), qui ont une incidence sur la taille du modèle et la qualité de l'inférence.
|
Niveau de quantification |
Description |
Taille du fichier |
Qualité |
Idéal pour |
|
Q8_0 |
quantification 8 bits |
Le plus grand |
Qualité supérieure |
Utilisation en production, tâches où la précision est essentielle |
|
Q5_0 |
quantification à 5 bits |
Moyen |
Bon équilibre |
Performances équilibrées à usage général |
|
Q4_0 |
quantification 4 bits |
Le plus petit |
Acceptable |
Environnements de développement, de test et à ressources limitées |
Quantification du modèle
Une considération importante est la gestion des versions du modèle. Vous pouvez spécifier des versions exactes à l'aide de balises (telles que Q4_0 ou latest), de manière similaire aux images Docker. Cela garantit des déploiements reproductibles et empêche les modifications inattendues lors de la mise à jour des modèles.
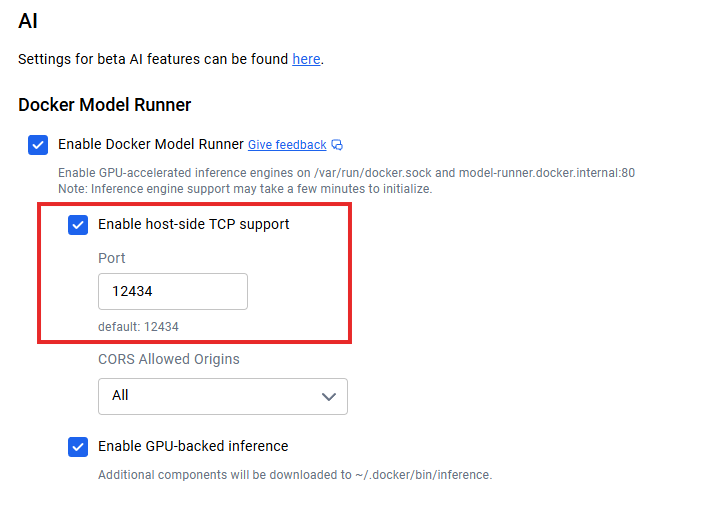
Une fois que les modèles fonctionnent localement, la question suivante se pose : comment connecter mes applications ? Lorsque la prise en charge TCP côté hôte est activée (par exemple, via les paramètres TCP de Docker Desktop), le point de terminaison API par défaut s'exécute sur localhost:12434, exposant les points de terminaison compatibles avec OpenAI.
Intégration de l'API Docker Model Runner
Voici un exemple simple pour effectuer une requête :
curl http://localhost:12434/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/smollm2",
"messages": [{"role": "user", "content": "Explain containerization"}],
"stream": false
}'Pour les architectures microservices, vos conteneurs d'application peuvent communiquer avec le service de modèle à l'aide de protocoles HTTP standard, sans nécessiter de SDK spécifiques. Le streaming de réponse est pris en charge pour les applications en temps réel en définissant "stream": true.
La documentation de l'API REST fournit des spécifications complètes des points de terminaison, des options de paramètres et des schémas de réponse. Je vous recommande de consulter la documentation officielle de Docker pour obtenir les informations les plus récentes sur l'API, car la plateforme continue d'évoluer rapidement.
Pour obtenir des performances optimales avec Docker Model Runner, il est nécessaire de comprendre plusieurs stratégies clés. Permettez-moi de partager ce que j'ai appris en travaillant avec des déploiements de modèles locaux.
En fonctionnant comme un processus au niveau hôte avec un accès direct au GPU, Model Runner offre une meilleure optimisation des performances que les solutions conteneurisées. Cette décision architecturale est avantageuse en termes de débit et de latence, mais il est nécessaire de procéder à des réglages appropriés pour en tirer le meilleur parti.
L'accélération matérielle constitue votre premier levier d'optimisation. L'activation de la prise en charge du GPU permet généralement d'améliorer les performances de 2 à 3 fois par rapport à l'inférence sur CPU uniquement. Au-delà du matériel, la quantification du modèle constitue votre deuxième paramètre principal. Je commence généralement par Q8_0 pour une qualité optimale, puis je passe à Q5_0 ou Q4_0 si j'ai besoin de meilleures performances.
Le point de terminaison des métriques intégré à l'adresse /metrics permet la surveillance avec Prometheus ou votre pile de surveillance existante. Pour la mise à l'échelle, veuillez configurer la longueur du contexte en fonction des besoins réels plutôt que d'utiliser les valeurs maximales. Si votre application ne nécessite que 2048 jetons de contexte, veuillez éviter de configurer 8192.
L'un des principaux avantages de Docker Model Runner réside dans son intégration à l'écosystème Docker au sens large.
Docker Model Runner prend en charge Docker Compose. Cela signifie que vous pouvez définir des applications multiservices où un service est un modèle d'IA, en gérant l'ensemble de la pile à l'aide de fichiers Docker Compose familiers. Voici à quoi cela ressemble :
services:
app:
image: my-app:latest
models:
- llm
- embedding
models:
llm:
model: ai/smollm2
embedding:
model: ai/embeddinggemmaVous pouvez également automatiser les workflows CI/CD : lancez des modèles dans votre environnement de test, effectuez des tests d'intégration et supprimez tout, le tout dans votre infrastructure de pipeline existante. Cela élimine le problème « cela fonctionne sur mon ordinateur » pour les fonctionnalités d'IA.
Une autre intégration intéressante est Docker Offload, qui étend votre flux de travail local vers le cloud lorsque cela est nécessaire. Bien qu'il s'agisse encore d'une fonctionnalité bêta, elle vous permet de développer localement avec Docker Model Runner, puis de transférer les inférences gourmandes en ressources vers l'infrastructure cloud lorsque les exigences dépassent la capacité locale.
Déchargement Docker
La prise en charge de l'exécution dans Kubernetes est également disponible sous forme de graphique Helm et de fichier YAML statique. Cela ouvre des possibilités pour des déploiements à l'échelle de la production où vous avez besoin d'une évolutivité horizontale, d'un équilibrage de charge et d'une haute disponibilité.
Bien qu'elle soit encore au stade expérimental, l'intégration de Kubernetes représente l'évolution de Docker Model Runner vers des déploiements de niveau entreprise, où vous traitez des milliers de requêtes par seconde sur plusieurs répliques.
Avec toutes ces options d'intégration, vous vous demandez peut-être : mais est-ce sécurisé? Docker Model Runner fonctionne dans un environnement isolé et contrôlé, offrant un bac à sable pour la sécurité. Cet isolement empêche les modèles d'accéder à des ressources système sensibles au-delà de ce qui est explicitement fourni.
Le principal avantage en matière de sécurité est la confidentialité des données. Vos demandes d'inférence ne quittent jamais votre infrastructure, ce qui élimine les risques d'exfiltration de données. Pour les organisations qui traitent des données sensibles, ce modèle d'exécution local est essentiel pour se conformer au RGPD, à la loi HIPAA et à d'autres réglementations en matière de confidentialité.
Les administrateurs peuvent configurer la prise en charge TCP côté hôte et CORS pour un contrôle de sécurité précis. Les métadonnées relatives aux licences de modèles dans les registres permettent le suivi de la conformité et la création de pistes d'audit pour la gouvernance d'entreprise.
À ce stade, vous vous demandez peut-être : comment cet outil se compare-t-il à ceux que j'utilise déjà ? Voici une comparaison entre Docker Model Runner, Ollama et NVIDIA NIM :
|
Caractéristique |
Modèle de coureur Docker |
Ollama |
NVIDIA NIM |
|
Performance |
1,00 à 1,12 fois plus rapide qu'Ollama |
Performance de référence |
Optimisé pour les processeurs graphiques NVIDIA |
|
Intégration de l'écosystème |
Workflow Docker natif, artefacts OCI |
Outil autonome, flux de travail distinct |
Conteneurisé, spécifique à NVIDIA |
|
Personnalisation du modèle |
Modèles pré-packagés de Docker Hub |
Fichiers de modèles personnalisés, importation GGUF/Safetensors |
Modèles optimisés par NVIDIA uniquement |
|
Assistance pour la plateforme |
macOS, Windows, Linux |
macOS, Windows, Linux, Docker |
Linux avec les GPU NVIDIA uniquement |
|
Configuration matérielle requise |
Tout GPU (Metal, CUDA, Vulkan) ou CPU |
Tout GPU ou CPU |
Cartes graphiques NVIDIA requises |
|
Communauté et SDK |
Croissance et concentration sur l'écosystème Docker |
Mature, approfondi |
Écosystème NVIDIA, axé sur les entreprises |
|
Idéal pour |
Équipes disposant d'une infrastructure Docker |
Projets d'IA autonomes, expérimentation rapide |
Déploiements de production axés sur NVIDIA |
Le principal facteur de différenciation de Docker Model Runner réside dans l'intégration de l'écosystème. Il traite les modèles d'IA comme des éléments de premier plan au même titre que les conteneurs, ce qui réduit la prolifération des outils pour les équipes centrées sur Docker.
Ollama offre davantage de possibilités de personnalisation des modèles et une communauté mature avec des SDK complets. NVIDIA NIM offre les meilleures performances pour les GPU NVIDIA, mais ne dispose pas de la flexibilité et de la prise en charge multiplateforme des autres options.
Avant de conclure, abordons la question de ce qui se passe lorsque les choses ne fonctionnent pas.
Cette erreur indique généralement que l'interface CLI Docker ne parvient pas à localiser l'exécutable du plugin.
Cause : Docker ne parvient pas à localiser le plugin dans le répertoire CLI prévu à cet effet.
Solution : Vous devrez probablement créer un lien symbolique (symlink) vers l'exécutable. Veuillez vous reporter à la section relative à l'installation pour connaître les commandes spécifiques.
À l'heure actuelle, l'utilisation de résumés spécifiques pour extraire ou référencer des modèles peut échouer.
Solution de contournement : Veuillez vous référer aux modèles par leur nom de balise (par exemple, model:v1) plutôt que par leur résumé.
Statut : L'équipe d'ingénieurs travaille activement à la mise en place d'une prise en charge adéquate de Digest pour une prochaine version.
Si vos modèles fonctionnent lentement ou n'utilisent pas le GPU, veuillez effectuer les vérifications suivantes :
Vérifier les pilotes : Veuillez vous assurer que les pilotes GPU de votre machine hôte sont à jour.
Vérifier les autorisations : Veuillez vérifier que Docker dispose des autorisations nécessaires pour accéder aux ressources GPU.
Linux (NVIDIA) : Veuillez vous assurer que NVIDIA Container Runtime est correctement installé et configuré.
Vérification : Veuillez exécuter la commande suivante pour vérifier que le GPU est détecté par le système : nvidia-smi
Si vous rencontrez un problème qui n'est pas mentionné ici :
Signaler un problème : Veuillez signaler les bogues ou demander des fonctionnalités sur le dépôt GitHub officiel.
Communauté : Il existe une communauté active qui fournit souvent des solutions rapides pour les cas particuliers.
Docker Model Runner représente une avancée significative dans la démocratisation du développement de l'IA. En intégrant la gestion des modèles dans l'écosystème Docker, cela élimine les obstacles qui ont historiquement ralenti l'adoption de l'IA.
L'importance stratégique va au-delà de la commodité. À une époque où la confidentialité des données, le contrôle des coûts et la rapidité de développement sont plus importants que jamais, l'exécution locale de l'IA devient de plus en plus cruciale. Docker Model Runner facilite l'expérimentation et la création d'applications d'IA à l'aide des mêmes commandes et workflows Docker que les développeurs utilisent déjà quotidiennement.
À l'avenir, la plateforme continuera d'évoluer avec la prise en charge de bibliothèques d'inférence supplémentaires, d'options de configuration avancées et de capacités de déploiement distribué. La convergence entre la conteneurisation et l'IA représente l'orientation future du secteur, et Docker Model Runner se positionne à cette intersection, permettant ainsi à des millions de développeurs utilisant déjà Docker de bénéficier d'un développement IA rentable et axé sur la confidentialité.
Maintenant que vos modèles fonctionnent dans votre environnement Docker local, l'étape suivante consiste à créer un pipeline fiable autour d'eux. Maîtrisez les principes de gestion des versions, du déploiement et du cycle de vie des modèles grâce au cursus MLOps Fundamentals sur DataCamp.
Cours sur Docker
Cursus
Cursus
Cours