

Programa
MLOps Fundamentals
14 h
À medida que a IA generativa continua a transformar o desenvolvimento de software, percebi um desafio persistente: executar modelos de IA localmente continua sendo mais complexo do que deveria ser.
Os desenvolvedores enfrentam ferramentas fragmentadas, problemas de compatibilidade de hardware e fluxos de trabalho que parecem desconectados do seu ambiente de desenvolvimento diário. O Docker Model Runner foi lançado em abril de 2025 para resolver esses desafios, facilitando a execução e o teste de modelos de IA localmente dentro dos fluxos de trabalho existentes do Docker.
O Docker Model Runner representa uma mudança da IA baseada em nuvem para fluxos de trabalho locais e em contêineres, oferecendo benefícios como privacidade de dados, redução de custos e iteração mais rápida, tudo isso enquanto está integrado ao ecossistema Docker. Pela minha experiência com implementações de IA, essas vantagens são essenciais para equipes que estão criando aplicativos prontos para produção, mantendo o controle sobre dados confidenciais.
Se você é novo no Docker, recomendo fazer este curso introdutório sobre o Docker.
O modelo tradicional de IA apresenta vários desafios que eu mesmo já enfrentei.
Os modelos de IA têm pesos matemáticos que não se beneficiam da compactação, diferente das imagens tradicionais do Docker. Isso cria ineficiências de armazenamento quando os modelos são empacotados com seu tempo de execução. Além disso, configurar mecanismos de inferência, gerenciar a aceleração de hardware e manter ferramentas separadas para modelos e contêineres de aplicativos cria uma complexidade desnecessária.
É exatamente aí que entra o Docker Model Runner. Em vez de adicionar mais uma ferramenta ao seu conjunto, ele facilita a extração, execução e distribuição de Modelos de Linguagem Grandes (LLMs) diretamente do Docker Hub em um formato compatível com OCI (Open Container Initiative) ou do Hugging Face, se os modelos estiverem disponíveis no formato GPT-Generated Unified Format.no formato unificado gerado por GPT (GGUF). A plataforma resolve o problema da fragmentação, trazendo o gerenciamento de modelos para o mesmo fluxo de trabalho que os desenvolvedores usam para contêineres.
O contexto histórico aqui é importante. Com a adoção acelerada da IA generativa, o setor viu uma tendência crescente em direção a fluxos de trabalho de IA seguros e com prioridade local. As organizações ficaram cada vez mais preocupadas com a privacidade dos dados, os custos das APIs e a dependência de fornecedores associada aos serviços de IA baseados na nuvem.
A Docker fez parceria com nomes influentes em IA e desenvolvimento de software, incluindo Google, Continue, Dagger, Qualcomm Technologies, Hugging Face, Spring AI e VMware Tanzu AI Solutions, reconhecendo que os desenvolvedores precisavam de uma maneira melhor de trabalhar com modelos de IA localmente, sem abrir mão das conveniências das práticas modernas de desenvolvimento.
Antes de mergulhar no Docker Model Runner, deixa eu te mostrar os requisitos de sistema que você vai precisar. A boa notícia é que, se você já usa o Docker, já está com metade do caminho andado. O Docker Model Runner já está disponível e funciona em todas as versões do Docker, com suporte para as plataformas macOS, Windows e Linux.
Embora o Docker Model Runner tenha sido lançado só no Docker Desktop, a partir de dezembro de 2025, ele funciona com qualquer plataforma que suporte o Docker Engine.
Aqui está o que você vai precisar nas diferentes plataformas:
|
Componente |
Requisito |
Notas |
|
Sistema Operacional |
macOS, Windows, Linux |
Todas as principais plataformas são compatíveis. |
|
Versão do Docker |
Docker Desktop Motor Docker |
Área de trabalho para macOS/Windows Motor para Linux |
|
RAM |
Mínimo de 8 GB Recomenda-se 16 GB ou mais |
Modelos maiores precisam de mais memória |
|
GPU (opcional) |
Silício da Apple NVIDIA ARM/Qualcomm |
Dá um aumento de 2 a 3 vezes no desempenho |
Requisitos do sistema do Docker Model Runner
Para aceleração por GPU, o Docker Model Runner agora suporta vários back-ends:
Apple Silicon (M1/M2/M3/M4): Usa a API Metal para aceleração da GPU, configurada automaticamente.
NVIDIA GPUs: Precisa do NVIDIA Container Runtime e dá suporte à aceleração CUDA.
ARM/Qualcomm: Aceleração de hardware disponível em dispositivos compatíveis.
Além disso, o Docker Model Runner suporta Vulkan desde outubro de 2025, permitindo a aceleração de hardware em uma gama muito mais ampla de GPUs, incluindo GPUs integradas e aquelas da AMD, Intel e outros fornecedores.
Embora você possa rodar modelos só com uma CPU, o suporte à GPU melhora muito o desempenho da inferência. Estamos falando da diferença entre esperar 10 segundos e 3 segundos por respostas.
Uma observação importante: Algumas recursosdo llama.cpp podem não ser totalmente compatíveis com as GPUs da série 6xx, e o suporte para mecanismos adicionais, como MLX ou vLLM será adicionado no futuro.
É aqui que as coisas ficam realmente interessantes. O design arquitetônico do Docker Model Runner foge da tradicional conteinerização de maneiras que podem te surpreender. Deixa eu explicar como isso realmente funciona nos bastidores.
O Docker Model Runner usa uma abordagem híbrida que junta as capacidades de orquestração do Docker com o desempenho nativo do host para inferência de IA. O que torna essa arquitetura diferente? Isso repensa completamente como a gente lida com as cargas de trabalho de IA.
Diferente dos contêineres Docker padrão, o mecanismo de inferência não roda dentro de um contêiner. Em vez disso, o servidor de inferência usa o llama.cpp como mecanismo, rodando como um processo host nativo que carrega modelos quando você precisa e faz a inferência direto no seu hardware.
Por que isso é importante? Essa escolha de design permite acesso direto à API Metal da Apple para aceleração de GPU e evita a sobrecarga de desempenho da execução de inferência dentro de máquinas virtuais. A separação entre armazenamento e execução do modelo é intencional: os modelos são armazenados separadamente e carregados na memória apenas quando necessário, sendo descarregados após um período de inatividade.
Agora, vamos dar um passo atrás e ver como essas peças se encaixam. Em um nível mais alto, o Docker Model Runner tem três componentes principais: o executador de modelos, as ferramentas de distribuição de modelos e o plug-in CLI de modelos. Essa arquitetura modular permite uma iteração mais rápida e limites de API mais claros entre diferentes questões.
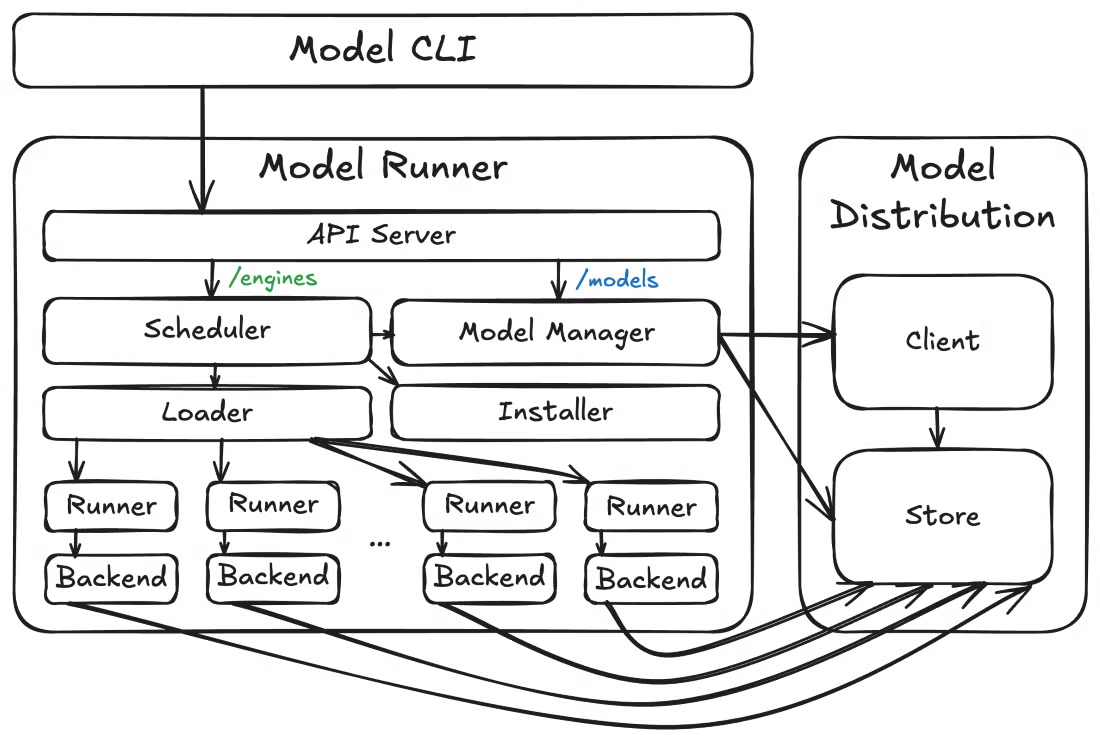
Arquitetura do Docker Model Runner
Além da arquitetura central, o Docker Model Runner também antecipa as necessidades operacionais. O Model Runner mostra os pontos finais das métricas em /metrics, permitindo que você monitore o desempenho do modelo, solicite estatísticas e acompanhe o uso de recursos. Essa observabilidade integrada é essencial para implantações de produção em que você precisa de visibilidade do comportamento do modelo e do consumo de recursos.
Com a arquitetura fazendo sentido, você provavelmente está se perguntando: o que eu posso realmente fazer com isso? Deixa eu te mostrar os recursos que tornaram o Docker Model Runner tão interessante para meus fluxos de trabalho de desenvolvimento de IA.
Aqui vai uma visão geral rápida dos recursos mais legais:
|
Recurso |
Benefício |
Ideal para |
|
Código aberto e gratuito |
Sem custos de licenciamento Total transparência |
Experimentação Aprendizagem Uso em produção |
|
Integração com a CLI do Docker |
Comandos conhecidos (modelo docker pull/run/list) |
Usuários do Docker que não querem aprender novas ferramentas |
|
Embalagem em conformidade com a OCI |
Distribuição do modelo padrão por meio de registros |
Controle de versão Gerenciamento de acesso |
|
Compatibilidade com a API OpenAI |
Substituição direta para APIs na nuvem |
Migração fácil da nuvem para o local |
|
Execução em sandbox |
Ambiente isolado para segurança |
Requisitos de conformidade empresarial |
|
Aceleração por GPU |
Inferência 2 a 3 vezes mais rápida |
Aplicativos em tempo real Alto rendimento |
Recursos principais do Docker Model Runner
A interface de linha de comando se integra perfeitamente aos fluxos de trabalho existentes do Docker. Você vai usar comandos como docker model pull, docker model run e docker model list, seguindo os mesmos padrões que você já conhece do trabalho com contêineres.
A interface gráfica do usuário no Docker Desktop oferece uma integração guiada para ajudar até mesmo desenvolvedores de IA iniciantes a começar a usar modelos sem problemas, com o gerenciamento automático de recursos disponíveis, como RAM e GPU.
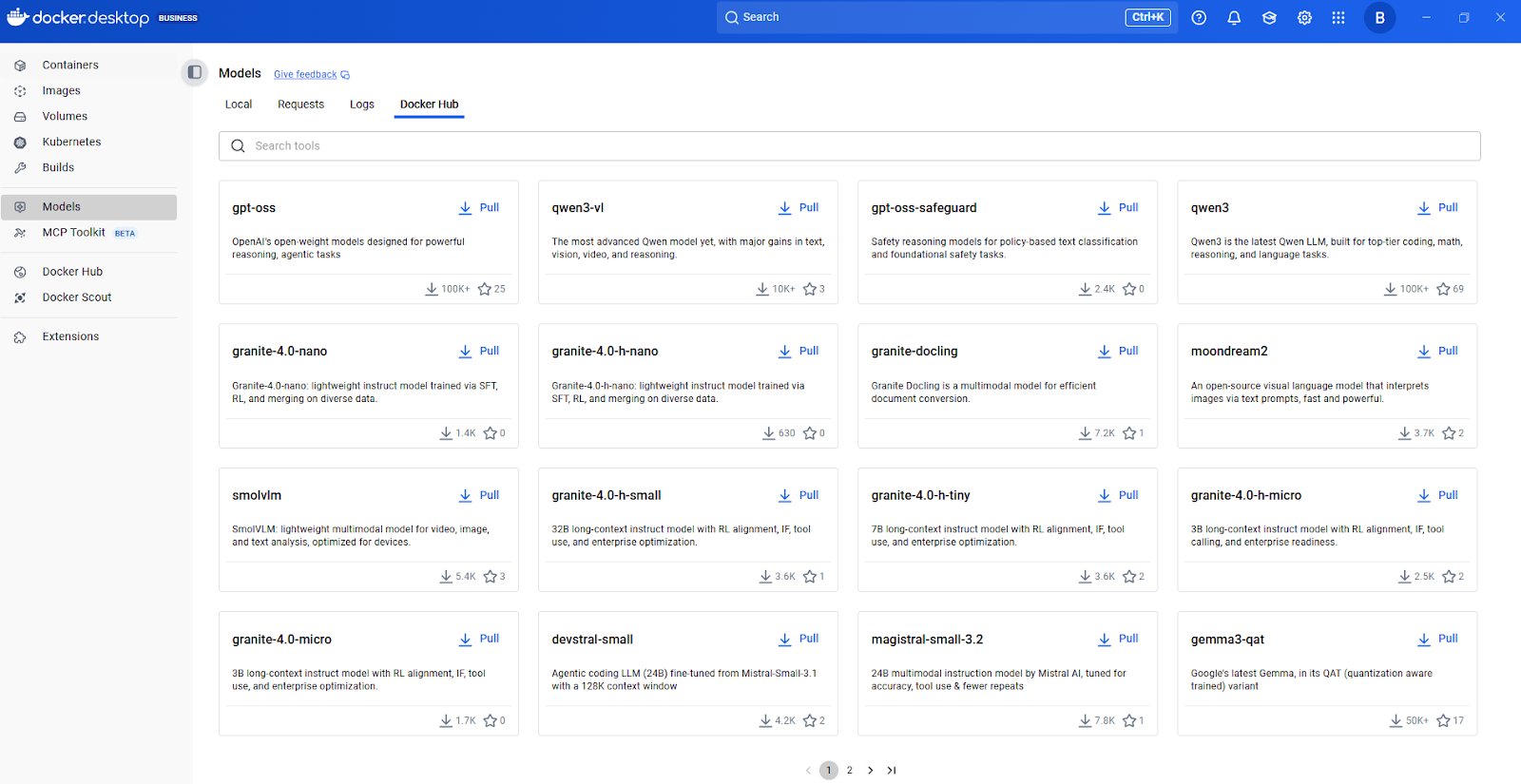
Central de Modelos Docker
Agora, vamos falar sobre como os modelos são empacotados e distribuídos. O Docker Model Runner dá suporte a modelos empacotados em OCI, permitindo que você armazene e distribua modelos por meio de qualquer registro compatível com OCI, incluindo o Docker Hub. Essa abordagem padronizada de empacotamento significa que você pode usar os mesmos padrões de controle de versão, controle de acesso e distribuição usados para imagens de contêiner.
Quando se trata de integrar com aplicativos, os recursos da API REST são super úteis para a integração de aplicativos. O Docker Model Runner inclui um mecanismo de inferência baseado no llama.cpp e acessível através da conhecida API OpenAI.
Essa compatibilidade com a OpenAI significa que o código já escrito para a API da OpenAI pode funcionar com modelos locais com poucas mudanças — basta apontar seu aplicativo para o endpoint local em vez da API na nuvem. Só essa flexibilidade já pode economizar semanas de refatoração.
Deixa eu te ajudar a instalar e configurar o Docker Model Runner no seu sistema. O processo de instalação é simples, mas tem algumas coisas específicas da plataforma que é bom saber antes.
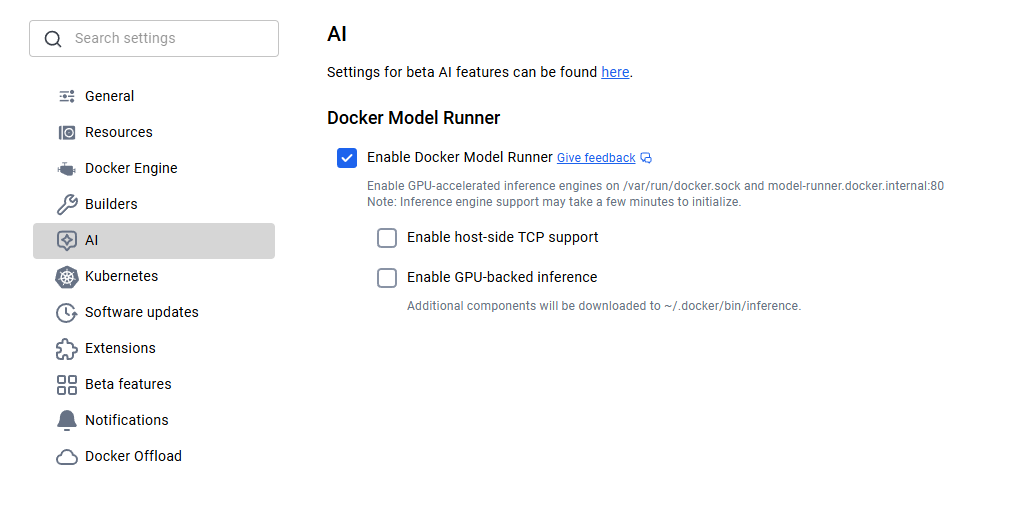
Para quem usa macOS e Windows, o Docker Model Runner já vem junto com o Docker Desktop 4.40 ou mais recente. É só baixar a versão mais recente do site oficial do Docker e instalar. Depois de instalar, você vai precisar ativar o Docker Model Runner nas configurações. Vá até Configurações > IA e escolha a opção Executador de modelo Docker e inferência com back-end de GPU, caso seu computador suporte GPU NVIDIA.
Ativação do Docker Model Runner
Os usuários do Linux têm uma experiência ainda mais simplificada. Atualize seu sistema e instale o plugin Docker Model Runner usando os comandos a seguir.
sudo apt-get update
sudo apt-get install docker-model-pluginDepois de instalar, dá uma olhada se tá funcionando executando docker model version.
Se você estiver usando Apple Silicon, a aceleração da GPU por meio do Metal é configurada automaticamente, sem necessidade de configurações adicionais. Para GPUs NVIDIA, certifique-se de ter o NVIDIA Container Runtime instalado.
Com o suporte ao Vulkan, agora você pode aproveitar a aceleração de hardware em GPUs AMD, Intel e outras que suportam a API Vulkan. O sistema detecta de forma inteligente o seu hardware e aplica a aceleração adequada.
Depois de instalar, baixar um modelo fica bem fácil. Você só precisa puxar o modelo primeiro e depois executá-lo para interagir com ele:
docker model pull ai/smollm2
docker model run ai/smollm2Se tudo estiver configurado corretamente, você deverá ver o modelo na lista:
docker model listMODEL NAME
ai/smollm2Depois de instalar o Docker Model Runner e entender como baixar modelos, a próxima pergunta que surge é: de onde vêm esses modelos e como posso gerenciá-los em escala? É aqui que a abordagem do Docker Model Runner se torna particularmente elegante.
O Docker empacota modelos como artefatos OCI, um padrão aberto que permite a distribuição através dos mesmos registros e fluxos de trabalho usados para contêineres. As equipes que já usam registros privados do Docker podem usar a mesma infraestrutura para modelos de IA. O Docker Hub oferece recursos empresariais, como o Gerenciamento de Acesso ao Registro, para controles de acesso baseados em políticas.
A integração com o Hugging Face merece destaque especial. Os desenvolvedores podem usar o Docker Model Runner como mecanismo de inferência local para executar modelos no Hugging Face e filtrar os modelos compatíveis (é necessário o formato GGUF) diretamente na interface do Hugging Face. Isso facilita bastante a descoberta de modelos.
docker model pull hf.co/bartowski/Llama-3.2-1B-Instruct-GGUFO que é realmente inteligente é como essa integração funciona nos bastidores. Quando você pega um modelo do Hugging Face no formato GGUF, o Docker Model Runner automaticamente o empacota como um artefato OCI na hora. Essa conversão perfeita elimina etapas manuais de empacotamento e acelera o caminho desde a descoberta do modelo até a implantação.
Entender o mecanismo de distribuição é ótimo, mas quais modelos você pode realmente executar? Vou te mostrar o que já vem pronto pra usar e como encontrar mais.
O Docker Model Runner tem uma seleção de modelos prontos pra usar na hora. O SmolLM2 é uma escolha popular, ideal para assistentes de chat, extração de texto, reescrita e tarefas de resumo, com 360 milhões de parâmetros. Achei esse modelo bem útil para desenvolvimento e testes por ser pequeno e rápido.
Pra achar mais modelos, recomendo começar pelo catálogo de modelos de IA do Docker Hub. Dá uma olhada nos modelos disponíveis, vê a documentação deles pra saber quais tarefas são compatíveis e quais são os requisitos de hardware, e depois pega eles com um comando simples do docker model pull.
Os modelos são obtidos do Docker Hub na primeira vez que você os usa e são armazenados localmente, sendo carregados na memória apenas em tempo de execução quando uma solicitação é feita e descarregados quando não estão em uso para otimizar os recursos.
Essa abordagem mantém seu sistema ágil mesmo quando você tem vários modelos baixados. Você não precisa manter tudo na RAM ao mesmo tempo.
Cada lista de modelos inclui informações sobre os níveis de quantização (como Q4_0, Q8_0), que afetam o tamanho do modelo e a qualidade da inferência.
|
Nível de quantização |
Descrição |
Tamanho do arquivo |
Qualidade |
Ideal para |
|
Q8_0 |
quantização de 8 bits |
Maior |
Qualidade máxima |
Uso em produção, tarefas que exigem muita precisão |
|
Q5_0 |
quantização de 5 bits |
Médio |
Bom equilíbrio |
Desempenho equilibrado para uso geral |
|
Q4_0 |
quantização de 4 bits |
Menor |
Aceitável |
Desenvolvimento, testes, ambientes com recursos limitados |
Quantização do modelo
Uma coisa importante a se pensar é a versão do modelo. Você pode especificar versões exatas usando tags (como Q4_0 ou latest), parecido com as imagens do Docker. Isso garante implantações reproduzíveis e evita alterações inesperadas quando os modelos são atualizados.
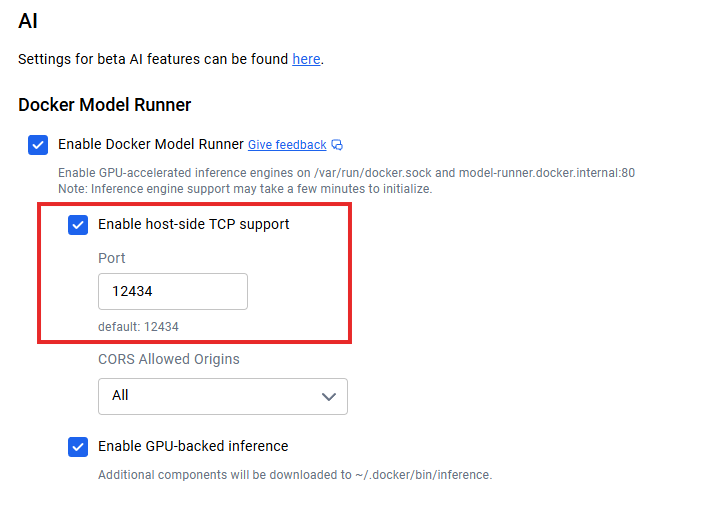
Depois de ter os modelos funcionando localmente, a questão passa a ser: como conectar meus aplicativos? Quando o suporte TCP do lado do host está ativado (por exemplo, através das configurações TCP do Docker Desktop), o endpoint padrão da API é executado em localhost:12434, expondo endpoints compatíveis com OpenAI.
Integração da API do Docker Model Runner
Aqui vai um exemplo simples de como fazer uma solicitação:
curl http://localhost:12434/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/smollm2",
"messages": [{"role": "user", "content": "Explain containerization"}],
"stream": false
}'Para arquiteturas de microsserviços, seus contêineres de aplicativos podem se comunicar com o serviço de modelo usando protocolos HTTP padrão, sem a necessidade de SDKs especiais. O streaming de resposta é compatível com aplicativos em tempo real ao definir "stream": true.
A documentação da API REST traz todas as especificações dos pontos finais, opções de parâmetros e esquemas de resposta. Recomendo consultar a documentação oficial do Docker para obter os detalhes mais recentes sobre a API, já que a plataforma continua evoluindo rapidamente.
Pra conseguir o melhor desempenho do Docker Model Runner, é preciso entender várias estratégias importantes. Deixa eu compartilhar o que aprendi trabalhando com implantações de modelos locais.
Ao rodar como um processo no nível do host com acesso direto à GPU, o Model Runner consegue uma otimização de desempenho melhor do que as soluções em contêineres. Essa escolha arquitetônica traz vantagens em termos de rendimento e latência, mas você ainda precisa ajustar tudo direitinho pra aproveitar ao máximo.
A aceleração de hardware é a sua primeira alavanca de otimização. A ativação do suporte a GPU normalmente proporciona melhorias de desempenho de 2 a 3 vezes em relação à inferência apenas com CPU. Além do hardware, a quantização do modelo é o seu segundo recurso importante. Normalmente, começo com Q8_0 para obter a melhor qualidade e, depois, passo para Q5_0 ou Q4_0 se precisar de um desempenho melhor.
O endpoint de métricas integrado em /metrics permite o monitoramento com o Prometheus ou sua pilha de monitoramento existente. Para dimensionamento, configure o comprimento do contexto com base nas necessidades reais, em vez de usar valores máximos. Se o seu aplicativo só precisa de 2048 tokens de contexto, não configure para 8192.
Uma das maiores vantagens do Docker Model Runner é como ele se integra ao ecossistema mais amplo do Docker.
O Docker Model Runner dá suporte ao Docker Compose. Isso quer dizer que você pode criar aplicativos com vários serviços, onde um deles é um modelo de IA, gerenciando tudo com os arquivos Docker Compose que você já conhece. Veja como fica:
services:
app:
image: my-app:latest
models:
- llm
- embedding
models:
llm:
model: ai/smollm2
embedding:
model: ai/embeddinggemmaVocê também pode automatizar fluxos de trabalho de CI/CD: crie modelos em seu ambiente de teste, execute testes de integração neles e desmonte tudo, tudo isso dentro de sua infraestrutura de pipeline existente. Isso acaba com o problema do “funciona no meu computador” para recursos de IA.
Outra integração interessante é o Docker Offload, que leva seu fluxo de trabalho local para a nuvem quando você precisar. Mesmo sendo ainda uma funcionalidade Beta, ela permite que você desenvolva localmente com o Docker Model Runner e, depois, transfira a inferência que consome muitos recursos para a infraestrutura em nuvem quando os requisitos ultrapassarem a capacidade local.
Descarregamento do Docker
O suporte para execução no Kubernetes também está disponível como um gráfico Helm e um arquivo YAML estático. Isso abre possibilidades para implantações em escala de produção onde você precisa de escalabilidade horizontal, balanceamento de carga e alta disponibilidade.
Embora ainda esteja em fase experimental, a integração com o Kubernetes mostra como o Docker Model Runner está evoluindo para implantações de nível empresarial, onde você atende milhares de solicitações por segundo em várias réplicas.
Com todas essas opções de integração, você pode se perguntar: mas isso é seguro? O Docker Model Runner rola num ambiente isolado e controlado, oferecendo sandboxing pra segurança. Esse isolamento impede que os modelos acessem recursos confidenciais do sistema além do que é explicitamente fornecido.
A principal vantagem em termos de segurança é a privacidade dos dados. Suas solicitações de inferência nunca saem da sua infraestrutura, eliminando os riscos de exfiltração de dados. Para organizações que lidam com dados confidenciais, esse modelo de execução local é essencial para a conformidade com o GDPR, HIPAA e outras regulamentações de privacidade.
Os administradores podem configurar o suporte TCP do lado do host e CORS para um controle de segurança mais detalhado. Os metadados de licenciamento de modelos nos registros permitem o acompanhamento da conformidade e trilhas de auditoria para a governança empresarial.
A essa altura, você deve estar pensando: como isso se compara às ferramentas que já uso? Veja como o Docker Model Runner se compara ao Ollama e ao NVIDIA NIM:
|
Recurso |
Executor de modelo Docker |
Ollama |
NVIDIA NIM |
|
Desempenho |
1,00-1,12x mais rápido que o Ollama |
Desempenho de referência |
Altamente otimizado para GPUs NVIDIA |
|
Integração do ecossistema |
Fluxo de trabalho nativo do Docker, artefatos OCI |
Ferramenta independente, fluxo de trabalho separado |
Em contêiner, específico para NVIDIA |
|
Personalização do modelo |
Modelos pré-configurados do Docker Hub |
Arquivos de modelos personalizados, importação GGUF/Safetensors |
Apenas modelos otimizados pela NVIDIA |
|
Suporte à plataforma |
macOS, Windows, Linux |
macOS, Windows, Linux, Docker |
Linux apenas com GPUs NVIDIA |
|
Requisitos de hardware |
Qualquer GPU (Metal, CUDA, Vulkan) ou CPU |
Qualquer GPU ou CPU |
É preciso ter GPUs NVIDIA |
|
Comunidade e SDKs |
Crescimento, foco no ecossistema Docker |
Maduro, extenso |
Ecossistema NVIDIA, focado nas empresas |
|
Ideal para |
Equipes com infraestrutura Docker |
Projetos de IA independentes, experimentação rápida |
Implementações de produção focadas na NVIDIA |
O principal diferencial do Docker Model Runner é a integração com o ecossistema. Ele trata os modelos de IA como cidadãos de primeira classe, junto com os contêineres, reduzindo a proliferação de ferramentas para equipes centradas no Docker.
O Ollama oferece mais personalização de modelos e uma comunidade madura com SDKs bem completos. O NVIDIA NIM oferece o melhor desempenho para GPUs NVIDIA, mas não tem a flexibilidade e o suporte multiplataforma das outras opções.
Antes de encerrarmos, vamos falar sobre o que acontece quando as coisas não dão certo.
Esse erro geralmente quer dizer que a CLI do Docker não consegue achar o executável do plugin.
Causa: O Docker não consegue encontrar o plugin no diretório de plugins CLI esperado.
Solução: Você provavelmente vai precisar criar um link simbólico (symlink) para o executável. Dá uma olhada na seção de instalação pra ver os comandos específicos.
Atualmente, usar resumos específicos para extrair ou referenciar modelos pode falhar.
Solução alternativa: Use o nome da tag dos modelos (por exemplo, model:v1) em vez do resumo deles.
Status: A equipe de engenharia está trabalhando ativamente no suporte adequado ao digest para uma versão futura.
Se seus modelos estiverem funcionando devagar ou não estiverem usando a GPU, dá uma olhada nessas verificações:
Verificar drivers: Verifique se os drivers da GPU da sua máquina host estão atualizados.
Verifique as permissões: Confirme emque o Docker tem permissão para acessar os recursos da GPU.
Linux (NVIDIA): Verifique se o NVIDIA Container Runtime está instalado e configurado.
Verificação: Execute o seguinte comando para confirmar se a GPU está visível para o sistema: nvidia-smi
Se você tiver algum problema que não tá listado aqui:
Relate um problema: Relate bugs ou peça recursos no repositório oficial do GitHub.
Comunidade: Tem uma galera ativa que sempre dá um jeito rápido pra resolver casos complicados.
O Docker Model Runner é um grande passo pra tornar o desenvolvimento de IA mais acessível. Ao trazer o gerenciamento de modelos para o ecossistema Docker, elimina-se o atrito que historicamente retardou a adoção da IA.
A importância estratégica vai além da conveniência. Numa época em que a privacidade dos dados, o controle de custos e a velocidade de desenvolvimento são mais importantes do que nunca, a execução local da IA se torna cada vez mais crítica. O Docker Model Runner facilita a experimentação e a criação de aplicativos de IA usando os mesmos comandos e fluxos de trabalho do Docker que os desenvolvedores já usam no dia a dia.
Olhando para o futuro, a plataforma continua evoluindo com suporte para bibliotecas de inferência adicionais, opções de configuração avançadas e recursos de implantação distribuída. A combinação de contêineres e IA mostra para onde a indústria está indo, e o Docker Model Runner está bem no meio disso, tornando o desenvolvimento de IA focado em privacidade e econômico uma realidade para milhões de desenvolvedores que já usam o Docker.
Agora que você tem modelos rodando no seu ambiente Docker local, o próximo passo é criar um pipeline confiável em torno deles. Domine os princípios de controle de versão de modelos, implantação e gerenciamento do ciclo de vida com o MLOps Fundamentals Skill Program no DataCamp.
Cursos sobre Docker
Programa
Programa
Curso
blog
Abid Ali Awan
8 min
blog
Stanislav Karzhev
9 min
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer
Tutorial
Moez Ali

