

programa
Fundamentos de MLOps
14 h
A medida que la IA generativa sigue transformando el desarrollo de software, he observado un reto persistente: ejecutar modelos de IA localmente sigue siendo más complejo de lo que debería ser.
Los programadores se enfrentan a herramientas fragmentadas, problemas de compatibilidad de hardware y flujos de trabajo que parecen desconectados de vuestro entorno de desarrollo cotidiano. Docker Model Runner se lanzó en abril de 2025 para abordar estos retos, facilitando la ejecución y prueba de modelos de IA a nivel local dentro de los flujos de trabajo existentes de Docker.
Docker Model Runner representa un cambio de la IA basada en la nube a flujos de trabajo locales y contenedorizados, lo que ofrece ventajas como la privacidad de los datos, la reducción de costes y una iteración más rápida, todo ello integrado en el ecosistema Docker. Según mi experiencia trabajando con implementaciones de IA, estas ventajas son fundamentales para los equipos que crean aplicaciones listas para la producción y, al mismo tiempo, mantienen el control sobre los datos confidenciales.
Si eres nuevo en Docker, te recomiendo que realices este curso introductorio sobre Docker.
El modelo tradicional de IA presenta varios retos con los que me he encontrado personalmente.
Los modelos de IA contienen pesos matemáticos que no se benefician de la compresión, a diferencia de las imágenes tradicionales de Docker. Esto genera ineficiencias de almacenamiento cuando los modelos se empaquetan con su tiempo de ejecución. Además, configurar motores de inferencia, gestionar la aceleración por hardware y mantener herramientas separadas para los modelos y los contenedores de aplicaciones crea una complejidad innecesaria.
Aquí es precisamente donde entra en juego Docker Model Runner. En lugar de añadir otra herramienta más a tu pila, facilita la extracción, ejecución y distribución de modelos de lenguaje grandes (LLM) directamente desde Docker Hub en un formato compatible con OCI (Open Container Initiative) o desde Hugging Face si los modelos están disponibles en formato unificado generado por GPT.en formato unificado generado por GPT (GGUF). La plataforma aborda el problema de la fragmentación al incorporar la gestión de modelos en el mismo flujo de trabajo que los programadores utilizan para los contenedores.
El contexto histórico es importante en este caso. A medida que se aceleraba la adopción de la IA generativa, la industria fue testigo de una tendencia creciente hacia flujos de trabajo de IA seguros y con prioridad local. Las organizaciones se mostraron cada vez más preocupadas por la privacidad de los datos, los costes de las API y la dependencia de un único proveedor asociada a los servicios de IA basados en la nube.
Docker se asoció con nombres influyentes en el campo de la IA y el desarrollo de software, entre los que se incluyen Google, Continue, Dagger, Qualcomm Technologies, Hugging Face, Spring AI y VMware Tanzu AI Solutions, al reconocer que los programadores necesitaban una forma mejor de trabajar con modelos de IA a nivel local sin sacrificar las comodidades de las prácticas de desarrollo modernas.
Antes de profundizar en Docker Model Runner, permíteme explicarte los requisitos del sistema que necesitarás. La buena noticia es que, si ya utilizas Docker, ya tienes medio camino recorrido. Docker Model Runner ya está disponible y funciona en todas las versiones de Docker, siendo compatible con las plataformas macOS, Windows y Linux.
Aunque Docker Model Runner se lanzó exclusivamente en Docker Desktop, desde diciembre de 2025 es compatible con cualquier plataforma que admita Docker Engine.
Esto es lo que necesitarás en las diferentes plataformas:
|
Componente |
Requisito |
Notas |
|
Sistema operativo |
macOS, Windows, Linux |
Se admiten todas las plataformas principales. |
|
Versión de Docker |
Docker Desktop Motor Docker |
Escritorio para macOS/Windows Motor para Linux |
|
RAM |
8 GB como mínimo Se recomiendan 16 GB o más. |
Los modelos más grandes necesitan más memoria. |
|
GPU (opcional) |
Silicio de Apple NVIDIA ARM/Qualcomm |
Proporciona un aumento del rendimiento de 2 a 3 veces. |
Requisitos del sistema del modelo Docker Runner
Para la aceleración de GPU, Docker Model Runner ahora admite múltiples backends:
Apple Silicon (M1/M2/M3/M4): Utiliza la API Metal para la aceleración de la GPU, configurada automáticamente.
NVIDIA GPUs: Requiere NVIDIA Container Runtime, compatible con aceleración CUDA.
ARM/Qualcomm: Aceleración por hardware disponible en dispositivos compatibles.
Además, Docker Model Runner es compatible con Vulkan desde octubre de 2025, lo que permite la aceleración por hardware en una gama mucho más amplia de GPU, incluidas las GPU integradas y las de AMD, Intel y otros proveedores.
Aunque puedes ejecutar modelos solo con una CPU, la compatibilidad con GPU mejora considerablemente el rendimiento de la inferencia. Estamos hablando de la diferencia entre esperar 10 segundos frente a 3 segundos para obtener respuestas.
Una nota importante: Algunas las funcionesde llama.cpp podrían no ser totalmente compatibles con las GPU de la serie 6xx, y la compatibilidad con motores adicionales como MLX o vLLM se añadirá en el futuro.
Aquí es donde las cosas se ponen realmente interesantes. El diseño arquitectónico de Docker Model Runner rompe con la contenedorización tradicional de formas que pueden sorprenderte. Déjame explicarte cómo funciona realmente por dentro.
Docker Model Runner implementa un enfoque híbrido que combina las capacidades de orquestación de Docker con el rendimiento nativo del host para la inferencia de IA. ¿Qué hace que esta arquitectura sea distintiva? Replantea de forma fundamental la forma en que gestionamos las cargas de trabajo de IA.
A diferencia de los contenedores Docker estándar, el motor de inferencia no se ejecuta realmente dentro de un contenedor. En su lugar, el servidor de inferencia utiliza llama.cpp como motor, que se ejecuta como un proceso host nativo que carga modelos bajo demanda y realiza la inferencia directamente en tu hardware.
¿Por qué es importante esto? Esta elección de diseño permite el acceso directo a la API Metal de Apple para la aceleración de la GPU y evita la sobrecarga de rendimiento que supone ejecutar la inferencia dentro de máquinas virtuales. La separación entre el almacenamiento y la ejecución de los modelos es intencionada: los modelos se almacenan por separado y se cargan en la memoria solo cuando es necesario, y luego se descargan tras un periodo de inactividad.
Ahora, alejémonos un poco y veamos cómo encajan estas piezas. A un nivel superior, Docker Model Runner consta de tres componentes de alto nivel: el ejecutor de modelos, las herramientas de distribución de modelos y el complemento CLI de modelos. Esta arquitectura modular permite una iteración más rápida y límites de API más claros entre diferentes aspectos.
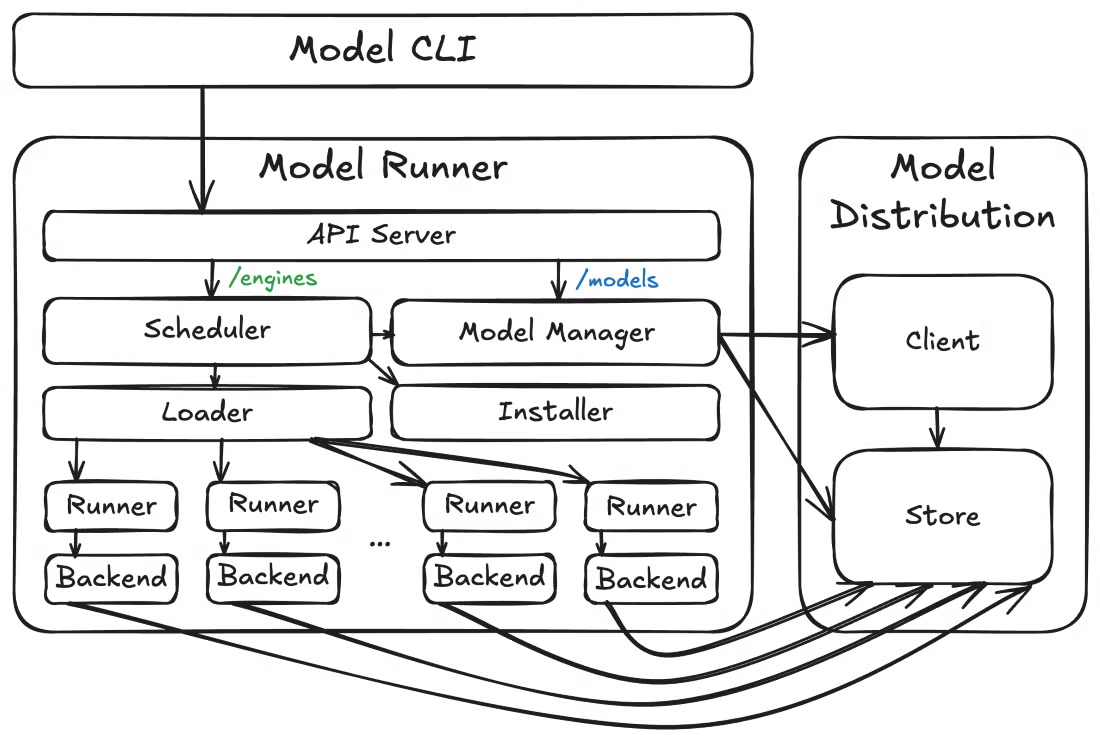
Arquitectura del modelo Docker Runner
Más allá de la arquitectura central, Docker Model Runner también anticipa las necesidades operativas. Model Runner expone puntos finales de métricas en /metrics, lo que te permite supervisar el rendimiento del modelo, solicitar estadísticas y realizar un seguimiento del uso de recursos. Esta observabilidad integrada es fundamental para las implementaciones de producción en las que necesitas visibilidad del comportamiento del modelo y el consumo de recursos.
Ahora que la arquitectura tiene sentido, probablemente te preguntes: ¿qué puedo hacer realmente con esto? Permíteme explicarte las características que han hecho que Docker Model Runner resulte tan atractivo para mis flujos de trabajo de desarrollo de IA.
A continuación, se ofrece una breve descripción general de las funciones más destacadas:
|
Característica |
Beneficio |
Ideal para |
|
Código abierto y gratuito |
Sin costes de licencia Transparencia total |
Experimentación Aprendizaje Uso en producción |
|
Integración de la CLI de Docker |
Comandos familiares (modelo docker pull/run/list) |
Usuarios de Docker que no quieren aprender a utilizar nuevas herramientas. |
|
Embalaje conforme con la normativa OCI |
Distribución del modelo estándar a través de registros |
Control de versiones Gestión de accesos |
|
Compatibilidad con la API de OpenAI |
Sustitución directa de las API en la nube |
Fácil migración de la nube al entorno local |
|
Ejecución en entorno aislado |
Entorno aislado por motivos de seguridad |
Requisitos de cumplimiento empresarial |
|
Aceleración por GPU |
Inferencia 2-3 veces más rápida |
Aplicaciones en tiempo real Alto rendimiento |
Características principales de Docker Model Runner
La interfaz de línea de comandos se integra perfectamente con los flujos de trabajo existentes de Docker. Utilizarás comandos como docker model pull, docker model run y docker model list, siguiendo los mismos patrones que ya conoces por trabajar con contenedores.
La interfaz gráfica de usuario de Docker Desktop ofrece una incorporación guiada para ayudar incluso a los programadores de IA principiantes a empezar a utilizar modelos sin problemas, con gestión automática de los recursos disponibles, como la RAM y la GPU.
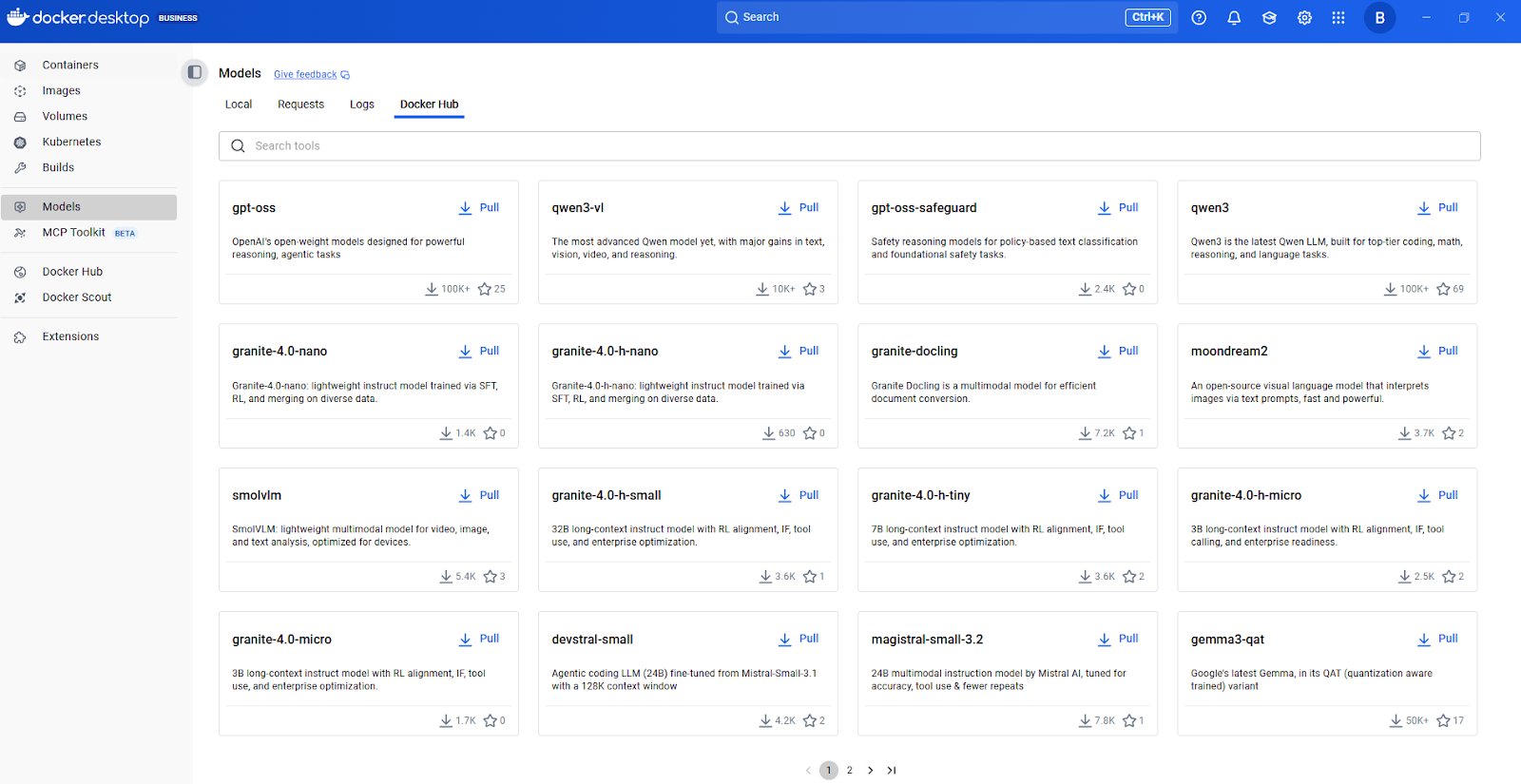
Centro de modelos de Docker
Ahora, hablemos de cómo se empaquetan y distribuyen los modelos. Docker Model Runner es compatible con modelos empaquetados con OCI, lo que te permite almacenar y distribuir modelos a través de cualquier registro compatible con OCI, incluido Docker Hub. Este enfoque de empaquetado estandarizado significa que puedes aplicar los mismos patrones de control de versiones, control de acceso y distribución que se utilizan para las imágenes de contenedor.
En lo que respecta a la integración con aplicaciones, las capacidades de la API REST son especialmente valiosas para la integración de aplicaciones. Docker Model Runner incluye un motor de inferencia basado en llama.cpp y accesible a través de la conocida API de OpenAI.
Esta compatibilidad con OpenAI significa que el código existente escrito para la API de OpenAI puede funcionar con modelos locales con cambios mínimos: simplemente apunta tu aplicación al punto final local en lugar de a la API de nube. Esta flexibilidad por sí sola puede ahorrar semanas de refactorización.
Déjame guiarte para que puedas instalar y ejecutar Docker Model Runner en tu sistema. El proceso de instalación es sencillo, pero hay algunas consideraciones específicas de la plataforma que conviene conocer de antemano.
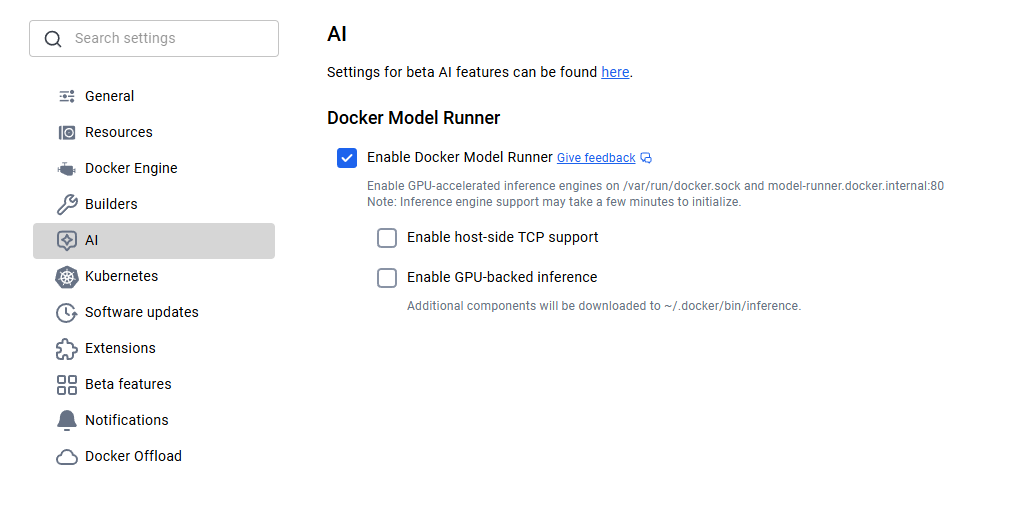
Para los usuarios de macOS y Windows, Docker Model Runner viene incluido con Docker Desktop 4.40 o posterior. Solo tienes que descargar la última versión desde el sitio web oficial de Docker e instalarla. Una vez instalado, deberás habilitar Docker Model Runner en la configuración. Ve a Configuración > IA y selecciona la opción Docker Model Runner y la inferencia con backend GPU en caso de que tu ordenador sea compatible con la GPU NVIDIA.
Activación del ejecutor del modelo Docker
Los usuarios de Linux disfrutan de una experiencia aún más optimizada. Actualiza tu sistema e instala el complemento Docker Model Runner utilizando los siguientes comandos.
sudo apt-get update
sudo apt-get install docker-model-pluginDespués de la instalación, comprueba que funciona ejecutando docker model version.
Si utilizas Apple Silicon, la aceleración de la GPU a través de Metal se configura automáticamente y no es necesario realizar ninguna configuración adicional. Para las GPU NVIDIA, asegúrate de tener instalado NVIDIA Container Runtime.
Con la compatibilidad con Vulkan, ahora puedes aprovechar la aceleración por hardware en AMD, Intel y otras GPU compatibles con la API Vulkan. El sistema detecta de forma inteligente tu hardware y aplica la aceleración adecuada.
Una vez instalado, descargar un modelo resulta muy fácil. Solo tienes que extraer primero el modelo y luego ejecutarlo para interactuar con él:
docker model pull ai/smollm2
docker model run ai/smollm2Si todo se ha configurado correctamente, deberías ver el modelo en la lista:
docker model listMODEL NAME
ai/smollm2Una vez que hayas instalado Docker Model Runner y comprendido cómo extraer modelos, la siguiente pregunta lógica es: ¿de dónde proceden estos modelos y cómo se gestionan a gran escala? Aquí es donde el enfoque de Docker Model Runner resulta especialmente elegante.
Docker empaqueta los modelos como artefactos OCI, un estándar abierto que permite la distribución a través de los mismos registros y flujos de trabajo que se utilizan para los contenedores. Los equipos que ya utilizan registros privados de Docker pueden usar la misma infraestructura para los modelos de IA. Docker Hub ofrece funciones empresariales como la gestión del acceso al registro para controles de acceso basados en políticas.
La integración con Hugging Face merece una mención especial. Los programadores pueden utilizar Docker Model Runner como motor de inferencia local para ejecutar modelos en Hugging Face y filtrar los modelos compatibles (se requiere el formato GGUF) directamente en la interfaz de Hugging Face. Esto facilita considerablemente el descubrimiento de modelos.
docker model pull hf.co/bartowski/Llama-3.2-1B-Instruct-GGUFLo realmente ingenioso es cómo funciona esta integración en segundo plano. Cuando extraes un modelo de Hugging Face en formato GGUF, Docker Model Runner lo empaqueta automáticamente como un artefacto OCI sobre la marcha. Esta conversión fluida elimina los pasos manuales de empaquetado y acelera el proceso desde el descubrimiento del modelo hasta su implementación.
Entender el mecanismo de distribución está muy bien, pero ¿qué modelos se pueden ejecutar realmente? Déjame mostrarte lo que hay disponible desde el primer momento y cómo encontrar más.
Docker Model Runner ofrece una selección cuidada de modelos listos para su uso inmediato. SmolLM2 es una opción muy popular, perfecta para asistentes de chat, extracción de texto, reescritura y tareas de resumen, con 360 millones de parámetros. He encontrado este modelo especialmente útil para el desarrollo y las pruebas debido a su pequeño tamaño y su rápida inferencia.
Para descubrir modelos adicionales, recomiendo empezar por el catálogo de modelos de IA de Docker Hub. Explora los modelos disponibles, consulta su documentación para conocer las tareas compatibles y los requisitos de hardware, y luego descárgalos con un simple comando « docker model pull ».
Los modelos se extraen de Docker Hub la primera vez que los utilizas y se almacenan localmente, cargándose en la memoria solo en tiempo de ejecución cuando se realiza una solicitud y descargándose cuando no se utilizan para optimizar los recursos.
Este enfoque mantiene la capacidad de respuesta de tu sistema incluso cuando tienes varios modelos descargados. No estás obligado a mantener todo en la RAM simultáneamente.
Cada ficha de modelo incluye información sobre los niveles de cuantificación (como Q4_0, Q8_0), que afectan al tamaño del modelo y a la calidad de la inferencia.
|
Nivel de cuantificación |
Descripción |
Tamaño del archivo |
Calidad |
Ideal para |
|
Q8_0 |
Cuantización de 8 bits |
Más grande |
La más alta calidad |
Uso en producción, tareas en las que la precisión es fundamental |
|
Q5_0 |
Cuantización de 5 bits |
Medio |
Buen equilibrio |
Rendimiento equilibrado y para uso general |
|
Q4_0 |
Cuantización de 4 bits |
Más pequeño |
Aceptable |
Entornos de desarrollo, pruebas y recursos limitados. |
Cuantificación del modelo
Una consideración importante es el control de versiones del modelo. Puedes especificar versiones exactas utilizando etiquetas (como Q4_0 o latest), de forma similar a las imágenes de Docker. Esto garantiza implementaciones reproducibles y evita cambios inesperados cuando se actualizan los modelos.
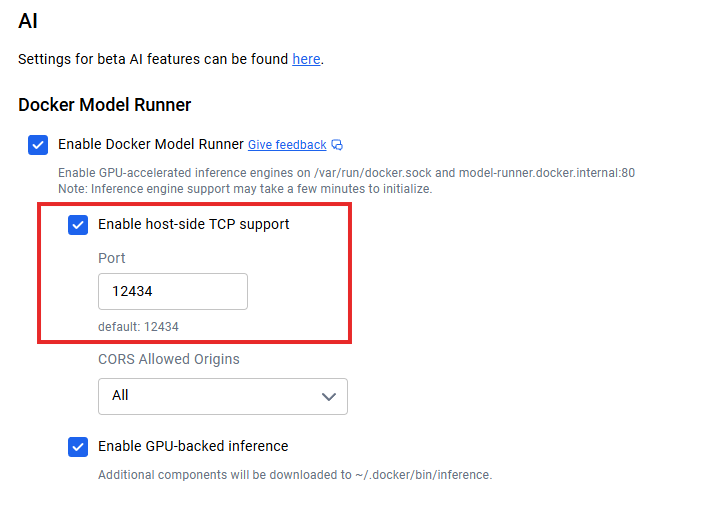
Una vez que tengas los modelos funcionando localmente, la pregunta es: ¿cómo conectas tus aplicaciones? Cuando la compatibilidad con TCP del lado del host está habilitada (por ejemplo, a través de la configuración de TCP de Docker Desktop), el punto final de la API predeterminado se ejecuta en localhost:12434, exponiendo puntos finales compatibles con OpenAI.
Integración de la API Docker Model Runner
Aquí tienes un ejemplo sencillo para realizar una solicitud:
curl http://localhost:12434/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/smollm2",
"messages": [{"role": "user", "content": "Explain containerization"}],
"stream": false
}'En el caso de las arquitecturas de microservicios, los contenedores de aplicaciones pueden comunicarse con el servicio de modelos mediante protocolos HTTP estándar, sin necesidad de SDK especiales. La transmisión de respuestas es compatible con aplicaciones en tiempo real configurando "stream": true .
La documentación de la API REST proporciona especificaciones completas de los puntos finales, opciones de parámetros y esquemas de respuesta. Recomiendo consultar la documentación oficial de Docker para obtener los detalles más actuales sobre la API, ya que la plataforma sigue evolucionando rápidamente.
Para obtener un rendimiento óptimo de Docker Model Runner, es necesario comprender varias estrategias clave. Permíteme compartir lo que he aprendido al trabajar con implementaciones de modelos locales.
Al ejecutarse como un proceso a nivel de host con acceso directo a la GPU, Model Runner logra una mejor optimización del rendimiento que las soluciones en contenedores. Esta decisión arquitectónica ofrece ventajas en términos de rendimiento y latencia, pero aún así es necesario ajustar los parámetros adecuadamente para sacarle el máximo partido.
La aceleración por hardware es tu primera herramienta de optimización. Habilitar la compatibilidad con GPU suele proporcionar mejoras de rendimiento de entre 2 y 3 veces superiores a las de la inferencia solo con CPU. Más allá del hardware, la cuantificación del modelo es tu segunda herramienta principal. Normalmente empiezo con Q8_0 para obtener la mejor calidad y luego paso a Q5_0 o Q4_0 si necesito un mejor rendimiento.
El punto final de métricas integrado en /metrics permite la supervisión con Prometheus o tu pila de supervisión existente. Para el escalado, configura la longitud del contexto en función de las necesidades reales, en lugar de utilizar valores máximos. Si tu aplicación solo necesita 2048 tokens de contexto, no configures 8192.
Una de las mayores ventajas de Docker Model Runner es cómo se integra con el ecosistema más amplio de Docker.
Docker Model Runner es compatible con Docker Compose. Esto significa que puedes definir aplicaciones multiservicio en las que uno de los servicios sea un modelo de IA, gestionando toda la pila con los conocidos archivos Docker Compose. Así es como se ve:
services:
app:
image: my-app:latest
models:
- llm
- embedding
models:
llm:
model: ai/smollm2
embedding:
model: ai/embeddinggemmaTambién puedes automatizar los flujos de trabajo de CI/CD: activa modelos en tu entorno de prueba, ejecuta pruebas de integración con ellos y desmantela todo, todo ello dentro de tu infraestructura de canalización existente. Esto elimina el problema de «funciona en mi máquina» para las funciones de IA.
Otra integración interesante es Docker Offload, que amplía tu flujo de trabajo local a la nube cuando es necesario. Aunque todavía es una función beta, te permite desarrollar localmente con Docker Model Runner y, a continuación, descargar la inferencia que consume muchos recursos a la infraestructura de nube cuando los requisitos superan la capacidad local.
Descarga de Docker
La compatibilidad con Kubernetes también está disponible como gráfico Helm y archivo YAML estático. Esto abre posibilidades para implementaciones a escala de producción en las que se necesita escalabilidad horizontal, equilibrio de carga y alta disponibilidad.
Aunque todavía se encuentra en fase experimental, la integración con Kubernetes representa la evolución de Docker Model Runner hacia implementaciones de nivel empresarial en las que se atienden miles de solicitudes por segundo en múltiples réplicas.
Con todas estas opciones de integración, es posible que te preguntes: ¿pero es seguro? Docker Model Runner se ejecuta en un entorno aislado y controlado, lo que proporciona un espacio aislado para mayor seguridad. Este aislamiento impide que los modelos accedan a recursos sensibles del sistema más allá de lo que se proporciona explícitamente.
La principal ventaja en materia de seguridad es la privacidad de los datos. Tus solicitudes de inferencia nunca salen de tu infraestructura, lo que elimina los riesgos de exfiltración de datos. Para las organizaciones que manejan datos confidenciales, este modelo de ejecución local es esencial para cumplir con el RGPD, la HIPAA y otras normativas de privacidad.
Los administradores pueden configurar la compatibilidad con TCP del lado del host y CORS para un control de seguridad granular. Los metadatos de licencias de modelos en los registros permiten realizar un seguimiento del cumplimiento normativo y crear registros de auditoría para la gobernanza empresarial.
A estas alturas, quizá te estés preguntando: ¿cómo se compara esto con las herramientas que ya utilizas? A continuación se muestra una comparación entre Docker Model Runner, Ollama y NVIDIA NIM:
|
Característica |
Ejecutor de modelos Docker |
Ollama |
NVIDIA NIM |
|
Rendimiento |
Entre 1,00 y 1,12 veces más rápido que Ollama. |
Rendimiento de referencia |
Altamente optimizado para GPU NVIDIA. |
|
Integración del ecosistema |
Flujo de trabajo nativo de Docker, artefactos OCI |
Herramienta independiente, flujo de trabajo independiente |
En contenedores, específico para NVIDIA |
|
Personalización del modelo |
Modelos preempaquetados de Docker Hub |
Archivos de modelos personalizados, importación de GGUF/Safetensors |
Solo modelos optimizados para NVIDIA |
|
Soporte técnico para plataformas |
macOS, Windows, Linux |
macOS, Windows, Linux, Docker |
Linux solo con GPU NVIDIA |
|
Requisitos de hardware |
Cualquier GPU (Metal, CUDA, Vulkan) o CPU |
Cualquier GPU o CPU |
Se requieren GPU NVIDIA |
|
Comunidad y SDK |
Crecimiento, enfoque en el ecosistema Docker |
Maduro, extenso |
Ecosistema NVIDIA, enfocado en las empresas |
|
Ideal para |
Equipos con infraestructura Docker |
Proyectos de IA independientes, experimentación rápida |
Implementaciones de producción centradas en NVIDIA |
El factor diferenciador clave de Docker Model Runner es la integración en el ecosistema. Trata los modelos de IA como elementos de primera clase junto con los contenedores, lo que reduce la proliferación de herramientas para los equipos centrados en Docker.
Ollama ofrece una mayor personalización de los modelos y una comunidad madura con amplios SDK. NVIDIA NIM ofrece el máximo rendimiento para las GPU NVIDIA, pero carece de la flexibilidad y la compatibilidad multiplataforma de las demás opciones.
Antes de terminar, veamos qué pasa cuando las cosas no funcionan.
Este error suele indicar que la CLI de Docker no puede localizar el ejecutable del complemento.
Causa: Docker no puede encontrar el complemento en el directorio de complementos CLI esperado.
Solución: Probablemente tengas que crear un enlace simbólico (symlink) al ejecutable. Consulta la sección de instalación para conocer los comandos específicos.
Actualmente, el uso de resúmenes específicos para extraer o hacer referencia a modelos puede fallar.
Solución alternativa: Hacé referencia a los modelos por su nombre de etiqueta (por ejemplo, model:v1) en lugar de por su resumen.
Estado: El equipo de ingeniería está trabajando activamente en la compatibilidad adecuada con digest para una futura versión.
Si tus modelos funcionan lentamente o no utilizan la GPU, realiza las siguientes comprobaciones:
Verificar controladores: Asegúrate de que los controladores de la GPU de tu máquina host estén actualizados.
Comprueba los permisos: COnfirma que Docker tiene permisos para acceder a los recursos de la GPU.
Linux (NVIDIA): Asegúrate de que NVIDIA Container Runtime esté instalado y configurado.
Verificación: Ejecuta el siguiente comando para confirmar que la GPU es visible para el sistema: nvidia-smi
Si te encuentras con un problema que no aparece aquí:
Informar de un problema: Informen de errores o soliciten funciones en el repositorio oficial de GitHub.
Comunidad: Existe una comunidad activa que a menudo proporciona soluciones rápidas para casos extremos.
Docker Model Runner representa un importante avance para hacer más accesible el desarrollo de la IA. Al incorporar la gestión de modelos al ecosistema Docker, se elimina la fricción que históricamente ha ralentizado la adopción de la IA.
La importancia estratégica va más allá de la comodidad. En una época en la que la privacidad de los datos, el control de los costes y la velocidad de desarrollo son más importantes que nunca, la ejecución local de la IA cobra cada vez más importancia. Docker Model Runner facilita la experimentación y la creación de aplicaciones de IA utilizando los mismos comandos y flujos de trabajo de Docker que los programadores ya utilizan a diario.
De cara al futuro, la plataforma sigue evolucionando con soporte para bibliotecas de inferencia adicionales, opciones de configuración avanzadas y capacidades de implementación distribuida. La convergencia de la contenedorización y la IA representa el rumbo que está tomando el sector, y Docker Model Runner se sitúa en esta encrucijada, haciendo realidad el desarrollo de IA rentable y centrado en la privacidad para millones de programadores que ya utilizan Docker.
Ahora que ya tienes modelos ejecutándose en tu entorno Docker local, el siguiente paso es crear un proceso fiable en torno a ellos. Domina los principios del control de versiones de modelos, la implementación y la gestión del ciclo de vida con el curso MLOps Fundamentals Skill Program de DataCamp.
Cursos de Docker
programa
programa
Curso
blog
Bhavishya Pandit
8 min
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Moez Ali


