
Kurs
Feinabstimmung mit Llama 3
2 Std.
3.7K
Ministral 3 ist eine neue Familie von für Edge-Anwendungen optimierten multimodalen Modellen, die in den Größen 3B, 8B und 14B verfügbar sind. Jedes Modell gibt's in den Varianten „Base“, „Instruct“ und „Reasoning“ mit voller Bildverarbeitungsunterstützung.
Der Ministral 3 ist so gemacht, dass er echt gute Leistung bringt und trotzdem leicht genug ist, um ihn vor Ort oder privat zu nutzen. Er schafft den Spagat zwischen coolen Funktionen und praktischen Hardware-Einschränkungen. Sein Topmodell 14B Instruct hat 24 GB VRAM in FP8 und kann mit größeren Systemen wie dem Mistral Small 3.2 24B mithalten. Mit einem großen 256k-Kontextfenster, einer robusten mehrsprachigen Abdeckung, nativen Funktionsaufrufen, einer starken Einhaltung von Systemaufforderungen und einer offenen Apache 2.0-Lizenzierung.
In diesem Tutorial werden wir das Modell „Ministral 3 14B Instruct” anhand eines Datensatzes von Röntgenbildern von Knochenbrüchen optimieren, um seine Fähigkeit zur Erkennung von Brüchen und zur genauen Klassifizierung ihrer Kategorien zu verbessern.
Du wirst lernen, wie man:
Wenn du mehr über die Mistral-KI-Modelle erfahren möchtest, empfehle ich dir unseren Leitfaden Mistral 3 und Mistral 3 Large Tutorial.
Haftungsausschluss: Dieses Tutorial zeigt einen technischen Feinabstimmungsprozess, der nur zu Schulungszwecken gedacht ist. Das Modell, das dabei rauskommt, ist nicht für medizinische oder klinische Zwecke gedacht und sollte nicht für Diagnosen, Entscheidungen oder die Patientenversorgung herangezogen werden.
Auch wenn wir das 14B-Modell optimieren, braucht das Training mit Bilddaten viel mehr Speicherplatz als das Optimieren mit reinen Textdaten. Der Bildcodierer macht die GPU ziemlich voll, also brauchen wir eine A100-GPU mit 80 GB VRAM, damit das Ganze reibungslos läuft.
Für dieses Projekt benutze ich Runpod und starte einen A100-Pod.
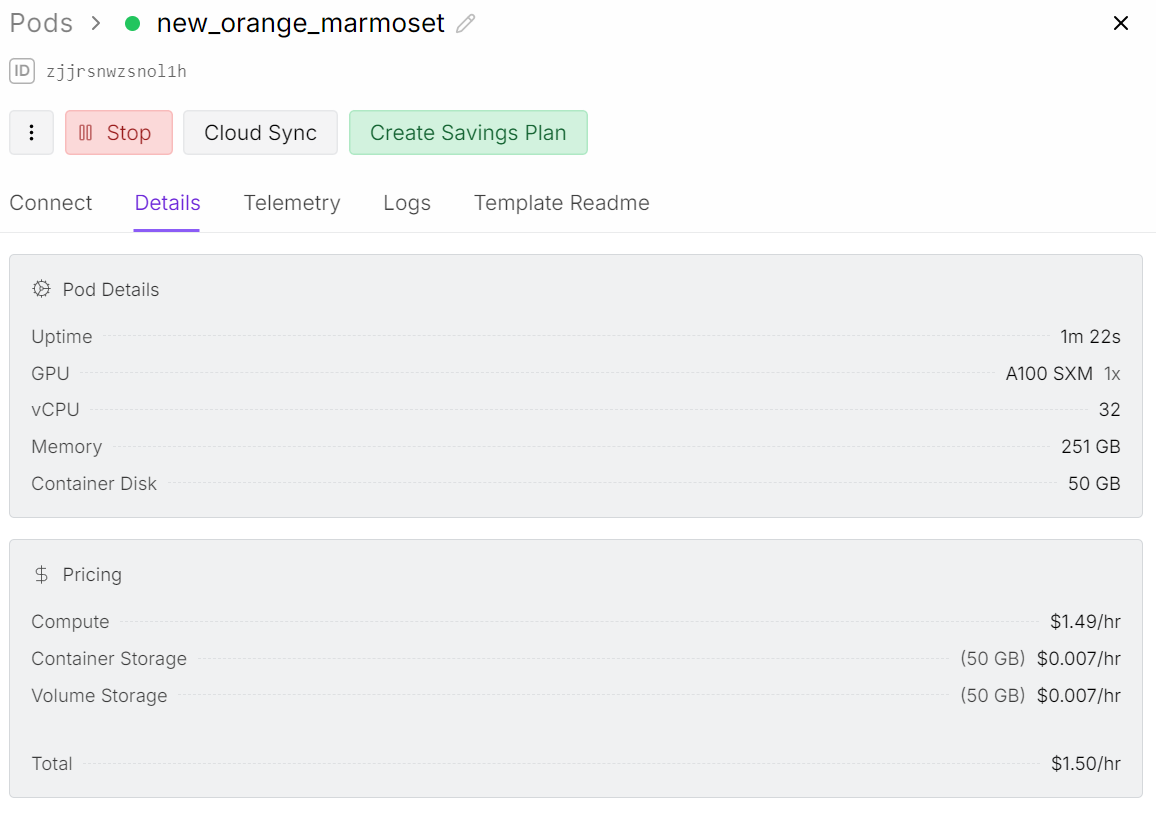
Nachdem du den Pod gestartet hast, machst du den Container-Speicherplatz auf 50 GB groß. Dann füge die Umgebungsvariablen für die API-Schlüssel von Kaggle und Hugging Face hinzu.
Mit Kaggle können wir den Datensatz mit den Knochenröntgenbildern direkt runterladen, und mit Hugging Face können wir unseren fein abgestimmten LoRA-Adapter wieder in den Model Hub hochladen.
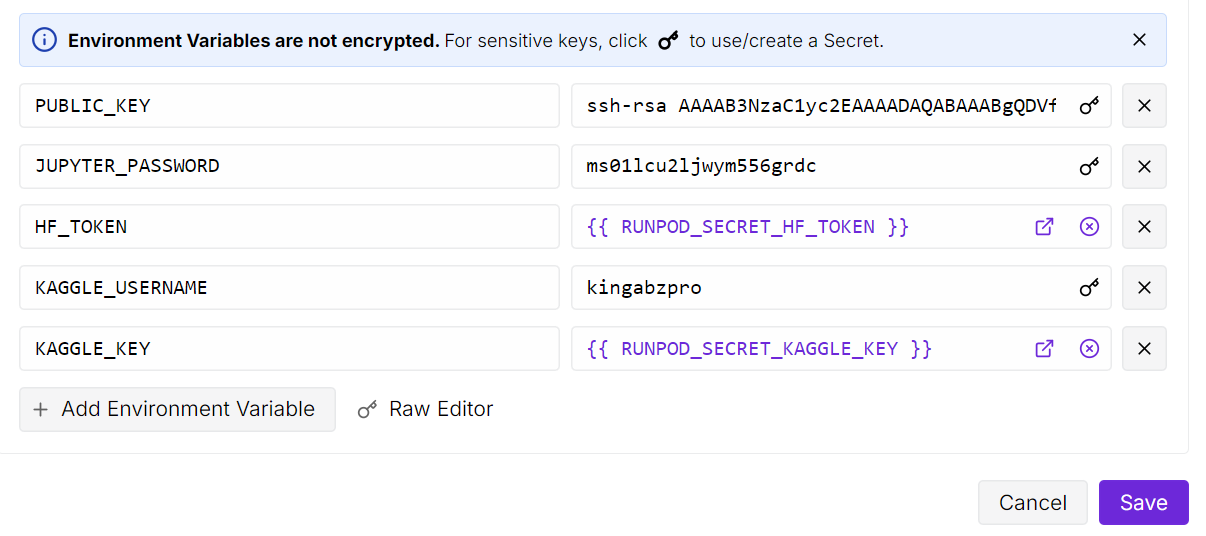
Öffne dann die JupyterLab-Instanz und mach ein neues Notizbuch. Vor dem Training müssen wir alle benötigten Python-Pakete installieren.
Stell sicher, dass die Transformers-Bibliothek auf die neueste Version aktualisiert ist, weil die Unterstützung für Ministral 3 erst kürzlich hinzugefügt wurde und ältere Versionen das Modell nicht richtig laden können.
! pip install --upgrade --quiet bitsandbytes datasets evaluate hf_transfer peft scikit-learn matplotlib Pillow kaggle ipywidgets
!pip install --quiet git+https://github.com/huggingface/transformers.git@bf3f0ae70d0e902efab4b8517fce88f6697636ce
!pip install --quiet --no-deps trl==0.22.2Sobald alles installiert ist, kannst du den Datensatz laden, den Collator vorbereiten und mit der Feinabstimmung beginnen.
Als Nächstes legen wir einen Stammordner für unseren Datensatz an und laden mit der Kaggle Python API den Datensatz „Bone Break Classification Image“ runter.
Dieser Datensatz hat verschiedene Kategorien von Knochenbrüchen im Röntgenformat und wird dazu verwendet, Ministral 3 für die visuelle Klassifizierung zu optimieren.
import os
import glob
from kaggle.api.kaggle_api_extended import KaggleApi
DATA_ROOT = "/bone-break"
os.makedirs(DATA_ROOT, exist_ok=True)
kaggle_dataset = "pkdarabi/bone-break-classification-image-dataset"
# Initialize and authenticate Kaggle API (it will read KAGGLE_USERNAME / KAGGLE_KEY)
api = KaggleApi()
api.authenticate()
# Download and unzip the dataset using the Python API
api.dataset_download_files(
kaggle_dataset,
path=DATA_ROOT,
unzip=True,
)Du kannst dir den Datensatz hier auf Kaggle anschauen:
Dataset URL: https://www.kaggle.com/datasets/pkdarabi/bone-break-classification-image-datasetDer heruntergeladene Datensatz ist nicht so organisiert, wie man es normalerweise erwarten würde. Jede Frakturkategorie hat einen Ordner für das Training und einen für die Tests.
Also, zuerst brauchen wir eine Methode, um alle Klassenordner durchzugehen, die beiden Teile zu trennen und dann einen kombinierten Hugging Face-Datensatz mit einer sauberen Trainings- und Testzuordnung zu erstellen.
import glob, os
from typing import Any, Dict, List
from datasets import Dataset, DatasetDict, Features, ClassLabel, Image
inner_root = os.path.join(
DATA_ROOT, "Bone Break Classification", "Bone Break Classification"
)
classes = []
train_records: List[Dict[str, Any]] = []
test_records: List[Dict[str, Any]] = []
for class_name in sorted(os.listdir(inner_root)):
class_dir = os.path.join(inner_root, class_name)
if not os.path.isdir(class_dir):
continue
classes.append(class_name)
for split_name, split_key in [("Train", "train"), ("Test", "test")]:
split_dir = os.path.join(class_dir, split_name)
if not os.path.isdir(split_dir):
continue
for ext in ("*.png", "*.jpg", "*.jpeg"):
for img_path in glob.glob(os.path.join(split_dir, ext)):
rec = {"image": img_path, "label_name": class_name}
if split_key == "train":
train_records.append(rec)
else:
test_records.append(rec)
print("Classes:", classes)
print("Train samples:", len(train_records))
print("Test samples:", len(test_records))Wir haben insgesamt 10 Klassifikationen mit 989 Trainingsbeispielen und 140 Testbeispielen.
Classes: ['Avulsion fracture', 'Comminuted fracture', 'Fracture Dislocation', 'Greenstick fracture', 'Hairline Fracture', 'Impacted fracture', 'Longitudinal fracture', 'Oblique fracture', 'Pathological fracture', 'Spiral Fracture']
Train samples: 989
Test samples: 140Wir werden jetzt die Labels für den Hugging Face-Datensatz so kodieren, dass jede Label-Klasse als Klassenlabel betrachtet und jedes Bild als Bildmerkmal behandelt wird.
Wir machen zwei Datensätze: einen zum Trainieren und einen zum Testen. Zum Schluss packen wir alles in einen einzigen Datensatz, der sowohl Trainings- als auch Testuntergruppen hat.
# Encode labels
classes = sorted(list(set(classes)))
label2id = {name: i for i, name in enumerate(classes)}
for rec in train_records:
rec["label"] = label2id[rec["label_name"]]
for rec in test_records:
rec["label"] = label2id[rec["label_name"]]
features = Features(
{
"image": Image(),
"label": ClassLabel(names=classes),
}
)
train_ds = Dataset.from_list(
[{"image": r["image"], "label": r["label"]} for r in train_records],
features=features,
)
test_ds = Dataset.from_list(
[{"image": r["image"], "label": r["label"]} for r in test_records],
features=features,
)
data = DatasetDict({"train": train_ds, "test": test_ds})
dataHier ist die Übersicht über den Datensatz.
DatasetDict({
train: Dataset({
features: ['image', 'label'],
num_rows: 989
})
test: Dataset({
features: ['image', 'label'],
num_rows: 140
})
})Bevor du mit der Feinabstimmung anfängst, ist es gut zu wissen, wie ausgewogen der Datensatz ist und wie die Bilder aussehen. Zuerst schauen wir mal, wie viele Trainingsbeispiele es für jede Frakturkategorie gibt.
from collections import Counter
label_names = data["train"].features["label"].names
label_ids = data["train"]["label"]
counts = Counter(label_ids)
print("Training Class counts:")
for lbl_id, cnt in counts.items():
print(f"{lbl_id:2d} ({label_names[lbl_id]}): {cnt}")
FRACTURE_CLASSES = label_namesDie Kategorien sind ziemlich ausgewogen, auch wenn die Stichprobengröße für eine komplexe Bildklassifizierungsaufgabe insgesamt klein ist.
Vorerst werden wir mit diesem Datensatz weitermachen, aber die Ergebnisse sollten wegen der begrenzten Stichprobenmenge mit realistischen Erwartungen interpretiert werden.
Training Class counts:
0 (Avulsion fracture): 109
1 (Comminuted fracture): 134
2 (Fracture Dislocation): 137
3 (Greenstick fracture): 106
4 (Hairline Fracture): 101
5 (Impacted fracture): 75
6 (Longitudinal fracture): 68
7 (Oblique fracture): 69
8 (Pathological fracture): 116
9 (Spiral Fracture): 74
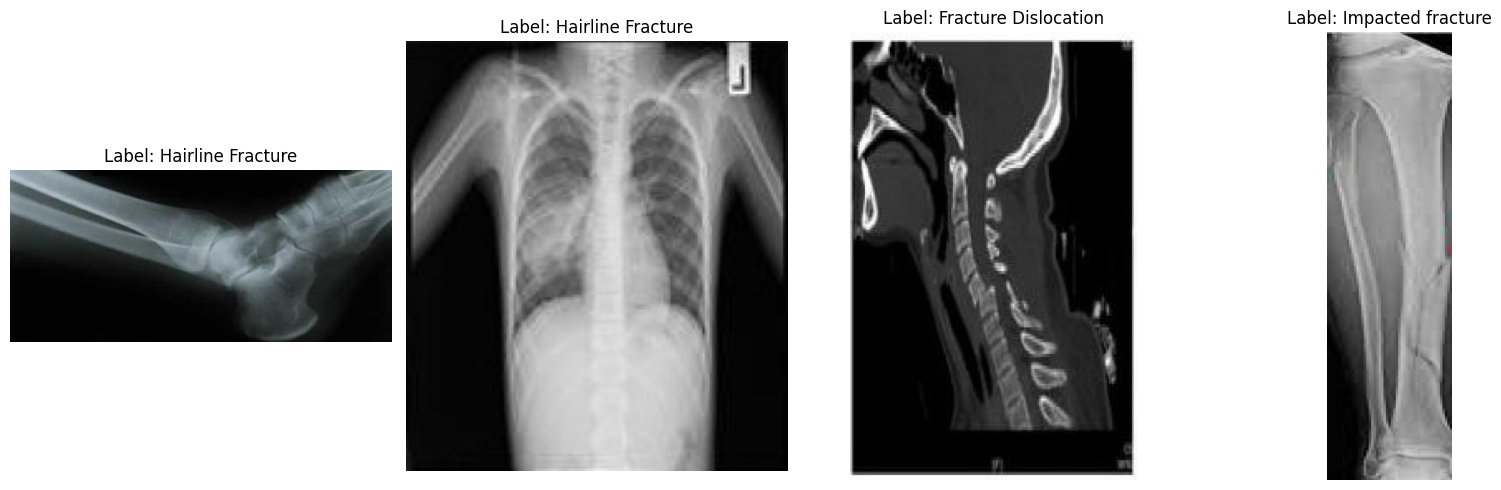
Als Nächstes schauen wir uns ein paar zufällige Bilder an, um den Datensatz besser zu verstehen.
import matplotlib.pyplot as plt
from datasets import Image
# Cast the 'image' column to Hugging Face Image feature
dataset_images = data.cast_column("image", Image())
# Select random samples from the training set
samples = dataset_images["train"].shuffle(seed=420).select(range(4))
# Plot
fig, axes = plt.subplots(1, 4, figsize=(16, 5))
for i, sample in enumerate(samples):
img_object = sample["image"] # PIL Image
label_id = sample["label"] # int
label_name = label_names[label_id] # string
axes[i].imshow(img_object)
axes[i].set_title(f"Label: {label_name}")
axes[i].axis("off")
plt.tight_layout()
plt.show()Wenn wir uns die Beispielbilder anschauen, sehen wir Unterschiede in Größe, Auflösung, Ausrichtung und Scanqualität. Das hat keinen Einfluss auf die Feinabstimmung eines visuellen Sprachmodells, kann aber beeinflussen, wie konsequent das Modell jede Frakturkategorie lernt.
Eine Fraktur optisch zu erkennen ist oft einfach, aber um sie in eine von zehn subtilen medizinischen Frakturarten einzuordnen, braucht man mehr strukturierte Daten, als hier zur Verfügung stehen.
Als Nächstes müssen wir uns überlegen, wie sich das Modell verhalten soll. Für diese Aufgabe haben wir uns ein klares Ziel gesetzt: Wenn wir ein Röntgenbild eingeben, soll das Modellnur einen Namen für eine Frakturklasse ausgebenund sonst nichts anderes . Keine Erklärungen, keine Preisnachlässe, kein zusätzlicher Text.
Wir schreiben eine klare Anweisung und nutzen sie dann, um eine Spalte „ messages ” im Datensatz zu erstellen.
PROMPT = f"""
You are a radiology assistant specialised in bone fracture classification.
You must classify the X-ray image into exactly ONE of the following classes:
{", ".join(FRACTURE_CLASSES)}
Rules:
- Reply with ONLY the class name.
- No explanations, no extra words, no markdown, no punctuation.
- Output must be EXACTLY one of: {", ".join(FRACTURE_CLASSES)}
""".strip()
from typing import Dict, Any
def convert_to_conversation(example: Dict[str, Any]) -> Dict[str, Any]:
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": PROMPT},
{"type": "image"}, # no image bytes here
],
},
{
"role": "assistant",
"content": [
{"type": "text", "text": FRACTURE_CLASSES[example["label"]]},
],
},
]
example["messages"] = conversation
return example
formatted_data = data["train"].map(convert_to_conversation)
formatted_data["messages"][0]Dadurch wird eine Spalte „ messages “ erstellt, in der jeder Datensatz jetzt eine komplette Mini-Konversation enthält: die Anweisung plus die richtige Frakturklasse. Genau das wird das Sprachmodell während der Feinabstimmung sehen.

Jetzt laden wir die BF16-Version des Modells „Ministral-3 14B Instruct” vom Hugging Face Hub zusammen mit dem Prozessor. Der Prozessor kombiniert den Tokenizer und die Bildvorverarbeitungs-Pipeline, die für visuelle Spracheingaben gebraucht werden.
import torch
from transformers import AutoProcessor, AutoModelForImageTextToText, BitsAndBytesConfig
model_id = "mistralai/Ministral-3-14B-Instruct-2512-BF16"
model_kwargs = dict(
attn_implementation="eager",
torch_dtype=torch.bfloat16,
device_map="auto",
)
model = AutoModelForImageTextToText.from_pretrained(model_id, **model_kwargs)
processor = AutoProcessor.from_pretrained(model_id)
# Use right padding to avoid issues during training
processor.tokenizer.padding_side = "right"Die Chat-Vorlage, die Mistral AI zur Verfügung stellt, ist für lange Unterhaltungen gedacht. Bei diesem Projekt wurde das zum Problem. Das Modell hat sich auf die langen Rollenanweisungen und den Systemtext konzentriert und dabei das eigentliche Ziel vergessen, nämlich die Vorhersage einer einzelnen Knochenbruchklasse anhand des Röntgenbildes.
Um das zu ändern, machen wir eine kürzere Vorlage für die Sprachverarbeitung, die nur die wichtigen Teile behält: die Anweisungen vom Nutzer und die Antwort vom Assistenten. Das reduziert Rauschen und hilft dem Modell, eine saubere Zuordnung von Bild zu Klassenbezeichnung zu lernen.
SHORT_VLM_TEMPLATE = r"""{{ bos_token }}[INST]
{% for message in messages if message['role'] == 'user' -%}
{%- for content in message['content'] -%}
{%- if content['type'] == 'text' -%}
{{ content['text'] }}
{%- elif content['type'] == 'image' -%}
[IMG]
{%- endif -%}
{%- endfor -%}
{%- endfor -%}
[/INST]{% if not add_generation_prompt %}
{%- for message in messages if message['role'] == 'assistant' -%}
{{ message['content'][0]['text'] }}{{ eos_token }}
{%- endfor -%}
{%- endif %}"""
# Attach to processor / tokenizer
processor.chat_template = SHORT_VLM_TEMPLATE
processor.tokenizer.chat_template = SHORT_VLM_TEMPLATEBevor wir mit der Feinabstimmung anfangen, ist es sinnvoll, das Originalmodell Ministral 3 14B Instruct zu testen, um eine Ausgangsbasis zu schaffen.
Zuerst geben wir dem Modell ein zufälliges Bild aus dem Datensatz und stellen eine allgemeine Frage, um zu sehen, wie es den Inhalt des Röntgenbildes versteht.
image = formatted_data[200]["image"]
messages = [
{"role": "user", "content": [
{"type": "text", "text": "What is the image about?"},
{"type": "image"},
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt = True)
inputs = processor(
image,
input_text,
add_special_tokens = False,
return_tensors = "pt",
).to(device="cuda", dtype=torch.bfloat16)
from transformers import TextStreamer
text_streamer = TextStreamer(processor, skip_prompt = True)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 1000,
use_cache = True, temperature = 1.5, min_p = 0.1)Deshalb hat das Modell zwar den groben Inhalt des Röntgenbildes verstanden, ist dann aber in Beschreibungen abgeglitten, die für medizinische Zwecke nicht zuverlässig waren.

Als Nächstes probieren wir was aus, das unserem eigentlichen Ziel näher kommt. Wir zeigen das gleiche Bild, aber diesmal benutzen wir unsere strenge Frakturklassifizierung statt einer offenen Frage.
image = formatted_data[200]["image"]
messages = [
{"role": "user", "content": [
{"type": "text", "text": PROMPT},
{"type": "image"},
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt = True)
inputs = processor(
image,
input_text,
add_special_tokens = False,
return_tensors = "pt",
).to(device="cuda", dtype=torch.bfloat16)
from transformers import TextStreamer
text_streamer = TextStreamer(processor, skip_prompt = True)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 1000,
use_cache = True, temperature = 1.5, min_p = 0.1Für dieses Beispiel hat das Modell geantwortet:
Hairline Fracture</s>Jetzt schauen wir uns mal das echte Ground-Truth-Label für dasselbe Bild an.
FRACTURE_CLASSES[formatted_data[200]["label"]]Das gibt Folgendes zurück:
'Comminuted fracture'Also, das Modell hat das Anweisungsformat richtig befolgt und einen einzigen Klassennamen erzeugt, aber die Klassifizierung selbst war falsch.
Genau deshalb brauchen wir eine Feinabstimmung. Das Basismodell hat ein gutes Verständnis für Bilder, aber es wurde nicht speziell darauf trainiert, verschiedene Arten von Knochenbrüchen zu unterscheiden.
In den nächsten Schritten werden wir es anhand unseres Frakturdatensatzes optimieren, um dieses Verhalten zu verbessern.
Als Nächstes richten wir LoRA, um das Ministral-3-Modell effizient zu optimieren, ohne alle Parameter zu aktualisieren. Diese Konfiguration konzentriert sich auf die Haupt-Aufmerksamkeits- und MLP-Projektionsschichten, die in einem Mistral-ähnlichen Bild-Sprache-Modell verwendet werden.
from peft import LoraConfig, TaskType, get_peft_model
# LoRA config for a Mistral-style VLM used as a causal LM
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
modules_to_save=None,
)Als Nächstes schauen wir uns die Trainingsargumente für das überwachte Fine-Tuning (SFT) an.
Diese Konfiguration regelt den ganzen Trainingsprozess, zum Beispiel wie Batches behandelt werden, Speicheroptimierung, das Verhalten der Lernrate, Protokollierung, Speicherstrategie und die Integration mit Hugging Face Hub.
from trl import SFTConfig
args = SFTConfig(
output_dir="ministral-3-bone-fracture",
num_train_epochs=1,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
optim="adamw_8bit",
logging_steps=0.1,
save_strategy="epoch",
learning_rate=2e-4,
bf16=True,
fp16=False,
max_grad_norm=0.3,
warmup_steps=25,
lr_scheduler_type="linear",
push_to_hub=True,
report_to="none",
gradient_checkpointing_kwargs={"use_reentrant": False},
dataset_kwargs={"skip_prepare_dataset": True},
remove_unused_columns = False,
label_names=["labels"],
)Um ein Bild-Sprach-Modell wie Ministral 3 richtig einzustellen, brauchen wir einen speziellen Daten-Sortierer, der Bilder und Chat-Texte in einem einheitlichen Format zusammenfassen kann.
Der unten stehende Collator kümmert sich um Folgendes: Einrichten des Tokenizers und des Pad-Tokens, Anwenden der Chat-Vorlage, gemeinsames Tokenisieren von Text und Bildern, Durchsetzen einer sicheren maximalen Sequenzlänge und Erstellen von Labels, bei denen Padding- und Bild-Token ausgeblendet werden (-100), damit sie den Verlust nicht beeinflussen.
from typing import Any, Dict, List
import torch
# --- One-time processor setup ---
tokenizer = processor.tokenizer
tokenizer.padding_side = "right"
# Ensure we have a pad token
if tokenizer.pad_token is None:
tokenizer.add_special_tokens({"pad_token": tokenizer.eos_token})
pad_token_id = tokenizer.pad_token_id
image_token_id = getattr(processor, "image_token_id", None)
# Hard cap for sequence length
MAX_SEQ_LEN = 2048
def collate_fn(examples: List[Dict[str, Any]]) -> Dict[str, torch.Tensor]:
"""
Collate function for VLM fine-tuning.
Each example must contain:
- "image": a PIL image
- "messages": chat-style conversation (list[dict])
"""
images = [ex["image"] for ex in examples]
conversations = [ex["messages"] for ex in examples]
# Build chat prompts for the whole batch
chat_texts = processor.apply_chat_template(
conversations,
add_generation_prompt=False,
tokenize=False,
)
# Tokenize + process images
batch = processor(
text=chat_texts,
images=images,
padding="longest",
truncation=True,
max_length=MAX_SEQ_LEN,
return_tensors="pt",
)
# Labels: same as input_ids but mask pad & image tokens
labels = batch["input_ids"].clone()
if pad_token_id is not None:
labels[labels == pad_token_id] = -100
if image_token_id is not None and image_token_id != pad_token_id:
labels[labels == image_token_id] = -100
batch["labels"] = labels
return batchJetzt, wo wir den LoRA-Adapter, die Trainingskonfiguration und den Datenkollator haben, können wir alles an den SFTTrainer von trl anschließen.
Dieser Trainer kümmert sich um die komplette überwachte Feinabstimmung für unser Vision-Language-Modell Ministral 3. Dabei nutzt er unseren formatierten Datensatz, die LoRA-Konfiguration und eine spezielle Sortierfunktion für Bild-Text-Batches.
from trl import SFTTrainer
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=formatted_data,
peft_config=peft_config,
processing_class=processor,
data_collator=collate_fn,
)Führ einfach den Code unten aus, um mit dem Training loszulegen.
trainer.train()Während meines Laufs hat die Feinabstimmung ungefähr 57 GB VRAM verbraucht, und ein bisschen mehr während der Auswertungsphasen, die alle paar Durchläufe stattfinden. In der Praxis heißt das, dass du diese Einstellung ganz bequem auf Hardware mit weniger als 70 GB VRAM optimieren kannst.
Das ganze Training hat ungefähr eine halbe Stunde gedauert, und der Trainingsverlust ist mit der Zeit immer weiter zurückgegangen, was ein gutes Zeichen dafür ist, dass das Modell aus dem Datensatz lernt.
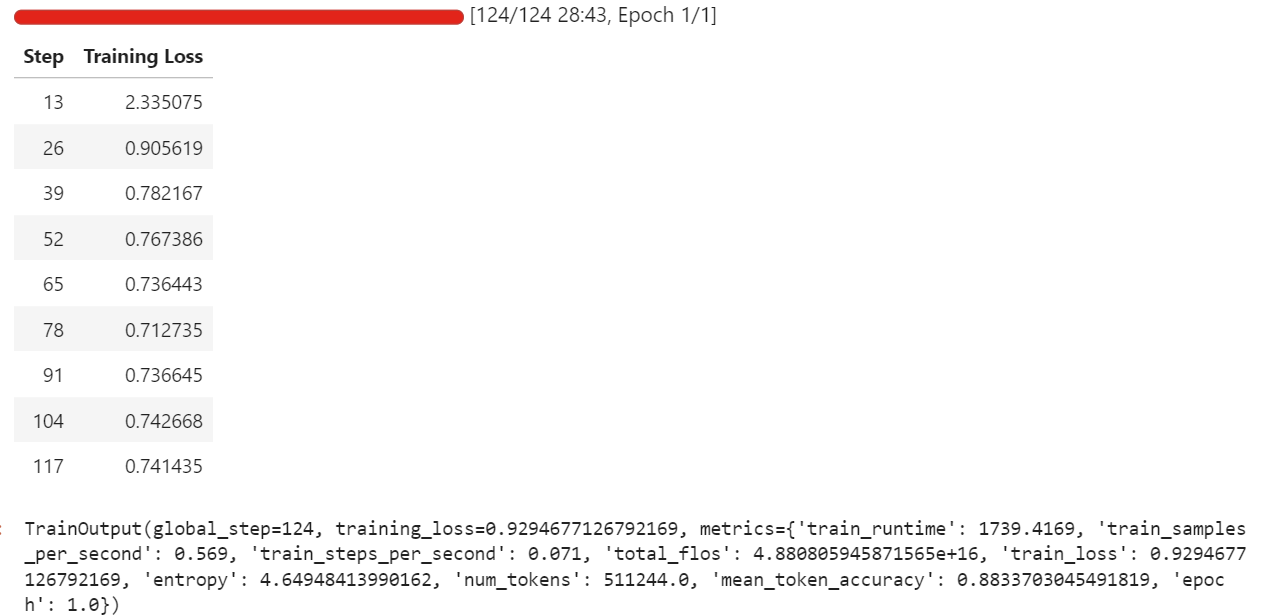
Sobald das Training fertig ist, speichern wir das angepasste Modell bei Hugging Face. Dadurch wird ein neues Repository erstellt und alle erforderlichen Dateien werden übertragen, sodass du das optimierte Modell aus jeder Umgebung neu laden und ausführen kannst.
trainer.save_model()Du kannst dir das Modell unter kingabzpro/ministral-3-bone-fracture.
Jetzt laden wir das fein abgestimmte Modell und den Prozessor vom Hugging Face Hub. Im Hintergrund wird der gespeicherte LoRA-Adapter runtergeladen, der Basis-Checkpoint Ministral 3 geladen und der Adapter ins Basismodell eingebaut, damit er für die Inferenz bereit ist.
import torch
from transformers import AutoProcessor, AutoModelForImageTextToText, BitsAndBytesConfig
model_id = "kingabzpro/ministral-3-bone-fracture"
model_kwargs = dict(
attn_implementation="eager",
dtype=torch.bfloat16,
device_map="auto",
)
model = AutoModelForImageTextToText.from_pretrained(model_id, **model_kwargs)
processor = AutoProcessor.from_pretrained(model_id)
processor.tokenizer.padding_side = "left"Damit der Vergleich fair bleibt, nehmen wir erstmal wieder das gleiche Bild, das wir vor der Feinabstimmung getestet haben (Index 200), und lassen es mit unserer strengen Klassifizierungsanweisung durch die Inferenz-Pipeline laufen.
image = formatted_data[200]["image"]
messages = [
{"role": "user", "content": [
{"type": "text", "text": PROMPT},
{"type": "image"},
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt = True)
inputs = processor(
image,
input_text,
add_special_tokens = False,
return_tensors = "pt",
).to(device="cuda", dtype=torch.bfloat16)
from transformers import TextStreamer
text_streamer = TextStreamer(processor, skip_prompt = True)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 100)Wir haben ein super Ergebnis hingekriegt. Es war keine zusätzliche Nachbearbeitung nötig. Das Modell hat sich an die Vorgaben gehalten und direkt die richtige Klasse rausgebracht.
Comminuted fracture</s>Als Nächstes probieren wir eine andere Zufallsstichprobe aus dem Datensatz aus, um zu sehen, ob dieses Verhalten nicht nur bei einem Beispiel auftritt.
image = formatted_data[400]["image"]
messages = [
{"role": "user", "content": [
{"type": "text", "text": PROMPT},
{"type": "image"},
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt = True)
inputs = processor(
image,
input_text,
add_special_tokens = False,
return_tensors = "pt",
).to(device="cuda", dtype=torch.bfloat16)
from transformers import TextStreamer
text_streamer = TextStreamer(processor, skip_prompt = True)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 100)Modellausgabe:
Greenstick fracture</s>Die Wahrheit:
FRACTURE_CLASSES[formatted_data[400]["label"]]Ausgabe:
'Greenstick fracture'Auch hier stimmt die Vorhersage und passt voll zum Label.
Mit diesen Tests können wir sagen, dass unser Modell Ministral 3 14B erfolgreich auf den Röntgendatensatz von Knochenbrüchen abgestimmt wurde und jetzt in der Lage ist, den Anweisungen zu folgen und genaue Vorhersagen für diese Beispiele zu machen.
Das Modell Ministral 3 richtig einzustellen, braucht Geduld und ständige Anpassungen. Ich hab echt zwei ganze Tage gebraucht, um zu kapieren, warum das Modell nicht so trainiert hat, wie ich es mir vorgestellt hab, und warum es, obwohl es ein relativ kleines Modell ist, meine GPU trotzdem zu Speicherfehlern gebracht hat.
Der Hauptgrund war einfach, aber leicht zu übersehen. Das ist nicht nur ein Sprachmodell. Es ist ein visuelles Sprachmodell, was heißt, dass es einen Bild-Encoder hat, der zusätzlichen Speicherplatz braucht.
Höhere Bildauflösungen bedeuten direkt mehr VRAM-Verbrauch. Wenn du die Bildgröße verringerst oder mit kleineren Stapeln anfängst, läuft das Training viel stabiler.
Ein weiteres Problem, auf das ich gestoßen bin, war die Verwendung der Standard-Chat-Vorlage. Es war viel zu lang und zu strukturiert für diese Art von Aufgabe. Das Modell hat sich mehr damit beschäftigt, die Formatierung der Vorlage anzupassen, anstatt zu lernen, wie man die Bilder liest und eine klare Frakturklassifizierung erstellt.
Nachdem ich die Eingabeaufforderung zu einer direkten Anweisung vereinfacht hatte, fing das Modell endlich an, richtig auf die visuelle Eingabe zu reagieren, anstatt jede Antwort wie eine vollständige Chat-Antwort zu gestalten.
Ich dachte auch, dass das Modell, weil es so gut sehen kann, bei medizinischen Scans einfach super funktionieren würde. Diese Annahme hat mich ausgebremst. Es in meinem Kopf „MedGemma“ zu nennen, war weder dem Modell noch dem Prozess gegenüber fair. Es ist kein spezielles medizinisches Modell, das man einfach so aus der Box nehmen kann, und es war mein Fehler, zu erwarten, dass es ohne richtige Schulung so funktioniert.
Am Ende habe ich alle Hindernisse überwunden und meine Erfahrungen in diesen Leitfaden gepackt. Das Ziel ist, dir dabei zu helfen, die gleiche Verwirrung zu vermeiden und schneller zu sinnvollen Ergebnissen zu kommen.
Mit kleineren Bildern, einfacheren Eingabeaufforderungen und realistischen Erwartungen kann Ministral 3 viel reibungsloser und zuverlässiger für das Verständnis von Röntgenbildern optimiert werden.
Wenn du mehr praktische Erfahrung mit der Feinabstimmung sammeln möchtest, empfehle ich dir den Kurs Kurs „Feinabstimmung mit Llama 3”.
Die besten DataCamp-Kurse
Kurs
Kurs
Kurs
Blog
Tutorial
Adel Nehme
Tutorial
DataCamp Team
Tutorial
Derrick Mwiti
Tutorial
Matt Crabtree
