
Cours
Ajustement fin avec Llama 3
2 h
3.7K
Ministral 3 est une nouvelle famille de modèles multimodaux optimisés pour les périphériques, disponibles en tailles 3B, 8B et 14B, chacun offrant des variantes Base, Instruct et Reasoning avec prise en charge complète de la vision.
Conçu pour offrir des performances de pointe tout en restant suffisamment léger pour être déployé localement et en privé, Ministral 3 concilie des capacités avancées et des contraintes matérielles pratiques. Son modèle phare, le 14B Instruct, intègre 24 Go de VRAM en FP8 et rivalise avec des systèmes plus imposants tels que le Mistral Small 3.2 24B. Avec une fenêtre contextuelle étendue de 256 ko, une couverture multilingue robuste, l'appel de fonctions natives, une forte adhésion aux invites système et une licence ouverte Apache 2.0.
Dans ce tutoriel, nous allons affiner le modèle Ministral 3 14B Instruct sur un ensemble de données de radiographies de fractures osseuses afin d'améliorer sa capacité à détecter les fractures et à classer leurs catégories avec précision.
Vous apprendrez à :
Si vous souhaitez en savoir plus sur les modèles Mistral AI, je vous recommande notre guide Mistral 3 et Mistral 3 Large.
Avertissement : Ce tutoriel présente un processus de réglage technique à des fins éducatives uniquement. Le modèle obtenu est . Il n'est pas destiné à un usage médical ou clinique et ne doit pas être utilisé à des fins de diagnostic, de prise de décision ou de soins aux patients.
Bien que nous procédions à un ajustement du modèle 14B, l'entraînement du langage visuel nécessite beaucoup plus de mémoire que l'ajustement du texte seul. L'encodeur d'images augmente la charge du GPU, ce qui implique que nous avons besoin d'un GPU A100 avec 80 Go de VRAM pour exécuter ce processus de manière fluide.
Pour ce projet, j'utilise Runpod et je lance un pod A100.
Après avoir lancé le pod, veuillez augmenter la capacité de stockage du conteneur à 50 Go. Veuillez ensuite ajouter les variables d'environnement pour les clés API Kaggle et Hugging Face.
Kaggle nous permettra de télécharger directement l'ensemble de données radiographiques osseuses, et Hugging Face nous permettra de renvoyer notre adaptateur LoRA optimisé vers le hub de modèles.
Ensuite, veuillez ouvrir l'instance JupyterLab et créer un nouveau notebook. Avant de commencer la formation, il est nécessaire d'installer tous les paquets Python requis.
Veuillez vous assurer que la bibliothèque Transformers est mise à jour vers la dernière version, car la prise en charge de Ministral 3 a été récemment ajoutée et les anciennes versions ne chargeront pas correctement le modèle.
! pip install --upgrade --quiet bitsandbytes datasets evaluate hf_transfer peft scikit-learn matplotlib Pillow kaggle ipywidgets
!pip install --quiet git+https://github.com/huggingface/transformers.git@bf3f0ae70d0e902efab4b8517fce88f6697636ce
!pip install --quiet --no-deps trl==0.22.2Une fois que tout est installé, vous êtes prêt à charger l'ensemble de données, à préparer le collateur et à commencer le réglage fin.
Dans l'étape suivante, nous créons un dossier racine pour notre ensemble de données et utilisons l'API Python Kaggle pour télécharger l'ensemble de données Bone Break Classification Image.
Cet ensemble de données contient différentes catégories de fractures osseuses au format radiographique et sera utilisé pour affiner Ministral 3 en vue d'une classification visuelle.
import os
import glob
from kaggle.api.kaggle_api_extended import KaggleApi
DATA_ROOT = "/bone-break"
os.makedirs(DATA_ROOT, exist_ok=True)
kaggle_dataset = "pkdarabi/bone-break-classification-image-dataset"
# Initialize and authenticate Kaggle API (it will read KAGGLE_USERNAME / KAGGLE_KEY)
api = KaggleApi()
api.authenticate()
# Download and unzip the dataset using the Python API
api.dataset_download_files(
kaggle_dataset,
path=DATA_ROOT,
unzip=True,
)Vous pouvez consulter l'ensemble de données sur Kaggle ici :
Dataset URL: https://www.kaggle.com/datasets/pkdarabi/bone-break-classification-image-datasetL'ensemble de données téléchargé n'est pas organisé selon la structure habituelle. Chaque catégorie de fracture contient à la fois un dossier de formation et un dossier de test.
Tout d'abord, nous avons besoin d'une méthode pour parcourir chaque dossier de classe, séparer les deux divisions, puis créer un ensemble de données Hugging Face combiné avec un mappage propre pour l'entraînement et le test.
import glob, os
from typing import Any, Dict, List
from datasets import Dataset, DatasetDict, Features, ClassLabel, Image
inner_root = os.path.join(
DATA_ROOT, "Bone Break Classification", "Bone Break Classification"
)
classes = []
train_records: List[Dict[str, Any]] = []
test_records: List[Dict[str, Any]] = []
for class_name in sorted(os.listdir(inner_root)):
class_dir = os.path.join(inner_root, class_name)
if not os.path.isdir(class_dir):
continue
classes.append(class_name)
for split_name, split_key in [("Train", "train"), ("Test", "test")]:
split_dir = os.path.join(class_dir, split_name)
if not os.path.isdir(split_dir):
continue
for ext in ("*.png", "*.jpg", "*.jpeg"):
for img_path in glob.glob(os.path.join(split_dir, ext)):
rec = {"image": img_path, "label_name": class_name}
if split_key == "train":
train_records.append(rec)
else:
test_records.append(rec)
print("Classes:", classes)
print("Train samples:", len(train_records))
print("Test samples:", len(test_records))Nous disposons d'un total de 10 classifications, avec 989 échantillons d'entraînement et 140 échantillons de test.
Classes: ['Avulsion fracture', 'Comminuted fracture', 'Fracture Dislocation', 'Greenstick fracture', 'Hairline Fracture', 'Impacted fracture', 'Longitudinal fracture', 'Oblique fracture', 'Pathological fracture', 'Spiral Fracture']
Train samples: 989
Test samples: 140Nous allons maintenant encoder les étiquettes pour l'ensemble de données Hugging Face afin que chaque classe d'étiquettes soit considérée comme une étiquette de classe et que chaque image soit traitée comme une caractéristique d'image.
Nous allons créer deux ensembles de données : un pour l'entraînement et un pour les tests. Enfin, nous les combinerons en un seul ensemble de données contenant à la fois des sous-ensembles d'entraînement et de test.
# Encode labels
classes = sorted(list(set(classes)))
label2id = {name: i for i, name in enumerate(classes)}
for rec in train_records:
rec["label"] = label2id[rec["label_name"]]
for rec in test_records:
rec["label"] = label2id[rec["label_name"]]
features = Features(
{
"image": Image(),
"label": ClassLabel(names=classes),
}
)
train_ds = Dataset.from_list(
[{"image": r["image"], "label": r["label"]} for r in train_records],
features=features,
)
test_ds = Dataset.from_list(
[{"image": r["image"], "label": r["label"]} for r in test_records],
features=features,
)
data = DatasetDict({"train": train_ds, "test": test_ds})
dataVoici un aperçu de l'ensemble de données.
DatasetDict({
train: Dataset({
features: ['image', 'label'],
num_rows: 989
})
test: Dataset({
features: ['image', 'label'],
num_rows: 140
})
})Avant de procéder au réglage fin, il est utile de comprendre dans quelle mesure l'ensemble de données est équilibré et à quoi ressemblent les images. Nous commencerons par vérifier le nombre d'échantillons d'entraînement existants pour chaque catégorie de fracture.
from collections import Counter
label_names = data["train"].features["label"].names
label_ids = data["train"]["label"]
counts = Counter(label_ids)
print("Training Class counts:")
for lbl_id, cnt in counts.items():
print(f"{lbl_id:2d} ({label_names[lbl_id]}): {cnt}")
FRACTURE_CLASSES = label_namesLes catégories sont relativement équilibrées, bien que la taille globale de l'échantillon soit réduite pour une tâche complexe de classification visuelle.
Pour l'instant, nous allons poursuivre avec cet ensemble de données, mais les résultats doivent être interprétés avec des attentes réalistes en raison du volume limité de l'échantillon.
Training Class counts:
0 (Avulsion fracture): 109
1 (Comminuted fracture): 134
2 (Fracture Dislocation): 137
3 (Greenstick fracture): 106
4 (Hairline Fracture): 101
5 (Impacted fracture): 75
6 (Longitudinal fracture): 68
7 (Oblique fracture): 69
8 (Pathological fracture): 116
9 (Spiral Fracture): 74
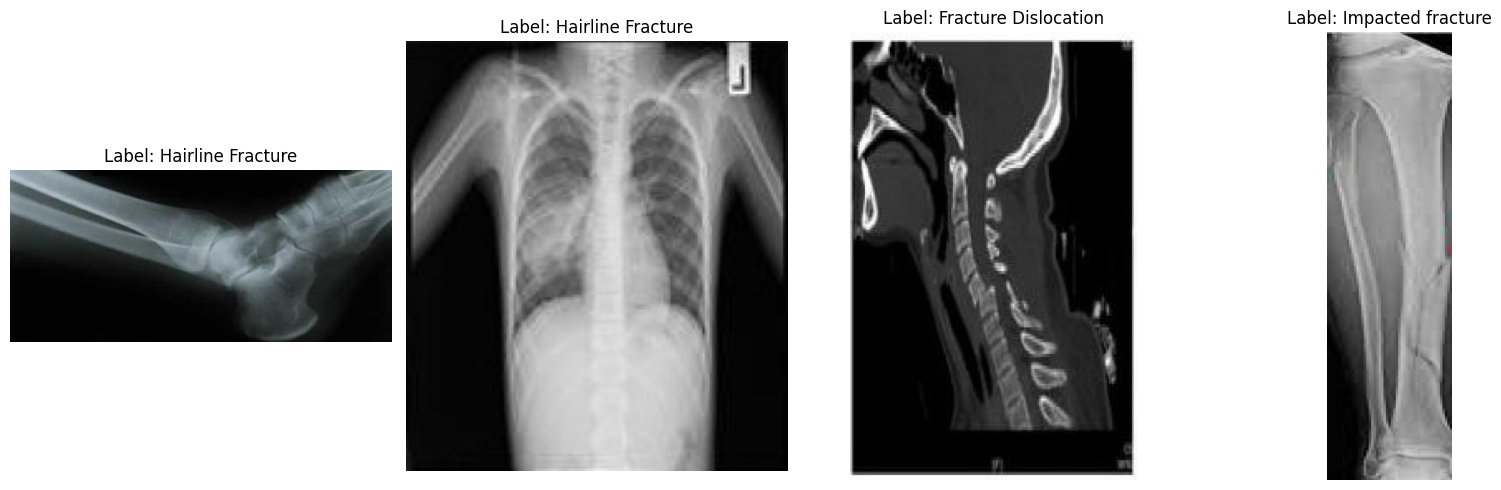
Ensuite, examinons quelques images aléatoires afin de mieux appréhender visuellement l'ensemble de données.
import matplotlib.pyplot as plt
from datasets import Image
# Cast the 'image' column to Hugging Face Image feature
dataset_images = data.cast_column("image", Image())
# Select random samples from the training set
samples = dataset_images["train"].shuffle(seed=420).select(range(4))
# Plot
fig, axes = plt.subplots(1, 4, figsize=(16, 5))
for i, sample in enumerate(samples):
img_object = sample["image"] # PIL Image
label_id = sample["label"] # int
label_name = label_names[label_id] # string
axes[i].imshow(img_object)
axes[i].set_title(f"Label: {label_name}")
axes[i].axis("off")
plt.tight_layout()
plt.show()En examinant les exemples d'images, nous pouvons observer des différences en termes de taille, de résolution, d'orientation et de qualité de numérisation. Cela n'affecte pas le réglage fin d'un modèle de langage visuel, mais peut influencer la cohérence avec laquelle le modèle apprend chaque catégorie de fracture.
La détection visuelle d'une fracture est souvent simple, mais sa classification parmi les dix types de fractures médicales subtiles nécessite des données plus structurées que celles fournies ici.
Ensuite, nous devons déterminer comment nous souhaitons que le modèle se comporte. Pour cette tâche, notre objectif est très strict : à partir d'une image radiographique, le modèle doit fournir uniquement le nom d'une classe de fracture et rien d'autre. Aucune explication, aucune réduction, aucun texte supplémentaire.
Nous rédigerons une instruction claire, puis l'utiliserons pour créer une colonne d' messages s dans l'ensemble de données.
PROMPT = f"""
You are a radiology assistant specialised in bone fracture classification.
You must classify the X-ray image into exactly ONE of the following classes:
{", ".join(FRACTURE_CLASSES)}
Rules:
- Reply with ONLY the class name.
- No explanations, no extra words, no markdown, no punctuation.
- Output must be EXACTLY one of: {", ".join(FRACTURE_CLASSES)}
""".strip()
from typing import Dict, Any
def convert_to_conversation(example: Dict[str, Any]) -> Dict[str, Any]:
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": PROMPT},
{"type": "image"}, # no image bytes here
],
},
{
"role": "assistant",
"content": [
{"type": "text", "text": FRACTURE_CLASSES[example["label"]]},
],
},
]
example["messages"] = conversation
return example
formatted_data = data["train"].map(convert_to_conversation)
formatted_data["messages"][0]Cela crée une colonne « messages » dans laquelle chaque enregistrement contient désormais une mini-conversation complète : l'instruction et la classe de fracture correcte. C'est précisément ce que le modèle linguistique de vision percevra lors du réglage fin.

Nous chargeons maintenant la version BF16 du modèle Ministral-3 14B Instruct depuis Hugging Face Hub, ainsi que le processeur. Le processeur regroupe le tokeniseur et le pipeline de prétraitement des images, qui est nécessaire pour les entrées de langage visuel.
import torch
from transformers import AutoProcessor, AutoModelForImageTextToText, BitsAndBytesConfig
model_id = "mistralai/Ministral-3-14B-Instruct-2512-BF16"
model_kwargs = dict(
attn_implementation="eager",
torch_dtype=torch.bfloat16,
device_map="auto",
)
model = AutoModelForImageTextToText.from_pretrained(model_id, **model_kwargs)
processor = AutoProcessor.from_pretrained(model_id)
# Use right padding to avoid issues during training
processor.tokenizer.padding_side = "right"Le modèle de chat original fourni par Mistral AI est conçu pour des cas d'utilisation conversationnels de longue durée. Pour ce projet, cela a posé un problème. Le modèle a commencé à se concentrer sur les longues instructions et le texte du système, et a ignoré l'objectif réel, qui est de prédire une seule classe de fracture osseuse à partir de la radiographie.
Pour remédier à cela, nous définissons un modèle de langage visuel plus court qui ne conserve que les éléments essentiels : les instructions de l'utilisateur et la réponse de l'assistant. Cela réduit le bruit et aide le modèle à apprendre un mappage clair entre l'image et l'étiquette de classe.
SHORT_VLM_TEMPLATE = r"""{{ bos_token }}[INST]
{% for message in messages if message['role'] == 'user' -%}
{%- for content in message['content'] -%}
{%- if content['type'] == 'text' -%}
{{ content['text'] }}
{%- elif content['type'] == 'image' -%}
[IMG]
{%- endif -%}
{%- endfor -%}
{%- endfor -%}
[/INST]{% if not add_generation_prompt %}
{%- for message in messages if message['role'] == 'assistant' -%}
{{ message['content'][0]['text'] }}{{ eos_token }}
{%- endfor -%}
{%- endif %}"""
# Attach to processor / tokenizer
processor.chat_template = SHORT_VLM_TEMPLATE
processor.tokenizer.chat_template = SHORT_VLM_TEMPLATEAvant de procéder aux réglages fins, il est recommandé de tester le modèle Ministral 3 14B Instruct d'origine afin d'établir une base de référence.
Tout d'abord, nous fournissons au modèle une image aléatoire issue de l'ensemble de données et lui posons une question générale, simplement pour évaluer sa capacité à comprendre le contenu de la radiographie.
image = formatted_data[200]["image"]
messages = [
{"role": "user", "content": [
{"type": "text", "text": "What is the image about?"},
{"type": "image"},
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt = True)
inputs = processor(
image,
input_text,
add_special_tokens = False,
return_tensors = "pt",
).to(device="cuda", dtype=torch.bfloat16)
from transformers import TextStreamer
text_streamer = TextStreamer(processor, skip_prompt = True)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 1000,
use_cache = True, temperature = 1.5, min_p = 0.1)En conséquence, le modèle a compris le contenu général de la radiographie, mais a ensuite dérivé vers des descriptions qui n'étaient pas fiables à des fins médicales.

Ensuite, nous tentons une approche plus proche de notre objectif final. Nous présentons la même image, mais cette fois-ci, nous utilisons notre classification stricte des fractures au lieu d'une question ouverte.
image = formatted_data[200]["image"]
messages = [
{"role": "user", "content": [
{"type": "text", "text": PROMPT},
{"type": "image"},
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt = True)
inputs = processor(
image,
input_text,
add_special_tokens = False,
return_tensors = "pt",
).to(device="cuda", dtype=torch.bfloat16)
from transformers import TextStreamer
text_streamer = TextStreamer(processor, skip_prompt = True)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 1000,
use_cache = True, temperature = 1.5, min_p = 0.1Pour cet échantillon, le modèle a répondu :
Hairline Fracture</s>Nous vérifions maintenant l'étiquette de vérité terrain réelle pour la même image.
FRACTURE_CLASSES[formatted_data[200]["label"]]Cela renvoie :
'Comminuted fracture'Ainsi, le modèle a correctement suivi le format des instructions et a produit un nom de classe unique, mais la classification elle-même était incorrecte.
C'est précisément pour cette raison que nous avons besoin d'un ajustement. Le modèle de base dispose d'une excellente compréhension visuelle, mais il n'a pas été spécifiquement formé pour distinguer les différents types de fractures osseuses.
Dans les prochaines étapes, nous procéderons à des ajustements sur notre ensemble de données relatives aux fractures afin d'améliorer ce comportement.
Ensuite, nous avons configuré LoRA afin d'ajuster efficacement le modèle Ministral 3 sans mettre à jour tous les paramètres. Cette configuration cible les couches d'attention principale et de projection MLP utilisées dans un modèle de vision-langage de type Mistral.
from peft import LoraConfig, TaskType, get_peft_model
# LoRA config for a Mistral-style VLM used as a causal LM
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
modules_to_save=None,
)Ensuite, nous définissons les arguments d'entraînement du réglage fin supervisé (SFT).
Cette configuration contrôle l'ensemble du processus d'entraînement, y compris la gestion des lots, l'optimisation de la mémoire, le comportement du taux d'apprentissage, la journalisation, la stratégie d'enregistrement et l'intégration avec Hugging Face Hub.
from trl import SFTConfig
args = SFTConfig(
output_dir="ministral-3-bone-fracture",
num_train_epochs=1,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
optim="adamw_8bit",
logging_steps=0.1,
save_strategy="epoch",
learning_rate=2e-4,
bf16=True,
fp16=False,
max_grad_norm=0.3,
warmup_steps=25,
lr_scheduler_type="linear",
push_to_hub=True,
report_to="none",
gradient_checkpointing_kwargs={"use_reentrant": False},
dataset_kwargs={"skip_prepare_dataset": True},
remove_unused_columns = False,
label_names=["labels"],
)Pour affiner un modèle de vision-langage tel que Ministral 3, nous avons besoin d'un collecteur de données personnalisé capable de regrouper des images et du texte de type conversationnel dans un format cohérent.
Le collateur ci-dessous se charge de : configurer le tokenizer et le pad token, appliquer le modèle de chat, tokeniser conjointement le texte et les images, appliquer une longueur maximale de séquence sécurisée et créer des étiquettes où les tokens de remplissage et d'image sont masqués (-100) afin qu'ils n'affectent pas la perte.
from typing import Any, Dict, List
import torch
# --- One-time processor setup ---
tokenizer = processor.tokenizer
tokenizer.padding_side = "right"
# Ensure we have a pad token
if tokenizer.pad_token is None:
tokenizer.add_special_tokens({"pad_token": tokenizer.eos_token})
pad_token_id = tokenizer.pad_token_id
image_token_id = getattr(processor, "image_token_id", None)
# Hard cap for sequence length
MAX_SEQ_LEN = 2048
def collate_fn(examples: List[Dict[str, Any]]) -> Dict[str, torch.Tensor]:
"""
Collate function for VLM fine-tuning.
Each example must contain:
- "image": a PIL image
- "messages": chat-style conversation (list[dict])
"""
images = [ex["image"] for ex in examples]
conversations = [ex["messages"] for ex in examples]
# Build chat prompts for the whole batch
chat_texts = processor.apply_chat_template(
conversations,
add_generation_prompt=False,
tokenize=False,
)
# Tokenize + process images
batch = processor(
text=chat_texts,
images=images,
padding="longest",
truncation=True,
max_length=MAX_SEQ_LEN,
return_tensors="pt",
)
# Labels: same as input_ids but mask pad & image tokens
labels = batch["input_ids"].clone()
if pad_token_id is not None:
labels[labels == pad_token_id] = -100
if image_token_id is not None and image_token_id != pad_token_id:
labels[labels == image_token_id] = -100
batch["labels"] = labels
return batchUne fois l'adaptateur LoRA, la configuration de formation et le collecteur de données prêts, nous pouvons maintenant connecter l'ensemble au SFTTrainer de trl.
Ce formateur gère l'ensemble du cycle de réglage fin supervisé pour notre modèle Ministral 3 de vision-langage, en utilisant notre ensemble de données formaté, la configuration LoRA et une fonction de collationnement personnalisée pour les lots d'images et de textes.
from trl import SFTTrainer
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=formatted_data,
peft_config=peft_config,
processing_class=processor,
data_collator=collate_fn,
)Veuillez exécuter le code ci-dessous pour démarrer le processus de formation.
trainer.train()Au cours de mon exécution, le réglage fin a utilisé environ 57 Go de VRAM, et un peu plus lors des étapes d'évaluation qui s'exécutent toutes les quelques itérations. En pratique, cela signifie que vous pouvez facilement ajuster cette configuration sur du matériel disposant de moins de 70 Go de VRAM.
La formation complète a duré environ une demi-heure, et la perte de formation a diminué progressivement au fil du temps, ce qui est un signe encourageant indiquant que le modèle apprend à partir de l'ensemble de données.
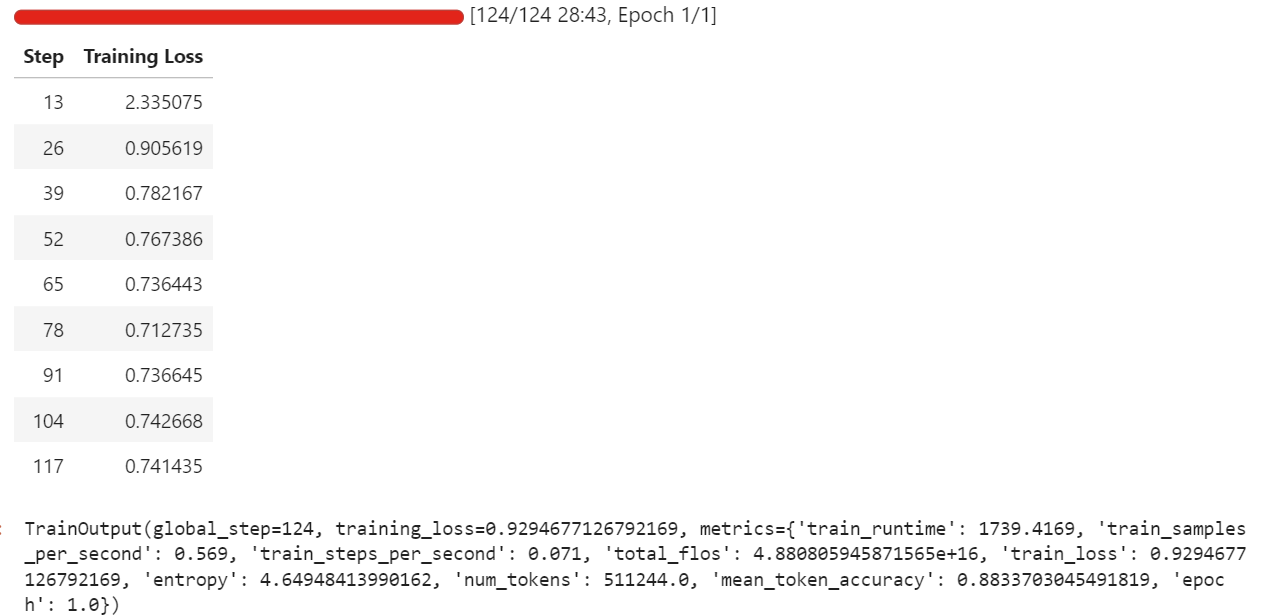
Une fois la formation terminée, nous enregistrons le modèle adapté sur le Hugging Face Hub. Cela créera un nouveau référentiel et transférera tous les fichiers requis afin que vous puissiez recharger et exécuter le modèle optimisé depuis n'importe quel environnement.
trainer.save_model()Vous pouvez consulter le modèle à l'adresse suivante : kingabzpro/ministral-3-bone-fracture.
Nous chargeons maintenant le modèle et le processeur optimisés à partir du Hugging Face Hub. En arrière-plan, cela permettra de télécharger l'adaptateur LoRA enregistré, de charger le point de contrôle de base Ministral 3 et de fusionner l'adaptateur dans le modèle de base afin qu'il soit prêt pour l'inférence.
import torch
from transformers import AutoProcessor, AutoModelForImageTextToText, BitsAndBytesConfig
model_id = "kingabzpro/ministral-3-bone-fracture"
model_kwargs = dict(
attn_implementation="eager",
dtype=torch.bfloat16,
device_map="auto",
)
model = AutoModelForImageTextToText.from_pretrained(model_id, **model_kwargs)
processor = AutoProcessor.from_pretrained(model_id)
processor.tokenizer.padding_side = "left"Afin de garantir l'équité de la comparaison, nous réutilisons d'abord la même image que celle que nous avons testée avant le réglage fin (index 200) et la soumettons au pipeline d'inférence avec notre invite de classification stricte.
image = formatted_data[200]["image"]
messages = [
{"role": "user", "content": [
{"type": "text", "text": PROMPT},
{"type": "image"},
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt = True)
inputs = processor(
image,
input_text,
add_special_tokens = False,
return_tensors = "pt",
).to(device="cuda", dtype=torch.bfloat16)
from transformers import TextStreamer
text_streamer = TextStreamer(processor, skip_prompt = True)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 100)Nous avons obtenu un résultat parfait. Aucun post-traitement supplémentaire n'a été nécessaire. Le modèle a respecté les règles de prompt et a directement produit la classe correcte.
Comminuted fracture</s>Ensuite, nous essayons un autre échantillon aléatoire tiré de l'ensemble de données afin de confirmer que ce comportement ne se limite pas à un seul exemple.
image = formatted_data[400]["image"]
messages = [
{"role": "user", "content": [
{"type": "text", "text": PROMPT},
{"type": "image"},
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt = True)
inputs = processor(
image,
input_text,
add_special_tokens = False,
return_tensors = "pt",
).to(device="cuda", dtype=torch.bfloat16)
from transformers import TextStreamer
text_streamer = TextStreamer(processor, skip_prompt = True)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 100)Résultats du modèle :
Greenstick fracture</s>Vérité terrain :
FRACTURE_CLASSES[formatted_data[400]["label"]]Résultat :
'Greenstick fracture'Une fois de plus, la prévision est correcte et parfaitement conforme à l'étiquette.
Grâce à ces vérifications, nous pouvons affirmer que notre modèle Ministral 3 14B a été optimisé avec succès sur l'ensemble de données de radiographies de fractures osseuses et qu'il est désormais capable de suivre les instructions et de produire des prédictions précises à classe unique pour ces exemples.
Le réglage précis du modèle Ministral 3 nécessite de la patience et des ajustements réguliers. Il m'a véritablement fallu deux jours complets pour comprendre pourquoi le modèle ne s'entraînait pas comme je l'avais prévu et pourquoi, bien qu'il s'agisse d'un modèle relativement petit, il provoquait tout de même des erreurs de mémoire insuffisante sur mon GPU.
La raison principale était simple, mais facile à négliger. Il ne s'agit pas seulement d'un modèle linguistique. Il s'agit d'un modèle linguistique visuel, ce qui signifie qu'il intègre un encodeur d'images qui augmente la consommation de mémoire.
Une résolution d'image plus élevée entraîne directement une consommation plus importante de mémoire vidéo. Réduire la taille des images ou commencer par des lots plus petits rend le processus d'apprentissage beaucoup plus stable.
Un autre problème que j'ai rencontré concernait l'utilisation du modèle de chat par défaut. Il était beaucoup trop long et structuré pour ce type de tâche. Le modèle consacrait davantage d'efforts à l'ajustement du formatage du modèle qu'à l'apprentissage de la lecture des images et à la production d'une classification claire des fractures.
Une fois que j'ai simplifié l'invite en un format d'instruction directe, le modèle a finalement commencé à répondre correctement à l'entrée visuelle au lieu de formuler chaque réponse comme une réponse de chat complète.
J'ai également supposé que, comme le modèle dispose de solides capacités de vision, il serait naturellement performant pour les scans médicaux. Cette hypothèse m'a ralenti. L'appeler « MedGemma » dans mon esprit n'était pas équitable envers le modèle ou le processus. Il ne s'agit pas d'un modèle médical spécialisé prêt à l'emploi, et j'ai commis l'erreur de m'attendre à ce qu'il se comporte comme tel sans formation adéquate.
Finalement, j'ai surmonté chaque obstacle et j'ai transformé ce que j'ai appris en ce guide. L'objectif est de vous aider à éviter la même confusion et d'obtenir plus rapidement des résultats significatifs.
« Grâce à des images plus petites, des invites plus simples et des attentes réalistes, Ministral 3 peut être ajusté pour une compréhension des radiographies de manière beaucoup plus fluide et fiable. »
Si vous souhaitez acquérir davantage d'expérience pratique en matière de réglage fin, je vous recommande le cours cours « Réglage fin avec Llama 3 ».
Meilleurs cours DataCamp
Cours
Cours
Cours