
Curso
Fine-Tuning with Llama 3
2 h
3.7K
O Ministral 3 é uma nova família de modelos multimodais otimizados para borda, disponíveis nos tamanhos 3B, 8B e 14B, cada um oferecendo variantes Base, Instruct e Reasoning com suporte total para visão.
Feito pra oferecer um desempenho top de linha, mas leve o suficiente pra usar em lugares locais e particulares, o Ministral 3 combina recursos avançados com limitações práticas de hardware. Seu modelo principal, o 14B Instruct, tem 24 GB de VRAM em FP8 e compete com sistemas maiores, como o Mistral Small 3.2 24B. Com uma janela de contexto grande de 256k, cobertura multilíngue robusta, chamada de função nativa, forte adesão ao prompt do sistema e licença aberta Apache 2.0.
Neste tutorial, vamos ajustar o modelo Ministral 3 14B Instruct em um conjunto de dados de raios-X de fraturas ósseas para melhorar sua capacidade de detectar fraturas e classificar suas categorias com precisão.
Você vai aprender como:
Se você quer saber mais sobre os modelos de IA da Mistral, recomendo nosso guia Mistral 3 e tutorial do Mistral 3 Large.
Isenção de responsabilidade: Este tutorial mostra um processo de ajuste técnico só para fins educacionais. O modelo que saiu é enão é pra serusado pra fins médicos ou clínicos, então não dá pra confiar nele pra fazer diagnósticos, tomar decisões ou cuidar de pacientes.
Mesmo que estejamos ajustando o modelo 14B, o treinamento de linguagem visual precisa de muito mais memória do que o ajuste só de texto. O codificador de imagem aumenta a carga da GPU, o que significa que precisamos de uma GPU A100 com 80 GB de VRAM para rodar esse processo sem problemas.
Para esse projeto, estou usando o Runpod e lançando um pod A100.
Depois de lançar o pod, aumente o armazenamento do contêiner para 50 GB. Depois, adiciona as variáveis de ambiente para as chaves API do Kaggle e do Hugging Face.
O Kaggle vai deixar a gente baixar o conjunto de dados de raios-X dos ossos direto, e o Hugging Face vai deixar a gente mandar nosso adaptador LoRA ajustado de volta pro hub do modelo.
Depois, abra a instância do JupyterLab e crie um caderno novo. Antes do treinamento, precisamos instalar todos os pacotes Python necessários.
Certifique-se de que a biblioteca Transformers esteja atualizada para a versão mais recente, porque o suporte ao Ministral 3 foi adicionado recentemente e as versões mais antigas não carregam o modelo corretamente.
! pip install --upgrade --quiet bitsandbytes datasets evaluate hf_transfer peft scikit-learn matplotlib Pillow kaggle ipywidgets
!pip install --quiet git+https://github.com/huggingface/transformers.git@bf3f0ae70d0e902efab4b8517fce88f6697636ce
!pip install --quiet --no-deps trl==0.22.2Depois que tudo estiver instalado, você estará pronto para carregar o conjunto de dados, preparar o classificador e começar o ajuste fino.
Na próxima etapa, vamos criar uma pasta raiz para o nosso conjunto de dados e usar a API Python do Kaggle para baixar o conjunto de dados Bone Break Classification Image.
Esse conjunto de dados tem várias categorias de fraturas ósseas em formato de raio-X e vai ser usado pra ajustar o Ministral 3 pra classificação visual.
import os
import glob
from kaggle.api.kaggle_api_extended import KaggleApi
DATA_ROOT = "/bone-break"
os.makedirs(DATA_ROOT, exist_ok=True)
kaggle_dataset = "pkdarabi/bone-break-classification-image-dataset"
# Initialize and authenticate Kaggle API (it will read KAGGLE_USERNAME / KAGGLE_KEY)
api = KaggleApi()
api.authenticate()
# Download and unzip the dataset using the Python API
api.dataset_download_files(
kaggle_dataset,
path=DATA_ROOT,
unzip=True,
)Você pode ver o conjunto de dados no Kaggle aqui:
Dataset URL: https://www.kaggle.com/datasets/pkdarabi/bone-break-classification-image-datasetO conjunto de dados baixado não está organizado na estrutura normal. Cada categoria de fratura tem uma pasta de treinamento e uma pasta de teste dentro dela.
Então, primeiro, precisamos de um jeito de percorrer todas as pastas de classes, separar as duas divisões e, em seguida, criar um conjunto de dados combinado do Hugging Face com um mapeamento limpo de treinamento e teste.
import glob, os
from typing import Any, Dict, List
from datasets import Dataset, DatasetDict, Features, ClassLabel, Image
inner_root = os.path.join(
DATA_ROOT, "Bone Break Classification", "Bone Break Classification"
)
classes = []
train_records: List[Dict[str, Any]] = []
test_records: List[Dict[str, Any]] = []
for class_name in sorted(os.listdir(inner_root)):
class_dir = os.path.join(inner_root, class_name)
if not os.path.isdir(class_dir):
continue
classes.append(class_name)
for split_name, split_key in [("Train", "train"), ("Test", "test")]:
split_dir = os.path.join(class_dir, split_name)
if not os.path.isdir(split_dir):
continue
for ext in ("*.png", "*.jpg", "*.jpeg"):
for img_path in glob.glob(os.path.join(split_dir, ext)):
rec = {"image": img_path, "label_name": class_name}
if split_key == "train":
train_records.append(rec)
else:
test_records.append(rec)
print("Classes:", classes)
print("Train samples:", len(train_records))
print("Test samples:", len(test_records))Temos um total de 10 classificações, com 989 amostras de treinamento e 140 amostras de teste.
Classes: ['Avulsion fracture', 'Comminuted fracture', 'Fracture Dislocation', 'Greenstick fracture', 'Hairline Fracture', 'Impacted fracture', 'Longitudinal fracture', 'Oblique fracture', 'Pathological fracture', 'Spiral Fracture']
Train samples: 989
Test samples: 140Agora vamos codificar os rótulos para o conjunto de dados Hugging Face, de modo que cada classe de rótulo seja considerada como rótulos de classe e cada imagem seja tratada como características da imagem.
Vamos criar dois conjuntos de dados: um para treinamento e outro para teste. Por fim, vamos juntar tudo num único conjunto de dados que tem tanto os subconjuntos de treinamento quanto os de teste.
# Encode labels
classes = sorted(list(set(classes)))
label2id = {name: i for i, name in enumerate(classes)}
for rec in train_records:
rec["label"] = label2id[rec["label_name"]]
for rec in test_records:
rec["label"] = label2id[rec["label_name"]]
features = Features(
{
"image": Image(),
"label": ClassLabel(names=classes),
}
)
train_ds = Dataset.from_list(
[{"image": r["image"], "label": r["label"]} for r in train_records],
features=features,
)
test_ds = Dataset.from_list(
[{"image": r["image"], "label": r["label"]} for r in test_records],
features=features,
)
data = DatasetDict({"train": train_ds, "test": test_ds})
dataAqui está uma visão geral do conjunto de dados.
DatasetDict({
train: Dataset({
features: ['image', 'label'],
num_rows: 989
})
test: Dataset({
features: ['image', 'label'],
num_rows: 140
})
})Antes de ajustar tudo, é legal entender como o conjunto de dados está equilibrado e como são as imagens. Vamos começar verificando quantas amostras de treinamento existem para cada categoria de fratura.
from collections import Counter
label_names = data["train"].features["label"].names
label_ids = data["train"]["label"]
counts = Counter(label_ids)
print("Training Class counts:")
for lbl_id, cnt in counts.items():
print(f"{lbl_id:2d} ({label_names[lbl_id]}): {cnt}")
FRACTURE_CLASSES = label_namesAs categorias estão bem equilibradas, embora o tamanho geral da amostra seja pequeno para uma tarefa complexa de classificação visual.
Por enquanto, vamos continuar com esse conjunto de dados, mas os resultados devem ser interpretados com expectativas realistas, já que a amostra é pequena.
Training Class counts:
0 (Avulsion fracture): 109
1 (Comminuted fracture): 134
2 (Fracture Dislocation): 137
3 (Greenstick fracture): 106
4 (Hairline Fracture): 101
5 (Impacted fracture): 75
6 (Longitudinal fracture): 68
7 (Oblique fracture): 69
8 (Pathological fracture): 116
9 (Spiral Fracture): 74
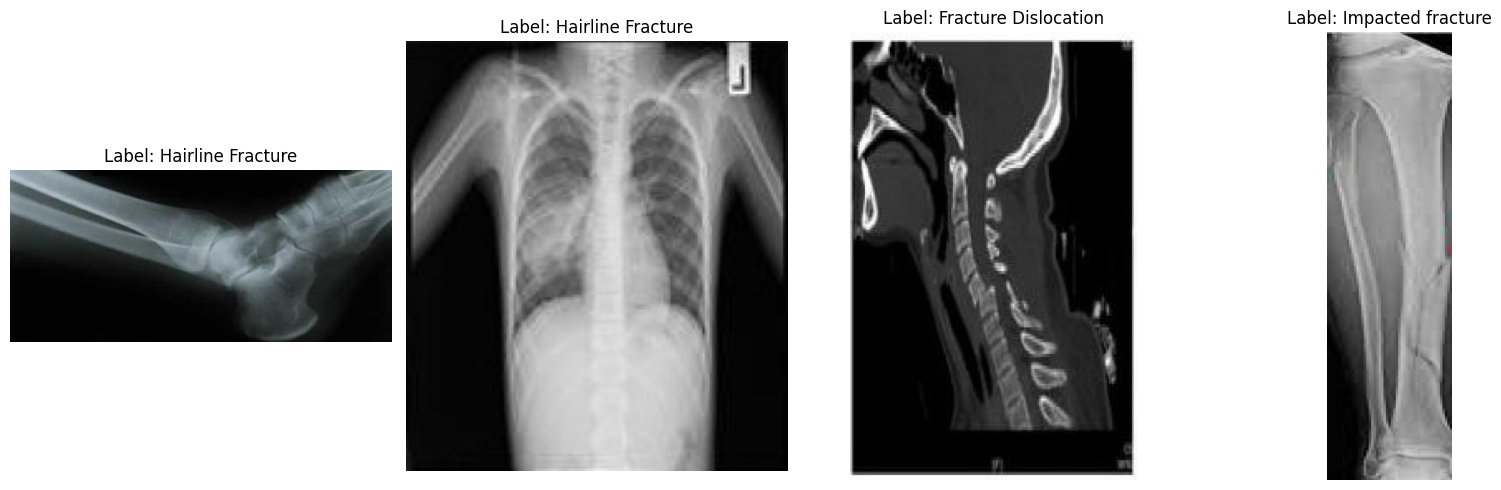
Agora, vamos dar uma olhada em algumas imagens aleatórias pra entender melhor o conjunto de dados visualmente.
import matplotlib.pyplot as plt
from datasets import Image
# Cast the 'image' column to Hugging Face Image feature
dataset_images = data.cast_column("image", Image())
# Select random samples from the training set
samples = dataset_images["train"].shuffle(seed=420).select(range(4))
# Plot
fig, axes = plt.subplots(1, 4, figsize=(16, 5))
for i, sample in enumerate(samples):
img_object = sample["image"] # PIL Image
label_id = sample["label"] # int
label_name = label_names[label_id] # string
axes[i].imshow(img_object)
axes[i].set_title(f"Label: {label_name}")
axes[i].axis("off")
plt.tight_layout()
plt.show()Olhando para as imagens de amostra, podemos ver diferenças em tamanho, resolução, orientação e qualidade de digitalização. Isso não afeta o ajuste fino de um modelo de linguagem visual, mas pode influenciar a consistência com que o modelo aprende cada categoria de fratura.
Detectar uma fratura visualmente é geralmente fácil, mas classificá-la em um dos dez tipos médicos sutis de fratura precisa de dados mais organizados do que os que estão aqui.
Depois, precisamos decidir como queremos que o modelo se comporte. Pra essa tarefa, nosso objetivo é bem rígido: dada uma imagem de raio-X, o modelo deve gerar só o nome de uma classe de fratura e nada mais. Sem explicações, sem descontos, sem texto extra.
Vamos escrever uma instrução clara e usá-la para criar uma coluna “ messages ” no conjunto de dados.
PROMPT = f"""
You are a radiology assistant specialised in bone fracture classification.
You must classify the X-ray image into exactly ONE of the following classes:
{", ".join(FRACTURE_CLASSES)}
Rules:
- Reply with ONLY the class name.
- No explanations, no extra words, no markdown, no punctuation.
- Output must be EXACTLY one of: {", ".join(FRACTURE_CLASSES)}
""".strip()
from typing import Dict, Any
def convert_to_conversation(example: Dict[str, Any]) -> Dict[str, Any]:
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": PROMPT},
{"type": "image"}, # no image bytes here
],
},
{
"role": "assistant",
"content": [
{"type": "text", "text": FRACTURE_CLASSES[example["label"]]},
],
},
]
example["messages"] = conversation
return example
formatted_data = data["train"].map(convert_to_conversation)
formatted_data["messages"][0]Isso cria uma coluna “ messages ” (Fratura/Classe), onde cada registro agora tem uma mini conversa completa: a instrução mais a classe de fratura correta. É exatamente isso que o modelo de linguagem de visão vai ver durante o ajuste fino.

Agora vamos carregar a versão BF16 do modelo Ministral-3 14B Instruct do Hugging Face Hub, junto com o processador. O processador junta o tokenizador e o pipeline de pré-processamento de imagens, que é necessário para entradas de linguagem visual.
import torch
from transformers import AutoProcessor, AutoModelForImageTextToText, BitsAndBytesConfig
model_id = "mistralai/Ministral-3-14B-Instruct-2512-BF16"
model_kwargs = dict(
attn_implementation="eager",
torch_dtype=torch.bfloat16,
device_map="auto",
)
model = AutoModelForImageTextToText.from_pretrained(model_id, **model_kwargs)
processor = AutoProcessor.from_pretrained(model_id)
# Use right padding to avoid issues during training
processor.tokenizer.padding_side = "right"O modelo de chat original fornecido pela Mistral AI foi feito pra conversas longas. Para esse projeto, isso virou um problema. O modelo começou a se concentrar nas instruções longas e no texto do sistema, e ignorou o objetivo real, que é prever uma única classe de fratura óssea a partir do raio-X.
Para resolver isso, criamos um modelo de linguagem de visão mais curto que só mantém as partes importantes: a instrução do usuário e a resposta do assistente. Isso reduz o ruído e ajuda o modelo a aprender um mapeamento limpo da imagem para o rótulo da classe.
SHORT_VLM_TEMPLATE = r"""{{ bos_token }}[INST]
{% for message in messages if message['role'] == 'user' -%}
{%- for content in message['content'] -%}
{%- if content['type'] == 'text' -%}
{{ content['text'] }}
{%- elif content['type'] == 'image' -%}
[IMG]
{%- endif -%}
{%- endfor -%}
{%- endfor -%}
[/INST]{% if not add_generation_prompt %}
{%- for message in messages if message['role'] == 'assistant' -%}
{{ message['content'][0]['text'] }}{{ eos_token }}
{%- endfor -%}
{%- endif %}"""
# Attach to processor / tokenizer
processor.chat_template = SHORT_VLM_TEMPLATE
processor.tokenizer.chat_template = SHORT_VLM_TEMPLATEAntes de começarmos o ajuste fino, é legal testar o modelo original Ministral 3 14B Instruct para criar uma linha de base.
Primeiro, a gente dá pro modelo uma imagem aleatória do conjunto de dados e faz uma pergunta geral, só pra ver como ele entende o conteúdo do raio-X.
image = formatted_data[200]["image"]
messages = [
{"role": "user", "content": [
{"type": "text", "text": "What is the image about?"},
{"type": "image"},
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt = True)
inputs = processor(
image,
input_text,
add_special_tokens = False,
return_tensors = "pt",
).to(device="cuda", dtype=torch.bfloat16)
from transformers import TextStreamer
text_streamer = TextStreamer(processor, skip_prompt = True)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 1000,
use_cache = True, temperature = 1.5, min_p = 0.1)Por causa disso, o modelo entendeu o conteúdo geral do raio X, mas depois acabou fazendo descrições que não eram confiáveis para uso médico.

Depois, vamos tentar algo mais próximo do nosso objetivo final. A gente dá a mesma imagem, mas dessa vez a gente usa nossa classificação rígida de fraturas em vez de uma pergunta aberta.
image = formatted_data[200]["image"]
messages = [
{"role": "user", "content": [
{"type": "text", "text": PROMPT},
{"type": "image"},
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt = True)
inputs = processor(
image,
input_text,
add_special_tokens = False,
return_tensors = "pt",
).to(device="cuda", dtype=torch.bfloat16)
from transformers import TextStreamer
text_streamer = TextStreamer(processor, skip_prompt = True)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 1000,
use_cache = True, temperature = 1.5, min_p = 0.1Para essa amostra, o modelo respondeu com:
Hairline Fracture</s>Agora vamos conferir o rótulo real da verdade fundamental para a mesma imagem.
FRACTURE_CLASSES[formatted_data[200]["label"]]Isso retorna:
'Comminuted fracture'Então, o modelo seguiu o formato da instrução direitinho e criou um único nome de classe, mas a classificação em si estava errada.
É exatamente por isso que precisamos de ajustes. O modelo básico tem uma boa compreensão visual, mas não foi treinado especificamente para distinguir entre tipos detalhados de fraturas ósseas.
Nas próximas etapas, vamos ajustar isso no nosso conjunto de dados de fraturas para melhorar esse comportamento.
Depois, a gente configura o LoRA para ajustar o modelo Ministral 3 de forma eficiente, sem atualizar todos os parâmetros. Essa configuração foca nas principais camadas de atenção e projeção MLP usadas em um modelo de visão-linguagem do tipo Mistral.
from peft import LoraConfig, TaskType, get_peft_model
# LoRA config for a Mistral-style VLM used as a causal LM
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
modules_to_save=None,
)Depois, vamos definir os argumentos de treinamento de ajuste fino supervisionado (SFT).
Essa configuração controla todo o processo de treinamento, incluindo como os lotes são tratados, otimização de memória, comportamento da taxa de aprendizagem, registro, estratégia de salvamento e integração com o Hugging Face Hub.
from trl import SFTConfig
args = SFTConfig(
output_dir="ministral-3-bone-fracture",
num_train_epochs=1,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
optim="adamw_8bit",
logging_steps=0.1,
save_strategy="epoch",
learning_rate=2e-4,
bf16=True,
fp16=False,
max_grad_norm=0.3,
warmup_steps=25,
lr_scheduler_type="linear",
push_to_hub=True,
report_to="none",
gradient_checkpointing_kwargs={"use_reentrant": False},
dataset_kwargs={"skip_prepare_dataset": True},
remove_unused_columns = False,
label_names=["labels"],
)Pra ajustar um modelo de visão-linguagem como o Ministral 3, a gente precisa de um coletor de dados personalizado que possa juntar imagens e textos tipo bate-papo num formato consistente.
O classificador abaixo cuida de: configurar o tokenizador e o token de preenchimento, aplicar o modelo de chat, tokenizar texto e imagens juntos, garantir um comprimento máximo seguro da sequência e criar rótulos onde os tokens de preenchimento e imagem são mascarados (-100) para que não afetem a perda.
from typing import Any, Dict, List
import torch
# --- One-time processor setup ---
tokenizer = processor.tokenizer
tokenizer.padding_side = "right"
# Ensure we have a pad token
if tokenizer.pad_token is None:
tokenizer.add_special_tokens({"pad_token": tokenizer.eos_token})
pad_token_id = tokenizer.pad_token_id
image_token_id = getattr(processor, "image_token_id", None)
# Hard cap for sequence length
MAX_SEQ_LEN = 2048
def collate_fn(examples: List[Dict[str, Any]]) -> Dict[str, torch.Tensor]:
"""
Collate function for VLM fine-tuning.
Each example must contain:
- "image": a PIL image
- "messages": chat-style conversation (list[dict])
"""
images = [ex["image"] for ex in examples]
conversations = [ex["messages"] for ex in examples]
# Build chat prompts for the whole batch
chat_texts = processor.apply_chat_template(
conversations,
add_generation_prompt=False,
tokenize=False,
)
# Tokenize + process images
batch = processor(
text=chat_texts,
images=images,
padding="longest",
truncation=True,
max_length=MAX_SEQ_LEN,
return_tensors="pt",
)
# Labels: same as input_ids but mask pad & image tokens
labels = batch["input_ids"].clone()
if pad_token_id is not None:
labels[labels == pad_token_id] = -100
if image_token_id is not None and image_token_id != pad_token_id:
labels[labels == image_token_id] = -100
batch["labels"] = labels
return batchCom o adaptador LoRA, a configuração de treinamento e o coletor de dados prontos, agora podemos conectar tudo ao SFTTrainer da trl.
Esse treinador cuida de todo o ciclo de ajuste fino supervisionado para o nosso modelo Ministral 3 de linguagem visual, usando nosso conjunto de dados formatado, configuração LoRA e função de compilação personalizada para lotes de imagens e textos.
from trl import SFTTrainer
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=formatted_data,
peft_config=peft_config,
processing_class=processor,
data_collator=collate_fn,
)Execute o código abaixo para começar o processo de treinamento.
trainer.train()Durante a minha execução, o ajuste fino usou cerca de 57 GB de VRAM e um pouco mais durante as etapas de avaliação que rolam a cada poucas iterações. Na prática, isso quer dizer que você pode ajustar essa configuração tranquilamente em um hardware com menos de 70 GB de VRAM.
O treinamento completo levou cerca de meia hora, e a perda de treinamento diminuiu de forma constante com o tempo, o que é um bom sinal de que o modelo está aprendendo com o conjunto de dados.
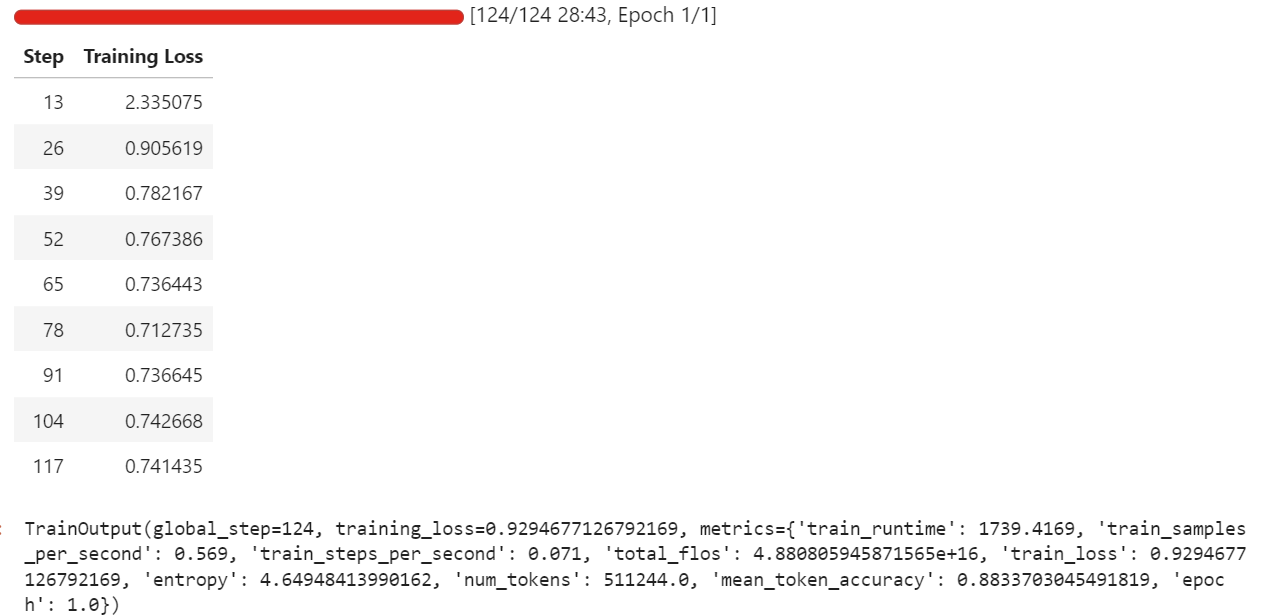
Depois que o treinamento estiver pronto, a gente salva o modelo adaptado no Hugging Face Hub. Isso vai criar um novo repositório e enviar todos os arquivos necessários para que você possa recarregar e executar o modelo ajustado a partir de qualquer ambiente.
trainer.save_model()Você pode ver o modelo em kingabzpro/ministral-3-fratura-óssea.
Agora vamos carregar o modelo e o processador ajustados do Hugging Face Hub. Nos bastidores, isso vai baixar o adaptador LoRA salvo, carregar o ponto de verificação base Ministral 3 e juntar o adaptador ao modelo base para que ele fique pronto para inferência.
import torch
from transformers import AutoProcessor, AutoModelForImageTextToText, BitsAndBytesConfig
model_id = "kingabzpro/ministral-3-bone-fracture"
model_kwargs = dict(
attn_implementation="eager",
dtype=torch.bfloat16,
device_map="auto",
)
model = AutoModelForImageTextToText.from_pretrained(model_id, **model_kwargs)
processor = AutoProcessor.from_pretrained(model_id)
processor.tokenizer.padding_side = "left"Para manter a comparação justa, primeiro reutilizamos a mesma imagem que testamos antes do ajuste fino (índice 200) e a executamos no pipeline de inferência com nosso prompt de classificação rigoroso.
image = formatted_data[200]["image"]
messages = [
{"role": "user", "content": [
{"type": "text", "text": PROMPT},
{"type": "image"},
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt = True)
inputs = processor(
image,
input_text,
add_special_tokens = False,
return_tensors = "pt",
).to(device="cuda", dtype=torch.bfloat16)
from transformers import TextStreamer
text_streamer = TextStreamer(processor, skip_prompt = True)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 100)Conseguimos um resultado perfeito. Não foi necessário nenhum pós-processamento extra. O modelo seguiu as regras de prompt e produziu a classe correta diretamente.
Comminuted fracture</s>Depois, tentamos outra amostra aleatória do conjunto de dados para confirmar que esse comportamento não se limita a um único exemplo.
image = formatted_data[400]["image"]
messages = [
{"role": "user", "content": [
{"type": "text", "text": PROMPT},
{"type": "image"},
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt = True)
inputs = processor(
image,
input_text,
add_special_tokens = False,
return_tensors = "pt",
).to(device="cuda", dtype=torch.bfloat16)
from transformers import TextStreamer
text_streamer = TextStreamer(processor, skip_prompt = True)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 100)Resultado do modelo:
Greenstick fracture</s>Verdade fundamental:
FRACTURE_CLASSES[formatted_data[400]["label"]]Resultado:
'Greenstick fracture'Mais uma vez, a previsão está certa e totalmente de acordo com o rótulo.
Com essas verificações, podemos dizer que nosso modelo Ministral 3 14B foi ajustado com sucesso no conjunto de dados de raios-X de fraturas ósseas e agora é capaz de seguir as instruções e produzir previsões precisas de classe única para esses exemplos.
Ajustar o modelo Ministral 3 exige paciência e ajustes constantes. Levei dois dias inteiros para entender por que o modelo não estava sendo treinado da maneira que eu esperava e por que, apesar de ser um modelo relativamente pequeno, ainda estava sobrecarregando minha GPU e causando erros de memória insuficiente.
A principal razão era simples, mas fácil de ignorar. Isso não é só um modelo de linguagem. É um modelo de linguagem de visão, o que significa que ele carrega um codificador de imagem que adiciona uso extra de memória.
Resoluções de imagem maiores levam diretamente a um maior consumo de VRAM. Reduzir o tamanho da imagem ou começar com lotes menores torna o processo de treinamento muito mais estável.
Outro problema que tive foi usar o modelo padrão de chat. Era muito longo e estruturado para esse tipo de tarefa. O modelo estava se esforçando mais para ajustar a formatação do modelo em vez de aprender a ler as imagens e produzir uma classificação clara das fraturas.
Depois que simplifiquei o prompt pra um formato de instrução direta, o modelo finalmente começou a responder corretamente à entrada visual, em vez de moldar cada resposta como uma resposta completa de chat.
Também achei que, como o modelo tem uma visão super boa, ele ia se sair bem em exames médicos. Essa suposição me atrasou. Chamar isso de “MedGemma” na minha cabeça não era justo com o modelo nem com o processo. Não é um modelo médico especializado pronto para usar, e esperar que ele funcionasse como tal sem o treinamento adequado foi um erro meu.
No final, superei todos os obstáculos e transformei o que aprendi neste guia. O objetivo é ajudar você a evitar a mesma confusão e chegar a resultados significativos mais rápido.
Com imagens menores, instruções mais simples e expectativas realistas, o Ministral 3 pode ser ajustado para entender raios-X de um jeito muito mais tranquilo e confiável.
Se você quer ter mais prática com o ajuste fino, recomendo o curso curso Ajustes finos com Llama 3.
Cursos mais populares do DataCamp
Curso
Curso
Curso
blog
Bhavishya Pandit
8 min
blog
Nisha Arya Ahmed
12 min
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita

