

Kurs
Künstliche Intelligenz verstehen
2 Std.
401.5K
Es kann sein, dass viele Unternehmens-Workloads keine Modelle auf dem neuesten Stand brauchen, sondern eigentlich schnelle, kostengünstige Schlussfolgerungen für bestimmte Aufgaben. Ich denke gerade über Kundensupport-Weiterleitung, Dokumentenklassifizierung und Code-Vervollständigung nach.
Das ist die Geschichte, auf die Mistral AI setzt: kompakte Modelle mit offenem Gewicht, die auf Domänendaten abgestimmt werden können und effizient in großem Maßstab laufen.
Dafür hat Mistral gerade diese Woche Mistral 3 rausgebracht, und ich denke, das bringt uns dem Ziel echt ein großes Stück näher. Zuerst mal, die Modelle selbst sind echt vielversprechend: Mistral Large 3, das Flaggschiff, schlägt seine Open-Source-Konkurrenten Kimi-K2 und Deepseek-3.1 bei wichtigen Benchmark-Tests. Zweitens macht Mistral sein Produktangebot übersichtlicher. Weißt du, das ist das erste Mal, dass Mistral AI eine komplette Modellfamilie rausgebracht hat. (Als Medium 3 Anfang des Jahres rauskam, war es nicht sofort klar (nur vom Namen her), dass es besser sein sollte als Large 2, das letztes Jahr rausgekommen war.)
Mistral 3 ist die neueste Generation von Modellen von Mistral AI, die auf einer gemeinsamen Architektur und einem gemeinsamen Funktionsumfang basieren. neueste Generation von Modellen, die auf einer gemeinsamen Architektur und einem gemeinsamen Funktionsumfang basieren. Mistral hat sich von einzelnen Varianten zu einer einheitlichen Familie entwickelt, in der jedes Modell mehrsprachige Eingabeaufforderungen, multimodale Eingaben und die gleichen Kernfunktionen unterstützt. Die Idee ist, Entwicklern eine einheitliche Basis zu bieten, egal welche Größe sie wählen.
Diese Generation konzentriert sich auch darauf, das logische Denken, die Effizienz und die praktische Anwendbarkeit auf ganzer Linie zu verbessern. Egal, ob du Tests in der Cloud machst oder Apps entwickelst, die schnellere Schlussfolgerungen brauchen – Mistral 3 bietet dir eine klarere und berechenbarere Basis, auf der du aufbauen kannst.
Ich hab schon gesagt, dass Mistral 3 eigentlich eine ganze Reihe von Modellen ist. Es gibt insgesamt vier, und sie kümmern sich alle um unterschiedliche Einschränkungen, wie zum Beispiel die Tiefe der Schlussfolgerungen, Hardware-Grenzen, Latenz und Einsatzumgebungen. Allerdings sticht ein Modell besonders hervor: Large 3 ist für ganz andere Workloads gedacht als die kleineren Stufen, bei denen es vor allem um Praktikabilität und Flexibilität bei der Bereitstellung geht.
Mistral Large 3 ist das Topmodell dieser Generation. Es nutzt eine spärliche MoE-Architektur mit 675 Milliarden Parametern, von denen etwa 41 Milliarden während der Inferenz aktiv sind, was natürlich höhere Hardwareanforderungen mit sich bringt. Das Modell ist für Aufgaben gedacht, die starkes logisches Denken, die Verarbeitung langer Kontexte und eine gleichbleibende Ausgabequalität brauchen. Es schneidet bei Open-Source-Bewertungen gut ab, zum Beispiel mit Top-Ergebnissen in der Rangliste von LMArena für Nicht-Argumentation. Die Token-Effizienz ist gut, aber die Rechenkosten hängen von der Größe ab.
Das ist das stärkste dichte Modell in der Familie. Das ist eine gute Wahl, wenn du echte Leistung willst, ohne gleich in den Bereich der Multi-GPU-Cluster einzusteigen. Es läuft problemlos auf einer einzigen High-End-GPU-Konfiguration (vier GPUs, wenn du Spielraum haben willst) und erzielt starke Ergebnisse bei Aufgaben wie AIME '25. Die Balance zwischen Output-Qualität und Token-Effizienz macht es zu einem praktischen Mittelweg für Teams, die intelligente Schlussfolgerungen ohne MoE-Hardware wollen.
Ich sehe 8B als das Arbeitstier. Es bleibt schnell, berechenbar und günstig und deckt dabei eine Vielzahl von Produktionsszenarien ab: Chat-Systeme, interne Tools, Automatisierungsabläufe und RAG-Anwendungen. Es kann zwar nicht mit Large 3 oder 14B mithalten, wenn es um tiefgreifende Überlegungen geht, aber das Preis-Leistungs-Verhältnis ist das beste in der Familie. Die Token-Nutzung bleibt niedrig und die Ausgaben sind immer noch im Gleichgewicht.
Das ist das kleinste Modell und kann fast überall eingesetzt werden. Es ist kompakt, leicht und läuft super auf CPUs, Mobilgeräten oder IoT-Hardware. Du wirst es nicht nehmen, wenn du komplexe Überlegungen brauchst, aber es ist super für Offline-Apps, Routing-Aufgaben, einfache Klassifizierer und Assistenten, die sofortige Antworten brauchen. Die Effizienz der Token ist echt super.

Bei allen vier gibt's eine Apache 2.0-Lizenz, Unterstützung für Bilder und Text und eine breite mehrsprachige Abdeckung. Weil die Modelle immer gleich funktionieren, kannst du sie ohne Probleme vergrößern oder verkleinern, ohne dass du dich neu einarbeiten musst.
Hier ist ein kurzer Überblick über die Modelle im Vergleich:
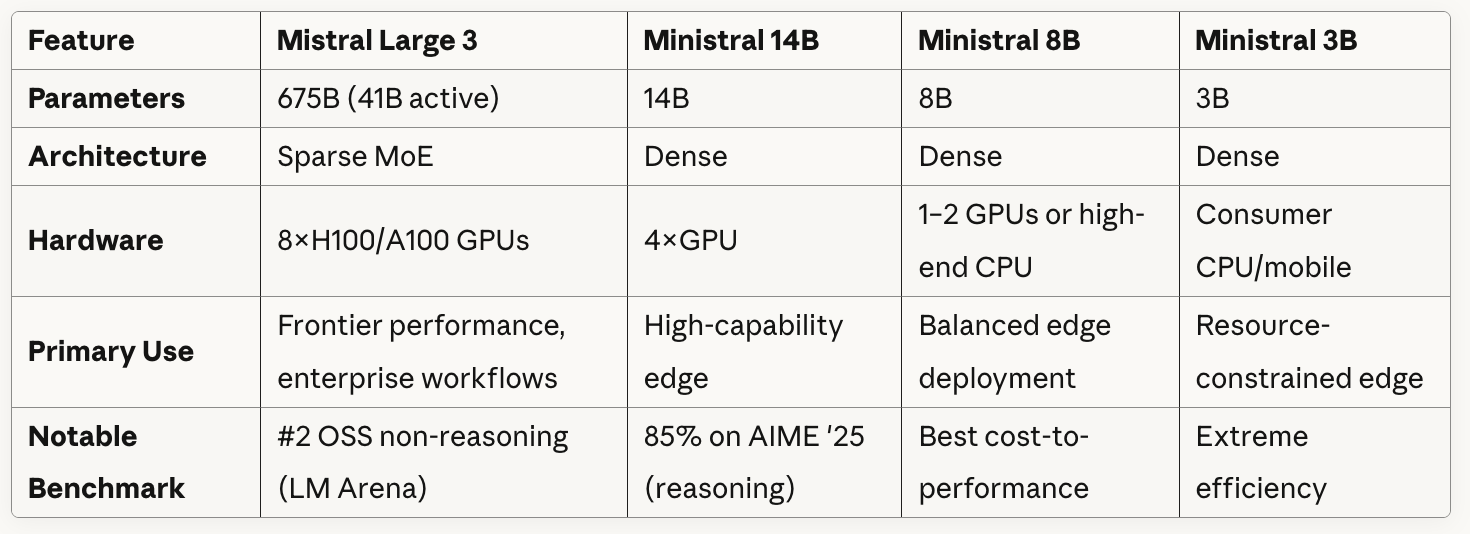
Wie du in der Tabelle sehen kannst, nutzt Mistral Large 3 eine Sparse-MoE-Architektur mit 41 Milliarden aktiven Parametern von insgesamt 675 Milliarden. Im Grunde hat das Modell mehrere spezialisierte „Experten“-Netzwerke, und für jedes Token oder jede Aufgabe leitet es die Daten nur durch einen Teil dieser Experten weiter, anstatt alle Parameter zu nutzen.
Die Ministral-Modelle nutzen alle dichte Architekturen, was bedeutet, dass alle Parameter bei jeder Inferenz aktiv sind.
Wenn du dir die Angaben zu den Hardwareanforderungen in der Tabelle genauer ansiehst, wirst du einen klaren Kompromiss zwischen den Modellgrößen und der Flexibilität bei der Bereitstellung erkennen: Mistral Large 3 braucht acht High-End-GPUs, aber Ministral 3B läuft auch auf normalen CPUs/Mobilgeräten.
Ich habe mich bei meinen Tests auf Large 3 konzentriert. Da Large 3 das Flaggschiff ist, ist es sowohl das leistungsstärkste Modell als auch das, das die meisten Leute benutzen werden.
Für meinen ersten Test hab ich Mistral 3 Large einen Screenshot auf Arabisch mit der folgenden Eingabe gegeben.
In diesem Fall erzählt ein Kunde von einem Problem mit seiner Satellitenschüssel. Die sagen, sie hätten es neu installiert oder neu positioniert, aber es funktioniert nicht richtig und ihre Internetverbindung ist tot.

A customer sent the attached error message screenshot showing an error in Arabic.
Please:
1. Read and translate the error message from the screenshot
2. Write a troubleshooting guide in English for our support team (3-4 steps)
3. Translate that solution back to Levantine Arabic in a natural, conversational way the customer would understandZuerst hat Large 3 die Nachricht übersetzt, und ich war besorgt, dass wir vielleicht in die falsche Richtung gehen. Du musst kein arabischer Muttersprachler sein, um zu merken, dass die englische Version nicht stimmt.

Large 3 machte weiter und gab mir Anweisungen auf Arabisch, die ich als Antwort geben konnte.
Auch wenn Mistral die Frage nicht richtig übersetzt hat, waren die Anweisungen, die ich dem Kunden weitergeben konnte (was ja der nützlichere Teil ist), total klar. Die Punkte 1 bis 3 sind auf Arabisch gut zu lesen (ich weiß das, weil ich um Hilfe bei der Übersetzung gebeten habe), aber Mistral hat im vierten Punkt einen Fehler gemacht, als es von „Art Support“ statt von „Tech Support“ sprach.

Zum Schluss hab ich noch rausgefunden, dass Mistral echt den gewünschten arabischen Dialekt benutzt hat. Das Gespräch war echt levantinisch.
Dann habe ich ihm eine kleine, aber realistische Programmieraufgabe gegeben:
Write a Python function that takes a list of timestops (ISO format) and returns time gaps between each consecutive time gap in minutes. Make the function safe against invalid entries.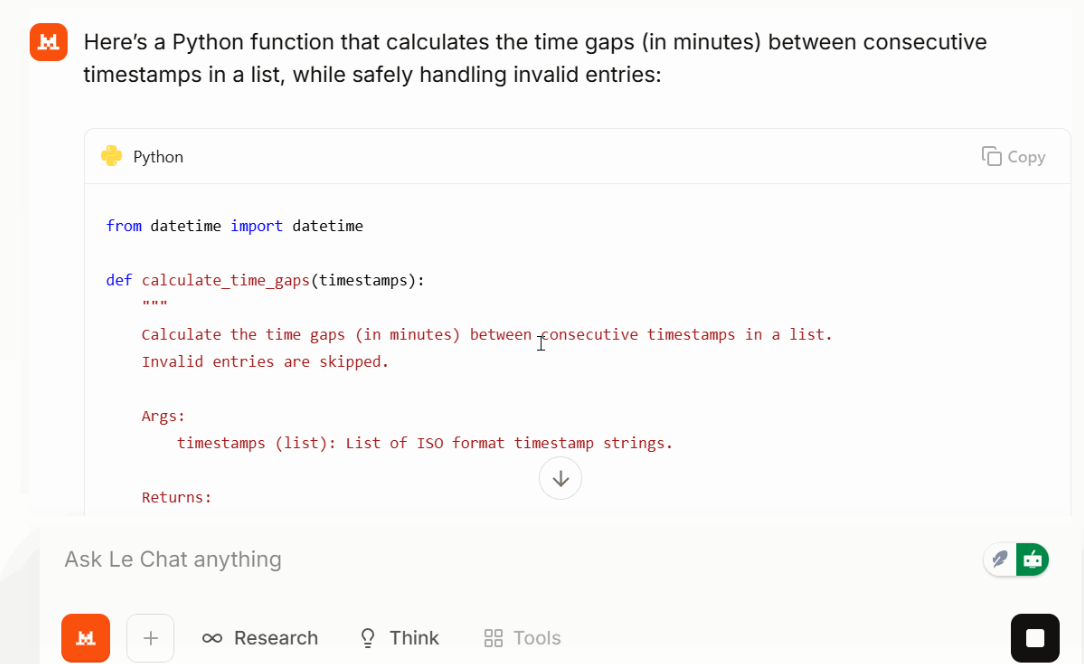
Large 3 hat eine kurze, leicht verständliche Funktion mit vernünftiger Fehlerbehandlung und sortierten Eingaben zurückgegeben. In meinem Test war die Lösung kompakt und die Ausgabe blieb fokussiert. Je nach Eingabeaufforderung und Aufgabe kann das helfen, den Tokenverbrauch niedriger als erwartet zu halten.
Um mehrstufige Schlussfolgerungen zu checken, ohne in einen speziellen Modus zu wechseln, hab ich ein klassisches Rätsel benutzt:
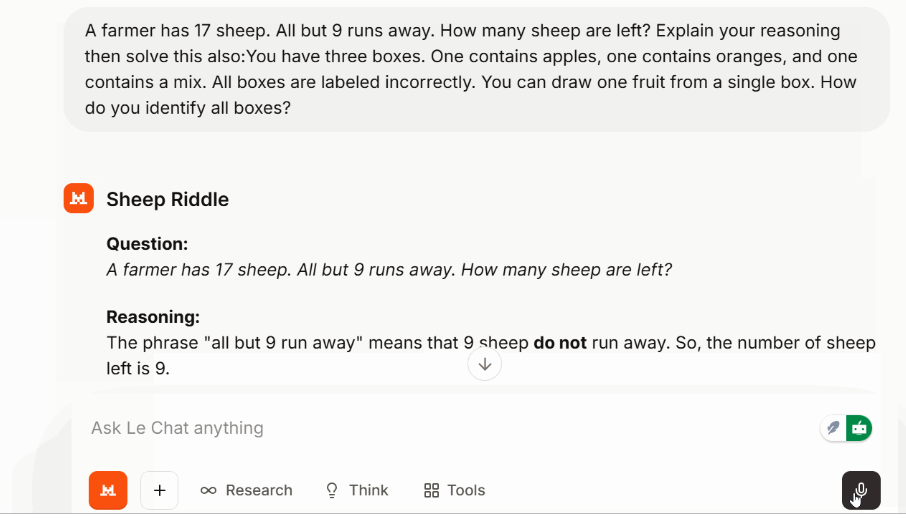
Ein weiteres Logikrätsel über falsch beschriftete Obstkisten wurde auch ohne Umwege gelöst.
Benchmarks sind nicht alles, aber sie helfen dabei, das Modell in einen Kontext zu setzen. Mistral vergleicht Large 3 hauptsächlich mit Open-Source-Konkurrenten wie DeepSeek-3.1 und Kimi-K2 was angesichts der Apache 2.0-Lizenz Sinn macht.
Large 3 macht eine gute Figur bei den Bewertungen in den Bereichen Logik, GSM8K, AIME und Programmierung. Es ist echt das aktuell beste Open-Source-Codierungsmodell auf der LMArena-Rangliste. Die ersten SWE-Bench-Ergebnisse zeigen, dass es Software-Engineering-Aufgaben auf einem Niveau löst, das mit anderen leistungsstarken Dense- und MoE-Systemen mithalten kann. Die Ministral-Modelle sind auch für ihre Größe echt stark.
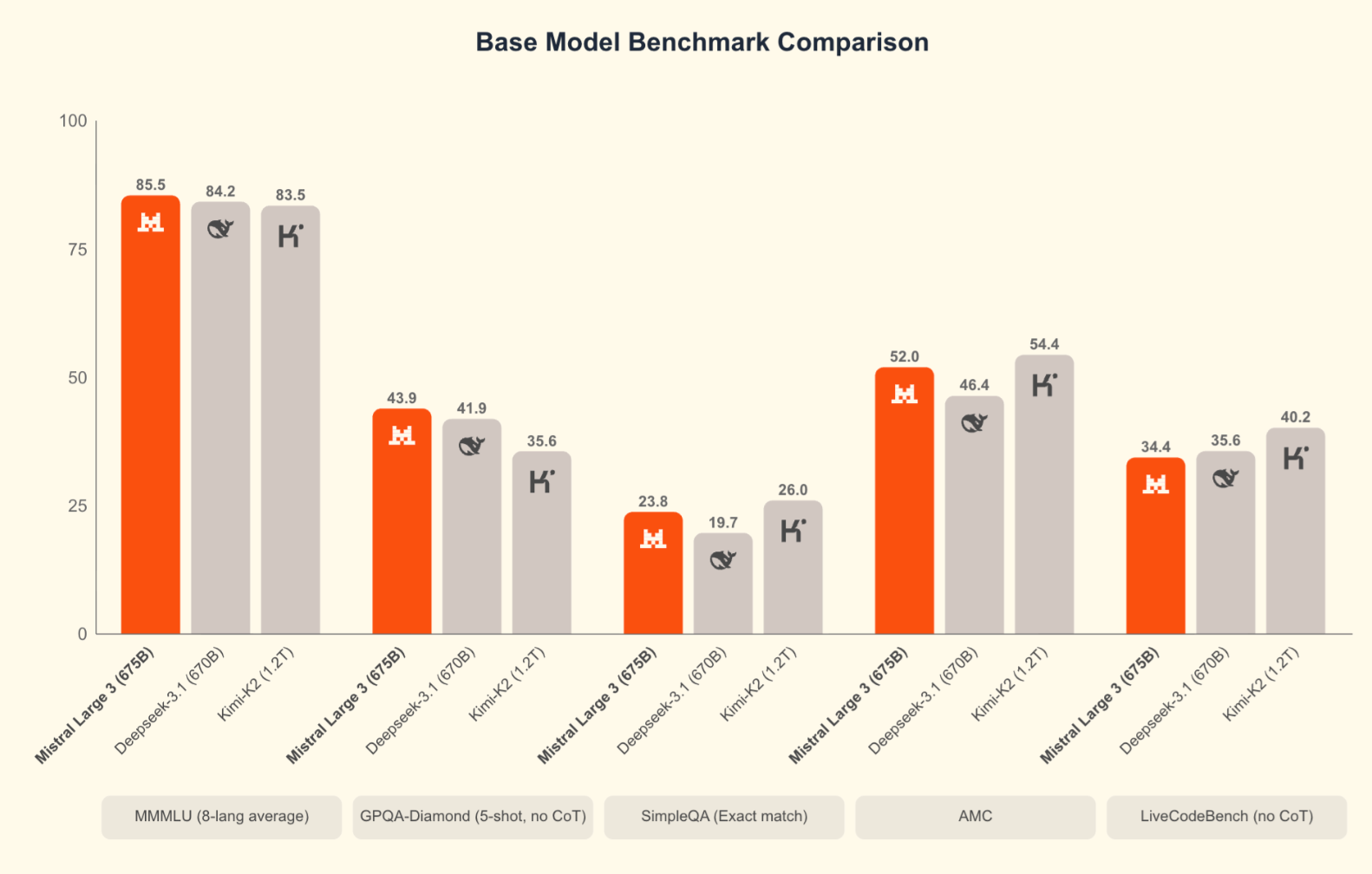
In den Vergleichen von Mistral fehlen vor allem die Ende November herausgebrachten Frontier-Modelle: Gemini 3 Pro (mit 91,9 % bei GPQA Diamond und 1501 Elo bei LMArena), GPT-5.1und Claude Opus 4.5 (das bei SWE-bench Verified mit über 80 % führt). Wenn man Large 3 mit diesen Modellen vergleicht, haben die proprietären Systeme immer noch einen Vorteil bei den schwierigsten Benchmarks für logisches Denken und komplexen agentenbasierten Aufgaben. Das stimmt. Aber für viele praktische Aufgaben, vor allem wenn man bedenkt, dass man alles selbst hosten, optimieren und einsetzen kann, ohne an einen Anbieter gebunden zu sein, bietet Large 3 eine echt gute Leistung.
|
Feature |
Mistral Large 3 |
Gemini 3 Pro |
GPT-5.1 |
Claude Opus 4.5 |
|
Typ |
Sparse MoE, offene Gewichte |
Eigene multimodale Technologie |
Eigene multimodale Technologie |
Eigenes, auf Argumentation fokussiertes Denken |
|
Lizenzierung |
Apache 2.0 |
Geschlossen |
Geschlossen |
Geschlossen |
|
Einsatz |
API, komplett selbst gehostet |
Nur gehostet |
Nur gehostet |
Nur gehostet |
|
Stärken |
Logisches Denken, Offenheit, Mehrsprachigkeit/Multimodalität |
Tiefgehende Multimodalität, Video |
Programmieren, Werkzeuggebrauch, allgemeine Aufgaben |
Sorgfältige ausführliche Begründung |
|
Fähigkeit zum logischen Denken |
Hoch |
Hoch |
Super hoch |
Super hoch |
|
Fähigkeit zum Programmieren |
Stark |
Solide |
Super stark |
Stark, aber langsamer |
|
Multimodal |
Bild + Text |
Bild, Ton, Video |
Bild + Text |
Bild + Text |
|
Kontextlänge |
Long |
Super lang |
Super lang |
Super lang |
|
Token-Effizienz |
Schlanke Ergebnisse |
Ausführlicher |
Knapp |
Oft detailliert/länger |
|
Selbsthosting |
Ja |
Nein |
Nein |
Nein |
|
Beste Passform |
Teams, die Leistung und Kontrolle brauchen |
Video-/multimodale Arbeitsabläufe |
Produktionsagenten |
Tiefgehende analytische Aufgaben |
Mistral 3 ist ein starkes Release für das offene Ökosystem. Die Kombination aus Token-Effizienz, mehrsprachiger Tiefe und der Möglichkeit, mit langen Kontexten umzugehen, macht es echt wichtig. Es ist eine Mischung aus Leistungsfähigkeit und Offenheit in einem Ausmaß, das wir bisher noch nicht gesehen haben. Large 3 kommt den besten proprietären Systemen ziemlich nahe, kann aber trotzdem runtergeladen, geprüft und nach Belieben eingesetzt werden.
Wenn es einen Punkt gibt, bei dem man die Erwartungen im Griff behalten sollte, dann ist es eine super gründliche Planung. Large 3 macht seine Sache gut, aber Modelle wie Opus und GPT können besser mit langen Argumentationsketten umgehen. Bei den meisten echten Apps ist der Unterschied aber nicht so groß.
Es gibt ein paar Möglichkeiten, um loszulegen, je nachdem, wie du die Modelle nutzen willst.
Wenn du sie einfach nur ausprobieren willst, ist die gehostete API der einfachste Weg. Alle vier Stufen – Large 3, 14B, 8B und 3B – sind mit einem Standard-API-Schlüssel verfügbar. Die Abrechnung läuft über Token und ist der schnellste Weg, um logisches Denken, multimodale Eingabeaufforderungen oder mehrsprachige Aufgaben zu testen.
Wenn du die volle Kontrolle haben willst, kannst du die offenen Gewichte runterladen. Wenn Mistral diese als die „besten permissiven Modelle mit freiem Gewicht“ bezeichnet, meinen sie damit:
Large 3 braucht echt starke Hardware, aber die Ministral-Modelle lassen sich problemlos verkleinern. Du kannst auch Partnerplattformen nutzen, wenn du mit verschiedenen Backends experimentieren möchtest, ohne eigene Maschinen zu betreiben.
Ich habe in diesem Artikel ein paar Anwendungsfälle angesprochen, aber ich möchte jetzt mehr Zeit darauf verwenden, darüber zu schreiben, wie ich mir die praktische Nutzung der einzelnen Ebenen durch Teams vorstellen könnte. Das Team bei Mistral setzt voll drauf, dass die meisten Unternehmen mit kleinen, flexiblen Modellen, die man genau anpassen kann, gut zurechtkommen.
Ich stell mir vor, wie ein Hedgefonds-Analyst von „ “ 50 Transkripte von Gewinnbekanntgaben hochladen und Mistral Large 3 bitten könnte, zu markieren, welche Managementteams ihre Prognosen absichern oder ihren Ton von Quartal zu Quartal ändern. Das 256k-Kontextfenster kann ganze Transkripte und 10-Ks (jährliche Finanzdokumente) ohne Aufteilung verarbeiten. Oder wenn du bei einer europäischen Investmentfirma arbeitest, würde Mistral sicher auf Französisch, Deutsch, Italienisch (oder Arabisch, wie wir es ausprobiert haben) funktionieren.
Wenn das weit hergeholt klingt, sollte es das vielleicht nicht, denn HSBC hat gerade diese Woche eine Vereinbarung mit Mistral angekündigt .
Mistral 3 gibt Mistral endlich eine einheitliche Struktur und Modelle, die sich ganz natürlich an verschiedene Einschränkungen anpassen. Large 3 kann mit den großen proprietären Systemen mithalten, während die Ministral-Produktreihe die Auswahl einer Stufe erleichtert, die zu deiner Hardware und deinen Latenzanforderungen passt.
Wenn du experimentieren willst, ist die gehostete API der schnellste Weg, um loszulegen. Und wenn du lokal oder selbst hosten willst, hast du durch das Herunterladen der Gewichte die volle Kontrolle.
Wenn du wissen willst, wie Modelle wie Mistral funktionieren, ist unser Kurs „Large Language Models Concepts” genau das Richtige für dich. Und wenn du Mistral in eine Anwendung einbinden willst, hilft dir„API Fundamentals in Python” bei den praktischen Sachen.
Lerne mit DataCamp
Kurs
Kurs
Kurs
Blog
Blog
Nisha Arya Ahmed
15 Min.
Tutorial
Matt Crabtree