
Lernpfad
Keras Grundlagen
16 Std.
Tiefe neuronale Netze haben die Landschaft der künstlichen Intelligenz in der heutigen Zeit verändert. In letzter Zeit gab es mehrere Forschungsfortschritte im Bereich des Deep Learning und der neuronalen Netze, die die Qualität von Projekten im Bereich der künstlichen Intelligenz drastisch erhöht haben.
Diese tiefen neuronalen Netze helfen Entwicklern, nachhaltigere und hochwertigere Ergebnisse zu erzielen. Daher ersetzen sie sogar einige herkömmliche maschinelle Lernverfahren.
Aber was genau sind tiefe neuronale Netze, und warum sind sie die beste Wahl für eine Vielzahl von Aufgaben? Und welche verschiedenen Bibliotheken und Tools gibt es, um mit tiefen neuronalen Netzen zu arbeiten?
Dieser Artikel erklärt tiefe neuronale Netze, ihre Anforderungen an die Bibliothek und wie man eine grundlegende Architektur eines tiefen neuronalen Netzes von Grund auf aufbaut.
Ein künstliches neuronales Netz (ANN) oder ein einfaches traditionelles neuronales Netz zielt darauf ab, triviale Aufgaben mit einer einfachen Netzwerkstruktur zu lösen. Ein künstliches neuronales Netz ist lose an biologische neuronale Netze angelehnt. Es ist eine Sammlung von Schichten, die eine bestimmte Aufgabe erfüllen. Jede Schicht besteht aus einer Sammlung von Knotenpunkten, die zusammenarbeiten.
Diese Netze bestehen in der Regel aus einer Eingabeschicht, ein bis zwei versteckten Schichten und einer Ausgabeschicht. Während es möglich ist, einfache mathematische Fragen und Computerprobleme zu lösen, einschließlich grundlegender Gatterstrukturen mit ihren jeweiligen Tabellen, ist es für diese Netze schwierig, komplizierte Aufgaben in den Bereichen Bildverarbeitung, Computer Vision und Verarbeitung natürlicher Sprache zu lösen.
Für diese Probleme verwenden wir tiefe neuronale Netze, die oft eine komplexe Struktur mit einer Vielzahl verschiedener Schichten haben, wie z.B. eine Faltungsschicht, eine Max-Pooling-Schicht, eine dichte Schicht und andere einzigartige Schichten. Diese zusätzlichen Schichten helfen dem Modell, Probleme besser zu verstehen und optimale Lösungen für komplexe Projekte zu finden. Ein tiefes neuronales Netzwerk hat mehr Schichten (mehr Tiefe) als ein ANN und jede Schicht erhöht die Komplexität des Modells, während das Modell die Eingaben präzise verarbeiten kann, um die ideale Lösung auszugeben.
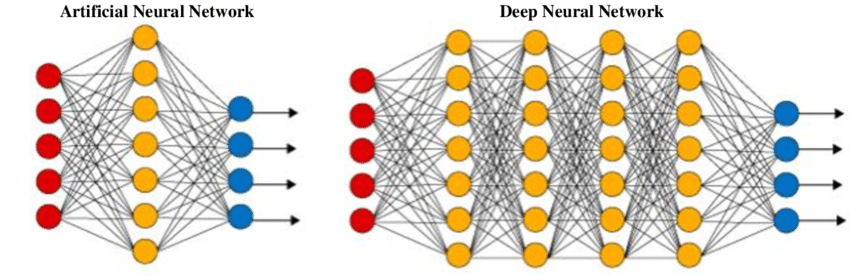
Tiefe neuronale Netze haben aufgrund ihrer hohen Effizienz bei der Durchführung zahlreicher Deep-Learning-Projekte eine extrem hohe Popularität erlangt. Erkunde die Unterschiede zwischen maschinellem Lernen und Deep Learning in einem separaten Artikel.
Nach dem Training eines gut aufgebauten tiefen neuronalen Netzwerks können sie die gewünschten Ergebnisse mit hoher Genauigkeit erzielen. Sie sind in allen Bereichen des Deep Learning beliebt, z. B. beim Computer Vision, bei der Verarbeitung natürlicher Sprache und beim Transfer Learning.
Die wichtigsten Beispiele für die Bedeutung von tiefen neuronalen Netzen sind ihre Nützlichkeit bei der Objekterkennung mit Modellen wie YOLO (You Only Look Once), bei Sprachübersetzungsaufgaben mit BERT-Modellen (Bidirectional Encoder Representations from Transformers), bei Transfer-Learning-Modellen wie VGG-19, RESNET-50, efficient net und anderen ähnlichen Netzen für Bildverarbeitungsprojekte.
Um diese Deep Learning-Konzepte der künstlichen Intelligenz besser zu verstehen, empfehle ich den Kurs Deep Learning in Python von DataCamp.
Neuronale Netze von Grund auf zu konstruieren, hilft Programmierern, Konzepte zu verstehen und triviale Aufgaben zu lösen, indem sie diese Netze manipulieren. Der Aufbau dieser Netzwerke von Grund auf ist jedoch zeitaufwändig und erfordert einen enormen Aufwand. Um Deep Learning zu vereinfachen, stehen uns verschiedene Tools und Bibliotheken zur Verfügung, mit denen wir ein effektives Deep Neural Network-Modell erstellen können, das mit wenigen Zeilen Code komplexe Probleme lösen kann.
Die beliebtesten Deep-Learning-Bibliotheken und -Tools, die für die Konstruktion von tiefen neuronalen Netzen verwendet werden, sind TensorFlow, Keras und PyTorch. Die Keras- und TensorFlow-Bibliotheken werden seit dem Start von TensorFlow 2.0 synonym verlinkt. Diese Integration ermöglicht es Nutzern, komplexe neuronale Netze mit High-Level-Codestrukturen unter Verwendung von Keras innerhalb des TensorFlow-Netzwerks zu entwickeln.
Die PyTorch-Bibliothek ist ein weiteres sehr beliebtes Framework für maschinelles Lernen, mit dem du High-End-Forschungsprojekte entwickeln kannst.
Während es in der Visualisierungsabteilung ein wenig hapert, kompensiert PyTorch dies durch seine kompakte und schnelle Leistung mit relativ schnelleren und einfacheren GPU-Installationen für die Konstruktion von tiefen neuronalen Netzwerkmodellen.
Der Kurs Einführung in PyTorch in Python von DataCamp ist der beste Ausgangspunkt, um mehr über PyTorch zu erfahren.
Das TensorFlow-Framework bietet seinen Entwicklern eine breite Palette an fantastischen Optionen für Visualisierungswerkzeuge für Deep Learning-Aufgaben. Das Tensorboard Grafik-Dashboard ist eine hervorragende Wahl, um die Daten und Ergebnisse eines Projekts zu visualisieren, zu analysieren und entsprechend zu interpretieren.
Die Integration der Keras-Bibliothek ermöglicht eine schnellere Erstellung von Projekten mit einfachen Codestrukturen, was sie zu einer beliebten Wahl für langfristige Entwicklungsprojekte macht. Die Einführung in TensorFlow in Python ist ein großartiger Ort für Anfänger, um mit TensorFlow zu beginnen.
In diesem Abschnitt werden wir einige grundlegende Konzepte von tiefen neuronalen Netzen verstehen und erfahren, wie man ein solches Netz von Grund auf konstruiert.
Der erste Schritt besteht darin, deine bevorzugte Bibliothek für die gewünschte Anwendung auszuwählen. Wir werden die Deep-Learning-Frameworks TensorFlow und Keras verwenden, um das tiefe neuronale Netz zu konstruieren.
# Importing the necessary functionality
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Input, Dense, Conv2D
from tensorflow.keras.layers import Flatten, MaxPooling2DSobald wir die gewünschten Bibliotheken für diese Aufgabe importiert haben, werden wir die sequenzielle Modellierung für die Erstellung des Deep Learning-Modells verwenden. Das sequentielle Modell ist ein einfacher Stapel von Schichten mit einem Eingangs- und einem Ausgangswert. Die anderen verfügbaren Optionen sind die funktionale API-Klasse oder eine benutzerdefinierte Modellbildung. Die Klasse Sequential bietet jedoch einen einfachen Ansatz, um die Architektur des neuronalen Netzes zu erstellen.
# Creating the model
DNN_Model = Sequential()
Wir fügen eine Eingabeform hinzu, die normalerweise der Größe des Bildes entspricht, das du in deinem Projekt verwendest. Die Größe enthält die Breite, Höhe und Farbkodierung des Bildes. Im Beispielcode unten sind die Höhe und Breite des Bildes 256 mit einem RGB-Farbschema, das durch 3 dargestellt wird (1 wird für Graustufenbilder verwendet). Dann konstruieren wir die notwendigen versteckten Schichten mit Faltungsschichten und Max-Pooling-Schichten mit unterschiedlichen Filtergrößen. Schließlich verwenden wir eine abgeflachte Schicht, um die Ausgaben zu glätten und eine dichte Schicht als letzte Ausgabeschicht zu verwenden.
Die versteckten Schichten erhöhen die Komplexität des neuronalen Netzes. Eine Faltungsschicht führt eine Faltungsoperation an visuellen Bildern durch, um die Informationen zu filtern. Jede Filtergröße in einer Faltungsschicht hilft dabei, bestimmte Merkmale aus der Eingabe zu extrahieren. Ein Max-Pooling-Layer hilft dabei, die Anzahl der Merkmale zu reduzieren, indem er die Maximalwerte der extrahierten Merkmale berücksichtigt.
Eine abgeflachte Ebene reduziert die räumlichen Dimensionen auf eine einzige Dimension, um die Berechnungen zu beschleunigen. Eine dichte Schicht ist die einfachste Schicht, die eine Ausgabe von den vorherigen Schichten erhält und normalerweise als Ausgabeschicht verwendet wird. Die 2D-Faltung führt eine elementweise Multiplikation über eine 2D-Eingabe durch. Die Aktivierungsfunktion ReLU (rectified linear unit) verleiht dem Modell Nichtlinearität für eine bessere Rechenleistung. Wir werden dieselbe Auffüllung verwenden, um die Eingangs- und Ausgangsformen der Faltungsschichten beizubehalten.
# Inputting the shape to the model
DNN_Model.add(Input(shape = (256, 256, 3)))
# Creating the deep neural network
DNN_Model.add(Conv2D(256, (3, 3), activation='relu', padding = "same"))
DNN_Model.add(MaxPooling2D(2, 2))
DNN_Model.add(Conv2D(128, (3, 3), activation='relu', padding = "same"))
DNN_Model.add(MaxPooling2D(2, 2))
DNN_Model.add(Conv2D(64, (3, 3), activation='relu', padding = "same"))
DNN_Model.add(MaxPooling2D(2, 2))
# Creating the output layers
DNN_Model.add(Flatten())
DNN_Model.add(Dense(64, activation='relu'))
DNN_Model.add(Dense(10))Die Modellstruktur und das Diagramm des konstruierten tiefen neuronalen Netzes sind unten aufgeführt.
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_5 (Conv2D) (None, 256, 256, 256) 7168
max_pooling2d_5 (MaxPooling (None, 128, 128, 256) 0
2D)
conv2d_6 (Conv2D) (None, 128, 128, 128) 295040
max_pooling2d_6 (MaxPooling (None, 64, 64, 128) 0
2D)
conv2d_7 (Conv2D) (None, 64, 64, 64) 73792
max_pooling2d_7 (MaxPooling (None, 32, 32, 64) 0
2D)
flatten_2 (Flatten) (None, 65536) 0
dense_4 (Dense) (None, 64) 4194368
dense_5 (Dense) (None, 10) 650
=================================================================
Total params: 4,571,018
Trainable params: 4,571,018
Non-trainable params: 0
_________________________________________________________________Die Handlung ist wie folgt:
tf.keras.utils.plot_model(DNN_Model, to_file='model_big.png', show_shapes=True)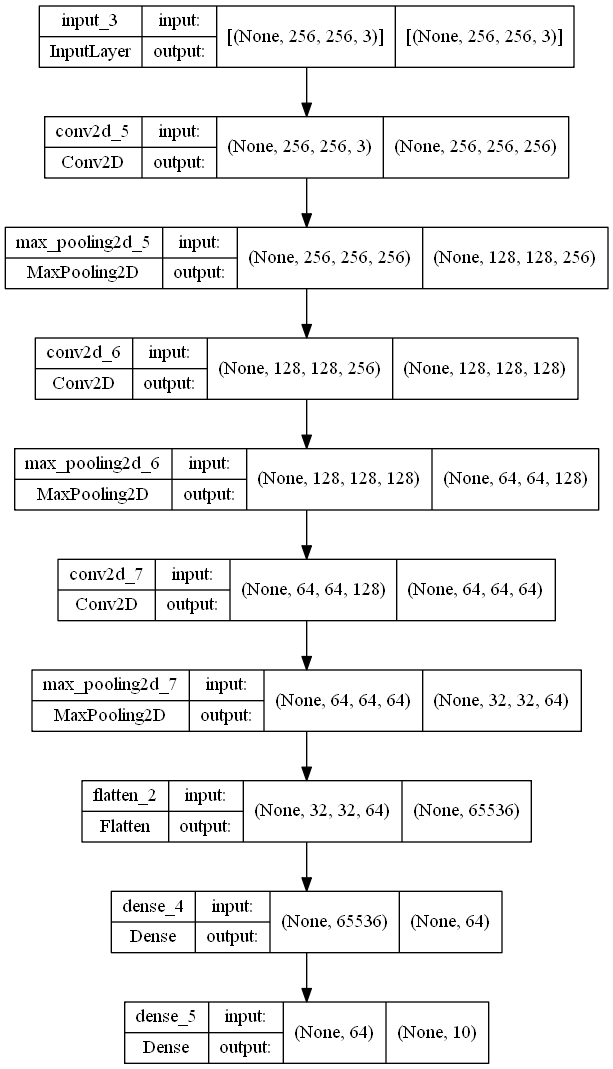
Machine Learning Workflow - Bildquelle
Sobald das Modell erstellt ist, muss es kompiliert werden, um das Modell zu konfigurieren. Während der Erstellung des Modells sind die wichtigsten Operationen in Deep Learning-Modellen die Vorwärtspropagation und die Rückwärtspropagation. Bei der Vorwärtspropagation werden alle wichtigen Informationen durch die verschiedenen Knoten bis zur Ausgabeschicht geleitet. In der Ausgabeschicht werden bei Klassifizierungsaufgaben die vorhergesagten Werte und die wahren Werte entsprechend berechnet.
In der Trainings- oder Anpassungsphase findet der Prozess der Backpropagation statt. Die Gewichte werden in jeder Schicht durch Festlegen der Gewichte nachjustiert, bis die vorhergesagten und die wahren Werte nahe beieinander liegen, um die gewünschten Ergebnisse zu erzielen. Für eine ausführliche Erklärung dieses Themas empfehle ich den folgenden Backpropagation-Leitfaden aus dem Kurs Introduction to Deep Learning in Python.
Bei der Erforschung von Deep Learning gibt es eine Menge Feinheiten. Ich empfehle dir, den Kurs Deep Learning with Keras zu besuchen, um zu verstehen, wie man tiefe neuronale Netze konstruiert.
Für die Berechnung einer bestimmten Machine-Learning-Aufgabe ist ein bestimmtes tiefes neuronales Netzwerk erforderlich, um die notwendigen Aktionen durchzuführen. Zwei hauptsächlich verwendete Deep-Learning-Modelle sind Faltungsneuronale Netze (CNN) und Rekurrente Neuronale Netze (RNN). Faltungsneuronale Netze sind in der Bildverarbeitung und bei Computer-Vision-Projekten von großem Nutzen.
In diesen tiefen neuronalen Netzen führen wir in den verborgenen Schichten statt einer typischen Matrixoperation eine Faltungsoperation durch. Es ermöglicht dem Netzwerk einen skalierbaren Ansatz, der eine höhere Effizienz und genauere Ergebnisse liefert. Bei Bildklassifizierungs- und Objekterkennungsaufgaben gibt es eine Menge Daten und Bilder, die das Modell berechnen muss. Diese Faltungsneuronalen Netze helfen, diese Probleme erfolgreich zu bekämpfen.
Bei der Verarbeitung natürlicher Sprache und bei semantischen Projekten werden oft rekurrente neuronale Netze eingesetzt, um die Ergebnisse zu optimieren. Eine beliebte Variante dieser RNNs, das Langzeit-Kurzzeitgedächtnis (LSTM), wird in der Regel für verschiedene maschinelle Übersetzungsaufgaben, Textklassifizierung, Spracherkennung und andere ähnliche Aufgaben verwendet.
Diese Netzwerke übertragen die wichtigsten Informationen von jeder der vorherigen Zellen an die nächste und speichern die entscheidenden Informationen für eine optimierte Modellleistung. Das Buch " Convolutional Neural Networks for Image Processing" ist ein fantastischer Leitfaden, um mehr über CNNs und Deep Learning in Python zu erfahren und ein umfassendes Verständnis von Deep Learning zu erlangen.
Wir haben ein kurzes Verständnis von tiefen neuronalen Netzen und ihrer Konstruktion mit dem TensorFlow Deep Learning Framework. Es gibt jedoch bestimmte Herausforderungen, die jeder Entwickler berücksichtigen muss, bevor er ein neuronales Netzwerk für ein bestimmtes Projekt entwickelt. Schauen wir uns ein paar dieser Herausforderungen an.
Eine der wichtigsten Voraussetzungen für Deep Learning sind Daten. Daten sind die wichtigste Komponente bei der Erstellung eines hochpräzisen Modells. In vielen Fällen benötigen tiefe neuronale Netze große Datenmengen, um eine Überanpassung zu verhindern und gute Leistungen zu erzielen. Die Datenanforderungen für Objekterkennungsaufgaben können mehr Daten erfordern, damit ein Modell verschiedene Objekte mit hoher Genauigkeit erkennen kann.
Während Techniken zur Datenerweiterung als schnelle Lösung für einige dieser Probleme nützlich sind, sind die Datenanforderungen ein Muss für jedes Deep Learning-Projekt.
Abgesehen von der großen Datenmenge muss man auch die hohen Rechenkosten für die Berechnung des tiefen neuronalen Netzes berücksichtigen. Modelle wie der Generative Pre-trained Transformer 3 (GPT-3) haben z.B. 175 Milliarden Parameter.
Für die Erstellung und das Training von Modellen für komplexe Aufgaben wird ein leistungsstarker Grafikprozessor benötigt. Modelle können oft effizienter auf GPUs oder TPUs trainiert werden als auf CPUs. Bei sehr komplexen Aufgaben sind die Systemanforderungen höher und erfordern mehr Ressourcen für eine bestimmte Aufgabe.
Während des Trainings kann das Modell auch auf Probleme wie Underfitting oder Overfitting stoßen. Underfitting tritt in der Regel aufgrund eines Mangels an Daten auf, während Overfitting ein größeres Problem ist, das auftritt, wenn sich die Trainingsdaten ständig verbessern, während die Testdaten konstant bleiben. Daher ist die Trainingsgenauigkeit hoch, aber die Validierungsgenauigkeit niedrig, was zu einem sehr instabilen Modell führt, das nicht die besten Ergebnisse liefert.
In diesem Artikel haben wir uns mit tiefen neuronalen Netzen beschäftigt und ihre Kernkonzepte verstanden. Wir haben den Unterschied zwischen diesen neuronalen Netzen und einem herkömmlichen Netz verstanden und ein Verständnis für die verschiedenen Arten von Deep-Learning-Frameworks zur Berechnung von Deep-Learning-Projekten entwickelt. Anschließend haben wir die TensorFlow- und Keras-Bibliotheken verwendet, um den Aufbau eines tiefen neuronalen Netzwerks zu demonstrieren. Zum Schluss haben wir uns einige der kritischen Herausforderungen des Deep Learning und einige Methoden zu ihrer Bewältigung angesehen.
Tiefe neuronale Netze sind eine fantastische Ressource, um die meisten gängigen Anwendungen und Projekte der künstlichen Intelligenz zu bewältigen. Sie ermöglichen es uns, Aufgaben der Bildverarbeitung und der Verarbeitung natürlicher Sprache mit hoher Genauigkeit zu lösen.
Es ist wichtig, dass alle qualifizierten Entwickler/innen mit den aufkommenden Trends Schritt halten, denn ein Modell, das heute beliebt ist, ist vielleicht in Zukunft nicht mehr so beliebt oder die beste Wahl.
Daher ist es wichtig, ständig zu lernen und Wissen zu erwerben, denn die Welt der künstlichen Intelligenz ist ein Abenteuer voller Spannung und neuer technologischer Entwicklungen. Eine der besten Möglichkeiten, um auf dem Laufenden zu bleiben, ist der Lernpfad "Deep Learning in Python " des DataCamps, in dem Themen wie TensorFlow und Keras sowie Deep Learning in PyTorch behandelt werden, um mehr über PyTorch zu erfahren. Für einen sanfteren Einstieg kannst du dir auch die KI-Grundlagenkurse ansehen. Ersteres hilft, das enorme Potenzial von Deep-Learning-Projekten freizusetzen, während letzteres dabei hilft, die Grundlagen zu stabilisieren.
Lerne über die Themen, die in diesem Lernprogramm erwähnt werden!
Lernpfad
Kurs
Kurs