Programa
Fundamentos de Keras
16 h
As redes neurais profundas mudaram o cenário da inteligência artificial na era moderna. Nos últimos tempos, houve vários avanços nas pesquisas sobre aprendizagem profunda e redes neurais, que aumentaram drasticamente a qualidade dos projetos relacionados à inteligência artificial.
Essas redes neurais profundas ajudam os desenvolvedores a obter resultados mais sustentáveis e de alta qualidade. Portanto, eles estão até mesmo substituindo várias técnicas convencionais de aprendizado de máquina.
Mas o que são exatamente as redes neurais profundas e por que elas são a melhor opção para uma grande variedade de tarefas? E quais são as diferentes bibliotecas e ferramentas para começar a usar as redes neurais profundas?
Este artigo explicará as redes neurais profundas, seus requisitos de biblioteca e como construir uma arquitetura básica de rede neural profunda a partir do zero.
Uma rede neural artificial (ANN) ou uma rede neural tradicional simples tem como objetivo resolver tarefas triviais com um esquema de rede simples. Uma rede neural artificial é livremente inspirada em redes neurais biológicas. É uma coleção de camadas para executar uma tarefa específica. Cada camada consiste em um conjunto de nós que operam juntos.
Essas redes geralmente consistem em uma camada de entrada, uma ou duas camadas ocultas e uma camada de saída. Embora seja possível resolver questões matemáticas fáceis e problemas de computador, incluindo estruturas básicas de portas com suas respectivas tabelas de verdade, é difícil para essas redes resolver tarefas complicadas de processamento de imagens, visão computacional e processamento de linguagem natural.
Para esses problemas, utilizamos redes neurais profundas, que geralmente têm uma estrutura de camada oculta complexa com uma ampla variedade de camadas diferentes, como uma camada convolucional, uma camada de pooling máximo, uma camada densa e outras camadas exclusivas. Essas camadas adicionais ajudam o modelo a entender melhor os problemas e a fornecer soluções ideais para projetos complexos. Uma rede neural profunda tem mais camadas (mais profundidade) do que a ANN e cada camada acrescenta complexidade ao modelo, permitindo que o modelo processe as entradas de forma concisa para gerar a solução ideal.
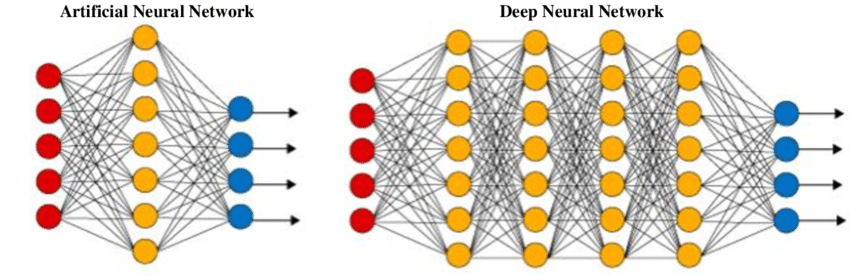
As redes neurais profundas ganharam uma tração extremamente alta devido à sua alta eficiência na realização de inúmeras variedades de projetos de aprendizagem profunda. Explore as diferenças entre aprendizado de máquina e aprendizado profundo em um artigo separado.
Depois de treinar uma rede neural profunda bem desenvolvida, eles podem alcançar os resultados desejados com altas pontuações de precisão. Eles são populares em todos os aspectos da aprendizagem profunda, incluindo visão computacional, processamento de linguagem natural e aprendizagem por transferência.
Os principais exemplos da proeminência das redes neurais profundas são sua utilidade na detecção de objetos com modelos como YOLO (You Only Look Once), tarefas de tradução de idiomas com modelos BERT (Bidirectional Encoder Representations from Transformers), modelos de aprendizagem por transferência, como VGG-19, RESNET-50, rede eficiente e outras redes semelhantes para projetos de processamento de imagens.
Para entender esses conceitos de aprendizagem profunda da inteligência artificial de forma mais intuitiva, recomendo que você confira o curso Aprendizagem profunda em Python do DataCamp.
A construção de redes neurais a partir do zero ajuda os programadores a entender conceitos e resolver tarefas triviais por meio da manipulação dessas redes. No entanto, criar essas redes do zero consome tempo e exige um esforço enorme. Para simplificar a aprendizagem profunda, temos várias ferramentas e bibliotecas à nossa disposição para produzir um modelo eficaz de rede neural profunda capaz de resolver problemas complexos com poucas linhas de código.
As bibliotecas e ferramentas de aprendizagem profunda mais populares utilizadas para a construção de redes neurais profundas são TensorFlow, Keras e PyTorch. As bibliotecas do Keras e do TensorFlow foram vinculadas como sinônimos desde o início do TensorFlow 2.0. Essa integração permite que os usuários desenvolvam redes neurais complexas com estruturas de código de alto nível usando o Keras dentro da rede TensorFlow.
A biblioteca PyTorch é outra estrutura de aprendizado de máquina extremamente popular que permite aos usuários desenvolver projetos de pesquisa de alto nível.
Embora falte um pouco no departamento de visualização, o PyTorch compensa com seu desempenho compacto e rápido, com instalações de GPU relativamente mais rápidas e simples para a construção de modelos de redes neurais profundas.
O curso Introduction to PyTorch in Python da DataCamp é o melhor ponto de partida para aprender mais sobre o PyTorch.
A estrutura do TensorFlow oferece a seus desenvolvedores uma ampla gama de opções fantásticas de ferramentas de visualização para tarefas de aprendizagem profunda. O painel gráfico do tensorboard é uma excelente opção para visualizar, analisar e interpretar os dados e os resultados de um projeto.
A integração da biblioteca Keras permite a construção mais rápida de projetos com estruturas de código simplificadas, tornando-a uma escolha popular para projetos de desenvolvimento de longo prazo. A Introdução ao TensorFlow em Python é um ótimo lugar para os iniciantes começarem a usar o TensorFlow.
Nesta seção, entenderemos alguns conceitos fundamentais das redes neurais profundas e como construir uma rede desse tipo a partir do zero.
A primeira etapa é escolher sua biblioteca preferida para o aplicativo necessário. Usaremos as estruturas de aprendizagem profunda do TensorFlow e do Keras para construir a rede neural profunda.
# Importing the necessary functionality
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Input, Dense, Conv2D
from tensorflow.keras.layers import Flatten, MaxPooling2DQuando terminarmos de importar as bibliotecas desejadas para essa tarefa, usaremos a modelagem do tipo Sequential para criar o modelo de aprendizagem profunda. O modelo sequencial é uma pilha simples de camadas com um valor de entrada e saída. As outras opções disponíveis são a classe API funcional ou uma criação de modelo personalizado. Entretanto, a classe Sequential oferece uma abordagem direta para a construção da arquitetura da rede neural.
# Creating the model
DNN_Model = Sequential()
Adicionaremos uma forma de entrada, geralmente equivalente ao tamanho do tipo de imagem que você está utilizando em seu projeto. O tamanho contém a largura, a altura e a codificação de cores da imagem. No código de exemplo abaixo, a altura e a largura da imagem são 256 com um esquema de cores RGB, representado por 3 (1 é usado para imagens em escala de cinza). Em seguida, construiremos as camadas ocultas necessárias com convolução e camadas de pooling máximo com tamanhos de filtro variados. Por fim, utilizaremos uma camada achatada para achatar as saídas e usar uma camada densa como a camada de saída final.
As camadas ocultas aumentam a complexidade da rede neural. Uma camada convolucional executa uma operação de convolução em imagens visuais para filtrar as informações. Cada tamanho de filtro em uma camada de convolução ajuda a extrair recursos específicos da entrada. Uma camada de pooling máximo ajuda a reduzir a amostragem (reduzir) o número de recursos considerando os valores máximos dos recursos extraídos.
Uma camada achatada reduz as dimensões espaciais em uma única dimensão para acelerar a computação. Uma camada densa é a camada mais simples que recebe uma saída das camadas anteriores e é normalmente usada como a camada de saída. A convolução 2D realiza uma multiplicação por elementos em uma entrada 2D. A função de ativação ReLU (unidade linear retificada) fornece não linearidade ao modelo para um melhor desempenho de computação. Usaremos o mesmo preenchimento para manter as formas de entrada e saída das camadas convolucionais.
# Inputting the shape to the model
DNN_Model.add(Input(shape = (256, 256, 3)))
# Creating the deep neural network
DNN_Model.add(Conv2D(256, (3, 3), activation='relu', padding = "same"))
DNN_Model.add(MaxPooling2D(2, 2))
DNN_Model.add(Conv2D(128, (3, 3), activation='relu', padding = "same"))
DNN_Model.add(MaxPooling2D(2, 2))
DNN_Model.add(Conv2D(64, (3, 3), activation='relu', padding = "same"))
DNN_Model.add(MaxPooling2D(2, 2))
# Creating the output layers
DNN_Model.add(Flatten())
DNN_Model.add(Dense(64, activation='relu'))
DNN_Model.add(Dense(10))A estrutura do modelo e o diagrama de plotagem da rede neural profunda construída são fornecidos abaixo.
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_5 (Conv2D) (None, 256, 256, 256) 7168
max_pooling2d_5 (MaxPooling (None, 128, 128, 256) 0
2D)
conv2d_6 (Conv2D) (None, 128, 128, 128) 295040
max_pooling2d_6 (MaxPooling (None, 64, 64, 128) 0
2D)
conv2d_7 (Conv2D) (None, 64, 64, 64) 73792
max_pooling2d_7 (MaxPooling (None, 32, 32, 64) 0
2D)
flatten_2 (Flatten) (None, 65536) 0
dense_4 (Dense) (None, 64) 4194368
dense_5 (Dense) (None, 10) 650
=================================================================
Total params: 4,571,018
Trainable params: 4,571,018
Non-trainable params: 0
_________________________________________________________________O enredo é o seguinte:
tf.keras.utils.plot_model(DNN_Model, to_file='model_big.png', show_shapes=True)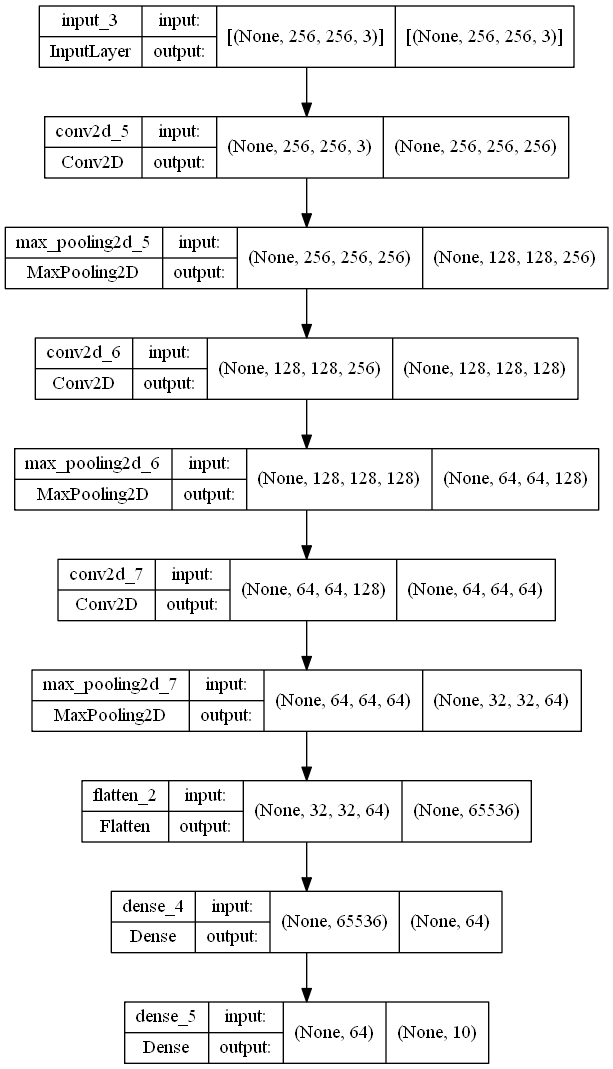
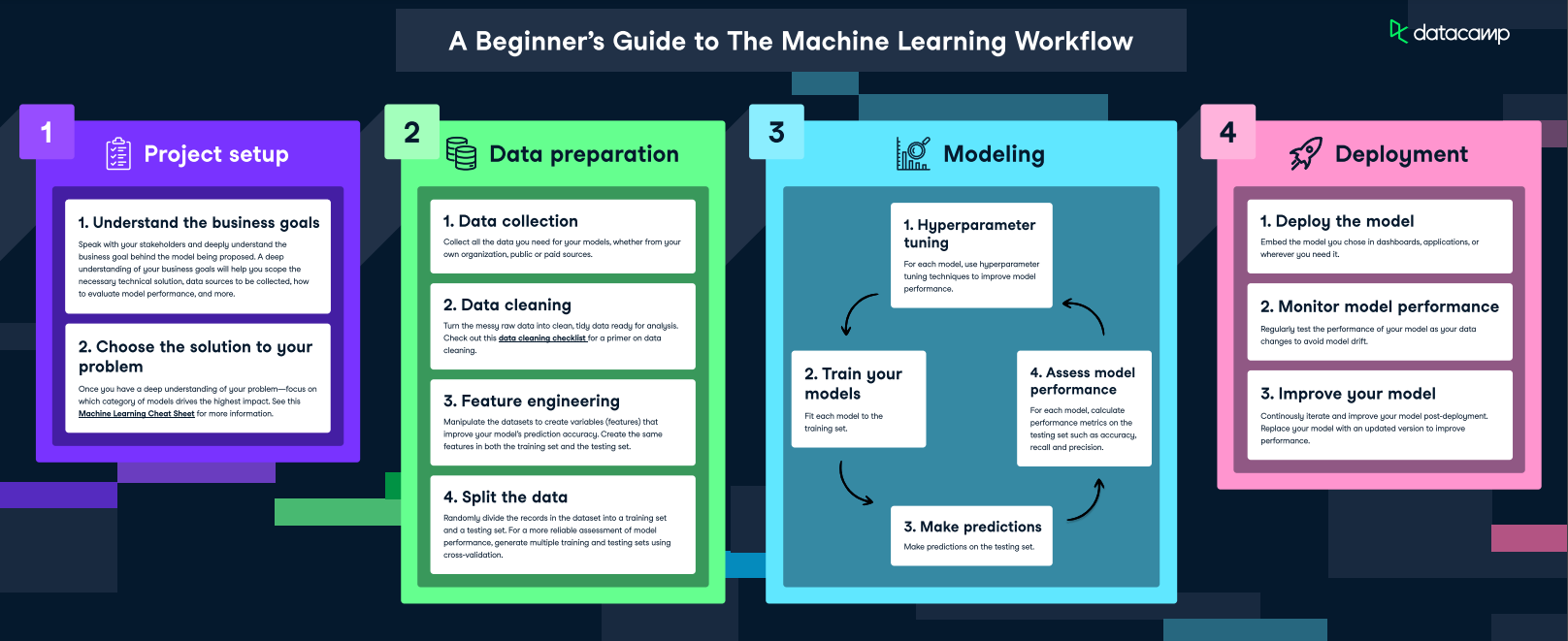
Fluxo de trabalho de aprendizado de máquina - Fonte da imagem
Depois que o modelo é criado, ele precisa ser compilado para configurá-lo. Durante a compilação do modelo, as operações significativas nos modelos de aprendizagem profunda incluem a propagação direta e a retropropagação. Na propagação direta, todas as informações essenciais são passadas pelos diferentes nós até a camada de saída. Na camada de saída, para tarefas de classificação, os valores previstos e os valores reais são calculados de acordo.
No estágio de treinamento ou ajuste, ocorre o processo de retropropagação. Os pesos são reajustados em cada camada, fixando os pesos até que os valores previstos e reais se aproximem um do outro para alcançar os resultados desejados. Para obter uma explicação detalhada sobre esse tópico, recomendo consultar o seguinte guia de retropropagação de um curso de Introdução à aprendizagem profunda em Python.
Há muitas complexidades na exploração da aprendizagem profunda. Recomendo enfaticamente que você confira o curso Deep Learning with Keras para entender melhor como construir redes neurais profundas.
O cálculo de qualquer tarefa específica de aprendizado de máquina requer uma rede neural profunda específica para executar as ações necessárias. Dois modelos de aprendizagem profunda utilizados principalmente são as redes neurais convolucionais (CNN) e as redes neurais recorrentes (RNN). As redes neurais convolucionais são de grande utilidade em projetos de processamento de imagens e visão computacional.
Nessas redes neurais profundas, em vez de realizar uma operação típica de matriz nas camadas ocultas, realizamos uma operação de convolução. Ele permite que a rede tenha uma abordagem mais dimensionável, produzindo maior eficiência e resultados precisos. Nas tarefas de classificação de imagens e detecção de objetos, há uma grande quantidade de dados e imagens para o modelo calcular. Essas redes neurais convolucionais ajudam a combater esses problemas com sucesso.
Para projetos de processamento de linguagem natural e semântica, as redes neurais recorrentes são frequentemente usadas para otimizar os resultados. Uma variante popular desses RNNs, a memória de longo e curto prazo (LSTMs), é normalmente usada para executar várias tarefas de tradução automática, classificação de texto, reconhecimento de fala e outras tarefas semelhantes.
Essas redes carregam as informações essenciais de cada uma das células anteriores e as transmitem para a próxima, enquanto armazenam as informações cruciais para otimizar o desempenho do modelo. O Convolutional Neural Networks for Image Processing é um guia fantástico para explorar mais sobre CNNs e aprendizagem profunda em Python para uma compreensão completa da aprendizagem profunda.
Temos um breve conhecimento sobre redes neurais profundas e sua construção com a estrutura de aprendizagem profunda do TensorFlow. No entanto, há certos desafios que todo desenvolvedor deve considerar antes de desenvolver uma rede neural para um projeto específico. Vamos dar uma olhada em alguns desses desafios.
Um dos principais requisitos para a aprendizagem profunda são os dados. Os dados são o componente mais importante na construção de um modelo altamente preciso. Em vários casos, as redes neurais profundas normalmente exigem grandes quantidades de dados para evitar o ajuste excessivo e ter um bom desempenho. Os requisitos de dados para tarefas de detecção de objetos podem exigir mais dados para que um modelo detecte diferentes objetos com alta precisão.
Embora as técnicas de aumento de dados sejam úteis como uma solução rápida para alguns desses problemas, os requisitos de dados são uma obrigação a ser considerada em todos os projetos de aprendizagem profunda.
Além de uma grande quantidade de dados, também é preciso considerar o alto custo computacional do cálculo da rede neural profunda. Modelos como o Generative Pre-trained Transformer 3 (GPT-3) têm 175 bilhões de parâmetros, por exemplo.
A compilação e o treinamento de modelos para tarefas complexas exigirão uma GPU com recursos. Em geral, os modelos podem ser treinados com mais eficiência em GPUs ou TPUs em vez de CPUs. Para tarefas extremamente complexas, os requisitos do sistema são mais altos, exigindo mais recursos para uma determinada tarefa.
Durante o treinamento, o modelo também pode encontrar problemas como subajuste ou superajuste. O subajuste geralmente ocorre devido à falta de dados, enquanto o superajuste é um problema mais proeminente que ocorre devido ao aprimoramento constante dos dados de treinamento, enquanto os dados de teste permanecem constantes. Portanto, a precisão do treinamento é alta, mas a precisão da validação é baixa, levando a um modelo altamente instável que não produz os melhores resultados.
Neste artigo, exploramos as redes neurais profundas e entendemos seus principais conceitos. Compreendemos a diferença entre essas redes neurais e uma rede tradicional e desenvolvemos um entendimento dos diferentes tipos de estruturas de aprendizagem profunda para projetos de aprendizagem profunda de computação. Em seguida, usamos as bibliotecas TensorFlow e Keras para demonstrar uma construção de rede neural profunda. Por fim, consideramos alguns dos principais desafios da aprendizagem profunda e alguns métodos para superá-los.
As redes neurais profundas são um recurso fantástico para realizar a maioria dos aplicativos e projetos comuns de inteligência artificial. Eles nos permitem resolver tarefas de processamento de imagens e de linguagem natural com alta precisão.
É importante que todos os desenvolvedores qualificados se mantenham atualizados com as tendências emergentes, pois um modelo que é popular hoje pode não ser tão popular ou a melhor opção no futuro próximo.
Portanto, é essencial continuar aprendendo e adquirindo conhecimento, pois o mundo da inteligência artificial é uma aventura repleta de entusiasmo e novos desenvolvimentos tecnológicos. Uma das melhores maneiras de se manter atualizado é conferir a trilha de habilidades de aprendizagem profunda em Python do DataCamp para abordar tópicos como TensorFlow e Keras e aprendizagem profunda em PyTorch para saber mais sobre o PyTorch. Você também pode conferir os cursos AI Fundamentals para uma introdução mais suave. O primeiro ajuda a liberar o enorme potencial dos projetos de aprendizagem profunda, enquanto o segundo ajuda a estabilizar as bases.
Aprenda sobre os tópicos mencionados neste tutorial!
Programa
Curso
Curso
blog
Abid Ali Awan
7 min
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan




