
Cursus
Principes fondamentaux de Keras
16 h
Les réseaux neuronaux profonds ont changé le paysage de l'intelligence artificielle à l'ère moderne. Ces derniers temps, plusieurs avancées de la recherche ont été réalisées à la fois dans le domaine de l'apprentissage profond et des réseaux neuronaux, ce qui augmente considérablement la qualité des projets liés à l'intelligence artificielle.
Ces réseaux neuronaux profonds aident les développeurs à obtenir des résultats plus durables et de meilleure qualité. C'est pourquoi elles remplacent même plusieurs techniques conventionnelles d'apprentissage automatique.
Mais que sont exactement les réseaux neuronaux profonds et pourquoi constituent-ils le choix le plus optimal pour un large éventail de tâches ? Et quels sont les différentes bibliothèques et les différents outils pour commencer à utiliser les réseaux neuronaux profonds ?
Cet article explique les réseaux neuronaux profonds, les exigences de leur bibliothèque et la manière de construire une architecture de réseau neuronal profond de base à partir de zéro.
Un réseau neuronal artificiel (RNA) ou un réseau neuronal traditionnel simple vise à résoudre des tâches triviales à l'aide d'un réseau simple. Un réseau neuronal artificiel est librement inspiré des réseaux neuronaux biologiques. Il s'agit d'un ensemble de couches permettant d'effectuer une tâche spécifique. Chaque couche est constituée d'un ensemble de nœuds qui fonctionnent ensemble.
Ces réseaux se composent généralement d'une couche d'entrée, d'une ou deux couches cachées et d'une couche de sortie. S'il est possible de résoudre des questions mathématiques et des problèmes informatiques simples, y compris des structures de portes de base avec leurs tableaux de vérité respectifs, il est difficile pour ces réseaux de résoudre des tâches compliquées de traitement d'images, de vision par ordinateur et de traitement du langage naturel.
Pour ces problèmes, nous utilisons des réseaux neuronaux profonds, qui ont souvent une structure complexe de couches cachées avec une grande variété de couches différentes, telles qu'une couche convolutive, une couche de mise en commun maximale, une couche dense et d'autres couches uniques. Ces couches supplémentaires aident le modèle à mieux comprendre les problèmes et à fournir des solutions optimales à des projets complexes. Un réseau neuronal profond comporte plus de couches (plus de profondeur) que l'ANN et chaque couche ajoute de la complexité au modèle tout en permettant au modèle de traiter les entrées de manière concise pour produire la solution idéale.
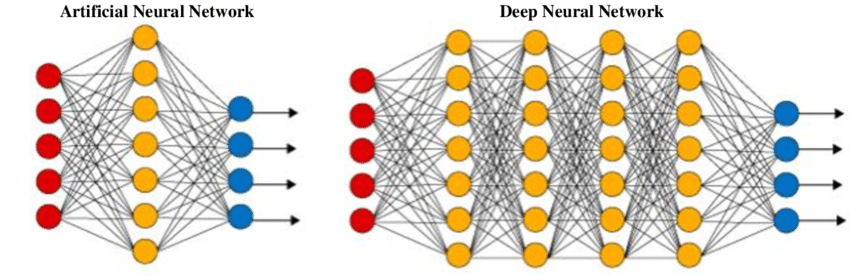
ANN vs DNN - Source de l'image
Les réseaux neuronaux profonds ont suscité un engouement considérable en raison de leur grande efficacité dans la réalisation de nombreux projets d'apprentissage profond. Découvrez les différences entre l'apprentissage automatique et l'apprentissage profond dans un autre article.
Après avoir entraîné un réseau neuronal profond bien construit, ils peuvent obtenir les résultats souhaités avec des scores de précision élevés. Ils sont populaires dans tous les aspects de l'apprentissage profond, y compris la vision par ordinateur, le traitement du langage naturel et l'apprentissage par transfert.
Les premiers exemples de l'importance des réseaux neuronaux profonds sont leur utilité dans la détection d'objets avec des modèles tels que YOLO (You Only Look Once), les tâches de traduction linguistique avec les modèles BERT (Bidirectional Encoder Representations from Transformers), les modèles d'apprentissage par transfert, tels que VGG-19, RESNET-50, efficient net, et d'autres réseaux similaires pour les projets de traitement d'images.
Pour comprendre plus intuitivement ces concepts d'apprentissage profond de l'intelligence artificielle, je vous recommande de consulter le cours Deep Learning in Python de DataCamp.
La construction de réseaux neuronaux à partir de zéro aide les programmeurs à comprendre les concepts et à résoudre des tâches triviales en manipulant ces réseaux. Toutefois, la mise en place de ces réseaux à partir de zéro prend du temps et nécessite des efforts considérables. Pour simplifier l'apprentissage profond, nous disposons de plusieurs outils et bibliothèques permettant de créer un modèle de réseau neuronal profond efficace, capable de résoudre des problèmes complexes en quelques lignes de code.
Les bibliothèques et outils d'apprentissage profond les plus populaires utilisés pour construire des réseaux neuronaux profonds sont TensorFlow, Keras et PyTorch. Les bibliothèques Keras et TensorFlow sont liées de manière synonyme depuis le début de TensorFlow 2.0. Cette intégration permet aux utilisateurs de développer des réseaux neuronaux complexes avec des structures de code de haut niveau en utilisant Keras au sein du réseau TensorFlow.
La bibliothèque PyTorch est un autre cadre d'apprentissage automatique extrêmement populaire qui permet aux utilisateurs de développer des projets de recherche de haut niveau.
Bien qu'il soit légèrement moins performant dans le domaine de la visualisation, PyTorch compense ses performances compactes et rapides par des installations GPU relativement plus rapides et plus simples pour la construction de modèles de réseaux neuronaux profonds.
Le cours Introduction à PyTorch en Python de DataCamp est le meilleur point de départ pour en savoir plus sur PyTorch.
Le framework TensorFlow offre à ses développeurs un large éventail d'options fantastiques pour les outils de visualisation des tâches d'apprentissage profond. Le tableau de bord graphique tensorboard constitue un choix exceptionnel pour visualiser, analyser et interpréter les données et les résultats d'un projet en conséquence.
L'intégration de la bibliothèque Keras permet de construire plus rapidement des projets avec des structures de code simplistes, ce qui en fait un choix populaire pour les projets de développement à long terme. L'introduction à TensorFlow en Python permet aux débutants de s'initier à TensorFlow.
Dans cette section, nous allons comprendre certains concepts fondamentaux des réseaux neuronaux profonds et comment construire un tel réseau à partir de zéro.
La première étape consiste à choisir votre bibliothèque préférée pour l'application requise. Nous utiliserons les cadres d'apprentissage profond TensorFlow et Keras pour construire le réseau neuronal profond.
# Importing the necessary functionality
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Input, Dense, Conv2D
from tensorflow.keras.layers import Flatten, MaxPooling2DUne fois que nous aurons fini d'importer les bibliothèques souhaitées pour cette tâche, nous utiliserons la modélisation de type séquentiel pour construire le modèle d'apprentissage profond. Le modèle séquentiel est une simple pile de couches avec une valeur d'entrée et une valeur de sortie. Les autres options disponibles sont la classe API fonctionnelle ou la création d'un modèle personnalisé. Cependant, la classe séquentielle offre une approche directe de la construction de l'architecture du réseau neuronal.
# Creating the model
DNN_Model = Sequential()
Nous ajouterons une forme d'entrée, généralement équivalente à la taille du type d'image que vous utilisez dans votre projet. La taille contient la largeur, la hauteur et le code couleur de l'image. Dans l'exemple de code ci-dessous, la hauteur et la largeur de l'image sont de 256 avec un schéma de couleurs RVB, représenté par 3 (1 est utilisé pour les images en niveaux de gris). Nous construirons ensuite les couches cachées nécessaires avec des couches de convolution et de mise en commun maximale avec différentes tailles de filtre. Enfin, nous utiliserons une couche aplatie pour aplatir les sorties et utiliserons une couche dense comme couche de sortie finale.
Les couches cachées ajoutent à la complexité du réseau neuronal. Une couche convolutive effectue une opération de convolution sur les images visuelles pour filtrer les informations. Chaque taille de filtre dans une couche de convolution permet d'extraire des caractéristiques spécifiques de l'entrée. Une couche de mise en commun des valeurs maximales permet de réduire le nombre de caractéristiques en prenant en compte les valeurs maximales des caractéristiques extraites.
Une couche aplatie réduit les dimensions spatiales en une seule dimension pour un calcul plus rapide. Une couche dense est la couche la plus simple qui reçoit une sortie des couches précédentes et est généralement utilisée comme couche de sortie. La convolution 2D effectue une multiplication par éléments sur une entrée 2D. La fonction d'activation ReLU (unité linéaire rectifiée) confère une non-linéarité au modèle afin d'améliorer les performances de calcul. Nous utiliserons le même remplissage pour maintenir les formes d'entrée et de sortie des couches convolutives.
# Inputting the shape to the model
DNN_Model.add(Input(shape = (256, 256, 3)))
# Creating the deep neural network
DNN_Model.add(Conv2D(256, (3, 3), activation='relu', padding = "same"))
DNN_Model.add(MaxPooling2D(2, 2))
DNN_Model.add(Conv2D(128, (3, 3), activation='relu', padding = "same"))
DNN_Model.add(MaxPooling2D(2, 2))
DNN_Model.add(Conv2D(64, (3, 3), activation='relu', padding = "same"))
DNN_Model.add(MaxPooling2D(2, 2))
# Creating the output layers
DNN_Model.add(Flatten())
DNN_Model.add(Dense(64, activation='relu'))
DNN_Model.add(Dense(10))La structure du modèle et le diagramme du réseau neuronal profond construit sont présentés ci-dessous.
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_5 (Conv2D) (None, 256, 256, 256) 7168
max_pooling2d_5 (MaxPooling (None, 128, 128, 256) 0
2D)
conv2d_6 (Conv2D) (None, 128, 128, 128) 295040
max_pooling2d_6 (MaxPooling (None, 64, 64, 128) 0
2D)
conv2d_7 (Conv2D) (None, 64, 64, 64) 73792
max_pooling2d_7 (MaxPooling (None, 32, 32, 64) 0
2D)
flatten_2 (Flatten) (None, 65536) 0
dense_4 (Dense) (None, 64) 4194368
dense_5 (Dense) (None, 10) 650
=================================================================
Total params: 4,571,018
Trainable params: 4,571,018
Non-trainable params: 0
_________________________________________________________________L'intrigue est la suivante :
tf.keras.utils.plot_model(DNN_Model, to_file='model_big.png', show_shapes=True)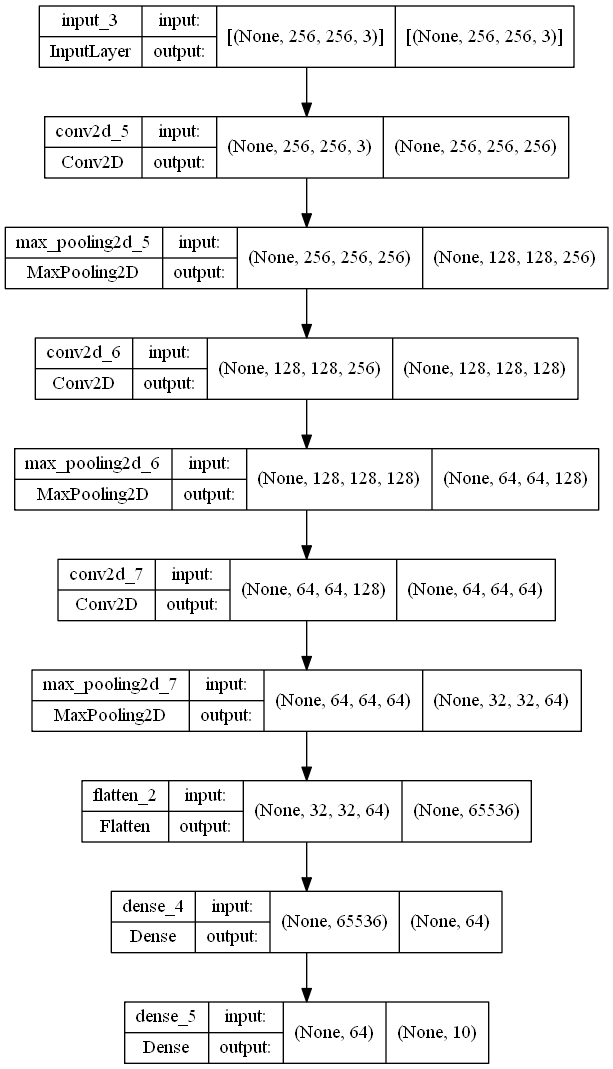
Flux de travail de l'apprentissage automatique - Source de l'image
Une fois le modèle construit, il doit être compilé pour être configuré. Lors de la compilation du modèle, les opérations significatives dans les modèles d'apprentissage profond comprennent la propagation vers l'avant et la rétropropagation. Dans la propagation vers l'avant, toutes les informations essentielles passent par les différents nœuds jusqu'à la couche de sortie. Dans la couche de sortie, pour les tâches de classification, les valeurs prédites et les valeurs réelles sont calculées en conséquence.
Lors de la phase de formation ou d'adaptation, le processus de rétropropagation intervient. Les poids sont réajustés dans chaque couche en fixant les poids jusqu'à ce que les valeurs prédites et les valeurs réelles soient proches l'une de l'autre afin d'obtenir les résultats souhaités. Pour une explication approfondie de ce sujet, je vous recommande de vérifier le guide de rétropropagation suivant, tiré d'un cours d'introduction à l'apprentissage profond en Python.
L'exploration de l'apprentissage profond comporte de nombreuses subtilités. Je vous recommande vivement de consulter le cours Deep Learning with Keras pour mieux comprendre comment construire des réseaux neuronaux profonds.
Le calcul d'une tâche particulière d'apprentissage automatique nécessite un réseau neuronal profond spécifique pour effectuer les actions nécessaires. Les réseaux neuronaux convolutifs (CNN) et les réseaux neuronaux récurrents (RNN) sont deux modèles d'apprentissage profond principalement utilisés. Les réseaux neuronaux convolutifs sont extrêmement utiles dans les projets de traitement d'images et de vision par ordinateur.
Dans ces réseaux neuronaux profonds, au lieu d'effectuer une opération matricielle classique dans les couches cachées, nous effectuons une opération de convolution. Il permet au réseau d'avoir une approche plus évolutive produisant une plus grande efficacité et des résultats plus précis. Dans les tâches de classification d'images et de détection d'objets, le modèle doit calculer un grand nombre de données et d'images. Ces réseaux neuronaux convolutifs permettent de résoudre ces problèmes avec succès.
Pour le traitement du langage naturel et les projets sémantiques, les réseaux neuronaux récurrents sont souvent utilisés pour optimiser les résultats. Une variante populaire de ces RNN, les mémoires à long et court terme (LSTM), est généralement utilisée pour effectuer diverses tâches de traduction automatique, de classification de texte, de reconnaissance vocale et d'autres tâches similaires.
Ces réseaux transportent les informations essentielles de chacune des cellules précédentes et les transmettent à la suivante, tout en stockant les informations cruciales pour une performance optimisée du modèle. Les réseaux neuronaux convolutifs pour le traitement des images est un guide fantastique pour explorer plus sur les CNN et l'apprentissage profond en Python pour une compréhension approfondie de l'apprentissage profond.
Nous avons une brève compréhension des réseaux neuronaux profonds et de leur construction avec le cadre d'apprentissage profond TensorFlow. Cependant, chaque développeur doit tenir compte de certains défis avant de mettre au point un réseau neuronal pour un projet particulier. Examinons quelques-uns de ces défis.
Les données constituent l'une des principales exigences de l'apprentissage profond. Les données sont l'élément le plus important dans la construction d'un modèle très précis. Dans plusieurs cas, les réseaux neuronaux profonds nécessitent généralement de grandes quantités de données afin d'éviter un surajustement et d'obtenir de bons résultats. Les exigences en matière de données pour les tâches de détection d'objets peuvent nécessiter davantage de données pour qu'un modèle puisse détecter différents objets avec une grande précision.
Bien que les techniques d'augmentation des données soient utiles pour résoudre rapidement certains de ces problèmes, les exigences en matière de données doivent être prises en compte pour chaque projet d'apprentissage profond.
Outre la grande quantité de données, il faut également tenir compte du coût de calcul élevé du réseau neuronal profond. Des modèles comme le Generative Pre-trained Transformer 3 (GPT-3) ont 175 milliards de paramètres, par exemple.
La compilation et la formation de modèles pour des tâches complexes nécessiteront un GPU plein de ressources. Les modèles peuvent souvent être formés plus efficacement sur des GPU ou des TPU que sur des CPU. Pour les tâches extrêmement complexes, les exigences du système sont plus élevées, ce qui nécessite plus de ressources pour une tâche particulière.
Au cours de la formation, le modèle peut également rencontrer des problèmes tels que le sous-ajustement ou le surajustement. L'inadaptation est généralement due à un manque de données, tandis que l'inadaptation excessive est un problème plus important qui se produit lorsque les données d'entraînement s'améliorent constamment alors que les données de test restent constantes. Par conséquent, la précision de l'apprentissage est élevée, mais la précision de la validation est faible, ce qui conduit à un modèle très instable qui ne donne pas les meilleurs résultats.
Dans cet article, nous avons exploré les réseaux neuronaux profonds et compris leurs concepts fondamentaux. Nous avons compris la différence entre ces réseaux neuronaux et un réseau traditionnel et nous avons acquis une compréhension des différents types de cadres d'apprentissage profond pour les projets d'apprentissage profond. Nous avons ensuite utilisé les bibliothèques TensorFlow et Keras pour faire la démonstration de la construction d'un réseau neuronal profond. Enfin, nous avons examiné certains des défis critiques de l'apprentissage profond et quelques méthodes pour les surmonter.
Les réseaux neuronaux profonds constituent une ressource fantastique pour réaliser la plupart des applications et projets d'intelligence artificielle courants. Ils nous permettent de résoudre des tâches de traitement d'image et de traitement du langage naturel avec une grande précision.
Il est important pour tous les développeurs compétents de se tenir au courant des nouvelles tendances, car un modèle qui est populaire aujourd'hui ne le sera peut-être plus ou ne sera plus le meilleur choix dans un avenir proche.
Il est donc essentiel de continuer à apprendre et à acquérir des connaissances, car le monde de l'intelligence artificielle est une aventure pleine d'excitation et de nouveaux développements technologiques. L'une des meilleures façons de rester à jour est de consulter le cursus Deep Learning in Python Skill de DataCamp pour couvrir des sujets tels que TensorFlow et Keras et Deep Learning in PyTorch pour en savoir plus sur PyTorch. Vous pouvez également consulter les cours sur les principes fondamentaux de l'IA pour une introduction plus douce. La première aide à libérer l'énorme potentiel des projets d'apprentissage en profondeur, tandis que la seconde aide à stabiliser les fondations.
Apprenez-en plus sur les sujets mentionnés dans ce tutoriel !
Cursus
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min