
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Die Llama 3.2-Familie bietet eine Reihe leistungsstarker Modelle, die Seh- und Sprachverständnis kombinieren. Die beiden größten Modelle, 11B und 90B, wurden speziell für komplexe Aufgaben entwickelt, bei denen visuelle und textliche Informationen zusammen verstanden werden müssen.
Diese Modelle zeichnen sich durch das Lesen und Analysieren von Diagrammen, Grafiken und Tabellen aus und sind damit perfekt geeignet, um Erkenntnisse zu gewinnen, mit denen herkömmliche reine Textmodelle Schwierigkeiten haben. Ein Geschäftsinhaber könnte zum Beispiel fragen: "Welcher Monat hatte letztes Jahr den höchsten Gewinn?" und Llama 3.2 würde sich die Rentabilitätskarte ansehen und die richtige Antwort geben.
Außerdem können die Modelle Objekte in Bildern anhand von Beschreibungen lokalisieren. Ob du Landmarken auf einer Karte entdeckst oder Trends in einem Diagramm erkennst, Llama 3.2 kann das ganz einfach erledigen.
Llama 3.2 kann nicht nur mit Top-Konkurrenten wie Claude 3 Haiku und GPT4o-mini mithalten, sondern schneidet bei Aufgaben wie dem Erkennen von Bildern und dem Verstehen von visuellen Darstellungen genauso gut ab, wie die auf Vision-Instruktionen abgestimmten Benchmarks zeigen. Die Fähigkeit, sowohl mit Text als auch mit Bildern zu arbeiten, bedeutet, dass es natürlichere, flexiblere Konversationen führen kann, die visuelle und schriftliche Informationen mischen, was es ideal für eine Vielzahl von Anwendungsfällen macht.
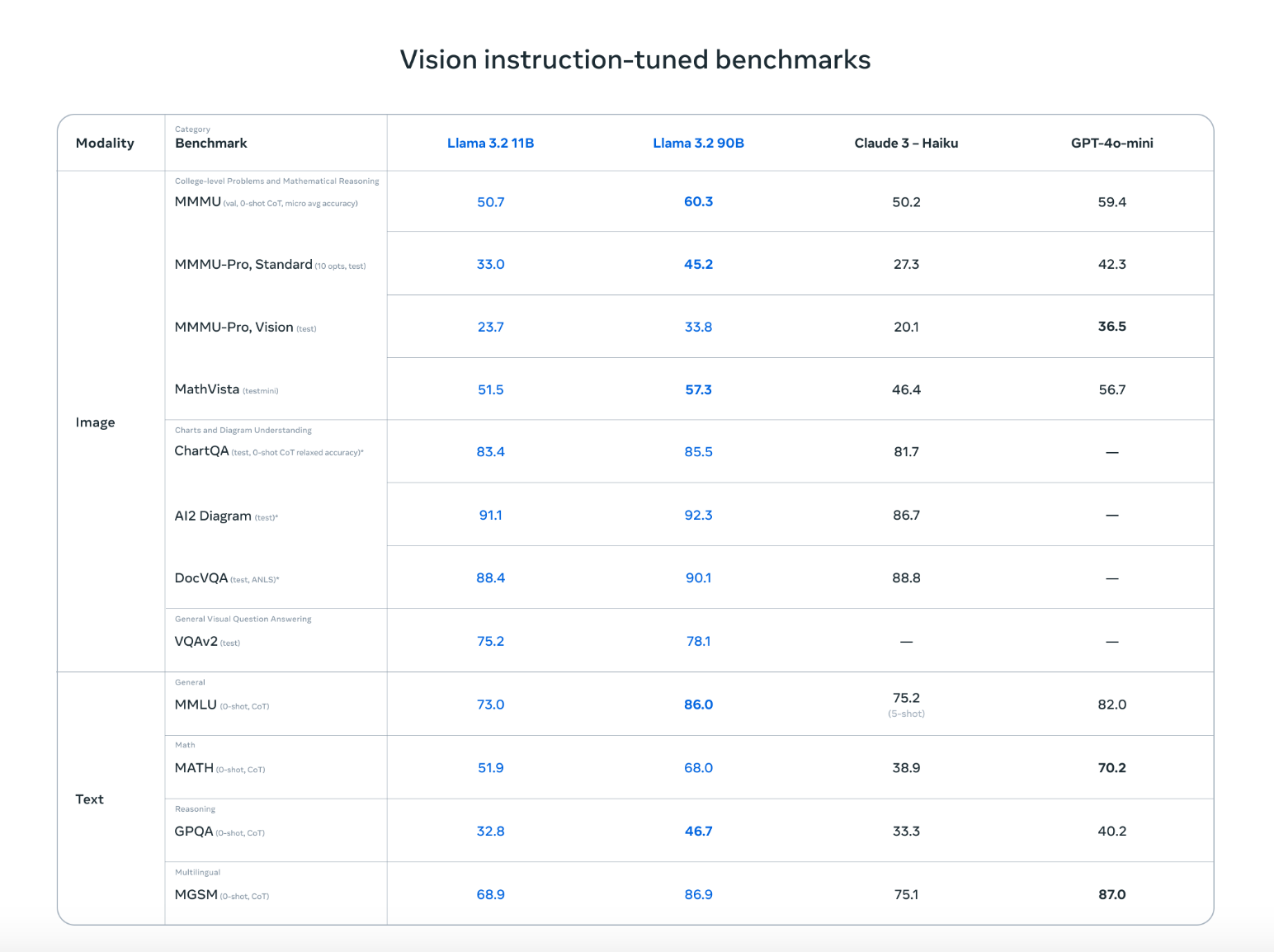
Quelle: Meta AI
Mit diesen erweiterten Funktionen eröffnen die Llama 3.2 Vision Modelle neue Möglichkeiten für RAG Anwendungen. Sie machen es viel einfacher, Erkenntnisse aus komplizierten Datenquellen wie PDFs zu ziehen, indem sie Bilder und Text für genauere und nützlichere Ergebnisse kombinieren.
Um eine RAG-Anwendung mit Llama 3.2 Vision einzurichten, müssen wir das Llama 3.2 Vision-Modell herunterladen, die Umgebung einrichten, die erforderlichen Bibliotheken installieren und ein Abrufsystem erstellen. Im Folgenden findest du eine einfache Schritt-für-Schritt-Anleitung, die dir hilft, eine RAG-Anwendung mit Llama 3.2 Vision und ColPali zu implementieren.
Bitte beachte, dass die folgenden Schritte auf einem Colab Pro-Notebook mit einer A100-Instanz getestet wurden.
Stelle zunächst sicher, dass du die erforderlichen Abhängigkeiten installiert hast:
!pip install byaldi
!sudo apt-get install -y poppler-utils
!pip install -q git+https://github.com/huggingface/transformers.git qwen-vl-utils flash-attn optimum auto-gptq bitsandbytes
!pip install ollama
!pip install colab-xtermDie Bibliothek byaldi ist für die Indizierung und Suche in multimodalen Dokumenten unerlässlich, während andere Tools wie poppler-utils für die Bearbeitung von PDFs benötigt werden.
ColPali ist eine Methode, die die Dokumentensuche verbessert, indem sie Bilder von Dokumentenseiten, wie z.B. gescannte PDFs, direkt einbettet, anstatt sich nur auf extrahierten Text zu verlassen. Mit fortschrittlichen visuellen Sprachmodellen wie PaliGemma und einem Mechanismus für die späte Interaktion kann ColPali komplexe visuelle Elemente (Tabellen, Bilder und Grafiken) effizient verarbeiten und so eine genauere und schnellere Dokumentensuche ermöglichen.
Wir werden ColPali verwenden, um unsere PDFs in Einbettungen zu kodieren. Du kannst das ColPali RAGMultiModalModel wie folgt laden:
import os
import base64
from byaldi import RAGMultiModalModel
RAG = RAGMultiModalModel.from_pretrained("vidore/colpali-v1.2", verbose=1)Wir werden das berühmte Attention is All You Need Paper herunterladen und mit Hilfe von RAGMultiModalModel einen Index dafür erstellen. Dieser Schritt verarbeitet das Dokument und extrahiert visuelle und textuelle Daten für ein schnelles Abrufen.
!wget <https://arxiv.org/pdf/1706.03762>
!mkdir docs
!mv 1706.03762 docs/attention.pdfRAG.index(
input_path="./docs/attention.pdf",
index_name="attention",
store_collection_with_index=True, # Store base64 representation of images
overwrite=True
)Added page 1 of document 0 to index.
Added page 2 of document 0 to index.
Added page 3 of document 0 to index.
Added page 4 of document 0 to index.
Added page 5 of document 0 to index.
Added page 6 of document 0 to index.
Added page 7 of document 0 to index.
Added page 8 of document 0 to index.
Added page 9 of document 0 to index.
Added page 10 of document 0 to index.
Added page 11 of document 0 to index.
Added page 12 of document 0 to index.
Added page 13 of document 0 to index.
Added page 14 of document 0 to index.
Added page 15 of document 0 to index.
Index exported to .byaldi/attention
Index exported to .byaldi/attention
{0: 'docs/attention.pdf'}Sobald du das Dokument indiziert hast, kannst du relevante Inhalte aus dem Dokument wie folgt abrufen:
query = "What's the BLEU score of the transformer architecture in EN-DE"
results = RAG.search(query, k=1)
results[{'doc_id': 0, 'page_num': 8, 'score': 19.0, 'metadata': {}, 'base64': 'iVBORw0KGgoAAAANSUhEUgAABqQAAAiYCAIAAAA+NVHkAAEAAElEQVR4nOzdd1gUx/8H8KGDoC....'}]Damit wird die oberste übereinstimmende Seite oder das oberste übereinstimmende visuelle Element aus der indizierten PDF-Datei abgerufen.
Um die abgerufene Seite zu visualisieren, können wir das Bild in einer Datei speichern und es wie folgt anzeigen:
from IPython.display import Image
def see_image(image_base64):
image_bytes = base64.b64decode(image_base64)
filename = 'image.jpg'
with open(filename, 'wb') as f:
f.write(image_bytes)
display(Image(filename))
# For multiple retrieved pages
for res in results:
see_image(res['base64'])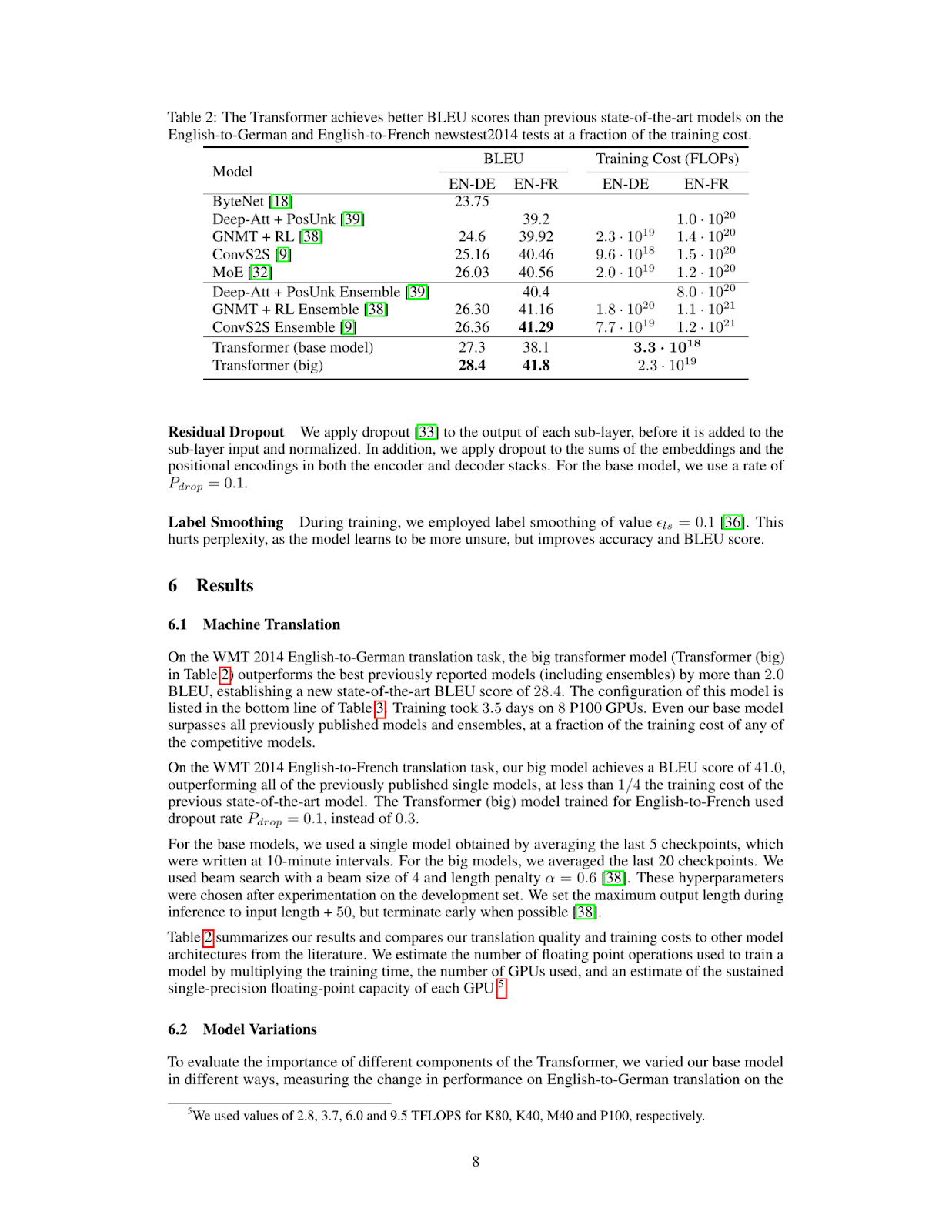
Wie du siehst, enthält die abgerufene Seite die Informationen, die wir brauchen, um die Frage What's the BLEU score of the transformer architecture in EN-DE zu beantworten. Im nächsten Schritt wird dieses Bild zusammen mit der Frage des Nutzers in unser Llama 3.2 Vision Modell eingegeben.
Um das Llama 3.2 Vision Modell zu installieren und einzurichten, verwenden wir Ollama auf einem Colab Pro Notebook mit einer A100 Instanz. Du führst Ollama auf dem Notebook aus und lädst das Llama 3.2 Vision Modell herunter, um es zu benutzen.
%load_ext colabxterm
%xterm%xterm erstellt ein Terminal innerhalb des Notebooks, von dem du dann Ollama mit diesem Befehl curl -fsSL | sh herunterladen und dann den folgenden Befehl ausführen kannst, um das Llama 3.2 11B Vision Modell herunterzuladen und auszuführen.
ollama serve & ollama run llama3.2-visionWenn du das Llama 3.2 11B Vision Modell erfolgreich heruntergeladen und ausgeführt hast, können wir uns nun mit der ollama Bibliothek wie folgt mit ihm verbinden. Beachte, dass wir hier die abgerufene Seite in der image.jpg gespeichert haben, die wir hier zusammen mit der Frage des Nutzers in das Llama 3.2 11B Vision Modell eingeben.
import ollama
response = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': "What's the BLEU score of the transformer architecture in EN-DE",
'images': ['image.jpg']
}]
)
print(response['message']['content'])The table shows that the BLEU score for the transformer (base model) on the EN-DE task is 27.3. The BLEU score for the transformer (big) on the same task is 28.4.
Therefore, the BLEU score of the transformer architecture in EN-DE is **28.4**.Wir können den ColPali-Abruf und den Ollama-Inferenzcode in der folgenden inference Funktion kombinieren. Diese Funktion ruft die relevanteste Seite aus dem Dokument ab, übergibt sie zusammen mit der Anfrage an das Visionsmodell und gibt eine Antwort zurück.
def inference(question: str):
results = RAG.search(question, k=1) # Retrieve relevant data
see_image(results[0]['base64']) # Save and display image
response = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': question,
'images': ['image.jpg']
}]
)
return response['message']['content']
# Example queries
inference_result = inference("Please explain figure 1")
print(inference_result)The Transformer model is a type of neural network architecture that was introduced in the paper "Attention Is All You Need" by Vaswani et al. in 2017. It has since become one of the most widely used architectures for natural language processing tasks, such as machine translation, text summarization, and question answering.
**What is a Transformer?**
A Transformer is a type of neural network that uses self-attention mechanisms to process input sequences, such as sentences or paragraphs. Unlike traditional recurrent neural networks (RNNs), which rely on sequential processing of inputs, Transformers can process all input elements simultaneously using parallelized attention modules.
**How does the Transformer work?**
The Transformer consists of an encoder and a decoder. The encoder takes in a sequence of tokens (e.g., words or characters) as input and produces a continuous representation of the input sequence. This representation is then fed into the decoder, which generates output sequences one token at a time.
**Key Components:**
* **Self-Attention Mechanism:** This mechanism allows the model to attend to different parts of the input sequence simultaneously and weigh their importance.
* **Multi-Head Attention:** The Transformer uses multiple attention heads to process different aspects of the input sequence in parallel, improving the model's ability to capture complex relationships between tokens.
* **Positional Encoding:** To incorporate positional information into the input sequence, the Transformer uses a positional encoding scheme that adds a learned vector to each token based on its position in the sequence.
**Advantages:**
* **Parallelization:** The Transformer can process all input elements simultaneously, making it much faster than traditional RNNs.
* **Flexibility:** The Transformer can handle sequences of varying lengths and is particularly effective for tasks involving long-range dependencies.
**Applications:**
The Transformer has been widely adopted in various natural language processing applications, including:
* Machine Translation
* Text Summarization
* Question Answering
* Sentiment Analysis
In summary, the Transformer model is a powerful neural network architecture that uses self-attention mechanisms to process input sequences efficiently and effectively. Its ability to parallelize attention modules has made it a popular choice for many natural language processing tasks.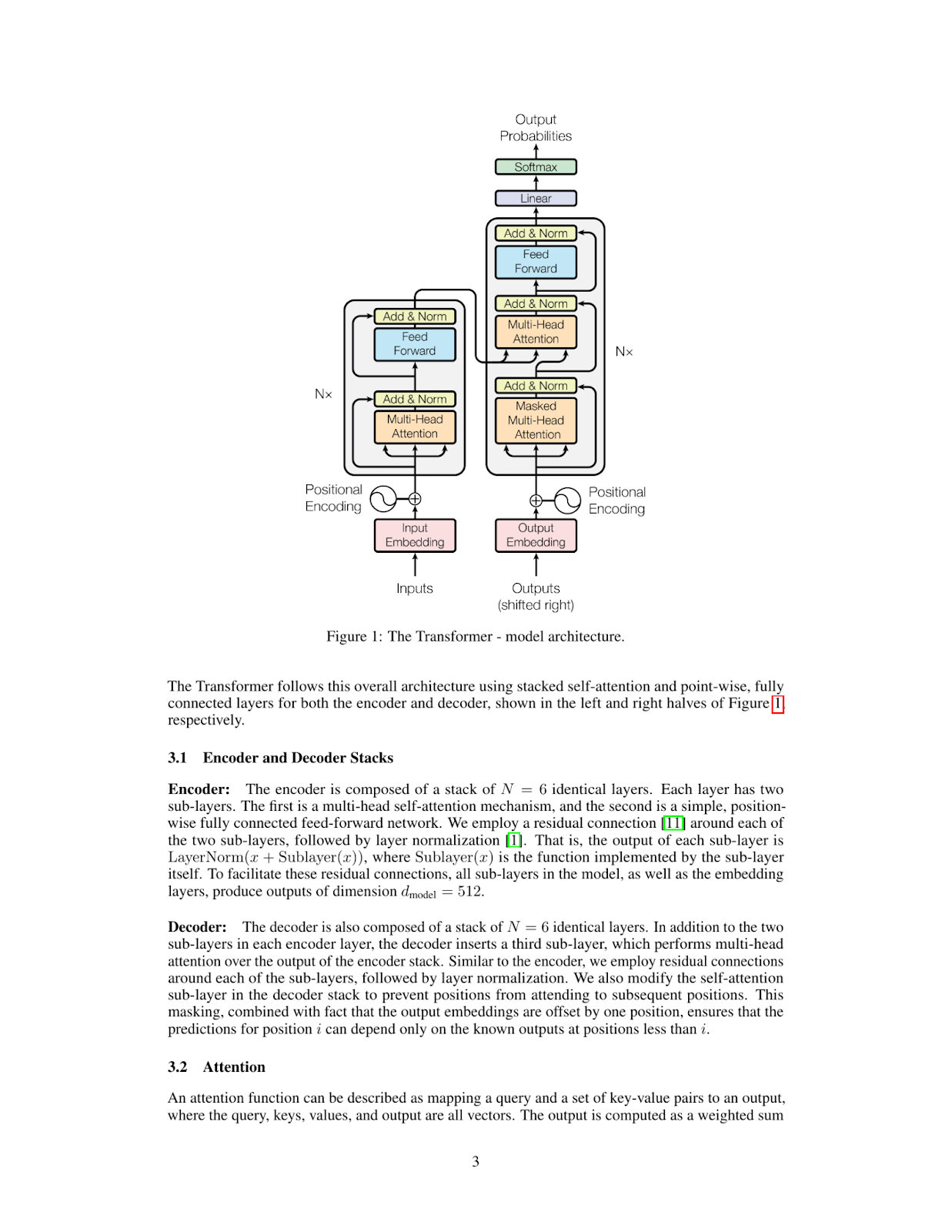
Versuchen wir eine andere Abfrage:
inference_result = inference("What's the maximum path length of recurrent layer type")
print(inference_result)The table provided in the image shows that for a Recurrent Layer, the Maximum Path Length is O(n). This means that as the number of nodes (n) in the network increases, the maximum path length also increases linearly with it.
Therefore, the maximum path length of a recurrent layer type is O(n).
*Answer*: O(n)
Die Fähigkeit von Llama 3.2 Vision, sowohl visuelles als auch textuelles Verständnis zu kombinieren, macht es ideal für eine Vielzahl von Anwendungen in der realen Welt.
Im Gesundheitswesen kann Llama 3.2 Vision die Diagnosegenauigkeit verbessern, indem es medizinische Bilder wie Röntgenaufnahmen und MRTs zusammen mit Patientenakten analysiert. Diese Kombination aus visuellen und textuellen Daten hilft Ärzten, fundiertere Entscheidungen zu treffen und beschleunigt die klinische Forschung, was letztendlich der Patientenversorgung zugute kommt.
Llama 3.2 Vision kann auch das Einkaufserlebnis der Kunden verbessern, indem es Produktbilder, Textbewertungen und Kundenanfragen kombiniert. Dies ermöglicht personalisierte Empfehlungen und ein maßgeschneidertes Einkaufserlebnis, was sowohl das Engagement als auch die Zufriedenheit erhöht.
In der Rechtsbranche hilft Llama 3.2 Vision Fachleuten, Informationen aus Verträgen, Rechtsprechung und gescannten Dokumenten schnell abzurufen und zusammenzufassen. Es kann sogar komplexe visuelle Darstellungen wie Gerichtsdiagramme oder Anmerkungen zu Dokumenten interpretieren und so wertvolle Erkenntnisse für die rechtliche Analyse und Entscheidungsfindung liefern.
Und schließlich kann Llama 3.2 Vision Lernumgebungen unterstützen, indem es visuelle Hilfsmittel wie Diagramme und Tabellen interpretiert und sie mit klaren Texterklärungen in Echtzeit verknüpft. Dadurch werden Bildungsinhalte interaktiver und sowohl Schüler/innen als auch Fachkräfte lernen effektiver.
Mit ColPali und Llama 3.2 Vision Models kannst du ein leistungsstarkes RAG-System aufbauen, das PDFs mit komplexen visuellen und textuellen Daten verstehen und interpretieren kann. Diese Kombination eröffnet Möglichkeiten für Anwendungen, die von der Dokumentenanalyse bis zur automatischen Berichterstellung reichen, und macht sie sehr nützlich für multimodale KI-Workflows.
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Kurs
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
