
Programa
Desenvolvimento de aplicativos de IA
21 h
A família Llama 3.2 apresenta um conjunto avançado de modelos que combinam visão e compreensão de linguagem. Os dois maiores modelos, 11B e 90B, foram projetados especificamente para lidar com tarefas complexas em que as informações visuais e textuais precisam ser compreendidas em conjunto.
Esses modelos são excelentes na leitura e análise de tabelas, gráficos e quadros, o que os torna perfeitos para extrair insights com os quais os modelos tradicionais somente de texto têm dificuldade. Por exemplo, o proprietário de uma empresa poderia perguntar: "Qual mês do ano passado teve o maior lucro?" e o Llama 3.2 examinaria o gráfico de lucratividade e daria a resposta correta.
Além disso, os modelos podem localizar objetos em imagens com base em descrições. Seja para localizar pontos de referência em um mapa ou identificar tendências em um gráfico, o Llama 3.2 pode lidar com isso facilmente.
O Llama 3.2 não só se equipara aos principais concorrentes, como o Claude 3 Haiku e o GPT4o-mini, como também apresenta um desempenho igualmente bom em tarefas como reconhecimento de imagens e compreensão de recursos visuais, conforme demonstrado nos benchmarks ajustados por instruções de visão. Sua capacidade de trabalhar com texto e imagens significa que ele pode lidar com conversas mais naturais e flexíveis que misturam informações visuais e escritas, tornando-o ideal para uma ampla gama de casos de uso.
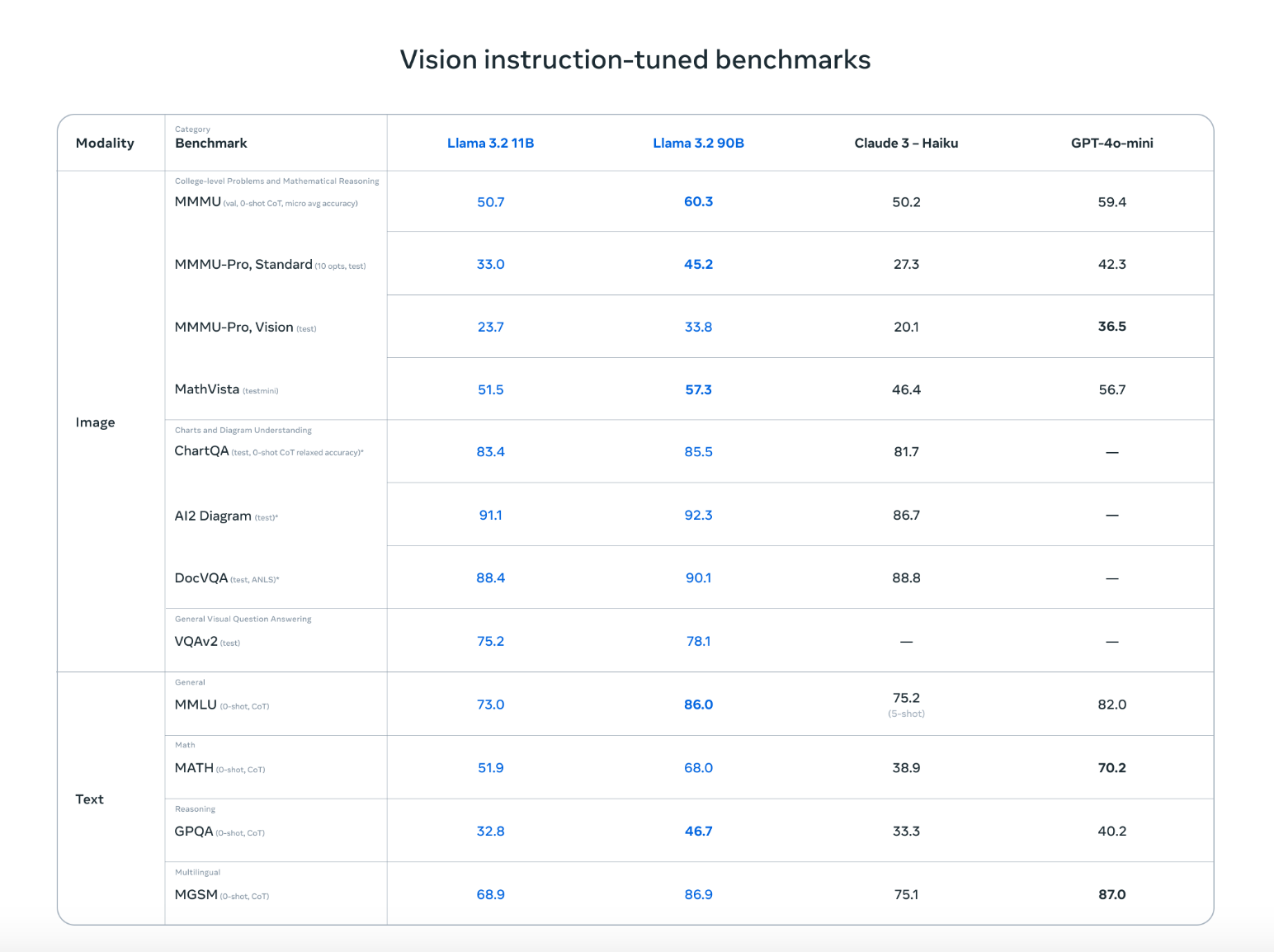
Fonte: Meta AI
Com esses recursos avançados, os modelos Llama 3.2 Vision abrem novas possibilidades para você. RAG para aplicações RAG. Eles facilitam muito a extração de insights de fontes de dados complicadas, como PDFs, combinando recursos visuais e texto para obter resultados mais precisos e úteis.
Para configurar um aplicativo RAG com o Llama 3.2 Vision, precisamos fazer o download do modelo do Llama 3.2 Vision, configurar o ambiente, instalar as bibliotecas necessárias e criar um sistema de recuperação. Abaixo está um guia simples, passo a passo, para ajudar você a implementar um aplicativo RAG usando o Llama 3.2 Vision e o ColPali.
Observe que as etapas a seguir foram testadas em um notebook Colab Pro com uma instância A100.
Primeiro, verifique se você tem as dependências necessárias instaladas:
!pip install byaldi
!sudo apt-get install -y poppler-utils
!pip install -q git+https://github.com/huggingface/transformers.git qwen-vl-utils flash-attn optimum auto-gptq bitsandbytes
!pip install ollama
!pip install colab-xtermA biblioteca byaldi é essencial para indexação e pesquisa em documentos multimodais, enquanto outras ferramentas, como poppler-utils, são necessárias para o manuseio de PDFs.
O ColPali é um método que aprimora a recuperação de documentos ao incorporar diretamente imagens de páginas de documentos, como PDFs digitalizados, em vez de depender apenas do texto extraído. Usando modelos avançados de linguagem de visão, como o PaliGemma, e um mecanismo de recuperação de interação tardia, o ColPali lida de forma eficiente com elementos visuais complexos (tabelas, imagens e gráficos) para uma pesquisa de documentos mais precisa e rápida.
Usaremos o ColPali para codificar nossos PDFs em incorporações. Você pode carregar o ColPali RAGMultiModalModel da seguinte forma:
import os
import base64
from byaldi import RAGMultiModalModel
RAG = RAGMultiModalModel.from_pretrained("vidore/colpali-v1.2", verbose=1)Faremos o download do famoso artigo Attention is All You Need e criaremos um índice para ele usando o site RAGMultiModalModel. Essa etapa processa o documento, extraindo dados visuais e textuais para recuperação rápida.
!wget <https://arxiv.org/pdf/1706.03762>
!mkdir docs
!mv 1706.03762 docs/attention.pdfRAG.index(
input_path="./docs/attention.pdf",
index_name="attention",
store_collection_with_index=True, # Store base64 representation of images
overwrite=True
)Added page 1 of document 0 to index.
Added page 2 of document 0 to index.
Added page 3 of document 0 to index.
Added page 4 of document 0 to index.
Added page 5 of document 0 to index.
Added page 6 of document 0 to index.
Added page 7 of document 0 to index.
Added page 8 of document 0 to index.
Added page 9 of document 0 to index.
Added page 10 of document 0 to index.
Added page 11 of document 0 to index.
Added page 12 of document 0 to index.
Added page 13 of document 0 to index.
Added page 14 of document 0 to index.
Added page 15 of document 0 to index.
Index exported to .byaldi/attention
Index exported to .byaldi/attention
{0: 'docs/attention.pdf'}Depois de indexar o documento, você pode recuperar facilmente o conteúdo relevante do documento da seguinte forma:
query = "What's the BLEU score of the transformer architecture in EN-DE"
results = RAG.search(query, k=1)
results[{'doc_id': 0, 'page_num': 8, 'score': 19.0, 'metadata': {}, 'base64': 'iVBORw0KGgoAAAANSUhEUgAABqQAAAiYCAIAAAA+NVHkAAEAAElEQVR4nOzdd1gUx/8H8KGDoC....'}]Isso recupera a página ou o elemento visual correspondente no topo do PDF indexado.
Para visualizar a página recuperada, podemos salvar a imagem em um arquivo e exibi-la da seguinte forma:
from IPython.display import Image
def see_image(image_base64):
image_bytes = base64.b64decode(image_base64)
filename = 'image.jpg'
with open(filename, 'wb') as f:
f.write(image_bytes)
display(Image(filename))
# For multiple retrieved pages
for res in results:
see_image(res['base64'])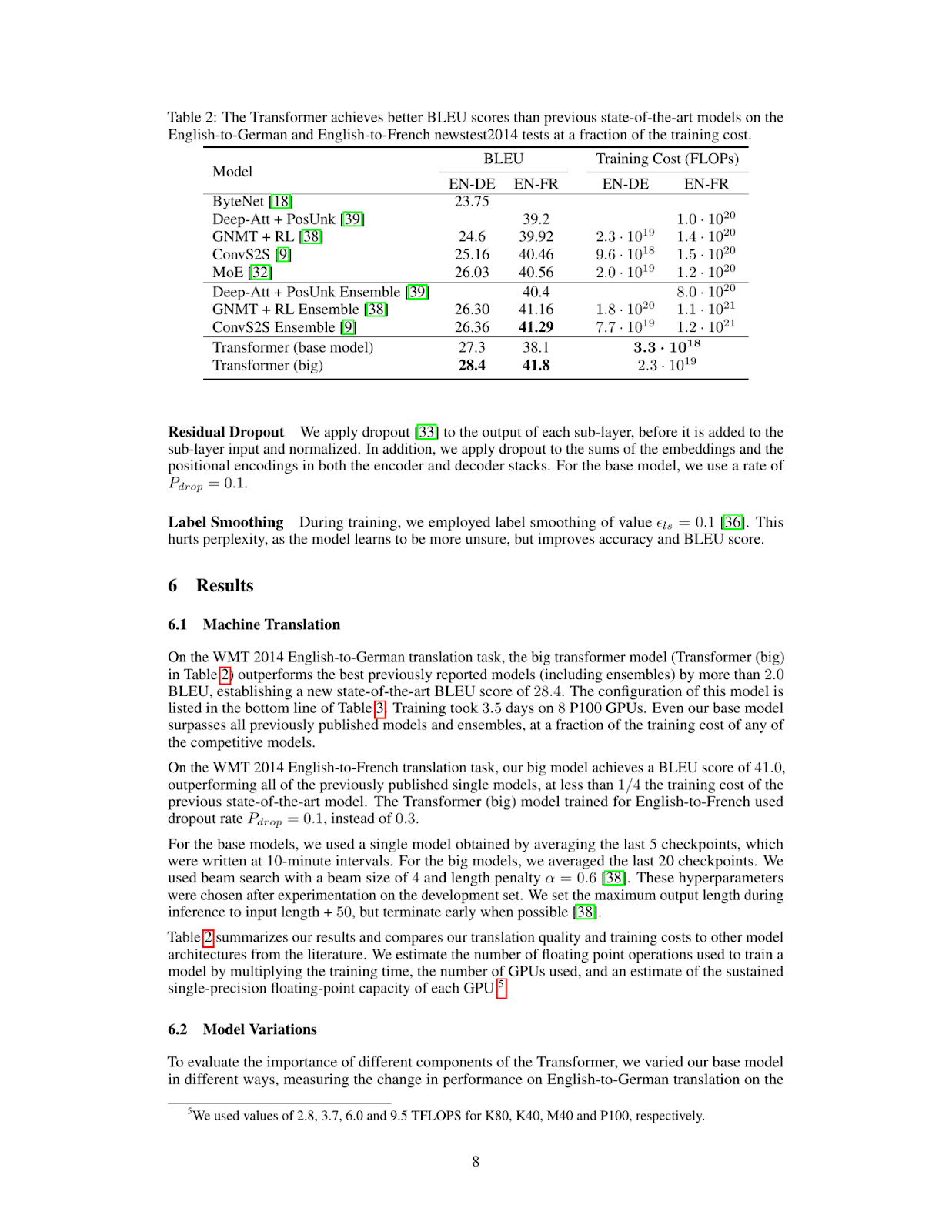
Como você pode ver, a página recuperada contém as informações de que precisamos para responder à pergunta What's the BLEU score of the transformer architecture in EN-DE. A próxima etapa é alimentar essa imagem em nosso modelo Llama 3.2 Vision juntamente com a pergunta do usuário.
Para instalar e configurar o modelo Llama 3.2 Vision, usaremos o Ollama em um notebook Colab Pro com uma instância A100. Você executará o Ollama no notebook e fará o download do modelo Llama 3.2 Vision para uso.
%load_ext colabxterm
%xterm%xterm criará um terminal dentro do notebook, do qual você poderá fazer o download do Ollama usando este comando curl -fsSL | sh e, em seguida, executar o seguinte comando para fazer o download e executar o modelo Llama 3.2 11B Vision.
ollama serve & ollama run llama3.2-visionDepois que você tiver baixado e executado com êxito o modelo Llama 3.2 11B Vision, poderemos nos conectar a ele usando a biblioteca ollama da seguinte forma. Observe que aqui salvamos a página recuperada em image.jpg, da qual estamos inserindo juntamente com a pergunta do usuário no modelo Llama 3.2 11B Vision.
import ollama
response = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': "What's the BLEU score of the transformer architecture in EN-DE",
'images': ['image.jpg']
}]
)
print(response['message']['content'])The table shows that the BLEU score for the transformer (base model) on the EN-DE task is 27.3. The BLEU score for the transformer (big) on the same task is 28.4.
Therefore, the BLEU score of the transformer architecture in EN-DE is **28.4**.Podemos combinar a recuperação ColPali e o código de inferência Ollama na função inference abaixo. Essa função recupera a página mais relevante do documento, passa essa página para o modelo de visão junto com a consulta e retorna uma resposta.
def inference(question: str):
results = RAG.search(question, k=1) # Retrieve relevant data
see_image(results[0]['base64']) # Save and display image
response = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': question,
'images': ['image.jpg']
}]
)
return response['message']['content']
# Example queries
inference_result = inference("Please explain figure 1")
print(inference_result)The Transformer model is a type of neural network architecture that was introduced in the paper "Attention Is All You Need" by Vaswani et al. in 2017. It has since become one of the most widely used architectures for natural language processing tasks, such as machine translation, text summarization, and question answering.
**What is a Transformer?**
A Transformer is a type of neural network that uses self-attention mechanisms to process input sequences, such as sentences or paragraphs. Unlike traditional recurrent neural networks (RNNs), which rely on sequential processing of inputs, Transformers can process all input elements simultaneously using parallelized attention modules.
**How does the Transformer work?**
The Transformer consists of an encoder and a decoder. The encoder takes in a sequence of tokens (e.g., words or characters) as input and produces a continuous representation of the input sequence. This representation is then fed into the decoder, which generates output sequences one token at a time.
**Key Components:**
* **Self-Attention Mechanism:** This mechanism allows the model to attend to different parts of the input sequence simultaneously and weigh their importance.
* **Multi-Head Attention:** The Transformer uses multiple attention heads to process different aspects of the input sequence in parallel, improving the model's ability to capture complex relationships between tokens.
* **Positional Encoding:** To incorporate positional information into the input sequence, the Transformer uses a positional encoding scheme that adds a learned vector to each token based on its position in the sequence.
**Advantages:**
* **Parallelization:** The Transformer can process all input elements simultaneously, making it much faster than traditional RNNs.
* **Flexibility:** The Transformer can handle sequences of varying lengths and is particularly effective for tasks involving long-range dependencies.
**Applications:**
The Transformer has been widely adopted in various natural language processing applications, including:
* Machine Translation
* Text Summarization
* Question Answering
* Sentiment Analysis
In summary, the Transformer model is a powerful neural network architecture that uses self-attention mechanisms to process input sequences efficiently and effectively. Its ability to parallelize attention modules has made it a popular choice for many natural language processing tasks.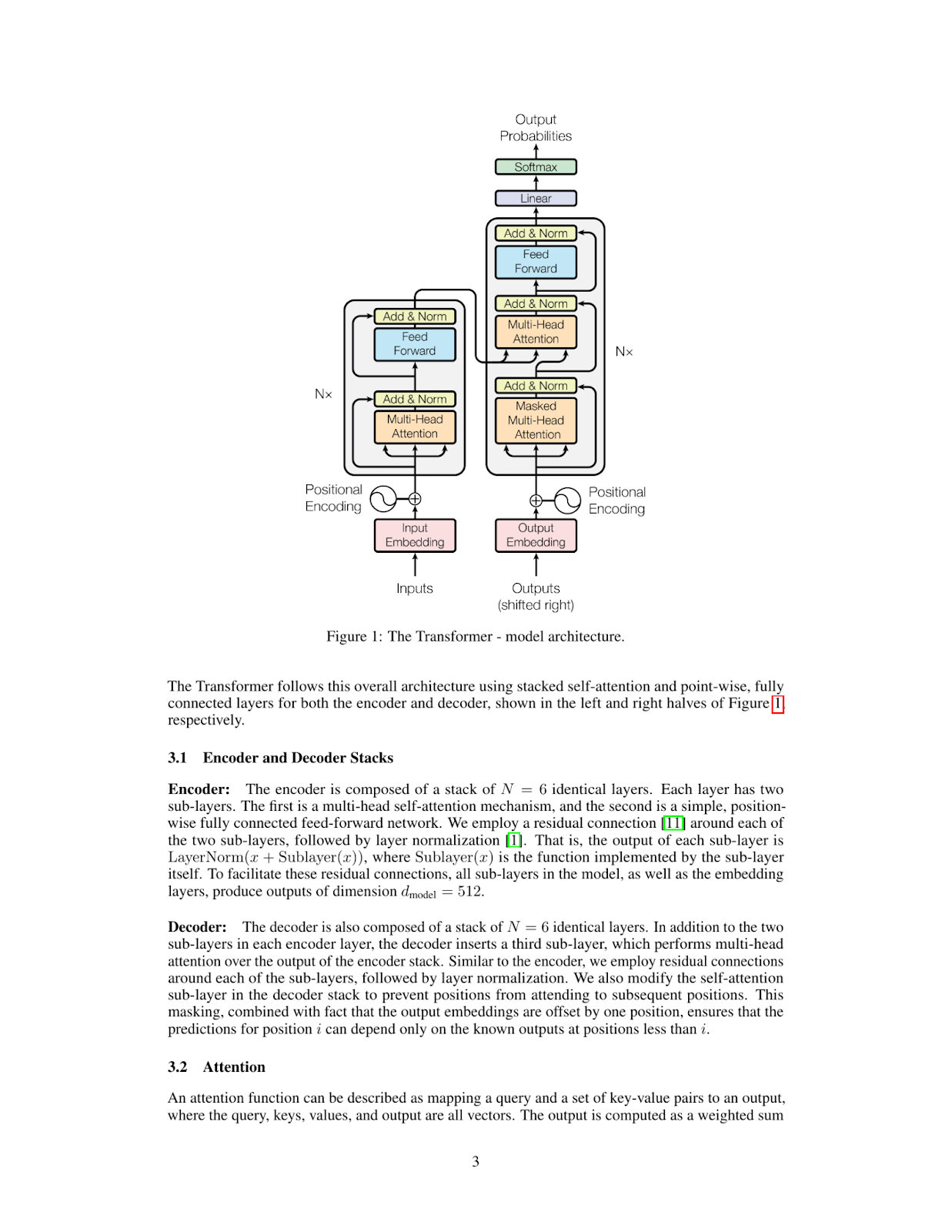
Vamos tentar outra consulta:
inference_result = inference("What's the maximum path length of recurrent layer type")
print(inference_result)The table provided in the image shows that for a Recurrent Layer, the Maximum Path Length is O(n). This means that as the number of nodes (n) in the network increases, the maximum path length also increases linearly with it.
Therefore, the maximum path length of a recurrent layer type is O(n).
*Answer*: O(n)
A capacidade do Llama 3.2 Vision de combinar a compreensão visual e textual o torna ideal para uma variedade de aplicativos do mundo real.
No setor de saúde, o Llama 3.2 Vision pode melhorar a precisão do diagnóstico analisando imagens médicas, como raios X e ressonâncias magnéticas, juntamente com registros de pacientes. Essa combinação de dados visuais e textuais ajuda os médicos a tomar decisões mais informadas e acelera a pesquisa clínica, beneficiando, em última análise, o atendimento ao paciente.
O Llama 3.2 Vision também pode aprimorar a experiência de compra do cliente combinando imagens de produtos, análises de texto e consultas de clientes. Isso permite recomendações mais personalizadas e uma jornada de compras sob medida, melhorando o envolvimento e a satisfação.
No setor jurídico, o Llama 3.2 Vision ajuda os profissionais a recuperar e resumir rapidamente informações de contratos, jurisprudência e documentos digitalizados. Ele pode até mesmo interpretar visuais complexos, como diagramas de tribunais ou anotações de documentos, fornecendo insights valiosos para análise jurídica e tomada de decisões.
Por fim, o Llama 3.2 Vision pode ajudar os ambientes de aprendizagem interpretando recursos visuais, como diagramas e gráficos, e vinculando-os a explicações textuais claras e em tempo real. Isso torna o conteúdo educacional mais interativo, ajudando estudantes e profissionais a aprender com mais eficiência.
Com os modelos de visão ColPali e Llama 3.2, você pode criar um sistema RAG avançado capaz de compreender e raciocinar sobre PDFs que contêm dados visuais e textuais complexos. Essa combinação abre possibilidades para aplicativos que vão desde a análise de documentos até a geração automatizada de relatórios, o que a torna muito útil para fluxos de trabalho de IA multimodal.
Aprenda IA com estes cursos!
Programa
Programa
Curso
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan


