
Track
Developing AI Applications
21 hr
The Llama 3.2 family introduces a powerful set of models that combine vision and language understanding. The two largest models, 11B and 90B, are specifically designed to handle complex tasks where visual and textual information need to be understood together.
These models excel in reading and analyzing charts, graphs, and tables, making them perfect for extracting insights that traditional text-only models struggle with. For example, a business owner could ask, “Which month last year had the highest profit?” and Llama 3.2 would look at the profitability chart and give the correct answer.
Additionally, the models can locate objects in pictures based on descriptions. Whether spotting landmarks on a map or identifying trends in a graph, Llama 3.2 can handle it easily.
Llama 3.2 doesn’t just match top competitors like Claude 3 Haiku and GPT4o-mini, it performs just as well in tasks like recognizing images and understanding visuals as demonstrated across the vision instruction-tuned benchmarks. Its ability to work with both text and images means it can handle more natural, flexible conversations that mix visual and written information, making it ideal for a wide range of use cases.
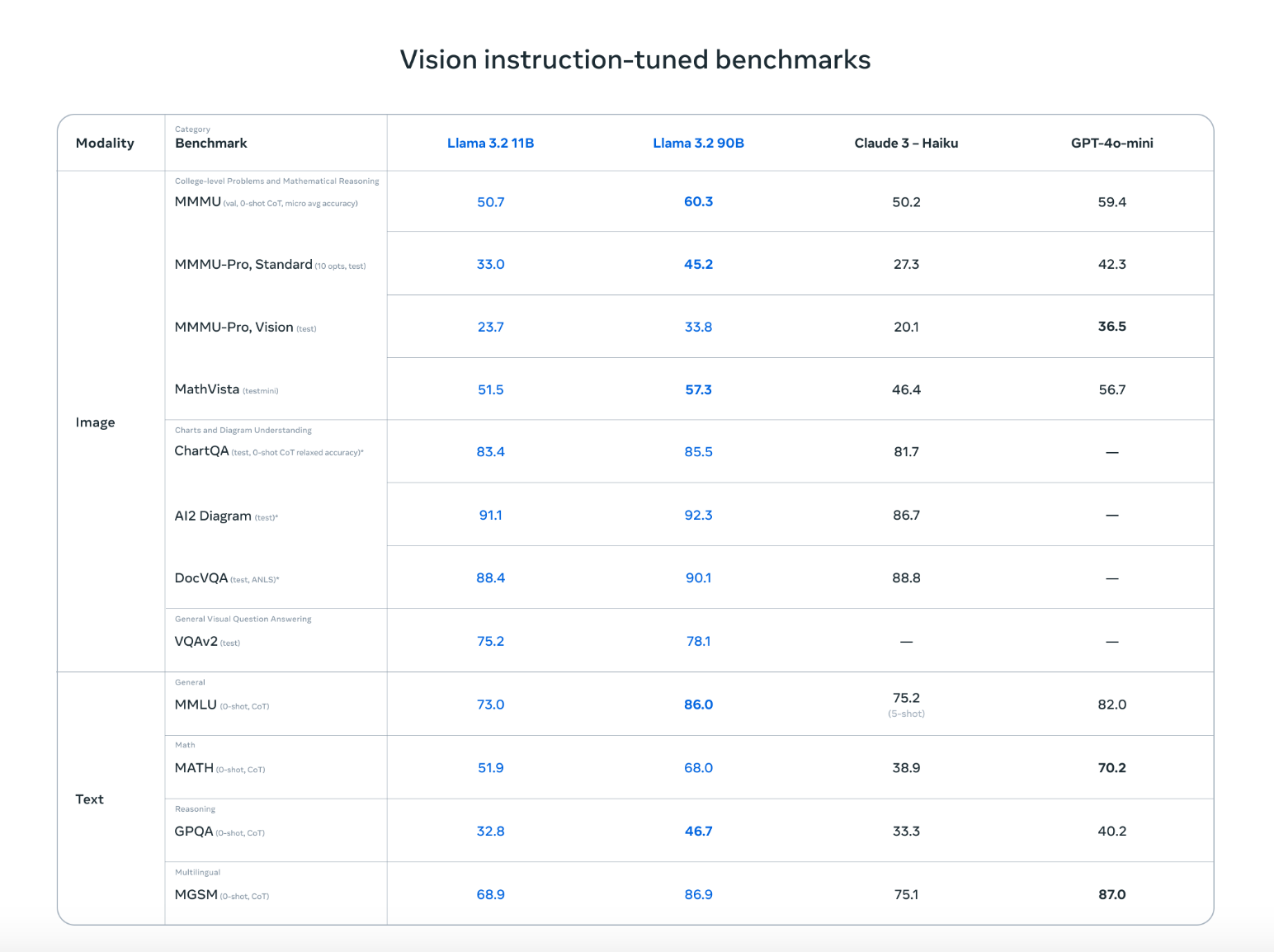
Source: Meta AI
With these advanced features, Llama 3.2 Vision models open up new possibilities for RAG applications. They make it much easier to pull insights from complicated data sources like PDFs, combining visuals and text for more accurate and useful results.
To set up a RAG application with Llama 3.2 Vision, we need to download the Llama 3.2 Vision model, set up the environment, install the required libraries, and create a retrieval system. Below is a simple, step-by-step guide to help you implement a RAG application using Llama 3.2 Vision and ColPali.
Please note that the following steps were tested on a Colab Pro notebook with an A100 instance.
First, make sure you have the required dependencies installed:
!pip install byaldi
!sudo apt-get install -y poppler-utils
!pip install -q git+https://github.com/huggingface/transformers.git qwen-vl-utils flash-attn optimum auto-gptq bitsandbytes
!pip install ollama
!pip install colab-xtermThe byaldi library is essential for indexing and searching within multimodal documents, while other tools like poppler-utils are required for PDF handling.
ColPali is a method that enhances document retrieval by directly embedding images of document pages, such as scanned PDFs, instead of relying solely on extracted text. Using advanced vision language models like PaliGemma and a late interaction retrieval mechanism, ColPali efficiently handles complex visual elements (tables, images, and graphs) for more accurate and faster document search.
We will be using ColPali to encode our PDFs into embeddings. You can load the ColPali RAGMultiModalModel as follows:
import os
import base64
from byaldi import RAGMultiModalModel
RAG = RAGMultiModalModel.from_pretrained("vidore/colpali-v1.2", verbose=1)We will download the famous Attention is All You Need paper and create an index for it using the RAGMultiModalModel. This step processes the document, extracting visual and textual data for quick retrieval.
!wget <https://arxiv.org/pdf/1706.03762>
!mkdir docs
!mv 1706.03762 docs/attention.pdfRAG.index(
input_path="./docs/attention.pdf",
index_name="attention",
store_collection_with_index=True, # Store base64 representation of images
overwrite=True
)Added page 1 of document 0 to index.
Added page 2 of document 0 to index.
Added page 3 of document 0 to index.
Added page 4 of document 0 to index.
Added page 5 of document 0 to index.
Added page 6 of document 0 to index.
Added page 7 of document 0 to index.
Added page 8 of document 0 to index.
Added page 9 of document 0 to index.
Added page 10 of document 0 to index.
Added page 11 of document 0 to index.
Added page 12 of document 0 to index.
Added page 13 of document 0 to index.
Added page 14 of document 0 to index.
Added page 15 of document 0 to index.
Index exported to .byaldi/attention
Index exported to .byaldi/attention
{0: 'docs/attention.pdf'}Once you have indexed the document, you can easily retrieve relevant content from the document as follows:
query = "What's the BLEU score of the transformer architecture in EN-DE"
results = RAG.search(query, k=1)
results[{'doc_id': 0, 'page_num': 8, 'score': 19.0, 'metadata': {}, 'base64': 'iVBORw0KGgoAAAANSUhEUgAABqQAAAiYCAIAAAA+NVHkAAEAAElEQVR4nOzdd1gUx/8H8KGDoC....'}]This retrieves the top matching page or visual element from the indexed PDF.
To visualize the retrieved page, we can save the image to a file and display it as follows:
from IPython.display import Image
def see_image(image_base64):
image_bytes = base64.b64decode(image_base64)
filename = 'image.jpg'
with open(filename, 'wb') as f:
f.write(image_bytes)
display(Image(filename))
# For multiple retrieved pages
for res in results:
see_image(res['base64'])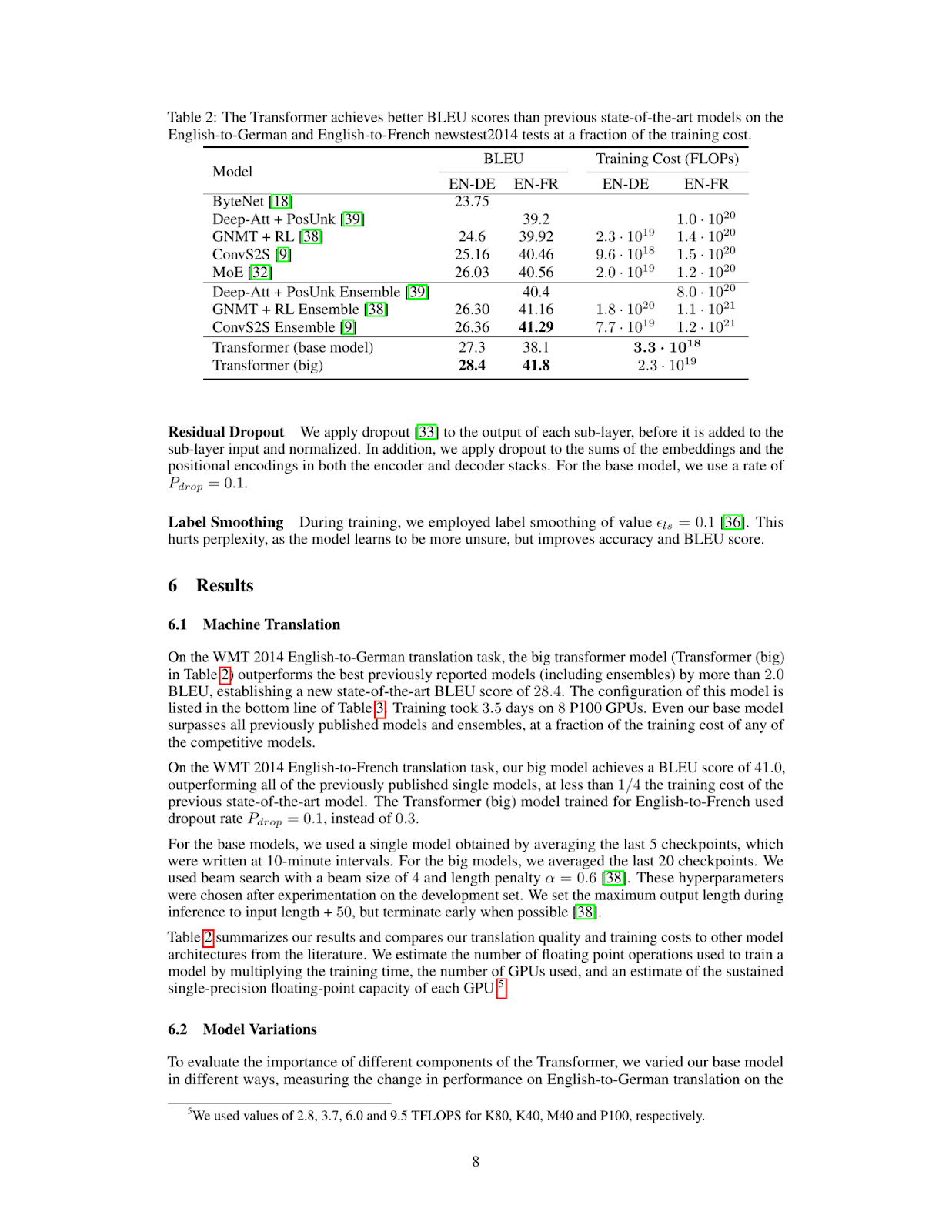
As you can see, the retrieved page contains the information we need to answer the question What's the BLEU score of the transformer architecture in EN-DE. The next step is to feed this image into our Llama 3.2 Vision model along with the user’s question.
To install and set up the Llama 3.2 Vision model, we will use Ollama within a Colab Pro notebook with an A100 instance. You will run Ollama in the notebook and download the Llama 3.2 Vision model for use.
%load_ext colabxterm
%xterm%xterm will create a terminal within the notebook, of which you can then download Ollama using this command curl -fsSL <https://ollama.com/install.sh> | sh and then run the following command to download and run the Llama 3.2 11B Vision model.
ollama serve & ollama run llama3.2-visionOnce you have successfully downloaded and run the Llama 3.2 11B Vision model, we can now connect to it using the ollama library as follows. Note that here we have saved the retrieved page into the image.jpg , of which we are inputting here along with the user’s question into the Llama 3.2 11B Vision model.
import ollama
response = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': "What's the BLEU score of the transformer architecture in EN-DE",
'images': ['image.jpg']
}]
)
print(response['message']['content'])The table shows that the BLEU score for the transformer (base model) on the EN-DE task is 27.3. The BLEU score for the transformer (big) on the same task is 28.4.
Therefore, the BLEU score of the transformer architecture in EN-DE is **28.4**.We can combine the ColPali retrieval and the Ollama inference code together into the inference function below. This function retrieves the most relevant page from the document, passes it to the vision model along with the query, and returns an answer.
def inference(question: str):
results = RAG.search(question, k=1) # Retrieve relevant data
see_image(results[0]['base64']) # Save and display image
response = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': question,
'images': ['image.jpg']
}]
)
return response['message']['content']
# Example queries
inference_result = inference("Please explain figure 1")
print(inference_result)The Transformer model is a type of neural network architecture that was introduced in the paper "Attention Is All You Need" by Vaswani et al. in 2017. It has since become one of the most widely used architectures for natural language processing tasks, such as machine translation, text summarization, and question answering.
**What is a Transformer?**
A Transformer is a type of neural network that uses self-attention mechanisms to process input sequences, such as sentences or paragraphs. Unlike traditional recurrent neural networks (RNNs), which rely on sequential processing of inputs, Transformers can process all input elements simultaneously using parallelized attention modules.
**How does the Transformer work?**
The Transformer consists of an encoder and a decoder. The encoder takes in a sequence of tokens (e.g., words or characters) as input and produces a continuous representation of the input sequence. This representation is then fed into the decoder, which generates output sequences one token at a time.
**Key Components:**
* **Self-Attention Mechanism:** This mechanism allows the model to attend to different parts of the input sequence simultaneously and weigh their importance.
* **Multi-Head Attention:** The Transformer uses multiple attention heads to process different aspects of the input sequence in parallel, improving the model's ability to capture complex relationships between tokens.
* **Positional Encoding:** To incorporate positional information into the input sequence, the Transformer uses a positional encoding scheme that adds a learned vector to each token based on its position in the sequence.
**Advantages:**
* **Parallelization:** The Transformer can process all input elements simultaneously, making it much faster than traditional RNNs.
* **Flexibility:** The Transformer can handle sequences of varying lengths and is particularly effective for tasks involving long-range dependencies.
**Applications:**
The Transformer has been widely adopted in various natural language processing applications, including:
* Machine Translation
* Text Summarization
* Question Answering
* Sentiment Analysis
In summary, the Transformer model is a powerful neural network architecture that uses self-attention mechanisms to process input sequences efficiently and effectively. Its ability to parallelize attention modules has made it a popular choice for many natural language processing tasks.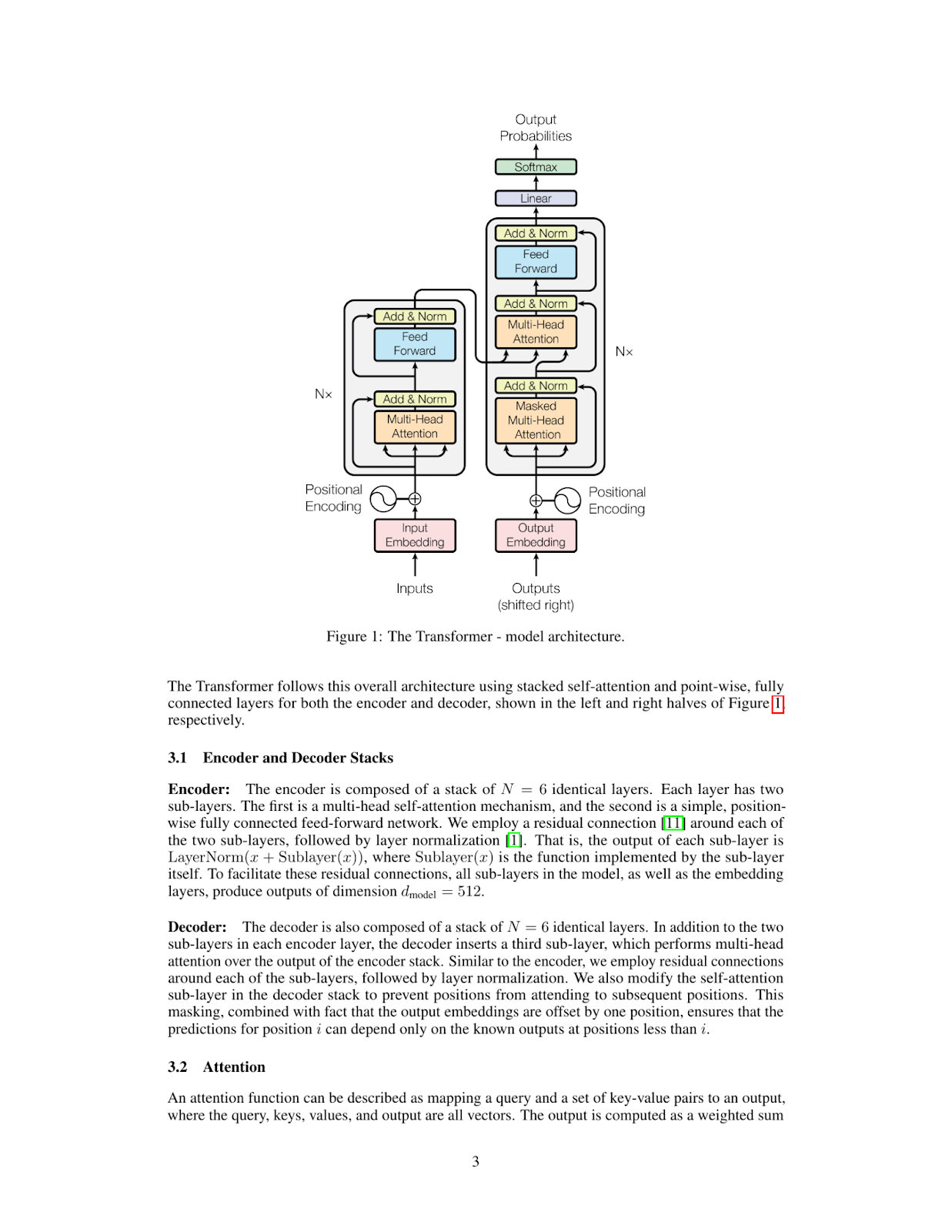
Let’s try another query:
inference_result = inference("What's the maximum path length of recurrent layer type")
print(inference_result)The table provided in the image shows that for a Recurrent Layer, the Maximum Path Length is O(n). This means that as the number of nodes (n) in the network increases, the maximum path length also increases linearly with it.
Therefore, the maximum path length of a recurrent layer type is O(n).
*Answer*: O(n)
Llama 3.2 Vision's ability to combine both visual and textual understanding makes it ideal for a variety of real-world applications.
In healthcare, Llama 3.2 Vision can improve diagnostic accuracy by analyzing medical images, like X-rays and MRIs, alongside patient records. This combination of visual and textual data supports doctors in making more informed decisions and speeds up clinical research, ultimately benefiting patient care.
Llama 3.2 Vision can also enhance the customer shopping experience by combining product images, text reviews, and customer queries. This allows for more personalized recommendations and a tailored shopping journey, improving both engagement and satisfaction.
In the legal industry, Llama 3.2 Vision helps professionals quickly retrieve and summarize information from contracts, case law, and scanned documents. It can even interpret complex visuals such as court diagrams or document annotations, providing valuable insights for legal analysis and decision-making.
Lastly, Llama 3.2 Vision can help learning environments by interpreting visual aids like diagrams and charts and linking them with clear, real-time textual explanations. This makes educational content more interactive, helping both students and professionals learn more effectively.
With ColPali and Llama 3.2 Vision Models, you can build a powerful RAG system capable of understanding and reasoning over PDFs containing complex visual and textual data. This combination unlocks possibilities for applications ranging from document analysis to automated report generation, making it very useful for multimodal AI workflows.
Learn AI with these courses!
Track
Track
Course
blog
Alex Olteanu
8 min
Tutorial
Ryan Ong
Tutorial
Aashi Dutt
Tutorial
Aashi Dutt
Tutorial
Ryan Ong
Tutorial
Dr Ana Rojo-Echeburúa
