
programa
Desarrollo de aplicaciones de IA
21 h
La familia Llama 3.2 introduce un potente conjunto de modelos que combinan la visión y la comprensión del lenguaje. Los dos modelos más grandes, el 11B y el 90B, están diseñados específicamente para realizar tareas complejas en las que es necesario comprender conjuntamente la información visual y textual.
Estos modelos destacan en la lectura y el análisis de tablas, gráficos y cuadros, por lo que son perfectos para extraer información que a los modelos tradicionales de sólo texto les resulta difícil. Por ejemplo, un empresario podría preguntar, "¿Qué mes del año pasado tuvo el mayor beneficio?" y Llama 3.2 miraría el gráfico de rentabilidad y daría la respuesta correcta.
Además, los modelos pueden localizar objetos en imágenes basándose en descripciones. Tanto si se trata de localizar puntos de referencia en un mapa como de identificar tendencias en un gráfico, Llama 3.2 puede hacerlo fácilmente.
Llama 3.2 no sólo está a la altura de los mejores competidores, como Claude 3 Haiku y GPT4o-mini, sino que rinde igual de bien en tareas como el reconocimiento de imágenes y la comprensión de elementos visuales, como demuestran las pruebas comparativas ajustadas a las instrucciones de visión. Su capacidad para trabajar tanto con texto como con imágenes significa que puede manejar conversaciones más naturales y flexibles que mezclan información visual y escrita, lo que la hace ideal para una amplia gama de casos de uso.
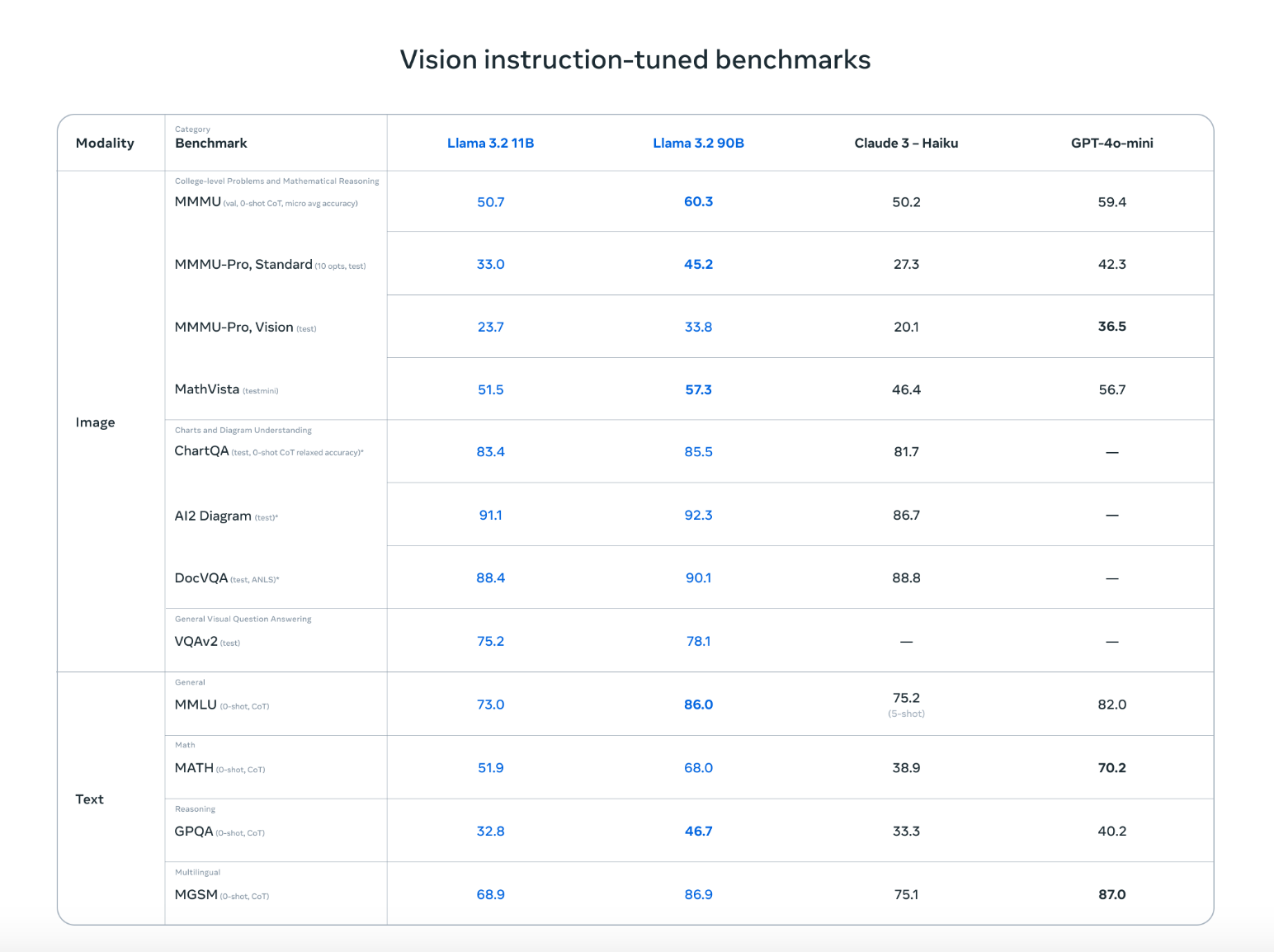
Fuente: Meta AI
Con estas funciones avanzadas, los modelos Llama 3.2 Vision abren nuevas posibilidades para RAG aplicaciones. Facilitan mucho la extracción de información de fuentes de datos complicadas, como los PDF, combinando imágenes y texto para obtener resultados más precisos y útiles.
Para configurar una aplicación RAG con Llama 3.2 Vision, tenemos que descargar el modelo Llama 3.2 Vision, configurar el entorno, instalar las bibliotecas necesarias y crear un sistema de recuperación. A continuación encontrarás una guía sencilla, paso a paso, que te ayudará a poner en marcha una aplicación RAG utilizando Llama 3.2 Vision y ColPali.
Ten en cuenta que los siguientes pasos se probaron en un portátil Colab Pro con una instancia A100.
En primer lugar, asegúrate de que tienes instaladas las dependencias necesarias:
!pip install byaldi
!sudo apt-get install -y poppler-utils
!pip install -q git+https://github.com/huggingface/transformers.git qwen-vl-utils flash-attn optimum auto-gptq bitsandbytes
!pip install ollama
!pip install colab-xtermLa biblioteca byaldi es esencial para indexar y buscar en documentos multimodales, mientras que otras herramientas como poppler-utils son necesarias para el manejo de PDF.
ColPali es un método que mejora la recuperación de documentos incrustando directamente imágenes de páginas de documentos, como PDF escaneados, en lugar de basarse únicamente en el texto extraído. Utilizando modelos avanzados de lenguaje visual como PaliGemma y un mecanismo de recuperación de interacción tardía, ColPali maneja eficazmente elementos visuales complejos (tablas, imágenes y gráficos) para una búsqueda de documentos más precisa y rápida.
Utilizaremos ColPali para codificar nuestros PDF en incrustaciones. Puedes cargar el ColPali RAGMultiModalModel del siguiente modo:
import os
import base64
from byaldi import RAGMultiModalModel
RAG = RAGMultiModalModel.from_pretrained("vidore/colpali-v1.2", verbose=1)Descargaremos el famoso documento La atención es todo lo que necesitas y crearemos un índice para él utilizando la página RAGMultiModalModel. Este paso procesa el documento, extrayendo datos visuales y textuales para una rápida recuperación.
!wget <https://arxiv.org/pdf/1706.03762>
!mkdir docs
!mv 1706.03762 docs/attention.pdfRAG.index(
input_path="./docs/attention.pdf",
index_name="attention",
store_collection_with_index=True, # Store base64 representation of images
overwrite=True
)Added page 1 of document 0 to index.
Added page 2 of document 0 to index.
Added page 3 of document 0 to index.
Added page 4 of document 0 to index.
Added page 5 of document 0 to index.
Added page 6 of document 0 to index.
Added page 7 of document 0 to index.
Added page 8 of document 0 to index.
Added page 9 of document 0 to index.
Added page 10 of document 0 to index.
Added page 11 of document 0 to index.
Added page 12 of document 0 to index.
Added page 13 of document 0 to index.
Added page 14 of document 0 to index.
Added page 15 of document 0 to index.
Index exported to .byaldi/attention
Index exported to .byaldi/attention
{0: 'docs/attention.pdf'}Una vez que hayas indexado el documento, puedes recuperar fácilmente el contenido relevante del documento de la siguiente manera:
query = "What's the BLEU score of the transformer architecture in EN-DE"
results = RAG.search(query, k=1)
results[{'doc_id': 0, 'page_num': 8, 'score': 19.0, 'metadata': {}, 'base64': 'iVBORw0KGgoAAAANSUhEUgAABqQAAAiYCAIAAAA+NVHkAAEAAElEQVR4nOzdd1gUx/8H8KGDoC....'}]Recupera la página o el elemento visual superior coincidente del PDF indexado.
Para visualizar la página recuperada, podemos guardar la imagen en un archivo y mostrarla de la siguiente forma:
from IPython.display import Image
def see_image(image_base64):
image_bytes = base64.b64decode(image_base64)
filename = 'image.jpg'
with open(filename, 'wb') as f:
f.write(image_bytes)
display(Image(filename))
# For multiple retrieved pages
for res in results:
see_image(res['base64'])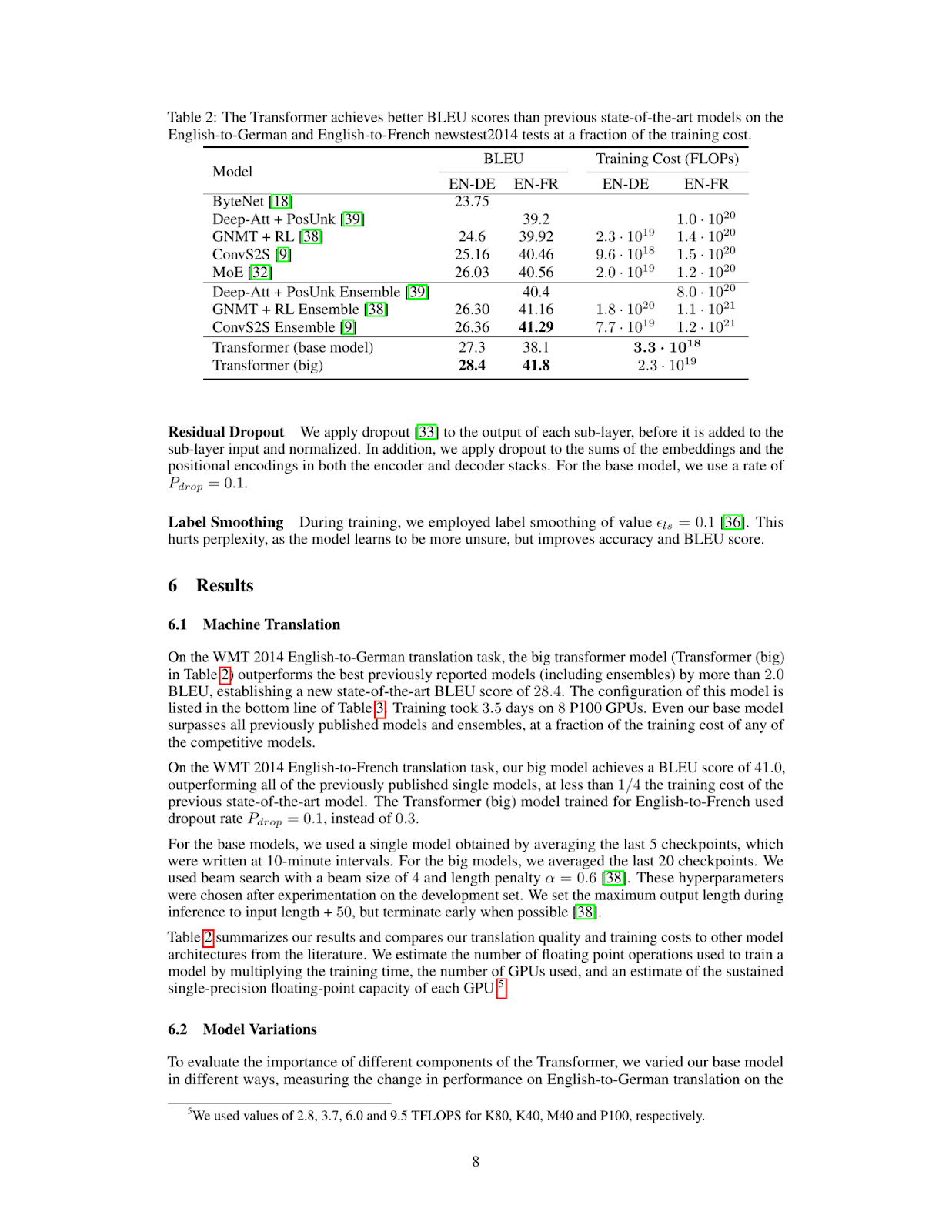
Como puedes ver, la página recuperada contiene la información que necesitamos para responder a la pregunta What's the BLEU score of the transformer architecture in EN-DE. El siguiente paso es introducir esta imagen en nuestro modelo de Visión Llama 3.2 junto con la pregunta del usuario.
Para instalar y configurar el modelo Llama 3.2 Vision, utilizaremos Ollama dentro de un portátil Colab Pro con una instancia A100. Ejecutarás Ollama en el portátil y descargarás el modelo Llama 3.2 Vision para utilizarlo.
%load_ext colabxterm
%xterm%xterm creará un terminal dentro del bloc de notas, del que podrás descargar Ollama utilizando este comando curl -fsSL | sh y, a continuación, ejecutar el siguiente comando para descargar y ejecutar el modelo Llama 3.2 11B Vision.
ollama serve & ollama run llama3.2-visionUna vez que hayas descargado y ejecutado correctamente el modelo Llama 3.2 11B Vision, ya podemos conectarnos a él utilizando la biblioteca ollama del siguiente modo. Observa que aquí hemos guardado la página recuperada en la dirección image.jpg, de la que estamos introduciendo aquí junto con la pregunta del usuario en el modelo Llama 3.2 11B Visión.
import ollama
response = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': "What's the BLEU score of the transformer architecture in EN-DE",
'images': ['image.jpg']
}]
)
print(response['message']['content'])The table shows that the BLEU score for the transformer (base model) on the EN-DE task is 27.3. The BLEU score for the transformer (big) on the same task is 28.4.
Therefore, the BLEU score of the transformer architecture in EN-DE is **28.4**.Podemos combinar la recuperación ColPali y el código de inferencia Ollama en la función inference que aparece a continuación. Esta función recupera la página más relevante del documento, la pasa al modelo de visión junto con la consulta, y devuelve una respuesta.
def inference(question: str):
results = RAG.search(question, k=1) # Retrieve relevant data
see_image(results[0]['base64']) # Save and display image
response = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': question,
'images': ['image.jpg']
}]
)
return response['message']['content']
# Example queries
inference_result = inference("Please explain figure 1")
print(inference_result)The Transformer model is a type of neural network architecture that was introduced in the paper "Attention Is All You Need" by Vaswani et al. in 2017. It has since become one of the most widely used architectures for natural language processing tasks, such as machine translation, text summarization, and question answering.
**What is a Transformer?**
A Transformer is a type of neural network that uses self-attention mechanisms to process input sequences, such as sentences or paragraphs. Unlike traditional recurrent neural networks (RNNs), which rely on sequential processing of inputs, Transformers can process all input elements simultaneously using parallelized attention modules.
**How does the Transformer work?**
The Transformer consists of an encoder and a decoder. The encoder takes in a sequence of tokens (e.g., words or characters) as input and produces a continuous representation of the input sequence. This representation is then fed into the decoder, which generates output sequences one token at a time.
**Key Components:**
* **Self-Attention Mechanism:** This mechanism allows the model to attend to different parts of the input sequence simultaneously and weigh their importance.
* **Multi-Head Attention:** The Transformer uses multiple attention heads to process different aspects of the input sequence in parallel, improving the model's ability to capture complex relationships between tokens.
* **Positional Encoding:** To incorporate positional information into the input sequence, the Transformer uses a positional encoding scheme that adds a learned vector to each token based on its position in the sequence.
**Advantages:**
* **Parallelization:** The Transformer can process all input elements simultaneously, making it much faster than traditional RNNs.
* **Flexibility:** The Transformer can handle sequences of varying lengths and is particularly effective for tasks involving long-range dependencies.
**Applications:**
The Transformer has been widely adopted in various natural language processing applications, including:
* Machine Translation
* Text Summarization
* Question Answering
* Sentiment Analysis
In summary, the Transformer model is a powerful neural network architecture that uses self-attention mechanisms to process input sequences efficiently and effectively. Its ability to parallelize attention modules has made it a popular choice for many natural language processing tasks.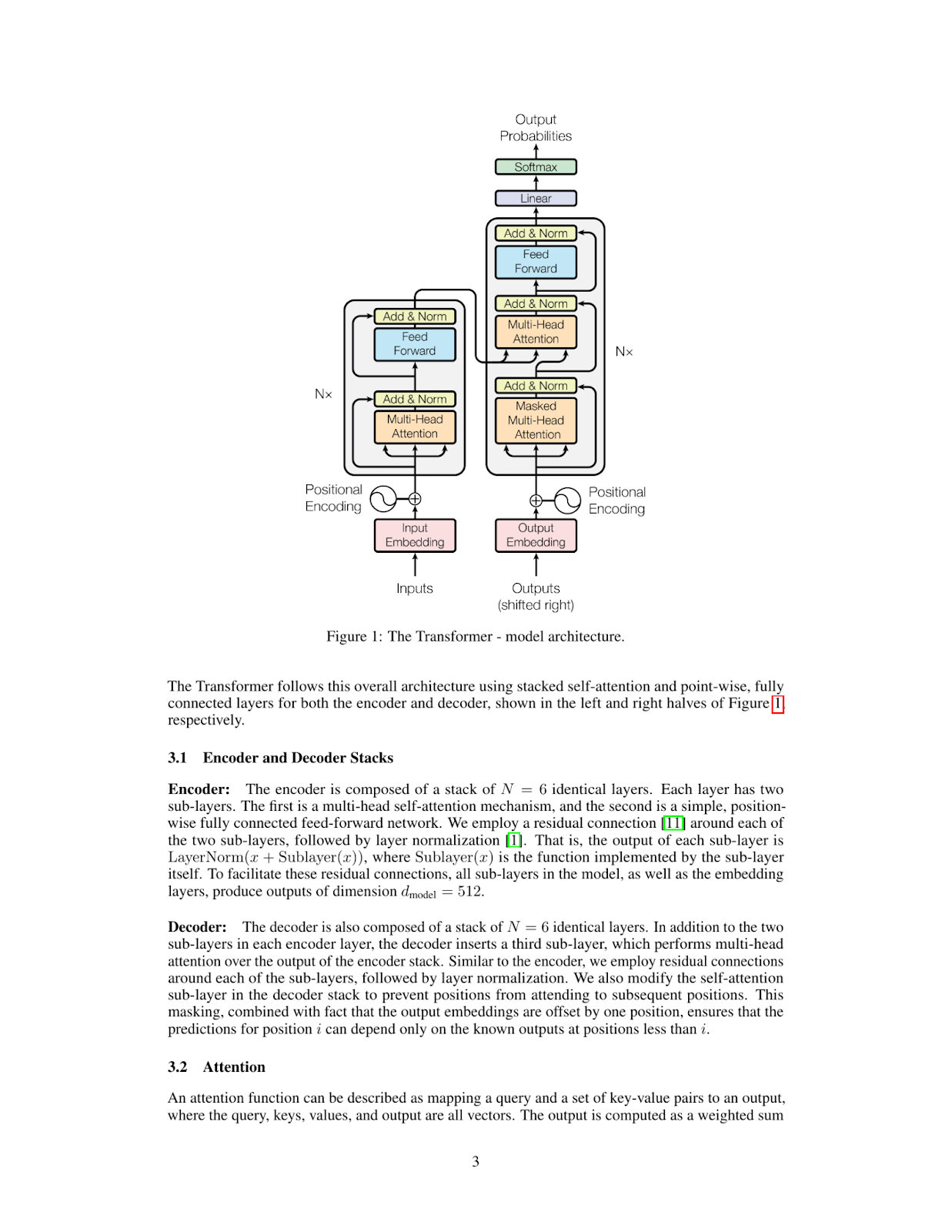
Probemos con otra consulta:
inference_result = inference("What's the maximum path length of recurrent layer type")
print(inference_result)The table provided in the image shows that for a Recurrent Layer, the Maximum Path Length is O(n). This means that as the number of nodes (n) in the network increases, the maximum path length also increases linearly with it.
Therefore, the maximum path length of a recurrent layer type is O(n).
*Answer*: O(n)
La capacidad de Llama 3.2 Visión para combinar la comprensión visual y textual la hace ideal para diversas aplicaciones del mundo real.
En sanidad, Llama 3.2 Vision puede mejorar la precisión diagnóstica analizando imágenes médicas, como radiografías y resonancias magnéticas, junto con los historiales de los pacientes. Esta combinación de datos visuales y textuales ayuda a los médicos a tomar decisiones más informadas y acelera la investigación clínica, beneficiando en última instancia a la atención al paciente.
Llama 3.2 Visión también puede mejorar la experiencia de compra del cliente combinando imágenes de productos, reseñas de texto y consultas de clientes. Esto permite recomendaciones más personalizadas y un recorrido de compra a medida, mejorando tanto el compromiso como la satisfacción.
En el sector jurídico, Llama 3.2 Vision ayuda a los profesionales a recuperar y resumir rápidamente información de contratos, jurisprudencia y documentos escaneados. Incluso puede interpretar elementos visuales complejos, como diagramas judiciales o anotaciones en documentos, proporcionando información valiosa para el análisis jurídico y la toma de decisiones.
Por último, Llama 3.2 Visión puede ayudar a los entornos de aprendizaje interpretando ayudas visuales como diagramas y gráficos y enlazándolas con explicaciones textuales claras y en tiempo real. Esto hace que el contenido educativo sea más interactivo, ayudando tanto a estudiantes como a profesionales a aprender de forma más eficaz.
Con ColPali y los Modelos de Visión de Llama 3.2, puedes construir un potente sistema RAG capaz de comprender y razonar sobre PDF que contengan datos visuales y textuales complejos. Esta combinación abre posibilidades para aplicaciones que van desde el análisis de documentos a la generación automatizada de informes, por lo que resulta muy útil para los flujos de trabajo de IA multimodal.
Aprende IA con estos cursos
programa
programa
Curso
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer


