
Cursus
Développer des applications d'IA
21 h
La famille Llama 3.2 présente un ensemble puissant de modèles qui combinent la vision et la compréhension du langage. Les deux plus grands modèles, 11B et 90B, sont spécialement conçus pour traiter des tâches complexes où les informations visuelles et textuelles doivent être comprises ensemble.
Ces modèles excellent dans la lecture et l'analyse de diagrammes, de graphiques et de tableaux, ce qui les rend parfaits pour extraire des informations que les modèles traditionnels basés sur le texte ne parviennent pas à obtenir. Par exemple, un chef d'entreprise peut demander à "Quel mois de l'année dernière a été le plus rentable ?" et le lama 3.2 consultera le tableau de rentabilité et donnera la bonne réponse.
En outre, les modèles peuvent localiser des objets dans des images sur la base de descriptions. Qu'il s'agisse de repérer des points de repère sur une carte ou d'identifier des tendances dans un graphique, Llama 3.2 peut le faire facilement.
Llama 3.2 ne se contente pas d'égaler des concurrents de premier plan comme Claude 3 Haiku et GPT4o-mini, il est tout aussi performant dans des tâches telles que la reconnaissance d'images et la compréhension d'éléments visuels, comme le démontrent les tests de référence basés sur les instructions de vision. Sa capacité à travailler avec du texte et des images lui permet de gérer des conversations plus naturelles et plus souples qui mélangent des informations visuelles et écrites, ce qui le rend idéal pour un large éventail de cas d'utilisation.
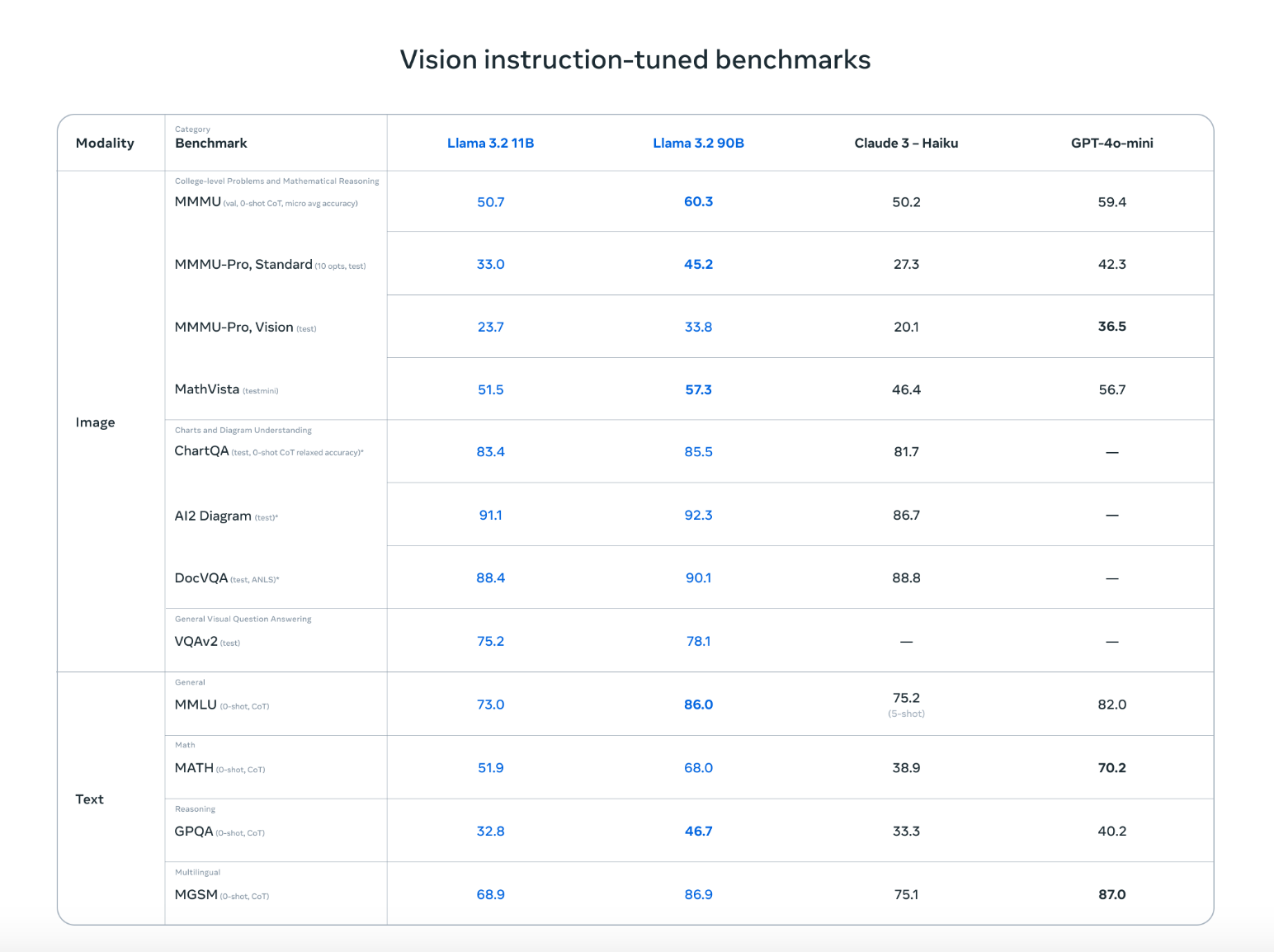
Source : Meta AI
Grâce à ces caractéristiques avancées, les modèles Llama 3.2 Vision ouvrent de nouvelles possibilités pour les éleveurs. RAG et les applications RAG. Ils facilitent grandement l'extraction d'informations à partir de sources de données complexes telles que les PDF, en combinant les images et le texte pour obtenir des résultats plus précis et plus utiles.
Pour mettre en place une application RAG avec Llama 3.2 Vision, nous devons télécharger le modèle Llama 3.2 Vision, configurer l'environnement, installer les bibliothèques nécessaires et créer un système de recherche. Vous trouverez ci-dessous un guide simple, étape par étape, pour vous aider à mettre en œuvre une application RAG en utilisant Llama 3.2 Vision et ColPali.
Veuillez noter que les étapes suivantes ont été testées sur un ordinateur portable Colab Pro avec une instance A100.
Tout d'abord, assurez-vous que les dépendances nécessaires sont installées :
!pip install byaldi
!sudo apt-get install -y poppler-utils
!pip install -q git+https://github.com/huggingface/transformers.git qwen-vl-utils flash-attn optimum auto-gptq bitsandbytes
!pip install ollama
!pip install colab-xtermLa bibliothèque byaldi est essentielle pour l'indexation et la recherche dans les documents multimodaux, tandis que d'autres outils comme poppler-utils sont nécessaires pour la gestion des PDF.
ColPali est une méthode qui améliore la recherche de documents en intégrant directement des images de pages de documents, tels que des PDF scannés, au lieu de s'appuyer uniquement sur le texte extrait. En utilisant des modèles de langage de vision avancés comme PaliGemma et un mécanisme de recherche par interaction tardive, ColPali traite efficacement les éléments visuels complexes (tableaux, images et graphiques) pour une recherche de documents plus précise et plus rapide.
Nous utiliserons ColPali pour encoder nos PDF en embeddings. Vous pouvez charger le ColPali RAGMultiModalModel comme suit :
import os
import base64
from byaldi import RAGMultiModalModel
RAG = RAGMultiModalModel.from_pretrained("vidore/colpali-v1.2", verbose=1)Nous allons télécharger le célèbre document " L'attention est tout ce dont vous avez besoin" et créer un index à l'aide de la page RAGMultiModalModel. Cette étape consiste à traiter le document, à en extraire les données visuelles et textuelles afin de les retrouver rapidement.
!wget <https://arxiv.org/pdf/1706.03762>
!mkdir docs
!mv 1706.03762 docs/attention.pdfRAG.index(
input_path="./docs/attention.pdf",
index_name="attention",
store_collection_with_index=True, # Store base64 representation of images
overwrite=True
)Added page 1 of document 0 to index.
Added page 2 of document 0 to index.
Added page 3 of document 0 to index.
Added page 4 of document 0 to index.
Added page 5 of document 0 to index.
Added page 6 of document 0 to index.
Added page 7 of document 0 to index.
Added page 8 of document 0 to index.
Added page 9 of document 0 to index.
Added page 10 of document 0 to index.
Added page 11 of document 0 to index.
Added page 12 of document 0 to index.
Added page 13 of document 0 to index.
Added page 14 of document 0 to index.
Added page 15 of document 0 to index.
Index exported to .byaldi/attention
Index exported to .byaldi/attention
{0: 'docs/attention.pdf'}Une fois le document indexé, vous pouvez facilement en extraire le contenu pertinent de la manière suivante :
query = "What's the BLEU score of the transformer architecture in EN-DE"
results = RAG.search(query, k=1)
results[{'doc_id': 0, 'page_num': 8, 'score': 19.0, 'metadata': {}, 'base64': 'iVBORw0KGgoAAAANSUhEUgAABqQAAAiYCAIAAAA+NVHkAAEAAElEQVR4nOzdd1gUx/8H8KGDoC....'}]Cette fonction permet de récupérer la page ou l'élément visuel le plus proche dans le PDF indexé.
Pour visualiser la page récupérée, nous pouvons enregistrer l'image dans un fichier et l'afficher comme suit :
from IPython.display import Image
def see_image(image_base64):
image_bytes = base64.b64decode(image_base64)
filename = 'image.jpg'
with open(filename, 'wb') as f:
f.write(image_bytes)
display(Image(filename))
# For multiple retrieved pages
for res in results:
see_image(res['base64'])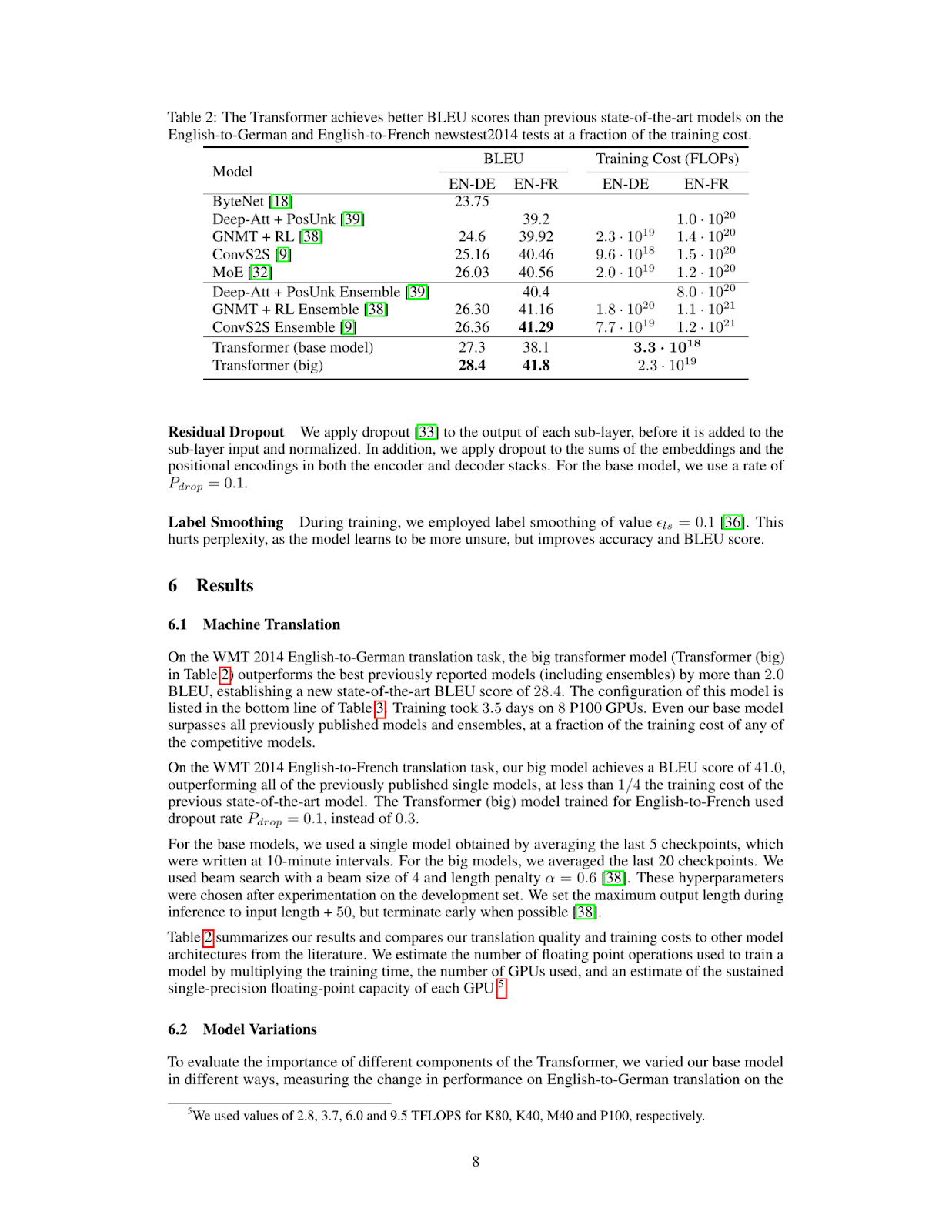
Comme vous pouvez le constater, la page récupérée contient les informations dont nous avons besoin pour répondre à la question What's the BLEU score of the transformer architecture in EN-DE. L'étape suivante consiste à introduire cette image dans notre modèle de vision Llama 3.2 avec la question de l'utilisateur.
Pour installer et configurer le modèle Llama 3.2 Vision, nous utiliserons Ollama dans un ordinateur portable Colab Pro avec une instance A100. Vous exécuterez Ollama dans l'ordinateur portable et téléchargerez le modèle Llama 3.2 Vision pour l'utiliser.
%load_ext colabxterm
%xterm%xterm créera un terminal dans l'ordinateur portable, à partir duquel vous pourrez télécharger Ollama à l'aide de cette commande curl -fsSL | sh et exécuter la commande suivante pour télécharger et exécuter le modèle Llama 3.2 11B Vision.
ollama serve & ollama run llama3.2-visionUne fois que vous avez téléchargé et exécuté avec succès le modèle Llama 3.2 11B Vision, nous pouvons maintenant nous y connecter en utilisant la bibliothèque ollama comme suit. Notez que nous avons sauvegardé la page récupérée dans le site image.jpg, que nous introduisons ici, avec la question de l'utilisateur, dans le modèle Llama 3.2 11B Vision.
import ollama
response = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': "What's the BLEU score of the transformer architecture in EN-DE",
'images': ['image.jpg']
}]
)
print(response['message']['content'])The table shows that the BLEU score for the transformer (base model) on the EN-DE task is 27.3. The BLEU score for the transformer (big) on the same task is 28.4.
Therefore, the BLEU score of the transformer architecture in EN-DE is **28.4**.Nous pouvons combiner la recherche ColPali et le code d'inférence Ollama dans la fonction inference ci-dessous. Cette fonction récupère la page la plus pertinente du document, la transmet au modèle de vision avec la requête et renvoie une réponse.
def inference(question: str):
results = RAG.search(question, k=1) # Retrieve relevant data
see_image(results[0]['base64']) # Save and display image
response = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': question,
'images': ['image.jpg']
}]
)
return response['message']['content']
# Example queries
inference_result = inference("Please explain figure 1")
print(inference_result)The Transformer model is a type of neural network architecture that was introduced in the paper "Attention Is All You Need" by Vaswani et al. in 2017. It has since become one of the most widely used architectures for natural language processing tasks, such as machine translation, text summarization, and question answering.
**What is a Transformer?**
A Transformer is a type of neural network that uses self-attention mechanisms to process input sequences, such as sentences or paragraphs. Unlike traditional recurrent neural networks (RNNs), which rely on sequential processing of inputs, Transformers can process all input elements simultaneously using parallelized attention modules.
**How does the Transformer work?**
The Transformer consists of an encoder and a decoder. The encoder takes in a sequence of tokens (e.g., words or characters) as input and produces a continuous representation of the input sequence. This representation is then fed into the decoder, which generates output sequences one token at a time.
**Key Components:**
* **Self-Attention Mechanism:** This mechanism allows the model to attend to different parts of the input sequence simultaneously and weigh their importance.
* **Multi-Head Attention:** The Transformer uses multiple attention heads to process different aspects of the input sequence in parallel, improving the model's ability to capture complex relationships between tokens.
* **Positional Encoding:** To incorporate positional information into the input sequence, the Transformer uses a positional encoding scheme that adds a learned vector to each token based on its position in the sequence.
**Advantages:**
* **Parallelization:** The Transformer can process all input elements simultaneously, making it much faster than traditional RNNs.
* **Flexibility:** The Transformer can handle sequences of varying lengths and is particularly effective for tasks involving long-range dependencies.
**Applications:**
The Transformer has been widely adopted in various natural language processing applications, including:
* Machine Translation
* Text Summarization
* Question Answering
* Sentiment Analysis
In summary, the Transformer model is a powerful neural network architecture that uses self-attention mechanisms to process input sequences efficiently and effectively. Its ability to parallelize attention modules has made it a popular choice for many natural language processing tasks.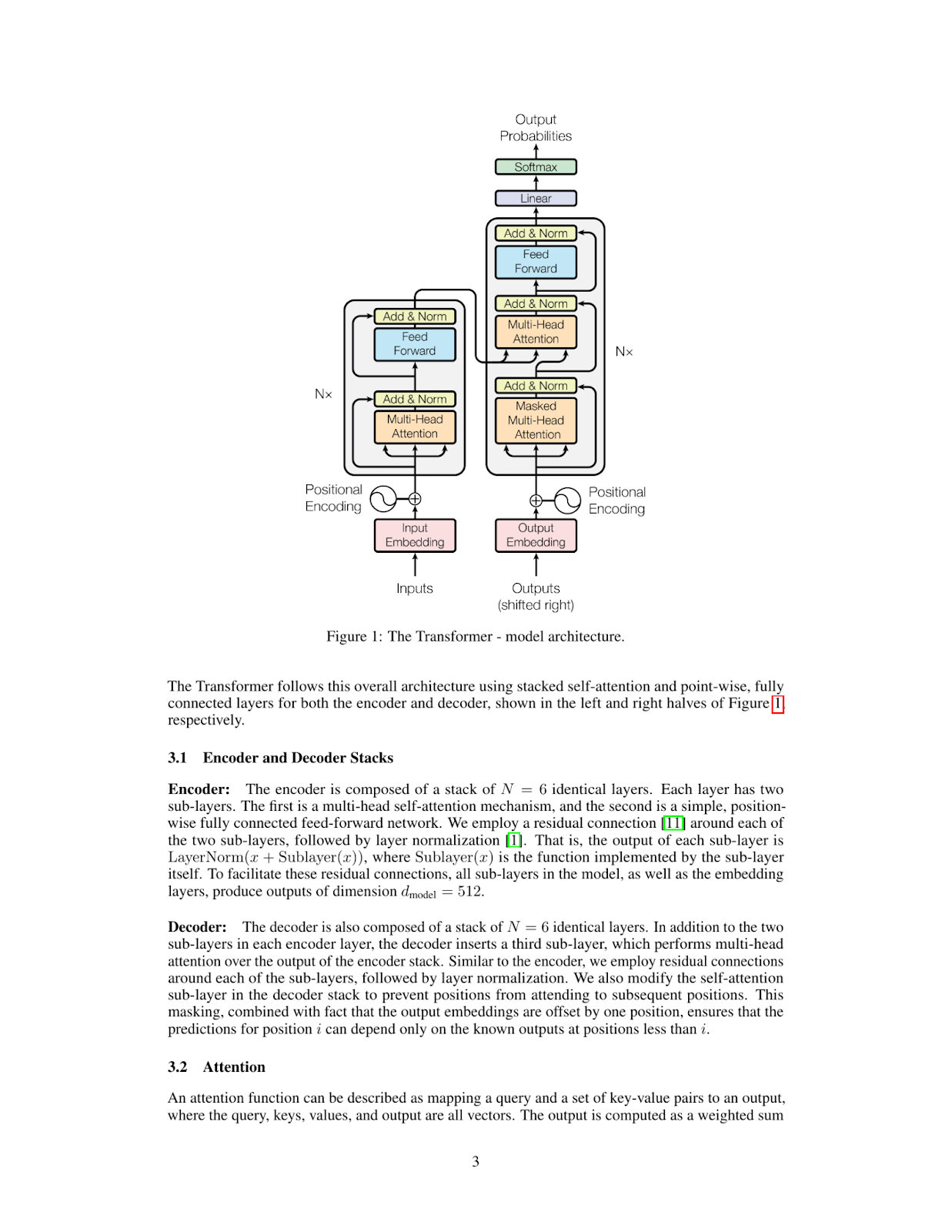
Essayons une autre requête :
inference_result = inference("What's the maximum path length of recurrent layer type")
print(inference_result)The table provided in the image shows that for a Recurrent Layer, the Maximum Path Length is O(n). This means that as the number of nodes (n) in the network increases, the maximum path length also increases linearly with it.
Therefore, the maximum path length of a recurrent layer type is O(n).
*Answer*: O(n)
La capacité de Llama 3.2 Vision à combiner la compréhension visuelle et textuelle le rend idéal pour une variété d'applications dans le monde réel.
Dans le domaine de la santé, Llama 3.2 Vision peut améliorer la précision des diagnostics en analysant les images médicales, comme les radiographies et les IRM, en même temps que les dossiers des patients. Cette combinaison de données visuelles et textuelles aide les médecins à prendre des décisions plus éclairées et accélère la recherche clinique, ce qui profite en fin de compte aux soins des patients.
Llama 3.2 Vision peut également améliorer l'expérience d'achat du client en combinant des images de produits, des commentaires textuels et des questions de clients. Cela permet d'obtenir des recommandations plus personnalisées et un parcours d'achat sur mesure, ce qui améliore à la fois l'engagement et la satisfaction.
Dans le secteur juridique, Llama 3.2 Vision aide les professionnels à récupérer et à résumer rapidement les informations contenues dans les contrats, la jurisprudence et les documents scannés. Il peut même interpréter des éléments visuels complexes tels que des diagrammes d'audience ou des annotations de documents, fournissant ainsi des informations précieuses pour l'analyse juridique et la prise de décision.
Enfin, Llama 3.2 Vision peut aider les environnements d'apprentissage en interprétant les aides visuelles telles que les diagrammes et les graphiques et en les associant à des explications textuelles claires et en temps réel. Le contenu éducatif devient ainsi plus interactif, ce qui permet aux étudiants et aux professionnels d'apprendre plus efficacement.
Avec ColPali et les modèles de vision Llama 3.2, vous pouvez construire un puissant système RAG capable de comprendre et de raisonner sur des PDF contenant des données visuelles et textuelles complexes. Cette combinaison ouvre des possibilités d'applications allant de l'analyse de documents à la génération automatisée de rapports, ce qui la rend très utile pour les flux de travail multimodaux de l'IA.
Apprenez l'IA avec ces cours !
Cursus
Cursus
Cours