
Lernpfad
Llama-Grundlagen
4 Std.
Meta hat gerade die Llama 4 Modellreihe angekündigt, die zwei bereits veröffentlichte Modelle - Llama4 Scout und Llama 4 Maverick- und ein drittes, das noch in der Ausbildung ist, umfasst: Llama 4 Behemoth.
Die Scout- und Maverick-Varianten sind ab sofort verfügbar und werden unter Metas typischer Open-Weight-Lizenz veröffentlicht - mit einem bemerkenswerten Vorbehalt: Wenn deine Dienste mehr als 700 Millionen monatlich aktive Nutzer haben, musst du eine separate Lizenz von Meta erwerben, die Meta nach eigenem Ermessen vergeben kann oder auch nicht.
Llama Scout unterstützt ein Kontextfenster mit 10 Millionen Token, das größte aller bisher veröffentlichten Modelle. Llama Maverick ist ein Generalistenmodell und zielt auf GPT-4o, Gemini 2.0 Flash und DeepSeek-V3. Llama Behemoth, das sich noch in der Ausbildung befindet, dient als leistungsstarkes Lehrermodell.
Unser Team testet das Modell aktiv, und wir werden separate Blogs zur Feinabstimmung von Llama 4 und zum Betrieb auf vLLMund das Testen des riesigen Kontextfensters veröffentlichen - ich werde diesen Artikel mit Links aktualisieren, sobald sie fertig sind. In diesem Einführungsblog gebe ich dir einen Überblick über die Llama 4 Suite.
Wir halten unsere Leserinnen und Leser mit The Median auf dem Laufenden, unserem kostenlosen Freitags-Newsletter, der die wichtigsten Meldungen der Woche aufschlüsselt. Melde dich an und bleibe in nur ein paar Minuten pro Woche auf dem Laufenden:
Llama 4 ist die neue Familie der großen Sprachmodelle von Meta. Die Veröffentlichung umfasst zwei bereits erhältliche Modelle - Llama 4 Scout und Llama 4 Maverick - und ein drittes, Llama 4 Behemoth, das sich noch im Training befindet.

Quelle: Meta AI
Llama 4 bringt wesentliche Verbesserungen mit sich. Insbesondere beinhaltet es eine Mixture-of-Experts (MoE) Architektur, die darauf abzielt, die Effizienz und Leistung zu verbessern, indem nur die für bestimmte Aufgaben notwendigen Komponenten aktiviert werden (mehr dazu später). Dieses Design steht für einen Wandel hin zu skalierbaren und spezialisierten KI-Modellen.
Llama 4 setzt die Strategie von Meta fort, Modelle mit offenem Gewicht herauszubringen - allerdings mit einem Vorbehalt. Wenn dein Unternehmen Dienste mit mehr als 700 Millionen monatlich aktiven Nutzerinnen und Nutzern betreibt, brauchst du eine separate Lizenz von Meta, die du unter Umständen auch erhalten kannst. Abgesehen von dieser Einschränkung fühlt sich die Veröffentlichung immer noch wie ein großes Ereignis in der Open-Weight-Landschaft an, obwohl sich die Landschaft in den letzten Monaten rasant verändert hat.
Wenn Llama 2 und 3 einst die Kategorie definierten, betritt Llama 4 jetzt ein Feld, das viel wettbewerbsfähiger ist. DeepSeek ist mit starken Argumentationsfähigkeiten ausgestattet. Alibaba's Qwen Serie hat bei mehrsprachigen und kodierten Benchmarks gut abgeschnitten. Googles Gemma Modelle drängen mit kleineren, effizienten Architekturen in den gleichen Bereich. Und erst vor wenigen Tagen kündigte OpenAI Pläne an, ein Modell mit offenem Gewicht zu veröffentlichen - eine Veränderung, die vor einem Jahr noch unwahrscheinlich gewesen wäre.
Wir wollen mehr über die einzelnen Modelle erfahren.
Das Llama 4 Scout ist das leichtere Modell der neuen Reihe, aber es ist wohl das faszinierendste. Er läuft auf einer einzigen H100 GPU und unterstützt ein Kontextfenster mit 10 Millionen Token. Damit ist Scout das kontextstärkste offene Modell, das bisher veröffentlicht wurde, und potenziell das nützlichste für Aufgaben wie die Zusammenfassung mehrerer Dokumente, Longform Code Reasoning und Activity Parsing.

Scout hat 17 Milliarden aktive Parameter, die von 16 Experten organisiert werden, mit einer Gesamtparameterzahl von 109 Milliarden. Es wurde mit einem 256K-Kontextfenster vor- und nachtrainiert, aber Meta sagt, dass es weit darüber hinaus generalisiert (diese Behauptung muss noch getestet werden). In der Praxis öffnet das die Tür zu Workflows, die ganze Codebases, Sitzungsprotokolle oder juristische Dokumente umfassen - alles in einem einzigen Durchgang.
Die Architektur von Scout basiert auf dem Mixture-of-Experts (MoE)-Framework von Meta, bei dem nur eine Teilmenge der Parameter pro Token aktiviert wird - im Gegensatz zu dichten Modellen wie GPT-4o, bei denen alle Parameter aktiviert werden. Das bedeutet, dass es sowohl recheneffizient als auch hoch skalierbar ist.
Über die Kernarchitektur hinaus betonte Meta, dass Scout multimodale Fähigkeiten. Es wurde mit Text-, Bild- und Videodaten trainiert, so dass es Kombinationen aus Text und visuellen Aufforderungen verarbeiten kann. Bei bildlastigen Aufgaben wie visuellem Grounding und VQA (visuellem Question Answering) schneidet Scout besser ab als alle bisherigen Llama-Modelle - und kann es mit viel größeren Systemen aufnehmen.
Kurz gesagt: Scout ist auf Breite und Umfang ausgelegt. Er ist so konzipiert, dass er effizient arbeitet, mehr Eingaben als jedes andere offene Modell verarbeiten kann und sowohl bei Text- als auch bei Bildaufgaben gut funktioniert. Wir werden das 10-Millionen-Kontext-Limit bald testen und darüber berichten.
Llama 4 Maverick ist der Generalist in der Reihe - ein vollwertiges, multimodales Modell, das auf Leistung in den Bereichen Chat, Argumentation, Bildverständnis und Code ausgelegt ist. Während Scout die Grenzen der Kontextlänge ausreizt, konzentriert sich Maverick auf eine ausgewogene, qualitativ hochwertige Leistung bei allen Aufgaben. Es ist die Antwort von Meta auf GPT-4o, DeepSeek-V3und Gemini 2.0 Flash.

Maverick hat die gleichen 17 Milliarden aktiven Parameter wie Scout, aber mit einer größeren MoE-Konfiguration: 128 Experten und eine Gesamtanzahl von 400 Milliarden Parametern. Wie Scout verwendet es eine Mixture-of-Experts-Architektur, die nur einen Teil des Modells pro Token aktiviert und so die Inferenzkosten reduziert, während die Kapazität skaliert wird. Das Modell läuft auf einem einzelnen H100 DGX-Host, kann aber auch mit verteilten Inferenzen für größere Anwendungen eingesetzt werden.
Meta wählte hier einen anderen Ansatz für das Post-Training, indem es eine Mischung aus leichtem, überwachten Feinabstimmungund Online Verstärkungslernenund direkter Präferenzoptimierung. Das Ziel war es, die Leistung bei schwierigen Aufforderungen zu verbessern, ohne das Modell zu überfordern. Zu diesem Zweck hat Meta mehr als 50 % der Trainingsbeispiele herausgefiltert, die von früheren Llama-Modellen als "leicht" eingestuft wurden, und einen Lehrplan erstellt, der den Schwerpunkt auf schwierigeres logisches Denken, Codieren und multimodale Aufgaben legt.
Maverick wurde außerdem aus Llama 4 Behemoth, dem viel größeren internen Modell von Meta, mitdestilliert, was die Leistung ohne zusätzliche Ausbildungskosten erhöht hat. Laut Meta hat diese Destillationspipeline einen deutlichen Sprung in der Argumentations- und Chatqualität bewirkt.
Das Llama 4 Behemoth ist Metas bisher leistungsstärkstes und größtes Modell - aber es ist noch nicht erhältlich. Behemoth befindet sich noch im Training und ist kein Denkmodell im gleichen Sinne wie DeepSeek-R1 oder OpenAI's o3die für mehrstufige Chain-of-Thought-Aufgaben entwickelt und optimiert wurden.
Nach dem, was wir bisher wissen, scheint es auch nicht als Produkt für den direkten Gebrauch konzipiert zu sein. Stattdessen fungiert es als Lehrermodell, das dazu dient destillieren und sowohl Scout als auch Maverick zu formen. Sobald es veröffentlicht ist, können auch andere ihre eigenen Modelle destillieren.

Behemoth hat 288 Milliarden aktive Parameter, die von 16 Experten organisiert werden, mit einer Gesamtparameterzahl von fast 2 Billionen. Meta hat eine völlig neue Ausbildungsinfrastruktur aufgebaut, um Behemoth in dieser Größenordnung zu unterstützen. Sie führte asynchrones Verstärkungslernen, eine auf der Schwierigkeit der Aufforderung basierende Lehrplanauswahl und eine neue Destillationsverlustfunktion ein, die einen dynamischen Ausgleich zwischen weichen und harten Zielen schafft.
Nach der Ausbildung brauchte Behemoth auch ein anderes Rezept. Meta verwarf über 95 % der SFT-Beispiele, um sich auf schwierige Aufforderungen zu beschränken, und konzentrierte das Verstärkungslernen auf komplexes Denken, Codieren und mehrsprachige Szenarien. Stichproben aus verschiedenen Systemanweisungen halfen dem Modell, sich zu verallgemeinern, während die dynamische Filterung geringwertige Aufforderungen während des RL-Trainings entfernte.
Meta hat interne Benchmark-Ergebnisse für jedes der Llama 4-Modelle veröffentlicht, in denen sie sowohl mit ihren vorherigen Llama-Varianten als auch mit mehreren konkurrierenden Open-Weight- und Frontier-Modellen verglichen werden.
In diesem Abschnitt gehe ich mit dir die Benchmark-Highlights für Scout, Maverick und Behemoth durch und verwende dabei Metas eigene Zahlen. Wie immer rate ich zur Vorsicht bei selbstberichteten Benchmarks - aber diese Ergebnisse bieten einen hilfreichen ersten Blick darauf, wie die einzelnen Modelle bei verschiedenen Aufgaben abschneiden und wo sie in der aktuellen Landschaft stehen. Beginnen wir mit Scout.
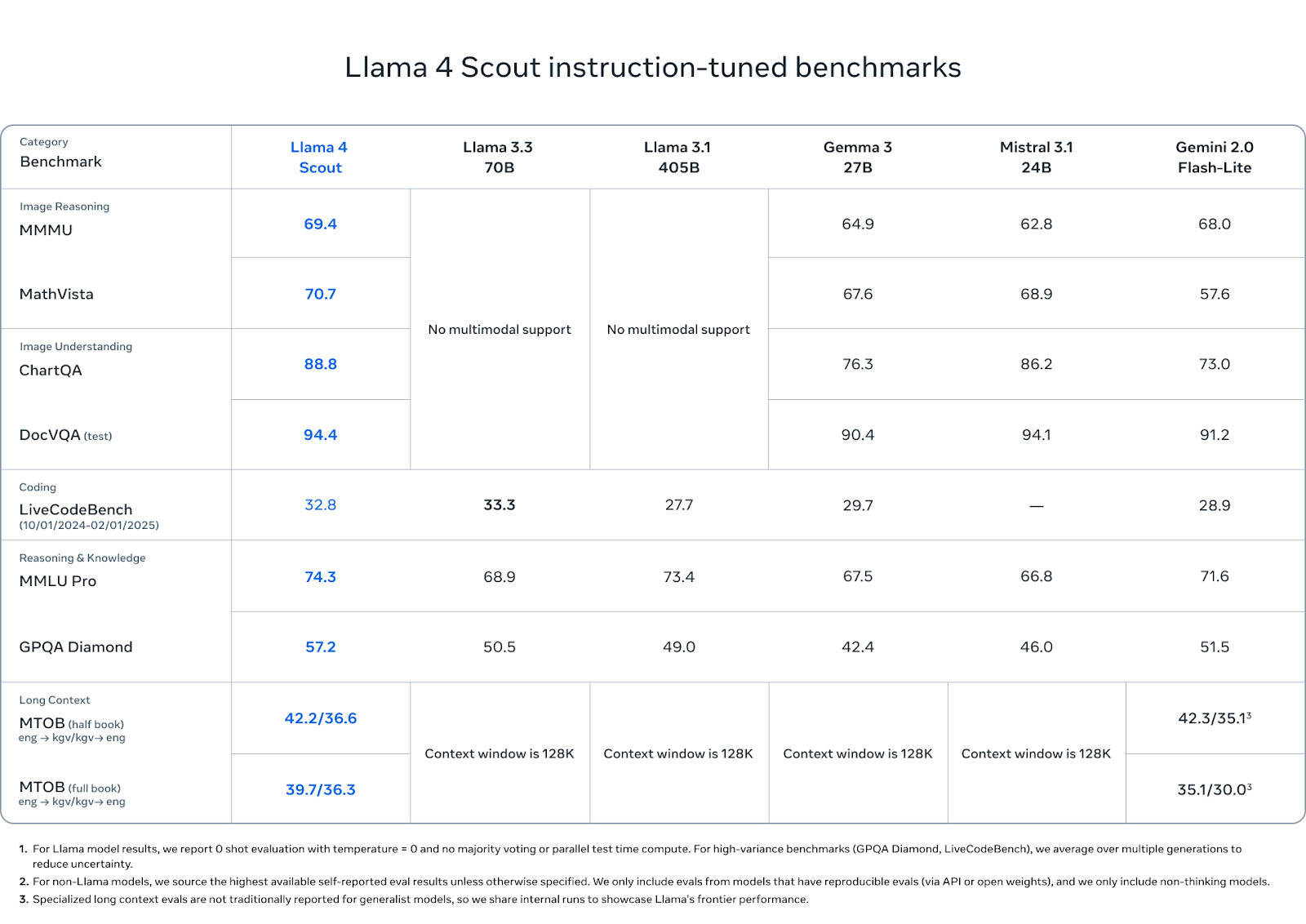
Llama 4 Scout schneidet in einer Mischung aus Reasoning-, Coding- und multimodalen Benchmarks gut ab - vor allem, wenn man bedenkt, dass es weniger aktive Parameter hat und nur eine GPU benötigt.
Quelle: MetaAI
Beim Bildverstehen liegt Scout vor der Konkurrenz: Mit 88,8 Punkten bei ChartQA und 94,4 Punkten bei DocVQA (Test) übertrifft es Gemini 2.0 Flash-Lite (73,0 bzw. 91,2) und liegt gleichauf oder leicht vor Mistral 3.1 und Gemma 3 27B.
Bei den Image Reasoning Benchmarks wie MMMU (69,4) und MathVista (70,7) liegt er ebenfalls an der Spitze und übertrifft Gemma 3 (64,9, 67,6), Mistral 3.1 (62,8, 68,9) und Gemini Flash-Lite (68,0, 57,6).
Beim Coding erreicht Scout im LiveCodeBench einen Wert von 32,8 und liegt damit vor Gemini Flash-Lite (28,9) und Gemma 3 27B (29,7), aber knapp hinter dem Wert von Llama 3.3 (33,3). Es ist kein Coding-First-Modell, aber es kann sich sehen lassen.
Bei Wissen und logischem Denken erreicht Scout 74,3 Punkte bei MMLU Pro und 57,2 Punkte bei GPQA Diamond und übertrifft damit alle anderen offenen Modelle. Diese Benchmarks bevorzugen lange, mehrstufige Argumentationen, daher ist die starke Leistung von Scout hier bemerkenswert, besonders in dieser Größenordnung.
Und schließlich zeigen die Fähigkeiten von Scout in Bezug auf lange Kontexte ihr Potenzial in der Praxis. Beim MTOB (Massive Textual Overlap Benchmark), der die Fähigkeit des Modells testet, zwischen Englisch und KGV, einer ressourcenarmen Sprache, zu übersetzen, erzielt es 42,2/36,6 Punkte im Halbbuchtest und 39,7/36,3 Punkte im Ganzbuchtest. Im Halbbuchtest liegt Gemini 2.0 Flash-Lite mit 42,3 leicht vorne, aber Scout schließt die Lücke im Vollbuchtest und übertrifft Gemini mit 35,1/30,0.
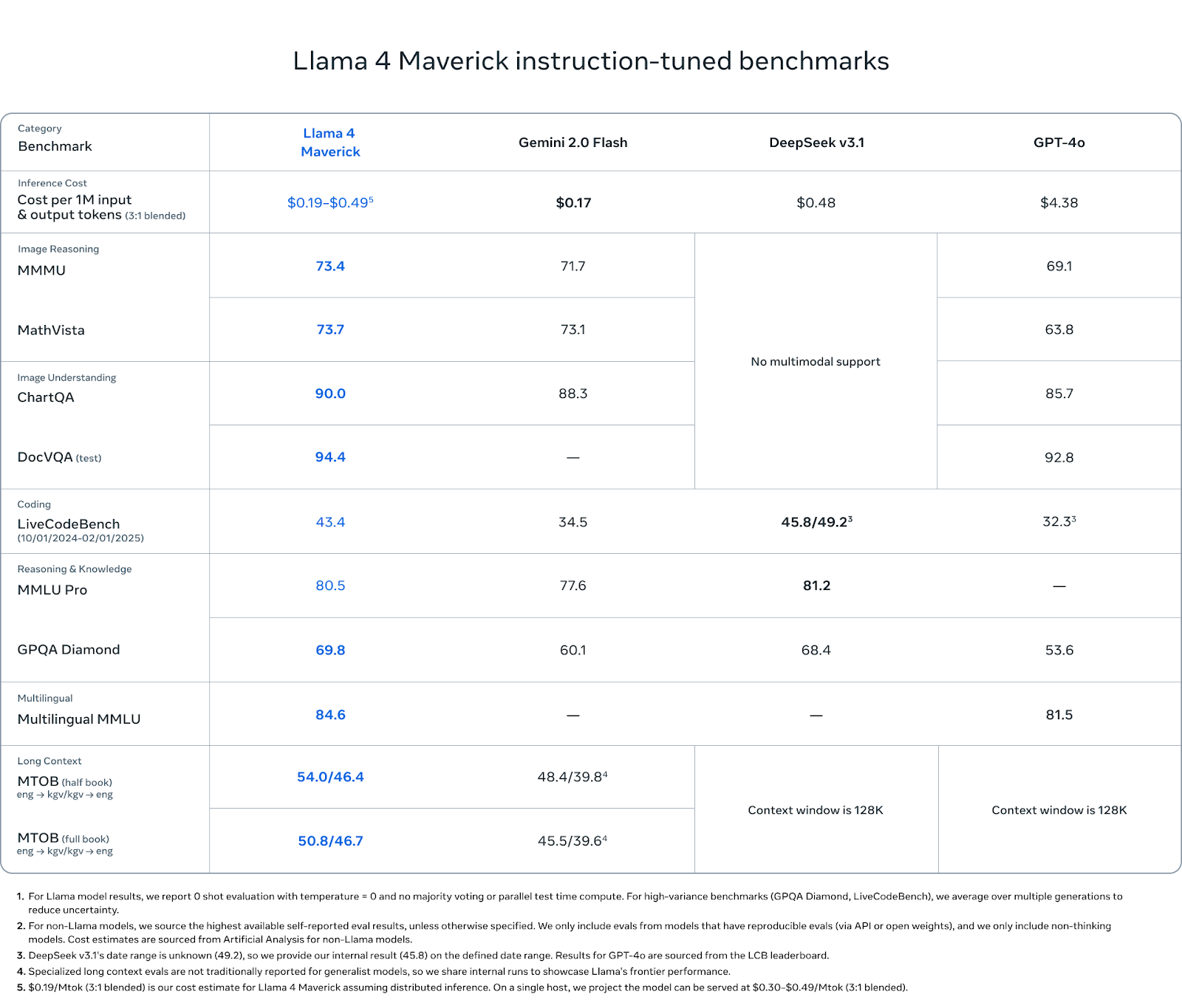
Maverick ist das vielseitigste Modell der Llama 4-Reihe - und das spiegelt sich auch in den Benchmark-Ergebnissen wider. Auch wenn er nicht die extreme Kontextlänge von Scout oder die grobe Skala von Behemoth anstrebt, zeigt er in allen wichtigen Kategorien eine konsistente Leistung: multimodales Denken, Kodieren, Sprachverständnis und Behalten von langen Kontexten.
Quelle: MetaAI
Beim Image Reasoning erreicht Maverick 73,4 Punkte bei MMMU und 73,7 Punkte bei MathVista und übertrifft damit Gemini 2.0 Flash (71,7 und 73,1) und GPT-4o (69,1 und 63,8). Bei ChartQA (Bildverständnis) liegt es mit 90,0 Punkten leicht über dem Wert von Gemini (88,3) und deutlich über dem Wert von GPT-4o (85,7). Im DocVQA-Test erreicht Maverick 94,4 Punkte und liegt damit gleichauf mit Scout und übertrifft GPT-4o mit 92,8 Punkten.
Beim Coding erreicht Maverick im LiveCodeBench einen Wert von 43,4 und liegt damit vor GPT-4o (32,3), Gemini Flash (34,5) und nahe am Wert von DeepSeek v3.1 (45,8).
Beim logischen Denken und Wissen erreicht Maverick 80,5 Punkte bei MMLU Pro und 69,8 Punkte bei GPQA Diamond und übertrifft damit erneut Gemini Flash (77,6 und 60,1) und GPT-4o (keine Angaben bei MMLU Pro, 53,6 bei GPQA). DeepSeek v3.1 führt mit einem Vorsprung von 0,7 in MMLU Pro.
Auch beim Verstehen von Mehrsprachigkeit schneidet Maverick gut ab und liegt mit 84,6 Punkten beim Multilingual MMLU leicht über dem Wert von Gemini (81,5). Das ist ein Vorteil für Entwickler, die in mehreren Sprachen oder Regionen arbeiten.
Bei den Bewertungen im langen Kontext (MTOB) schneidet Maverick mit 54,0/46,4 Punkten im Halbbuch-Test und 50,8/46,7 Punkten im Vollbuch-Test deutlich besser ab als Gemini mit 48,4/39,8 bzw. 45,5/39,6 Punkten. Diese Ergebnisse deuten darauf hin, dass Maverick zwar nicht so laut mit seiner Kontextlänge wirbt wie Scout, aber dennoch von seinem erweiterten Fenster profitiert.
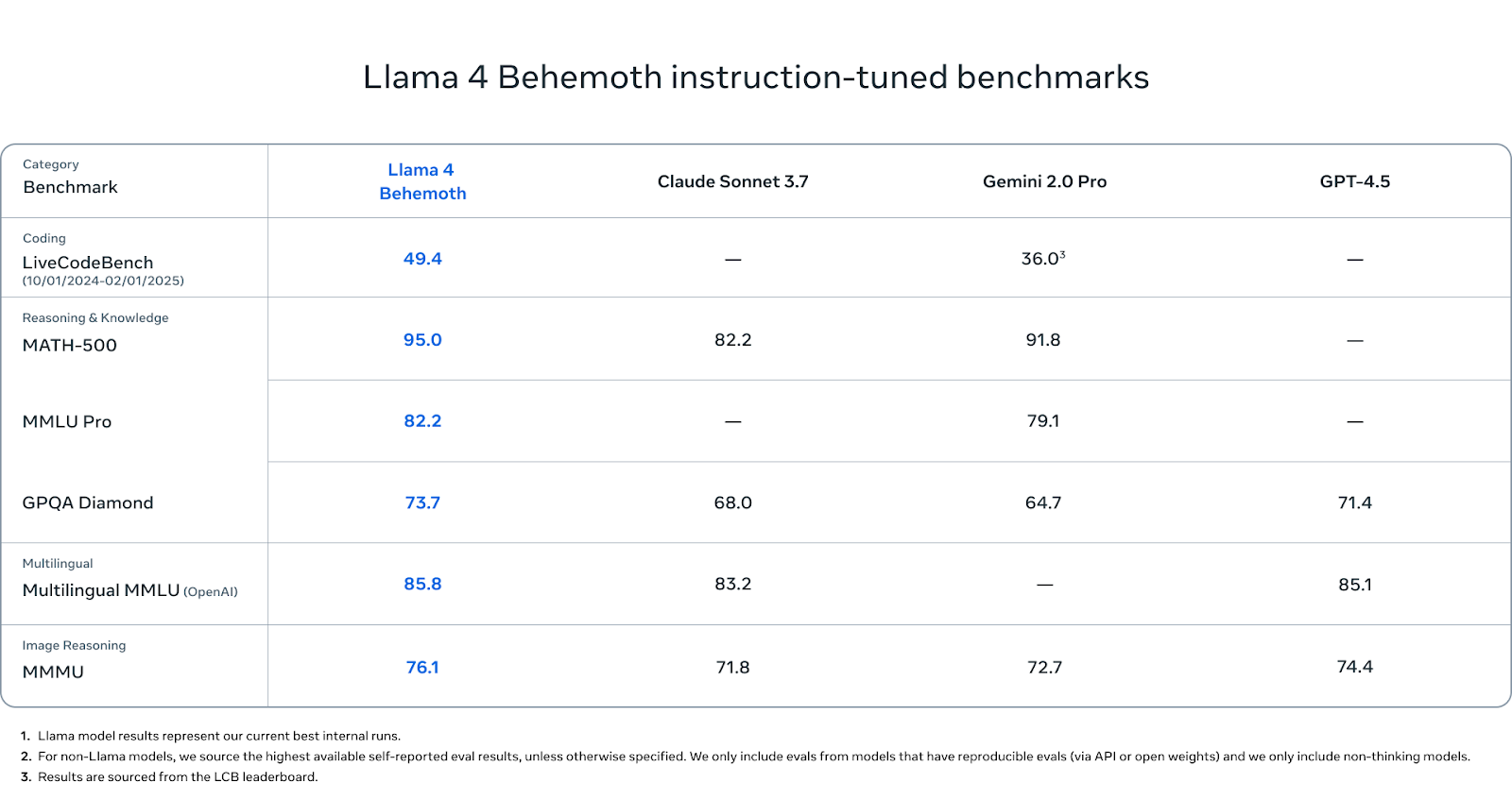
Behemoth ist noch nicht veröffentlicht, aber seine Benchmark-Zahlen sind es wert, beachtet zu werden.
Quelle: MetaAI
Bei MINT-lastigen Benchmarks schneidet Behemoth außergewöhnlich gut ab. Er erreicht 95,0 Punkte auf MATH-500 - das ist besser als Gemini 2.0 Pro (91,8) und deutlich besser als Claude Sonnet 3.7 (82.2). Bei MMLU Pro erreicht Behemoth einen Wert von 82,2, während Gemini Pro auf 79,1 kommt (Claude hat keinen Wert gemeldet). Und bei GPQA Diamond, einem weiteren Benchmark, der Faktentiefe und Präzision belohnt, erreicht Behemoth 73,7 und liegt damit vor Claude (68,0), Gemini (64,7) und GPT-4.5 (71.4).
Beim mehrsprachigen Verstehen erreicht Behemoth 85,8 Punkte auf Multilingual MMLU und liegt damit leicht vor Claude Sonnet (83,2) und GPT-4.5 (85,1). Diese Werte sind wichtig für globale Entwickler, die außerhalb der englischen Sprache arbeiten, und Behemoth führt diese Kategorie derzeit an.
Beim Image Reasoning erreicht Behemoth 76,1 auf MMMU und übertrifft damit Gemini (71,8), Claude (72,7) und GPT-4.5 (74,4). Auch wenn dies nicht sein Hauptaugenmerk ist, kann er dennoch mit führenden multimodalen Modellen mithalten.
Bei der Codegenerierung erzielt Behemoth 49,4 Punkte auf dem LiveCodeBench. Das ist deutlich mehr als Gemini 2.0 Pro (36,0).
Sowohl Llama 4 Scout als auch Llama 4 Maverick sind ab sofort unter der Open-Weight-Lizenz von Meta erhältlich. Du kannst sie direkt von der offiziellen Llama-Website oder über Hugging Face.
Um über Metas eigene Dienste auf die Modelle zuzugreifen, kannst du auf verschiedenen Plattformen mit Meta AI interagieren: WhatsApp, Messenger, Instagram und Facebook. Der Zugang erfordert derzeit eine Anmeldung mit einem Meta-Konto, und es gibt keinen eigenständigen API-Endpunkt für Meta AI - zumindest noch nicht.
Wenn du vorhast, die Modelle in deine eigenen Anwendungen oder deine Infrastruktur zu integrieren, solltest du die Lizenzklausel beachten: Wenn dein Produkt oder dein Dienst mehr als 700 Millionen monatlich aktive Nutzer/innen hat, musst du eine separate Genehmigung von Meta einholen. Die Modelle sind ansonsten für Forschung, Experimente und die meisten kommerziellen Anwendungsfälle geeignet.
Scout führt eine noch nie dagewesene Kontextlänge auf einer einzelnen GPU ein. Maverick behauptet sich gegen größere Modelle in den Bereichen Argumentation, Code und multimodale Aufgaben. Und Behemoth, das sich noch in der Ausbildung befindet, gibt einen Einblick, wie Lehrermodelle effizientere und einsatzfähigere Varianten formen können.
Der Wettbewerb im Bereich der offenen Gewichte ist größer denn je. DeepSeek, Qwen, Gemma und bald auch OpenAI sind alle mit starken Veröffentlichungen auf dem Vormarsch. Mit Llama 4 setzt Meta seine Bemühungen fort, skalierbare, offen verfügbare Modelle für eine Reihe von Anwendungsfällen anzubieten.
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Mark Pedigo
Tutorial
Abid Ali Awan
Tutorial
Sejal Jaiswal
Tutorial
Matt Crabtree