
Kurs
Maschinelles Lernen mit baumbasierten Modellen in Python
5 Std.
116.4K
Beim maschinellen Lernen liegt die Grundlage für erfolgreiche Modelle in der Qualität der Daten, auf denen sie trainiert werden. Während komplexe, ausgeklügelte Algorithmen und Modelle oft im Rampenlicht stehen, ist die Datenvorverarbeitung oft der unbesungene Held. Die Datenvorverarbeitung ist ein wichtiger Schritt, der Rohdaten in Merkmale umwandelt, die dann für effektives maschinelles Lernen verwendet werden.
Algorithmen für maschinelles Lernen werden oft unter der Annahme trainiert, dass alle Merkmale gleichermaßen zur endgültigen Vorhersage beitragen. Diese Annahme scheitert jedoch, wenn sich die Merkmale in Umfang und Einheit unterscheiden, was sich auf ihre Bedeutung auswirkt.
Hier kommt die Normalisierung ins Spiel - ein wichtiger Schritt in der Datenvorverarbeitung, der die Einheitlichkeit der numerischen Größen der Merkmale sicherstellt. Diese Einheitlichkeit verhindert die Dominanz von Merkmalen, die im Vergleich zu den anderen Merkmalen oder Variablen größere Werte haben.
In diesem Artikel befassen wir uns mit der Normalisierung, einer Technik zur Skalierung von Merkmalen, die einen Weg bietet, die Waage der Merkmale auszugleichen.
Die Normalisierung ist eine spezielle Form der Merkmalsskalierung, bei der die Bandbreite der Merkmale in eine Standardskala umgewandelt wird. Eine Normalisierung und damit eine Skalierung der Daten ist nur dann erforderlich, wenn dein Datensatz Merkmale mit unterschiedlichen Bereichen enthält. Die Normalisierung umfasst verschiedene Techniken, die auf unterschiedliche Datenverteilungen und Modellanforderungen zugeschnitten sind.
Die Normalisierung ist nicht nur auf numerische Daten beschränkt. In diesem Artikel werden wir uns jedoch auf numerische Beispiele konzentrieren. Sieh dir unbedingt Datacamps Textacy an: Eine Einführung in die Bereinigung und Normalisierung von Textdaten in Python, wenn du Textdaten für maschinelles Lernen vorverarbeiten willst.
Normalisierte Daten erhöhen die Modellleistung und verbessern die Genauigkeit eines Modells. Sie hilft Algorithmen, die sich auf Abstandsmetriken stützen, wie z.B. k-nearest neighbors oder Support Vector Machines, indem sie verhindert, dass Merkmale mit größeren Skalen den Lernprozess dominieren.
Die Normalisierung fördert die Stabilität des Optimierungsprozesses und damit eine schnellere Konvergenz beim gradientenbasierten Training. Sie entschärft Probleme im Zusammenhang mit verschwindenden oder explodierenden Gradienten, so dass die Modelle effizienter zu optimalen Lösungen gelangen können.
Normalisierte Daten sind außerdem leicht zu interpretieren und daher einfacher zu verstehen. Wenn alle Merkmale eines Datensatzes denselben Maßstab haben, ist es auch einfacher, die Beziehungen zwischen verschiedenen Merkmalen zu erkennen und zu visualisieren und aussagekräftige Vergleiche anzustellen.
Nehmen wir ein einfaches Beispiel, um die Bedeutung der Normalisierung von Daten zu verdeutlichen. Wir versuchen, die Wohnungspreise auf der Grundlage verschiedener Merkmale wie Quadratmeterzahl, Anzahl der Schlafzimmer und Entfernung zum Supermarkt usw. vorherzusagen. Der Datensatz enthält verschiedene Merkmale mit unterschiedlichen Maßstäben, wie zum Beispiel:
Wenn du diese Daten ohne Vorverarbeitung direkt an ein maschinelles Lernmodell weitergibst, kann es sein, dass der Algorithmus Merkmale mit großen Skalen, wie zum Beispiel die Quadratmeterzahl, stärker gewichtet. Beim Training geht der Algorithmus davon aus, dass eine Veränderung der Gesamtfläche einen erheblichen Einfluss auf die Wohnungspreise hat. Der Algorithmus könnte die Feinheiten von Merkmalen übersehen, die relativ klein sind, wie die Anzahl der Schlafzimmer und die Entfernung zum Supermarkt. Diese verzerrte Gewichtung kann zu einer suboptimalen Modellleistung und verzerrten Vorhersagen führen.
Indem wir die Merkmale normalisieren, können wir sicherstellen, dass jedes Merkmal einen proportionalen Beitrag zum Lernprozess des Modells leistet. Das Modell kann nun Muster über alle Merkmale hinweg effektiver lernen, was zu einer genaueren Darstellung der zugrunde liegenden Beziehungen in den Daten führt.
Min-Max-Skalierung und Z-Score-Normalisierung (Standardisierung) sind die beiden grundlegenden Techniken zur Normalisierung. Darüber hinaus werden wir auch die Normalisierung der Dezimalskalierung, die Normalisierung der Log-Skalierung und die robuste Skalierung besprechen, die besondere Herausforderungen bei der Datenvorverarbeitung angehen.
Die Min-Max-Skalierung wird oft einfach "Normalisierung" genannt. Sie wandelt Merkmale in einen bestimmten Bereich um, in der Regel zwischen 0 und 1. Die Formel für die Min-Max-Skalierung lautet:
Xnormalisiert = X - Xmin / Xmax - Xmin
Dabei ist X ein zufälliger Merkmalswert, der normalisiert werden soll. Xmin ist der minimale Merkmalswert im Datensatz und Xmax ist der maximale Merkmalswert.
Min-Max-Skalierung ist eine gute Wahl, wenn:
Die Z-Score-Normalisierung (Standardisierung) geht von einer Gauß'schen (Glockenkurve) Verteilung der Daten aus und transformiert die Merkmale so, dass sie einen Mittelwert (μ) von 0 und eine Standardabweichung (σ) von 1 haben. Die Formel für die Normung lautet:
Xstandardisiert = X-μ / σ
Diese Technik ist besonders nützlich, wenn du mit Algorithmen arbeitest, die von normalverteilten Daten ausgehen, wie zum Beispiel viele lineare Modelle. Anders als bei der Min-Max-Skalierung sind die Merkmalswerte bei der Standardisierung nicht auf einen bestimmten Bereich beschränkt. Diese Normalisierungstechnik stellt die Merkmale im Wesentlichen anhand der Anzahl der Standardabweichungen dar, die vom Mittelwert entfernt liegen.
Bevor wir uns mit anderen Datenumwandlungstechniken befassen, wollen wir einen Vergleich zwischen Normalisierung (Min-Max-Skalierung) und Standardisierung anstellen.
|
Normalisierung |
Normung |
|
Ziel ist es, die Werte eines Merkmals in einen bestimmten Bereich zu bringen, oft zwischen 0 und 1 |
Ziel ist es, die Werte eines Merkmals so zu transformieren, dass sie einen Mittelwert von 0 und eine Standardabweichung von 1 haben. |
|
Empfindlich für Ausreißer und den Bereich der Daten |
Weniger anfällig für Ausreißer aufgrund der Verwendung von Mittelwert und Standardabweichung |
|
Nützlich, wenn die Beibehaltung der ursprünglichen Reichweite wichtig ist |
Wirksam, wenn Algorithmen eine Standard-Normalverteilung annehmen |
|
Es werden keine Annahmen über die Verteilung der Daten gemacht |
Geht von einer Normalverteilung oder einer guten Annäherung aus |
|
Geeignet für Algorithmen, bei denen die absoluten Werte und ihre Beziehungen wichtig sind (z. B. k-nearest neighbors, neuronale Netze) |
Besonders nützlich für Algorithmen, die von normalverteilten Daten ausgehen, wie z. B. lineare Regression und Support-Vektor-Maschinen |
|
Behält die Interpretierbarkeit der ursprünglichen Werte innerhalb des angegebenen Bereichs bei |
Verändert die ursprünglichen Werte, was die Interpretation aufgrund der Verschiebung von Maßstab und Einheiten erschwert |
|
Kann zu einer schnelleren Konvergenz führen, insbesondere bei Algorithmen, die auf Gradientenabstieg beruhen |
Trägt auch zu einer schnelleren Konvergenz bei, insbesondere bei Algorithmen, die auf die Skalierung der Eingangsmerkmale reagieren |
|
Anwendungsfälle: Bildverarbeitung, neuronale Netze, Algorithmen, die auf Merkmalsskalen reagieren |
Anwendungsfälle: Lineare Regression, Support-Vektor-Maschinen, Algorithmen, die von einer Normalverteilung ausgehen |
Das Ziel der Dezimalskalierung ist es, die Merkmalswerte mit einer Potenz von 10 zu skalieren und so sicherzustellen, dass der größte absolute Wert in jedem Merkmal kleiner als 1 wird. Sie ist nützlich, wenn der Wertebereich in einem Datensatz bekannt ist, aber der Bereich zwischen den Merkmalen variiert. Die Formel für die Normalisierung der Dezimalskalierung lautet:
Xdecimal = X / 10d
Dabei ist X der ursprüngliche Merkmalswert und d die kleinste ganze Zahl, bei der der größte absolute Wert des Merkmals kleiner als 1 wird.
Wenn zum Beispiel der größte absolute Wert eines Merkmals 3500 beträgt, wäre d gleich 3 und das Merkmal würde um103 skaliert werden.
Die dezimale Skalierungsnormalisierung ist vorteilhaft, wenn es um Datensätze geht, bei denen die absolute Größe der Werte wichtiger ist als ihr spezifischer Maßstab.
Bei der Log-Skalierung werden die Daten in eine logarithmische Skala umgewandelt, indem der Logarithmus jedes Datenpunktes genommen wird. Sie ist besonders nützlich, wenn du mit Daten arbeitest, die sich über mehrere Größenordnungen erstrecken. Die Formel für die logarithmische Normierung lautet:
Xlog = log(X)
Diese Normalisierung ist bei Daten nützlich, die einem exponentiellen Wachstums- oder Zerfallsmuster folgen. Es komprimiert den Umfang des Datensatzes und macht es für Modelle einfacher, Muster und Beziehungen in den Daten zu erfassen. Die Bevölkerungsgröße im Laufe der Jahre ist ein gutes Beispiel für einen Datensatz, bei dem einige Merkmale ein exponentielles Wachstum aufweisen. Die Normalisierung der Log-Skalierung kann diese Merkmale für die Modellierung besser geeignet machen.
Eine robuste Skalierungsnormalisierung ist nützlich, wenn du mit Datensätzen arbeitest, die Ausreißer enthalten. Es verwendet den Median und den Interquartilsbereich (IQR) anstelle von Mittelwert und Standardabweichung, um Ausreißer zu behandeln. Die Formel für robuste Skalierung lautet:
Xrobust = X - Median/ IQR
Da die robuste Skalierung unempfindlich gegen den Einfluss von Ausreißern ist, eignet sie sich für Datensätze mit schiefen oder anomalen Werten.
Wir haben über Normalisierung gesprochen und warum sie beim maschinellen Lernen nützlich ist. Obwohl die Normalisierung sehr wirkungsvoll ist, ist sie nicht ohne Herausforderungen. Von der Behandlung von Ausreißern bis hin zur Auswahl der am besten geeigneten Technik für deinen Datensatz ist es wichtig, diese Fragen zu klären, um das volle Potenzial deines maschinellen Lernmodells auszuschöpfen.
Ausreißer sind Datenpunkte in deinem Datensatz, die erheblich von der Norm abweichen und die Wirksamkeit von Normalisierungsverfahren verzerren. Wenn du Ausreißer in deinen Daten nicht berücksichtigst, können diese zu schiefen Transformationen führen. Du kannst mit der robusten Skalierungsnormalisierungstechnik arbeiten, die wir bereits besprochen haben, um Ausreißer zu behandeln.
Eine andere Strategie ist das Trimmen oder Winsorisieren, bei dem wir alle Merkmalswerte, die über (oder unter) einem bestimmten Wert liegen, identifizieren und entweder abschneiden oder auf einen festen Wert begrenzen.
Wir haben die nützlichsten Normalisierungstechniken besprochen, aber es gibt noch viele weitere, aus denen du wählen kannst. Die Auswahl der geeigneten Technik erfordert ein differenziertes Verständnis des Datensatzes. Bei der Datenvorverarbeitung musst du mehrere Normalisierungstechniken ausprobieren und ihre Auswirkungen auf die Modellleistung bewerten. Durch das Experimentieren kannst du beobachten, wie die einzelnen Methoden den Lernprozess beeinflussen.
Du musst ein tiefes Verständnis für die Eigenschaften der Daten entwickeln. Überlege, ob die Annahmen einer bestimmten Normalisierungstechnik mit der Verteilung und den Mustern im Datensatz übereinstimmen.
Die Normalisierung kann eine Herausforderung sein, wenn es um spärliche Daten geht, bei denen viele Merkmalswerte Null sind. Die direkte Anwendung von Standardnormalisierungsverfahren kann zu unbeabsichtigten Konsequenzen führen. Es gibt Versionen der oben beschriebenen Normalisierungstechniken, die speziell für spärliche Daten entwickelt wurden, wie z.B. die "sparse min-max scaling".
Bevor du die Normalisierung vornimmst, solltest du überlegen, ob du fehlende Werte in deinem Datensatz imputierst oder behandelst. Dies ist oft einer der ersten Schritte, wenn du deinen Datensatz untersuchst und ihn für die Verwendung in maschinellen Lernmodellen bereinigst.
Im DataCamp-Kurs "Feature Engineering for Machine Learning" erfährst du, wie du Daten für deine eigenen Machine Learning-Modelle vorbereiten kannst. In diesem Kurs arbeitest du mit einer Stack Overflow-Entwicklerumfrage und historischen Adressen der Amtseinführung des US-Präsidenten, um zu verstehen, wie man kategoriale, kontinuierliche und unstrukturierte Daten am besten vorverarbeitet und Merkmale entwickelt.
Beim maschinellen Lernen kommt es zu einer Überanpassung, wenn ein Modell nicht nur die zugrunde liegenden Muster in den Trainingsdaten lernt, sondern auch Rauschen und zufällige Schwankungen erfasst. Das kann zu einem Modell führen, das in den Trainingsdaten außergewöhnlich gut abschneidet, aber nicht auf neue, ungesehene Daten generalisiert werden kann.
Die Normalisierung allein muss keine Überanpassung verursachen. Wenn die Normalisierung jedoch mit anderen Faktoren wie der Komplexität des Modells oder einer unzureichenden Regularisierung kombiniert wird, kann sie zu einer Überanpassung beitragen. Wenn die Normalisierungsparameter anhand des gesamten Datensatzes (einschließlich der Validierungs- oder Testdatensätze) berechnet werden, kann dies zu Datenverlusten führen. Das Modell könnte versehentlich Informationen aus den Validierungs- oder Testdatensätzen lernen, was seine Fähigkeit zur Verallgemeinerung beeinträchtigt.
Um das Risiko einer Überanpassung zu minimieren, solltest du die Trainingsmenge normalisieren und dieselben Normalisierungsparameter auf die Validierungs- und Testmengen anwenden. Dadurch wird sichergestellt, dass das Modell lernt, aus den Trainingsdaten zu verallgemeinern, ohne von den Informationen in den Validierungs- oder Testdaten beeinflusst zu werden.
Du musst geeignete Regularisierungsverfahren einsetzen, um zu komplexe Modelle zu bestrafen. Die Regularisierung hilft zu verhindern, dass sich das Modell dem Rauschen in den Trainingsdaten anpasst. Verwende geeignete Validierungstechniken, wie z.B. die Kreuzvalidierung, um die Leistung des Modells bei ungesehenen Daten zu bewerten. Wenn bei der Validierung eine Überanpassung festgestellt wird, können Anpassungen vorgenommen werden, z. B. eine Reduzierung der Modellkomplexität oder eine Erhöhung der Regularisierung.
Scikit-learn ist eine vielseitige Python-Bibliothek, die entwickelt wurde, um die Feinheiten des maschinellen Lernens zu vereinfachen. Es bietet eine Vielzahl von Werkzeugen und Funktionen für die Datenvorverarbeitung, die Merkmalsauswahl, die Dimensionalitätsreduktion, den Aufbau und das Training von Modellen, die Modellbewertung, die Abstimmung von Hyperparametern, die Modellserialisierung, den Aufbau von Pipelines usw. Der modulare Aufbau fördert das Experimentieren und Erforschen und ermöglicht es den Nutzern, nahtlos von grundlegenden Konzepten zu fortgeschrittenen Methoden überzugehen.
Wir werden scikit-learn verwenden, um das Gelernte in die Praxis umzusetzen. Wir werden den klassischen und weit verbreiteten "Iris-Datensatz" verwenden, der 1936 von dem britischen Biologen und Statistiker Ronald A. Fisher eingeführt wurde. Der Iris-Datensatz umfasst Messungen von vier Merkmalen von drei verschiedenen Irisarten: setosa, versicolor und virginica.
Für jede Blüte werden vier Merkmale gemessen: Kelchblattlänge, Kelchblattbreite, Blütenblattlänge und Blütenblattbreite - alle in Zentimetern. Der Datensatz besteht aus 150 Instanzen (Proben), wobei 50 Proben von jeder der drei Arten stammen. Der Iris-Datensatz wird normalerweise für Klassifizierungsaufgaben verwendet, bei denen es darum geht, die richtige Art unter den drei Klassen vorherzusagen. Heute werden wir diesen Datensatz jedoch nutzen, um zu zeigen, wie sich die Daten durch die Anwendung von Normalisierung (Min-Max-Skalierung) und Standardisierung verändern.
Du kannst den unten beschriebenen Python-Code im Arbeitsbereich von DataCamp ausführen, um den Datensatz selbst zu untersuchen.
Beginnen wir mit dem Importieren der Bibliotheken, die wir brauchen....
import numpy as np
import pandas as pd
# To import the dataset
from sklearn.datasets import load_iris
# To be used for splitting the dataset into training and test sets
from sklearn.model_selection import train_test_split
# To be used for min-max normalization
from sklearn.preprocessing import MinMaxScaler
# To be used for Z-normalization (standardization)
from sklearn.preprocessing import StandardScaler
# Load the iris dataset from Scikit-learn package
iris = load_iris()
# This prints a summary of the characteristics, statistics of the dataset
print(iris.DESCR)
# Divide the data into features (X) and target (Y)
# Data is converted to a panda’s dataframe
X = pd.DataFrame(iris.data)
# Separate the target attribute from rest of the data columns
Y = iris.target
# Take a look at the dataframe
X.head()
# This prints the shape of the dataframe (150 rows and 4 columns)
X.shape()
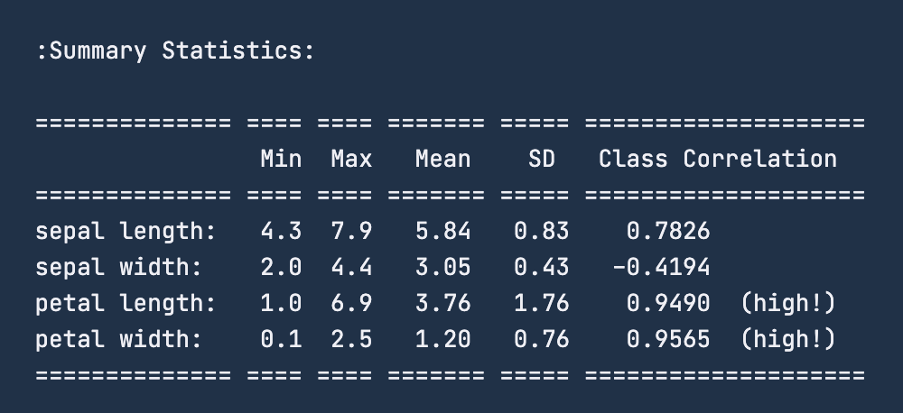
Wenn du dir die zusammenfassenden Statistiken für die Daten mit print(iris.DESCR) ansiehst, erhältst du die folgende Abbildung. Für das Merkmal "Kelchblattlänge" liegt die Spanne bei 4,3 - 7,9 Zentimetern. Ähnlich verhält es sich mit der "Kelchblattbreite": Sie liegt zwischen 2 und 4,4 Zentimetern. Bei der "Blütenblattlänge" liegt die Spanne zwischen 1 und 6,9 Zentimetern und bei der "Blütenblattbreite" zwischen 0,1 und 2,5 Zentimetern.
Bevor wir die Normalisierung anwenden, ist es sinnvoll, den Datensatz in einen Trainings- und einen Testdatensatz zu unterteilen. Dazu nutzen wir die Funktion train_test_split von sklearn.model_selection. Wir erstellen kein Validierungsset, da wir in dieser Übung keine eigentliche Modellierung durch maschinelles Lernen durchführen werden. Wir teilen den Datensatz im Verhältnis 80:20 auf, d.h. der Trainingssatz besteht aus 120 Zeilen und der Test aus den restlichen 30 Datenpunkten.
# To divide the dataset into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, Y ,test_size=0.2)Ein üblicher Schritt nach dem Laden der Daten und der Aufteilung der Daten in einen Trainings- und einen Testsatz ist die Datenbereinigung, die Datenkalkulation, um fehlende Werte zu behandeln und um Datenausreißer zu behandeln. Da der Schwerpunkt dieses Artikels jedoch auf der Normalisierung liegt, überspringen wir diese Vorverarbeitungsschritte und sehen uns die Normalisierung in Aktion an.
Wir werden diese Daten nun so umwandeln, dass sie in den Bereich von 0 - 1 Zentimeter fallen, indem wir die Min-Max-Normalisierungstechnik anwenden. Um die Daten zu normalisieren, verwenden wir die Funktion MinMaxScaler aus der Sklearn-Bibliothek und wenden sie auf unseren Datensatz an; die erforderlichen Bibliotheken haben wir bereits zuvor importiert.
# Good practice to keep original dataframes untouched for reusability
X_train_n = X_train.copy()
X_test_n = X_test.copy()
# Fit min-max scaler on training data
norm = MinMaxScaler().fit(X_train_n)
# Transform the training data
X_train_norm = norm.transform(X_train_n)
# Use the same scaler to transform the testing set
X_test_norm = norm.transform(X_test_n)Wir können die Trainingsdaten ausdrucken, um zu sehen, wie sie sich verändert haben. Konvertieren wir die Menge jedoch in einen Pandas DataFrame und überprüfen dann ihre statistische Beschreibung mit der Funktion describe().
X_train_norm_df = pd.DataFrame(X_train_norm)
# Assigning original feature names for ease of read
X_train_norm_df.columns = iris.feature_names
X_train_norm_df.describe()
Daraus ergibt sich das folgende Ergebnis für die Normalisierung:
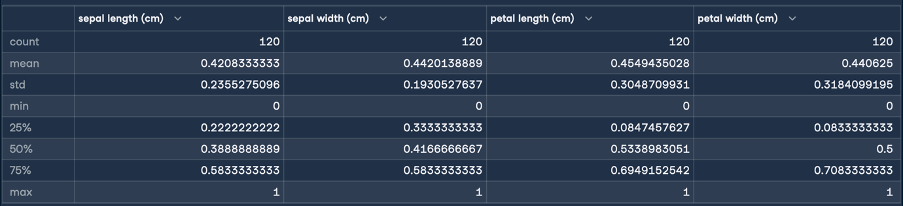
Hier zeigen die Min- und Max-Statistiken, dass die Bereiche der Merkmale alle in einen Bereich von 0 - 1 Zentimeter umgewandelt wurden. Das ist die Verwandlung, die wir angestrebt haben! Wir führen nun eine Standardisierung (Z-Score-Normalisierung) durch, indem wir die gleichen Schritte wie bei der Normalisierung durchführen:
X_train_s = X_train.copy()
X_test_s = X_test.copy()
# Fit the standardization scaler onto the training data
stan = StandardScaler().fit(X_train_s)
# Transform the training data
X_train_stan = stan.transform(X_train_s)
# Use the same scaler to transform the testing set
X_test_stan = stan.transform(X_test_s)
# Convert the transformed data into pandas dataframe
X_train_stan_df = pd.DataFrame(X_train_stan)
# Assigning original feature names for ease of read
X_train_stan_df.columns = iris.feature_names
# Check out the statistical description
X_train_stan_df.describe()
Daraus ergibt sich das folgende Ergebnis für die Normung:
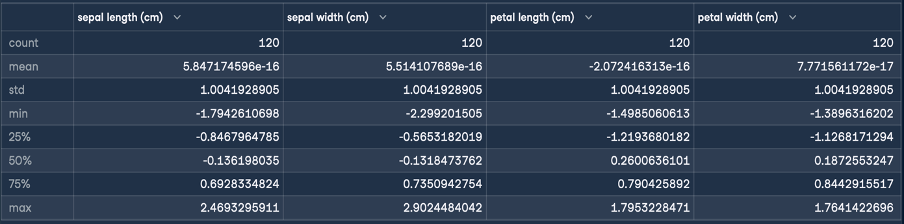
Das Ziel der Z-Normalisierung ist es, die Werte eines Merkmals so zu transformieren, dass sie einen Mittelwert von 0 und eine Standardabweichung von 1 haben. Wie du aus der Beschreibung des erstellten DataFrames ersehen kannst, ist der Mittelwert für alle vier Merkmale eine kleine Zahl nahe Null und die Standardabweichung beträgt 1.
Diese umgewandelten Daten können wir nun einem Algorithmus für maschinelles Lernen zum Training vorlegen.
In diesem Artikel haben wir uns mit der Min-Max-Skalierung, der Z-Normalisierung, der Dezimalskalierung und der Log-Skalierungsnormalisierung beschäftigt. Jede Technik hat ihre eigenen Stärken und ihren eigenen Nutzen. Du hast auch über einige der häufigsten Fallstricke und Best Practices bei der Normalisierung gelesen. Zum Schluss haben wir das neu erworbene Wissen mit scikit learn in die Praxis umgesetzt.
Wenn du mehr über die Konzepte und Prozesse erfahren möchtest, die wir behandelt haben, schau dir unsere Kurse Feature Engineering for Machine Learning in Python und Textacy an: Eine Einführung in die Textdatenbereinigung und -normalisierung in Python.
Lerne Maschinelles Lernen!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
