
Curso
Aprendizado de máquina com modelos baseados em árvores em Python
5 h
116.4K
No aprendizado de máquina, a base para modelos bem-sucedidos é construída sobre a qualidade dos dados nos quais eles são treinados. Embora os holofotes geralmente se voltem para algoritmos e modelos complexos e sofisticados, o herói não celebrado costuma ser o pré-processamento de dados. O pré-processamento de dados é uma etapa importante que transforma os dados brutos em recursos que são usados para o aprendizado de máquina eficaz.
Os algoritmos de aprendizado de máquina geralmente são treinados com a suposição de que todos os recursos contribuem igualmente para a previsão final. No entanto, essa suposição falha quando os recursos diferem em alcance e unidade, afetando, portanto, sua importância.
Entre na normalização - uma etapa vital no pré-processamento de dados que garante a uniformidade das magnitudes numéricas dos recursos. Essa uniformidade evita o domínio de recursos que têm valores maiores em comparação com outros recursos ou variáveis.
Neste artigo, vamos nos aprofundar na normalização, uma técnica de dimensionamento de recursos que oferece um caminho para equilibrar as escalas dos recursos.
A normalização é uma forma específica de dimensionamento de recursos que transforma o intervalo de recursos em uma escala padrão. A normalização e, nesse caso, qualquer técnica de dimensionamento de dados é necessária somente quando o conjunto de dados tem recursos de intervalos variados. A normalização abrange diversas técnicas adaptadas a diferentes distribuições de dados e requisitos de modelos.
A normalização não se limita apenas a dados numéricos. No entanto, neste artigo, vamos nos concentrar em exemplos numéricos. Não deixe de conferir o Textacy da Datacamp: Uma introdução à limpeza e normalização de dados de texto no tutorial Python se você estiver planejando realizar o pré-processamento de dados de texto para aprendizado de máquina.
Os dados normalizados aprimoram o desempenho do modelo e melhoram a precisão de um modelo. Ele ajuda os algoritmos que dependem de métricas de distância, como os vizinhos mais próximos ou as máquinas de vetor de suporte, evitando que os recursos com escalas maiores dominem o processo de aprendizado.
A normalização estimula a estabilidade no processo de otimização, promovendo uma convergência mais rápida durante o treinamento baseado em gradiente. Ele atenua os problemas relacionados ao desaparecimento ou à explosão de gradientes, permitindo que os modelos alcancem soluções ideais com mais eficiência.
Os dados normalizados também são fáceis de interpretar e, portanto, mais fáceis de entender. Quando todos os recursos de um conjunto de dados estão na mesma escala, também fica mais fácil identificar e visualizar as relações entre os diferentes recursos e fazer comparações significativas.
Vamos dar um exemplo simples para destacar a importância da normalização dos dados. Estamos tentando prever os preços das moradias com base em vários recursos, como metragem quadrada, número de quartos, distância do supermercado etc. O conjunto de dados contém diversos recursos com escalas variadas, como:
Quando você alimenta esses dados sem nenhum pré-processamento diretamente em um modelo de aprendizado de máquina, o algoritmo pode dar mais peso a recursos com escalas grandes, como metragem quadrada. Durante o treinamento, o algoritmo pressupõe que uma alteração na metragem quadrada total terá um impacto significativo nos preços das moradias. O algoritmo pode ignorar as nuances de recursos que são relativamente pequenos, como o número de quartos e a distância até o supermercado. Essa ênfase distorcida pode levar a um desempenho abaixo do ideal do modelo e a previsões tendenciosas.
Ao normalizar os recursos, podemos garantir que cada recurso contribua proporcionalmente para o processo de aprendizado do modelo. Agora, o modelo pode aprender padrões em todos os recursos com mais eficiência, o que leva a uma representação mais precisa das relações subjacentes nos dados.
O escalonamento Min-Max e a normalização (padronização) do escore Z são as duas técnicas fundamentais para a normalização. Além disso, também discutiremos a normalização da escala decimal, a normalização da escala logarítmica e a escala robusta, que abordam desafios exclusivos no pré-processamento de dados.
O escalonamento mínimo-máximo é muitas vezes chamado simplesmente de "normalização". Ele transforma os recursos em um intervalo especificado, normalmente entre 0 e 1. A fórmula para o escalonamento mínimo-máximo é:
Xnormalizado = X - Xmin / Xmax - Xmin
Onde X é um valor de recurso aleatório que deve ser normalizado. Xmin é o valor mínimo do recurso no conjunto de dados, e Xmax é o valor máximo do recurso.
O escalonamento mínimo-máximo é uma boa escolha quando você:
A normalização (padronização) do escore Z pressupõe uma distribuição gaussiana (curva de sino) dos dados e transforma os recursos para que tenham uma média (μ) de 0 e um desvio padrão (σ) de 1. A fórmula para a padronização é:
X padronizado = X-μ / σ
Essa técnica é particularmente útil ao lidar com algoritmos que pressupõem dados normalmente distribuídos, como muitos modelos lineares. Ao contrário da técnica de dimensionamento mínimo-máximo, os valores dos recursos não estão restritos a um intervalo específico na técnica de padronização. Essa técnica de normalização basicamente representa os recursos em termos do número de desvios padrão que se afastam da média.
Antes de nos aprofundarmos em outras técnicas de transformação de dados, vamos fazer uma comparação entre normalização (escalonamento mínimo-máximo) e padronização.
|
Normalização |
Padronização |
|
O objetivo é colocar os valores de um recurso em um intervalo específico, geralmente entre 0 e 1 |
O objetivo é transformar os valores de um recurso para que tenham uma média de 0 e um desvio padrão de 1 |
|
Sensível a valores discrepantes e ao intervalo dos dados |
Menos sensível a discrepâncias devido ao uso da média e do desvio padrão |
|
Útil quando é essencial manter a faixa original |
Eficaz quando os algoritmos assumem uma distribuição normal padrão |
|
Nenhuma suposição sobre a distribuição de dados é feita |
Pressupõe uma distribuição normal ou uma aproximação próxima |
|
Adequado para algoritmos em que os valores absolutos e suas relações são importantes (por exemplo, k-nearest neighbors, redes neurais) |
Particularmente útil para algoritmos que pressupõem dados normalmente distribuídos, como regressão linear e máquinas de vetor de suporte |
|
Mantém a interpretabilidade dos valores originais dentro do intervalo especificado |
Altera os valores originais, tornando a interpretação mais desafiadora devido à mudança na escala e nas unidades |
|
Pode levar a uma convergência mais rápida, especialmente em algoritmos que dependem de descida de gradiente |
Também contribui para uma convergência mais rápida, especialmente em algoritmos sensíveis à escala dos recursos de entrada |
|
Casos de uso: Processamento de imagens, redes neurais, algoritmos sensíveis a escalas de recursos |
Casos de uso: Regressão linear, máquinas de vetores de suporte, algoritmos que pressupõem distribuição normal |
O objetivo da normalização da escala decimal é dimensionar os valores dos recursos por uma potência de 10, garantindo que o maior valor absoluto em cada recurso seja menor que 1. É útil quando o intervalo de valores em um conjunto de dados é conhecido, mas o intervalo varia entre os recursos. A fórmula para a normalização da escala decimal é:
Xdecimal = X / 10d
Em que X é o valor original do recurso e d é o menor número inteiro para que o maior valor absoluto do recurso seja menor que 1.
Por exemplo, se o maior valor absoluto em um recurso for 3500, então d seria 3 e o recurso seria dimensionado em103.
A normalização da escala decimal é vantajosa ao lidar com conjuntos de dados em que a magnitude absoluta dos valores é mais importante do que sua escala específica.
A normalização de escala logarítmica converte os dados em uma escala logarítmica, tomando o logaritmo de cada ponto de dados. É particularmente útil ao lidar com dados que abrangem várias ordens de magnitude. A fórmula para a normalização da escala logarítmica é:
Xlog = log(X)
Essa normalização é útil com dados que seguem um padrão de crescimento ou decaimento exponencial. Ele comprime a escala do conjunto de dados, facilitando a captura de padrões e relacionamentos nos dados pelos modelos. O tamanho da população ao longo dos anos é um bom exemplo de um conjunto de dados em que alguns recursos apresentam crescimento exponencial. A normalização da escala de logs pode tornar esses recursos mais fáceis de modelar.
A normalização de escala robusta é útil quando você trabalha com conjuntos de dados com valores discrepantes. Ele usa a mediana e o intervalo interquartil (IQR) em vez da média e do desvio padrão para lidar com exceções. A fórmula para o dimensionamento robusto é:
Xrobusto = X - mediana/ IQR
Como o escalonamento robusto é resistente à influência de discrepâncias, ele é adequado para conjuntos de dados com valores distorcidos ou anômalos.
Discutimos a normalização e por que ela é útil no aprendizado de máquina. Embora poderosa, a normalização tem seus desafios. Desde o tratamento de outliers até a seleção da técnica mais adequada com base no conjunto de dados, é essencial abordar esses problemas para liberar todo o potencial do seu modelo de aprendizado de máquina.
Os outliers são pontos de dados em seu conjunto de dados que se desviam significativamente da norma e distorcem a eficácia das técnicas de normalização. Se você não tratar os valores discrepantes nos dados, eles podem levar a transformações distorcidas. Você pode trabalhar com a técnica de normalização de escala robusta que discutimos anteriormente para lidar com outliers.
Outra estratégia é aplicar o corte ou a winsorização, em que identificamos e cortamos ou limitamos todos os valores de recursos acima (ou abaixo) de um determinado valor para um valor fixo.
Discutimos as técnicas de normalização mais úteis, mas há muitas outras para você escolher. A seleção da técnica adequada requer uma compreensão diferenciada do conjunto de dados. No pré-processamento de dados, você precisa experimentar várias técnicas de normalização e avaliar o impacto delas no desempenho do modelo. A experimentação permite que você observe como cada método influencia o processo de aprendizagem.
Você precisa obter um entendimento profundo das características dos dados. Considere se as suposições de uma técnica de normalização específica estão alinhadas com a distribuição e os padrões presentes no conjunto de dados.
A normalização pode ser desafiadora ao lidar com dados esparsos em que muitos valores de recursos são zero. A aplicação direta de técnicas de normalização padrão pode levar a consequências indesejadas. Há versões das técnicas de normalização que discutimos acima que foram projetadas especificamente para dados esparsos, como "sparse min-max scaling".
Antes da normalização, considere a possibilidade de imputar ou lidar com valores ausentes em seu conjunto de dados. Essa costuma ser uma das primeiras etapas quando você está explorando seu conjunto de dados e limpando-o para uso em modelos de aprendizado de máquina.
Não deixe de conferir o curso Engenharia de recursos para aprendizado de máquina do DataCamp, que oferece a você experiência prática sobre como preparar quaisquer dados para seus próprios modelos de aprendizado de máquina. No curso, você trabalhará com a pesquisa de desenvolvedores do Stack Overflow e com endereços históricos da posse presidencial dos EUA para entender a melhor forma de pré-processar e projetar recursos de dados categóricos, contínuos e não estruturados.
No aprendizado de máquina, o overfitting ocorre quando um modelo aprende não apenas os padrões subjacentes nos dados de treinamento, mas também capta ruídos e flutuações aleatórias. Isso pode levar a um modelo com desempenho excepcional nos dados de treinamento, mas que não consegue generalizar para dados novos e não vistos.
A normalização por si só pode não causar ajuste excessivo. No entanto, quando a normalização é combinada com outros fatores, como a complexidade do modelo ou a regularização insuficiente, ela pode contribuir para o ajuste excessivo. Quando os parâmetros de normalização são calculados usando todo o conjunto de dados (incluindo conjuntos de validação ou teste), isso pode levar ao vazamento de dados. O modelo pode aprender inadvertidamente informações dos conjuntos de validação ou teste, comprometendo sua capacidade de generalização.
Assim, para reduzir o risco de ajuste excessivo, normalize o conjunto de treinamento e aplique os mesmos parâmetros de normalização aos conjuntos de validação e teste. Isso garante que o modelo aprenda a generalizar a partir dos dados de treinamento sem ser influenciado pelas informações dos conjuntos de validação ou teste.
Você precisa implementar técnicas de regularização adequadas para penalizar modelos excessivamente complexos. A regularização ajuda a evitar que o modelo se ajuste ao ruído nos dados de treinamento. Use técnicas de validação adequadas, como a validação cruzada, para avaliar o desempenho do modelo em dados não vistos. Se for detectado um excesso de ajuste durante a validação, poderão ser feitos ajustes, como a redução da complexidade do modelo ou o aumento da regularização.
O Scikit-learn é uma biblioteca Python versátil projetada para simplificar as complexidades do aprendizado de máquina. Ele oferece um rico conjunto de ferramentas e funcionalidades para pré-processamento de dados, seleção de recursos, redução de dimensionalidade, construção e treinamento de modelos, avaliação de modelos, ajuste de hiperparâmetros, serialização de modelos, construção de pipeline etc. Seu design modular incentiva a experimentação e a exploração, permitindo que os usuários façam uma transição perfeita de conceitos fundamentais para metodologias avançadas.
Usaremos o scikit-learn para colocar em prática o que aprendemos. Usaremos o conjunto de dados clássico e amplamente utilizado `Iris`. Esse conjunto de dados foi introduzido pelo biólogo e estatístico britânico Ronald A. Fisher em 1936. O conjunto de dados Iris inclui medições de quatro recursos de três espécies diferentes de flores de íris: setosa, versicolor e virginica.
Há quatro características medidas para cada flor: o comprimento da sépala, a largura da sépala, o comprimento da pétala e a largura da pétala, todos em centímetros. Há 150 instâncias (amostras) no conjunto de dados, com 50 amostras de cada uma das três espécies. O conjunto de dados Iris é normalmente usado para tarefas de classificação, em que o objetivo é prever a espécie correta entre as três classes. No entanto, hoje, usaremos esse conjunto de dados para mostrar a transformação dos dados ao aplicar a normalização (escala mín-máx) e a padronização.
Você pode executar o código Python discutido abaixo no espaço de trabalho do Datacamp para explorar o conjunto de dados por conta própria.
Vamos começar importando as bibliotecas de que precisamos....
import numpy as np
import pandas as pd
# To import the dataset
from sklearn.datasets import load_iris
# To be used for splitting the dataset into training and test sets
from sklearn.model_selection import train_test_split
# To be used for min-max normalization
from sklearn.preprocessing import MinMaxScaler
# To be used for Z-normalization (standardization)
from sklearn.preprocessing import StandardScaler
# Load the iris dataset from Scikit-learn package
iris = load_iris()
# This prints a summary of the characteristics, statistics of the dataset
print(iris.DESCR)
# Divide the data into features (X) and target (Y)
# Data is converted to a panda’s dataframe
X = pd.DataFrame(iris.data)
# Separate the target attribute from rest of the data columns
Y = iris.target
# Take a look at the dataframe
X.head()
# This prints the shape of the dataframe (150 rows and 4 columns)
X.shape()
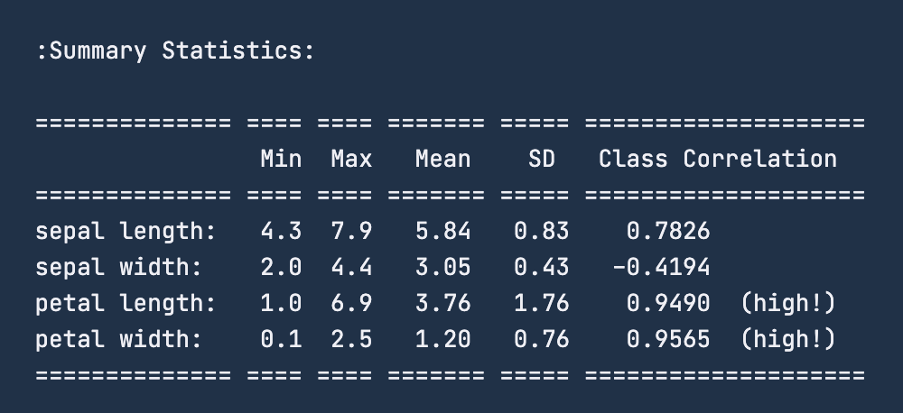
Quando você verifica as estatísticas resumidas dos dados usando print(iris.DESCR), a imagem abaixo é o resumo que você receberá. Para o recurso "comprimento da sépala", o intervalo é de 4,3 a 7,9 centímetros. Da mesma forma, para a "largura da sépala", o intervalo é de 2 a 4,4 centímetros. Para o "comprimento da pétala", o intervalo é de 1 a 6,9 centímetros e, finalmente, para a "largura da pétala", o intervalo é de 0,1 a 2,5 centímetros.
Antes de aplicarmos a normalização, é uma boa prática dividir o conjunto de dados em conjuntos de treinamento e de teste. Para isso, usaremos a funcionalidade train_test_split do site sklearn.model_selection. Não estamos criando um conjunto de validação, pois não realizaremos modelagem real de aprendizado de máquina neste exercício. Faremos uma divisão 80-20 do conjunto de dados, o que significa que o conjunto de treinamento terá 120 linhas e o teste terá os 30 pontos de dados restantes.
# To divide the dataset into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, Y ,test_size=0.2)Uma etapa comum depois de carregar os dados e dividi-los em um conjunto de treinamento e teste é realizar a limpeza dos dados, a imputação de dados para lidar com valores ausentes e lidar com dados discrepantes. No entanto, como o foco do artigo é a normalização, pularemos essas etapas de pré-processamento e começaremos a ver a normalização em ação.
Agora, transformaremos esses dados para que se enquadrem no intervalo de 0 a 1 centímetro usando a técnica de normalização min-max. Para normalizar os dados, usaremos a funcionalidade MinMaxScaler da biblioteca sklearn e a aplicaremos ao nosso conjunto de dados; já importamos as bibliotecas necessárias anteriormente.
# Good practice to keep original dataframes untouched for reusability
X_train_n = X_train.copy()
X_test_n = X_test.copy()
# Fit min-max scaler on training data
norm = MinMaxScaler().fit(X_train_n)
# Transform the training data
X_train_norm = norm.transform(X_train_n)
# Use the same scaler to transform the testing set
X_test_norm = norm.transform(X_test_n)Podemos imprimir os dados de treinamento para ver a transformação que ocorreu. No entanto, vamos converter o conjunto em um dataframe do pandas e, em seguida, verificar sua descrição estatística usando a funcionalidade describe().
X_train_norm_df = pd.DataFrame(X_train_norm)
# Assigning original feature names for ease of read
X_train_norm_df.columns = iris.feature_names
X_train_norm_df.describe()
Isso dará o seguinte resultado para a normalização:
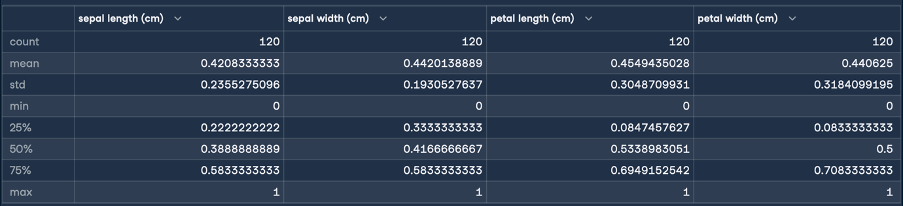
Aqui, as estatísticas de mínimo e máximo indicam que os intervalos dos recursos foram todos transformados em um intervalo de 0 a 1 centímetro. Essa é a transformação que estávamos buscando! Agora, realizaremos a padronização (normalização do escore Z) seguindo as mesmas etapas que fizemos para a normalização:
X_train_s = X_train.copy()
X_test_s = X_test.copy()
# Fit the standardization scaler onto the training data
stan = StandardScaler().fit(X_train_s)
# Transform the training data
X_train_stan = stan.transform(X_train_s)
# Use the same scaler to transform the testing set
X_test_stan = stan.transform(X_test_s)
# Convert the transformed data into pandas dataframe
X_train_stan_df = pd.DataFrame(X_train_stan)
# Assigning original feature names for ease of read
X_train_stan_df.columns = iris.feature_names
# Check out the statistical description
X_train_stan_df.describe()
Isso dará o seguinte resultado para a padronização:
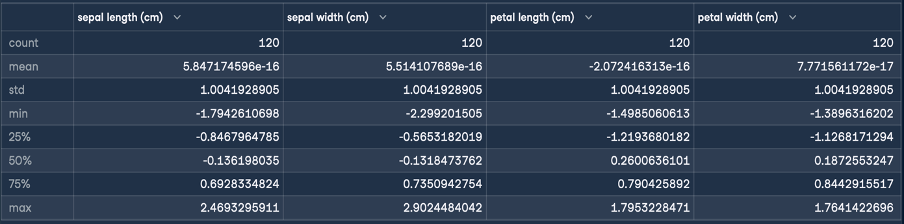
O objetivo da normalização Z é transformar os valores de um recurso para que tenham uma média de 0 e um desvio padrão de 1. Como você pode ver na descrição do dataframe que foi gerado, a média de todos os quatro recursos é um número pequeno, próximo de zero, e o desvio padrão é 1.
Agora podemos pegar esses dados transformados e alimentá-los com um algoritmo de aprendizado de máquina para treinamento.
Neste artigo, você verá as normalizações de escalonamento mínimo-máximo, normalização Z, escalonamento decimal e escalonamento logarítmico. Cada técnica revelou seus pontos fortes e sua utilidade exclusivos. Você também leu sobre algumas das armadilhas comuns e práticas recomendadas ao realizar a normalização. Por fim, concluímos aplicando parte desse conhecimento recém-adquirido com o scikit learn.
Para saber mais sobre os conceitos e processos que abordamos, confira nossos cursos sobre Engenharia de recursos para aprendizado de máquina em Python e Textacy: Uma introdução à limpeza e normalização de dados de texto em Python.
Aprenda aprendizado de máquina!
Curso
Curso
Curso
blog
Abid Ali Awan
7 min
blog
Yolanda Ferreiro
7 min
blog
Matt Crabtree
11 min
blog
Abid Ali Awan
11 min
blog
Matt Crabtree
14 min
Tutorial
Amberle McKee



