Kurs
Einführung in Datenbanken mit Python
4 Std.
101.3K

SQLAlchemy ist das Python SQL Toolkit, mit dem Entwickler auf SQL-Datenbanken zugreifen und diese verwalten können. Du kannst eine Abfrage in Form eines Strings schreiben oder Python-Objekte für ähnliche Abfragen verketten. Die Arbeit mit Objekten bietet Entwicklern Flexibilität und ermöglicht es ihnen, leistungsstarke SQL-basierte Anwendungen zu erstellen.
Mit einfachen Worten: Es ermöglicht den Nutzern, Datenbanken mit Python zu verbinden, SQL-Abfragen mit objektbasierter Programmierung auszuführen und den Arbeitsablauf zu optimieren.
Es ist ziemlich einfach, das Paket zu installieren und mit dem Programmieren zu beginnen.
Du kannst SQLAlchemy mit dem Python Package Manager (pip) installieren:
pip install sqlalchemyFalls du die Anaconda-Distribution von Python verwendest, versuche, den Befehl im conda-Terminal einzugeben:
conda install -c anaconda sqlalchemyLass uns überprüfen, ob das Paket erfolgreich installiert wurde:
>>> import sqlalchemy
>>> sqlalchemy.__version__
'1.4.41'Ausgezeichnet, wir haben SQLAlchemy Version 1.4.41 erfolgreich installiert.
In diesem Abschnitt lernen wir, SQLite-Datenbanken zu verbinden, Tabellenobjekte zu erstellen und sie zur Ausführung der SQL-Abfrage zu verwenden.
Wir werden die SQLite-Datenbank European Football von Kaggle verwenden, die zwei Tabellen enthält: Divisionen und Matches.
Zuerst erstellen wir SQLite-Engine-Objekte mit "create_object" und übergeben die Adresse der Datenbank. Dann erstellen wir ein Verbindungsobjekt, indem wir die Engine verbinden. Wir werden das Objekt "conn" verwenden, um alle Arten von SQL-Abfragen auszuführen.
from sqlalchemy as db
engine = db.create_engine("sqlite:///european_database.sqlite")
conn = engine.connect() Wenn du PostgreSQL-, MySQL-, Oracle- und Microsoft SQL Server-Datenbanken anbinden möchtest, solltest du die Engine-Konfiguration für eine reibungslose Verbindung mit dem Server überprüfen.
Dieses SQLAlchemy-Tutorial setzt voraus, dass du die Grundlagen von Python und SQL verstehst. Wenn nicht, dann ist es völlig in Ordnung. Du kannst die Skill-Tracks SQL Fundamentals und Python Fundamentals belegen, um eine solide Grundlage zu schaffen.
Um ein Tabellenobjekt zu erstellen, müssen wir Tabellennamen und Metadaten angeben. Du kannst Metadaten mit der Funktion `MetaData()` von SQLAlchemy erzeugen.
metadata = db.MetaData() #extracting the metadata
division= db.Table('divisions', metadata, autoload=True,
autoload_with=engine) #Table objectLass uns die Metadaten der "Abteilungen" drucken.
print(repr(metadata.tables['divisions']))Die Metadaten enthalten den Tabellennamen, die Spaltennamen mit dem Typ und das Schema.
Table('divisions', MetaData(), Column('division', TEXT(), table=<divisions>),
Column('name', TEXT(), table=<divisions>), Column('country', TEXT(),
table=<divisions>), schema=None)Verwenden wir das Tabellenobjekt "Division", um Spaltennamen zu drucken.
print(division.columns.keys())Die Tabelle besteht aus den Spalten Abteilung, Name und Land.
['division', 'name', 'country']Jetzt kommt der lustige Teil. Wir werden das Tabellenobjekt verwenden, um die Abfrage auszuführen und die Ergebnisse zu extrahieren.
Im folgenden Code wählen wir alle Spalten für die Tabelle "Division" aus.
query = division.select() #SELECT * FROM divisions
print(query)Hinweis: Du kannst den Select-Befehl auch als "db.select([division])" schreiben.
Um die Abfrage zu sehen, druckst du das Abfrageobjekt aus und es zeigt den SQL-Befehl an.
SELECT divisions.division, divisions.name, divisions.country
FROM divisionsJetzt führen wir die Abfrage über das Verbindungsobjekt aus und extrahieren die ersten fünf Zeilen.
exe = conn.execute(query) #executing the query
result = exe.fetchmany(5) #extracting top 5 results
print(result)Das Ergebnis zeigt die ersten fünf Zeilen der Tabelle.
[('B1', 'Division 1A', 'Belgium'), ('D1', 'Bundesliga', 'Deutschland'), ('D2', '2. Bundesliga', 'Deutschland'), ('E0', 'Premier League', 'England'), ('E1', 'EFL Championship', 'England')]In diesem Abschnitt werden wir uns verschiedene SQLAlchemy-Beispiele für das Erstellen von Tabellen, das Einfügen von Werten, das Ausführen von SQL-Abfragen, die Datenanalyse und die Tabellenverwaltung ansehen.
Du kannst mitmachen oder dir das DataLab-Arbeitsheft ansehen. Sie enthält eine Datenbank, den Quellcode und die Ergebnisse.
Zuerst erstellen wir eine neue Datenbank namens "datacamp.sqlite". Die create_engine erstellt automatisch eine neue Datenbank, wenn es noch keine Datenbank mit demselben Namen gibt. Erstellen und Verbinden sind also ziemlich ähnlich.
Danach verbinden wir die Datenbank und erstellen ein Metadaten-Objekt.
Wir werden die Tabellenfunktion von SQLAlchmy verwenden, um eine Tabelle mit dem Namen "Student" zu erstellen.
Sie besteht aus Spalten:
Wir haben die Struktur der Tabelle erstellt. Fügen wir sie mit `metadata.create_all(engine)` zur Datenbank hinzu.
engine = db.create_engine('sqlite:///datacamp.sqlite')
conn = engine.connect()
metadata = db.MetaData()
Student = db.Table('Student', metadata,
db.Column('Id', db.Integer(),primary_key=True),
db.Column('Name', db.String(255), nullable=False),
db.Column('Major', db.String(255), default="Math"),
db.Column('Pass', db.Boolean(), default=True)
)
metadata.create_all(engine) Um eine einzelne Zeile hinzuzufügen, verwenden wir zunächst `insert` und fügen das Tabellenobjekt hinzu. Danach verwendest du `values` und fügst den Spalten manuell Werte hinzu. Es funktioniert ähnlich wie das Hinzufügen von Argumenten zu Python-Funktionen.
Schließlich führen wir die Abfrage über die Verbindung aus, um die Funktion auszuführen.
query = db.insert(Student).values(Id=1, Name='Matthew', Major="English", Pass=True)
Result = conn.execute(query)Überprüfen wir, ob wir die Zeile zur Tabelle "Schüler" hinzufügen, indem wir eine Select-Abfrage ausführen und alle Zeilen abrufen.
output = conn.execute(Student.select()).fetchall()
print(output)Wir haben die Werte erfolgreich hinzugefügt.
[(1, 'Matthew', 'English', True)]Werte einzeln hinzuzufügen ist keine praktische Methode, um die Datenbank aufzufüllen. Lass uns mehrere Werte mithilfe von Listen hinzufügen.
query = db.insert(Student)
values_list = [{'Id':'2', 'Name':'Nisha', 'Major':"Science", 'Pass':False},
{'Id':'3', 'Name':'Natasha', 'Major':"Math", 'Pass':True},
{'Id':'4', 'Name':'Ben', 'Major':"English", 'Pass':False}]
Result = conn.execute(query,values_list)Um unsere Ergebnisse zu überprüfen, führen wir die einfache Select-Abfrage aus.
output = conn.execute(db.select([Student])).fetchall()
print(output)Die Tabelle enthält jetzt mehr Zeilen.
[(1, 'Matthew', 'English', True), (2, 'Nisha', 'Science', False), (3, 'Natasha', 'Math', True), (4, 'Ben', 'English', False)]Anstatt Python-Objekte zu verwenden, können wir auch SQL-Abfragen mit String ausführen.
Füge einfach das Argument als String zur Funktion "execute" hinzu und lass dir das Ergebnis mit "fetchall" anzeigen.
output = conn.execute("SELECT * FROM Student")
print(output.fetchall())Output:
[(1, 'Matthew', 'English', 1), (2, 'Nisha', 'Science', 0), (3, 'Natasha', 'Math', 1), (4, 'Ben', 'English', 0)]Du kannst sogar komplexere SQL-Abfragen übergeben. In unserem Fall wählen wir die Spalten Name und Hauptfach aus, in denen die Schüler die Prüfung bestanden haben.
output = conn.execute("SELECT Name, Major FROM Student WHERE Pass = True")
print(output.fetchall())Output:
[('Matthew', 'English'), ('Natasha', 'Math')]In den vorherigen Abschnitten haben wir einfache SQLAlchemy-API/Objekte verwendet. Kommen wir nun zu den komplexeren und mehrstufigen Abfragen.
Im folgenden Beispiel wählen wir alle Spalten aus, in denen das Hauptfach des Schülers Englisch ist.
query = Student.select().where(Student.columns.Major == 'English')
output = conn.execute(query)
print(output.fetchall())Output:
[(1, 'Matthew', 'English', True), (4, 'Ben', 'English', False)]Lass uns die AND-Logik auf die WHERE-Abfrage anwenden.
In unserem Fall suchen wir nach Schülern, die Englisch als Hauptfach haben und durchgefallen sind.
Hinweis: ungleich '!=' True ist False.
query = Student.select().where(db.and_(Student.columns.Major == 'English', Student.columns.Pass != True))
output = conn.execute(query)
print(output.fetchall())Nur Ben hat die Prüfung mit dem Hauptfach Englisch nicht bestanden.
[(4, 'Ben', 'English', False)]Mit einer ähnlichen Tabelle können wir alle möglichen Befehle ausführen, wie in der folgenden Tabelle gezeigt.
Du kannst diese Befehle kopieren und einfügen, um die Ergebnisse selbst zu testen. Schau in der DataLab-Arbeitsmappe nach, wenn du bei einem der angegebenen Befehle nicht weiterkommst.
|
Befehle |
API |
|
in |
Student.select().where(Student.columns.Major.in_(['Englisch','Mathe'])) |
|
und, oder, nicht |
Student.select().where(db.or_(Student.columns.Major == 'Englisch', Student.columns.Pass = True)) |
|
Bestellung durch |
Student.select().order_by(db.desc(Student.columns.Name)) |
|
Grenze |
Student.select().limit(3) |
|
sum, avg, count, min, max |
db.select([db.func.sum(Student.columns.Id)]) |
|
Gruppe von |
db.select([db.func.sum(Schüler.Spalten.Id),Schüler.Spalten.Major]).group_by(Schüler.Spalten.Pass) |
|
verschiedene |
db.select([Student.columns.Major.distinct()]) |
Weitere Funktionen und Befehle findest du in der offiziellen Dokumentation der SQL Statements and Expressions API.
Datenwissenschaftler/innen und Analytiker/innen schätzen Pandas Dataframes und würden gerne mit ihnen arbeiten. In diesem Teil werden wir lernen, wie man ein SQLAlchemy-Abfrageergebnis in einen Pandas-Dataframe umwandelt.
Führe zunächst die Abfrage aus und speichere die Ergebnisse.
query = Student.select().where(Student.columns.Major.in_(['English','Math']))
output = conn.execute(query)
results = output.fetchall()Verwende dann die DataFrame-Funktion und gib die SQL-Ergebnisse als Argument an. Schließlich fügst du die Spaltennamen hinzu, indem du die erste Zeile des Ergebnisses `results[0]` und `.keys()` verwendest.
Hinweis: Du kannst jede gültige Zeile angeben, um die Namen der Spalten mit `keys()` zu extrahieren.
data = pd.DataFrame(results)
data.columns = results[0].keys()
data
In diesem Teil werden wir die europäische Fußballdatenbank verbinden, komplexe Abfragen durchführen und die Ergebnisse visualisieren.
Wie üblich verbinden wir die Datenbank mit den Funktionen `create_engine` und `connect`.
In unserem Fall werden wir zwei Tabellen verbinden, also müssen wir zwei Tabellenobjekte erstellen: Division und Match.
engine = create_engine("sqlite:///european_database.sqlite")
conn = engine.connect()
metadata = db.MetaData()
division = db.Table('divisions', metadata, autoload=True, autoload_with=engine)
match = db.Table('matchs', metadata, autoload=True, autoload_with=engine)Du kannst sogar noch komplexere Abfragen erstellen, indem du zusätzliche Module hinzufügst.
Hinweis: Um zwei Tabellen automatisch zu verbinden, kannst du auch Folgendes verwenden: `db.select([division.columns.division,match.columns.Div])`
query = db.select([division,match]).\
select_from(division.join(match,division.columns.division == match.columns.Div)).\
where(db.and_(division.columns.division == "E1", match.columns.season == 2009 )).\
order_by(match.columns.HomeTeam)
output = conn.execute(query)
results = output.fetchall()
data = pd.DataFrame(results)
data.columns = results[0].keys()
data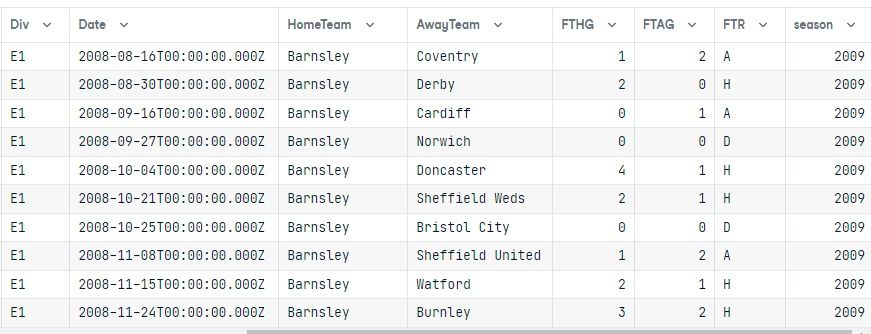
Nachdem wir die Abfrage ausgeführt haben, haben wir das Ergebnis in einen Pandas-Datenrahmen umgewandelt.
Beide Tabellen sind verbunden und die Ergebnisse zeigen nur die E1 Division für die Saison 2009, geordnet nach der Spalte Heimteam.
Jetzt, da wir einen Datenrahmen haben, können wir die Ergebnisse in Form eines Balkendiagramms mit Seaborn visualisieren.
Wir werden:
In diesem Teil geht es vor allem darum, dir zu zeigen, wie du die Ausgabe der SQL-Abfrage nutzen und eine beeindruckende Datenvisualisierung erstellen kannst.
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style="whitegrid")
f, ax = plt.subplots(figsize=(15, 6))
plt.xticks(rotation=90)
sns.set_color_codes("pastel")
sns.barplot(x="HomeTeam", y="FTHG", data=data,
label="Home Team Goals", color="b")
sns.barplot(x="HomeTeam", y="FTAG", data=data,
label="Away Team Goals", color="r")
ax.legend(ncol=2, loc="upper left", frameon=True)
ax.set(ylabel="", xlabel="")
sns.despine(left=True, bottom=True)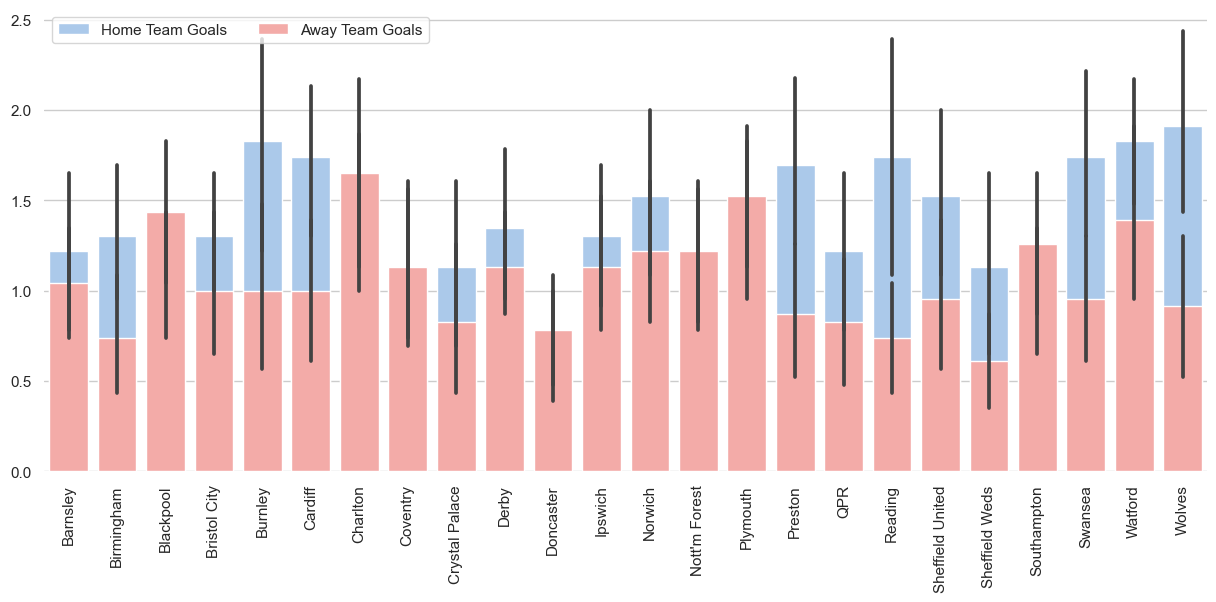
Nachdem du das Abfrageergebnis in einen Pandas-Datenrahmen umgewandelt hast, kannst du einfach die Funktion '.to_csv' mit dem Dateinamen verwenden.
output = conn.execute("SELECT * FROM matchs WHERE HomeTeam LIKE 'Norwich'")
results = output.fetchall()
data = pd.DataFrame(results)
data.columns = results[0].keys()Vermeide es, eine Spalte mit dem Namen "Index" hinzuzufügen, indem du `index=False` verwendest.
data.to_csv("SQl_result.csv",index=False)In diesem Teil werden wir die CSV-Datei der Börsendaten in eine SQL-Tabelle umwandeln.
Verbinde dich zunächst mit der datacamp sqlite Datenbank.
engine = create_engine("sqlite:///datacamp.sqlite")Importiere dann die CSV-Datei mit der Funktion read_csv. Verwende zum Schluss die Funktion "to_sql", um den Pandas-Datenrahmen als SQL-Tabelle zu speichern.
In erster Linie benötigt die Funktion "to_sql" die Verbindung und den Tabellennamen als Argument. Du kannst auch `if_exisits` verwenden, um eine bestehende Tabelle mit demselben Namen zu ersetzen und `index`, um die Indexspalte zu löschen.
df = pd.read_csv('Stock Exchange Data.csv')
df.to_sql(con=engine, name="Stock_price", if_exists='replace', index=False)
>>> 2222Um die Ergebnisse zu validieren, müssen wir die Datenbank verbinden und ein Tabellenobjekt erstellen.
conn = engine.connect()
metadata = db.MetaData()
stock = db.Table('Stock_price', metadata, autoload=True, autoload_with=engine)Führe dann die Abfrage aus und zeige die Ergebnisse an.
query = stock.select()
exe = conn.execute(query)
result = exe.fetchmany(5)
for r in result:
print(r)Wie du siehst, haben wir alle Werte aus der CSV-Datei erfolgreich in die SQL-Tabelle übertragen.
('HSI', '1986-12-31', 2568.300049, 2568.300049, 2568.300049, 2568.300049, 2568.300049, 0, 333.87900637)
('HSI', '1987-01-02', 2540.100098, 2540.100098, 2540.100098, 2540.100098, 2540.100098, 0, 330.21301274)
('HSI', '1987-01-05', 2552.399902, 2552.399902, 2552.399902, 2552.399902, 2552.399902, 0, 331.81198726)
('HSI', '1987-01-06', 2583.899902, 2583.899902, 2583.899902, 2583.899902, 2583.899902, 0, 335.90698726)
('HSI', '1987-01-07', 2607.100098, 2607.100098, 2607.100098, 2607.100098, 2607.100098, 0, 338.92301274)Das Aktualisieren von Werten ist ganz einfach. Wir werden die Funktionen update, values und where verwenden, um einen bestimmten Wert in der Tabelle zu aktualisieren.
table.update().values(column_1=1, column_2=4,...).where(table.columns.column_5 >= 5)In unserem Fall haben wir den Wert "Pass" von False auf True geändert, wobei der Name des Schülers "Nisha" lautet.
Student = db.Table('Student', metadata, autoload=True, autoload_with=engine)
query = Student.update().values(Pass = True).where(Student.columns.Name == "Nisha")
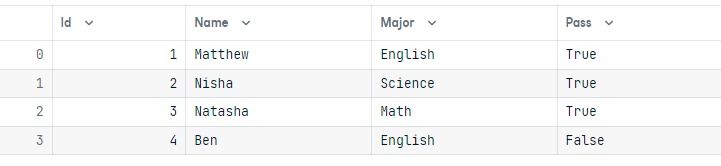
results = conn.execute(query)Um die Ergebnisse zu überprüfen, führen wir eine einfache Abfrage aus und zeigen die Ergebnisse in Form eines Pandas-Datenrahmens an.
output = conn.execute(Student.select()).fetchall()
data = pd.DataFrame(output)
data.columns = output[0].keys()
dataWir haben den Wert "Pass" für den Schülernamen "Nisha" erfolgreich auf True geändert.
Das Löschen der Zeilen ist ähnlich wie das Aktualisieren. Sie erfordert die Lösch- und Wo-Funktion.
table.delete().where(table.columns.column_1 == 6)In unserem Fall löschen wir den Datensatz des Schülers mit dem Namen "Ben".
Student = db.Table('Student', metadata, autoload=True, autoload_with=engine)
query = Student.delete().where(Student.columns.Name == "Ben")
results = conn.execute(query)Um die Ergebnisse zu überprüfen, führen wir eine Schnellabfrage durch und zeigen die Ergebnisse in Form eines Datenrahmens an. Wie du sehen kannst, haben wir die Zeile mit dem Schülernamen "Ben" gelöscht.
output = conn.execute(Student.select()).fetchall()
data = pd.DataFrame(output)
data.columns = output[0].keys()
data
Wenn du SQLite verwendest, wird beim Löschen der Tabelle der Fehler "Datenbank ist gesperrt" ausgegeben. Und warum? Denn SQLite ist eine sehr leichte Version. Er kann immer nur eine Funktion auf einmal ausführen. Derzeit wird eine Select-Abfrage ausgeführt. Bevor wir die Tabelle löschen, müssen wir die gesamte Ausführung beenden.
results.close()
exe.close()Danach verwendest du die Funktion drop_all von metadata und wählst ein Tabellenobjekt aus, um die einzelne Tabelle zu löschen. Du kannst auch den Befehl `Student.drop(engine)` verwenden, um eine einzelne Tabelle zu löschen.
metadata.drop_all(engine, [Student], checkfirst=True)Wenn du keine Tabelle für die drop_all-Funktion angibst. Dabei werden alle Tabellen in der Datenbank gelöscht.
metadata.drop_all(engine)Das SQLAlchemy-Tutorial deckt verschiedene Funktionen von SQLAlchemy ab, von der Verbindung mit der Datenbank bis zur Änderung von Tabellen. Wenn du mehr erfahren möchtest, solltest du den interaktiven Kurs Einführung in Datenbanken in Python absolvieren. Du lernst die Grundlagen von relationalen Datenbanken, Filtern, Ordnen und Gruppieren kennen. Außerdem lernst du fortgeschrittene SQLAlchemy-Funktionen zur Datenmanipulation kennen.
Wenn du Probleme hast, dem Tutorial zu folgen, gehe zur DataLab-Arbeitsmappe und vergleiche deinen Code mit ihr. Du kannst auch eine Kopie der Arbeitsmappe erstellen und sie direkt in DataLab ausführen.
Python & SQL Kurse
Kurs
Kurs
Tutorial
Sejal Jaiswal
Tutorial
Derrick Mwiti
Tutorial
DataCamp Team
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team