Cours
Introduction aux bases de données en Python
4 h
101.3K

SQLAlchemy est la boîte à outils SQL de Python qui permet aux développeurs d'accéder et de gérer des bases de données SQL en utilisant le langage de domaine de Python. Vous pouvez écrire une requête sous la forme d'une chaîne de caractères ou enchaîner des objets Python pour des requêtes similaires. L'utilisation d'objets offre aux développeurs une grande flexibilité et leur permet de créer des applications SQL très performantes.
En termes simples, il permet aux utilisateurs de connecter des bases de données à l'aide du langage Python, d'exécuter des requêtes SQL à l'aide de la programmation basée sur les objets et de rationaliser le flux de travail.
Il est assez facile d'installer le paquet et de commencer à coder.
Vous pouvez installer SQLAlchemy à l'aide du gestionnaire de paquets Python (pip) :
pip install sqlalchemySi vous utilisez la distribution Anaconda de Python, essayez d'entrer la commande dans le terminal conda :
conda install -c anaconda sqlalchemyVérifions si le paquet a été installé avec succès :
>>> import sqlalchemy
>>> sqlalchemy.__version__
'1.4.41'Excellent, nous avons installé avec succès la version 1.4.41 de SQLAlchemy.
Dans cette section, nous apprendrons à connecter les bases de données SQLite, à créer des objets tableaux et à les utiliser pour exécuter la requête SQL.
Nous utiliserons la base de données SQLite sur le football européen de Kaggle, et elle comporte deux tableaux : les divisions et les matchs.
Tout d'abord, nous allons créer des objets de moteur SQLite en utilisant 'create_object' et transmettre l'adresse de la base de données. Ensuite, nous allons créer un objet de connexion en connectant le moteur. Nous utiliserons l'objet "conn" pour exécuter tous les types de requêtes SQL.
from sqlalchemy as db
engine = db.create_engine("sqlite:///european_database.sqlite")
conn = engine.connect() Si vous souhaitez connecter des bases de données PostgreSQL, MySQL, Oracle et Microsoft SQL Server, vérifiez la configuration du moteur pour une connectivité fluide avec le serveur.
Ce tutoriel SQLAlchemy suppose que vous comprenez les principes fondamentaux de Python et de SQL. Si ce n'est pas le cas, c'est tout à fait normal. Vous pouvez suivre le cursus de compétences SQL Fundamentals et Python Fundamentals pour acquérir une base solide.
Pour créer un objet tableau, nous devons fournir des noms de tableaux et des métadonnées. Vous pouvez produire des métadonnées en utilisant la fonction `MetaData()` de SQLAlchemy.
metadata = db.MetaData() #extracting the metadata
division= db.Table('divisions', metadata, autoload=True,
autoload_with=engine) #Table objectImprimons les métadonnées "divisions".
print(repr(metadata.tables['divisions']))Les métadonnées contiennent le nom du tableau, le nom des colonnes avec leur type et le schéma.
Table('divisions', MetaData(), Column('division', TEXT(), table=<divisions>),
Column('name', TEXT(), table=<divisions>), Column('country', TEXT(),
table=<divisions>), schema=None)Utilisons l'objet tableau "division" pour imprimer les noms des colonnes.
print(division.columns.keys())Le tableau se compose d'une colonne division, d'une colonne nom et d'une colonne pays.
['division', 'name', 'country']C'est maintenant que vient la partie la plus amusante. Nous utiliserons l'objet tableau pour exécuter la requête et extraire les résultats.
Dans le code ci-dessous, nous sélectionnons tous les tableaux du tableau "division".
query = division.select() #SELECT * FROM divisions
print(query)Remarque: vous pouvez également écrire la commande select sous la forme "db.select([division])".
Pour visualiser la requête, imprimez l'objet requête, qui affichera la commande SQL.
SELECT divisions.division, divisions.name, divisions.country
FROM divisionsNous allons maintenant exécuter la requête à l'aide de l'objet de connexion et extraire les cinq premières lignes.
exe = conn.execute(query) #executing the query
result = exe.fetchmany(5) #extracting top 5 results
print(result)Le résultat affiche les cinq premières lignes du tableau.
[('B1', 'Division 1A', 'Belgium'), ('D1', 'Bundesliga', 'Deutschland'), ('D2', '2. Bundesliga', 'Deutschland'), ('E0', 'Premier League', 'England'), ('E1', 'EFL Championship', 'England')]Dans cette section, nous examinerons divers exemples de SQLAlchemy pour la création de tableaux, l'insertion de valeurs, l'exécution de requêtes SQL, l'analyse de données et la gestion de tableaux.
Vous pouvez suivre le cours ou consulter le cahier d'exercices DataLab. Il contient une base de données, le code source et les résultats.
Tout d'abord, nous allons créer une nouvelle base de données appelée "dataCamp.sqlite". Le moteur de création crée automatiquement une nouvelle base de données s'il n'existe pas de base de données portant le même nom. La création et la connexion sont donc assez similaires.
Ensuite, nous nous connecterons à la base de données et créerons un objet de métadonnées.
Nous allons utiliser la fonction Table de SQLAlchmy pour créer un tableau appelé "Étudiant"
Il se compose de colonnes :
Nous avons créé la structure du tableau. Ajoutons-le à la base de données en utilisant `metadata.create_all(engine)`.
engine = db.create_engine('sqlite:///datacamp.sqlite')
conn = engine.connect()
metadata = db.MetaData()
Student = db.Table('Student', metadata,
db.Column('Id', db.Integer(),primary_key=True),
db.Column('Name', db.String(255), nullable=False),
db.Column('Major', db.String(255), default="Math"),
db.Column('Pass', db.Boolean(), default=True)
)
metadata.create_all(engine) Pour ajouter une seule ligne, nous allons d'abord utiliser `insert` et ajouter l'objet tableau. Ensuite, utilisez `values` et ajoutez manuellement des valeurs aux colonnes. Son fonctionnement est similaire à celui de l'ajout d'arguments aux fonctions Python.
Enfin, nous exécuterons la requête en utilisant la connexion pour exécuter la fonction.
query = db.insert(Student).values(Id=1, Name='Matthew', Major="English", Pass=True)
Result = conn.execute(query)Vérifions si nous ajoutons la ligne au tableau "Étudiant" en exécutant une requête de sélection et en récupérant toutes les lignes.
output = conn.execute(Student.select()).fetchall()
print(output)Nous avons ajouté les valeurs avec succès.
[(1, 'Matthew', 'English', True)]Ajouter des valeurs une par une n'est pas une façon pratique d'alimenter la base de données. Ajoutons plusieurs valeurs à l'aide de listes.
query = db.insert(Student)
values_list = [{'Id':'2', 'Name':'Nisha', 'Major':"Science", 'Pass':False},
{'Id':'3', 'Name':'Natasha', 'Major':"Math", 'Pass':True},
{'Id':'4', 'Name':'Ben', 'Major':"English", 'Pass':False}]
Result = conn.execute(query,values_list)Pour valider nos résultats, exécutez la requête de sélection simple.
output = conn.execute(db.select([Student])).fetchall()
print(output)Le tableau contient maintenant plus de tableaux.
[(1, 'Matthew', 'English', True), (2, 'Nisha', 'Science', False), (3, 'Natasha', 'Math', True), (4, 'Ben', 'English', False)]Au lieu d'utiliser des objets Python, nous pouvons également exécuter des requêtes SQL à l'aide de String.
Ajoutez simplement l'argument en tant que chaîne de caractères à la fonction `execute` et visualisez le résultat en utilisant `fetchall`.
output = conn.execute("SELECT * FROM Student")
print(output.fetchall())Sortie :
[(1, 'Matthew', 'English', 1), (2, 'Nisha', 'Science', 0), (3, 'Natasha', 'Math', 1), (4, 'Ben', 'English', 0)]Vous pouvez même transmettre des requêtes SQL plus complexes. Dans notre cas, nous sélectionnons les colonnes Nom et Majeure dans lesquelles les étudiants ont réussi l'examen.
output = conn.execute("SELECT Name, Major FROM Student WHERE Pass = True")
print(output.fetchall())Sortie :
[('Matthew', 'English'), ('Natasha', 'Math')]Dans les sections précédentes, nous avons utilisé de simples API/Objets SQLAlchemy. Examinons maintenant des requêtes plus complexes et à plusieurs étapes.
Dans l'exemple ci-dessous, nous sélectionnerons toutes les colonnes dans lesquelles la matière principale de l'étudiant est l'anglais.
query = Student.select().where(Student.columns.Major == 'English')
output = conn.execute(query)
print(output.fetchall())Sortie :
[(1, 'Matthew', 'English', True), (4, 'Ben', 'English', False)]Appliquons la logique AND à la requête WHERE.
Dans notre cas, nous recherchons des étudiants qui ont une spécialisation en anglais et qui ont échoué.
Note: pas égal à '!=' Vrai est Faux.
query = Student.select().where(db.and_(Student.columns.Major == 'English', Student.columns.Pass != True))
output = conn.execute(query)
print(output.fetchall())Seul Ben a échoué à l'examen avec une spécialisation en anglais.
[(4, 'Ben', 'English', False)]En utilisant un tableau similaire, nous pouvons exécuter toutes sortes de commandes, comme le montre le tableau ci-dessous.
Vous pouvez copier et coller ces commandes pour tester les résultats par vous-même. Consultez le cahier d'exercices DataLab si vous êtes bloqué dans l'une des commandes données.
|
Commandes |
API |
|
en |
Student.select().where(Student.columns.Major.in_(['English','Math'])) |
|
et, ou, pas |
Student.select().where(db.or_(Student.columns.Major == 'English', Student.columns.Pass = True)) |
|
commander par |
Student.select().order_by(db.desc(Student.columns.Name)) |
|
limit |
Student.select().limit(3) |
|
sum, avg, count, min, max |
db.select([db.func.sum(Student.columns.Id)]) |
|
groupe par |
db.select([db.func.sum(Student.columns.Id),Student.columns.Major]).group_by(Student.columns.Pass) |
|
distincts |
db.select([Student.columns.Major.distinct()]) |
Pour en savoir plus sur les autres fonctions et commandes, consultez la documentation officielle de l'API SQL Statements and Expressions.
Les scientifiques des données et les analystes apprécient les dataframes pandas et aimeraient beaucoup travailler avec eux. Dans cette partie, nous allons apprendre à convertir un résultat de requête SQLAlchemy en un DataFrame pandas.
Tout d'abord, exécutez la requête et enregistrez les résultats.
query = Student.select().where(Student.columns.Major.in_(['English','Math']))
output = conn.execute(query)
results = output.fetchall()Ensuite, utilisez la fonction DataFrame et fournissez les résultats SQL comme argument. Enfin, ajoutez les noms des colonnes en utilisant les résultats de la première ligne `results[0]` et `.keys()`
Note: vous pouvez fournir n'importe quelle ligne valide pour extraire les noms des colonnes en utilisant `keys()`
data = pd.DataFrame(results)
data.columns = results[0].keys()
data
Dans cette partie, nous allons connecter la base de données du football européen, effectuer des requêtes complexes et visualiser les résultats.
Comme d'habitude, nous allons nous connecter à la base de données en utilisant les fonctions `create_engine` et `connect`.
Dans notre cas, nous allons joindre deux tableaux, nous devons donc créer deux objets de tableau : division et match.
engine = create_engine("sqlite:///european_database.sqlite")
conn = engine.connect()
metadata = db.MetaData()
division = db.Table('divisions', metadata, autoload=True, autoload_with=engine)
match = db.Table('matchs', metadata, autoload=True, autoload_with=engine)Vous pouvez même créer des requêtes plus complexes en ajoutant des modules supplémentaires.
Note: pour joindre automatiquement deux tableaux, vous pouvez également utiliser : `db.select([division.columns.division,match.columns.Div])`
query = db.select([division,match]).\
select_from(division.join(match,division.columns.division == match.columns.Div)).\
where(db.and_(division.columns.division == "E1", match.columns.season == 2009 )).\
order_by(match.columns.HomeTeam)
output = conn.execute(query)
results = output.fetchall()
data = pd.DataFrame(results)
data.columns = results[0].keys()
data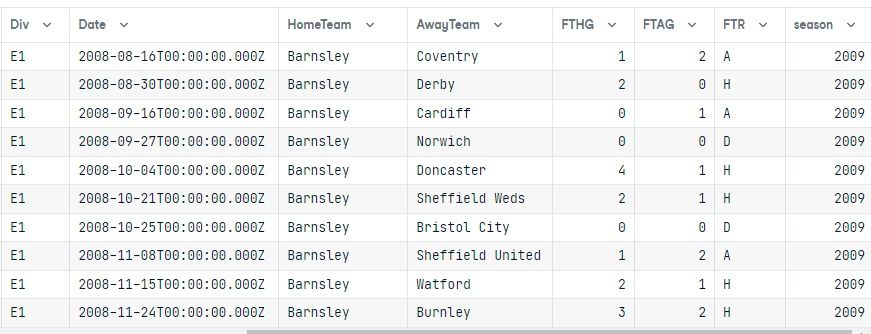
Après avoir exécuté la requête, nous avons converti le résultat en un DataFrame pandas.
Les deux tableaux sont joints, et les résultats ne montrent que la division E1 pour la saison 2009, classée par la colonne HomeTeam.
Maintenant que nous disposons d'un DataFrame, nous pouvons visualiser les résultats sous la forme d'un diagramme à barres à l'aide de Seaborn.
Nous le ferons:
L'objectif principal de cette partie est de vous montrer comment vous pouvez utiliser le résultat de la requête SQL et créer des visualisations de données étonnantes.
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style="whitegrid")
f, ax = plt.subplots(figsize=(15, 6))
plt.xticks(rotation=90)
sns.set_color_codes("pastel")
sns.barplot(x="HomeTeam", y="FTHG", data=data,
label="Home Team Goals", color="b")
sns.barplot(x="HomeTeam", y="FTAG", data=data,
label="Away Team Goals", color="r")
ax.legend(ncol=2, loc="upper left", frameon=True)
ax.set(ylabel="", xlabel="")
sns.despine(left=True, bottom=True)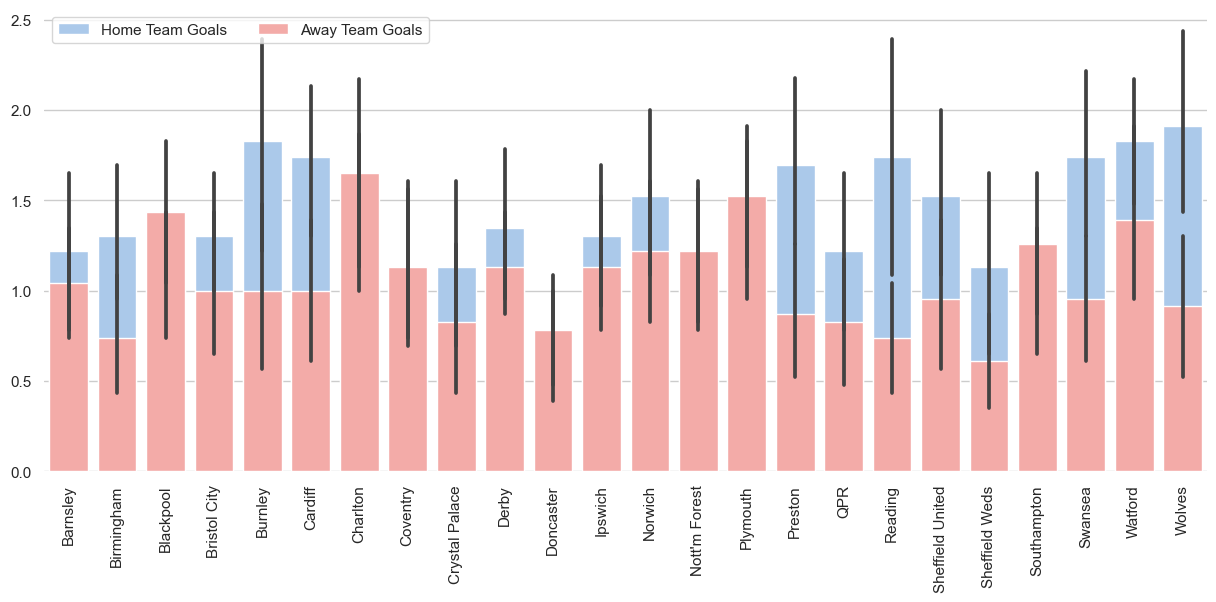
Après avoir converti le résultat de la requête en DataFrame pandas, vous pouvez simplement utiliser la fonction '.to_csv' avec le nom du fichier.
output = conn.execute("SELECT * FROM matchs WHERE HomeTeam LIKE 'Norwich'")
results = output.fetchall()
data = pd.DataFrame(results)
data.columns = results[0].keys()Evitez d'ajouter une colonne appelée "Index" en utilisant `index=False`.
data.to_csv("SQl_result.csv",index=False)Dans cette partie, nous allons convertir le fichier CSV de données boursières en tableau SQL.
Tout d'abord, connectez-vous à la base de données sqlite de DataCamp.
engine = create_engine("sqlite:///datacamp.sqlite")Importez ensuite le fichier CSV à l'aide de la fonction read_csv. Enfin, utilisez la fonction `to_sql` pour enregistrer le DataFrame pandas en tant que tableau SQL.
Principalement, la fonction `to_sql` requiert la connexion et le nom du tableau comme argument. Vous pouvez également utiliser `if_exisits` pour remplacer un tableau existant portant le même nom et `index` pour supprimer la colonne d'index.
df = pd.read_csv('Stock Exchange Data.csv')
df.to_sql(con=engine, name="Stock_price", if_exists='replace', index=False)
>>> 2222Pour valider les résultats, nous devons connecter la base de données et créer un objet tableau.
conn = engine.connect()
metadata = db.MetaData()
stock = db.Table('Stock_price', metadata, autoload=True, autoload_with=engine)Ensuite, exécutez la requête et affichez les résultats.
query = stock.select()
exe = conn.execute(query)
result = exe.fetchmany(5)
for r in result:
print(r)Comme vous pouvez le constater, nous avons transféré avec succès toutes les valeurs du fichier CSV vers le tableau SQL.
('HSI', '1986-12-31', 2568.300049, 2568.300049, 2568.300049, 2568.300049, 2568.300049, 0, 333.87900637)
('HSI', '1987-01-02', 2540.100098, 2540.100098, 2540.100098, 2540.100098, 2540.100098, 0, 330.21301274)
('HSI', '1987-01-05', 2552.399902, 2552.399902, 2552.399902, 2552.399902, 2552.399902, 0, 331.81198726)
('HSI', '1987-01-06', 2583.899902, 2583.899902, 2583.899902, 2583.899902, 2583.899902, 0, 335.90698726)
('HSI', '1987-01-07', 2607.100098, 2607.100098, 2607.100098, 2607.100098, 2607.100098, 0, 338.92301274)La mise à jour des valeurs est simple. Nous utiliserons les fonctions update, values et where pour mettre à jour la valeur spécifique du tableau.
table.update().values(column_1=1, column_2=4,...).where(table.columns.column_5 >= 5)Dans notre cas, nous avons changé la valeur "Pass" de False à True lorsque le nom de l'étudiant est "Nisha".
Student = db.Table('Student', metadata, autoload=True, autoload_with=engine)
query = Student.update().values(Pass = True).where(Student.columns.Name == "Nisha")
results = conn.execute(query)Pour valider les résultats, exécutons une requête simple et affichons les résultats sous la forme d'un DataFrame pandas.
output = conn.execute(Student.select()).fetchall()
data = pd.DataFrame(output)
data.columns = output[0].keys()
dataNous avons réussi à faire passer la valeur "Pass" à True pour l'élève "Nisha".
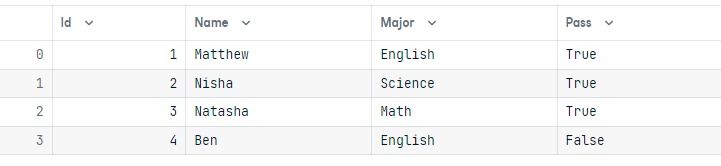
La suppression des lignes est similaire à la mise à jour. Elle nécessite une fonction d'effacement et d'emplacement.
table.delete().where(table.columns.column_1 == 6)Dans notre cas, nous supprimons l'enregistrement de l'étudiant nommé "Ben".
Student = db.Table('Student', metadata, autoload=True, autoload_with=engine)
query = Student.delete().where(Student.columns.Name == "Ben")
results = conn.execute(query)Pour valider les résultats, nous allons exécuter une requête rapide et afficher les résultats sous la forme d'un DataFrame. Comme vous pouvez le constater, nous avons supprimé la ligne contenant le nom de l'élève "Ben".
output = conn.execute(Student.select()).fetchall()
data = pd.DataFrame(output)
data.columns = output[0].keys()
data
Si vous utilisez SQLite, l'abandon du tableau provoquera une erreur "la base de données est verrouillée". Pourquoi ? Parce que SQLite est une version très légère. Il ne peut remplir qu'une seule fonction à la fois. Actuellement, il exécute une requête de sélection. Nous devons fermer toutes les exécutions avant de supprimer le tableau.
results.close()
exe.close()Ensuite, utilisez la fonction drop_all des métadonnées et sélectionnez un objet de tableau pour supprimer le tableau unique. Vous pouvez également utiliser la commande `Student.drop(engine)` pour supprimer un seul tableau.
metadata.drop_all(engine, [Student], checkfirst=True)Si vous ne spécifiez aucun tableau pour la fonction drop_all. Il supprimera tous les tableaux de la base de données.
metadata.drop_all(engine)Le tutoriel SQLAlchemy couvre diverses fonctions de SQLAlchemy, de la connexion à la base de données à la modification des tableaux. Si vous souhaitez en savoir plus, essayez de suivre le cours interactif Introduction aux bases de données en Python. Vous apprendrez les bases des bases de données relationnelles, du filtrage, de l'ordonnancement et du regroupement. En outre, vous apprendrez les fonctions avancées de SQLAlchemy pour la manipulation des données.
Si vous rencontrez des difficultés à suivre le tutoriel, consultez le classeur DataLab et comparez votre code avec celui-ci. Vous pouvez également faire une copie du classeur et l'exécuter directement dans DataLab.
Cours Python et SQL
Cours
Cours
Tutoriel
DataCamp Team
Tutoriel
Sejal Jaiswal
Tutoriel
Moez Ali
Tutoriel
Derrick Mwiti
Tutoriel
Abid Ali Awan
Tutoriel
DataCamp Team