

Curso
Conceitos de IA Generativa
2 h
105.1K
Os rumores sobre o próximo lançamento da Anthropic circulam há alguns dias. Enquanto muita gente esperava o Claude Sonnet 5, a primeira novidade do ano chega como Claude Opus 4.6.
Com uma janela de contexto de 1 milhão de tokens, raciocínio adaptativo, compactação de conversas e uma série de benchmarks em que lidera, o Claude Opus 4.6 é uma evolução do Opus 4.5. Como a própria Anthropic define, eles aprimoraram seu modelo mais inteligente. Junto com o modelo, a Anthropic também lançou times de agentes no Claude Code e o Claude no PowerPoint.
Neste artigo, vamos cobrir tudo o que há de novo no Claude Opus 4.6, explorando os recursos, analisando os benchmarks e colocando o modelo à prova com vários exemplos práticos.
Para conhecer alguns dos recursos mais recentes do Claude, recomendo conferir nossos guias sobre Claude Cowork e Claude Code, além do nosso tutorial OpenClaw. Para comparar com outros concorrentes, leia nossos guias sobre Muse Spark vs Claude Opus 4.6 e GPT-5.4 vs Claude Opus 4.6.
O Claude Opus 4.6 é o mais novo modelo de linguagem da Anthropic. Dando sequência ao Opus 4.5, ele representa um upgrade significativo no nível de modelo mais "inteligente" da companhia.
No post de lançamento, a Anthropic afirma que há um foco maior em code agents, raciocínio profundo e autocorreção. Em outras palavras, há uma mudança de ação para ação sustentada.
O Opus 4.6 foi projetado para planejar com mais cuidado, manter maior coerência por períodos longos e identificar erros no próprio raciocínio. Na prática, isso coloca o Claude Opus 4.6 no topo de diversos benchmarks, incluindo a maior pontuação na avaliação de código Terminal-Bench 2.0 e desempenho superior aos demais modelos de fronteira no Humanity’s Last Exam.
Um dos pontos que mais chamam atenção é a janela de contexto aprimorada do Claude Opus 4.6. Com 1 milhão de tokens no beta, o novo modelo fica alinhado ao Gemini 3, o que significa que ele processa mais informação sem perder o contexto.
Enquanto isso, a Anthropic já publicou a versão sucessora do Opus. Recomendo ler nosso guia do Claude Opus 4.7 para se manter atualizado.
Há vários recursos novos de destaque no Claude Opus 4.6, muitos deles focados em fluxos de trabalho com agentes. Vamos ver os principais:
Os times de agentes são uma evolução dos "subagentes" que vimos nas versões anteriores do Claude. Eles permitem criar várias instâncias do Claude, totalmente independentes, que trabalham em paralelo. Uma sessão funciona como agente "líder" que coordena tudo, enquanto os "colegas" executam as tarefas.
O mais interessante é que cada membro do time tem sua própria janela de contexto, o que permite execuções mais completas. E cada agente pode se comunicar diretamente com os demais do time.
Claro que há um possível contra: o custo. Como cada agente tem sua própria janela de contexto, você pode consumir tokens rapidamente. Por isso, a Anthropic recomenda usar esse recurso em cenários de maior complexidade.
Um recurso bem prático do Claude Opus 4.6 é a compactação de contexto. Esse upgrade de usabilidade ajuda a evitar problemas em fluxos longos que estouram a janela de contexto. Normalmente, você bateria num limite em que a performance começa a cair.
Com a compactação de conversas, o Claude Opus 4.6 detecta automaticamente quando a conversa está chegando a um limite de tokens e resume o histórico em um bloco conciso (um bloco de compactação).
Isso ajuda a preservar o essencial das suas interações e, ao mesmo tempo, libera espaço para continuar o trabalho. Se você pretende usar agentes orientados a tarefas que precisam rodar por muito tempo, esse recurso pode mantê-los no trilho com uma memória bem melhor.
Há dois recursos no Claude Opus 4.6 que determinam se ele precisa usar raciocínio estendido e com que intensidade vai aplicar esse raciocínio.
O raciocínio adaptativo permite ao modelo avaliar a complexidade do seu prompt. Com base no nível de simplicidade ou complexidade, ele decide se usa raciocínio estendido. Em vez de um ajuste manual do número de tokens para isso, o Claude ajusta seu orçamento conforme a complexidade de cada solicitação.
O parâmetro de esforço permite definir se o Claude será mais cauteloso ou mais pródigo no gasto de tokens. Na prática, você equilibra eficiência de tokens e profundidade das respostas.
Ao usar o Claude Opus 4.6 na API, você pode ajustar esses parâmetros manualmente. Por exemplo:
Recentemente falamos sobre o Claude no Excel, mostrando como o add-on pode ajudar em várias tarefas na barra lateral da sua planilha. Além de melhorar esse recurso, a Anthropic anunciou o Claude no PowerPoint.
Essa integração respeita os mestres de slide, fontes e layouts. Você pode fornecer um template corporativo e pedir para construir uma seção específica, ou selecionar um slide e pedir para converter um texto denso em um diagrama nativo e editável.
O foco em gerar objetos editáveis no PowerPoint, e não apenas "imagens de slides", transforma o recurso em uma ferramenta real de produtividade, e não só um gerador de conceitos.
O Claude no PowerPoint está em pesquisa preliminar para usuários Max e Enterprise.
Muitas das principais promessas do Opus 4.6 giram em torno de tarefas de código mais difíceis e raciocínio mais profundo. Essas habilidades dependem de uma base: manter múltiplas restrições em mente, raciocinar em várias etapas e identificar erros.
Com isso em mente, submetemos o Opus 4.6 a uma série de desafios de lógica, matemática e programação em múltiplas etapas. Queríamos ver se exporíamos fraquezas conhecidas e comuns dos LLMs — como erros de cálculo em cascata, raciocínio espacial (sempre um problema) e questões com restrições. Também incluímos uma tarefa específica de depuração, já que o anúncio da Anthropic exaltou o desempenho do Opus 4.6 em análise de causa raiz e outros problemas de debugging.
Nosso primeiro teste combina números primos, hexadecimais e contagem:
Step 1: Find the 6th prime number. Let this be P.
Step 2: Convert the square of P into hexadecimal.
Step 3: Count the letters (A–F) and digits (0–9) in that hex string. Let these be A and B.
Step 4: Multiply A × B. Let this be N.
Step 5: Find the Nth prime number.Parece complexo, mas é fácil de verificar. Sabemos que a resposta correta é 2 porque o 6º primo é 13; 13 ao quadrado é 169, que é "A9" em hexa. Isso tem 1 letra × 1 dígito, que dá 1 ao multiplicar, e o 1º primo é 2.
A preocupação é o modelo tropeçar na conversão para hexa, o que levaria a um erro final em cascata. Como dá para ver, o Opus 4.6 não teve problema:

O segundo teste avalia raciocínio espacial e tratamento de números negativos:
Step 1: Create a 2×2 matrix M with top row [4, 2] and bottom row [1, 5].
Step 2: Rotate M 90 degrees clockwise.
Step 3: Calculate the determinant of the rotated matrix.
Step 4: Cube that determinant.
Step 5: Subtract the 13th Fibonacci number from the result.Este exigiu um pouco mais de verificação. A resposta correta é -6.065. Sabemos disso porque a matriz rotacionada é [[1, 4], [5, 2]]; usamos Python para encontrar o determinante, que é -18; elevando ao cubo, temos -5.832; por fim, subtraímos 233 e chegamos a -6.065.
Escolhemos esse teste porque modelos costumam trocar elementos de lugar de forma incorreta ou perder o sinal negativo no caminho. De novo, o Opus 4.6 passou tranquilo:

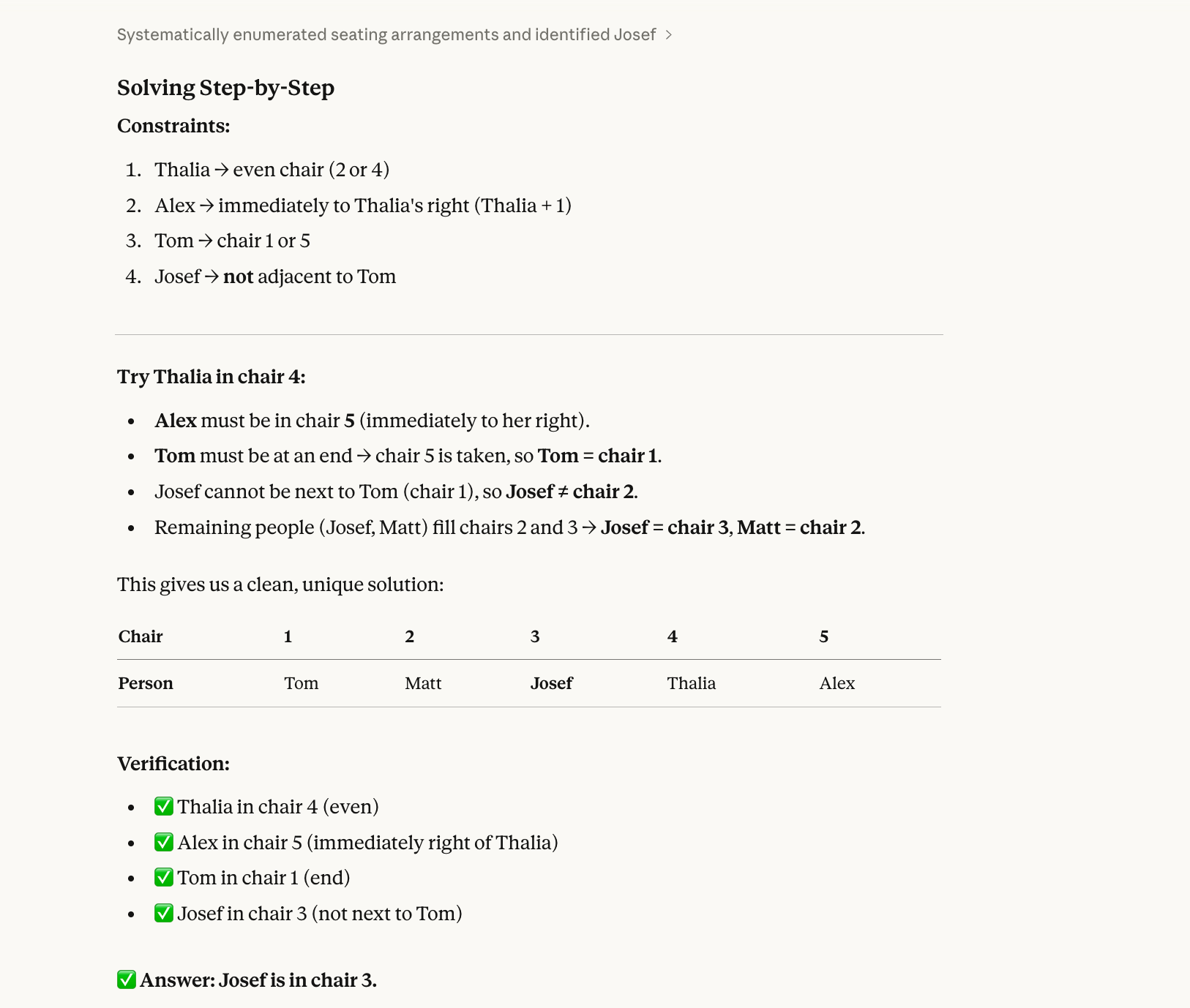
No terceiro teste, usamos um problema de satisfação de restrições que exige backtracking:
Five people (Alex, Josef, Matt, Thalia, Tom) sit in chairs 1–5.
Thalia is in an even-numbered chair.Alex is immediately to Thalia’s right.Tom is at one end.Josef is not next to Tom.Who is in chair 3?A resposta correta é Josef. (Alex-1, Matt-2, Josef-3, Thalia-4, Tom-5.) Dá para resolver no papel com um pouco de esforço.
Modelos costumam errar esse tipo de questão porque resolvem de forma sequencial, não holística. Leem "Thalia está em uma cadeira par" e escolhem uma (digamos, a 2) sem checar se essa escolha funciona com todas as outras restrições. Depois se comprometem, preenchem mais cadeiras e acabam em conflito — e não voltam para tentar a Thalia na cadeira 4.
O Opus 4.6 acertou também:
O quarto teste avalia visualização espacial e intuição física:
Step 1: Imagine a clock currently showing 3:15 PM.
Step 2: Rotate the clock 90 degrees counter-clockwise (physically turning the whole clock face). After the rotation, what time does the minute hand appear to be pointing at?
Step 3: Take that new "apparent" minute value and add it to the original time (3:15 PM).
Step 4: Subtract 45 minutes from that result.
Step 5: What is the final time?Para verificar, eu literalmente girei meu relógio.
A resposta correta é 14h30. Às 3:15, o ponteiro dos minutos aponta para o "3". Quando girei o 12 para a janela à esquerda, o "3" foi para onde estava o "12". Somei 0 a 3:15, subtraí 45 minutos e cheguei a 14h30.
Ao criar o teste, esperávamos que modelos confundissem girar o mostrador com mover o ponteiro. Também sabemos que modelos às vezes estranham somar 0 e tentam forçar outro número.
Mesmo assim, o Opus 4.6 resolveu corretamente e chegou ao resultado certo:

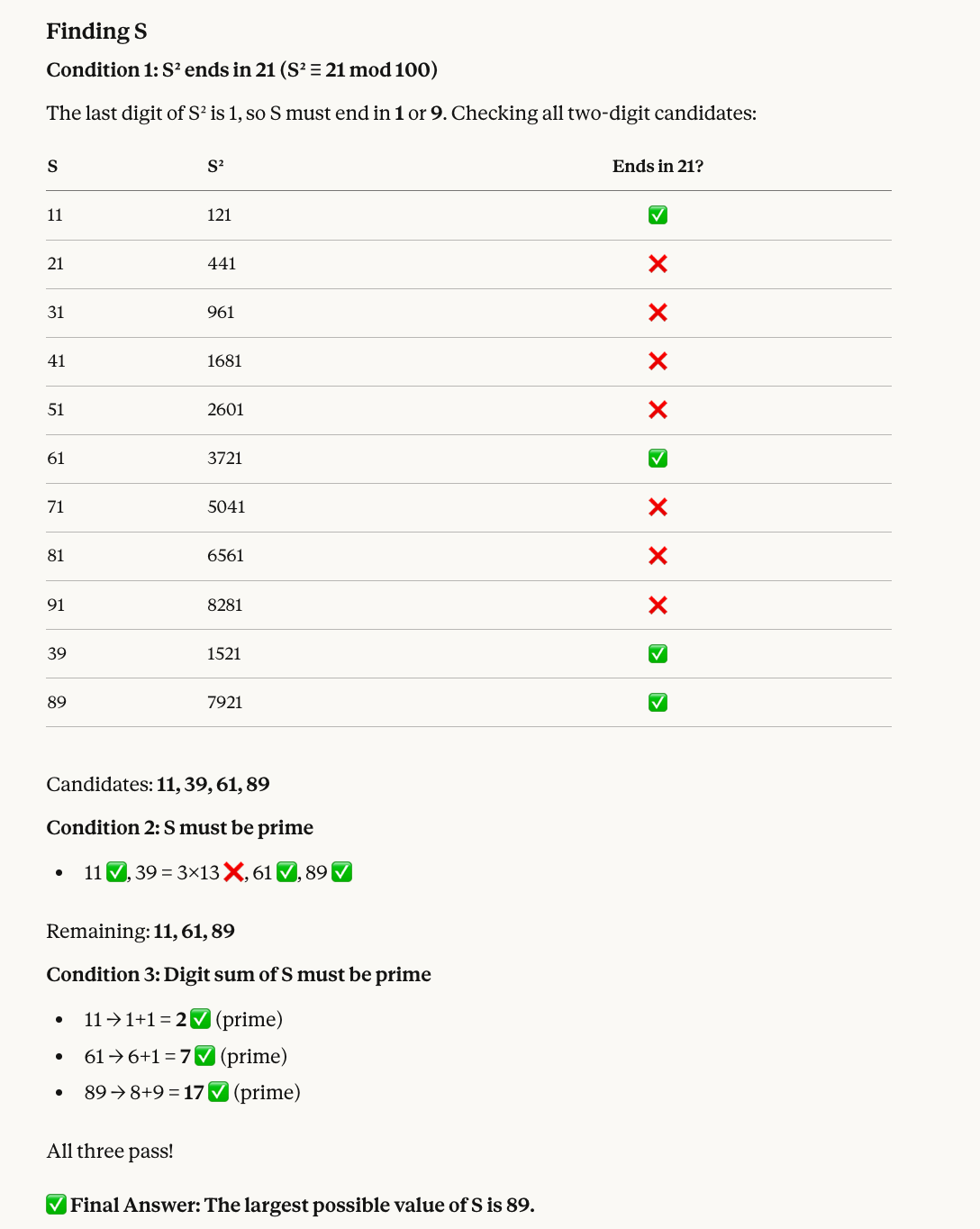
O quinto teste combina aritmética modular com filtragem de primos:
Find a two-digit number S that satisfies all of the following:
* When S is squared, the last two digits of the result are 21.
* S must be a prime number.
* The sum of the digits of S must also be a prime number.
What is the largest possible value of S?Veja por que o número correto é 89: Números cujo quadrado termina em 21 incluem 11, 39, 61 e 89. Desses, 39 não é primo, então sobram 11, 61 e 89. A soma dos dígitos dos três é primo (2, 7 e 17, respectivamente), então o maior é 89.
O Opus 4.6 acertou mais uma vez e ainda trouxe um visual útil:
O próximo teste encadeia fatorial, manipulação de strings e primos:
Step 1: Calculate 5! (5 factorial). Let this result be X.
Step 2: Take X, subtract 1, and reverse the digits of the result. Let this new number be Y.
Step 3: Identify all prime numbers (p) such that 10 ≤ p ≤ Y.
Step 4: Calculate the sum of these primes and divide it by the total count of primes found in that range.
Step 5: Provide the final average, rounded to the nearest whole number.Foi assim que verificamos 425 como resposta correta: 5! = 120; menos 1 dá 119; invertendo os dígitos, temos 911. Com um código em R (abaixo), vimos que há 152 primos entre 10 e 911, somando 64.598. Por fim, dividimos e arredondamos: 64.598 ÷ 152 ≈ 425.

Aqui está o script em R que usamos:
# Step 1: Calculate 5!
X <- factorial(5)
cat("Step 1: X =", X, "\n")
# Step 2: Subtract 1 and reverse digits
result <- X - 1
Y <- as.numeric(paste0(rev(strsplit(as.character(result), "")[[1]]), collapse = ""))
cat("Step 2:", X, "- 1 =", result, "-> reversed ->", Y, "\n")
# Step 3: Find all primes between 10 and Y
is_prime <- function(n) {
if (n < 2) return(FALSE)
if (n == 2) return(TRUE)
if (n %% 2 == 0) return(FALSE)
for (i in 3:floor(sqrt(n))) {
if (n %% i == 0) return(FALSE)
}
return(TRUE)
}
primes <- Filter(is_prime, 10:Y)
cat("Step 3: Found", length(primes), "primes between 10 and", Y, "\n")
# Step 4: Sum and average
total <- sum(primes)
count <- length(primes)
avg <- total / count
cat("Step 4: Sum =", total, ", Count =", count, ", Average =", avg, "\n")
# Step 5: Round
cat("Step 5: Rounded =", round(avg), "\n")O próximo teste mira uma das grandes promessas do Opus 4.6: diagnosticar bugs em código. Sabemos que modelos costumam traçar o passo a passo corretamente, mas falham em ligar o traçado ao defeito de origem.
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!Aqui está o motivo e por que o teste é bom: a função sempre divide por window (3), mesmo quando o bloco tem menos de 3 elementos no início da lista. A saída com bug é [3.33, 10.0, 20.0, 30.0, 40.0], mas os dois primeiros valores deveriam ser 10.0 e 15.0, já que esses blocos têm apenas 1 e 2 elementos, respectivamente. A correção é trocar / window por / len(chunk).
Gostamos desse teste porque os modelos muitas vezes percorrem o loop perfeitamente, mas depois dizem "a saída parece correta" — veem a matemática etapa a etapa e não apontam que dividir um elemento por 3 está errado. É preciso manter a intenção (o que uma média móvel deveria fazer) ao lado da execução (o que o código realmente faz) e identificar o descompasso.

Nosso último teste não tem matemática — é puro raciocínio contrafactual.
In a world where gravity repels objects instead of attracting them, what shape would rivers take?Claro, não há uma resposta única aqui, e é difícil até de imaginar. Mas queremos ver se o modelo pelo menos raciocina sobre as implicações, e achamos que a resposta do Claude Opus 4.6 é razoável.
Resumindo, o Opus 4.6 tirou nota máxima, embora, como você viu, incluímos uma pergunta com resposta um tanto subjetiva — então o veredito final é seu.

O Opus 4.6 lidera, sem contestação, pelo menos quatro benchmarks importantes:
O Terminal-Bench 2.0 avalia agentes de código; o Humanity’s Last Exam mede raciocínio complexo; o GDPval-AA testa desempenho em trabalho do conhecimento; o BrowseComp mede a capacidade do modelo de encontrar informações difíceis na web.
Os modelos Claude têm a merecida fama de serem ótimos programadores. Então vamos começar pelos resultados no Terminal-Bench 2.0.
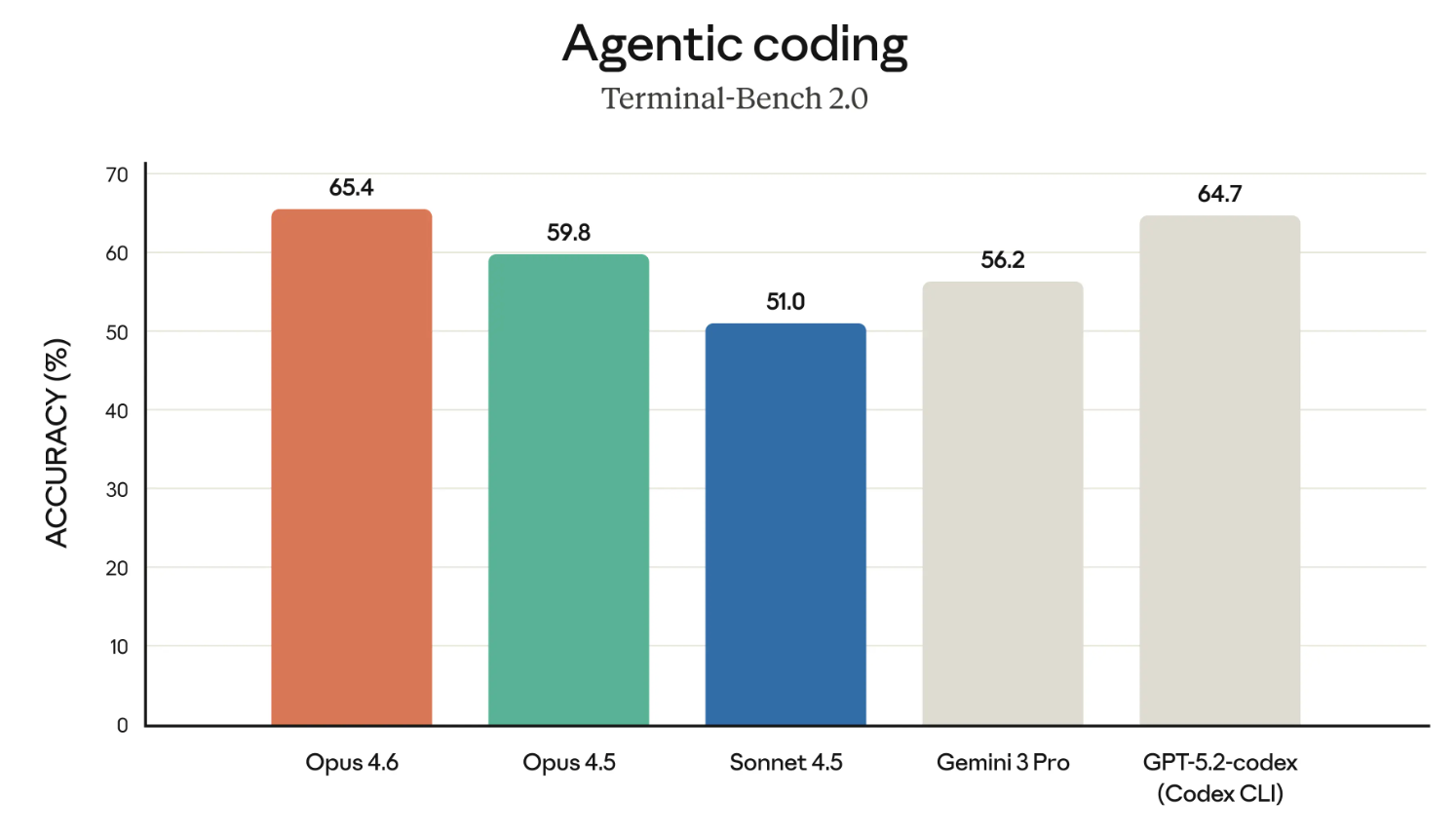
Se o gráfico acima parece destacar o Opus 4.6 em relação ao GPT-5.2-codex — sim, é intencional. A Anthropic vem desafiando a OpenAI diretamente em várias frentes e está construindo seu caso para uso corporativo.
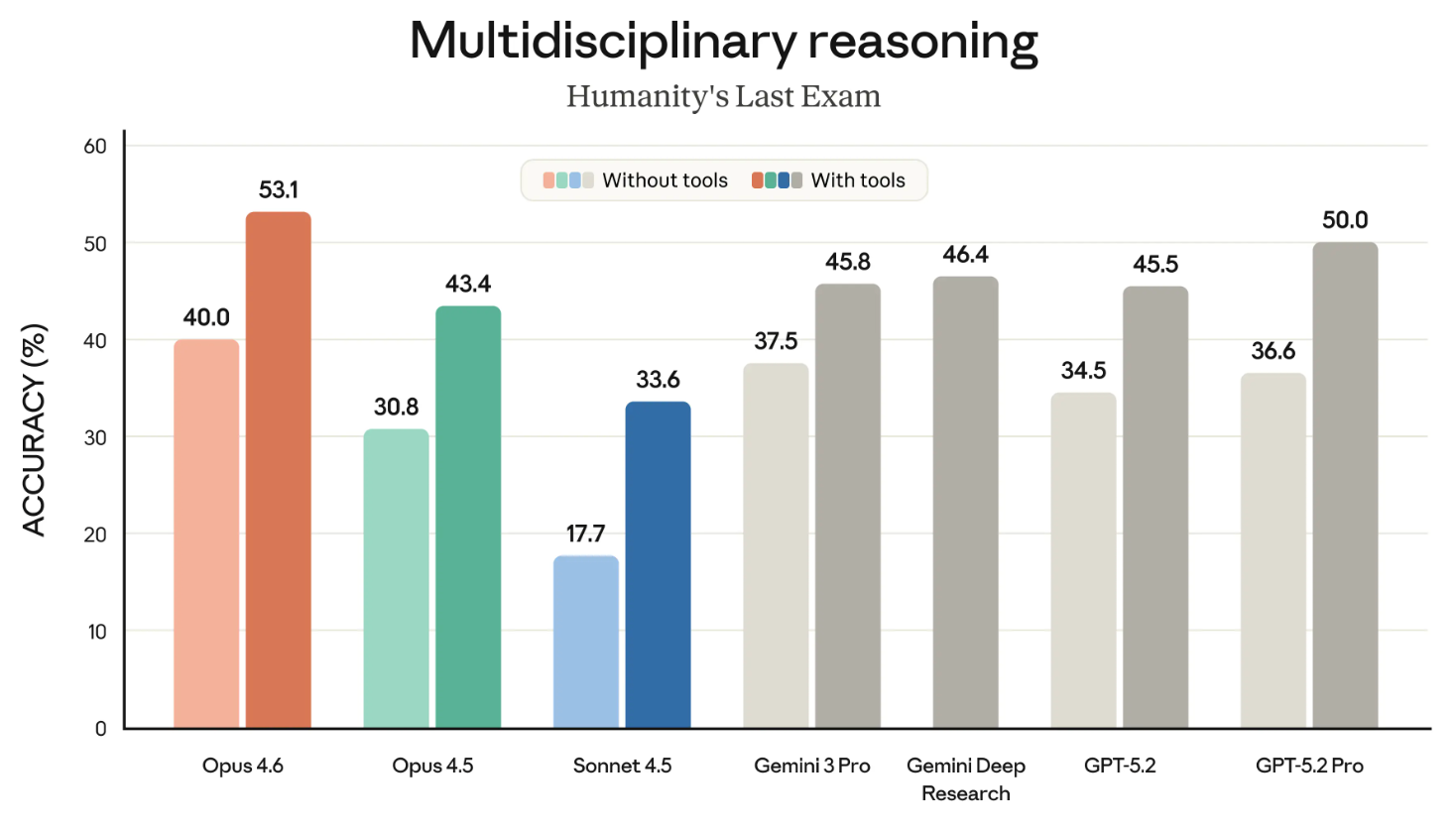
Humanity’s Last Exam é um dos benchmarks mais conhecidos e que acompanhamos de perto. Ele mede a capacidade geral de raciocínio de um modelo.
O gráfico a seguir mostra o desempenho dos diferentes modelos de fronteira no HLE com e sem ferramentas. ("Com ferramentas" significa que o modelo pôde usar capacidades externas como busca na web e execução de código.)
Talvez o ideal fosse dividir em dois gráficos, mas o recado é claro: o Opus 4.6 lidera tanto na categoria "com ferramentas" quanto em "sem ferramentas".
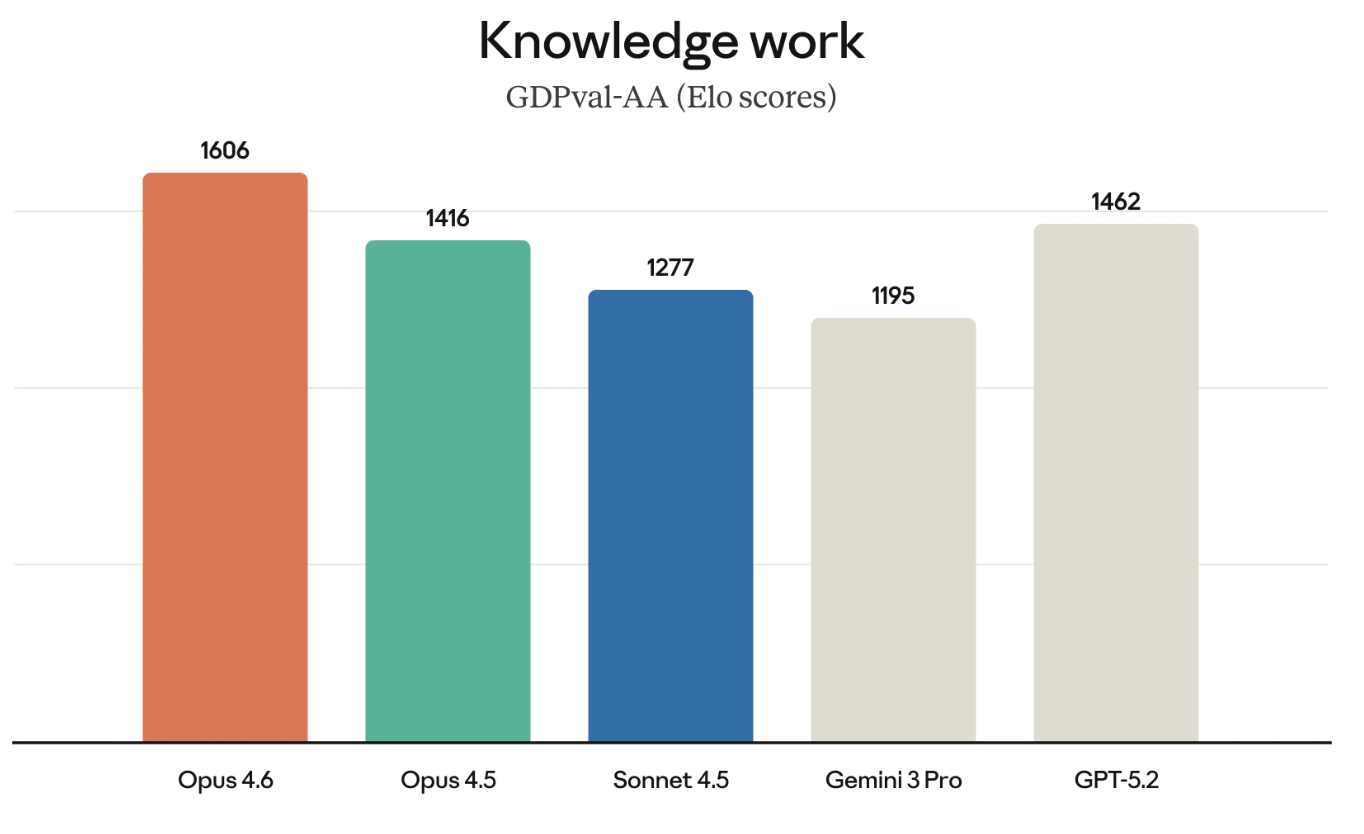
O GDPval-AA (como o nome sugere) é um teste de trabalho do conhecimento com valor econômico. Pense em rodar modelos financeiros ou fazer pesquisa.
O GDPval-AA e benchmarks semelhantes só ganham importância, porque medem exatamente o tipo de trabalho pelo qual as empresas pagam. O sucesso do Opus 4.6 nesse benchmark é mais um desafio direto ao conjunto de modelos GPT, já que OpenAI e Anthropic disputam muitos dos mesmos clientes.
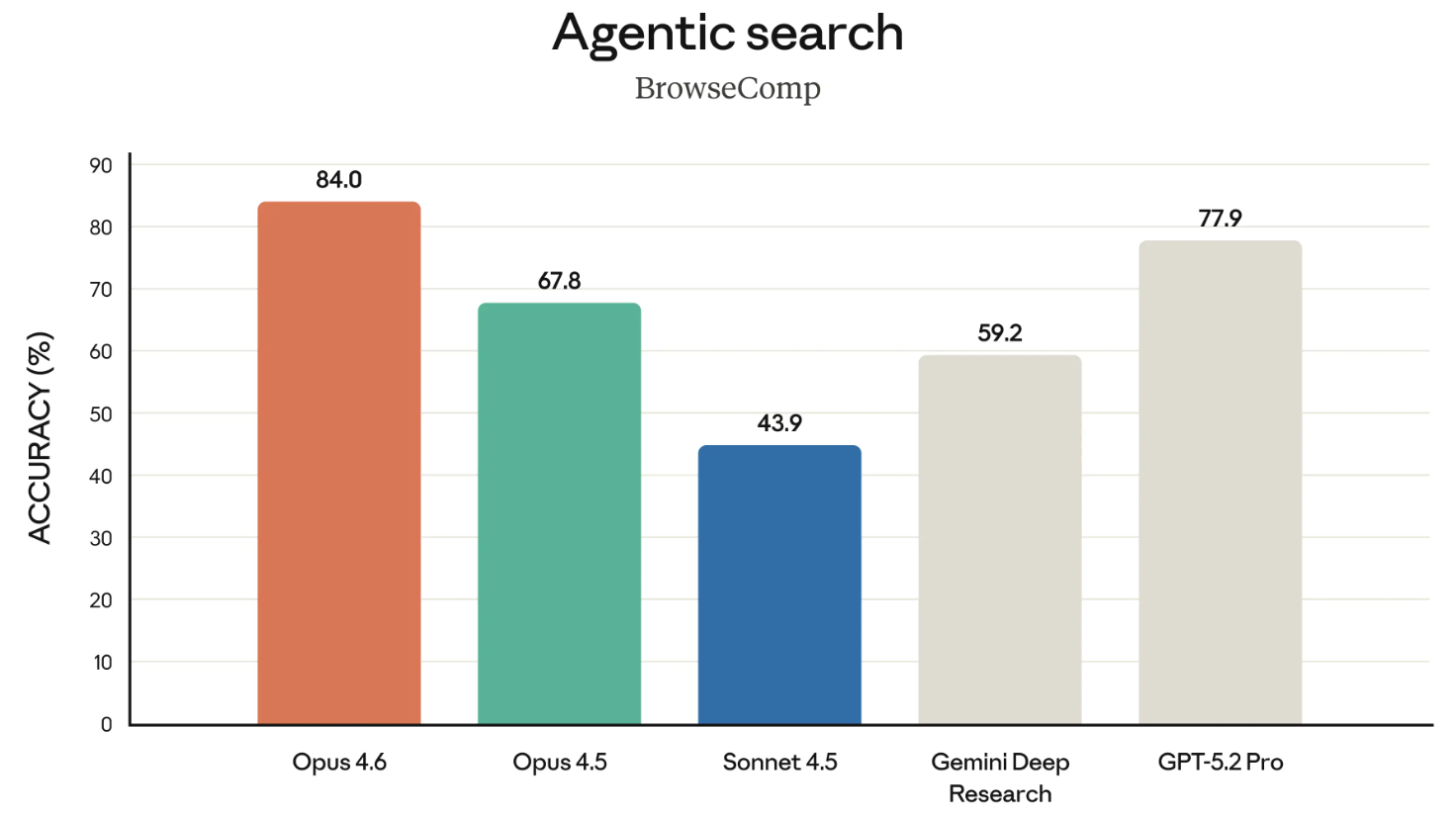
O BrowseComp é o último benchmark digno de nota neste lançamento. Ele mede a capacidade do modelo de encontrar informações difíceis na internet. Um pouco de histórico: a OpenAI criou o BrowseComp para evidenciar as capacidades de busca dos próprios modelos.
Em um movimento certeiro, neste lançamento a Anthropic linkou diretamente ao anúncio de abril de 2025 da OpenAI sobre o BrowseComp ao destacar que o Opus 4.6 lidera o ranking nele. Um toque provocativo, citando o benchmark da própria OpenAI contra ela.
O Opus 4.6 está amplamente disponível na data deste artigo. Porém, você não consegue acessá-lo sem fazer upgrade para uma conta Pro, que traz outros benefícios, como usar o Claude no Excel.
Se você é desenvolvedor, use claude-opus-4-6 na API do Claude. O preço não mudou: continua US$ 5/US$ 25 por milhão de tokens. Se ficou em dúvida sobre os dois valores, o primeiro é o que você paga para enviar tokens ao modelo (seus prompts) e o segundo é o que você paga pelos tokens gerados na resposta.
O Claude Opus 4.6 lidera em benchmarks importantes como o GPDVal-AA, que mede o desempenho do modelo em tarefas economicamente relevantes — exatamente o que os clientes corporativos valorizam. A OpenAI pode ter sentido o golpe, já que, poucas horas antes do lançamento do Opus 4.6, anunciou o OpenAI Frontier, uma nova plataforma corporativa para construir, implantar e gerenciar agentes de IA em produção.
Ou seja, em vez de competir em benchmarks de modelo, o Frontier mostra que a OpenAI está focada na infraestrutura ao redor de sua suíte, dando a agentes de IA contexto de negócio compartilhado, permissões e a capacidade de receber e aprender com feedback ao longo do tempo. Perdendo terreno nos benchmarks, a OpenAI sinaliza que sua plataforma está mais bem posicionada para tornar agentes realmente úteis nas empresas.
Se isso é uma mudança estratégica ou uma admissão tácita de que está perdendo a corrida de modelos, fica a seu critério.
No geral, ficamos bem impressionados com o que a Anthropic trouxe no Claude Opus 4.6 e estamos ansiosos para testar os times de agentes. Se você quer saber mais sobre a família Claude, confira o curso Introduction to Claude Models.
Learn AI with DataCamp
Curso
Curso
Curso
blog
Khalid Abdelaty
15 min
blog
Richie Cotton
7 min
blog
Abid Ali Awan
9 min
blog
Abid Ali Awan
8 min
Tutorial
Abid Ali Awan
Tutorial


