

Kurs
Konzeptuelle Einführung in generative KI
2 Std.
106.4K
Seit ein paar Tagen kursieren Gerüchte über Anthropics nächsten Release. Viele rechneten mit Claude Sonnet 5, doch das erste Update des Jahres heißt Claude Opus 4.6.
Mit einem Kontextfenster von 1 Million Tokens, adaptivem Denken, Gesprächskomprimierung und einer Reihe von Spitzenwerten in Benchmarks ist Claude Opus 4.6 ein Upgrade gegenüber Opus 4.5. Oder wie Anthropic es nennt: Das klügste Modell wurde weiterentwickelt. Parallel dazu hat Anthropic Agententeams in Claude Code und Claude in PowerPoint vorgestellt.
In diesem Artikel fassen wir alle Neuerungen von Claude Opus 4.6 zusammen, schauen uns die neuen Features an, beleuchten die Benchmarks und testen das Modell praxisnah mit mehreren Beispielen.
Wenn du mehr über die neuesten Claude-Features erfahren willst, schau dir unsere Guides zu Claude Cowork und Claude Code an – sowie unser OpenClaw-Tutorial. Für Vergleiche mit der Konkurrenz lies unsere Guides zu Muse Spark vs Claude Opus 4.6 und GPT-5.4 vs Claude Opus 4.6.
Claude Opus 4.6 ist das neueste Large Language Model von Anthropic. Es baut auf Opus 4.5 auf und stellt ein deutliches Upgrade der „smartesten“ Modellstufe des Unternehmens dar.
Laut Release-Blog legt Anthropic mehr Fokus auf agentisches Coding, tiefes Reasoning und Selbstkorrektur. Heißt: Es geht weniger um einzelne Aktionen, sondern um nachhaltige Ausführung.
Opus 4.6 plant sorgfältiger, bleibt über längere Phasen kohärent und erkennt eigene Fehler. Dadurch führt Claude Opus 4.6 mehrere Benchmarks an – etwa mit der Top-Bewertung in der Terminal-Bench 2.0-Coding-Evaluation und besseren Ergebnissen als alle anderen Spitzenmodelle bei Humanity’s Last Exam.
Besonders ins Auge fällt das verbesserte Kontextfenster von Claude Opus 4.6. Mit 1 Million Tokens in der Beta zieht das neue Modell mit Gemini 3 gleich – es kann also mehr Informationen verarbeiten, ohne den Kontext aus den Augen zu verlieren.
Inzwischen hat Anthropic die Nachfolgeversion von Opus veröffentlicht. Lies unseren Guide zu Claude Opus 4.7, um auf dem Laufenden zu bleiben.
Claude Opus 4.6 bringt mehrere bemerkenswerte Neuerungen, viele davon rund um agentische Workflows. Hier die wichtigsten Punkte:
Agententeams sind ein Upgrade gegenüber den „Subagents“ aus früheren Claude-Versionen. Sie erlauben dir, mehrere vollständig unabhängige Claude-Instanzen parallel zu starten. Eine Sitzung ist der leitende Agent, der koordiniert, während „Teamkollegen“ die eigentliche Ausführung übernehmen.
Spannend ist, dass jedes Teammitglied sein eigenes Kontextfenster hat – das ermöglicht eine gründlichere Ausführung. Die Teammitglieder können zudem direkt miteinander kommunizieren.
Klar, der Haken könnte der Preis sein. Da jeder Agent ein eigenes Kontextfenster hat, können die Token-Kosten schnell steigen. Anthropic empfiehlt Agententeams daher vor allem für Szenarien mit hoher Komplexität.
Ein praktisches Feature von Claude Opus 4.6 ist die Kontext- bzw. Gesprächskomprimierung. Dieses Quality-of-Life-Upgrade hilft bei langen Workflows, die das Kontextfenster ausreizen. Normalerweise stößt man irgendwann an eine Kontextgrenze, ab der die Leistung abnimmt.
Mit der Gesprächskomprimierung erkennt Claude Opus 4.6 automatisch, wenn eine Unterhaltung einen Tokengrenzwert erreicht, und fasst den bisherigen Verlauf in einem kompakten Block zusammen (Compaction Block).
So bleiben die Essentials deiner Interaktion erhalten und es wird gleichzeitig Platz geschaffen, um weiterzuarbeiten. Wenn du aufgabenorientierte Agenten langfristig laufen lassen willst, hilft das mit einer spürbar besseren „Erinnerung“, sie auf Kurs zu halten.
Zwei Funktionen von Claude Opus 4.6 steuern, ob erweitertes Denken nötig ist – und wie viel Aufwand dafür betrieben wird.
Adaptives Denken lässt das Modell die Komplexität deiner Anfrage einschätzen. Je nach Einfachheit oder Komplexität entscheidet es, ob erweitertes Denken eingesetzt wird. Statt einer manuellen Einstellung für die Tokenanzahl passt Claude sein Budget dynamisch an die Komplexität jeder Anfrage an.
Mit dem Effort-Parameter legst du fest, wie großzügig oder sparsam Claude Tokens einsetzt. Du balancierst damit Token-Effizienz und Gründlichkeit der Antworten.
In der API kannst du diese Parameter manuell setzen. Zum Beispiel:
Vor Kurzem haben wir Claude in Excel vorgestellt und gezeigt, wie dir das Add-on in einem Seitenpanel deiner Excel-Tabelle bei verschiedenen Aufgaben hilft. Neben Verbesserungen an diesem Tool hat Anthropic nun auch Claude in PowerPoint angekündigt.
Die Integration respektiert deine Folienmaster, Schriften und Layouts. Du kannst eine Corporate-Vorlage verwenden und eine bestimmte Sektion bauen lassen – oder eine Folie auswählen und dichte Textblöcke in ein natives, editierbares Diagramm umwandeln lassen.
Der Fokus auf editierbare PowerPoint-Objekte statt bloßer „Bilder von Folien“ macht das Ganze zu einem echten Produktivitätstool – nicht nur zu einem Ideengeber.
Claude in PowerPoint befindet sich derzeit in der Research Preview für Max- und Enterprise-Nutzer.
Viele der großen Versprechen von Opus 4.6 drehen sich um anspruchsvollere Coding-Aufgaben und tieferes Reasoning. Diese Fähigkeiten basieren auf einer Grundlage: mehrere Bedingungen gleichzeitig im Blick behalten, über viele Schritte schlussfolgern und Fehler erkennen.
Vor diesem Hintergrund haben wir Opus 4.6 mit einer Reihe von Logik-, Mathe- und Coding-Challenges über mehrere Schritte getestet. Wir wollten bekannte LLM-Schwächen aufdecken – etwa verkettete Rechenfehler, räumliches Denken (klassischer Stolperstein) und Aufgaben mit Nebenbedingungen. Außerdem haben wir eine Debugging-Aufgabe aufgenommen, weil Anthropic in der Ankündigung die Stärken von Opus 4.6 bei Root-Cause-Analysen und anderen Debugging-Themen hervorgehoben hat.
Unser erster Test kombiniert Primzahlen, Hexadezimalzahlen und Zählen:
Step 1: Find the 6th prime number. Let this be P.
Step 2: Convert the square of P into hexadecimal.
Step 3: Count the letters (A–F) and digits (0–9) in that hex string. Let these be A and B.
Step 4: Multiply A × B. Let this be N.
Step 5: Find the Nth prime number.Klingt etwas komplex, ist für uns Menschen aber leicht zu prüfen. Die richtige Antwort ist 2, denn die 6. Primzahl ist 13; 13 zum Quadrat ist 169, was in Hex „A9“ ist. Das sind 1 Buchstabe × 1 Ziffer, ergibt multipliziert 1, und die erste Primzahl ist 2.
Die Sorge: Ein Modell könnte bei der Hex-Konvertierung patzen – und dann ist das Endergebnis komplett falsch. Wie du siehst, hatte Opus 4.6 hier keinerlei Probleme:

Unser zweiter Test prüft räumliches Denken und den Umgang mit negativen Zahlen:
Step 1: Create a 2×2 matrix M with top row [4, 2] and bottom row [1, 5].
Step 2: Rotate M 90 degrees clockwise.
Step 3: Calculate the determinant of the rotated matrix.
Step 4: Cube that determinant.
Step 5: Subtract the 13th Fibonacci number from the result.Die Verifizierung brauchte hier etwas mehr Aufwand. Die richtige Antwort ist -6.065. Die gedrehte Matrix ist [[1, 4], [5, 2]]; den Determinanten berechnen wir mit Python: -18; hoch 3 ergibt -5.832; minus 233 (die 13. Fibonacci-Zahl) ergibt -6.065.
Wir mögen diesen Test, weil Modelle hier oft Elemente falsch vertauschen oder unterwegs das Minuszeichen verlieren. Auch hier hatte Opus 4.6 keine Mühe:

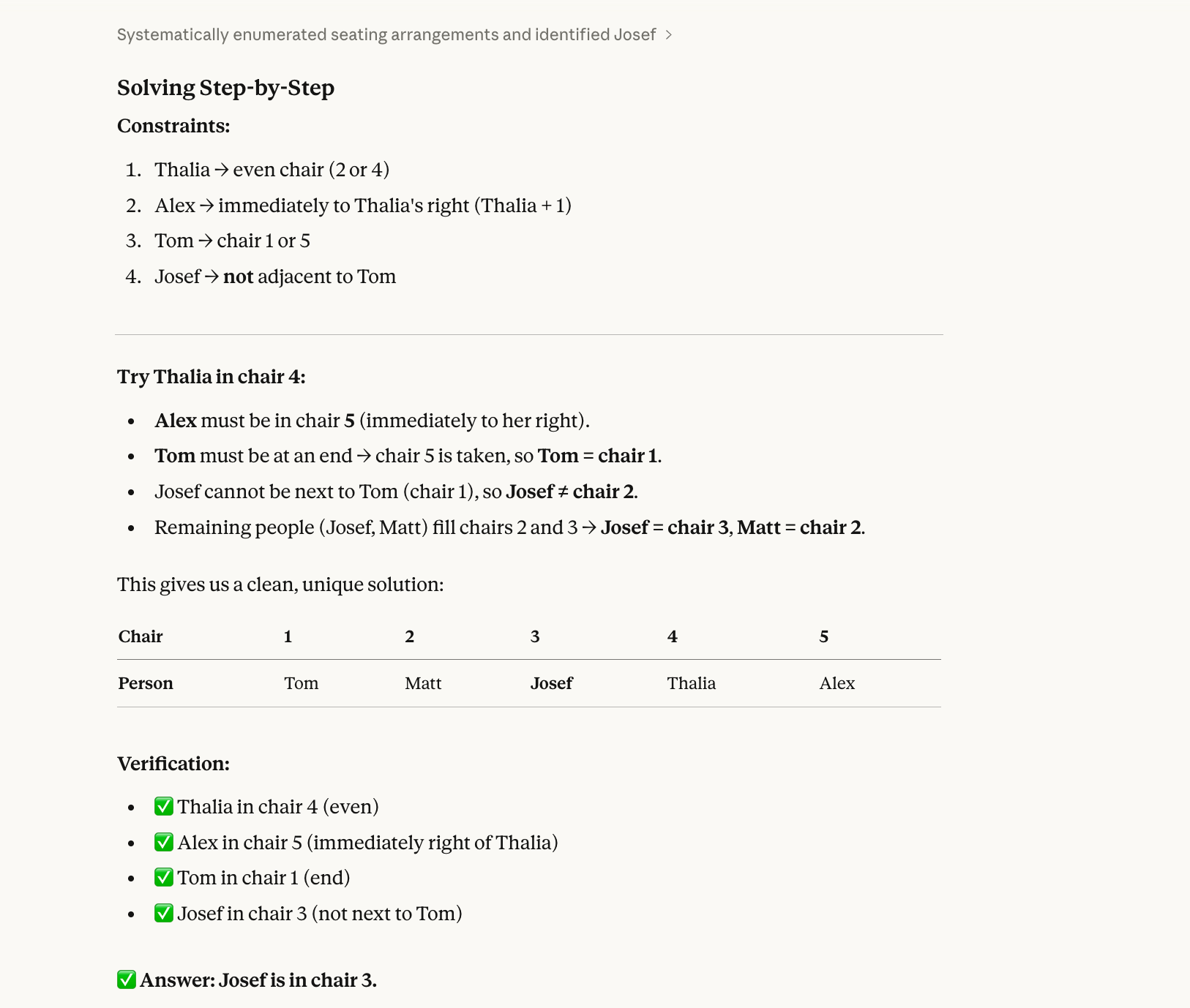
Im dritten Test geht es um ein Constraint-Problem mit Backtracking:
Five people (Alex, Josef, Matt, Thalia, Tom) sit in chairs 1–5.
Thalia is in an even-numbered chair.Alex is immediately to Thalia’s right.Tom is at one end.Josef is not next to Tom.Who is in chair 3?Die richtige Antwort ist Josef. (Alex-1, Matt-2, Josef-3, Thalia-4, Tom-5.) Man kann es mit etwas Geduld auf Papier lösen.
Warum Modelle hier oft falsch liegen: Sie lösen sequentiell, nicht holistisch. Sie lesen „Thalia sitzt auf einem geraden Stuhl“ und wählen einen (z. B. Stuhl 2), ohne zu prüfen, ob diese Wahl zu allen anderen Bedingungen passt. Dann legen sie sich fest, füllen weiter aus und stoßen irgendwann auf einen Konflikt – gehen aber nicht zurück, um z. B. Thalia auf Stuhl 4 zu setzen.
Opus 4.6 lag auch hier richtig:
Der vierte Test prüft räumliche Vorstellung und physikalische Intuition:
Step 1: Imagine a clock currently showing 3:15 PM.
Step 2: Rotate the clock 90 degrees counter-clockwise (physically turning the whole clock face). After the rotation, what time does the minute hand appear to be pointing at?
Step 3: Take that new "apparent" minute value and add it to the original time (3:15 PM).
Step 4: Subtract 45 minutes from that result.
Step 5: What is the final time?Zur Verifizierung habe ich tatsächlich meine Armbanduhr abgenommen und gedreht.
Die richtige Antwort ist 14:30 Uhr. Um 3:15 zeigt der Minutenzeiger auf die „3“. Drehe ich die 12 Richtung Fenster links von mir, wandert die „3“ an die Position der „12“. Ich addiere 0 zu 3:15, ziehe 45 Minuten ab – und lande bei 14:30.
Bei der Testkonstruktion dachten wir, Modelle könnten das Drehen des Zifferblatts mit dem Bewegen des Zeigers verwechseln. Außerdem neigen Modelle dazu, „0 addieren“ für verdächtig zu halten und erzwingen dann eine andere Zahl.
Opus 4.6 löste das korrekt und kam zur richtigen Zeitangabe:

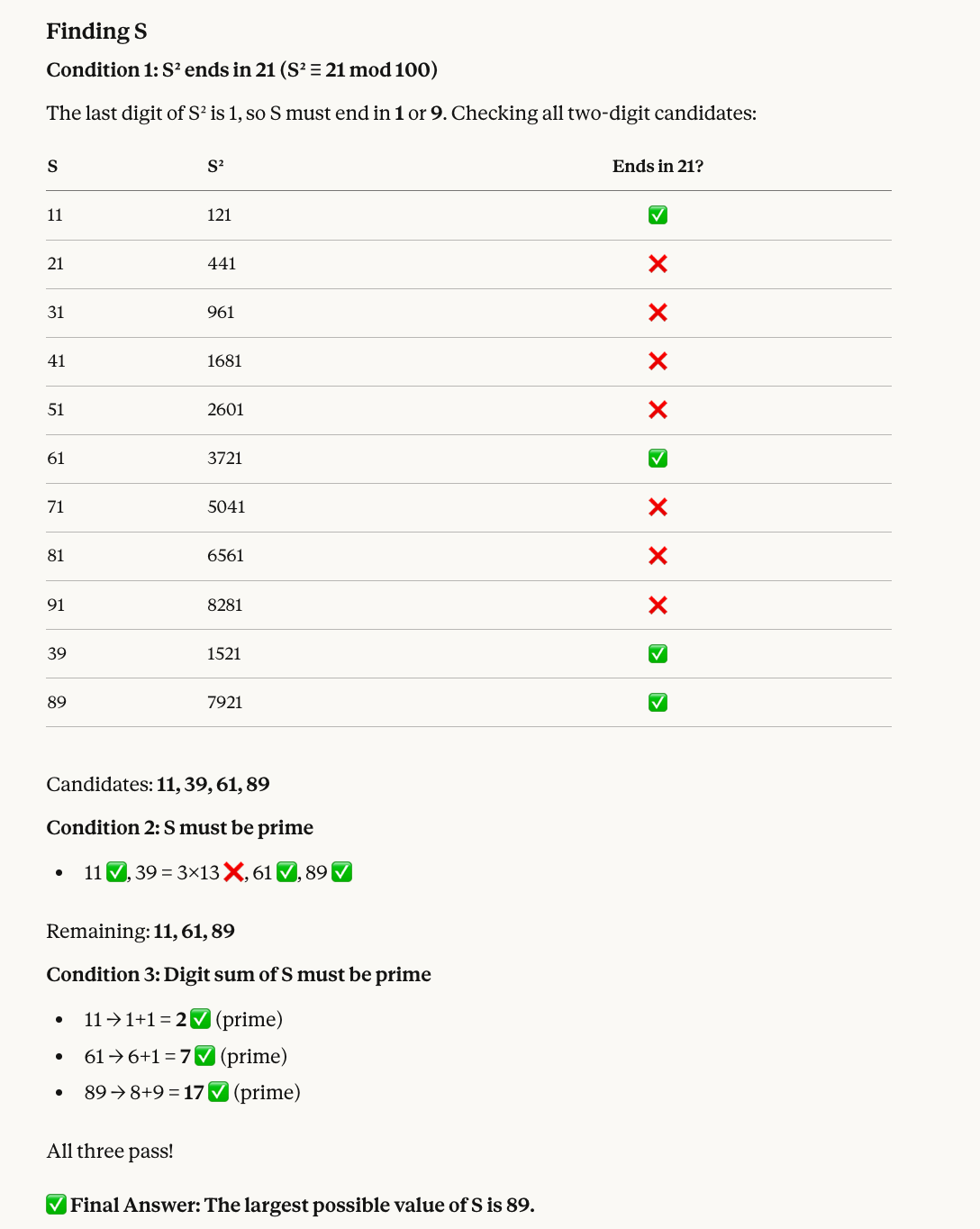
Im fünften Test kombinieren wir Modulo-Rechnung mit Primzahlfilterung:
Find a two-digit number S that satisfies all of the following:
* When S is squared, the last two digits of the result are 21.
* S must be a prime number.
* The sum of the digits of S must also be a prime number.
What is the largest possible value of S?Darum ist 89 korrekt: Zahlen, deren Quadrate auf 21 enden, sind u. a. 11, 39, 61 und 89. 39 ist nicht prim, übrig bleiben 11, 61 und 89. Alle drei haben Primzahlsummen (2, 7 und 17). Die größte ist 89.
Opus 4.6 traf erneut die richtige Wahl – inklusive einer hilfreichen Visualisierung:
Der nächste Test verknüpft Fakultäten, String-Manipulation und Primzahlen:
Step 1: Calculate 5! (5 factorial). Let this result be X.
Step 2: Take X, subtract 1, and reverse the digits of the result. Let this new number be Y.
Step 3: Identify all prime numbers (p) such that 10 ≤ p ≤ Y.
Step 4: Calculate the sum of these primes and divide it by the total count of primes found in that range.
Step 5: Provide the final average, rounded to the nearest whole number.So haben wir 425 verifiziert: 5! = 120; minus 1 ergibt 119; Ziffern umkehren ergibt 911. Mit etwas R-Code (unten) sehen wir: Es gibt 152 Primzahlen zwischen 10 und 911, ihre Summe ist 64.598. Teilen und runden: 64.598 ÷ 152 ≈ 425.

Hier das verwendete R-Skript:
# Step 1: Calculate 5!
X <- factorial(5)
cat("Step 1: X =", X, "\n")
# Step 2: Subtract 1 and reverse digits
result <- X - 1
Y <- as.numeric(paste0(rev(strsplit(as.character(result), "")[[1]]), collapse = ""))
cat("Step 2:", X, "- 1 =", result, "-> reversed ->", Y, "\n")
# Step 3: Find all primes between 10 and Y
is_prime <- function(n) {
if (n < 2) return(FALSE)
if (n == 2) return(TRUE)
if (n %% 2 == 0) return(FALSE)
for (i in 3:floor(sqrt(n))) {
if (n %% i == 0) return(FALSE)
}
return(TRUE)
}
primes <- Filter(is_prime, 10:Y)
cat("Step 3: Found", length(primes), "primes between 10 and", Y, "\n")
# Step 4: Sum and average
total <- sum(primes)
count <- length(primes)
avg <- total / count
cat("Step 4: Sum =", total, ", Count =", count, ", Average =", avg, "\n")
# Step 5: Round
cat("Step 5: Rounded =", round(avg), "\n")Als Nächstes testen wir einen der großen Claims von Opus 4.6: Bugs im Code diagnostizieren. Modelle können Code oft Zeile für Zeile korrekt nachverfolgen – scheitern aber daran, den Trace mit der eigentlichen Ursache zu verknüpfen.
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!Die Lösung und warum der Test gut ist: Die Funktion teilt immer durch window (3), auch wenn der Chunk am Anfang weniger als 3 Elemente hat. Das fehlerhafte Ergebnis ist [3.33, 10.0, 20.0, 30.0, 40.0], korrekt wären für die ersten beiden Werte jedoch 10.0 und 15.0, da die Chunks nur 1 bzw. 2 Elemente enthalten. Der Fix: / window durch / len(chunk) ersetzen.
Wir mögen diesen Test, weil Modelle die Schleife oft perfekt nachzeichnen, dann aber berichten „Output sieht korrekt aus“ – sie sehen die Rechenschritte und übersehen, dass das Teilen eines einzelnen Elements durch 3 falsch ist. Das erfordert, Intention (was ein gleitender Durchschnitt tun sollte) und Ausführung (was der Code tatsächlich macht) gleichzeitig im Blick zu behalten und die Lücke zu erkennen.

Zum Abschluss ein Test ohne Mathe – nur kontrafaktisches Denken.
In a world where gravity repels objects instead of attracting them, what shape would rivers take?Klar, es gibt hier keine einzig richtige Antwort, und es ist schwer vorstellbar. Wir wollten aber sehen, ob das Modell die Implikationen durchdenkt – und finden, dass die Antwort von Claude Opus 4.6 plausibel ist.
Unterm Strich: Opus 4.6 holte eine perfekte Punktzahl – auch wenn eine Frage etwas subjektiv war. Das letzte Urteil fällst du.

Opus 4.6 führt mindestens vier wichtige Benchmarks klar an:
Terminal-Bench 2.0 ist ein agentischer Coding-Benchmark; Humanity’s Last Exam testet komplexes Reasoning; GDPval-AA misst die Leistung bei Wissensarbeit; BrowseComp misst die Fähigkeit eines Modells, schwer auffindbare Informationen online zu recherchieren.
Claude-Modelle haben zu Recht den Ruf, zu den besten Codern zu gehören. Schauen wir uns die Ergebnisse bei Terminal-Bench 2.0 an.
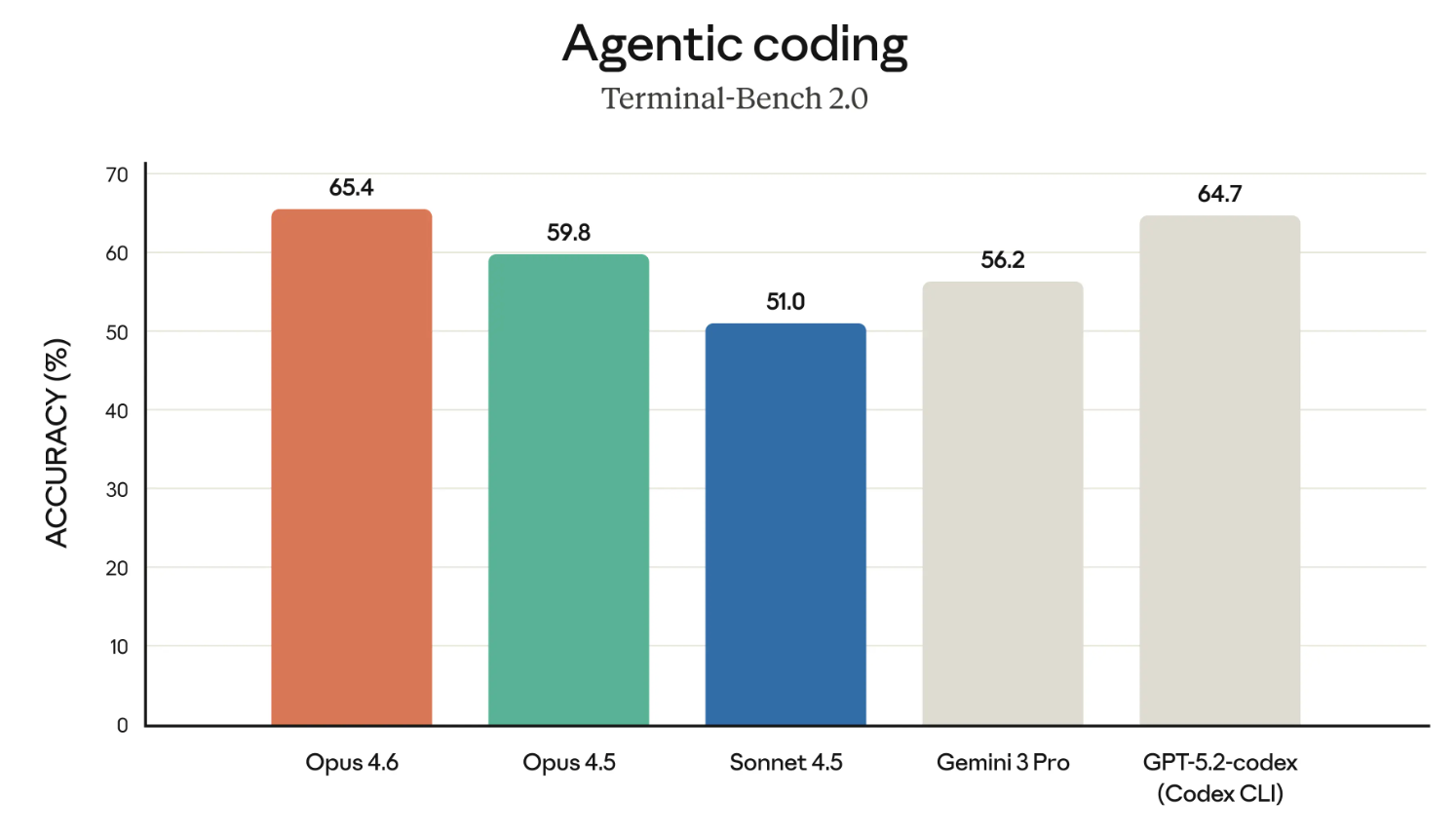
Wenn die Grafik Opus 4.6 im Verhältnis zu GPT-5.2-codex besonders hervorhebt – das ist sicher beabsichtigt. Anthropic fordert OpenAI zuletzt sehr direkt heraus und positioniert sich klar für den Enterprise-Einsatz.
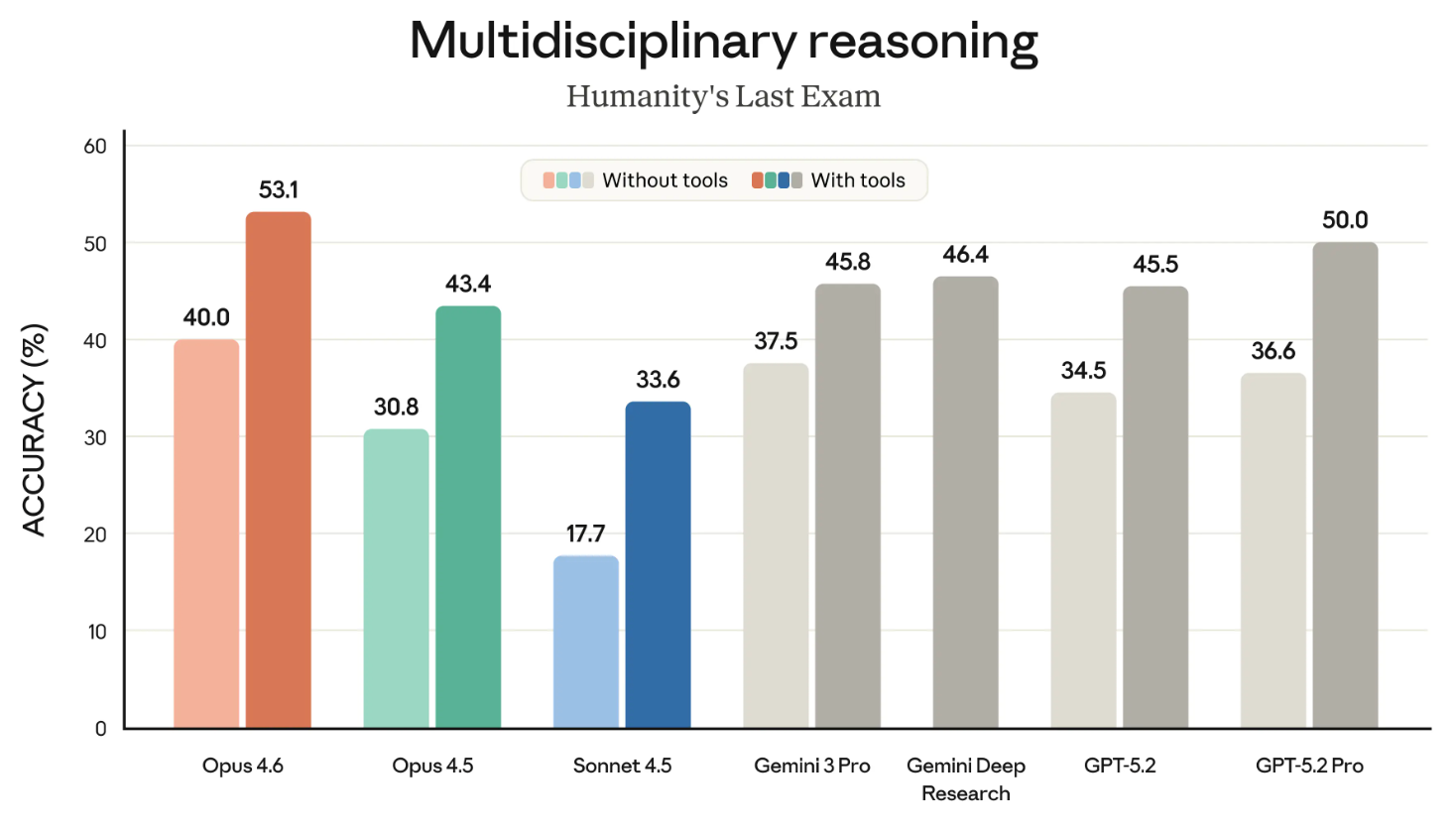
Humanity’s Last Exam ist einer der bekanntesten Benchmarks, den wir alle aufmerksam verfolgen. Er misst die allgemeine Schlussfolgerungsfähigkeit eines Modells.
Die nächste Grafik zeigt, wie die verschiedenen Spitzenmodelle im HLE-Benchmark mit und ohne Tools abschneiden. („Mit Tools“ bedeutet, dass das Modell externe Fähigkeiten wie Websuche oder Codeausführung nutzen durfte.)
Man könnte darüber streiten, ob zwei Grafiken besser wären. Dennoch ist die Botschaft klar: Opus 4.6 führt sowohl „mit Tools“ als auch „ohne Tools“.
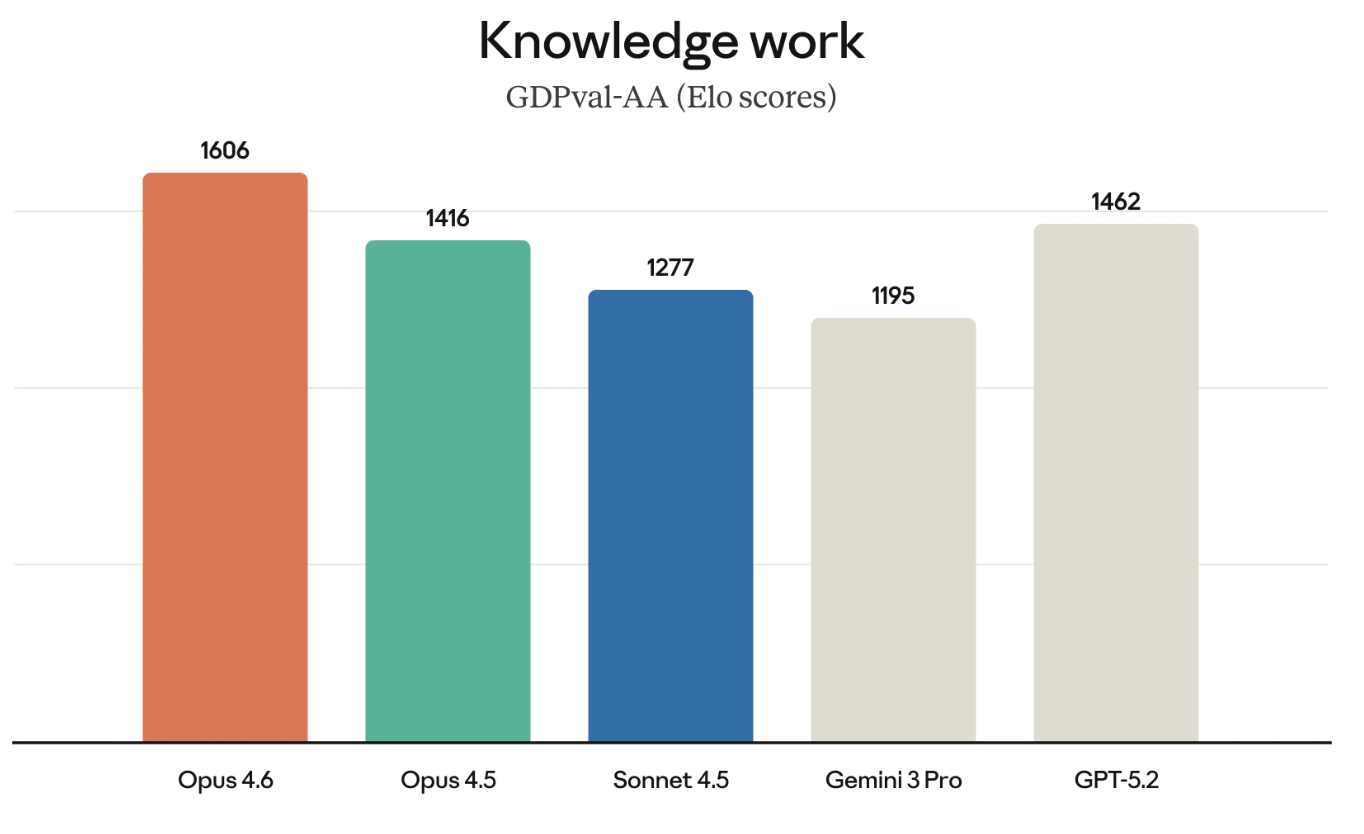
GDPval-AA (der Name verrät es) misst wirtschaftlich wertvolle Wissensarbeit – etwa Finanzmodelle bauen oder Recherchen durchführen.
GDPval-AA und ähnliche Benchmarks werden immer wichtiger, weil sie genau die Arbeit messen, für die Unternehmen tatsächlich zahlen. Der Erfolg von Opus 4.6 bei GDPval-AA ist zudem eine direkte Herausforderung für die GPT-Modellreihe, da OpenAI und Anthropic um viele der gleichen Kunden konkurrieren.
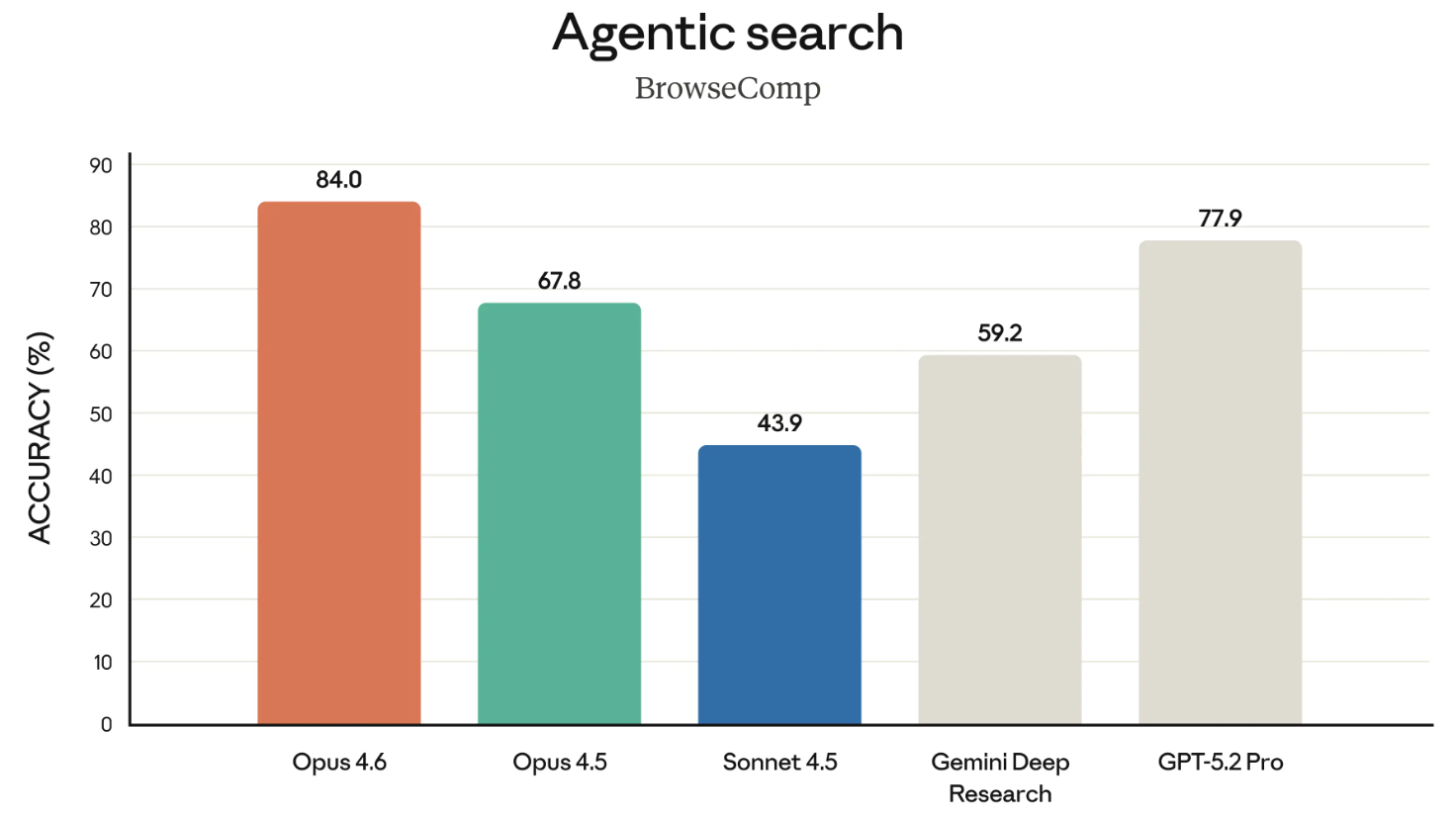
BrowseComp ist der letzte erwähnenswerte Benchmark in diesem Release. Er misst die Fähigkeit eines Modells, schwer auffindbare Informationen im Netz aufzuspüren. Zur Einordnung: OpenAI hat BrowseComp ursprünglich entwickelt, um die Suchfähigkeiten der eigenen Modelle zu demonstrieren.
In einem deutlichen Seitenhieb hat Anthropic im Release direkt auf OpenAIs Ankündigung von April 2025 zur Entwicklung von BrowseComp verlinkt – und gleichzeitig hervorgehoben, dass Opus 4.6 dort an der Spitze liegt. Ein kleiner, aber spitzer Move: OpenAIs eigenen Benchmark gegen sie zu zitieren.
Opus 4.6 ist zum Zeitpunkt dieses Artikels breit verfügbar. Allerdings brauchst du ein Pro-Abo, um Opus 4.6 zu nutzen – das bringt weitere Vorteile mit sich, etwa die Nutzung von Claude in Excel.
Wenn du entwickelst, nutze in der Claude API das Modell claude-opus-4-6. Die Preise bleiben unverändert: weiterhin $5/$25 pro Million Tokens. Falls dich die zwei Zahlen verwirren: Die erste ist der Preis für die Tokens, die du an das Modell sendest (also deine Prompts), die zweite für die Tokens, die das Modell zurückgibt (die Antworten).
Claude Opus 4.6 führt wichtige Benchmarks wie GPDVal-AA an – also genau die Messlatten für wirtschaftlich relevante Aufgaben, auf die große Enterprise-Kunden schauen. OpenAI dürfte das nervös machen, denn nur Stunden vor dem Opus-4.6-Release kündigten sie OpenAI Frontier an – eine neue Enterprise-Plattform zum Entwickeln, Ausrollen und Managen von KI-Agenten in der Produktion.
Mit anderen Worten: Statt auf Modell-Benchmarks zu setzen, zeigt Frontier, dass OpenAI den Fokus auf die Infrastruktur rund um die Modelle legt – etwa gemeinsamer Geschäftskontext für Agenten, Berechtigungen sowie die Fähigkeit, Feedback über die Zeit zu verarbeiten und daraus zu lernen. Während die Benchmarks wackeln, signalisiert OpenAI: Die Plattform mache Agenten im Unternehmen tatsächlich nützlicher.
Ob das ein strategischer Schwenk ist oder ein stilles Eingeständnis, im Modellrennen zurückzufallen – das entscheidest du.
Insgesamt sind wir von Anthropics Angebot mit Claude Opus 4.6 beeindruckt – und freuen uns darauf, Agententeams praktisch auszuprobieren. Wenn du mehr über die Claude-Familie lernen willst, schau dir unbedingt den Kurs Introduction to Claude Models an.
Lerne KI mit DataCamp
Kurs
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Tutorial
Matt Crabtree
Tutorial
Derrick Mwiti