
programa
Desarrollar grandes modelos lingüísticos
16 h
Imagina que le cuentas una larga historia a un amigo, solo para darte cuenta de que se ha olvidado del principio cuando llegas al momento culminante. Esta frustración es exactamente lo que ocurre cuando una IA se queda sin «memoria a corto plazo», lo que te obliga a descartar detalles cruciales para dejar espacio a otros nuevos.
En el mundo de los modelos de lenguaje grandes (LLM), esta capacidad de atención viene definida por la ventana de contexto.
A medida que los modelos se vuelven más potentes y el tamaño de los contextos aumenta, comprender cómo funcionan estas ventanas se convierte en un factor clave para crear sistemas de IA fiables y escalables. En esta guía, repasaremos los conceptos básicos de las ventanas contextuales, las ventajas e inconvenientes de ampliarlas y las estrategias para utilizarlas de forma eficaz.
Para ir más allá de la teoría y aprender a gestionar los límites del contexto en aplicaciones reales de Python, consulta nuestro curso Desarrollo de aplicaciones LLM con LangChain.
La ventana de contexto de un modelo de IA determina la cantidad de texto que puede almacenar en su memoria de trabajo mientras genera una respuesta. Limita la duración de una conversación sin olvidar detalles de interacciones anteriores.
Se puede considerar como la memoria a corto plazo de un ser humano. Almacena temporalmente información de conversaciones anteriores para utilizarla en la tarea que se está realizando.

Las ventanas contextuales afectan a diversos aspectos, como la calidad del razonamiento, la profundidad de la conversación y la capacidad del modelo para personalizar las respuestas de forma eficaz. También determina el tamaño máximo de entrada que puedes procesar a la vez. Cuando un contexto de conversación o una indicación supera ese límite, el modelo trunca (corta) las primeras partes del texto para dejar espacio.
Para tener una idea más clara de lo que esto significa exactamente, veamos algunos conceptos básicos que subyacen a los modelos de IA y las ventanas de contexto.
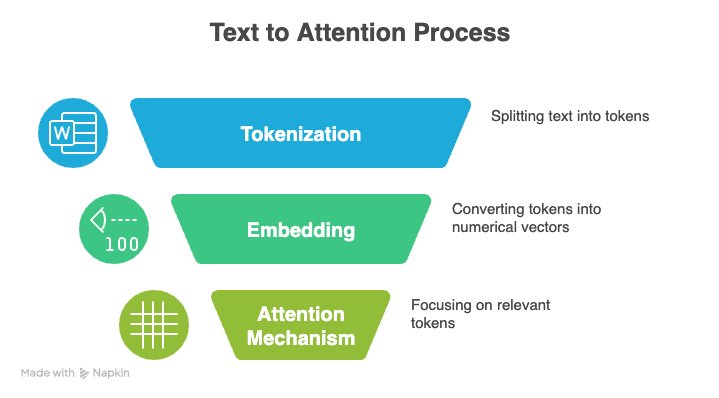
Hay tres conceptos fundamentales que subyacen a los LLM: la tokenización, el mecanismo de atención y la codificación posicional.
La tokenización es el proceso de convertir texto sin formato en una secuencia de unidades más pequeñas, o tokens, que un LLM puede procesar. Estos tokens pueden representar palabras completas, caracteres individuales o incluso sílabas parciales. En conjunto, el conjunto completo de tokens únicos que reconoce un modelo se denomina su vocabulario.
Por ejemplo, la frase «Hola, mundo» podría tokenizarse en [“Hello”, “,”, “ world”].
Durante el entrenamiento o la inferencia, cada token se convierte en un número entero único, y el modelo lee estos números en lugar del texto original. Analiza la secuencia numérica, aprende cómo se relacionan los tokens entre sí y genera nuevo texto prediciendo el siguiente token probable.
La tokenización eficiente juega un papel importante en la cantidad de información que cabe en la ventana de contexto de un modelo. Cuando un tokenizador puede representar texto con menos tokens, cabe más contenido en la misma ventana.
Los tokenizadores que representan palabras o frases comunes como tokens únicos son especialmente eficaces porque reducen el recuento de tokens, lo que permite al modelo manejar documentos más largos dentro de sus límites contextuales.
El llamado mecanismo de atención es otra de las bases de los LLM modernos. Ayuda a un modelo a centrarse en las partes más relevantes de su entrada al generar una salida.
En lugar de tratar todos los tokens por igual, el modelo compara la representación actual con todas las demás representaciones de tokens y asigna una puntuación a cada comparación. Esta ponderación selectiva permite al modelo procesar secuencias largas y comprender el contexto de forma más eficaz.
La atención se basa en tres componentes: Consultas, claves y valores.
Consultas: La señal enviada por el token actual para «buscar» información relevante en el resto de la secuencia.
Claves: El identificador de cada token de la secuencia que determina en qué medida coincide con la señal de búsqueda.
Valores: El contenido informativo real que se recupera y utiliza cuando se encuentra una coincidencia entre una consulta y una clave.
El modelo calcula puntuaciones de similitud entre consultas y claves, convierte esas puntuaciones en pesos utilizando la función de activación softmax y, a continuación, genera el resultado final como una suma ponderada de los valores.
La autoatención compara el token actual con todos los demás tokens de la secuencia. Esto genera un coste computacional cuadrático: duplicar la ventana de contexto cuadruplica la potencia de procesamiento y la memoria necesarias.
A medida que las ventanas de contexto se amplían, esto se vuelve rápidamente costoso, por lo que los modelos se basan en optimizaciones como la atención dispersa, la aproximación de rango bajo o la fragmentación para mantener el cálculo manejable.
Los transformadores, que alimentan los modelos lingüísticos modernos, no comprenden de forma natural el orden de los tokens. En su lugar, se basan en la codificación posicional para incorporar esta información.
La codificación posicional añade una pequeña señal a cada token que ayuda al modelo a comprender la distancia y la disposición relativa.
El método específico de información posicional también define hasta qué punto el modelo puede programar de forma fiable las relaciones dentro de una secuencia, lo que determina el tamaño y la eficacia de su ventana de contexto. Comparemos algunos métodos populares:
Incrustaciones posicionales absolutas: El modelo aprende un vector independiente para cada posición de la secuencia, como si se le asignara una dirección fija a cada token. Esto funciona para secuencias más cortas, pero el modelo no puede manejar posiciones más allá de aquellas con las que fue entrenado, lo que dificulta la ampliación de la ventana de contexto.
Codificaciones sinusoidales: Las posiciones se codifican utilizando ondas sinusoidales y cosinusoidales repetidas, que dan a cada token un patrón único basado en su ubicación. Generalizan mejor a longitudes no vistas que las incrustaciones absolutas, aunque se vuelven menos estables con secuencias extremadamente largas.
Codificaciones posicionales relativas: En lugar de marcar posiciones exactas, el modelo aprende la distancia entre los tokens. Esto ayuda a generalizar secuencias más largas, pero el límite del contexto general sigue dependiendo de la arquitectura y la memoria del modelo.
Incrustaciones posicionales rotativas (RoPE): RoPE codifica la posición girando la representación vectorial de cada token en función de su posición absoluta, calculando la distancia con respecto a otros tokens. Este método se mantiene estable a medida que las secuencias crecen y admite ventanas de contexto mucho más grandes.
ALiBi (sesgos lineales de atención): ALiBi aplica un sesgo simple basado en la distancia dentro del mecanismo de atención, por lo que los tokens más cercanos reciben naturalmente un peso mayor. Se adapta bien a secuencias largas.
Te recomiendo que consultes este tutorial sobre cómo funcionan los transformadores para obtener una descripción detallada.
Si el contexto excede la ventana de contexto, el modelo puede truncar o ignorar las partes más antiguas, lo que podría provocar la pérdida de contexto importante. Por eso, los investigadores experimentan continuamente con nuevas técnicas para superar estos límites y permitir ventanas de contexto más largas.
Hasta 2022, los modelos GPT de OpenAI dominaban el panorama. El primer modelo GPT, lanzado en 2018, admitía una ventana de 512 tokens. Las dos versiones siguientes, en 2019 y 2020, duplicaron ese límite, alcanzando los 2048 tokens para GPT-3. Los modelos sucesivos siguieron ampliando estos límites hasta alcanzar un millón de tokens (GPT-4.1).
Recientemente, OpenAI se vio superada o incluso adelantada por la competencia. Las versiones Gemini 2.5 y 3 Pro de Google se ajustan a este tamaño de ventana de hasta un millón de tokens, lo que permite procesar libros completos, grandes bases de código y cargas de trabajo de múltiples documentos en una sola pasada.
La serie Claude Sonnet 4.5 de Anthropic está probando actualmente el mismo tamaño de ventana de contexto en la versión beta, ampliándolo desde su tamaño original de 200 000 tokens.
Las familias de modelos de código abierto como Llama y Mistral suelen situarse en el rango de 100 000 a 200 000, lo que ofrece un rendimiento respetable en contextos largos, al tiempo que siguen siendo prácticas para implementar localmente o ajustar con precisión.
Entre las excepciones más destacadas se encuentra Llama Maverick, que admite una ventana de 1 millón de tokens diseñada para el razonamiento de propósito general en documentos largos. Mientras tanto, Llama Scout amplía aún más los límites con una enorme capacidad de 10 millones de tokens, diseñada específicamente para procesar bases de código completas o archivos legales en una sola pasada.
Sin embargo, el lanzamiento de GPT-5.2 esta misma semana ha supuesto un cambio de estrategia. En lugar de perseguir un contexto infinito, OpenAI limitó su nuevo buque insignia a una ventana de 400 000 tokens, cambiando el tamaño bruto por una «memoria perfecta» y unas capacidades de razonamiento superiores que evitan los problemas de distracción habituales en los modelos más grandes.
Las diferencias en el tamaño de la ventana de contexto determinan el rendimiento de cada modelo en flujos de trabajo reales. Las ventanas de contexto ampliadas potencian modelos con gran precisión, coherencia y razonamiento de largo alcance, pero también requieren más cálculos y una selección más cuidadosa del contexto.
Los modelos de gama media siguen siendo eficientes y permiten gestionar documentos largos y chats extensos, aunque necesitan la estructura adecuada para entradas muy grandes.
Los siguientes casos de uso destacan cómo las ventajas de los modelos con ventanas de contexto amplias se manifiestan en aplicaciones del mundo real.
Con espacio suficiente para almacenar informes completos, transcripciones, bases de código o trabajos de investigación de una sola vez, un modelo puede rastrear patrones, conectar detalles distantes y mantener una comprensión coherente de principio a fin. Esto ofrece muchos campos de aplicación:
Law: Las ventanas grandes permiten a los modelos analizar contratos completos, comparar cláusulas en varios documentos y programar referencias ocultas en documentos largos.
Atención sanitaria: Los equipos pueden revisar largas guías clínicas, historiales de pacientes o conjuntos de datos de múltiples estudios, conservando al mismo tiempo el contexto importante que se perdería en ventanas más pequeñas.
Investigación: Un modelo de ventana grande puede leer artículos completos y reseñas bibliográficas de una sola vez y detectar conexiones superficiales que solo aparecen cuando se ve el documento completo.
Las ventanas de contexto más grandes hacen que la IA conversacional resulte más natural, ya que el modelo puede recordar más parte de la conversación sin olvidar los mensajes anteriores.
En el servicio al cliente, esto conduce a interacciones más fluidas y personalizadas. El modelo puede utilizar preferencias pasadas y conversaciones anteriores para ofrecer respuestas más precisas y relevantes.
Las ventanas de contexto ampliadas permiten realizar razonamientos complejos entre texto, audio e imágenes, ya que proporcionan al modelo espacio suficiente para albergar todas las modalidades juntas, en lugar de procesarlas de forma aislada.
Cuando la transcripción completa, los fotogramas visuales y el material escrito relacionado caben en una sola ventana, el modelo puede comparar detalles entre formatos, rastrear relaciones y construir una comprensión unificada del contexto.
Esto elimina las lagunas que aparecen cuando la información debe fragmentarse o resumirse y permite que el modelo razone sobre todo el conjunto de entradas a la vez.
Las ventanas de contexto grandes desbloquean potentes capacidades de modelo, pero también introducen nuevos retos de rendimiento a medida que aumenta el tamaño de las entradas. Incluso los modelos avanzados tienen dificultades para mantener una atención perfecta a lo largo de secuencias extremadamente largas, por lo que no siempre utilizan la información de todas las partes del contexto con la fiabilidad que cabría esperar.
Un problema habitual en los modelos de contexto largo es el efecto «pérdida en el medio». Los modelos recuerdan bastante bien el principio y el final de una secuencia larga, pero a menudo se pierden o ignoran detalles importantes que se encuentran en el medio. Esto puede dar lugar a respuestas menos precisas, incluso cuando se dispone de todo el contexto.
Estructurar la entrada de forma inteligente ayuda a evitar este problema en tareas importantes. Esto significa dividirlo en secciones claras o repetir los puntos clave para que el modelo no los pase por alto.
Los costes pueden aumentar rápidamente al aumentar el tamaño de la ventana de contexto. Cada token adicional aumenta el tamaño del cálculo de atención, lo que incrementa el tiempo de inferencia, los requisitos de memoria de la GPU y la carga general del sistema.
Para gestionar esto, se necesitan formas más eficaces de alimentar la información del modelo. Técnicas como la recuperación selectiva, la fragmentación jerárquica o los resúmenes rápidos ayudan a reducir la cantidad de información introducida, de modo que el modelo no se sobrecargue.
Las ventanas grandes también plantean problemas relacionados con la seguridad y la privacidad. Cuando proporcionas más información al modelo, hay más posibilidades de que se expongan datos confidenciales.
Por eso, los equipos necesitan reglas sólidas para el manejo de datos, pasos de redacción y controles de acceso para garantizar que las ventanas de contexto grandes no generen nuevos riesgos.
En muchos casos, la información innecesaria o poco relevante aumenta la carga cognitiva del modelo, lo que eleva el riesgo de alucinaciones y patrones incorrectos. Las entradas largas también introducen ruido que puede distorsionar la comprensión de la tarea por parte del modelo.
En la práctica, un rendimiento de alta calidad suele derivarse de un contexto cuidadosamente seleccionado, lo que garantiza que el modelo vea la información adecuada en lugar de simplemente estar expuesto a la mayor cantidad de información posible.
Se pueden emplear varios métodos para aprovechar al máximo las ventanas de contexto. Entre ellas se encuentran la generación aumentada por recuperación (RAG), la ingeniería de contexto, la fragmentación y la selección de modelos.
La generación aumentada por recuperación (RAG) funciona extrayendo información adicional de una base de datos externa y alimentándola al modelo siempre que se necesita contexto.
En lugar de introducir documentos completos en la ventana de contexto, RAG almacena todo por separado y solo recupera las partes que son relevantes para la pregunta actual. Esto mantiene el contexto reducido, al tiempo que proporciona al modelo toda la información que necesita.
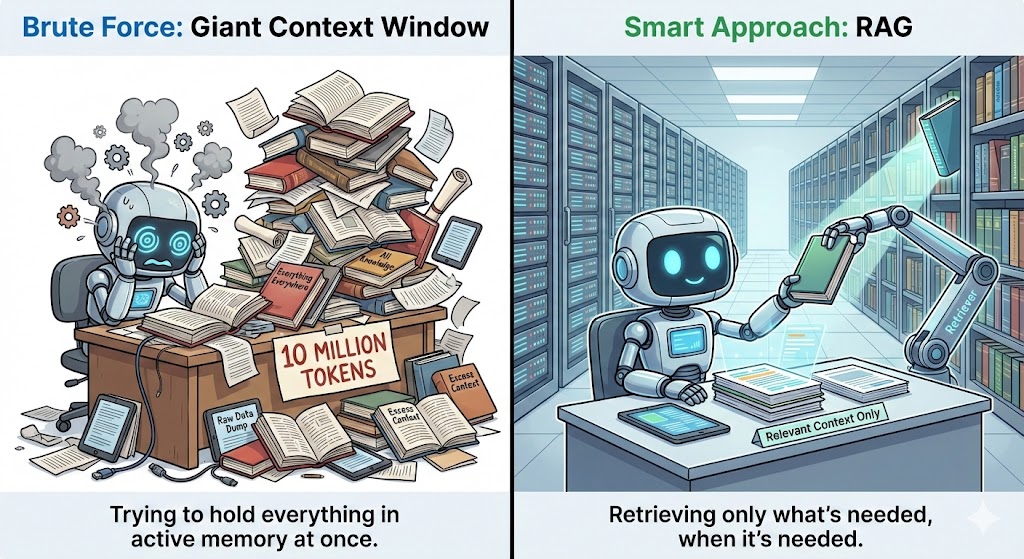
Para ello, utiliza incrustaciones o búsquedas vectoriales para encontrar los fragmentos más relevantes y los envía al modelo de forma clara y estructurada. Esto aumenta la precisión al garantizar que el modelo pueda utilizar información adicional relevante más allá de tus datos de entrenamiento.
La ingeniería de contexto se centra en proporcionar a los modelos información relevante en lugar de abrumarlos con detalles innecesarios. Entre las estrategias eficaces se incluyen la segmentación de documentos largos, el resumen de secciones de escaso valor y el uso de pasos de preprocesamiento ligeros para resaltar los puntos principales.
La búsqueda semántica ayuda en este sentido, ya que identifica el texto que es relevante para la consulta actual. También puedes mejorar los resultados colocando la información más importante al principio o al final del contexto, ya que los modelos tienden a recordar mejor esos puntos.
La división en fragmentos divide los documentos largos en secciones más pequeñas y coherentes. La idea es agrupar el contenido en función de su tema, estructura o la tarea que respalda.
Esto mantiene la coherencia de cada fragmento y ayuda al modelo a mantenerse centrado, en lugar de perderse en un enorme bloque de texto. Si deseas obtener más información, no dudes en consultar este artículo sobre estrategias avanzadas de fragmentación.
La agrupación semántica agrupa oraciones que comparten un significado similar en lugar de dividir el texto en límites de caracteres aleatorios. Divide el contenido en puntos de ruptura naturales, como cambios de tema, transiciones entre párrafos o encabezados de sección.
La división en fragmentos basada en tareas va aún más allá, ya que cada fragmento se adapta a la pregunta específica que intentas responder. Cada sección contiene solo la información que es realmente relevante para esa tarea.
Las tareas que implican el análisis completo de documentos, el razonamiento con múltiples archivos o conversaciones prolongadas se benefician de modelos con ventanas en el rango de 200 000 a 1 millón. Para tareas más específicas, como resumir, revisar código o responder preguntas breves, los modelos de entre 100 000 y 200 000 suelen ofrecer el mejor equilibrio entre velocidad, coste y precisión.
Las ventanas más pequeñas pueden seguir funcionando bien cuando se combinan con sistemas de recuperación potentes. Un buen sistema RAG ( ) o protocolo de contexto de modelo (MCP) puede extraer lainformación adecuadabajo demanda, por lo que el modelo no necesita almacenar todo en su memoria.
Antes de terminar, echemos un vistazo a hacia dónde se dirige la tecnología en lo que respecta a las ventanas contextuales.
Las arquitecturas de los modelos futuros se están orientando hacia ventanas de contexto dinámicas, en lugar de ventanas de tamaño fijo.
Los investigadores están explorando enfoques que combinan las ventajas de los transformadores con nuevos sistemas de memoria de largo alcance, lo que da como resultado modelos que pueden almacenar y recuperar información sin depender únicamente de mecanismos de atención.
Estas arquitecturas superan los límites actuales al pasar de ventanas de contexto estáticas a capas de memoria dinámicas que crecen con la tarea.
Los sistemas de memoria son otra área de innovación. Se espera que los modelos futuros dependan más de sistemas de memoria sensibles al contexto que vayan más allá de una sola sesión y proporcionen continuidad a lo largo del tiempo.
En lugar de tratar cada conversación como un nuevo comienzo, estos sistemas almacenan preferencias clave, decisiones pasadas y temas recurrentes en una capa de memoria estructurada que puede recuperarse cuando sea relevante.
Esto hace que la personalización pase de ser reactiva a proactiva, lo que permite al modelo comprender a los usuarios de forma más holística y respaldar objetivos a largo plazo con mucha mayor coherencia.
La recuperación externa también está evolucionando. Actualmente, RAG funciona como un motor de búsqueda, extrayendo texto relevante en el indicador. Ya han aparecido versiones avanzadas como Corrective Retrieval-Augmented Generation (CRAG) (Recuperación correctiva y generación aumentada) d , pero eso es solo el principio.
En el futuro, la recuperación se percibirá como algo más integrado, casi como si el modelo tuviera su propia memoria externa. Recopilarán, comprimirán y volverán a mostrar la información automáticamente con una intervención mínima por parte de los usuarios.
La memoria persistente también cambiará la forma en que interactuamos con la IA. En lugar de olvidar todo cuando finaliza una sesión, el modelo recordará detalles importantes a lo largo de días, semanas o incluso meses. A medida que aprende tu estilo, hábitos y prioridades, puede ofrecerte respuestas más personalizadas y útiles, sin necesidad de que repitas lo mismo.
Herramientascomo Mem0 ya sony están liderando este enfoque, actuando como una capa de memoria dedicada entre las aplicaciones y los LLM. Sin embargo, de cara al futuro, esperamos ver más de estas capacidades integradas directamente en las arquitecturas de los modelos, en lugar de depender de capas externas.
Las ventanas más grandes permiten nuevos y potentes flujos de trabajo, pero también plantean retos de atención, mayores costes computacionales y riesgos de calidad cuando el contexto está sobrecargado. Esto hace que la gestión estratégica del contexto sea esencial.
Técnicas como el aumento de la recuperación, la fragmentación semántica y la ingeniería contextual ayudan a los modelos a mantenerse centrados, eficientes y fiables, incluso a medida que se amplían sus capacidades.
De cara al futuro, los mejores sistemas basados en LLM combinan herramientas inteligentes y una sólida comprensión de cómo el contexto afecta al razonamiento. Al aplicar estos principios, los equipos pueden aprovechar las ventajas de los modelos de contexto largo mientras se preparan para la próxima generación de arquitecturas que amplían aún más los límites del contexto.
Lleva tus conocimientos básicos de Python al siguiente nivel conel programa de habilidades «Desarrollo de modelos de lenguaje grandes » Está diseñado para guiarte desde el código básico hasta la creación y el ajuste de tus propias y potentes aplicaciones de IA.
Cursos de máster en Derecho
programa
Curso
Curso
blog
Stanislav Karzhev
9 min
blog
Ryan Ong
8 min
blog
Bhavishya Pandit
8 min
blog
Javier Canales Luna
14 min
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
