

Cours
Concepts d'IA générative
2 h
105.5K
Des rumeurs sur la prochaine sortie d’Anthropic bruissent depuis quelques jours. Beaucoup attendaient Claude Sonnet 5, mais la première sortie de l’année prend la forme de Claude Opus 4.6.
Avec une fenêtre de contexte d'un million de tokens, une réflexion adaptative, une compaction des conversations et une série de benchmarks au top, Claude Opus 4.6 améliore Opus 4.5. Pour reprendre les mots d’Anthropic, leur modèle le plus intelligent a été mis à niveau. En parallèle, Anthropic a lancé des « agent teams » dans Claude Code et Claude in PowerPoint.
Dans cet article, nous passons en revue toutes les nouveautés de Claude Opus 4.6 : les nouvelles fonctionnalités, les benchmarks, et des tests pratiques pour l’éprouver sur des cas concrets.
Pour approfondir certaines des dernières fonctionnalités de Claude, nous vous recommandons nos guides sur Claude Cowork et Claude Code, ainsi que notre tutoriel OpenClaw. Pour comparer avec d’autres acteurs, consultez nos guides Muse Spark vs Claude Opus 4.6 et GPT-5.4 vs Claude Opus 4.6.
Claude Opus 4.6 est le dernier grand modèle de langage d’Anthropic. Successeur de Opus 4.5, il constitue une évolution majeure de la gamme de modèles dits « les plus intelligents » de l’entreprise.
D’après l’article de lancement, Anthropic met l’accent sur le codage agentique, le raisonnement approfondi et l’auto-correction. Autrement dit, il s’agit de passer d’une réponse ponctuelle à une action soutenue.
Opus 4.6 est conçu pour planifier avec plus de soin, maintenir une meilleure cohérence sur la durée et détecter ses propres erreurs. Résultat : Claude Opus 4.6 arrive en tête de plusieurs benchmarks, notamment le meilleur score sur l’évaluation de codage Terminal-Bench 2.0, et surpasse tous les autres modèles de pointe sur Humanity’s Last Exam.
L’une des améliorations qui m’a le plus marqué est la fenêtre de contexte de Claude Opus 4.6. Avec 1 million de tokens en bêta, ce nouveau modèle se met au niveau de Gemini 3, ce qui lui permet d’ingérer plus d’infos sans perdre le fil du contexte.
Entre-temps, Anthropic a publié la version suivante d’Opus. Nous vous conseillons de lire notre guide Claude Opus 4.7 pour rester à jour.
Plusieurs nouvelles fonctionnalités méritent l’attention, dont beaucoup tournent autour des workflows agentiques. Voici les points clés :
Les agent teams constituent une évolution des « sous-agents » que nous avions vus dans les versions précédentes de Claude. Elles permettent de lancer plusieurs instances de Claude, pleinement indépendantes, travaillant en parallèle. Une session joue le rôle d’agent « leader » qui coordonne, tandis que les « coéquipiers » exécutent.
Point intéressant : chaque membre de l’équipe dispose de sa propre fenêtre de contexte, ce qui permet une exécution plus fouillée. Chaque coéquipier peut également communiquer directement avec les autres.
Cette fonctionnalité a toutefois un revers potentiel : le coût. Puisque chaque agent a sa propre fenêtre de contexte, la consommation de tokens peut grimper vite. Anthropic recommande donc de les utiliser pour des scénarios à forte complexité.
La compaction de contexte est une fonctionnalité astucieuse de Claude Opus 4.6. Ce confort d’usage évite les problèmes quand vous exécutez de longs workflows qui saturent la fenêtre de contexte. En général, on atteint une limite où les performances se dégradent.
Avec la compaction des conversations, Claude Opus 4.6 détecte automatiquement quand un échange approche d’un seuil de tokens et résume l’historique en un bloc concis (un « compaction block »).
Cette fonction préserve l’essentiel de vos interactions tout en libérant de la place pour continuer. Si vous prévoyez d’utiliser des agents orientés tâches sur la durée, elle peut les aider à rester dans le bon cadre avec une mémoire nettement améliorée.
Deux paramètres de Claude Opus 4.6 décident s’il doit recourir à une réflexion étendue, et à quel niveau d’effort.
La réflexion adaptative permet au modèle d’évaluer la complexité de votre invite. Selon qu’elle est simple ou complexe, il choisira d’activer ou non la réflexion étendue. Plutôt qu’un réglage manuel du volume de tokens utilisés, Claude ajuste son budget en fonction de la difficulté de chaque demande.
Le paramètre d’effort vous permet de définir à quel point Claude est enclin ou prudent dans sa dépense de tokens. En clair, vous arbitrez entre efficacité de tokens et profondeur des réponses.
Dans l’API, vous pouvez régler ces paramètres manuellement. Par exemple :
Nous avons récemment présenté Claude in Excel, en montrant comment le complément peut vous aider dans un panneau latéral de votre feuille Excel. En plus d’améliorer cet outil, Anthropic annonce Claude in PowerPoint.
L’intégration respecte vos masques, polices et mises en page. Vous pouvez lui fournir un modèle d’entreprise et lui demander de construire une section spécifique, ou sélectionner une diapositive et lui demander de transformer un texte dense en un diagramme natif et modifiable.
L’accent mis sur la génération d’objets PowerPoint modifiables plutôt que de simples « images de slides » en fait un véritable outil de productivité, et pas seulement un générateur d’idées.
Claude in PowerPoint est actuellement en préversion de recherche pour les utilisateurs Max et Enterprise.
Nombre des promesses phares d’Opus 4.6 portent sur des tâches de codage plus ardues et un raisonnement plus profond. Ces compétences reposent sur un socle : garder plusieurs contraintes en tête, raisonner en plusieurs étapes et repérer les erreurs.
Dans cet esprit, nous avons soumis Opus 4.6 à une série de défis de logique multi-étapes, de maths et de codage. Objectif : mettre au jour des faiblesses connues des LLM – erreurs de calcul en cascade, raisonnement spatial (souvent problématique), et questions à contraintes. Nous avons aussi inclus une tâche de débogage, Anthropic vantant la capacité d’Opus 4.6 en analyse de cause racine et autres problèmes de debug.
Premier test : nombres premiers, hexadécimal et comptage :
Step 1: Find the 6th prime number. Let this be P.
Step 2: Convert the square of P into hexadecimal.
Step 3: Count the letters (A–F) and digits (0–9) in that hex string. Let these be A and B.
Step 4: Multiply A × B. Let this be N.
Step 5: Find the Nth prime number.Cela semble un peu complexe, mais ce test est facile à vérifier pour nous humains. La bonne réponse est 2, car le 6e nombre premier est 13 ; 13 au carré donne 169, soit « A9 » en hexadécimal. On compte 1 lettre × 1 chiffre, soit 1 ; le 1er nombre premier est 2.
Le risque, c’est qu’un modèle se trompe dans la conversion hexadécimale, ce qui entraîne une erreur finale. Comme vous le voyez, Opus 4.6 n’a rencontré aucune difficulté :

Deuxième test : raisonnement spatial et gestion des nombres négatifs :
Step 1: Create a 2×2 matrix M with top row [4, 2] and bottom row [1, 5].
Step 2: Rotate M 90 degrees clockwise.
Step 3: Calculate the determinant of the rotated matrix.
Step 4: Cube that determinant.
Step 5: Subtract the 13th Fibonacci number from the result.La vérification a demandé un peu plus de travail. La bonne réponse est -6 65. La matrice tournée est [[1, 4], [5, 2]] ; on calcule ensuite le déterminant avec Python, qui vaut -18 ; en l’élevant au cube, on obtient -5 832 ; enfin on soustrait 233 pour obtenir -6 65.
Nous aimions ce test car les modèles échangent souvent mal des éléments de matrice ou perdent le signe négatif en route. Encore une fois, Opus 4.6 n’a pas bronche :

Troisième test : un problème de satisfaction de contraintes avec retour en arrière :
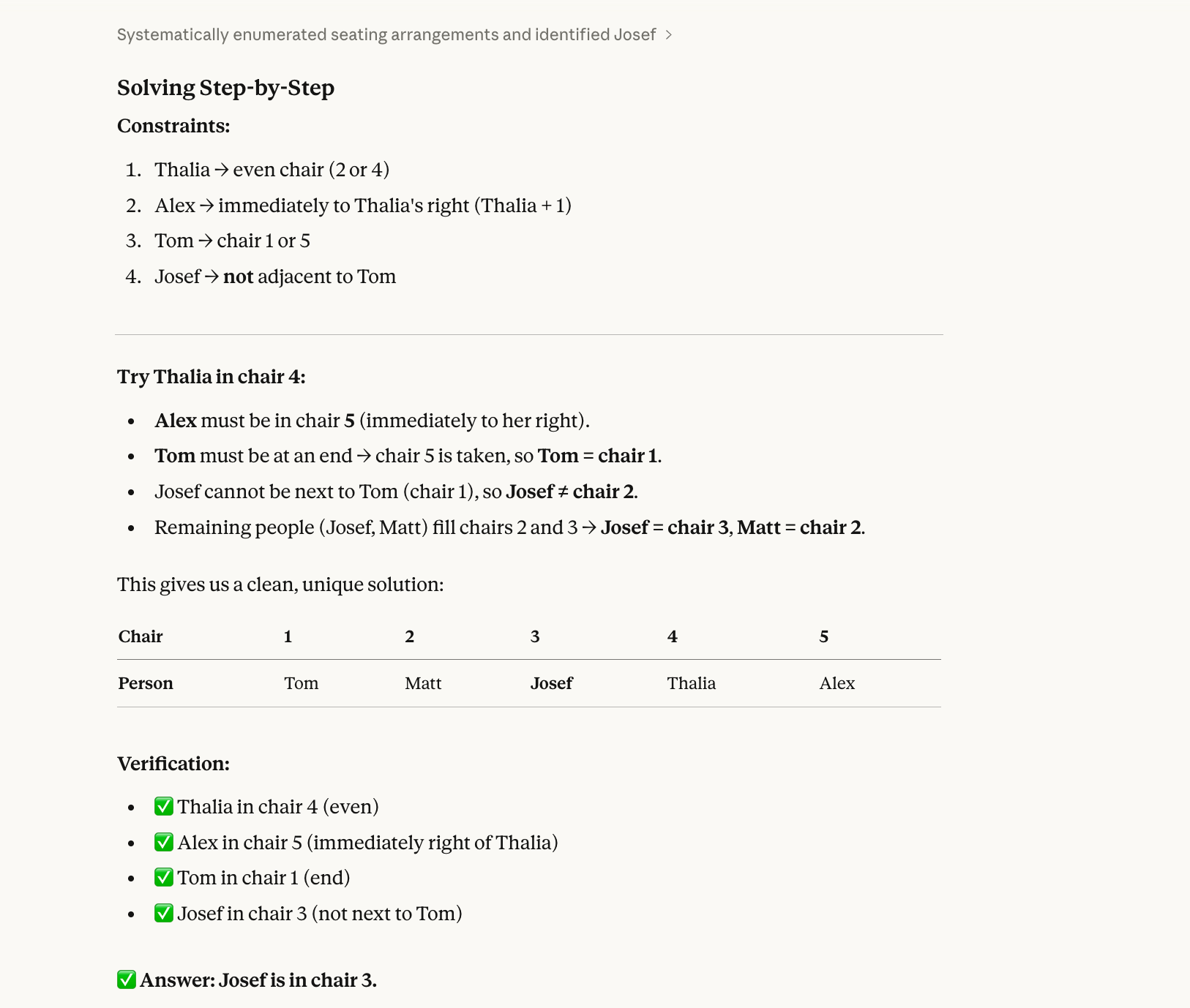
Five people (Alex, Josef, Matt, Thalia, Tom) sit in chairs 1–5.
Thalia is in an even-numbered chair.Alex is immediately to Thalia’s right.Tom is at one end.Josef is not next to Tom.Who is in chair 3?La réponse correcte est Josef. (Alex-1, Matt-2, Josef-3, Thalia-4, Tom-5.) On peut la trouver au crayon-papier avec un peu d’effort.
Historiquement, les modèles résolvent ce type de question de manière séquentielle, pas holistique. Ils lisent « Thalia est sur une chaise paire », en choisissent une (disons la 2) sans vérifier si ce choix respecte le reste. Ils s’y engagent, remplissent d’autres chaises, puis butent plus loin et n’envisagent pas de tenter la chaise 4 pour Thalia.
Opus 4.6 a aussi trouvé la bonne réponse :
Quatrième test : visualisation spatiale et intuition physique :
Step 1: Imagine a clock currently showing 3:15 PM.
Step 2: Rotate the clock 90 degrees counter-clockwise (physically turning the whole clock face). After the rotation, what time does the minute hand appear to be pointing at?
Step 3: Take that new "apparent" minute value and add it to the original time (3:15 PM).
Step 4: Subtract 45 minutes from that result.
Step 5: What is the final time?Pour le vérifier, j’ai littéralement tourné ma montre.
La réponse correcte est 14 h 30. À 3 h 15, l’aiguille des minutes pointe sur le « 3 ». En tournant le cadran de 90° vers la gauche, le « 3 » se retrouve à la place du « 12 ». J’ai ajouté 0 à 3 h 15, puis soustrait 45 minutes : on obtient 14 h 30.
En conçevant ce test, nous pensions que les modèles confondraient rotation du cadran et déplacement des aiguilles. On a aussi observé qu’ils suspectent l’ajout de 0 et « forcent » une autre valeur.
Pourtant, Opus 4.6 a également réussi :

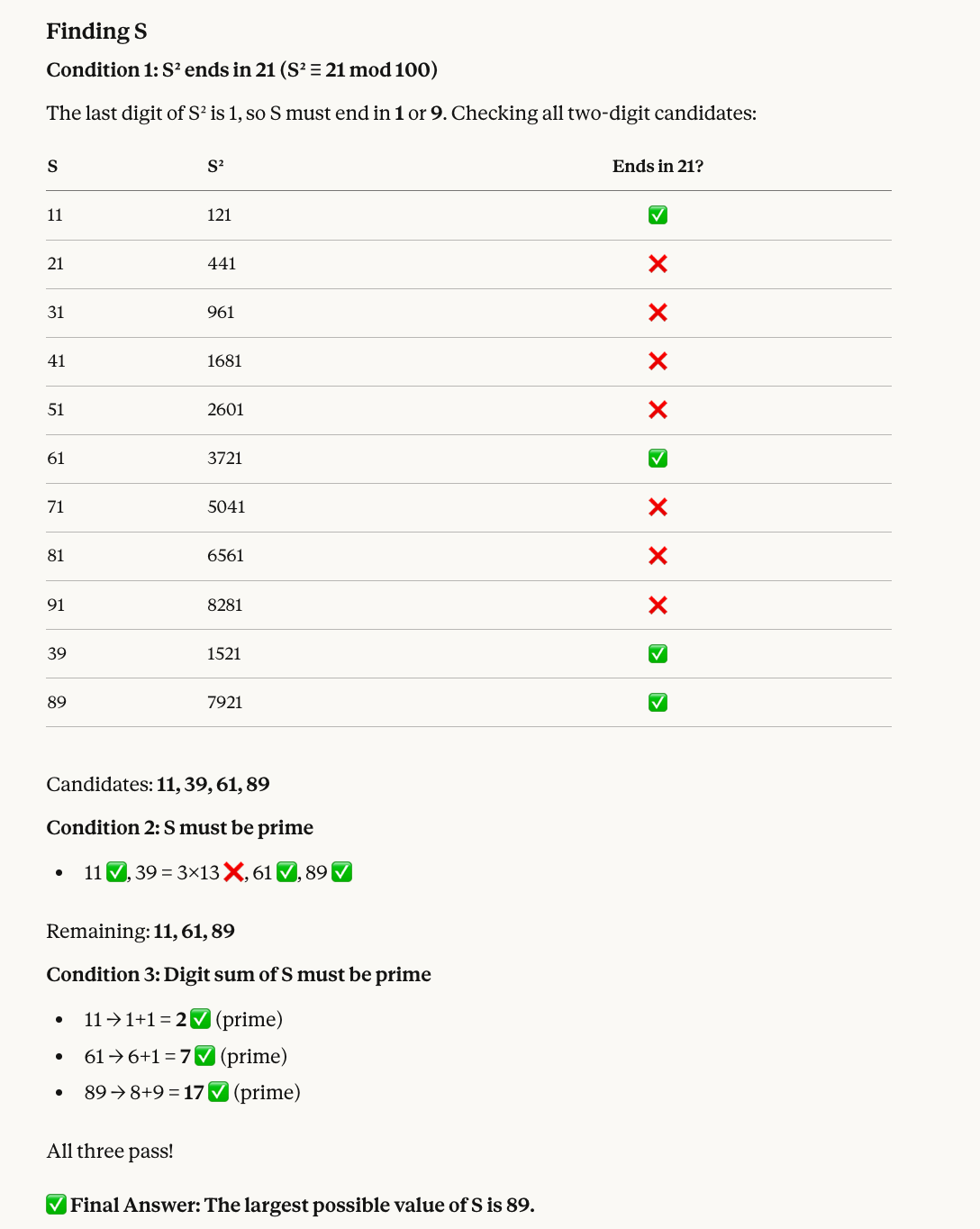
Cinquième test : arithmétique modulaire et filtrage par primalité :
Find a two-digit number S that satisfies all of the following:
* When S is squared, the last two digits of the result are 21.
* S must be a prime number.
* The sum of the digits of S must also be a prime number.
What is the largest possible value of S?Voici pourquoi la bonne valeur est 89 : les nombres dont le carré finit par 21 comprennent 11, 39, 61 et 89. 39 n’est pas premier ; restent 11, 61 et 89. La somme de leurs chiffres est aussi première (2, 7 et 17), donc le plus grand est 89.
Opus 4.6 a une nouvelle fois donné la bonne réponse, avec au passage un visuel utile :
Test suivant : factorielle, manipulation de chaînes et nombres premiers :
Step 1: Calculate 5! (5 factorial). Let this result be X.
Step 2: Take X, subtract 1, and reverse the digits of the result. Let this new number be Y.
Step 3: Identify all prime numbers (p) such that 10 ≤ p ≤ Y.
Step 4: Calculate the sum of these primes and divide it by the total count of primes found in that range.
Step 5: Provide the final average, rounded to the nearest whole number.Voici comment nous avons vérifié que 425 est correct : 5! = 120 ; on soustrait 1 pour obtenir 119 ; on inverse les chiffres → 911. Avec un peu de code R (ci-dessous), nous avons trouvé 152 nombres premiers entre 10 et 911, pour une somme de 64 598. Enfin, on divise et on arrondit : 64 598 ÷ 152 ≈ 425.

Voici le script R utilisé :
# Step 1: Calculate 5!
X <- factorial(5)
cat("Step 1: X =", X, "\n")
# Step 2: Subtract 1 and reverse digits
result <- X - 1
Y <- as.numeric(paste0(rev(strsplit(as.character(result), "")[[1]]), collapse = ""))
cat("Step 2:", X, "- 1 =", result, "-> reversed ->", Y, "\n")
# Step 3: Find all primes between 10 and Y
is_prime <- function(n) {
if (n < 2) return(FALSE)
if (n == 2) return(TRUE)
if (n %% 2 == 0) return(FALSE)
for (i in 3:floor(sqrt(n))) {
if (n %% i == 0) return(FALSE)
}
return(TRUE)
}
primes <- Filter(is_prime, 10:Y)
cat("Step 3: Found", length(primes), "primes between 10 and", Y, "\n")
# Step 4: Sum and average
total <- sum(primes)
count <- length(primes)
avg <- total / count
cat("Step 4: Sum =", total, ", Count =", count, ", Average =", avg, "\n")
# Step 5: Round
cat("Step 5: Rounded =", round(avg), "\n")Test suivant : l’un des grands arguments d’Opus 4.6 : diagnostiquer des bugs de code. Les modèles tracent souvent correctement le code ligne à ligne, mais ne relient pas ce traçage à la vraie cause du problème.
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!Voici la réponse et pourquoi ce test est pertinent : la fonction divise toujours par window (3), même lorsque le segment n’a que 1 ou 2 éléments en début de liste. La sortie erronée est [3.33, 10.0, 20.0, 30.0, 40.0], alors que les deux premières valeurs devraient être 10.0 et 15.0, puisque ces segments contiennent respectivement 1 et 2 éléments. La correction consiste à remplacer / window par / len(chunk).
Nous aimons ce test parce que les modèles tracent souvent la boucle parfaitement, puis concluent que « la sortie a l’air correcte » – ils voient le calcul étape par étape sans signaler que diviser un seul élément par 3 est faux. Il faut maintenir l’intention (ce que doit faire une moyenne glissante) en regard de l’exécution (ce que fait le code) et repérer l’écart.

Dernier test : pas de maths, mais du raisonnement contrefactuel.
In a world where gravity repels objects instead of attracting them, what shape would rivers take?Certes, il n’y a pas de réponse unique, et l’exercice est difficile à se représenter. Mais nous cherchons au moins un raisonnement sur les conséquences, et la réponse de Claude Opus 4.6 nous paraît tout à fait plausible.
Bref, Opus 4.6 réalise un sans-faute, même si l’une des questions comportait une part de subjectivité – à vous de juger.

Opus 4.6 domine sans conteste au moins quatre benchmarks importants :
Terminal-Bench 2.0 évalue le codage agentique ; Humanity’s Last Exam mesure le raisonnement complexe ; GDPval-AA teste la performance sur des tâches de connaissance à forte valeur économique ; BrowseComp mesure la capacité du modèle à trouver en ligne des informations difficiles à dénicher.
Les modèles Claude ont la réputation méritée d’être parmi les meilleurs en codage. Commençons donc par les résultats de Terminal-Bench 2.0.
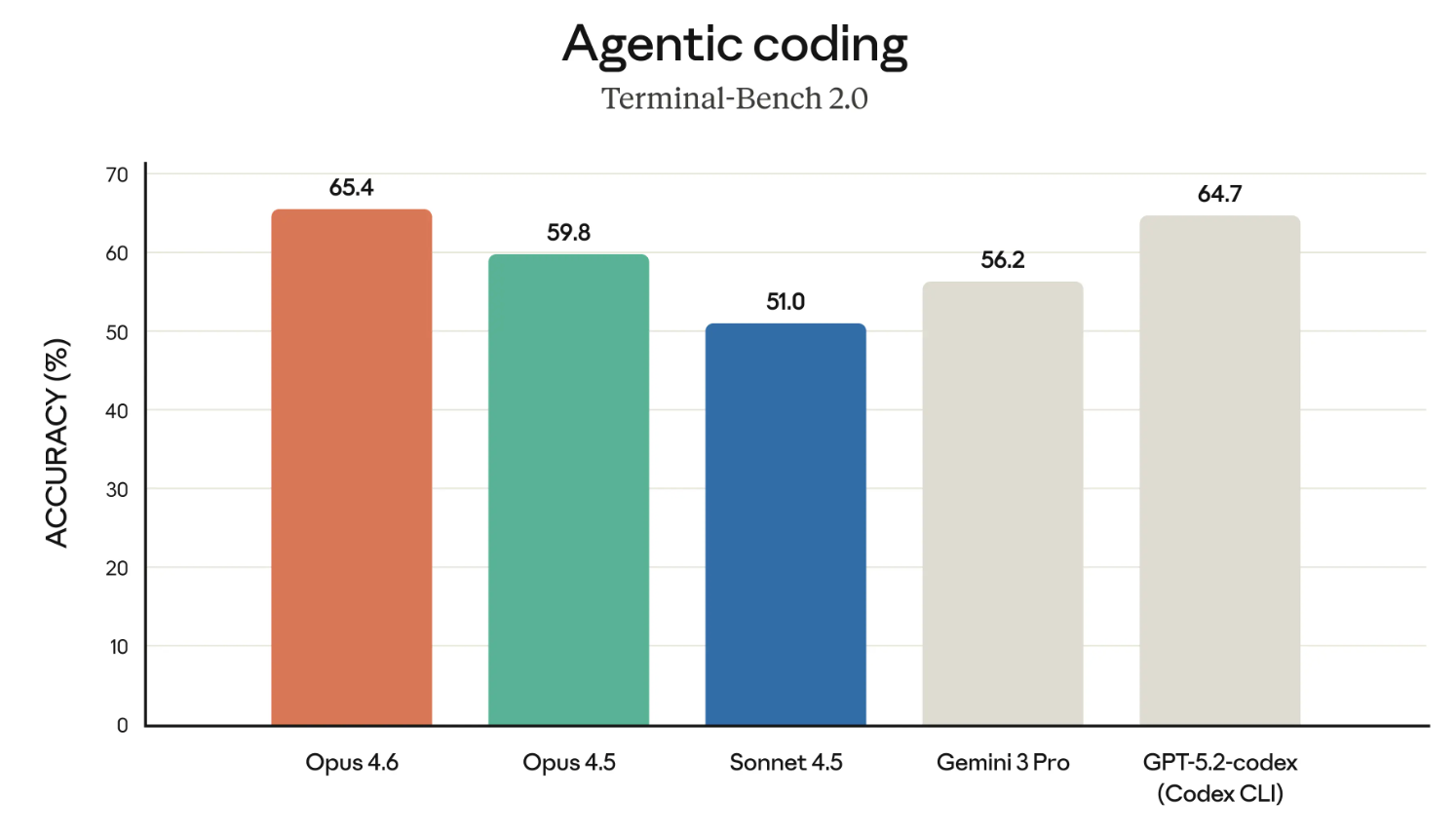
Si le graphique ci-dessus met en regard Opus 4.6 et GPT-5.2-codex, c’est sans doute volontaire. Anthropic conteste directement OpenAI sur plusieurs terrains dernièrement, et plaide sa cause pour les usages en entreprise.
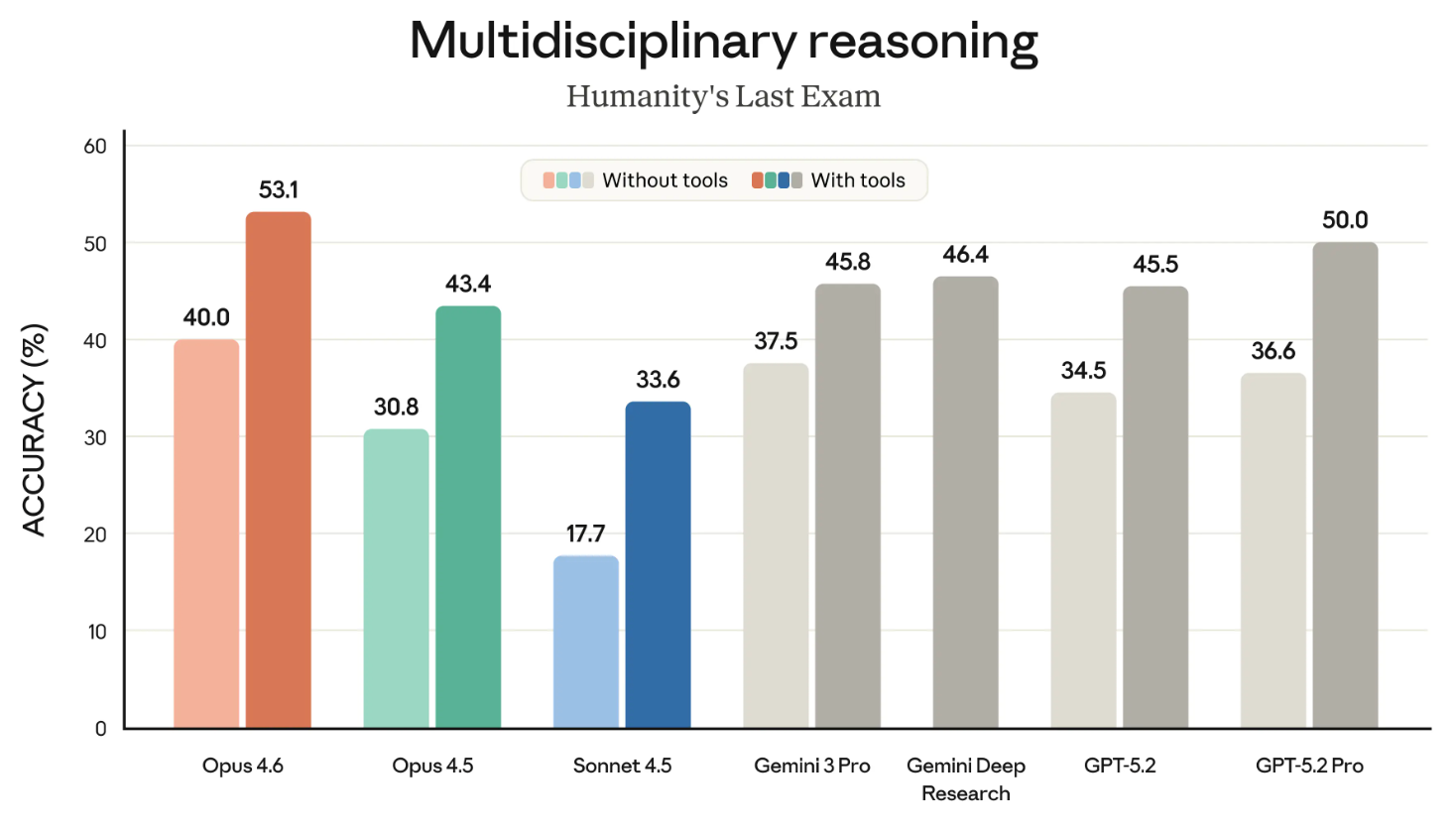
Humanity’s Last Exam est l’un des benchmarks les plus connus, et l’un de ceux que nous suivons de près. Il mesure la capacité générale de raisonnement d’un modèle.
Le graphique suivant montre la réussite des différents modèles de pointe sur HLE, avec et sans outils (« avec outils » signifiant que le modèle peut recourir à des capacités externes comme la recherche web ou l’exécution de code).
On aurait pu en faire deux graphiques, mais l’essentiel est clair : Opus 4.6 est en tête, avec et sans outils.
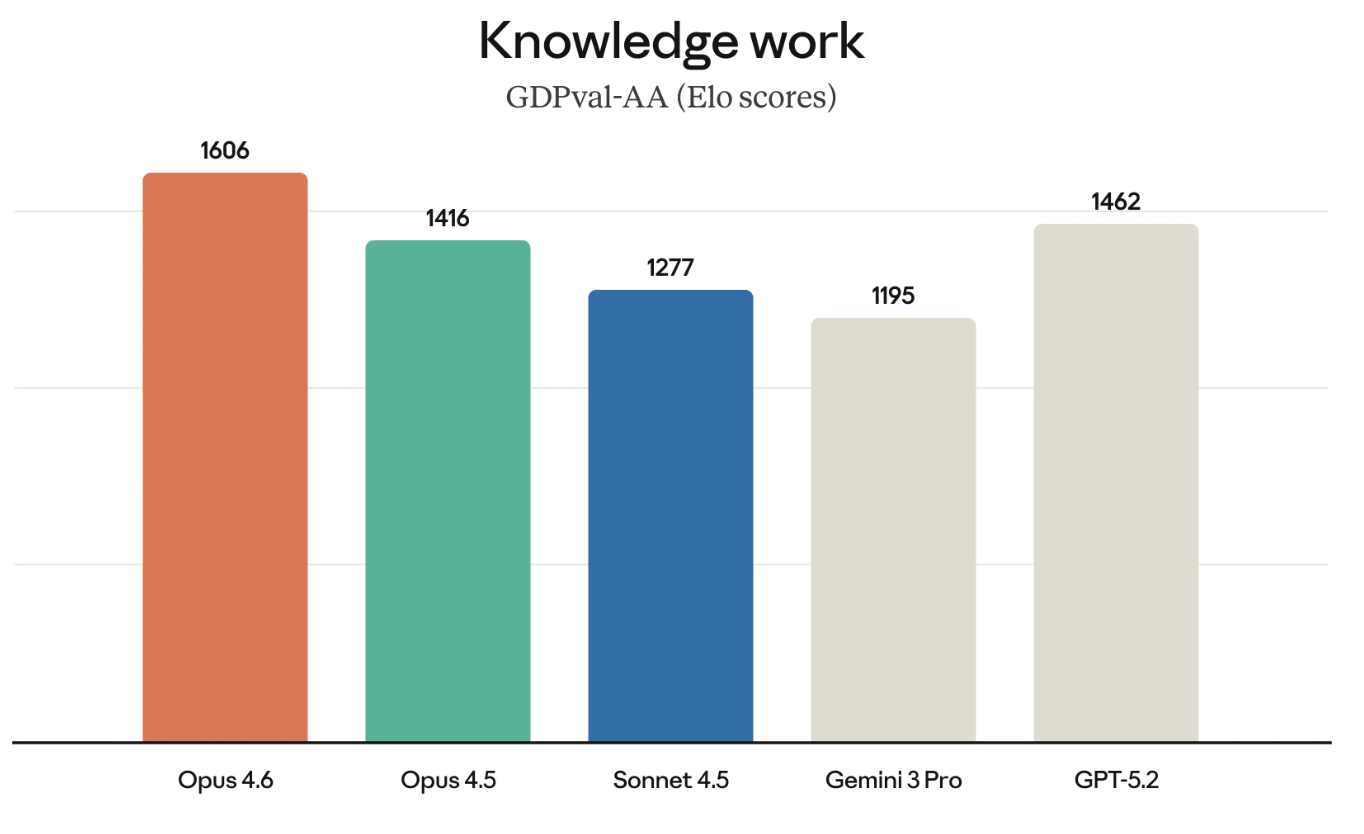
GDPval-AA, comme son nom l’indique, évalue des tâches de connaissance jugées créatrices de valeur économique : par exemple, construire des modèles financiers ou mener des recherches.
GDPval-AA et des benchmarks similaires gagnent en importance, car ils mesurent des travaux que les entreprises paient réellement. La performance d’Opus 4.6 sur GDPval-AA constitue aussi un défi direct à la gamme GPT, OpenAI et Anthropic visant souvent les mêmes clients.
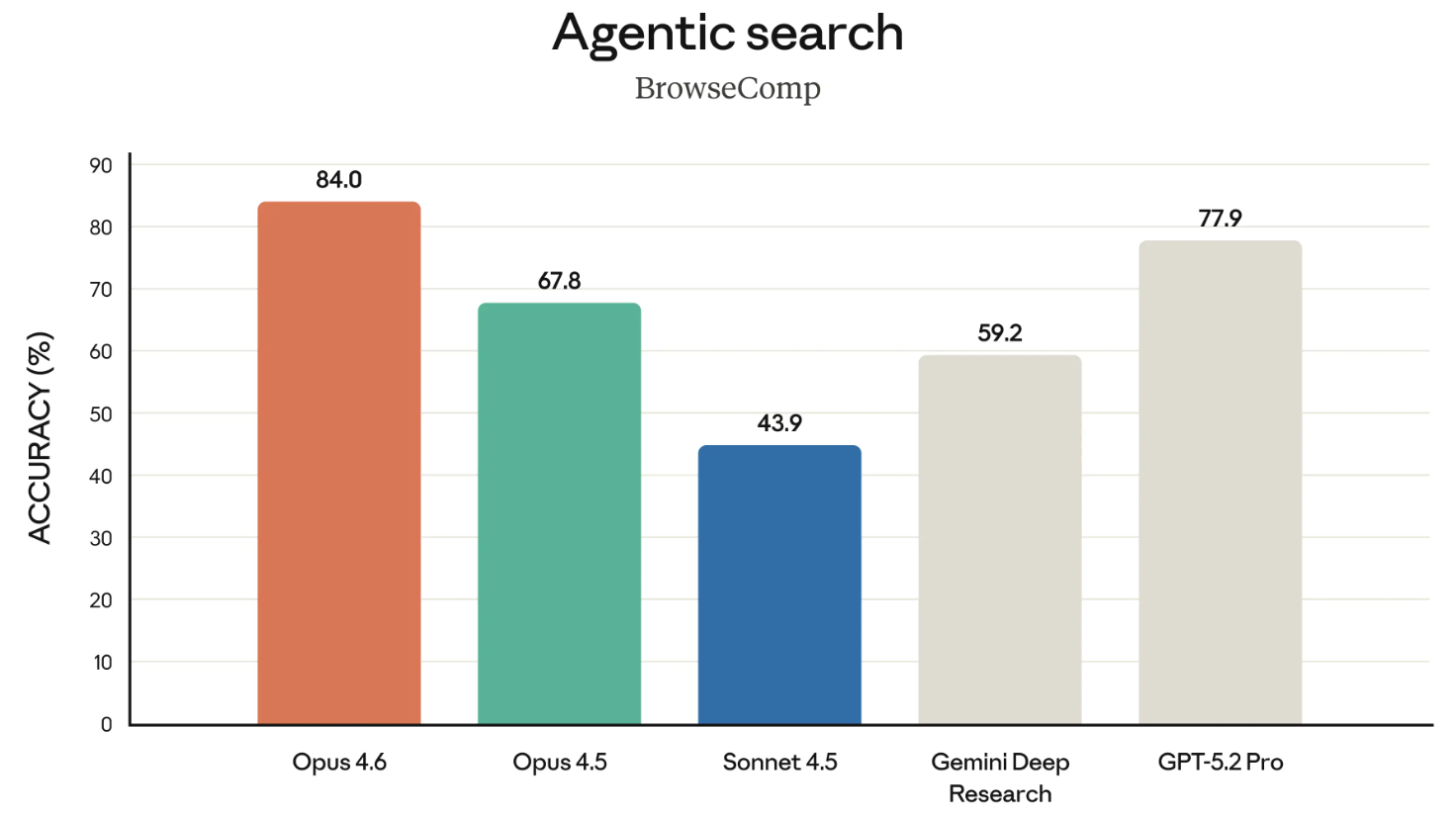
BrowseComp est le dernier benchmark marquant de cette sortie. Il mesure la capacité d’un modèle à retrouver en ligne des informations difficiles d’accès. Pour l’historique : OpenAI a conçu BrowseComp pour mettre en valeur les capacités de recherche de ses propres modèles.
Dans un clin d’œil appuyé, Anthropic a lié directement l’annonce d’avril 2025 d’OpenAI sur BrowseComp en soulignant qu’Opus 4.6 y arrive en tête. Une petite pique, en citant à OpenAI son propre benchmark.
Opus 4.6 est largement disponible à la date de cet article. En revanche, vous ne pouvez pas y accéder sans passer à un compte pro, qui offre d’autres avantages comme l’accès à Claude in Excel.
Si vous êtes développeur, utilisez claude-opus-4-6 dans l’API Claude. La tarification n’a pas changé : toujours 5 $ / 25 $ par million de tokens. Pour lever l’ambiguïté entre les deux montants : le premier correspond aux tokens envoyés au modèle (vos invites), le second à ceux qu’il génère en retour (les réponses).
Claude Opus 4.6 prend la tête sur des benchmarks clés comme GPDVal-AA, qui mesure la performance sur des tâches économiquement importantes – exactement ce qui compte pour les grands comptes. OpenAI a peut-être été ébranlé par cette avancée : quelques heures avant la sortie d’Opus 4.6, ils ont annoncé OpenAI Frontier, une nouvelle plateforme entreprise pour construire, déployer et opérer des agents d’IA en production.
Autrement dit, plutôt que de se battre sur les benchmarks de modèles, Frontier montre qu’OpenAI se concentre sur l’infrastructure autour de sa suite, en dotant les agents d’un contexte métier partagé, d’autorisations, et de la capacité à recevoir et apprendre des retours dans le temps. Alors qu’il perd du terrain sur les benchmarks, OpenAI fait valoir que sa plateforme est mieux armée pour rendre les agents utiles en entreprise.
S’agit-il d’un pivot stratégique ou de l’aveu tacite d’un retard dans la course aux modèles ? À vous d’en juger.
Globalement, nous sommes impressionnés par l’offre d’Anthropic avec Claude Opus 4.6, et avons hâte de prendre en main les agent teams. Pour en savoir plus sur la famille Claude, n’hésitez pas à suivre le cours Introduction to Claude Models.
Learn AI with DataCamp
Cours
Cours
Cours
blog
blog
Lynn Heidmann
blog
Kurtis Pykes
9 min
blog
Kurtis Pykes
15 min
Tutoriel

