
programa
Fundamentos de la IA
10 h
Recientemente he terminado un contrato con una empresa de inteligencia artificial. Entre otras cosas, ayudan a los investigadores a entrenar posteriormente los LLM. Como doctor en matemáticas, creé problemas matemáticos que dejaron perplejos a los modelos de IA más avanzados. Las indicaciones engañosas no contaban; las indicaciones tenían que poner de manifiesto errores de razonamiento.
Durante ese trabajo, escuché repetidas referencias al «último examen de la humanidad». Aprendí que se trataba de un punto de referencia de IA diseñado para evaluar el razonamiento en muchos campos académicos. Mi curiosidad me llevó a profundizar en lo que es HLE y lo que nos dice sobre los límites actuales del razonamiento de la IA.
Si eres nuevo en el campo de la IA y el benchmarking, te recomiendo que realices el programa de formación «Fundamentos de la IA».
A medida que los LLM han avanzado, los investigadores se basan en colecciones de preguntas de evaluación, conocidas como puntos de referencia, para comparar el rendimiento y realizar un programa del progreso. El último examen de la humanidad (HLE) es un punto de referencia diseñado para medir las capacidades e esde razonamiento de un LLM , no solo su capacidad para reconocer patrones. Su objetivo es evaluar la capacidad de un modelo para resolver problemas de nivel experto en numerosos ámbitos académicos.
Con tantos puntos de referencia ya existentes, ¿por qué otro más? Los puntos de referencia que antes suponían un reto para los LLM, como el MMLU, ahora están saturados, y los modelos suelen obtener puntuaciones superiores al 90 %. En este punto, estos puntos de referencia dejan de medir diferencias significativas entre los modelos.
HLE es un punto de referencia de última generación que aumenta el nivel de dificultad al reunir preguntas elaboradas por expertos que requieren un razonamiento de varios pasos, y no solo recordar patrones superficiales.
A finales de 2024, el Centro para la Seguridad de la IA, una organización sin ánimo de lucro dedicada a la seguridad de la IA, se asoció con Scale AI, una empresa de datos, para desarrollar un punto de referencia de IA más difícil. Dan Hendrycks dirigió el proyecto.
El equipo recopiló preguntas de nivel universitario de múltiples disciplinas académicas y ofreció importantes premios: los 50 contribuyentes principales ganaron 5000 dólares cada uno, y los 500 siguientes obtuvieron 500 dólares.
El resultado fue un amplio conjunto de preguntas de nivel experto sobre muchas materias, como matemáticas, informática, literatura, análisis musical e historia.
El documento HLE describe el punto de referencia como «... el punto de referencia definitivo y cerrado para las habilidades académicas generales». Sus preguntas requieren un razonamiento en varios pasos, lo que impide que los modelos adivinen o memoricen las respuestas.
HLE consta de 2500 preguntas públicas y unas 500 preguntas adicionales en un conjunto privado reservado.
Cada pregunta debe ser original, tener una única respuesta correcta y no poder resolverse mediante una simple búsqueda en Internet o en una base de datos. Alrededor del 76 % de las preguntas utilizan el formato de respuesta de coincidencia exacta y el 24 % restante utiliza preguntas de opción múltiple. Aproximadamente el 14 % de las preguntas son multimodales, es decir, incluyen tanto texto como imágenes.
El equipo de HLE sometió las preguntas a un riguroso proceso de selección.
Los primeros resultados mostraron que los modelos pioneros obtuvieron inicialmente puntuaciones bajas en las preguntas, pero expresaron un alto nivel de confianza. Esta diferencia indica alucinaciones.
Grupos independientes también expresaron su preocupación. Future House, un laboratorio de investigación sin ánimo de lucro, publicó un blog titulado «Aproximadamente el 30 % de las respuestas del último examen de química/biología de la humanidad son probablemente incorrectas».
Tu análisis se centró en el protocolo de revisión. Los autores de las preguntas afirmaban que las respuestas eran correctas, pero a los revisores se les indicó que solo dedicaran cinco minutos a revisar la corrección de las respuestas. Sostienen que este proceso permite que se cuelen respuestas excesivamente complejas, artificiosas o ambiguas que a menudo entran en conflicto con la literatura científica.
Los responsables del mantenimiento de HLE respondieron a la publicación encargando una revisión por parte de tres expertos del subconjunto en disputa. A partir del 16 de septiembre de 2025, tenían previsto anunciar un proceso de revisión continua a HLE.
HLE se inscribe en un ecosistema más amplio de pruebas comparativas que evalúan diferentes aspectos de la capacidad de los LLM.
Estos puntos de referencia evalúan los conocimientos académicos y el razonamiento.
Estos parámetros de referencia miden el razonamiento que implica tanto texto como imágenes.
Otros puntos de referencia se centran específicamente en la ingeniería de software y el uso de herramientas.
El Centro de Investigación sobre Modelos Fundamentales (CRFM) de Stanford desarrolló Evaluación Holística de Modelos Lingüísticos (HELM) para apoyar la evaluación responsable de la IA.
HELM evalúa los modelos en una serie de escenarios estandarizados, como la respuesta a preguntas, la síntesis, las consultas críticas para la seguridad y el contenido social/ético. Estos escenarios se puntúan en múltiples dimensiones, no solo en cuanto a precisión, sino también en cuanto a calibración, solidez y toxicidad.
HELM se ha convertido en una familia de marcos relacionados.
Los marcos de seguridad miden el riesgo en lugar de la competencia intelectual.
Muchas tablas de clasificación públicas realizan un seguimiento del rendimiento de los LLM a través de diversas métricas.
A continuación se muestran algunas puntuaciones en el momento de redactar este artículo, en diciembre de 2025.
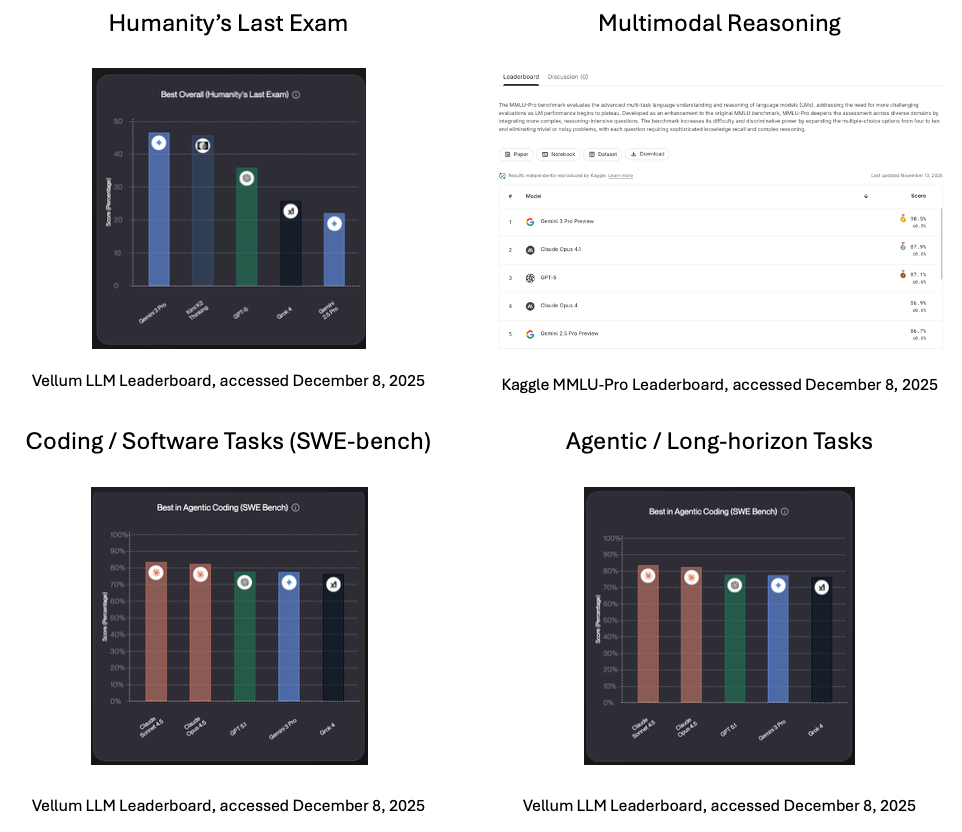
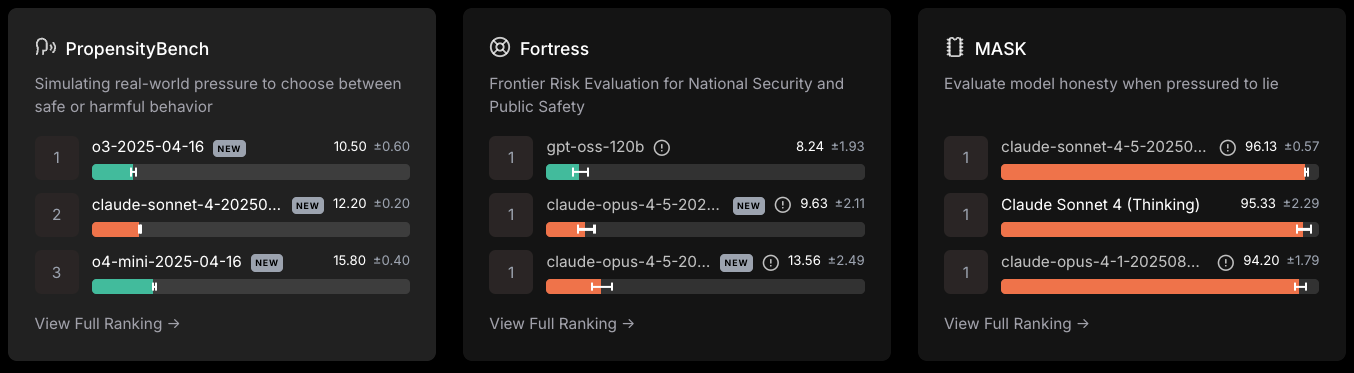
Clasificación de seguridad de LLM a escala, consultada el 8 de diciembre de 2025.
Hasta ahora, he descrito qué es HLE y cómo se desarrolló. Veamos ahora cómo se utiliza la prueba en la práctica.
HLE proporciona un método de evaluación estandarizado en todos los ámbitos. Destaca los puntos fuertes y débiles de un modelo. Revela la diferencia entre tu rendimiento y el de los expertos humanos. Los equipos pueden utilizar estos patrones como guía para el desarrollo de modelos y el enfoque posterior a la formación.
HLE proporciona una métrica pública y global del progreso del razonamiento de la IA. Crea un punto de referencia común entre países y organismos reguladores y permite centrar los debates sobre umbrales, supervisión y gobernanza en la realidad, y no en exageraciones.
Los puntos de referencia de la IA determinan cómo medimos el progreso de la IA. A medida que los puntos de referencia anteriores se han ido saturando, se ha hecho evidente la necesidad de un nuevo punto de referencia, centrado en el razonamiento, y no solo en la memoria o la comparación de patrones.
Humanity's Last Exam intenta llenar ese vacío mediante la recopilación colectiva de preguntas de nivel universitario formuladas por expertos de todo el mundo con el fin de poner de manifiesto las limitaciones de los LLM. No es la última palabra, pero aclara cuál es la situación actual de la IA en relación con el razonamiento de los expertos humanos.
Para obtener más información sobre los LLM y cómo funcionan, recomiendo los siguientes recursos:
Los mejores cursos de IA
programa
Curso
Curso
blog
Matt Crabtree
8 min
blog
Stanislav Karzhev
9 min
blog
Josep Ferrer
8 min
