
Curso
Conceptos de streaming
2 h
6.8K
La ingesta de datos consiste en recopilar datos de diversas fuentes y cargarlos en el destino. Muchas herramientas de ingestión de datos disponibles en el mercado pueden automatizar y simplificar este proceso.
Tras una minuciosa investigación y pruebas, he recopilado una lista con las 20 mejores herramientas de ingestión de datos. Cada una de estas herramientas ofrece características únicas, tanto si necesitas procesamiento en tiempo real, ingestión por lotes o compatibilidad con diversas fuentes de datos.
¡Vamos a sumergirnos en las herramientas y explorar sus capacidades y casos de uso ideales!
Apache Kafka es un motor distribuido de código abierto conocido por su alto rendimiento y baja latencia. Incluye Kafka Connect, un marco para integrar Kafka con bases de datos externas, sistemas de archivos y almacenes de claves-valores.
Apache Kafka sigue una arquitectura productor-consumidor. Los productores de datos envían datos a los temas de Kafka, que actúan como intermediarios, organizando lógicamente los datos recibidos dentro de sus particiones. Por último, los consumidores acceden a los datos necesarios desde estos temas de Kafka.
¿Por qué Apache Kafka para la ingesta de datos?
Si te interesa la ingesta de datos en tiempo real, consulta Introducción a Apache Kafka para aprender a procesar datos en streaming de forma eficiente.
Apache NiFi está diseñado para automatizar el flujo de datos entre sistemas. A diferencia de Kafka, ofrece una interfaz intuitiva para diseñar, implementar y supervisar el flujo de datos.
La herramienta utiliza procesadores para la ingesta de datos. Los procesadores de NiFi gestionan diversas funciones, como la extracción, publicación, transformación o enrutamiento de datos. Por ejemplo, los procesadores preconstruidos como InvokeHTTP extraen datos de la API REST, y GetKafka recupera mensajes de los temas de Kafka.
Una vez que los procesadores comienzan a ingestar datos, se crean FlowFiles para cada unidad de datos. Estos FlowFiles contienen metadatos junto con los datos reales y se envían a sus respectivos destinos según las reglas definidas.
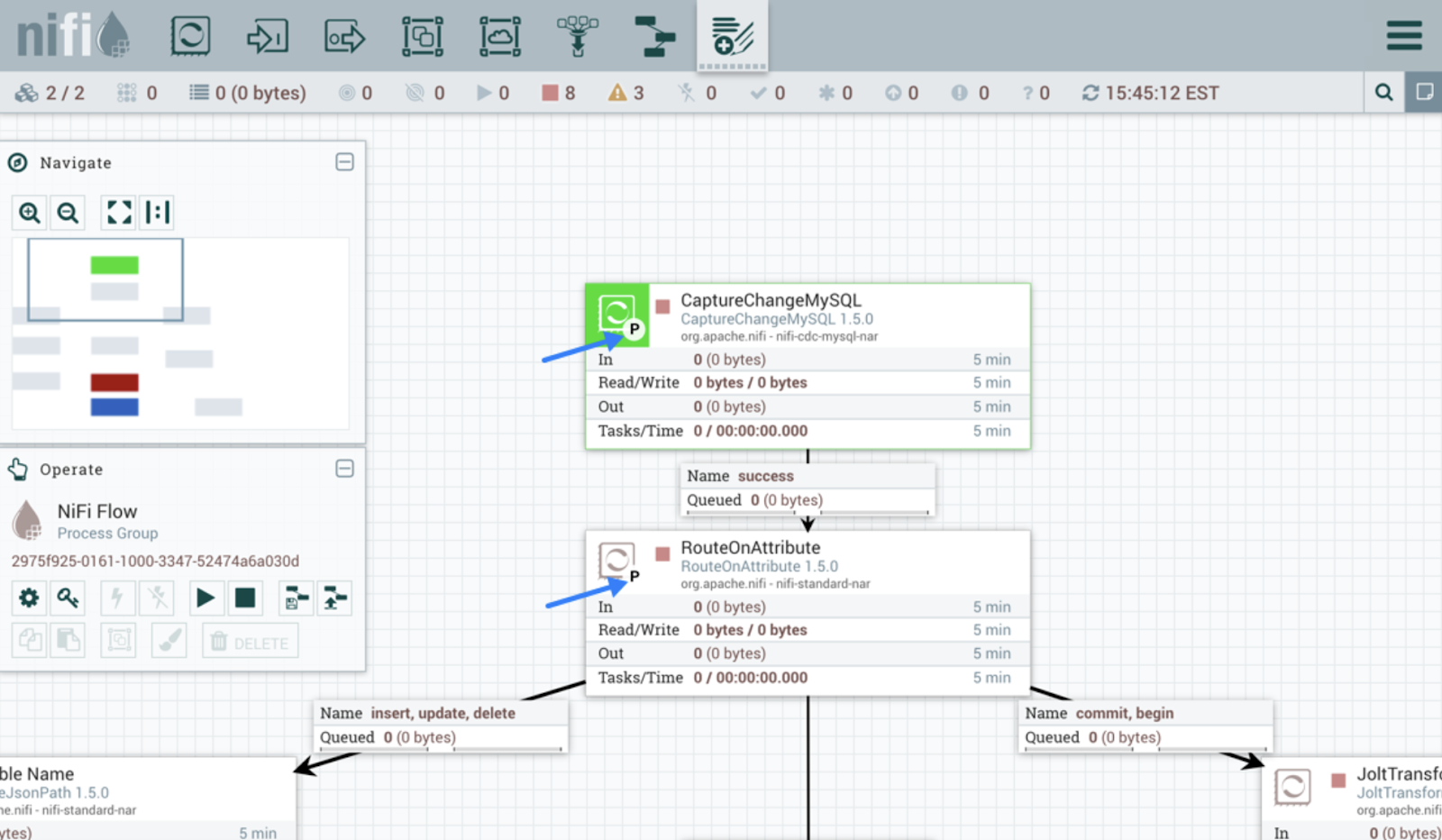
Interfaz de usuario de Apache NiFi. Fuente de la imagene: Guía del usuario de Apache NiFi.
AWS Glue es un servicio de integración de datos sin servidor de Amazon. Descubre, transforma y carga datos en destinos para casos de uso de análisis o aprendizaje automático. La plataforma ofrece una interfaz gráfica de usuario fácil de usar y entornos de desarrollo como los cuadernos Jupyter.
Los rastreadores y los trabajos ETL son los dos componentes principales de AWS Glue. Los rastreadores escanean las fuentes de datos para detectar esquemas y añadir metadatos a los catálogos. Los trabajos ETL pueden entonces descubrir fácilmente la fuente de datos y su estructura utilizando la información del catálogo.
AWS Glue ofrece varias formas de crear y ejecutar canalizaciones. Por ejemplo, las tareas ETL pueden escribirse en Python o Scala para transformar y cargar los datos. Para quienes no saben programar, Glue Studio ofrece una interfaz intuitiva que permite crear flujos de trabajo sin necesidad de escribir código.
Si estás explorando soluciones ETL sin servidor, echa un vistazo a este tutorial de AWS Glue para obtener una guía práctica sobre cómo crear canalizaciones de datos escalables.
Dataflow es un servicio de Google Cloud totalmente gestionado para el procesamiento por lotes y en tiempo real. Puede gestionar canalizaciones de datos sencillas, como el traslado de datos entre sistemas a intervalos programados, así como canalizaciones avanzadas en tiempo real.
Además, la herramienta es altamente escalable y permite una transición fluida del procesamiento por lotes al procesamiento en flujo cuando es necesario.
Google Dataflow se basa en Apache Beam. Así que puedes programar canalizaciones de ingestión utilizando los SDK de Beam. Además, la herramienta ofrece plantillas de flujo de trabajo predefinidas para crear canalizaciones al instante. Los programadores también pueden crear plantillas personalizadas y ponerlas a disposición de usuarios sin conocimientos técnicos para que las implementen cuando lo necesiten.
Azure Data Factory (ADF) es el servicio en la nube de Microsoft para la ingesta de datos procedentes de múltiples fuentes. Está diseñado para crear, programar y coordinar flujos de trabajo con el fin de automatizar el proceso.
ADF no almacena ningún dato. Permite el movimiento de datos entre sistemas y los procesa a través de recursos informáticos en servidores remotos.
La plataforma cuenta con más de 90 conectores integrados para vincular diversas fuentes de datos, incluidos almacenes de datos locales, API REST y servidores en la nube. A continuación, el componente «copiar actividad» copia los datos del origen al destino.
Si ya utilizas los servicios de Microsoft para otras operaciones con datos, Azure Data Factory es una solución integral para tus necesidades de ingestión de datos. Nuestro tutorial de Azure Data Factory te guía a través de la configuración de flujos de trabajo de ingestión de datos en Azure.
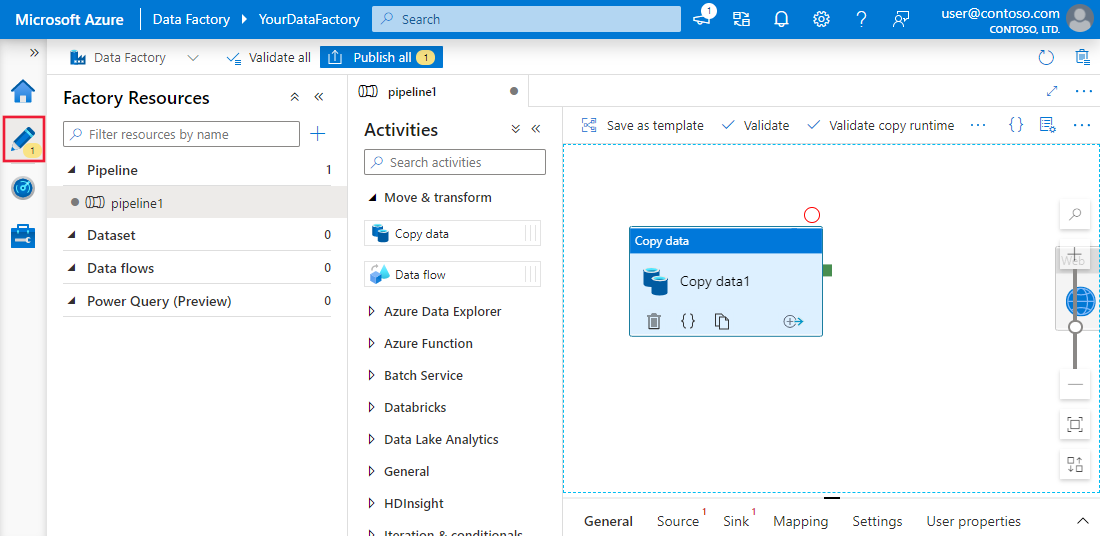
Experiencia de interfaz de usuario de Azure Data Factory y Synapse Analytics. ImagenFuente: Microsoft Learn
Talend es una plataforma de integración de datos de código abierto y de extremo a extremo. Facilita la creación de flujos de trabajo de ingestión de datos, ya que ofrece componentes de arrastrar y soltar para conectar diferentes fuentes y destinos.
Talend es conocido por transferir datos entre sistemas manteniendo la calidad. Tu sólido conjunto de herramientas de calidad de datos garantiza la precisión de los datos durante la ingestión. Además, las capacidades de supervisión integradas permiten cumplir con las normas de seguridad y gobernanza de datos.
Fivetran es una popular plataforma de integración de datos que automatiza las tareas de ELT. Proporciona datos ininterrumpidos al adaptarse automáticamente a los cambios de formato de datos. Esta función también ayuda a mantener la precisión de los datos mediante la asignación de esquemas durante la ingestión.
La principal ventaja de herramientas como Fivetran es que no requieren mantenimiento. Tu gestión y supervisión automáticas de esquemas permiten que las canalizaciones se mantengan por sí mismas.
Además, la herramienta incluye capacidades CDC (captura de datos modificados), lo que garantiza que el destino se mantenga actualizado en tiempo real.
Para quienes no estén familiarizados con el término, CDC se refiere al proceso de identificar las actualizaciones recientes realizadas en una base de datos y reflejarlas en el destino en tiempo real.
Airbyte es otra herramienta de ingestión de datos de código abierto que figura en la lista. Es la plataforma de integración de datos más popular, y más de 3000 empresas la utilizan.
Con más de 300 conectores predefinidos, Airbyte ofrece la compatibilidad más amplia para diversas conexiones de origen y destino. Además, al ser de código abierto, puedes examinar el código de estos conectores y personalizarlos. Si tu caso de uso no está cubierto, puedes escribir tu propio conector de origen.
Airbyte requiere conocimientos técnicos para configurar y mantener los canales, especialmente los conectores personalizados. Sin embargo, cuenta con planes de pago con servicios totalmente gestionados y asistencia dedicada.
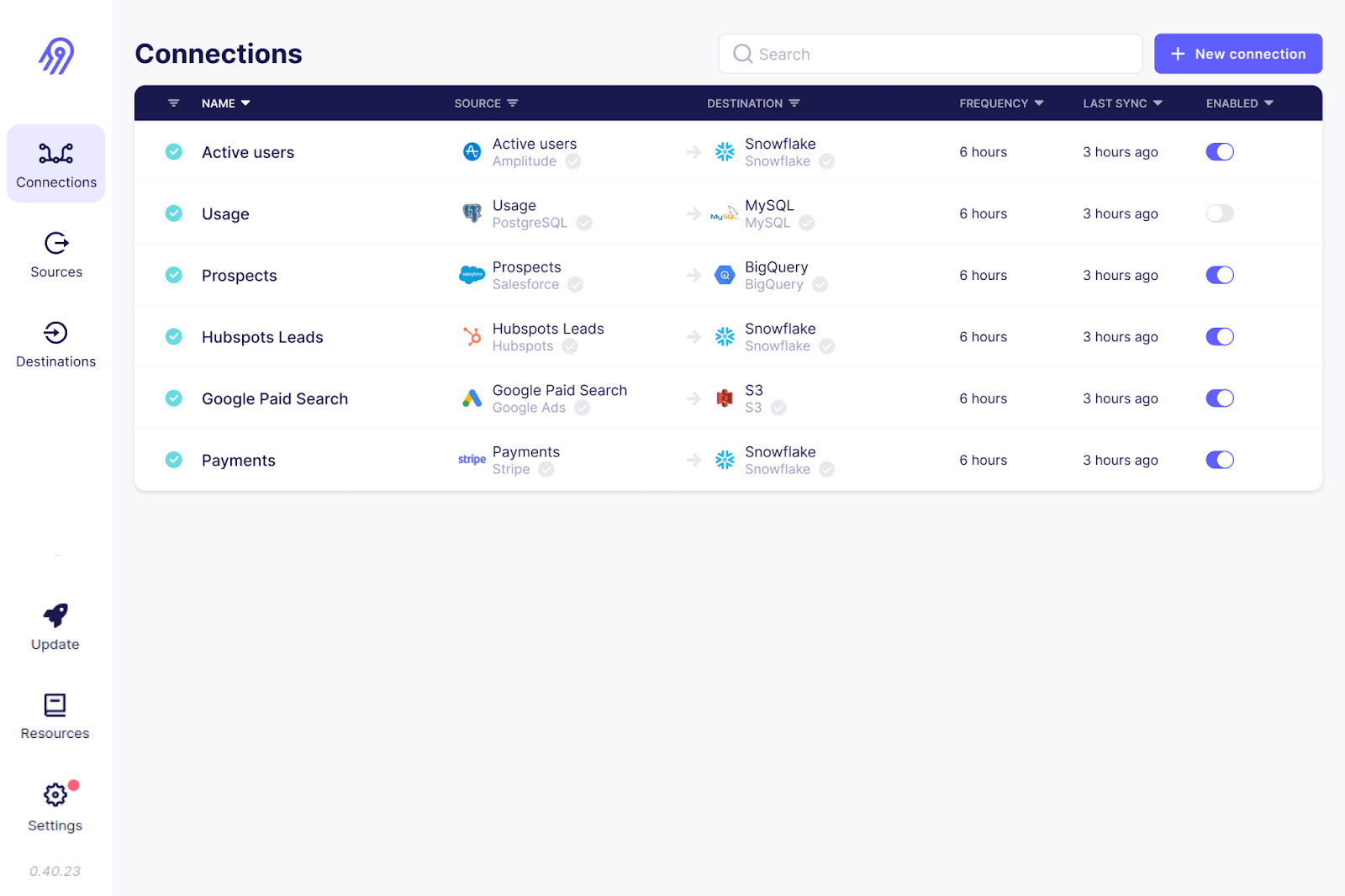
La interfaz de usuario de Airbyte. Imagen fuente: Airbyte GitHub
La nube de gestión inteligente de datos de Informatica contiene un conjunto de herramientas para simplificar la ingesta de datos. Tu herramienta «Data Loader» solo tarda unos minutos en cargar datos de más de 30 servicios en la nube.
Informatica también cuenta con una herramienta de integración de aplicaciones que conecta sistemas de software dispares, tanto locales como en la nube. Tu plataforma de integración de datos en la nube está bien diseñada para la ingesta de datos de alto rendimiento con ETL/ELT.
Diseñado para gestionar datos por lotes y en tiempo real, Informatica permite ingestar cualquier tipo de datos procedentes de bases de datos relacionales, aplicaciones y sistemas de archivos. Además, la plataforma ofrece capacidades de inteligencia artificial como CLAIRE Engine, que analiza la información de metadatos y sugiere conjuntos de datos relevantes para tus necesidades de ingestión de datos.
Apache Flume es un servicio distribuido y fiable para cargar datos de registro en destinos. Su arquitectura flexible está especialmente diseñada para flujos de datos en streaming, como los que se envían desde varios servidores web a HDFS o ElasticSearch casi en tiempo real.
El agente Flume es el componente principal responsable del movimiento de datos. Está compuesto por un canal, un sumidero y una fuente. El componente fuente selecciona los archivos de datos de los datos de origen, y el sumidero garantiza la sincronización entre el destino y el origen. Se pueden configurar varios agentes Flume para la ingesta paralela de datos cuando se transmiten grandes volúmenes de datos.
Apache Flume es conocido por su tolerancia a fallos. Con múltiples mecanismos de conmutación por error y recuperación, Flume garantiza una ingesta de datos coherente y fiable incluso en caso de fallos.
Stitch es una herramienta ETL en la nube sencilla y extensible. Aunque carece de capacidades complejas de transformación personalizada, es perfecto para tareas de ingestión de datos.
Al igual que otras herramientas ETL empresariales, Stitch ofrece una gama de conectores para más de 140 fuentes de datos, normalmente desde aplicaciones SaaS y bases de datos hasta almacenes y lagos de datos. Para flujos de trabajo de ingestión de datos personalizados, Stitch se integra con Singer, lo que te permite crear conectores personalizados.
Interfaz de usuario para la extracción de datos de Stitch. Yomage source: Documentación de Stitch
StreamSets, adquirida por IBM, es un motor de integración de datos de código abierto para datos de flujo, por lotes y CDC. Su función «Data Collector» ofrece conectores de origen de arrastrar y soltar para plataformas en la nube, como AWS, Microsoft Azure y Google Cloud, así como para sistemas locales.
No necesitas conocimientos especializados en TI para crear o editar canalizaciones de ingestión de datos: su interfaz de usuario de arrastrar y soltar para la recopilación de datos es muy intuitiva.
StreamSets es una herramienta independiente de la plataforma que permite a los usuarios crear canalizaciones de recopilación de datos que se adaptan a múltiples entornos con un mínimo de reconfiguraciones. Además de los recopiladores de datos, la plataforma cuenta con transformadores de datos que operan en Apache Spark para realizar transformaciones de datos complejas.
Apache Beam es una solución unificada que proporciona un único modelo de programación para casos de uso por lotes y en streaming. Funciona a la perfección con plataformas en la nube como Google Cloud Dataflow, Apache Flink y Apache Spark.
Para la ingesta de datos en tiempo real, puedes definir ventanas fijas, deslizantes y de sesión para agrupar y procesar datos rápidamente.
Apache Beam destaca por su flexibilidad. Permite definir canalizaciones en cualquier lenguaje de programación y ejecutarlas en múltiples motores de ejecución.
Hevo Data es una plataforma totalmente gestionada y sin código para transferir datos desde más de 150 fuentes al destino que elijas. La herramienta no solo gestiona la ingesta de datos, sino que también los transforma para que estén listos para su análisis.
La plataforma detecta automáticamente el esquema de los datos entrantes y lo compara con el esquema de destino, lo que proporciona flexibilidad.
Los datos de Hevo también ofrecen una arquitectura robusta y tolerante a fallos, lo que garantiza que no se pierdan datos durante la ingesta. En general, Hevo Data es la opción ideal para casos de uso de streaming y análisis en tiempo real.
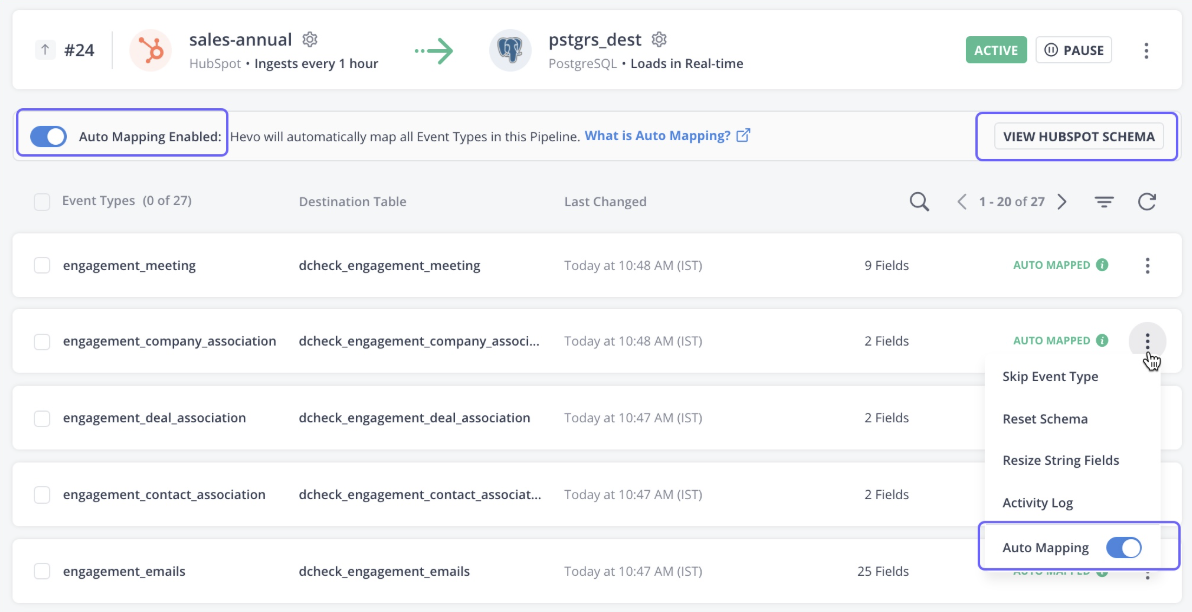
Interfaz de usuario de datos Hevo. Fuente de la imagen: Documentación de Hevo
Segment es una plataforma de datos de clientes que proporciona datos limpios y transformados para su análisis. La plataforma está especializada en recopilar diversos tipos de datos de los clientes, como interacciones, impresiones, clics y otros datos de comportamiento.
La API Track del programa de la herramienta recopila datos de eventos de múltiples fuentes, incluyendo dispositivos móviles, web y servidores. Con solo unos clics, los datos se pueden integrar con más de 450 aplicaciones.
Los datos recopilados a través de Segment están disponibles para los usuarios mediante consultas SQL, mientras que los programadores pueden acceder a los datos en tiempo real utilizando comandos curl.
Matillion es una plataforma de integración de datos nativa de la nube diseñada para mover y transformar datos dentro de la nube. Está diseñado especialmente para potentes almacenes de datos en la nube como Snowflake, Amazon Redshift y Google BigQuery.
La plataforma ofrece una amplia gama de conectores predefinidos para fuentes de datos tanto en la nube como locales, incluyendo bases de datos, aplicaciones SaaS, plataformas de redes sociales y mucho más.
Con su enfoque en el rendimiento, Matilion también ofrece potentes capacidades de transformación para limpiar y preparar los datos para su posterior análisis.
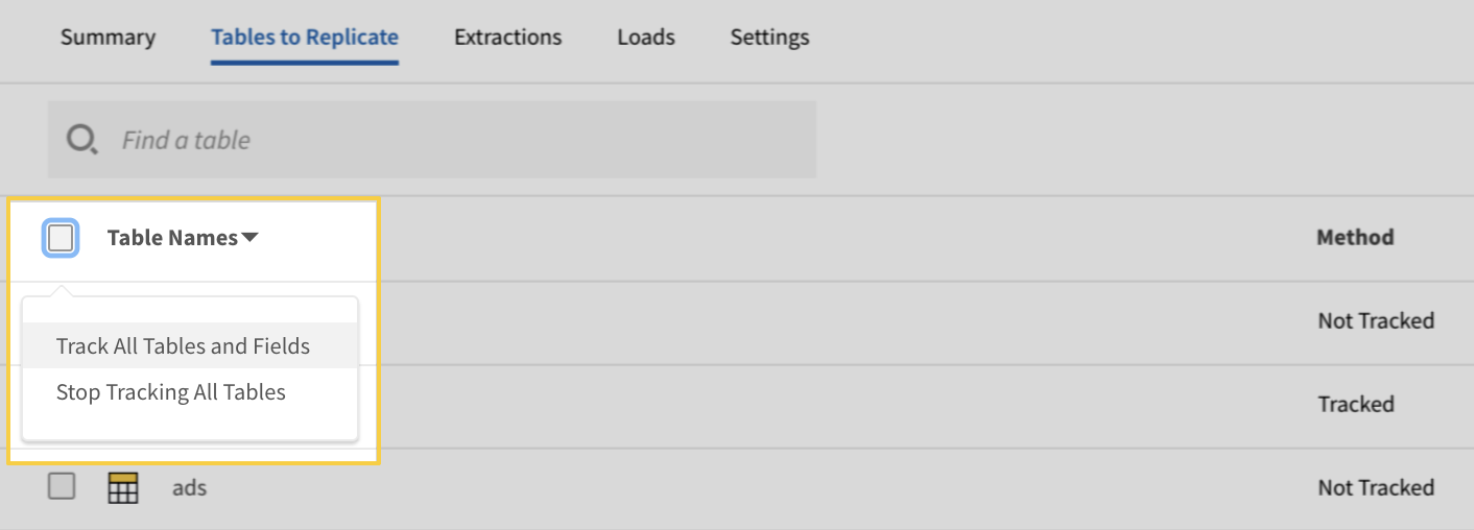
Keboola, un emente diseñado para realizar transformaciones complejas, ofrece funciones personalizadas de ingesta de datos. Con más de 250 integraciones incorporadas entre fuentes y destinos, automatiza la ingesta de datos con solo unos clics.
Keboola admite tanto la transmisión de datos por lotes como en tiempo real para importar datos empresariales. Sin embargo, en el caso de la ingesta de datos en tiempo real, necesitas conocimientos de programación para configurar los webhooks.
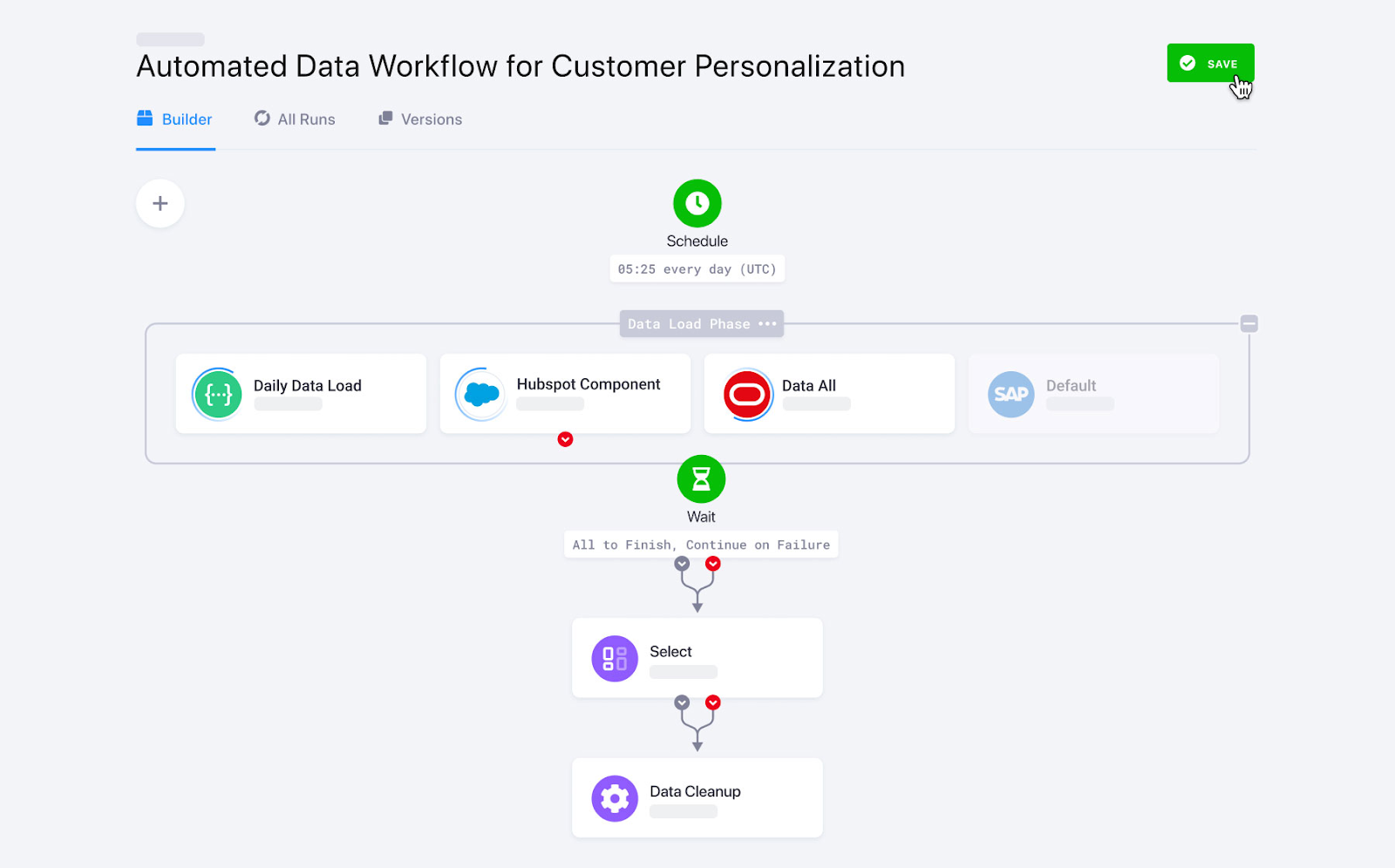
Flujos de trabajo de datos de Keboola. Fuente de la imagen: Keboola
Snowplow es una plataforma de recopilación de datos de última generación que captura y procesa datos de eventos procedentes de diversas fuentes. Se especializa en recopilar datos sobre el comportamiento de los clientes y prepararlos para su análisis mediante inteligencia artificial y machine learning avanzados.
Snowplow utiliza internamente rastreadores y webhooks para recopilar datos de eventos en tiempo real.
Los rastreadores son bibliotecas o SDK que se pueden integrar en aplicaciones móviles, sitios web y aplicaciones del lado del servidor. Recopilan información sobre eventos, como interacciones de los usuarios, clics y «me gusta», y la envían a los recopiladores. A continuación, los recopiladores someten los datos a un proceso de enriquecimiento antes de enviarlos al almacén de destino.
IBM DataStage es una plataforma de integración de datos líder en el sector, diseñada para operaciones ETL y ELT. La versión básica está disponible en las instalaciones, pero para disfrutar de la escalabilidad y la automatización a través de la nube, actualízala a DataStage para IBM Cloud Pak®.
Tu amplio conjunto de conectores y etapas predefinidos automatiza el movimiento de datos entre múltiples fuentes en la nube y almacenes de datos.
Para quienes configuran su arquitectura de datos en el ecosistema IBM, DataStage es la herramienta ideal para la ingesta de datos. Se integra con otras plataformas de datos de IBM, como Cloud Object Storage y Db2, para la ingestión y transformación.
Alteryx es conocidopor sus herramientas de análisis y visualización de datos. Con más de 8000 clientes, es una popular plataforma de análisis que automatiza las tareas de datos y análisis.
Alteryx cuenta con una herramienta llamada Designer Cloud que ofrece una interfaz intuitiva para crear canalizaciones de ingestión de datos para casos de uso de análisis e inteligencia artificial. Ofrece conectividad a diversas fuentes de datos, incluidos almacenes de datos, almacenamiento en la nube y sistemas de archivos.
¿Quieres simplificar la preparación y el análisis de datos sin necesidad de programar? Aprende a automatizar flujos de trabajo de ETL (extracción, transformación y carga) con Introducción a Alteryx ydescubre las capacidades de ETL de arrastrar y soltar.
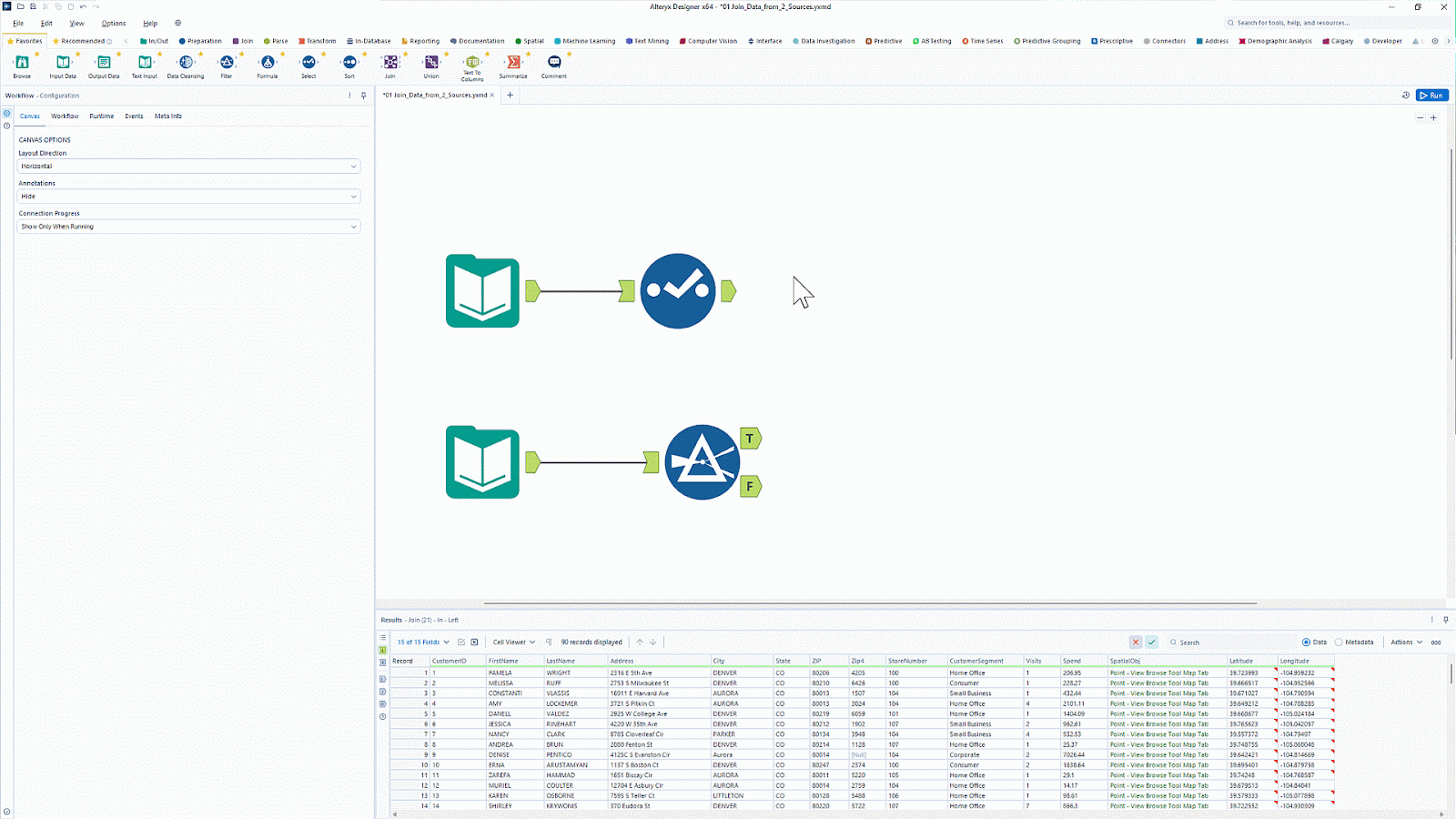
Interfaz de usuario de arrastrar y soltar de Alteryx. Fuente de la imagen: Alteryx
|
Herramienta |
Ideal para |
Características |
Precios |
|
Apache Kafka |
Transmisión de datos en tiempo real |
|
Código abierto |
|
Apache Nifi |
Ingesta de datos segura en tiempo real |
|
Código abierto |
|
AWS Glue |
Ecosistema de AWS |
|
Modelo de precios de pago por uso. Los cargos se basan en la cantidad de procesamiento de datos utilizados por hora. |
|
Flujo de datos en la nube de Google |
Ecosistema de Google Nube |
|
Modelo de precios de pago por uso. Los cargos se basan en los recursos informáticos y la memoria utilizados. |
|
Azure Data Factory |
Empresas que utilizan otros servicios Azure de Microsoft |
|
Modelo de precios de pago por uso |
|
Talend |
Empresas con presupuestos reducidos que buscan una solución ETL intuitiva. |
|
Código abierto |
|
Fivetran |
Necesidades de ELT totalmente gestionadas |
|
Precios basados en suscripción |
|
Airbyte |
Organizaciones que buscan una solución de personalización de código abierto. |
|
Hay disponibles servicios de código abierto y de pago. |
|
Informática |
Empresas que buscan herramientas de bajo código con amplios conectores de origen. |
|
Prueba gratuita de 30 días, modelo de precios de pago por uso. |
|
Apache Flume |
Flujos de datos en streaming |
|
Código abierto |
|
Puntada |
Organizaciones que buscan una herramienta sencilla para tareas de ingesta de datos. |
|
Puedes elegir entre modelos de precios basados en niveles o modelos de pago por uso. |
|
StreamSets |
Transformaciones complejas de datos |
|
Hay disponibles opciones tanto de código abierto como comerciales. |
|
Apache Beam |
Marco personalizable centrado en el código para crear canalizaciones de ingestión de datos. |
|
El marco Apache Beam es de código abierto, pero su uso con servicios de nube conlleva un coste. |
|
Datos de Hevo |
Empresas medianas que necesitan análisis en tiempo real |
|
Precios basados en suscripción |
|
Segmento |
Datos de eventos de clientes |
|
Modelo de precios de suscripción |
|
Matillion |
Herramienta ETL/ELT nativa en la nube |
|
Modelo de precios basado en suscripción |
|
Keboola |
Complejos procesos de transformación de datos |
|
Modelo de precios basado en suscripción |
|
Quitanieves |
Recopilación de datos sobre eventos |
|
Hay disponibles opciones tanto de código abierto como comerciales. |
|
IBM DataStage |
Ecosistema en la nube de IBM |
|
Modelo de precios basado en suscripción |
|
Alteryx |
Análisis y visualización de datos |
|
Modelo de precios basado en suscripción |
Con tantas herramientas disponibles en el sector, elegir la plataforma de integración de datos adecuada para tus necesidades puede resultar difícil. A continuación, se incluye una lista de algunos de los factores que debes tener en cuenta antes de optar por una herramienta de integración de datos específica.
Puedes importar fácilmente una hoja de Excel o un archivo CSV a los destinos deseados. Sin embargo, la ingesta manual de datos de streaming en tiempo real desde múltiples fuentes a diversos destinos puede resultar complicada. Por ejemplo, las aplicaciones modernas, como las redes sociales, suelen experimentar picos de demanda en determinados momentos y otros de menor actividad. Aquí es donde destaca la característica de escalabilidad de las herramientas de ingestión de datos.
La escalabilidad se refiere a la capacidad de crecer o reducirse en función de la demanda. Esto permite que la herramienta se adapte rápidamente a las crecientes demandas de volúmenes de datos sin comprometer el rendimiento.
La flexibilidad se refiere a la capacidad de manejar datos procedentes de diversas fuentes y formatos. Las herramientas de ingestión de datos que admiten diversas fuentes de datos y ofrecen conectores personalizados garantizan la flexibilidad en los sistemas de ingestión de datos.
Por ejemplo, la función de asignación automática de esquemas detecta el esquema de los datos entrantes y los asigna al destino sin restringirlos a una estructura de esquema predefinida. Esto permite que la herramienta ingiera datos de cualquier esquema.
La ingesta de datos por lotes recopila datos según un calendario y los actualiza en el destino. Por otro lado, la ingesta de datos en tiempo real significa transferir datos continuos sin ningún retraso.
Muchas herramientas de ingestión de datos actuales admiten tanto la ingestión de datos por lotes como en tiempo real. Sin embargo, si a menudo trabajas con datos en tiempo real, como eventos de clientes o streaming de vídeo, elige una herramienta con un alto rendimiento y baja latencia.
Las diferentes herramientas de ingestión de datos tienen estructuras de precios variables. Algunos ofrecen precios por niveles, mientras que otros siguen un modelo de pago por uso. Estas soluciones suelen ser más rentables que las herramientas de código abierto, ya que las herramientas gratuitas requieren contratar a expertos para permitir la ingesta de datos. Sin embargo, las herramientas de código abierto ofrecen una gran flexibilidad y personalización para tu caso de uso.
Algunas herramientas de ingestión de datos de pago también ofrecen funciones de nivel empresarial con amplias capacidades de personalización, aunque tienen un coste. Por lo tanto, en función de tu presupuesto y tus necesidades de personalización, debes elegir entre plataformas de pago y plataformas de código abierto.
La elección de la herramienta de ingestión de datos adecuada depende de tus necesidades específicas, ya sea que priorices la transmisión en tiempo real, el procesamiento por lotes, la compatibilidad con la nube o la facilidad de integración. Las herramientas mencionadas anteriormente ofrecen una variedad de opciones que te ayudan a optimizar la recopilación de datos y su carga en los sistemas de destino de manera eficiente.
Si eres nuevo en la ingeniería de datos y deseas profundizar tu comprensión sobre cómo fluyen los datos a través de los canales modernos, consulta el curso Introducción a la ingeniería de datos. Para aquellos interesados en aprender más sobre los procesos ETL y ELT en Python, ETL y ELT en Python es un excelente recurso para obtener experiencia práctica con técnicas de ingestión de datos.
¡Aprende más sobre ingeniería de datos con estos cursos!
Curso
Curso
Curso
blog
Joleen Bothma
12 min
blog
DataCamp Team
12 min
blog
Javier Canales Luna
13 min
blog
Javier Canales Luna
8 min
blog
Javier Canales Luna
7 min
