
Course
Streaming Concepts
2 hr
6.8K
Data ingestion means collecting data from various sources and loading it to the destination. Many data ingestion tools in the market can automate and simplify this process for you.
After careful research and testing, I’ve compiled a list of the top 20 data ingestion tools. Each of these tools offers unique features, whether you need real-time processing, batch ingestion, or support for diverse data sources.
Let’s dive into the tools and explore their capabilities and ideal use cases!
Apache Kafka is an open-source distributed engine known for its high throughput and low latency. It includes Kafka Connect, a framework for integrating Kafka with external databases, file systems, and key-value stores.
Apache Kafka follows a producer-consumer architecture. Data producers send data to Kafka topics, which act like a middleman, logically organizing the received data within their partitions. Finally, consumers access the required data from these Kafka topics.
Why Apache Kafka for data ingestion?
For readers interested in real-time data ingestion, check out Introduction to Apache Kafka to learn how to process streaming data efficiently.
Apache NiFi is built to automate data flow between systems. Unlike Kafka, it provides an intuitive interface for designing, deploying, and monitoring the data flow.
The tool uses processors for data ingestion. Processors in NiFi handle various functions such as extracting, publishing, transforming, or routing data. For example, prebuilt processors like InvokeHTTP pull data from REST API, and GetKafka retrieves messages from Kafka topics.
Once the processors start ingesting data, FlowFiles are created for each data unit. These FlowFiles contain metadata along with the actual data and are routed to their respective destinations based on defined rules.
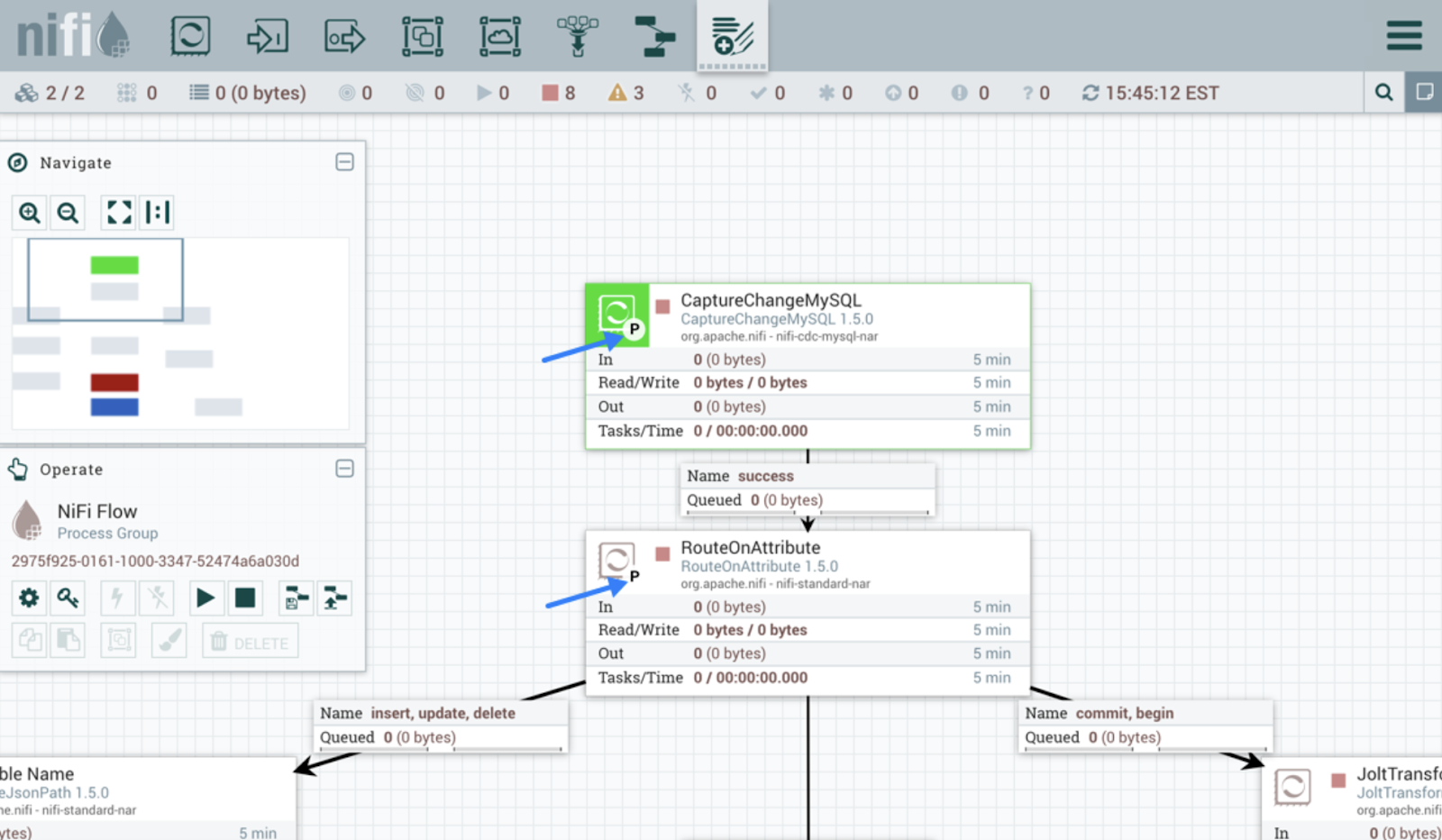
Apache NiFi user interface. Image source: Apache NiFi user guide.
AWS Glue is a serverless data integration service from Amazon. It discovers, transforms, and loads data to destinations for analytics or ML use cases. The platform offers both user-friendly GUI and development environments like Jupyter notebooks.
Crawlers and ETL jobs are the two main components in AWS Glue. Crawlers scan the data sources to detect schema and add metadata to catalogs. ETL jobs can then easily discover the data source and its structure using the catalog information.
AWS Glue provides several ways to create and execute pipelines. For example, ETL jobs can be written in Python or Scala to transform and load the data. For non-coders, Glue Studio offers an intuitive interface to create workflows without requiring you to code.
If you’re exploring serverless ETL solutions, take a look at this AWS Glue tutorial for a hands-on guide to building scalable data pipelines.
Dataflow is a fully managed Google Cloud service for stream and batch processing. It can handle simple data pipelines, such as moving data between systems at scheduled intervals, as well as advanced real-time pipelines.
Moreover, the tool is highly scalable and supports a seamless transition from batch to stream processing when required.
Google dataflow is built on top of Apache Beam. So you can code ingestion pipelines using Beam SDKs. Additionally, the tool offers predefined workflow templates to create pipelines instantly. Developers can also create custom templates and make them available for non-tech users to deploy on demand.
Azure Data Factory (ADF) is Microsoft's cloud service for ingesting data from multiple sources. It’s designed to create, schedule, and orchestrate workflows to automate the process.
ADF itself doesn’t store any data. It supports data movement between systems and processes it through computing resources on remote servers.
The platform has more than 90 built-in connectors to link various data sources, including on-premise data stores, REST APIs, and cloud servers. Then, the component ‘copy activity’ copies the data from the source to the sink.
If you already use Microsoft services for other data operations, Azure Data Factory is a one-stop solution for your data ingestion needs. Our Azure Data Factory tutorial walks you through setting up data ingestion workflows on Azure.
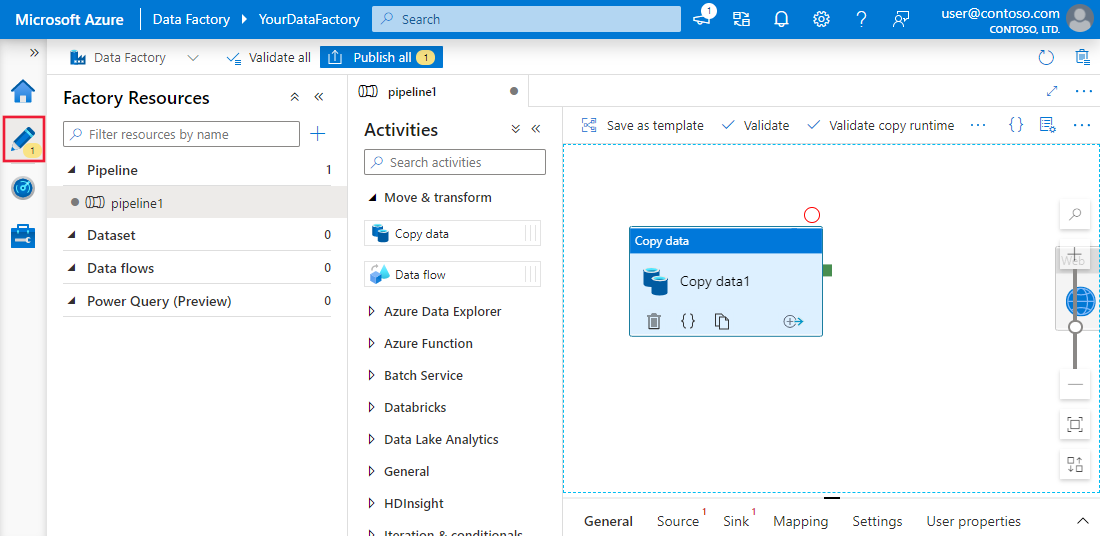
Azure Data Factory and Synapse Analytics user interface experience. Image source: Microsoft Learn
Talend is an open-source, end-to-end data integration platform. It makes building data ingestion workflows straightforward, offering drag-and-drop components for connecting different sources and destinations.
Talend is known for moving data between systems while maintaining quality. Its robust set of data quality tools ensures data accuracy during ingestion. Additionally, the built-in monitoring capabilities enable compliance with data security and governance rules.
Fivetran is a popular data integration platform that automates ELT tasks. It delivers uninterrupted data by automatically adapting data format changes. This feature also helps maintain data accuracy through schema mapping during ingestion.
The main advantage of tools like Fivetran is that they have zero maintenance. Its automatic schema management and monitoring enables self-maintaining pipelines.
Moreover, the tool includes CDC(change data capture) capabilities, ensuring the destination remains up-to-date in real time.
For those unfamiliar, CDC refers to the process of identifying recent updates made to a database and reflecting them in the destination in real-time.
Airbyte is another open-source data ingestion tool on the list. It is the most popular data integration platform, and over 3000 companies use it.
With over 300 pre-made connectors, Airbyte offers the most extensive support for various source and destination connections. Moreover, being open source, you can dig into these connectors’ code and customize them. If your use case isn’t covered, you can write your own source connector.
Airbyte requires technical expertise to set up and maintain pipelines, especially custom connectors. However, it has paid plans with fully managed services and dedicated support.
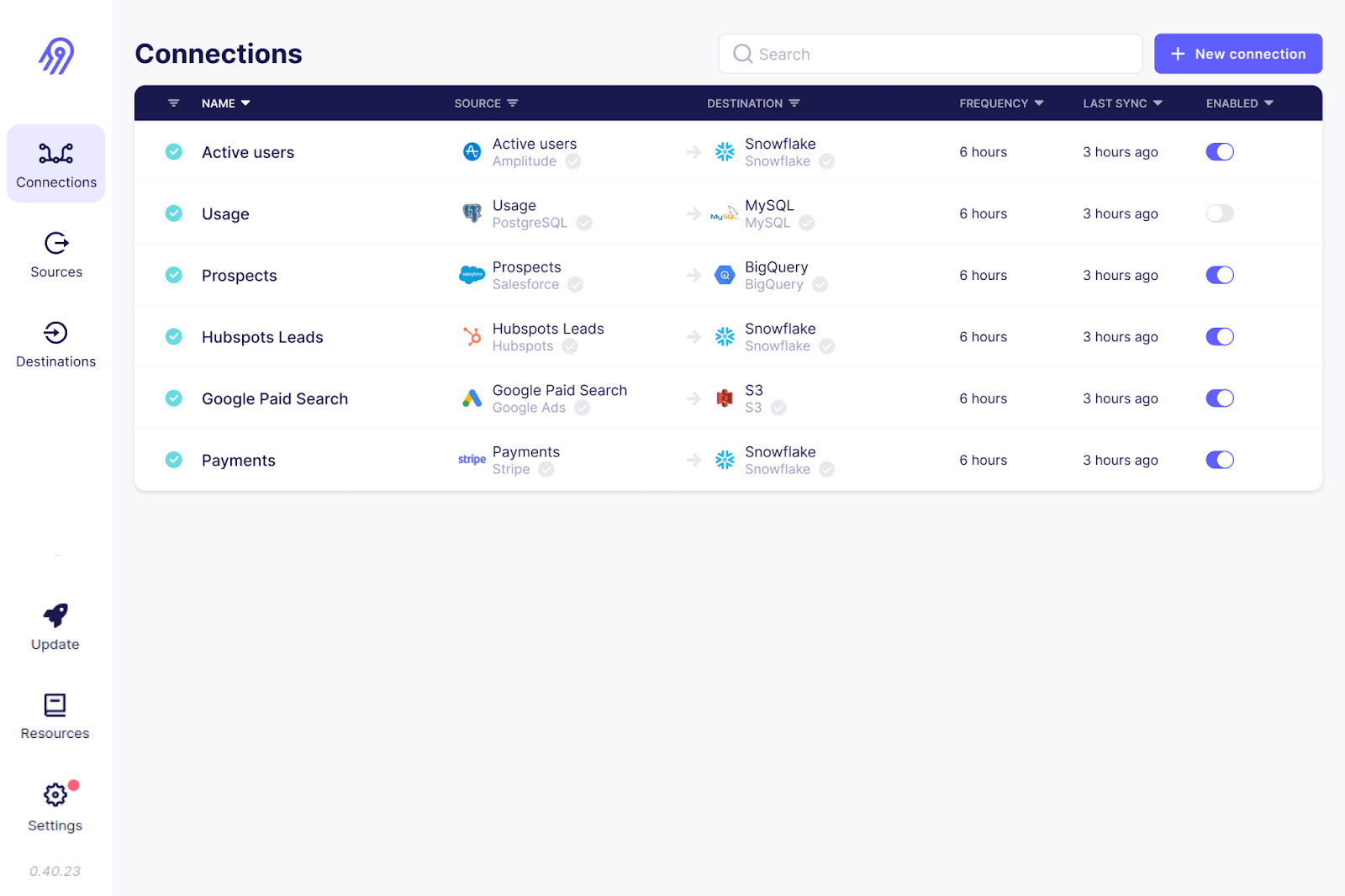
The Airbyte user interface. Image source: Airbyte GitHub
Informatica’s intelligent data management cloud contains a suite of tools to simplify data ingestion. Its ‘Data Loader’ tool takes only a few minutes to load data from 30+ cloud services.
Informatica also has an application integration tool that connects disparate software systems, both on-premises and in the cloud. Its cloud data integration platform is well designed for high-performance data ingestion with ETL/ELT.
Designed to handle batch and real-time data, Informatica allows ingest any type of data from relational databases, applications, and file systems. Additionally, the platform provides AI capabilities like CLAIRE Engine, which analyzes metadata information and suggests relevant datasets for your data ingestion needs.
Apache Flume is a distributed and reliable service for loading log data to destinations. Its flexible architecture is specially designed for streaming data flows, such as from multiple web servers to HDFS or ElasticSearch in near real-time.
The Flume agent is the main component responsible for data movements. It is made up of a channel, sink, and source. The source component picks the data files from the source data, and the sink ensures the sync between the destination and the source. Multiple Flume agents can be configured for parallel data ingestion when streaming large volumes of data.
Apache Flume is known for its fault tolerance. With multiple failover and recovery mechanisms, Flume ensures consistent and reliable data ingestion even in case of failures.
Stitch is a simple and extensible cloud ETL tool. Though it lacks complex custom transformation capabilities, it is perfect for data ingestion tasks.
Like other enterprise ETL tools, Stitch offers a range of connectors to over 140 data sources, typically from SaaS applications and databases into data warehouses and lakes. For custom data ingestion workflows, Stitch integrates with Singer, allowing you to build custom connectors.
Stitch data extraction user interface. Image source: Stitch documentation
StreamSets, acquired by IBM, is an open-source data integration engine for stream, batch, and CDC data. Its ‘Data Collector’ feature provides drag-and-drop source connectors for cloud platforms, such as AWS, Microsoft Azure, and Google Cloud, as well as on-premises systems.
You don’t need IT expertise to create or edit data ingestion pipelines — its data collector drag-and-drop UI is highly intuitive.
StreamSets is a platform-agnostic tool that allows users to build data collector pipelines that suit multiple environments with minimal re-configurations. In addition to data collectors, the platform has data transformers operating on Apache Spark for complex data transformations.
Apache Beam is a unified solution that provides a single programming model for batch and streaming use cases. It works seamlessly with cloud platforms such as Google Cloud Dataflow, Apache Flink, and Apache Spark.
For real-time data ingestion, you can define fixed, sliding, and session windows to group and process data quickly.
Apache Beam stands out for its flexibility. It allows pipelines to be defined in any programming language and run on multiple execution engines.
Hevo Data is a fully managed, no-code platform for moving data from over 150 sources to the destination of your choice. The tool not only handles data ingestion but also transforms the data to make it analytics-ready.
The platform automatically detects the schema of incoming data and matches it to the destination schema, providing flexibility.
Hevo data also offers robust fault-tolerant architecture, ensuring no data loss during data ingestion. Overall, Hevo Data is the go-to choice for streaming and real-time analytics use cases.
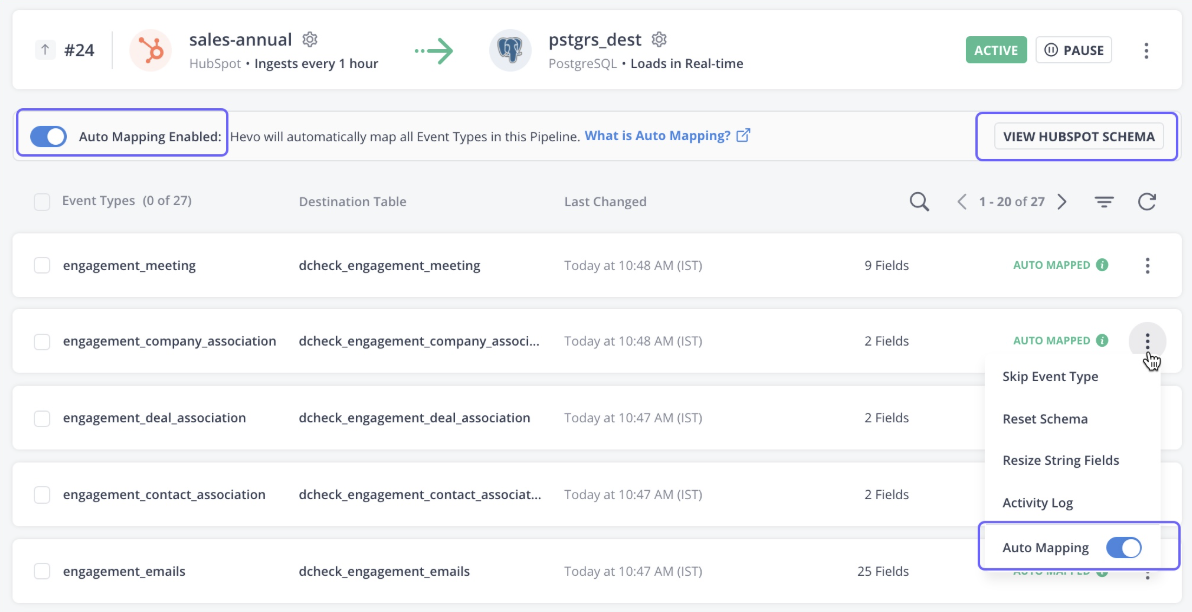
Hevo data user interface. Image source: Hevo documentation
Segment is a customer data platform, providing clean and transformed customer data for analytics. The platform is specialized for collecting various types of customer data, such as interactions, impressions, clicks, and other behavioral data.
The tool's Track API collects event data from multiple sources, including mobile, web, and server. With just a few clicks, the data can be integrated with over 450 apps.
The data collected through Segment is available to users via SQL queries, while programmers can access real-time data using curl commands.
Matillion is a cloud-native data integration platform designed to move and transform data within the cloud. It is best designed for powerful cloud data warehouses like Snowflake, Amazon Redshift, and Google BigQuery.
The platform provides a wide range of pre-built connectors for both cloud and on-premises data sources, including databases, SaaS applications, social media platforms, and more.
With its focus on performance, Matilion also offers strong transformation capabilities to clean and prepare data for further analysis.
Keboola, specially designed for performing complex transformations, provides custom data ingestion facilities. With over 250 built-in integrations between sources and destinations, It automates data ingestion within a few clicks.
Keboola supports both batch and real-time data streaming to import enterprise data. However, in case of real-time data ingestion, you need coding expertise to set up webhooks.
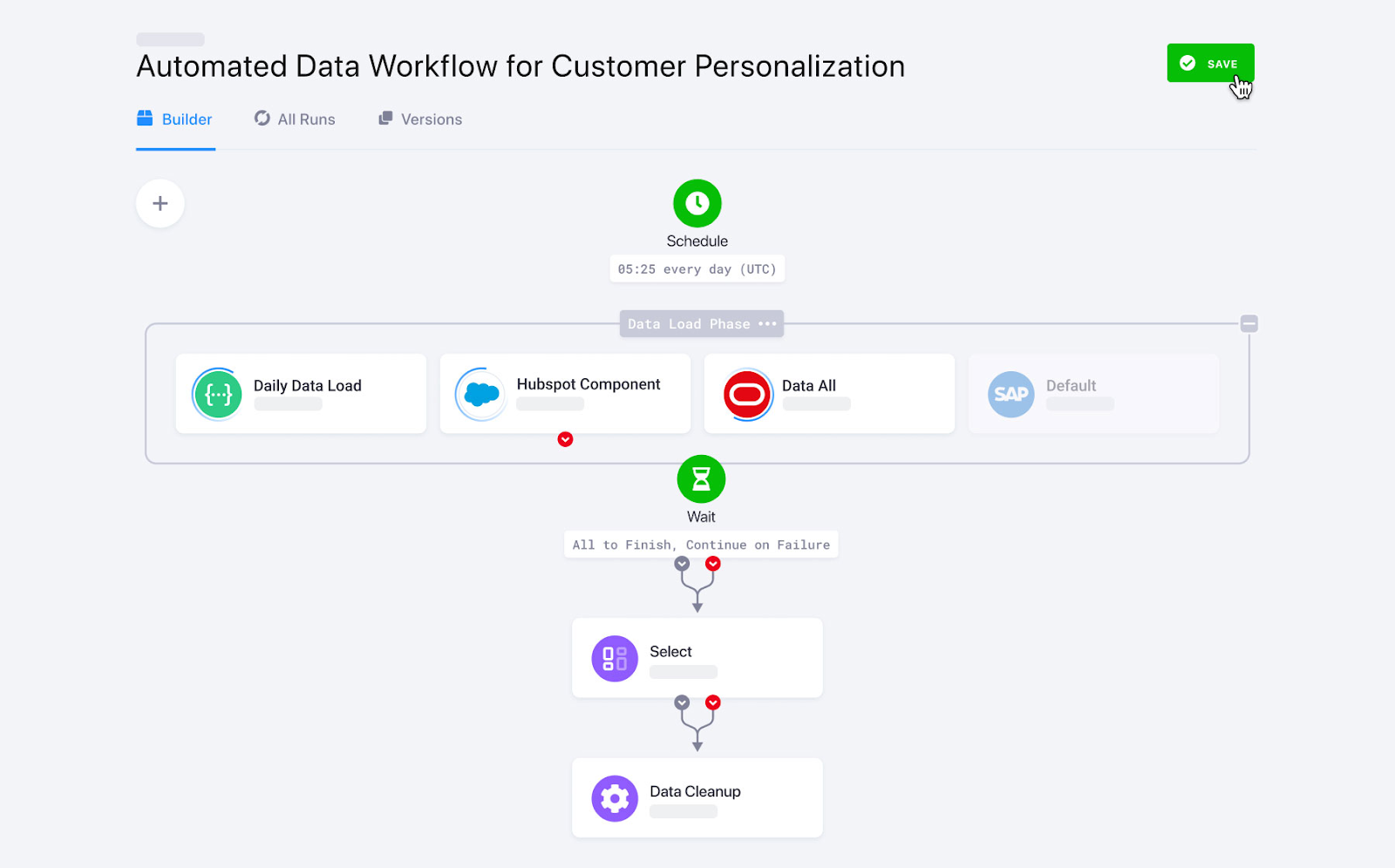
Keboola data workflows. Image source: Keboola
Snowplow is a next-gen data collection platform that captures and processes event data from various sources. It specializes in collecting customer behavioral data and preparing it for advanced AI and machine learning analysis.
Snowplow internally uses trackers and webhooks to collect real-time event data.
Trackers are the libraries or SDKs that can be integrated into mobile apps, websites, and server-side applications. They collect event information like user interactions, clicks, and likes and send it to collectors. The collectors then pass the data through the enrichment process before sending it to the destination warehouse.
IBM DataStage is an industry-leading data integration platform built for ETL and ELT operations. Its basic version is available on-premise, but to experience scale and automation through the cloud, upgrade it to DataStage for IBM Cloud Pak®.
Its extensive set of prebuilt connectors and stages automates the data movement between multiple cloud sources and data warehouses.
For those who set up their data architecture on the IBM ecosystem, DataStage is the go-to tool for data ingestion. It integrates with other IBM data platforms, such as Cloud Object Storage and Db2, for ingestion and transformation.
Alteryx is known for its data analytics and visualization tools. With over 8000 customers, it is a popular analytics platform that automates data and analytics tasks.
Alteryx has a tool called Designer Cloud that offers an intuitive interface for building data ingestion pipelines for analytics and AI use cases. It offers connectivity to various data sources, including data warehouses, cloud storage, and file systems.
Want to simplify data prep and analytics without coding? Learn how to automate workflows with Introduction to Alteryx and unlock drag-and-drop ETL capabilities.
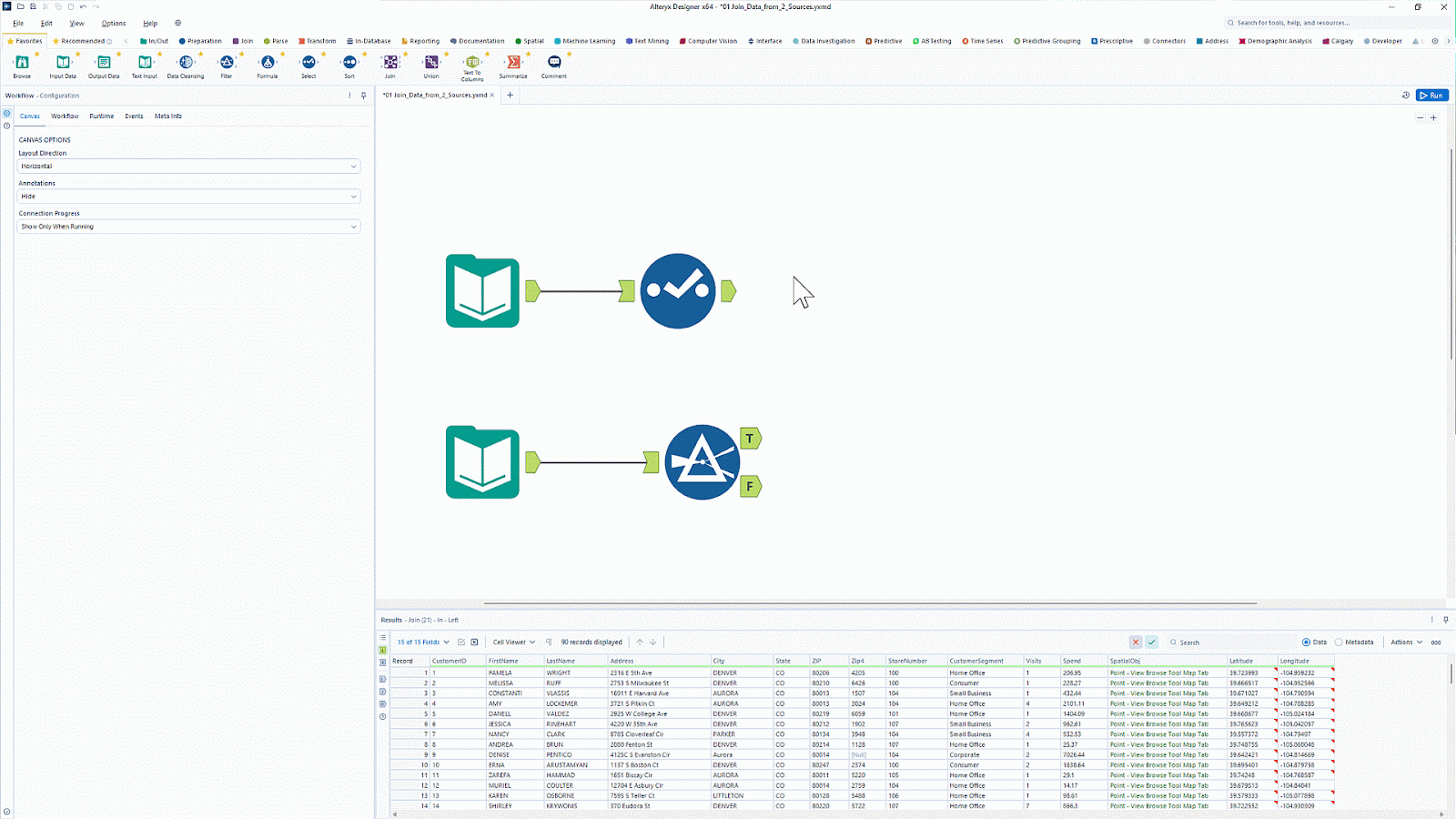
Alteryx drag and drop user interface. Image source: Alteryx
|
Tool |
Best for |
Features |
Pricing |
|
Apache Kafka |
Real-time data streaming |
|
Open-source |
|
Apache Nifi |
Secured real-time data ingestion |
|
Open-source |
|
AWS Glue |
AWS ecosystem |
|
Pay-as-you-go pricing model. Charges are based on the number of data processing used per hour. |
|
Google cloud dataflow |
Google cloud ecosystem |
|
Pay-as-you-go pricing model. Charges are based on the compute resources and memory utilized. |
|
Azure data factory |
Enterprises using other Microsoft’s Azure services |
|
Pay-as-you-go pricing model |
|
Talend |
Low-budget companies seeking intuitive ETL solution |
|
Open-source |
|
Fivetran |
Fully managed ELT needs |
|
Subscription-based pricing |
|
Airbyte |
Organizations looking for an open-source customization solution |
|
Open-source as well as paid services are available. |
|
Informatica |
Enterprises seeking low-code tools with extensive source connectors |
|
free 30-day trial, pay-as-you-go pricing model |
|
Apache Flume |
Streaming data flows |
|
Open-source |
|
Stitch |
Organizations looking for a simple tool for data ingestion tasks |
|
You can either choose tier-based or pay as you use model pricing models |
|
StreamSets |
Complex data transformations |
|
Both open-source and commercial options are available |
|
Apache Beam |
Customizable code-centric framework for building data ingestion pipelines |
|
Apache Beam framework is open-source, but cost is incurred when used with cloud services. |
|
Hevo Data |
Mid-sized businesses needing real-time analytics |
|
Subscription-based pricing |
|
Segment |
Customer event data |
|
Subscription pricing model |
|
Matillion |
Cloud-native ETL/ELT tool |
|
Subscription-based pricing model |
|
Keboola |
Complex data transformation pipelines |
|
Subscription-based pricing model |
|
Snowplow |
Collecting event data |
|
Both open-source and commercial options are available |
|
IBM DataStage |
IBM cloud ecosystem |
|
Subscription-based pricing model |
|
Alteryx |
Data analytics and visualization |
|
Subscription-based pricing model |
With so many tools in the industry, choosing the right data integration platform for your purposes may be difficult. Here is a list of some of the factors you should consider before opting for one specific data integration tool.
You can easily ingest an Excel sheet or CSV file into target destinations. However, manually ingesting real-time streaming data from multiple sources to various destinations can be challenging. For example, modern applications, such as social media, often experience peak demand at times and low at others. This is where the scalability feature of data ingestion tools shines.
Scalability refers to the ability to grow or shrink based on demand. This allows the tool to quickly adapt to the growing demands of data volumes without compromising performance.
Flexibility refers to the ability to handle data from various sources and formats. Data ingestion tools that support various data sources and offer custom connectors ensure flexibility in data ingestion systems.
For example, the automatic schema mapping feature detects the schema of incoming data and maps it to the destination without restricting it to a predefined schema structure. This allows the tool to ingest data of any schema.
Batch data ingestion collects data on a schedule and updates it at the destination. On the other hand, real-time data ingestion means transferring continuous data with zero delay.
Many data ingestion tools today support both batch and real-time data ingestion. However, if you often deal with real-time data, such as customer events or video streaming, choose a tool with high throughput and low latency capabilities.
Different data ingestion tools have varying pricing structures. Some offer tier-based pricing, while others follow a pay-as-you-go model. These solutions are often more cost-effective than open-source tools because free tools require you to hire experts to enable data ingestion. However, open-source tools offer high flexibility and customization for your use case.
Some paid data ingestion tools also provide enterprise-grade features with extensive customization capabilities, though they come at a cost. Therefore, based on your budget and customization needs, you should choose between paid and open-source platforms.
Choosing the right data ingestion tool depends on your specific needs—whether you prioritize real-time streaming, batch processing, cloud compatibility, or ease of integration. The tools listed above offer a variety of options, helping you streamline data collection and loading into your destination systems efficiently.
If you're new to data engineering and want to deepen your understanding of how data flows through modern pipelines, check out the Introduction to Data Engineering course. For those interested in learning more about ETL and ELT processes in Python, ETL and ELT in Python is a great resource to get hands-on experience with data ingestion techniques.
Learn more about data engineering with these courses!
Course
Course
Course
blog
Kurtis Pykes
14 min
blog
Abid Ali Awan
9 min
blog
Javier Canales Luna
13 min
blog
Kurtis Pykes
14 min
blog
Joleen Bothma
12 min
blog
Abid Ali Awan
10 min
