
Cours
Concepts de streaming
2 h
6.8K
L'ingestion de données consiste à collecter des données provenant de diverses sources et à les charger vers leur destination. De nombreux outils d'ingestion de données disponibles sur le marché peuvent automatiser et simplifier ce processus pour vous.
Après des recherches et des tests minutieux, j'ai dressé une liste des 20 meilleurs outils d'ingestion de données. Chacun de ces outils offre des fonctionnalités uniques, que vous ayez besoin d'un traitement en temps réel, d'une ingestion par lots ou d'une prise en charge de diverses sources de données.
Explorons ces outils, leurs fonctionnalités et leurs cas d'utilisation idéaux.
Apache Kafka est un moteur distribué open source réputé pour son débit élevé et sa faible latence. Il inclut Kafka Connect, un framework permettant d'intégrer Kafka à des bases de données externes, des systèmes de fichiers et des magasins de valeurs-clés.
Apache Kafka suit une architecture producteur-consommateur. Les producteurs de données transmettent les données aux sujets Kafka, qui agissent comme des intermédiaires, organisant de manière logique les données reçues au sein de leurs partitions. Enfin, les consommateurs accèdent aux données requises à partir de ces sujets Kafka.
Pourquoi choisir Apache Kafka pour l'ingestion de données ?
Pour les lecteurs intéressés par l'ingestion de données en temps réel, veuillez consulter l'introduction à Apache Kafka afin d'apprendre à traiter efficacement les données en continu.
Apache NiFi est conçu pour automatiser le flux de données entre les systèmes. Contrairement à Kafka, il offre une interface intuitive pour la conception, le déploiement et la surveillance du flux de données.
Cet outil utilise des processeurs pour l'ingestion des données. Les processeurs NiFi gèrent diverses fonctions telles que l'extraction, la publication, la transformation ou le routage des données. Par exemple, les processeurs préconfigurés tels que InvokeHTTP extraient des données à partir de l'API REST, et GetKafka récupère des messages à partir des rubriques Kafka.
Une fois que les processeurs commencent à ingérer les données, des FlowFiles sont créés pour chaque unité de données. Ces FlowFiles contiennent des métadonnées ainsi que les données réelles et sont acheminées vers leurs destinations respectives en fonction de règles définies.
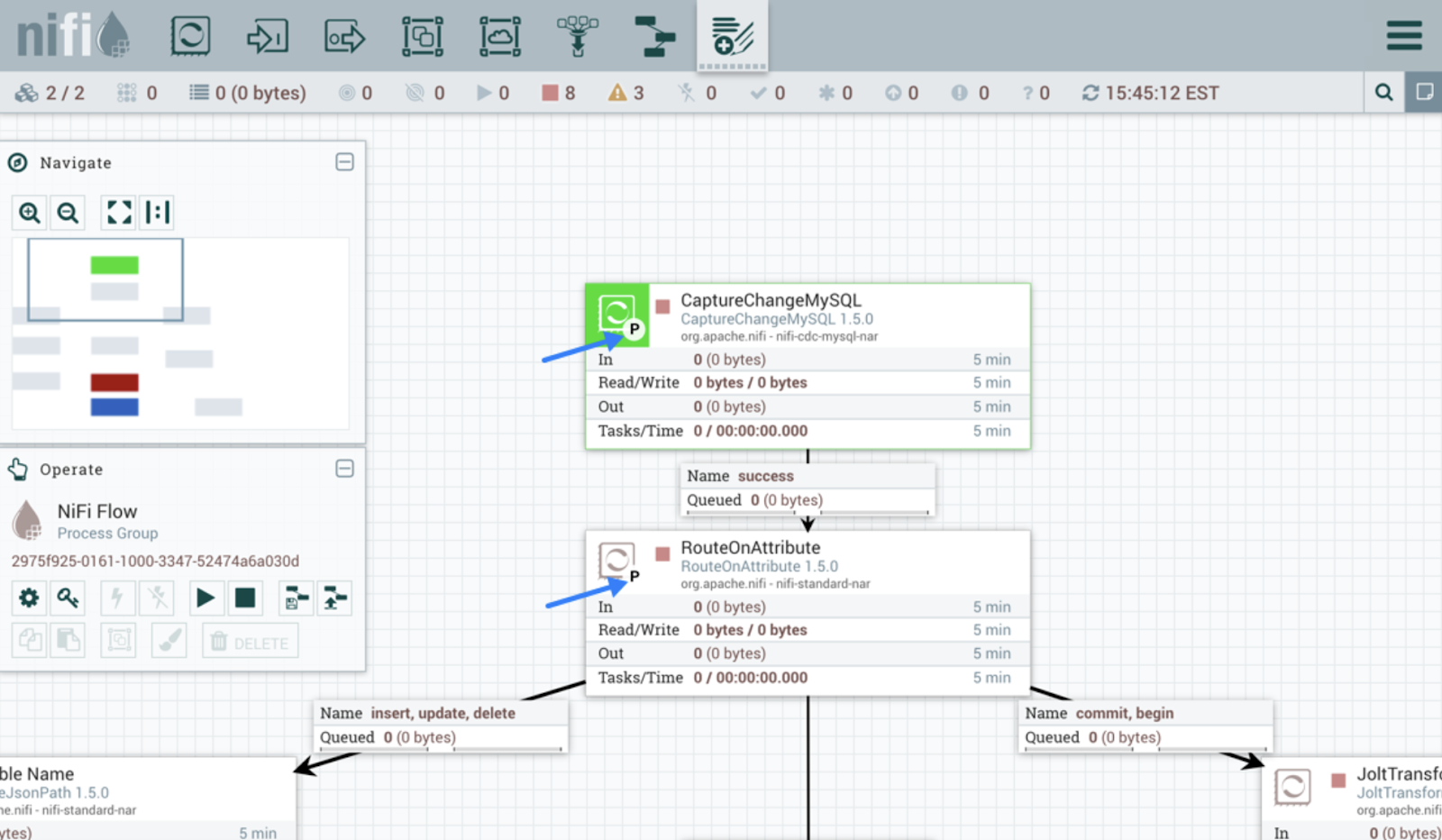
Interface utilisateur Apache NiFi. Source de l'image :e : Guide de l'utilisateur Apache NiFi.
AWS Glue est un service d'intégration de données sans serveur proposé par Amazon. Il identifie, transforme et charge les données vers des destinations pour des cas d'utilisation liés à l'analyse ou au ML. La plateforme propose à la fois une interface graphique conviviale et des environnements de développement tels que les notebooks Jupyter.
Les crawlers et les tâches ETL constituent les deux principaux composants d'AWS Glue. Les robots d'indexation analysent les sources de données afin de détecter les schémas et d'ajouter des métadonnées aux catalogues. Les tâches ETL peuvent alors facilement identifier la source de données et sa structure à l'aide des informations du catalogue.
AWS Glue propose plusieurs méthodes pour créer et exécuter des pipelines. Par exemple, les tâches ETL peuvent être programmées en Python ou en Scala pour transformer et charger les données. Pour les personnes qui ne maîtrisent pas le codage, Glue Studio propose une interface intuitive permettant de créer des flux de travail sans avoir besoin de coder.
Si vous envisagez d'adopter des solutions ETL sans serveur, nous vous invitons à consulter ce tutoriel AWS Glue qui vous fournira des conseils pratiques pour créer des pipelines de données évolutifs.
Dataflow est un service Google Cloud entièrement géré pour le traitement en continu et par lots. Il est capable de gérer des pipelines de données simples, tels que le transfert de données entre des systèmes à intervalles réguliers, ainsi que des pipelines avancés en temps réel.
De plus, cet outil est hautement évolutif et permet une transition fluide du traitement par lots au traitement en continu lorsque cela est nécessaire.
Google Dataflow est basé sur Apache Beam. Vous pouvez donc coder des pipelines d'ingestion à l'aide des SDK Beam. De plus, cet outil propose des modèles de flux de travail prédéfinis pour créer instantanément des pipelines. Les développeurs peuvent également créer des modèles personnalisés et les mettre à la disposition des utilisateurs non techniciens afin qu'ils puissent les déployer à la demande.
Azure Data Factory (ADF) est le service cloud de Microsoft permettant d'ingérer des données provenant de plusieurs sources. Il est conçu pour créer, planifier et coordonner des flux de travail afin d'automatiser le processus.
ADF ne stocke aucune donnée. Il facilite le transfert de données entre les systèmes et les traite à l'aide de ressources informatiques sur des serveurs distants.
La plateforme dispose de plus de 90 connecteurs intégrés pour relier diverses sources de données, notamment des magasins de données sur site, des API REST et des serveurs cloud. Ensuite, le composant « copier l'activité » transfère les données de la source vers le récepteur.
Si vous utilisez déjà les services Microsoft pour d'autres opérations de données, Azure Data Factory constitue une solution unique pour vos besoins en matière d'ingestion de données. Notre tutoriel Azure Data Factory vous guide dans la configuration des workflows d'ingestion de données sur Azure.
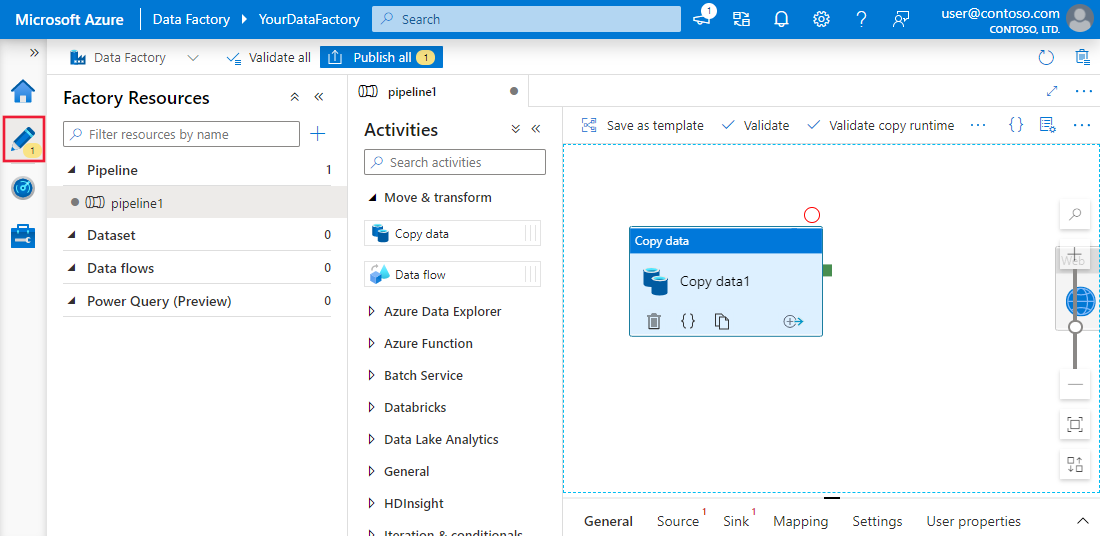
Expérience utilisateur d'Azure Data Factory et Synapse Analytics. Source de l'image Microsoft Learn
Talend est une plateforme d'intégration de données open source de bout en bout. Il simplifie la création de workflows d'ingestion de données en proposant des composants glisser-déposer pour connecter différentes sources et destinations.
Talend est reconnu pour transférer des données entre différents systèmes tout en préservant leur qualité. Son ensemble complet d'outils de qualité des données garantit l'exactitude des données lors de leur intégration. De plus, les capacités de surveillance intégrées permettent de se conformer aux règles de sécurité et de gouvernance des données.
Fivetran est une plateforme d'intégration de données réputée qui automatise les tâches ELT. Il assure la transmission ininterrompue des données en s'adaptant automatiquement aux changements de format des données. Cette fonctionnalité contribue également à maintenir l'exactitude des données grâce au mappage de schéma lors de l'ingestion.
Le principal avantage des outils tels que Fivetran réside dans le fait qu'ils ne nécessitent aucune maintenance. Sa gestion et sa surveillance automatiques des schémas permettent une maintenance autonome des pipelines.
De plus, cet outil intègre des fonctionnalités CDC (capture des données modifiées), garantissant ainsi que la destination reste à jour en temps réel.
Pour ceux qui ne sont pas familiers avec ce terme, le CDC désigne le processus qui consiste à identifier les mises à jour récentes effectuées dans une base de données et à les refléter en temps réel dans la destination.
Airbyte est un autre outil open source de collecte de données figurant sur la liste. Il s'agit de la plateforme d'intégration de données la plus populaire, utilisée par plus de 3 000 entreprises.
Avec plus de 300 connecteurs préconfigurés, Airbyte offre la prise en charge la plus complète pour diverses connexions sources et destinations. De plus, étant open source, vous pouvez examiner le code de ces connecteurs et les personnaliser. Si votre cas d'utilisation n'est pas couvert, vous pouvez créer votre propre connecteur source.
Airbyte nécessite une expertise technique pour configurer et maintenir les pipelines, en particulier les connecteurs personnalisés. Cependant, il propose des formules payantes avec des services entièrement gérés et une assistance dédiée.
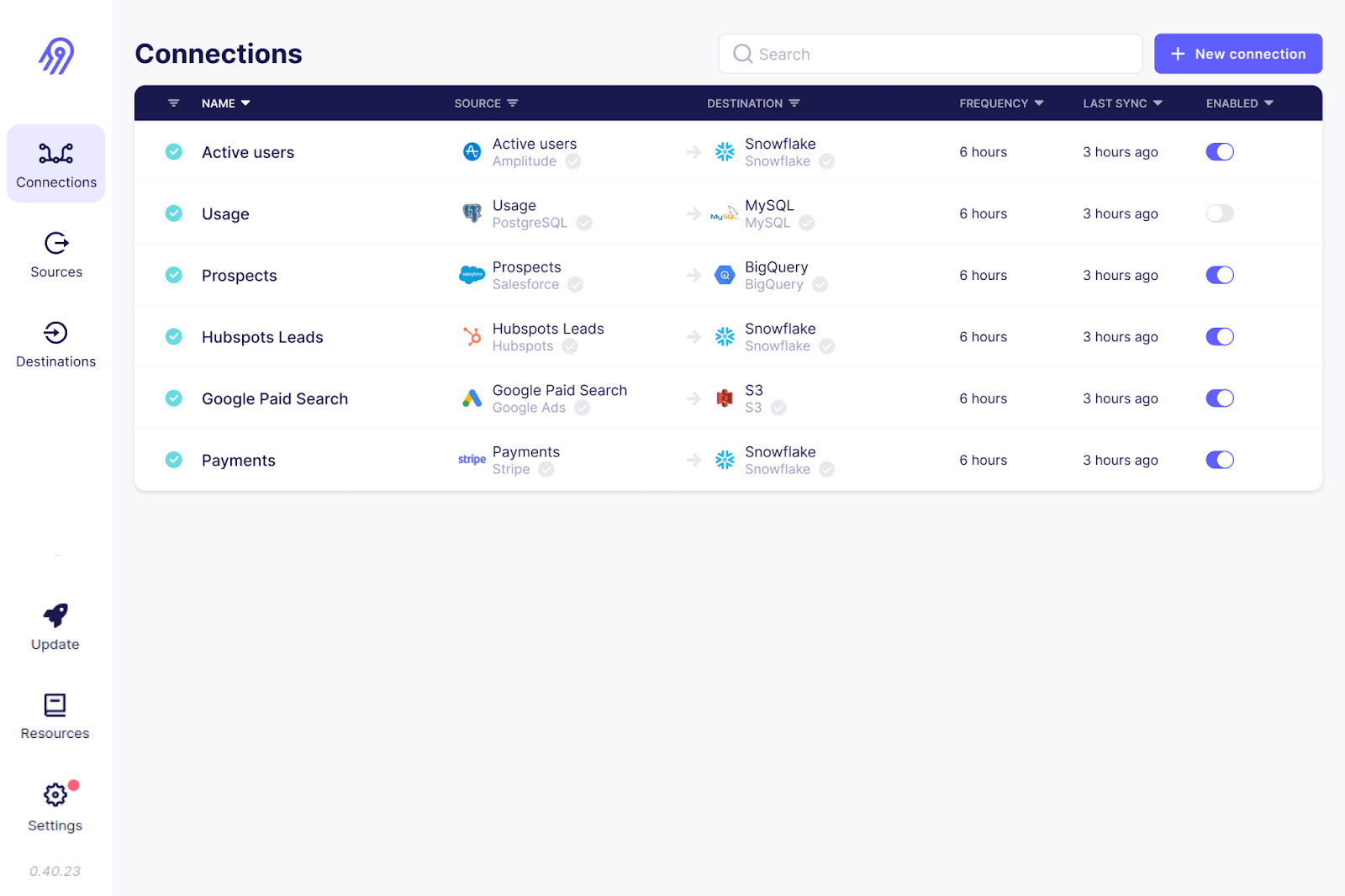
L'interface utilisateur Airbyte. Source de l'image: Airbyte GitHub
Le cloud de gestion intelligente des données d'Informatica comprend une suite d'outils destinés à simplifier l'ingestion des données. Son outil « Data Loader » ne nécessite que quelques minutes pour charger les données provenant de plus de 30 services cloud.
Informatica propose également un outil d'intégration d'applications qui relie des systèmes logiciels disparates, tant sur site que dans le cloud. Sa plateforme d'intégration de données dans le cloud est conçue pour une ingestion de données haute performance avec ETL/ELT.
Conçu pour traiter des données par lots et en temps réel, Informatica permet d'ingérer tout type de données provenant de bases de données relationnelles, d'applications et de systèmes de fichiers. De plus, la plateforme offre des fonctionnalités d'intelligence artificielle telles que CLAIRE Engine, qui analyse les métadonnées et suggère des ensembles de données pertinents pour vos besoins en matière d'ingestion de données.
Apache Flume est un service distribué et fiable permettant de charger des données de journalisation vers des destinations. Son architecture flexible est spécialement conçue pour les flux de données en continu, par exemple depuis plusieurs serveurs Web vers HDFS ou ElasticSearch, en temps quasi réel.
L'agent Flume est le principal composant responsable des mouvements de données. Il est composé d'un canal, d'un récepteur et d'une source. Le composant source sélectionne les fichiers de données à partir des données source, et le composant récepteur assure la synchronisation entre la destination et la source. Plusieurs agents Flume peuvent être configurés pour l'ingestion parallèle de données lors du streaming de grands volumes de données.
Apache Flume est réputé pour sa tolérance aux pannes. Grâce à ses multiples mécanismes de basculement et de récupération, Flume garantit une ingestion de données cohérente et fiable, même en cas de défaillance.
Stitch est un outil ETL cloud simple et extensible. Bien qu'il ne dispose pas de capacités de transformation personnalisées complexes, il est idéal pour les tâches d'ingestion de données.
À l'instar d'autres outils ETL d'entreprise, Stitch propose une gamme de connecteurs vers plus de 140 sources de données, généralement issues d'applications SaaS et de bases de données vers des entrepôts et des lacs de données. Pour les workflows d'ingestion de données personnalisés, Stitch s'intègre à Singer, vous permettant ainsi de créer des connecteurs personnalisés.
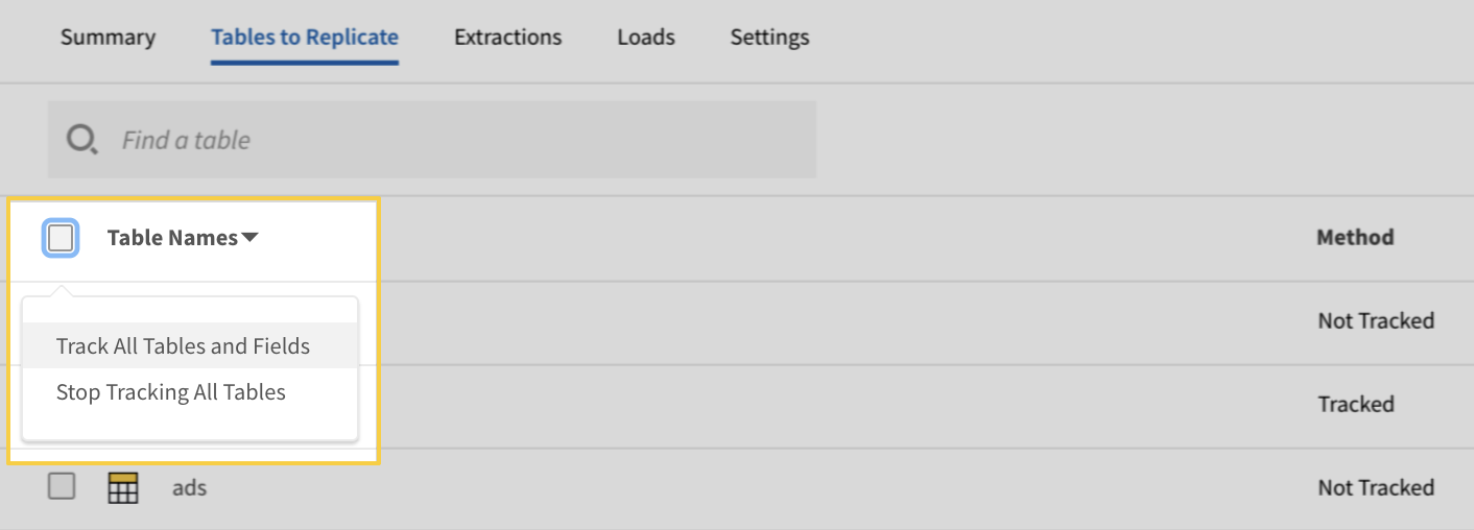
Interface utilisateur pour l'extraction des données de points de couture. Source de l'image « I» : Documentation relative aux points de couture
StreamSets, racheté par IBM, est un moteur d'intégration de données open source pour les données en flux continu, par lots et CDC. Sa fonctionnalité « Data Collector » fournit des connecteurs source par glisser-déposer pour les plateformes cloud, telles qu'AWS, Microsoft Azure et Google Cloud, ainsi que pour les systèmes sur site.
Il n'est pas nécessaire de posséder des compétences informatiques pour créer ou modifier des pipelines d'ingestion de données : l'interface utilisateur de type glisser-déposer du collecteur de données est extrêmement intuitive.
StreamSets est un outil indépendant de toute plateforme qui permet aux utilisateurs de créer des pipelines de collecte de données adaptés à plusieurs environnements avec un minimum de reconfigurations. Outre les collecteurs de données, la plateforme dispose de transformateurs de données fonctionnant sur Apache Spark pour les transformations de données complexes.
Apache Beam est une solution unifiée qui fournit un modèle de programmation unique pour les cas d'utilisation par lots et en continu. Il fonctionne de manière transparente avec les plateformes cloud telles que Google Cloud Dataflow, Apache Flink et Apache Spark.
Pour l'ingestion de données en temps réel, il est possible de définir des fenêtres fixes, glissantes et de session afin de regrouper et de traiter rapidement les données.
Apache Beam se distingue par sa flexibilité. Il permet de définir des pipelines dans n'importe quel langage de programmation et de les exécuter sur plusieurs moteurs d'exécution.
Hevo Data est une plateforme entièrement gérée et sans code permettant de transférer des données provenant de plus de 150 sources vers la destination de votre choix. Cet outil ne se contente pas de gérer l'ingestion des données, il les transforme également afin de les rendre prêtes à être analysées.
La plateforme détecte automatiquement le schéma des données entrantes et le fait correspondre au schéma de destination, offrant ainsi une grande flexibilité.
Les données Hevo offrent également une architecture robuste et tolérante aux pannes, garantissant qu'aucune perte de données ne se produit lors de l'ingestion des données. Dans l'ensemble, Hevo Data constitue le choix idéal pour les cas d'utilisation liés au streaming et à l'analyse en temps réel.
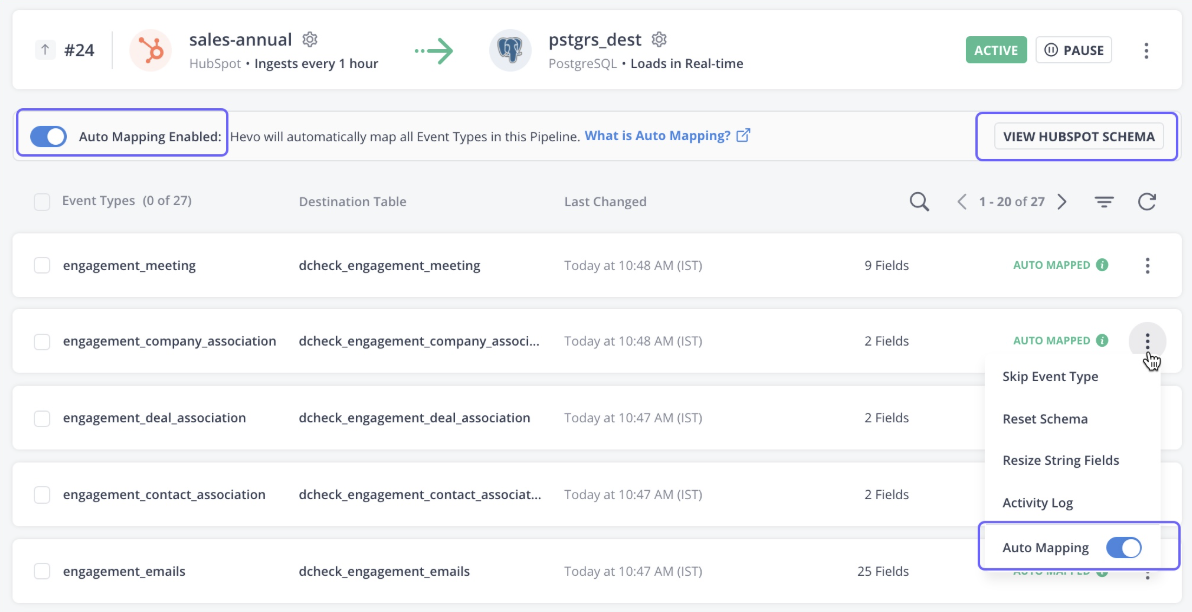
Interface utilisateur des données Hevo. Source de l'image : Documentation Hevo
Segment est une plateforme de données clients qui fournit des données clients propres et transformées à des fins d'analyse. La plateforme est spécialisée dans la collecte de divers types de données clients, telles que les interactions, les impressions, les clics et d'autres données comportementales.
L'API cursus de l'outil collecte des données d'événements provenant de plusieurs sources, notamment les appareils mobiles, le Web et les serveurs. En quelques clics, les données peuvent être intégrées à plus de 450 applications.
Les données collectées via Segment sont accessibles aux utilisateurs via des requêtes SQL, tandis que les programmeurs peuvent accéder aux données en temps réel à l'aide de commandes curl.
Matillion est une plateforme d'intégration de données native du cloud conçue pour déplacer et transformer les données au sein du cloud. Il est particulièrement adapté aux entrepôts de données cloud puissants tels que Snowflake, Amazon Redshift et Google BigQuery.
La plateforme offre une large gamme de connecteurs préconfigurés pour les sources de données cloud et sur site, notamment les bases de données, les applications SaaS, les plateformes de réseaux sociaux, etc.
Axé sur la performance, Matilion offre également de solides capacités de transformation pour nettoyer et préparer les données en vue d'une analyse plus approfondie.
Keboola, spécialement conçu pour effectuer des transformations complexes, offre des fonctionnalités personnalisées d'ingestion de données. Avec plus de 250 intégrations intégrées entre les sources et les destinations, il automatise l'ingestion des données en quelques clics.
Keboola prend en charge à la fois le traitement par lots et le streaming de données en temps réel pour l'importation des données d'entreprise. Toutefois, dans le cas d'une ingestion de données en temps réel, des compétences en codage sont nécessaires pour configurer les webhooks.
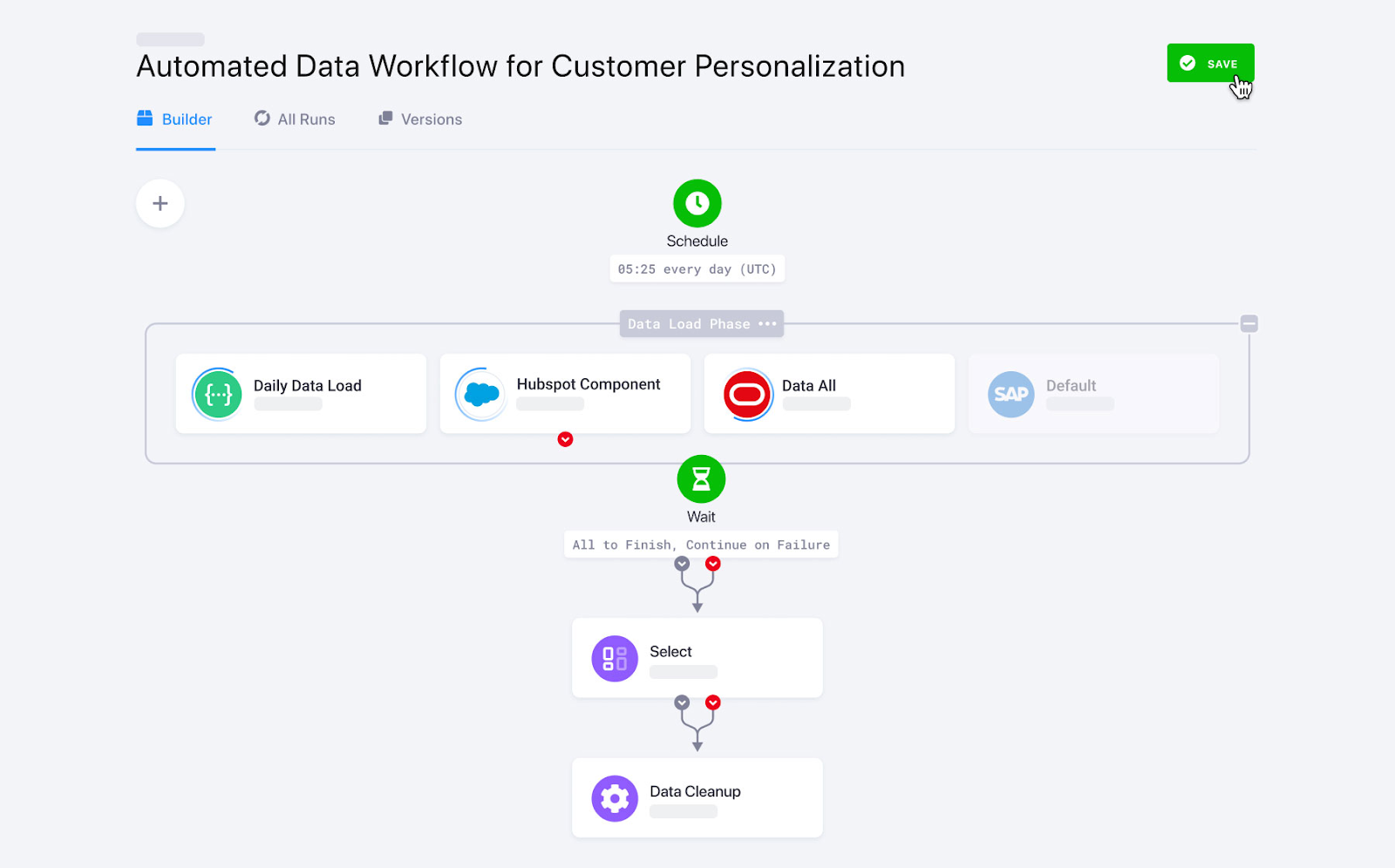
Flux de données Keboola. Source de l'image : Keboola
Snowplow est une plateforme de collecte de données de nouvelle génération qui capture et traite les données événementielles provenant de diverses sources. Elle est spécialisée dans la collecte de données comportementales sur les clients et leur préparation en vue d'une analyse avancée par l'intelligence artificielle et l'apprentissage automatique.
Snowplow utilise en interne des trackers et des webhooks pour collecter des données d'événements en temps réel.
Les trackers sont des bibliothèques ou des SDK pouvant être intégrés dans des applications mobiles, des sites Web et des applications côté serveur. Ils collectent des informations sur les événements, telles que les interactions des utilisateurs, les clics et les mentions « J'aime », et les transmettent aux collecteurs. Les collecteurs soumettent ensuite les données à un processus d'enrichissement avant de les transmettre à l'entrepôt de destination.
IBM DataStage est une plateforme d'intégration de données de pointe conçue pour les opérations ETL et ELT. Sa version de base est disponible sur site, mais pour bénéficier de l'évolutivité et de l'automatisation offertes par le cloud, veuillez effectuer la mise à niveau vers DataStage for IBM Cloud Pak®.
Son ensemble complet de connecteurs et d'étapes prédéfinis automatise le transfert de données entre plusieurs sources cloud et entrepôts de données.
Pour ceux qui ont mis en place leur architecture de données sur l'écosystème IBM, DataStage est l'outil incontournable pour l'ingestion de données. Il s'intègre à d'autres plateformes de données IBM, telles que Cloud Object Storage et Db2, pour l'ingestion et la transformation.
Alteryx est reconnu pour ses outils d'analyse et de visualisation de données. Avec plus de 8 000 clients, il s'agit d'une plateforme d'analyse très appréciée qui automatise les tâches liées aux données et à l'analyse.
Alteryx propose un outil appelé Designer Cloud qui offre une interface intuitive pour créer des pipelines d'ingestion de données destinés à des cas d'utilisation dans le domaine de l'analyse et de l'intelligence artificielle. Il offre une connectivité à diverses sources de données, notamment les entrepôts de données, le stockage dans le cloud et les systèmes de fichiers.
Souhaitez-vous simplifier la préparation et l'analyse des données sans avoir recours au codage ? Découvrez comment automatiser les flux de travail d's grâce à l'introduction à Alteryx etbénéficiez de fonctionnalités ETL par glisser-déposer.
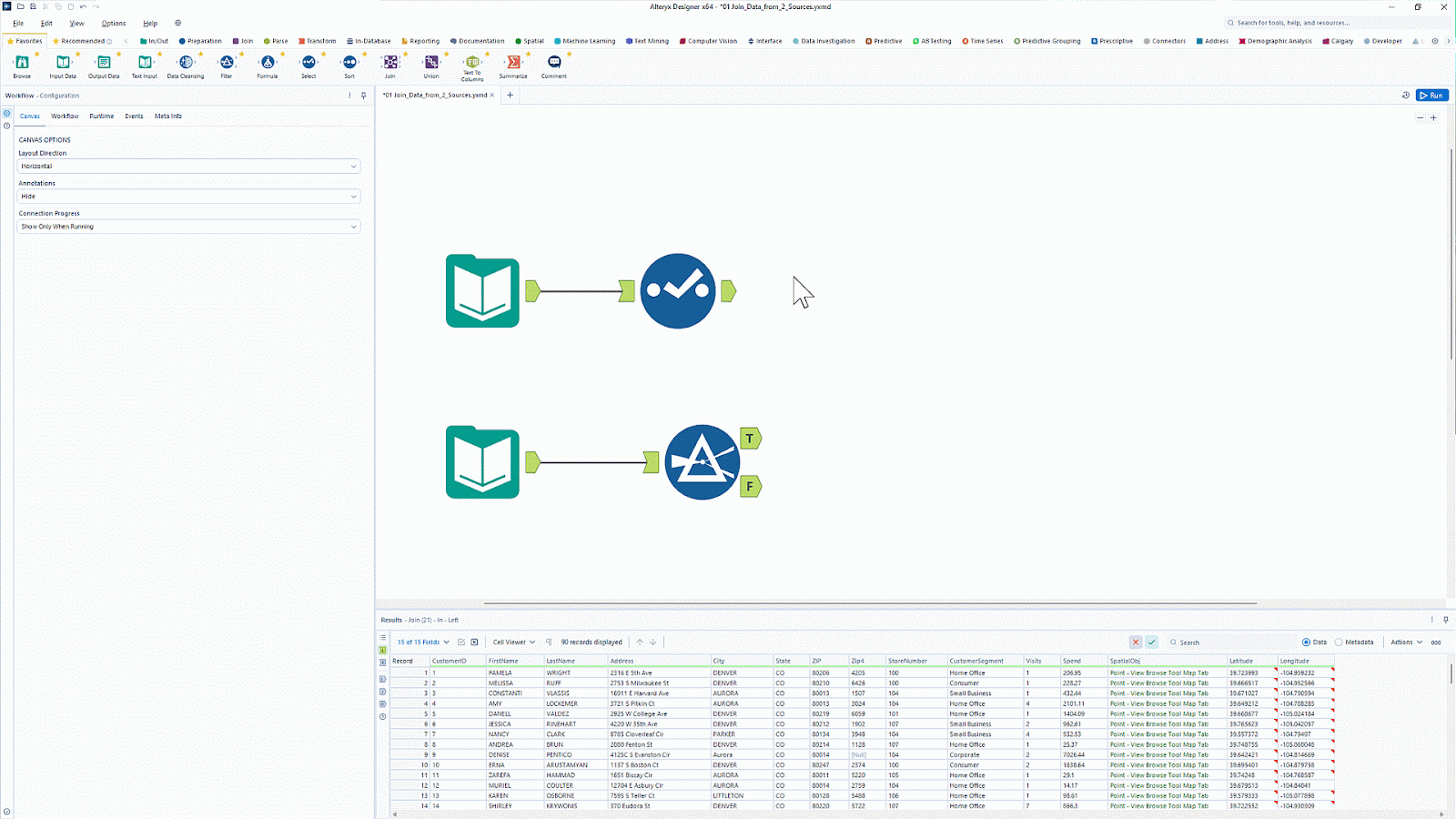
Interface utilisateur Alteryx de type glisser-déposer. Source de l'image : Alteryx
|
Outil |
Idéal pour |
Caractéristiques |
Tarification |
|
Apache Kafka |
Transmission de données en temps réel |
|
Open source |
|
Apache Nifi |
Collecte sécurisée des données en temps réel |
|
Open source |
|
AWS Glue |
Écosystème AWS |
|
Modèle de tarification à l'utilisation. Les frais sont calculés en fonction du nombre de traitements de données effectués par heure. |
|
Google Cloud Dataflow |
Écosystème Google Cloud |
|
Modèle de tarification à l'utilisation. Les frais sont calculés en fonction des ressources informatiques et de la mémoire utilisées. |
|
Usine de données Azure |
Entreprises utilisant d'autres services Azure de Microsoft |
|
Modèle de tarification à l'utilisation |
|
Talend |
Entreprises à budget restreint recherchant une solution ETL intuitive |
|
Open source |
|
Fivetran |
Besoins en matière d'ELT entièrement gérés |
|
Tarification par abonnement |
|
Airbyte |
Les organisations à la recherche d'une solution de personnalisation open source |
|
Des services open source et payants sont disponibles. |
|
Informatica |
Entreprises recherchant des outils low-code avec de nombreux connecteurs de sources |
|
Essai gratuit de 30 jours, modèle de tarification à l'utilisation |
|
Apache Flume |
Flux de données en continu |
|
Open source |
|
Couture |
Les organisations recherchant un outil simple pour les tâches d'ingestion de données |
|
Vous pouvez choisir entre des modèles de tarification par niveau ou des modèles de tarification à l'utilisation. |
|
StreamSets |
Transformations de données complexes |
|
Des options open source et commerciales sont disponibles. |
|
Apache Beam |
Cadre personnalisable axé sur le code pour la création de pipelines d'ingestion de données |
|
Le framework Apache Beam est open source, mais son utilisation avec des services cloud engendre des coûts. |
|
Données Hevo |
Les entreprises de taille moyenne qui ont besoin d'analyses en temps réel |
|
Tarification par abonnement |
|
Segment |
Données relatives aux événements clients |
|
Modèle de tarification par abonnement |
|
Matillion |
Outil ETL/ELT natif du cloud |
|
Modèle de tarification par abonnement |
|
Keboola |
Pipelines complexes de transformation des données |
|
Modèle de tarification par abonnement |
|
Chasse-neige |
Collecte de données événementielles |
|
Des options open source et commerciales sont disponibles. |
|
IBM DataStage |
Écosystème cloud IBM |
|
Modèle de tarification par abonnement |
|
Alteryx |
Analyse et visualisation des données |
|
Modèle de tarification par abonnement |
Avec une telle diversité d'outils disponibles dans le secteur, il peut s'avérer difficile de sélectionner la plateforme d'intégration de données la mieux adaptée à vos besoins. Voici une liste de certains des facteurs à prendre en compte avant de choisir un outil d'intégration de données spécifique.
Vous pouvez facilement importer une feuille Excel ou un fichier CSV dans les destinations cibles. Cependant, l'ingestion manuelle de données en temps réel provenant de plusieurs sources vers diverses destinations peut s'avérer complexe. Par exemple, les applications modernes, telles que les réseaux sociaux, connaissent souvent des pics de demande à certains moments et des creux à d'autres. C'est là que la fonctionnalité d'évolutivité des outils d'ingestion de données démontre son efficacité.
L'évolutivité désigne la capacité à s'adapter à la demande, que ce soit à la hausse ou à la baisse. Cela permet à l'outil de s'adapter rapidement à l'augmentation des volumes de données sans compromettre les performances.
La flexibilité fait référence à la capacité de traiter des données provenant de diverses sources et dans différents formats. Les outils d'ingestion de données qui prennent en charge diverses sources de données et offrent des connecteurs personnalisés garantissent la flexibilité des systèmes d'ingestion de données.
Par exemple, la fonctionnalité de mappage automatique des schémas détecte le schéma des données entrantes et le mappe à la destination sans le restreindre à une structure de schéma prédéfinie. Cela permet à l'outil d'ingérer des données de n'importe quel schéma.
L'ingestion de données par lots collecte les données selon un calendrier défini et les met à jour à leur destination. D'autre part, l'ingestion de données en temps réel implique le transfert continu de données sans aucun délai.
De nombreux outils d'ingestion de données prennent aujourd'hui en charge à la fois l'ingestion de données par lots et en temps réel. Toutefois, si vous traitez fréquemment des données en temps réel, telles que des événements clients ou du streaming vidéo, il est recommandé de choisir un outil offrant un débit élevé et une faible latence.
Les différents outils d'ingestion de données présentent des structures tarifaires variables. Certains proposent une tarification par niveaux, tandis que d'autres appliquent un modèle de paiement à l'utilisation. Ces solutions sont souvent plus rentables que les outils open source, car les outils gratuits nécessitent le recours à des experts pour permettre l'ingestion des données. Cependant, les outils open source offrent une grande flexibilité et personnalisation pour votre cas d'utilisation.
Certains outils payants d'ingestion de données offrent également des fonctionnalités de niveau entreprise avec des capacités de personnalisation étendues, mais ils ont un coût. Par conséquent, en fonction de votre budget et de vos besoins en matière de personnalisation, il est recommandé de choisir entre les plateformes payantes et les plateformes open source.
Le choix de l'outil d'ingestion de données approprié dépend de vos besoins spécifiques, que vous privilégiez le streaming en temps réel, le traitement par lots, la compatibilité avec le cloud ou la facilité d'intégration. Les outils mentionnés ci-dessus offrent diverses options qui vous aideront à rationaliser la collecte et le chargement des données dans vos systèmes cibles de manière efficace.
Si vous débutez dans le domaine de l'ingénierie des données et souhaitez approfondir vos connaissances sur la manière dont les données circulent dans les pipelines modernes, nous vous invitons à consulter le cours Introduction à l'ingénierie des données. Pour ceux qui souhaitent en savoir plus sur les processus ETL et ELT en Python, ETL et ELT en Python constitue une excellente ressource pour acquérir une expérience pratique des techniques d'ingestion de données.
Veuillez approfondir vos connaissances en ingénierie des données grâce à ces cours.
Cours
Cours
Cours