
Curso
Conceitos de Streaming
2 h
6.8K
Ingestão de dados significa coletar dados de várias fontes e carregá-los no destino. Muitas ferramentas de ingestão de dados disponíveis no mercado podem automatizar e simplificar esse processo para você.
Depois de pesquisar e testar com cuidado, fiz uma lista das 20 melhores ferramentas de ingestão de dados. Cada uma dessas ferramentas tem recursos únicos, seja pra processamento em tempo real, ingestão em lote ou suporte pra várias fontes de dados.
Vamos mergulhar nas ferramentas e explorar suas capacidades e casos de uso ideais!
O Apache Kafka é um mecanismo distribuído de código aberto conhecido por sua alta taxa de transferência e baixa latência. Inclui o Kafka Connect, uma estrutura para integrar o Kafka com bancos de dados externos, sistemas de arquivos e armazenamentos de chave-valor.
O Apache Kafka segue uma arquitetura produtor-consumidor. Os produtores de dados mandam os dados para os tópicos do Kafka, que funcionam como um tipo de intermediário, organizando de forma lógica os dados recebidos dentro das suas partições. Por fim, os consumidores acessam os dados necessários desses tópicos do Kafka.
Por que usar o Apache Kafka para ingestão de dados?
Se você curte a ideia de pegar dados em tempo real, dá uma olhada na Introdução ao Apache Kafka pra aprender como processar dados de streaming de um jeito eficiente.
O Apache NiFi foi criado para automatizar o fluxo de dados entre sistemas. Diferente do Kafka, ele tem uma interface fácil de usar pra projetar, implementar e monitorar o fluxo de dados.
A ferramenta usa processadores para a ingestão de dados. Os processadores no NiFi cuidam de várias funções, como extrair, publicar, transformar ou encaminhar dados. Por exemplo, processadores pré-construídos como InvokeHTTP puxam dados da API REST, e GetKafka recupera mensagens dos tópicos do Kafka.
Assim que os processadores começam a receber dados, são criados FlowFiles para cada unidade de dados. Esses FlowFiles têm metadados junto com os dados reais e são encaminhados para os seus destinos com base em regras definidas.
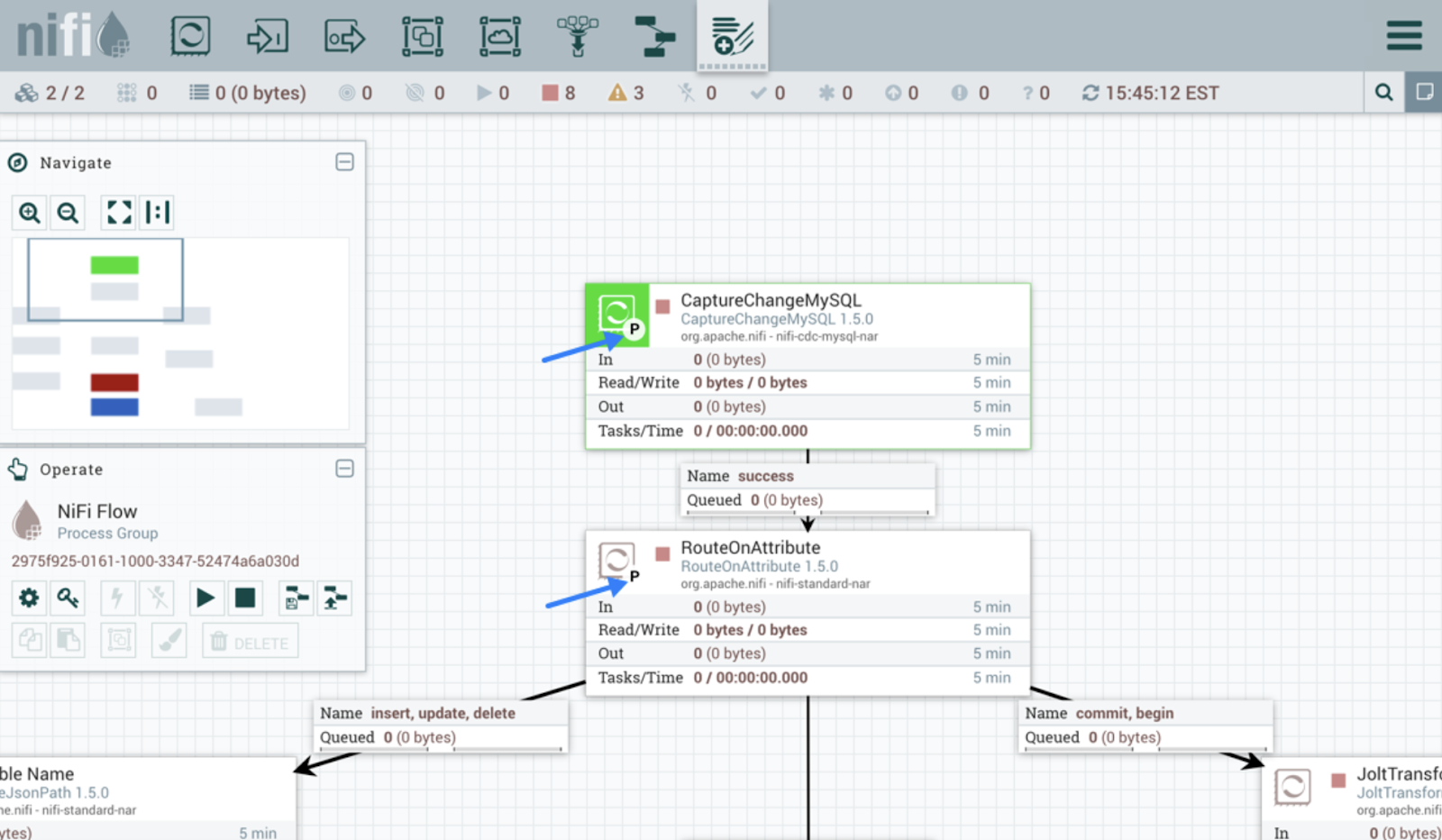
Interface do usuário do Apache NiFi. Fonte da imageme: Guia do usuário do Apache NiFi.
O AWS Glue é um serviço de integração de dados sem servidor da Amazon. Ele descobre, transforma e carrega dados para destinos para análise ou casos de uso de ML. A plataforma oferece uma interface gráfica fácil de usar e ambientes de desenvolvimento como os notebooks Jupyter.
Os rastreadores e as tarefas ETL são os dois principais componentes do AWS Glue. Os rastreadores examinam as fontes de dados para detectar esquemas e adicionar metadados aos catálogos. Os trabalhos ETL podem então descobrir facilmente a fonte de dados e sua estrutura usando as informações do catálogo.
O AWS Glue oferece várias maneiras de criar e executar pipelines. Por exemplo, tarefas ETL podem ser escritas em Python ou Scala para transformar e carregar os dados. Para quem não sabe programar, o Glue Studio oferece uma interface intuitiva para criar fluxos de trabalho sem precisar programar.
Se você está explorando soluções ETL sem servidor, dê uma olhada neste tutorial do AWS Glue para obter um guia prático sobre como criar pipelines de dados escaláveis.
O Dataflow é um serviço totalmente gerenciado da Google Nuvem para processamento em fluxo e em lote. Ele consegue lidar com pipelines de dados simples, como mover dados entre sistemas em intervalos programados, e também com pipelines avançados em tempo real.
Além disso, a ferramenta é super escalável e dá suporte a uma transição tranquila do processamento em lote para o processamento em fluxo, quando necessário.
O Google Dataflow é construído com base no Apache Beam. Então, você pode codificar pipelines de ingestão usando os SDKs do Beam. Além disso, a ferramenta oferece modelos de fluxo de trabalho pré-definidos para criar pipelines na hora. Os desenvolvedores também podem criar modelos personalizados e disponibilizá-los para usuários sem conhecimentos técnicos implementarem quando precisarem.
O Azure Data Factory (ADF) é o serviço em nuvem da Microsoft para coletar dados de várias fontes. Ele foi feito pra criar, programar e organizar fluxos de trabalho pra automatizar o processo.
O ADF não guarda nenhum dado. Ele ajuda a mover dados entre sistemas e processa tudo isso usando recursos de computação em servidores remotos.
A plataforma tem mais de 90 conectores integrados para conectar várias fontes de dados, incluindo armazenamentos de dados locais, APIs REST e servidores em nuvem. Então, o componente “copiar atividade” copia os dados da fonte para o destino.
Se você já usa os serviços da Microsoft para outras operações de dados, o Azure Data Factory é uma solução completa para suas necessidades de ingestão de dados. Nosso tutorial do Azure Data Factory mostra como configurar fluxos de trabalho de ingestão de dados no Azure.
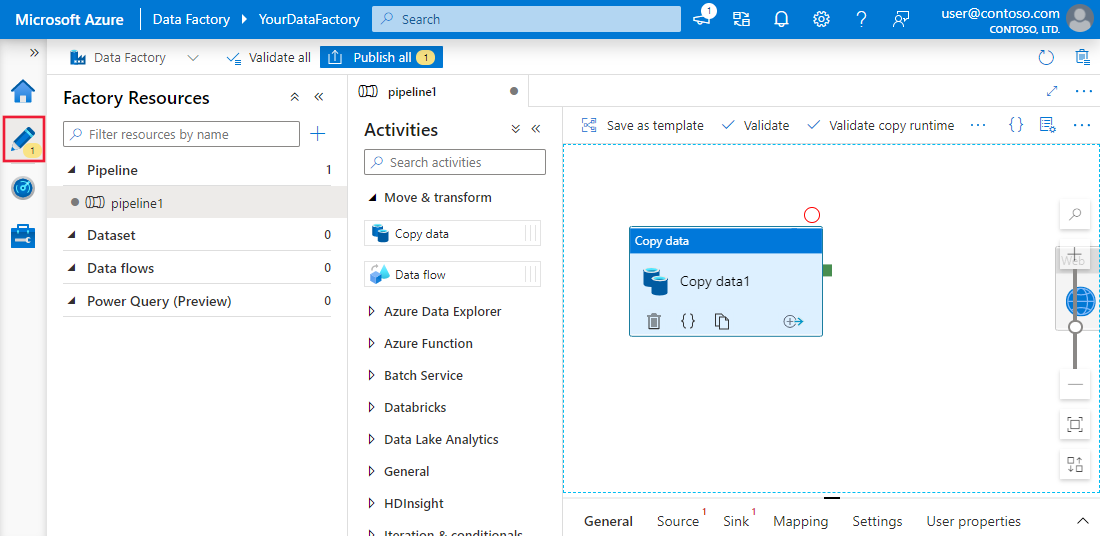
Experiência da interface do usuário do Azure Data Factory e do Synapse Analytics. Imageme fonte: Microsoft Aprender
A Talend é uma plataforma de integração de dados de código aberto e completa. Isso facilita a criação de fluxos de trabalho de ingestão de dados, oferecendo componentes de arrastar e soltar para conectar diferentes fontes e destinos.
A Talend é conhecida por transferir dados entre sistemas sem perder a qualidade. Seu conjunto robusto de ferramentas de qualidade de dados garante a precisão dos dados durante a ingestão. Além disso, os recursos de monitoramento integrados permitem a conformidade com as regras de segurança e governança de dados.
O Fivetran é uma plataforma de integração de dados bem conhecida que automatiza tarefas de ELT. Ele fornece dados sem interrupções, adaptando automaticamente as mudanças no formato dos dados. Esse recurso também ajuda a manter a precisão dos dados por meio do mapeamento de esquema durante a ingestão.
A principal vantagem de ferramentas como o Fivetran é que elas não precisam de manutenção. O gerenciamento e monitoramento automático de esquemas permite pipelines com manutenção automática.
Além disso, a ferramenta inclui recursos de CDC (captura de dados alterados), garantindo que o destino fique atualizado em tempo real.
Pra quem não sabe, CDC é o processo de identificar as atualizações recentes feitas em um banco de dados e refleti-las no destino em tempo real.
O Airbyte é outra ferramenta de ingestão de dados de código aberto da lista. É a plataforma de integração de dados mais popular, e mais de 3000 empresas a utilizam.
Com mais de 300 conectores pré-fabricados, o Airbyte oferece o suporte mais abrangente para várias conexões de origem e destino. Além disso, como é código aberto, você pode dar uma olhada no código desses conectores e personalizá-los. Se o seu caso de uso não estiver coberto, você pode criar seu próprio conector de origem.
O Airbyte precisa de conhecimento técnico pra configurar e manter pipelines, principalmente conectores personalizados. Mas tem planos pagos com serviços totalmente gerenciados e suporte dedicado.
A interface do usuário do Airbyte. Fonte da imagem: Airbyte GitHub
A nuvem de gerenciamento inteligente de dados da Informatica tem um conjunto de ferramentas pra facilitar a ingestão de dados. A ferramenta “Data Loader” leva só alguns minutos pra carregar dados de mais de 30 serviços na nuvem.
A Informatica também tem uma ferramenta de integração de aplicativos que conecta sistemas de software diferentes, tanto no local quanto na nuvem. A plataforma de integração de dados em nuvem deles é bem projetada para uma ingestão de dados de alto desempenho com ETL/ELT.
Feito pra lidar com dados em lote e em tempo real, o Informatica permite pegar qualquer tipo de dado de bancos de dados relacionais, aplicativos e sistemas de arquivos. Além disso, a plataforma oferece recursos de IA, como o CLAIRE Engine, que analisa informações de metadados e sugere conjuntos de dados relevantes para suas necessidades de ingestão de dados.
O Apache Flume é um serviço distribuído e confiável para carregar dados de log para destinos. Sua arquitetura flexível foi especialmente projetada para fluxos de dados em tempo quase real, como de vários servidores web para HDFS ou ElasticSearch.
O agente Flume é o principal responsável por mover os dados. É composto por um canal, um sumidouro e uma fonte. O componente de origem pega os arquivos de dados dos dados de origem, e o coletor garante a sincronização entre o destino e a origem. Vários agentes Flume podem ser configurados para ingestão paralela de dados ao transmitir grandes volumes de dados.
O Apache Flume é conhecido pela sua tolerância a falhas. Com vários mecanismos de failover e recuperação, o Flume garante uma ingestão de dados consistente e confiável, mesmo em caso de falhas.
O Stitch é uma ferramenta ETL na nuvem simples e que dá pra expandir. Embora não tenha recursos complexos de transformação personalizada, é perfeito para tarefas de ingestão de dados.
Assim como outras ferramentas ETL empresariais, o Stitch oferece vários conectores para mais de 140 fontes de dados, geralmente de aplicativos SaaS e bancos de dados para data warehouses e data lakes. Para fluxos de trabalho personalizados de ingestão de dados, o Stitch se integra ao Singer, permitindo que você crie conectores personalizados.
Interface do usuário para extração de dados de pontos. Eumage source: Documentação do Stitch
A StreamSets, comprada pela IBM, é um mecanismo de integração de dados de código aberto para dados de fluxo, em lote e CDC. O recurso “Data Collector” oferece conectores de origem do tipo arrastar e soltar para plataformas em nuvem, como AWS, Microsoft Azure e Google Cloud, além de sistemas locais.
Você não precisa ser especialista em TI pra criar ou editar pipelines de ingestão de dados — a interface do coletor de dados é super intuitiva, tipo arrastar e soltar.
O StreamSets é uma ferramenta independente de plataforma que permite aos usuários criar pipelines coletores de dados adequados a vários ambientes com o mínimo de reconfigurações. Além dos coletores de dados, a plataforma conta com transformadores de dados operando no Apache Spark para transformações complexas de dados.
O Apache Beam é uma solução unificada que oferece um modelo de programação único para casos de uso em lote e streaming. Funciona perfeitamente com plataformas em nuvem, como Google Cloud Dataflow, Apache Flink e Apache Spark.
Para a ingestão de dados em tempo real, você pode definir janelas fixas, deslizantes e de sessão para agrupar e processar dados rapidamente.
O Apache Beam é super flexível. Permite que os pipelines sejam definidos em qualquer linguagem de programação e executados em vários mecanismos de execução.
A Hevo Data é uma plataforma totalmente gerenciada e sem código para mover dados de mais de 150 fontes para o destino que você escolher. A ferramenta não só lida com a ingestão de dados, mas também transforma os dados para torná-los prontos para análise.
A plataforma detecta automaticamente o esquema dos dados recebidos e os combina com o esquema de destino, oferecendo flexibilidade.
Os dados Hevo também oferecem uma arquitetura robusta e tolerante a falhas, garantindo que não haja perda de dados durante a ingestão de dados. No geral, o Hevo Data é a escolha certa para streaming e análises em tempo real.
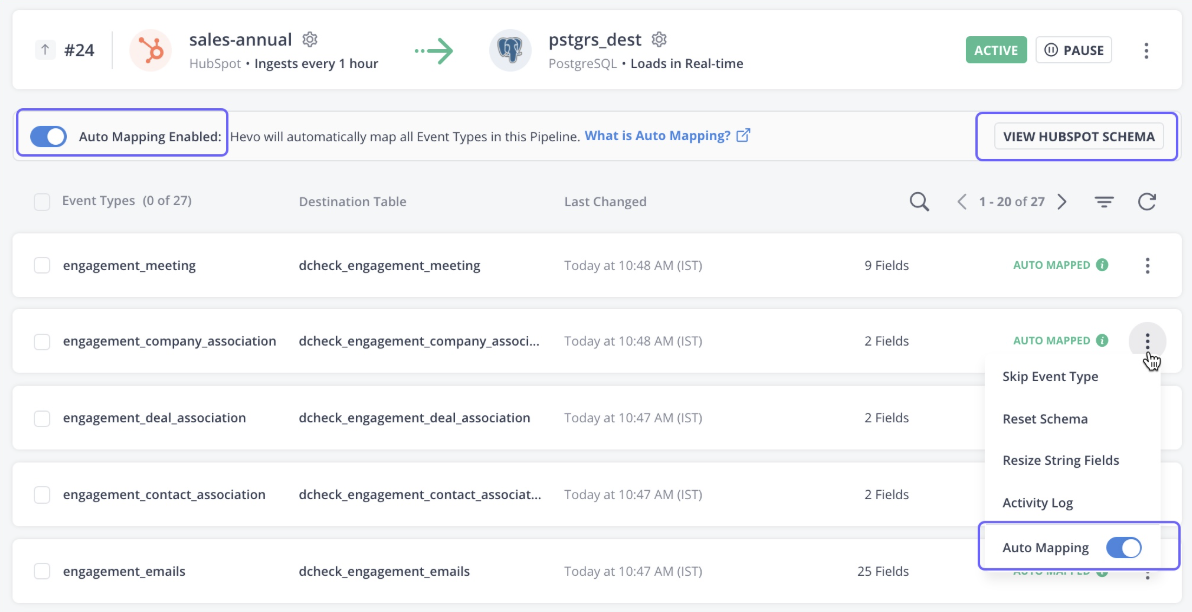
Interface de usuário de dados Hevo. Fonte da imagem: Documentação do Hevo
O Segment é uma plataforma de dados de clientes que fornece dados limpos e transformados para análise. A plataforma é especializada na coleta de vários tipos de dados de clientes, como interações, impressões, cliques e outros dados comportamentais.
A API de programa da ferramenta coleta dados de eventos de várias fontes, incluindo dispositivos móveis, web e servidores. Com só alguns cliques, os dados podem ser integrados com mais de 450 aplicativos.
Os dados coletados pelo Segment estão disponíveis para os usuários por meio de consultas SQL, enquanto os programadores podem acessar dados em tempo real usando comandos curl.
O Matillion é uma plataforma de integração de dados nativa da nuvem, feita pra mover e transformar dados dentro da nuvem. Ele foi feito especialmente para warehouse de dados em nuvem poderosos, como Snowflake, Amazon Redshift e Google BigQuery.
A plataforma oferece vários conectores prontos para fontes de dados na nuvem e locais, como bancos de dados, aplicativos SaaS, plataformas de mídia social e muito mais.
Com foco no desempenho, o Matilion também oferece recursos poderosos de transformação para limpar e preparar os dados para análises mais aprofundadas.
O Keboola, um software de especificação projetado especialmente para fazer transformações complexas, oferece recursos personalizados de ingestão de dados. Com mais de 250 integrações internas entre fontes e destinos, ele automatiza a ingestão de dados com apenas alguns cliques.
O Keboola suporta tanto o streaming de dados em lote quanto em tempo real para importar dados empresariais. Mas, se for pegar dados em tempo real, você vai precisar saber programar pra configurar os webhooks.
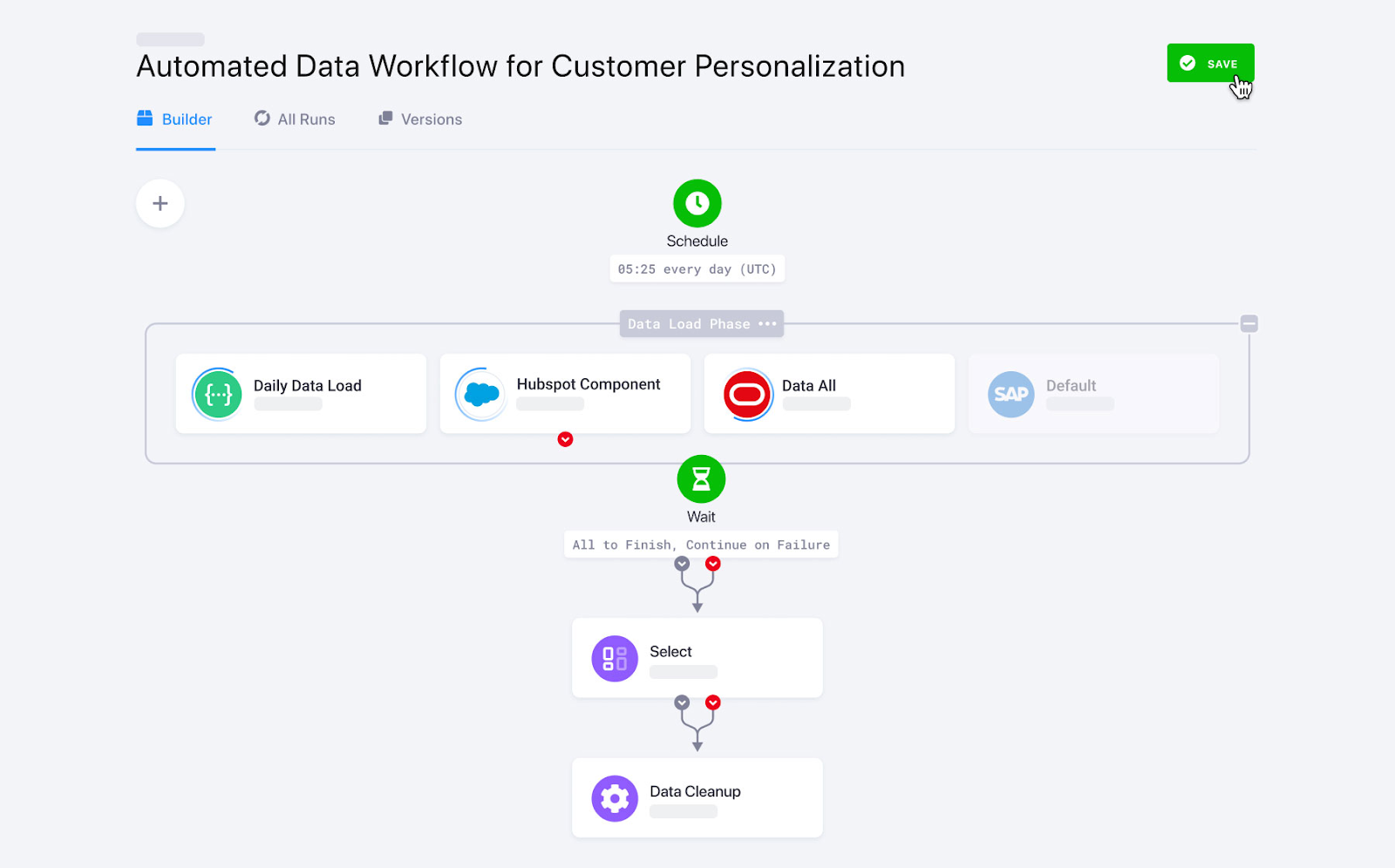
Fluxos de trabalho de dados Keboola. Fonte da imagem: Keboola
O Snowplow é uma plataforma de coleta de dados de última geração que captura e processa dados de eventos de várias fontes. É especialista em coletar dados sobre o comportamento dos clientes e prepará-los para análises avançadas de IA e machine learning.
O Snowplow usa rastreadores e webhooks pra coletar dados de eventos em tempo real.
Os rastreadores são bibliotecas ou SDKs que podem ser integrados em aplicativos móveis, sites e aplicativos do lado do servidor. Eles juntam informações de eventos, tipo interações dos usuários, cliques e curtidas, e mandam isso pros coletores. Os coletores então passam os dados pelo processo de enriquecimento antes de enviá-los para o warehouse de destino.
O IBM DataStage é uma plataforma de integração de dados líder do setor, criada para operações ETL e ELT. A versão básica tá disponível no local, mas pra aproveitar a escalabilidade e a automação da nuvem, atualize pro DataStage para IBM Cloud Pak®.
Seu amplo conjunto de conectores e estágios pré-construídos automatiza a movimentação de dados entre várias fontes na nuvem e warehouse.
Pra quem montou a arquitetura de dados no ecossistema IBM, o DataStage é a ferramenta ideal pra ingestão de dados. Ele se integra com outras plataformas de dados da IBM, como Cloud Object Storage e Db2, para ingestão e transformação.
A Alteryx é conhecn por suas ferramentas de análise e visualização de dados. Com mais de 8.000 clientes, é uma plataforma de análise popular que automatiza tarefas de dados e análise.
A Alteryx tem uma ferramenta chamada Designer Nuvem que oferece uma interface fácil de usar para criar pipelines de ingestão de dados para análise e casos de uso de IA. Ele oferece conectividade com várias fontes de dados, incluindo warehouse, armazenamento em nuvem e sistemas de arquivos.
Quer simplificar a preparação e análise de dados sem precisar programar? Aprenda a automatizar fluxos de trabalho de ETL (Extração, Transformação e Transferência) com a Introdução ao Alteryx edescubra os recursos de ETL do tipo arrastar e soltar.
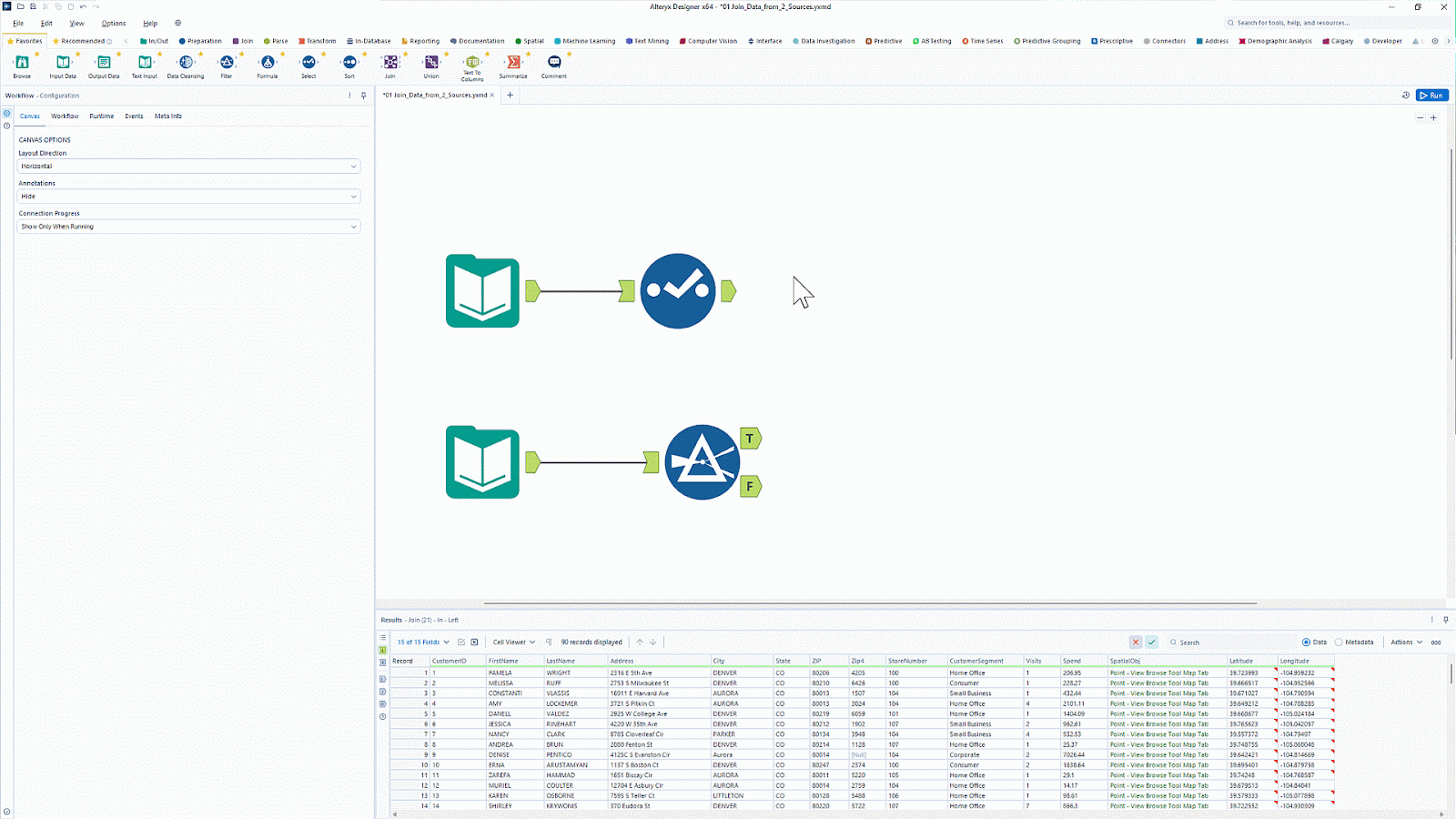
Interface de usuário do Alteryx com recurso de arrastar e soltar. Fonte da imagem: Alteryx
|
Ferramenta |
Ideal para |
Características |
Preços |
|
Apache Kafka |
Transmissão de dados em tempo real |
|
Código aberto |
|
Apache Nifi |
Ingestão segura de dados em tempo real |
|
Código aberto |
|
AWS Glue |
Ecossistema AWS |
|
Modelo de preços pré-pagos. As taxas são baseadas na quantidade de processamento de dados por hora. |
|
Fluxo de dados na nuvem do Google |
Ecossistema do Google Nuvem |
|
Modelo de preços pré-pagos. As cobranças são baseadas nos recursos de computação e na memória que você usa. |
|
Fábrica de dados do Azure |
Empresas que usam outros serviços do Microsoft Azure |
|
Modelo de preços pré-pagos |
|
Talend |
Empresas com orçamento apertado que querem uma solução ETL fácil de usar |
|
Código aberto |
|
Fivetran |
Necessidades de ELT totalmente gerenciadas |
|
Preços baseados em assinatura |
|
Airbyte |
Organizações que estão procurando uma solução de personalização de código aberto |
|
Tanto serviços de código aberto quanto serviços pagos estão disponíveis. |
|
Informática |
Empresas que procuram ferramentas low-code com conectores de origem abrangentes |
|
Teste grátis por 30 dias, modelo de preço conforme o uso |
|
Apache Flume |
Fluxos de dados em streaming |
|
Código aberto |
|
Ponto |
Organizações que querem uma ferramenta simples para tarefas de ingestão de dados |
|
Você pode escolher entre modelos de preços baseados em níveis ou modelos de preços conforme o uso. |
|
StreamSets |
Transformações complexas de dados |
|
Tanto opções de código aberto quanto comerciais estão disponíveis. |
|
Apache Beam |
Estrutura personalizável e centrada em código para criar pipelines de ingestão de dados |
|
A estrutura Apache Beam é de código aberto, mas tem um custo quando usada com serviços em nuvem. |
|
Hevo Data |
Empresas de médio porte que precisam de análises em tempo real |
|
Preços baseados em assinatura |
|
Segmento |
Dados de eventos do cliente |
|
Modelo de preços de assinatura |
|
Matillion |
Ferramenta ETL/ELT nativa da nuvem |
|
Modelo de preços baseado em assinatura |
|
Keboola |
Pipelines complexos de transformação de dados |
|
Modelo de preços baseado em assinatura |
|
Limpa-neve |
Coleta de dados do evento |
|
Tanto opções de código aberto quanto comerciais estão disponíveis. |
|
IBM DataStage |
Ecossistema de nuvem da IBM |
|
Modelo de preços baseado em assinatura |
|
Alteryx |
Análise e visualização de dados |
|
Modelo de preços baseado em assinatura |
Com tantas ferramentas disponíveis no mercado, pode ser difícil escolher a plataforma de integração de dados certa para suas necessidades. Aqui está uma lista de alguns dos fatores que você deve considerar antes de escolher uma ferramenta específica de integração de dados.
Você pode facilmente importar uma planilha do Excel ou um arquivo CSV para os destinos desejados. Mas, pegar manualmente dados de streaming em tempo real de várias fontes e mandar pra vários lugares pode ser complicado. Por exemplo, aplicativos modernos, como as redes sociais, costumam ter picos de demanda em alguns momentos e outros com demanda baixa. É aqui que a funcionalidade de escalabilidade das ferramentas de ingestão de dados se destaca.
Escalabilidade é a capacidade de crescer ou encolher de acordo com a demanda. Isso permite que a ferramenta se adapte rapidamente às crescentes demandas de volumes de dados sem comprometer o desempenho.
Flexibilidade é a capacidade de lidar com dados de várias fontes e formatos. Ferramentas de ingestão de dados que suportam várias fontes de dados e oferecem conectores personalizados garantem flexibilidade nos sistemas de ingestão de dados.
Por exemplo, o recurso de mapeamento automático de esquema detecta o esquema dos dados recebidos e os mapeia para o destino sem restringi-los a uma estrutura de esquema pré-definida. Isso permite que a ferramenta receba dados de qualquer esquema.
A ingestão de dados em lote coleta dados de acordo com uma programação e os atualiza no destino. Por outro lado, a ingestão de dados em tempo real significa transferir dados contínuos sem nenhum atraso.
Hoje em dia, muitas ferramentas de ingestão de dados suportam tanto a ingestão em lote quanto em tempo real. Mas, se você costuma lidar com dados em tempo real, tipo eventos de clientes ou streaming de vídeo, escolha uma ferramenta com alta taxa de transferência e baixa latência.
Diferentes ferramentas de ingestão de dados têm estruturas de preços diferentes. Alguns oferecem preços baseados em níveis, enquanto outros seguem um modelo de pagamento conforme o uso. Essas soluções costumam ser mais econômicas do que as ferramentas de código aberto, porque as ferramentas gratuitas exigem que você contrate especialistas para permitir a ingestão de dados. Mas, as ferramentas de código aberto oferecem muita flexibilidade e personalização para o seu caso de uso.
Algumas ferramentas pagas de ingestão de dados também oferecem recursos de nível empresarial com amplas capacidades de personalização, embora tenham um custo. Então, dependendo do seu orçamento e do que você precisa personalizar, é melhor escolher entre plataformas pagas e de código aberto.
Escolher a ferramenta certa para ingestão de dados depende das suas necessidades específicas — se você prioriza streaming em tempo real, processamento em lote, compatibilidade com a nuvem ou facilidade de integração. As ferramentas listadas acima oferecem várias opções, ajudando você a simplificar a coleta e o carregamento de dados nos seus sistemas de destino de forma eficiente.
Se você é novo na área de engenharia de dados e quer entender melhor como os dados fluem pelos pipelines modernos, dá uma olhada no curso Introdução à Engenharia de Dados. Pra quem quer saber mais sobre os processos ETL e ELT em Python, o ETL e ELT em Python é um ótimo recurso pra ganhar experiência prática com técnicas de ingestão de dados.
Aprenda mais sobre engenharia de dados com esses cursos!
Curso
Curso
Curso
blog
Javier Canales Luna
13 min
blog
DataCamp Team
12 min
blog
Javier Canales Luna
13 min
blog
Javier Canales Luna
9 min
blog
Joleen Bothma
12 min
