
Kurs
Streaming-Konzepte
2 Std.
6.8K
Datenaufnahme heißt, Daten aus verschiedenen Quellen zu sammeln und sie an den Zielort zu laden. Viele Tools zur Datenerfassung auf dem Markt können diesen Prozess für dich automatisieren und vereinfachen.
Nach gründlicher Recherche und Tests habe ich eine Liste der 20 besten Tools für die Datenerfassung zusammengestellt. Jedes dieser Tools hat einzigartige Funktionen, egal ob du Echtzeitverarbeitung, Batch-Erfassung oder Unterstützung für verschiedene Datenquellen brauchst.
Schauen wir uns die Tools genauer an und entdecken wir ihre Funktionen und die besten Einsatzmöglichkeiten!
Apache Kafka ist eine Open-Source-Engine, die für ihren hohen Durchsatz und ihre geringe Latenz bekannt ist. Es enthält Kafka Connect, ein Framework zur Integration von Kafka mit externen Datenbanken, Dateisystemen und Schlüsselwertspeichern.
Apache Kafka hat eine Produzent-Konsument-Architektur. Datenproduzenten schicken Daten an Kafka-Themen, die wie ein Mittelsmann funktionieren und die empfangenen Daten logisch in ihren Partitionen organisieren. Schließlich holen sich die Leute die benötigten Daten aus diesen Kafka-Themen raus.
Warum Apache Kafka für die Datenerfassung?
Wenn du dich für Echtzeit-Datenerfassung interessierst, schau dir die Einführung in Apache Kafka an, um zu erfahren, wie du Streaming-Daten effizient verarbeiten kannst.
Apache NiFi ist dafür gemacht, den Datenfluss zwischen Systemen zu automatisieren. Anders als Kafka hat es eine einfache Benutzeroberfläche zum Entwerfen, Bereitstellen und Überwachen des Datenflusses.
Das Tool nutzt Prozessoren, um Daten zu erfassen. Prozessoren in NiFi kümmern sich um verschiedene Aufgaben wie das Extrahieren, Veröffentlichen, Umwandeln oder Weiterleiten von Daten. Zum Beispiel holen vorgefertigte Prozessoren wie InvokeHTTP Daten von der REST-API ab, und GetKafka ruft Nachrichten aus Kafka-Themen ab.
Sobald die Prozessoren anfangen, Daten zu verarbeiten, werden für jede Dateneinheit FlowFiles erstellt. Diese FlowFiles haben Metadaten und die eigentlichen Daten und werden nach festgelegten Regeln an die richtigen Ziele geschickt.
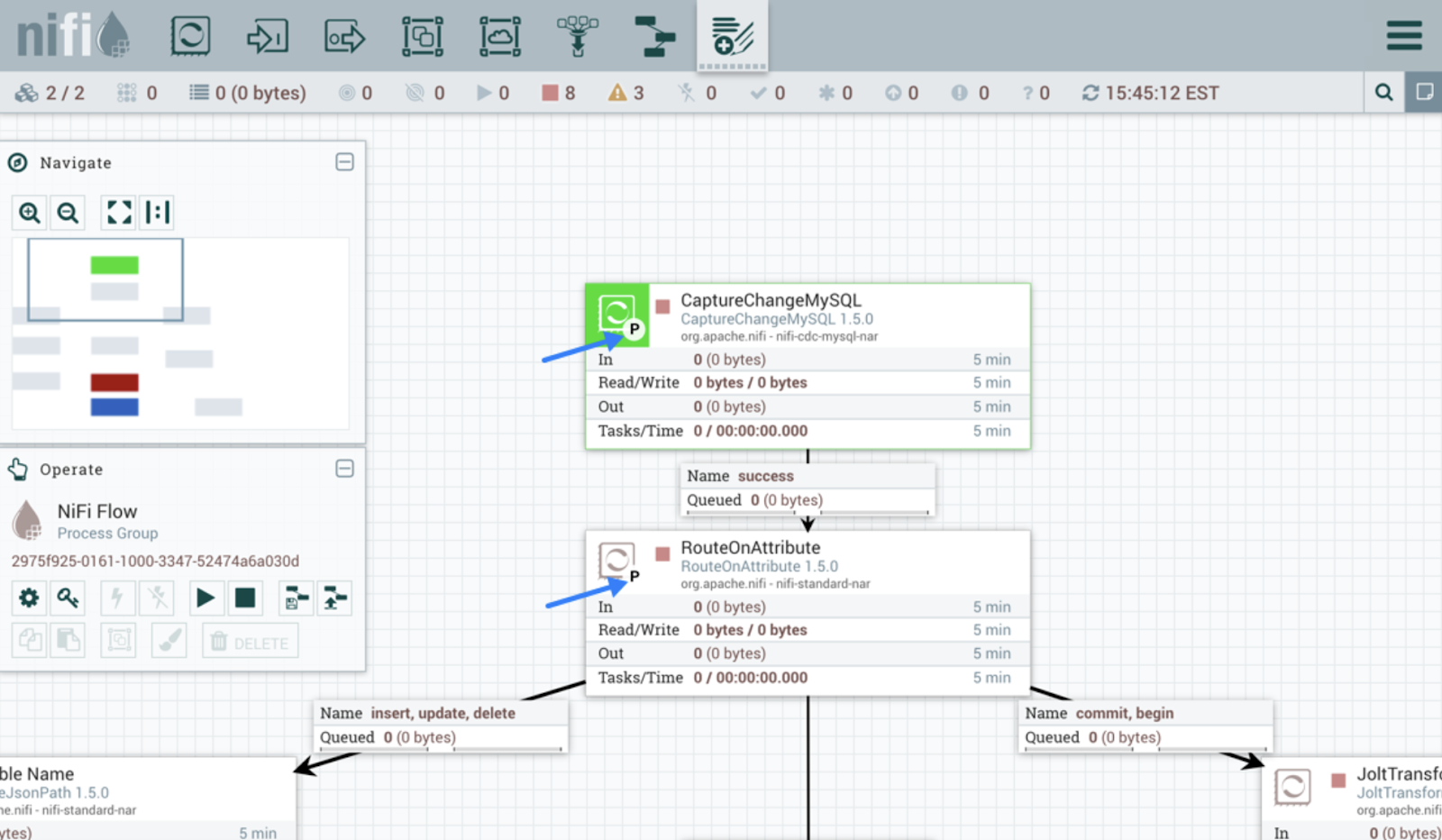
Benutzeroberfläche von Apache NiFi. Bildquelle: Apache NiFi Benutzerhandbuch.
AWS Glue ist ein serverloser Datenintegrationsdienst von Amazon. Es findet, wandelt und lädt Daten für Analysen oder ML-Anwendungen an die richtigen Orte. Die Plattform hat eine benutzerfreundliche GUI und Entwicklungsumgebungen wie Jupyter-Notebooks.
Crawler und ETL-Jobs sind die beiden Hauptkomponenten von AWS Glue. Crawler checken die Datenquellen, um Schemata zu erkennen und Metadaten zu Katalogen hinzuzufügen. ETL-Jobs können dann die Datenquelle und ihre Struktur ganz einfach anhand der Kataloginfos finden.
AWS Glue bietet mehrere Möglichkeiten, Pipelines zu erstellen und auszuführen. Zum Beispiel kann man ETL-Jobs in Python oder Scala schreiben, um die Daten zu transformieren und zu laden. Für Leute, die nicht programmieren können, hat Glue Studio eine einfache Oberfläche, mit der man Arbeitsabläufe erstellen kann, ohne programmieren zu müssen.
Wenn du dich für serverlose ETL-Lösungen interessierst, schau dir dieses AWS Glue-Tutorial an, um eine praktische Anleitung zum Aufbau skalierbarer Datenpipelines zu bekommen.
Dataflow ist ein komplett verwalteter Google Cloud-Dienst für die Stream- und Batch-Verarbeitung. Es kann einfache Datenpipelines verarbeiten, wie zum Beispiel das Verschieben von Daten zwischen Systemen zu festgelegten Zeitpunkten, aber auch komplexe Echtzeit-Pipelines.
Außerdem ist das Tool super skalierbar und macht einen nahtlosen Übergang von der Stapelverarbeitung zur Stream-Verarbeitung möglich, wenn das nötig ist.
Google Dataflow basiert auf Apache Beam. Du kannst also mit den Beam SDKs Pipelines für die Datenerfassung programmieren. Außerdem hat das Tool vorgefertigte Workflow-Vorlagen, mit denen man Pipelines im Handumdrehen erstellen kann. Entwickler können auch eigene Vorlagen erstellen und sie für Leute ohne technische Kenntnisse bereitstellen, damit diese sie bei Bedarf nutzen können.
Azure Data Factory (ADF) ist der Cloud-Dienst von Microsoft, mit dem man Daten aus verschiedenen Quellen zusammenführen kann. Es ist dafür gemacht, Workflows zu erstellen, zu planen und zu organisieren, um den Prozess zu automatisieren.
ADF selbst speichert keine Daten. Es hilft beim Datenaustausch zwischen Systemen und verarbeitet die Daten über Computerressourcen auf Remote-Servern.
Die Plattform hat über 90 eingebaute Konnektoren, um verschiedene Datenquellen zu verbinden, wie lokale Datenspeicher, REST-APIs und Cloud-Server. Dann kopiert die Komponente „Kopieraktivität” die Daten von der Quelle zum Ziel.
Wenn du schon Microsoft-Dienste für andere Datenoperationen nutzt, ist Azure Data Factory eine Komplettlösung für deine Datenerfassungsanforderungen. Unser Azure Data Factory-Tutorial zeigt dir, wie du Workflows für die Datenerfassung in Azure einrichtest.
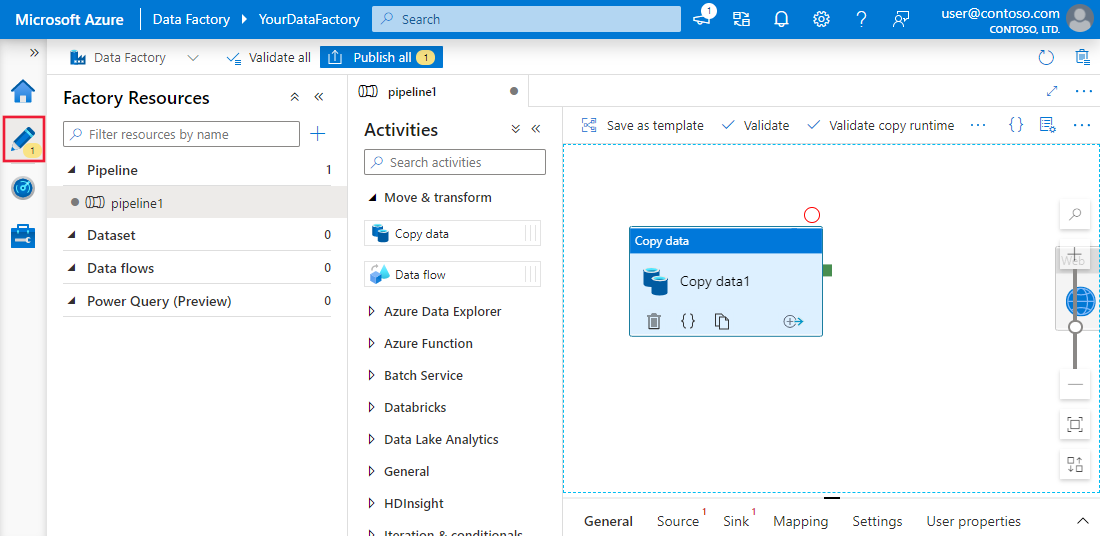
Benutzeroberfläche von Azure Data Factory und Synapse Analytics. BildQuelle: Microsoft Lernen
Talend ist eine Open-Source-Plattform für die Datenintegration von Anfang bis Ende. Es macht das Erstellen von Datenaufnahme-Workflows einfach und hat Drag-and-Drop-Komponenten, um verschiedene Quellen und Ziele zu verbinden.
Talend ist dafür bekannt, Daten zwischen Systemen zu verschieben und dabei die Qualität zu sichern. Die coolen Tools für die Datenqualität sorgen dafür, dass die Daten beim Einlesen richtig sind. Außerdem helfen die eingebauten Überwachungsfunktionen dabei, die Regeln für Datensicherheit und -verwaltung einzuhalten.
Fivetran ist eine beliebte Plattform für Datenintegration, die ELT-Aufgaben automatisch erledigt. Es sorgt für unterbrechungsfreie Daten, indem es sich automatisch an Änderungen im Datenformat anpasst. Diese Funktion hilft auch dabei, die Datengenauigkeit durch Schema-Mapping während der Erfassung zu halten.
Der größte Vorteil von Tools wie Fivetran ist, dass sie null Wartungsaufwand haben. Die automatische Schemaverwaltung und -überwachung macht selbstwartende Pipelines möglich.
Außerdem hat das Tool CDC-Funktionen (Change Data Capture), die dafür sorgen, dass das Ziel in Echtzeit immer auf dem neuesten Stand bleibt.
Für alle, die sich damit nicht auskennen: CDC ist der Prozess, bei dem man die neuesten Änderungen an einer Datenbank findet und sie in Echtzeit auf das Ziel übertragen kann.
Airbyte ist ein weiteres Open-Source-Tool zum Einlesen von Daten auf der Liste. Es ist die beliebteste Plattform für Datenintegration und wird von über 3000 Unternehmen genutzt.
Mit über 300 vorgefertigten Konnektoren bietet Airbyte die umfangreichste Unterstützung für verschiedene Quell- und Zielverbindungen. Da es sich um Open Source handelt, kannst du außerdem den Code dieser Konnektoren anschauen und sie anpassen. Wenn dein Anwendungsfall nicht abgedeckt ist, kannst du deinen eigenen Quellkonnektor schreiben.
Für die Einrichtung und Wartung von Pipelines, vor allem von benutzerdefinierten Konnektoren, braucht man bei Airbyte echt technisches Know-how. Allerdings gibt's auch kostenpflichtige Angebote mit komplett verwalteten Diensten und eigenem Support.
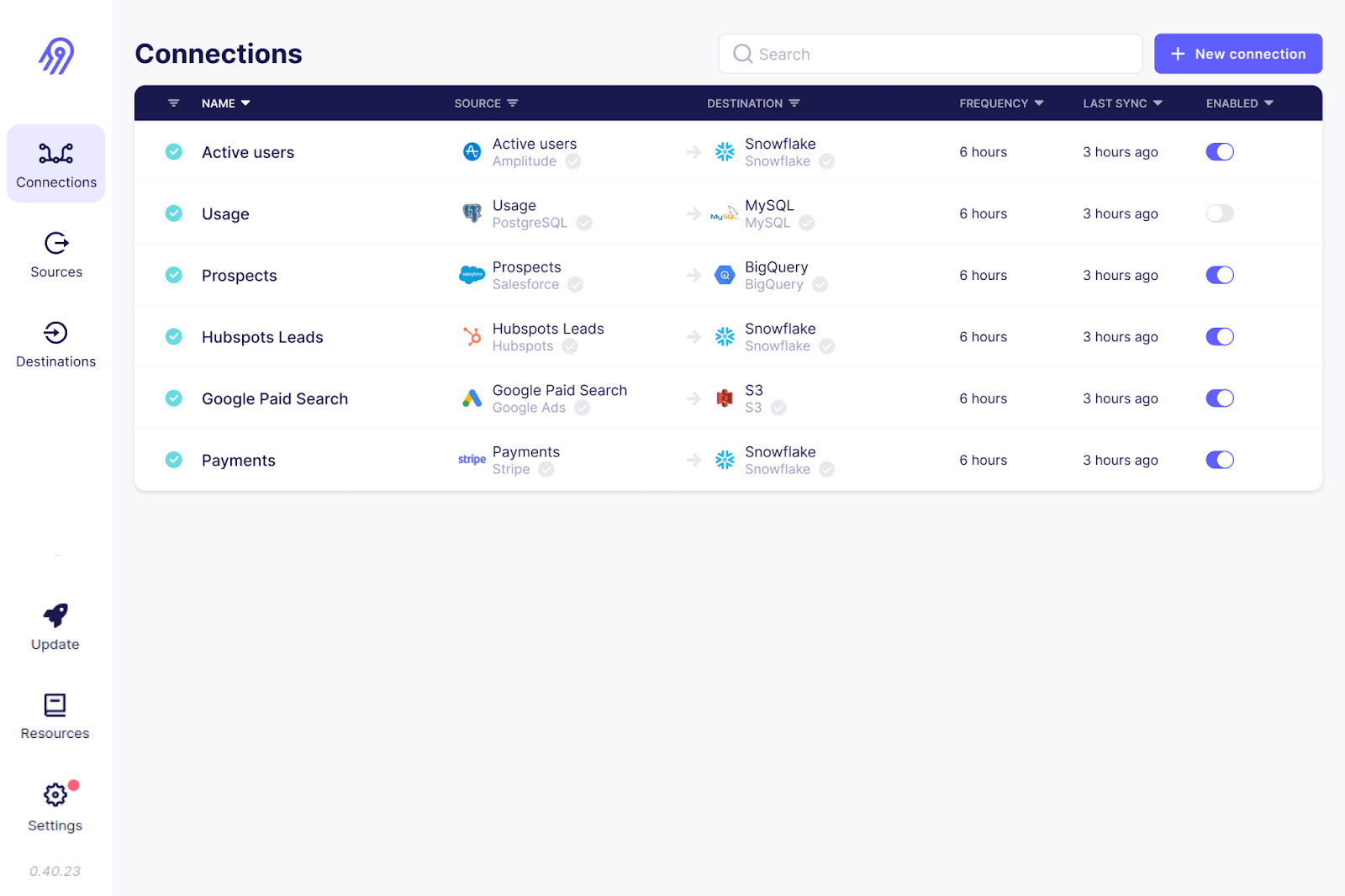
Die Benutzeroberfläche von Airbyte. Bild quelle: Airbyte GitHub
Die intelligente Datenmanagement-Cloud von Informatica hat eine Reihe von Tools, die das Einlesen von Daten einfacher machen. Mit dem Tool „Data Loader” kannst du in nur ein paar Minuten Daten aus über 30 Cloud-Diensten laden.
Informatica hat auch ein Tool zur Anwendungsintegration, das verschiedene Softwaresysteme verbindet, egal ob vor Ort oder in der Cloud. Die Cloud-Datenintegrationsplattform ist super für die schnelle Datenverarbeitung mit ETL/ELT gemacht.
Informatica ist für die Verarbeitung von Batch- und Echtzeitdaten ausgelegt und ermöglicht die Erfassung aller Arten von Daten aus relationalen Datenbanken, Anwendungen und Dateisystemen. Außerdem hat die Plattform KI-Funktionen wie die CLAIRE Engine, die Metadaten analysiert und passende Datensätze für deine Datenerfassungsanforderungen vorschlägt.
Apache Flume ist ein verteilter und zuverlässiger Dienst zum Laden von Protokolldaten an Ziele. Die flexible Architektur ist extra für Streaming-Datenströme gemacht, zum Beispiel von mehreren Webservern zu HDFS oder ElasticSearch, und das fast in Echtzeit.
Der Flume-Agent ist die Hauptkomponente, die für die Datenbewegungen zuständig ist. Es besteht aus einem Kanal, einer Senke und einer Quelle. Die Quellkomponente holt die Dateien aus den Quelldaten, und die Senke sorgt dafür, dass alles zwischen Ziel und Quelle synchron läuft. Bei der Übertragung großer Datenmengen können mehrere Flume-Agenten für die parallele Datenerfassung eingerichtet werden.
Apache Flume ist bekannt für seine Ausfallsicherheit. Mit mehreren Failover- und Wiederherstellungsmechanismen sorgt Flume auch bei Ausfällen für eine konsistente und zuverlässige Datenerfassung.
Stitch ist ein einfaches und erweiterbares Cloud-ETL-Tool. Auch wenn es keine komplexen Funktionen für benutzerdefinierte Transformationen hat, ist es super für Datenaufnahmeaufgaben.
Genau wie andere ETL-Tools für Unternehmen hat Stitch eine Reihe von Konnektoren für über 140 Datenquellen, meistens von SaaS-Anwendungen und Datenbanken zu Data Warehouses und Data Lakes. Für benutzerdefinierte Datenerfassungs-Workflows lässt sich Stitch mit Singer verbinden, sodass du eigene Konnektoren erstellen kannst.
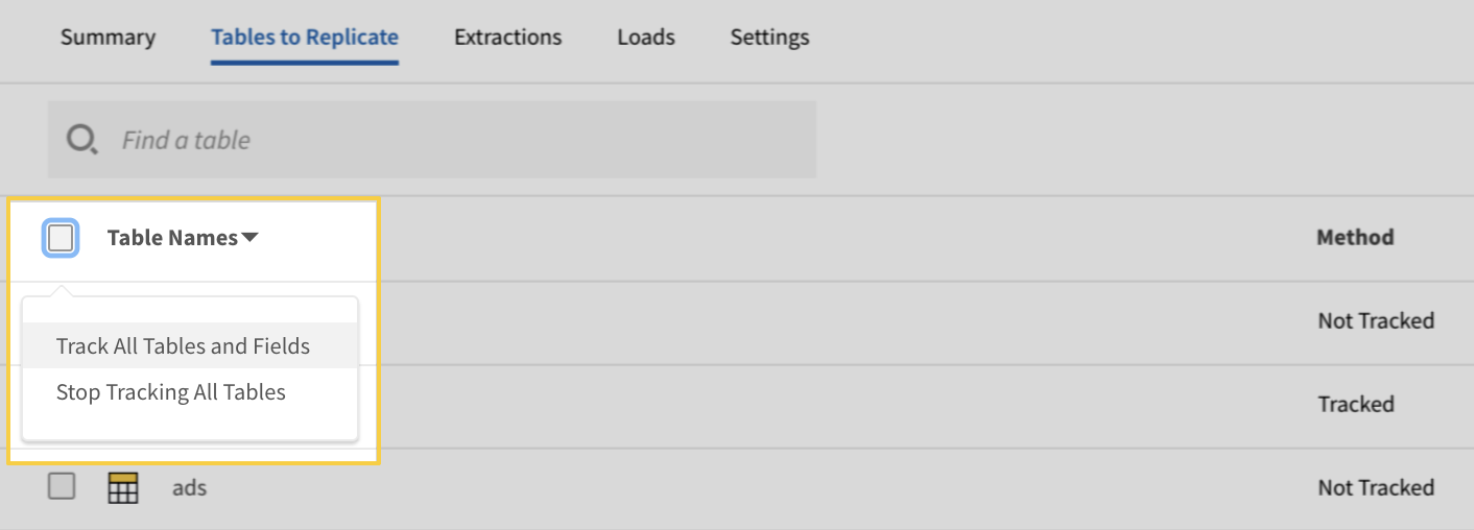
Benutzeroberfläche zur Extraktion von Stichdaten. Ich bin ein Magier der Quelle „“: Stich-Dokumentation
StreamSets, das von IBM übernommen wurde, ist eine Open-Source-Datenintegrations-Engine für Stream-, Batch- und CDC-Daten. Die „Data Collector”-Funktion bietet Drag-and-Drop-Quellkonnektoren für Cloud-Plattformen wie AWS, Microsoft Azure und Google Cloud sowie für lokale Systeme.
Du brauchst keine IT-Kenntnisse, um Pipelines für die Datenerfassung zu erstellen oder zu bearbeiten – die Drag-and-Drop-Benutzeroberfläche des Datensammlers ist super intuitiv.
StreamSets ist ein plattformunabhängiges Tool, mit dem Leute Datenerfassungspipelines erstellen können, die für verschiedene Umgebungen geeignet sind, ohne dass man viel umkonfigurieren muss. Neben den Datensammlern gibt's auf der Plattform auch Datentransformatoren, die mit Apache Spark arbeiten, um komplexe Datenumwandlungen zu machen.
Apache Beam ist eine einheitliche Lösung, die ein einziges Programmiermodell für Batch- und Streaming-Anwendungsfälle bietet. Es funktioniert super mit Cloud-Plattformen wie Google Cloud Dataflow, Apache Flink und Apache Spark.
Für die Echtzeit-Datenerfassung kannst du feste, gleitende und Sitzungsfenster festlegen, um Daten schnell zu gruppieren und zu verarbeiten.
Apache Beam ist echt flexibel. Damit kannst du Pipelines in jeder Programmiersprache definieren und auf mehreren Ausführungs-Engines laufen lassen.
Hevo Data ist eine komplett verwaltete Plattform, wo du ohne Programmierkenntnisse Daten aus über 150 Quellen dahin bringen kannst, wo du willst. Das Tool kümmert sich nicht nur um die Datenerfassung, sondern macht die Daten auch für Analysen bereit.
Die Plattform erkennt automatisch das Schema der eingehenden Daten und passt es an das Zielschema an, was für Flexibilität sorgt.
Hevo Data hat auch eine robuste, fehlertolerante Architektur, die dafür sorgt, dass beim Einlesen der Daten nichts verloren geht. Insgesamt ist Hevo Data die erste Wahl für Streaming und Echtzeit-Analysen.
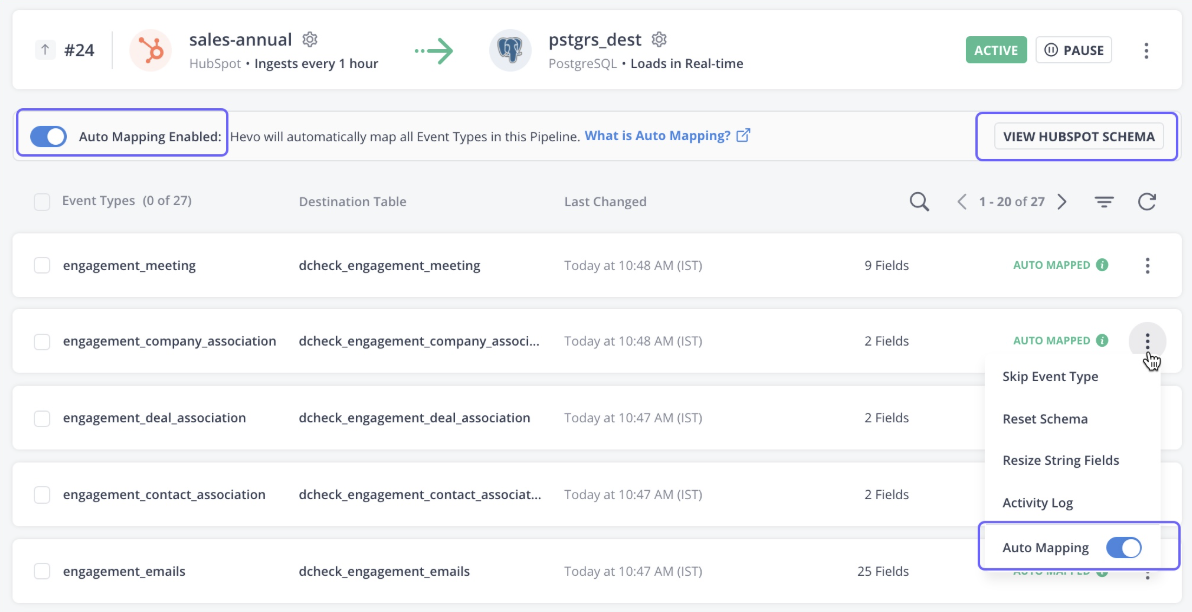
Hevo-Datenbenutzeroberfläche. Bildquelle: Hevo-Dokumentation
Segment ist eine Kundendatenplattform, die saubere und aufbereitete Kundendaten für Analysen bereitstellt. Die Plattform ist darauf ausgelegt, verschiedene Arten von Kundendaten zu sammeln, wie zum Beispiel Interaktionen, Impressionen, Klicks und andere Verhaltensdaten.
Die Lernpfad-API des Tools sammelt Ereignisdaten aus verschiedenen Quellen, wie zum Beispiel Mobilgeräten, dem Internet und Servern. Mit nur ein paar Klicks kannst du die Daten mit über 450 Apps verbinden.
Die über Segment gesammelten Daten sind für Nutzer über SQL-Abfragen verfügbar, während Programmierer mit curl-Befehlen auf Echtzeitdaten zugreifen können.
Matillion ist eine Cloud-native Datenintegrationsplattform, die dafür gemacht ist, Daten in der Cloud zu verschieben und umzuwandeln. Es ist am besten für leistungsstarke Cloud-Data-Warehouses wie Snowflake, Amazon Redshift und Google BigQuery gemacht.
Die Plattform hat eine Menge vorgefertigter Konnektoren für Cloud- und lokale Datenquellen, wie Datenbanken, SaaS-Anwendungen, Social-Media-Plattformen und mehr.
Matilion legt den Fokus auf Leistung und hat außerdem coole Funktionen zum Umwandeln von Daten, um sie für die weitere Analyse zu bereinigen und vorzubereiten.
Keboola, ein Spezifikations, der eigentlich für komplexe Transformationen entwickelt wurde, bietet benutzerdefinierte Funktionen zur Datenerfassung. Mit über 250 integrierten Verbindungen zwischen Quellen und Zielen macht es die Datenerfassung mit nur ein paar Klicks automatisch.
Keboola unterstützt sowohl Batch- als auch Echtzeit-Daten-Streaming zum Import von Unternehmensdaten. Bei der Echtzeit-Datenerfassung brauchst du allerdings Programmierkenntnisse, um Webhooks einzurichten.
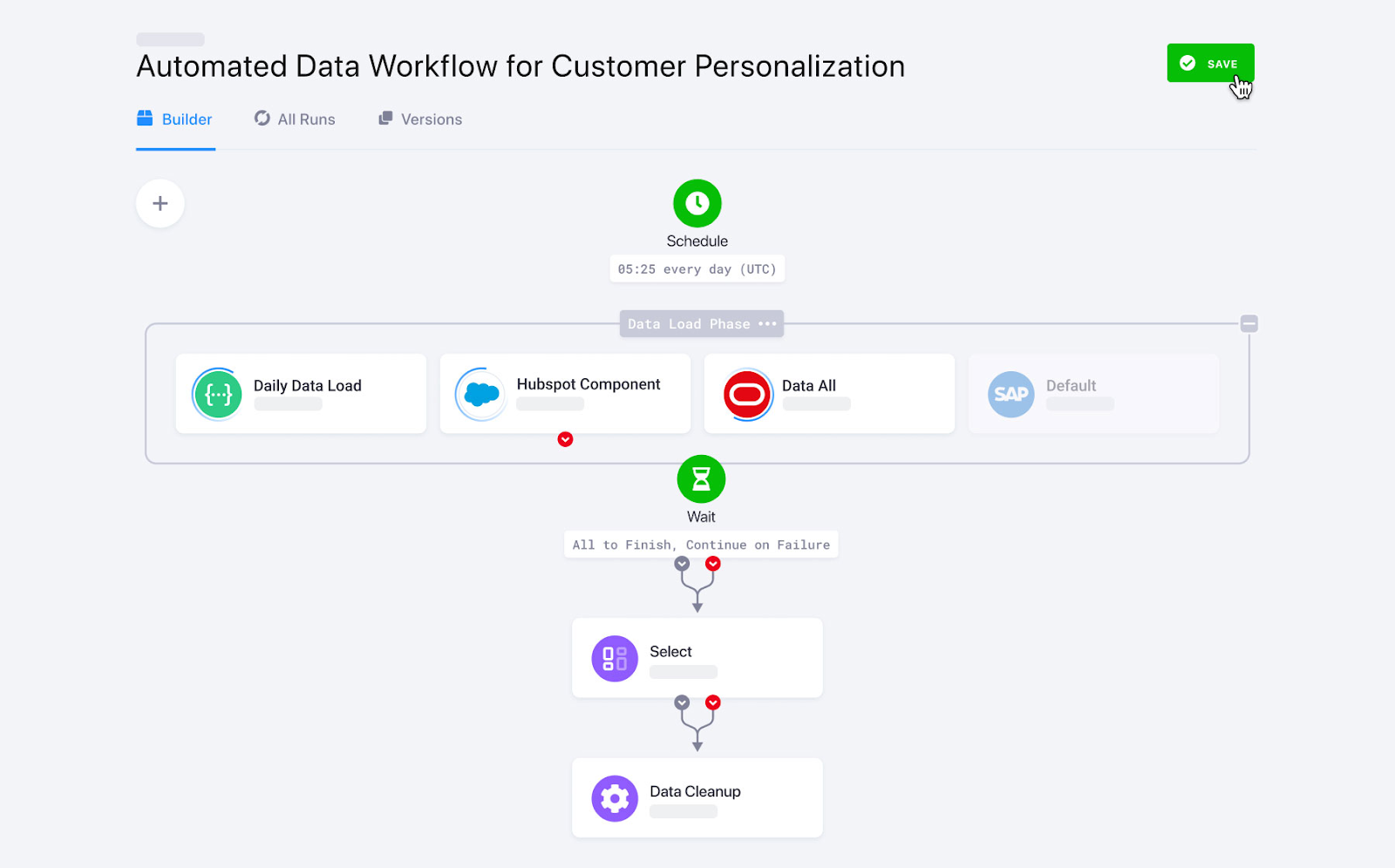
Keboola-Daten-Workflows. Bildquelle: Keboola
Snowplow ist eine moderne Plattform zum Sammeln von Daten, die Ereignisinfos aus verschiedenen Quellen erfasst und verarbeitet. Das Unternehmen ist darauf spezialisiert, Daten zum Kundenverhalten zu sammeln und für fortgeschrittene KI- und Machine-Learning-Analysen vorzubereiten.
Snowplow nutzt intern Tracker und Webhooks, um Echtzeit-Ereignisdaten zu sammeln.
Tracker sind Bibliotheken oder SDKs, die man in mobile Apps, Websites und serverseitige Anwendungen einbauen kann. Sie sammeln Event-Infos wie Nutzerinteraktionen, Klicks und Likes und schicken sie an Sammler. Die Sammler machen dann die Daten fertig, bevor sie zum Ziel-Warehouse geschickt werden.
IBM DataStage ist eine der besten Datenintegrationsplattformen für ETL- und ELT-Prozesse. Die Basisversion kannst du vor Ort nutzen, aber wenn du Skalierbarkeit und Automatisierung über die Cloud erleben willst, solltest du auf DataStage für IBM Cloud Pak® upgraden.
Die vielen vorgefertigten Konnektoren und Phasen machen die Datenübertragung zwischen verschiedenen Cloud-Quellen und Data Warehouses automatisch.
Für alle, die ihre Datenarchitektur auf dem IBM-Ökosystem aufbauen, ist DataStage das Tool der Wahl für die Datenerfassung. Es lässt sich mit anderen IBM-Datenplattformen wie Cloud Object Storage und Db2 verbinden, um Daten zu erfassen und umzuwandeln.
Alteryx ist bekannt für seine Tools zur Datenanalyse und -visualisierung.n Mit über 8000 Kunden ist es eine beliebte Analyseplattform, die Daten- und Analyseaufgaben automatisch erledigt.
Alteryx hat ein Tool namens Designer Cloud, das eine intuitive Oberfläche zum Erstellen von Datenaufnahmeleitungen für Analyse- und KI-Anwendungsfälle bietet. Es verbindet sich mit verschiedenen Datenquellen, wie zum Beispiel Data Warehouses, Cloud-Speicher und Dateisystemen.
Willst du die Datenvorbereitung und -analyse ohne Programmierung einfacher machen? Lerne mit „Einführung in Alteryx“, wie du „ “-Workflows automatisieren undDrag-and-Drop-ETL-Funktionen nutzen kannst.
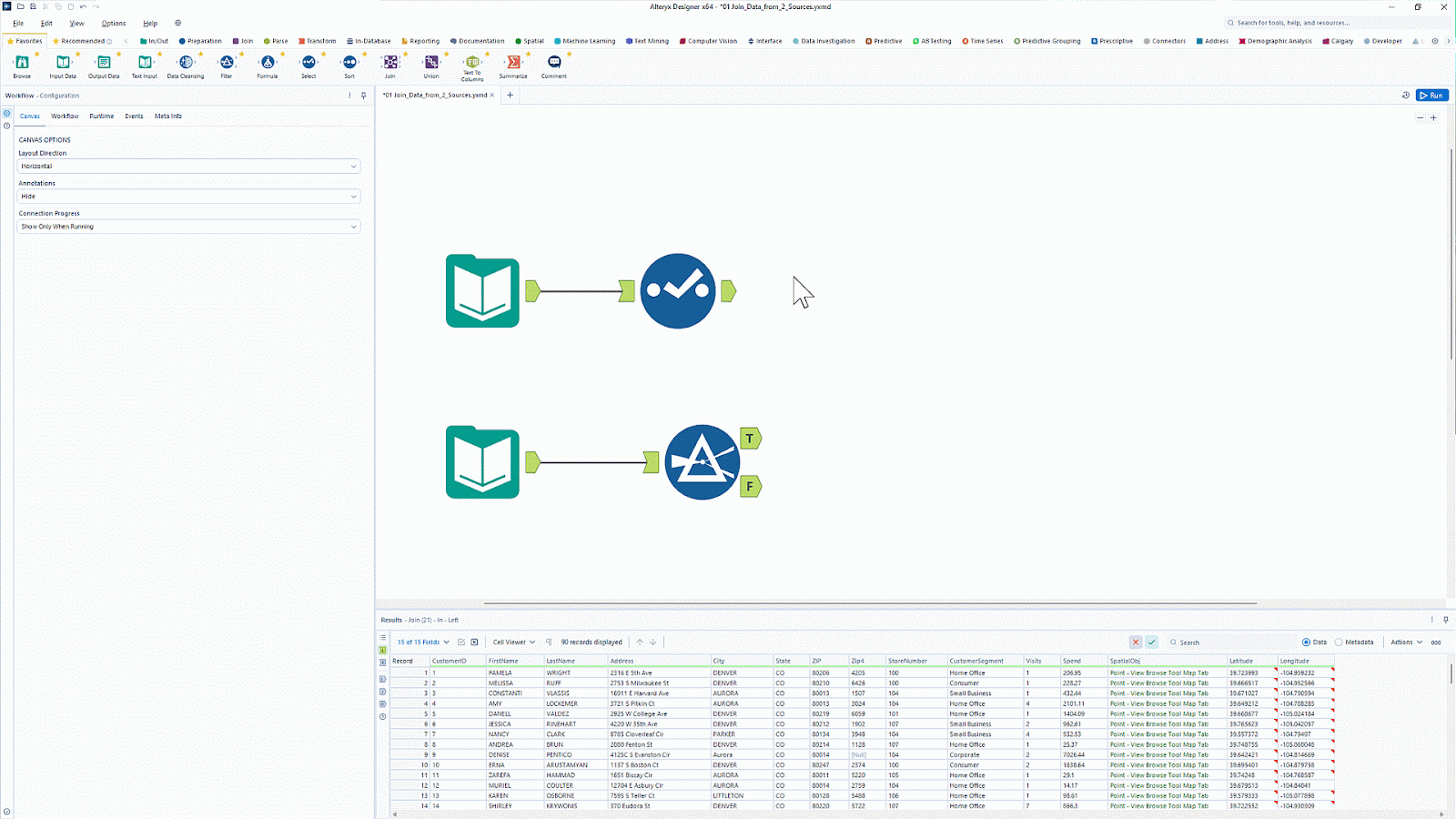
Alteryx-Benutzeroberfläche mit Drag-and-Drop-Funktion. Bildquelle: Alteryx
|
Werkzeug |
Am besten geeignet für |
Funktionen |
Preise |
|
Apache Kafka |
Echtzeit-Datenübertragung |
|
Open Source |
|
Apache Nifi |
Sichere Echtzeit-Datenerfassung |
|
Open Source |
|
AWS Glue |
AWS-Ökosystem |
|
Pay-as-you-go-Preismodell. Die Gebühren hängen davon ab, wie viele Daten pro Stunde verarbeitet werden. |
|
Google Cloud Dataflow |
Google Cloud-Ökosystem |
|
Pay-as-you-go-Preismodell. Die Gebühren hängen davon ab, wie viele Rechenressourcen und wie viel Speicher du benutzt. |
|
Azure-Datenfabrik |
Firmen, die andere Azure-Dienste von Microsoft nutzen |
|
Pay-as-you-go-Preismodell |
|
Talend |
Unternehmen mit kleinem Budget, die nach einer einfachen ETL-Lösung suchen |
|
Open Source |
|
Fivetran |
Vollständig verwaltete ELT-Anforderungen |
|
Abonnementbasierte Preise |
|
Airbyte |
Unternehmen, die nach einer Open-Source-Lösung für Anpassungen suchen |
|
Es gibt sowohl kostenlose Open-Source-Dienste als auch kostenpflichtige Dienste. |
|
Informatica |
Firmen, die Low-Code-Tools mit vielen Quellkonnektoren suchen |
|
30 Tage kostenlos testen, zahlst nur, was du nutzt |
|
Apache Flume |
Datenströme streamen |
|
Open Source |
|
Stitch |
Unternehmen, die nach einem einfachen Tool für Datenerfassungsaufgaben suchen |
|
Du kannst zwischen einem stufenbasierten oder einem nutzungsabhängigen Preismodell wählen. |
|
StreamSets |
Komplexe Datenumwandlungen |
|
Es gibt sowohl Open-Source- als auch kommerzielle Optionen. |
|
Apache Beam |
Anpassbares, codezentriertes Framework zum Aufbau von Datenaufnahmeleitungen |
|
Das Apache Beam-Framework ist Open Source, aber wenn man es mit Cloud-Diensten nutzt, fallen Kosten an. |
|
Hevo-Daten |
Mittelständische Unternehmen, die Echtzeitanalysen brauchen |
|
Abonnementbasierte Preise |
|
Segment |
Kundeneventdaten |
|
Abonnement-Preismodell |
|
Matillion |
Cloud-basiertes ETL/ELT-Tool |
|
Abonnementbasiertes Preismodell |
|
Keboola |
Komplexe Datenumwandlungspipelines |
|
Abonnementbasiertes Preismodell |
|
Snowplow |
Sammeln von Veranstaltungsdaten |
|
Es gibt sowohl Open-Source- als auch kommerzielle Optionen. |
|
IBM DataStage |
IBM Cloud-Ökosystem |
|
Abonnementbasiertes Preismodell |
|
Alteryx |
Datenanalyse und Visualisierung |
|
Abonnementbasiertes Preismodell |
Bei der großen Auswahl an Tools in der Branche kann es schwierig sein, die richtige Datenintegrationsplattform für deine Zwecke zu finden. Hier ist eine Liste mit ein paar Sachen, die du bedenken solltest, bevor du dich für ein bestimmtes Datenintegrationstool entscheidest.
Du kannst ganz einfach eine Excel-Tabelle oder CSV-Datei in die Zielorte einlesen. Es kann aber echt schwierig sein, Echtzeit-Streaming-Daten von verschiedenen Quellen manuell an unterschiedliche Ziele zu schicken. Zum Beispiel haben moderne Apps wie soziale Medien oft Zeiten mit viel und wenig Nachfrage. Hier zeigt sich die Skalierbarkeit von Tools zur Datenerfassung.
Skalierbarkeit ist die Möglichkeit, je nach Bedarf zu wachsen oder zu schrumpfen. Dadurch kann sich das Tool schnell an die steigenden Anforderungen der Datenmengen anpassen, ohne dass die Leistung darunter leidet.
Flexibilität ist die Fähigkeit, mit Daten aus verschiedenen Quellen und Formaten umzugehen. Datenaufnahmetools, die verschiedene Datenquellen unterstützen und benutzerdefinierte Konnektoren bieten, sorgen für Flexibilität in Datenaufnahmesystemen.
Die automatische Schema-Zuordnungsfunktion erkennt zum Beispiel das Schema der eingehenden Daten und ordnet sie dem Ziel zu, ohne sie auf eine vordefinierte Schema-Struktur zu beschränken. Dadurch kann das Tool Daten mit jedem Schema verarbeiten.
Beim Batch-Datenimport werden Daten nach einem Zeitplan gesammelt und am Zielort aktualisiert. Echtzeit-Datenaufnahme heißt dagegen, dass Daten ohne Verzögerung übertragen werden.
Viele Tools zum Einlesen von Daten können heutzutage sowohl Daten im Batch-Modus als auch in Echtzeit einlesen. Wenn du aber oft mit Echtzeitdaten wie Kundenereignissen oder Videostreaming zu tun hast, solltest du ein Tool mit hohem Durchsatz und geringer Latenz wählen.
Verschiedene Tools zum Einlesen von Daten haben unterschiedliche Preisstrukturen. Manche haben gestaffelte Preise, andere nutzen ein Pay-as-you-go-Modell. Diese Lösungen sind oft günstiger als Open-Source-Tools, weil man bei kostenlosen Tools Experten einstellen muss, um die Datenerfassung zu ermöglichen. Open-Source-Tools bieten aber echt viel Flexibilität und Anpassungsmöglichkeiten für deinen Anwendungsfall.
Einige kostenpflichtige Tools zur Datenerfassung bieten auch Funktionen für Unternehmen mit umfangreichen Anpassungsmöglichkeiten, sind aber nicht gerade billig. Deshalb solltest du je nach deinem Budget und deinen Anpassungswünschen zwischen kostenpflichtigen und Open-Source-Plattformen wählen.
Die Wahl des richtigen Tools zur Datenerfassung hängt von deinen spezifischen Anforderungen ab – egal, ob du Echtzeit-Streaming, Stapelverarbeitung, Cloud-Kompatibilität oder einfache Integration bevorzugst. Die oben genannten Tools bieten viele Optionen, mit denen du die Datenerfassung und das Laden in deine Zielsysteme effizienter machen kannst.
Wenn du noch nicht so viel Erfahrung mit Data Engineering hast und besser verstehen willst, wie Daten durch moderne Pipelines fließen, schau dir den Kurs „Einführung in Data Engineering“ an. Wenn du mehr über ETL- und ELT-Prozesse in Python wissen willst, ist „ETL und ELT in Python” eine super Quelle, um praktische Erfahrungen mit Datenaufnahmeverfahren zu sammeln.
Lerne mit diesen Kursen mehr über Data Engineering!
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Hesam Sheikh Hassani
15 Min.
