
programa
Fundamentos de la Gobernanza de Datos
10 h
La observabilidad de los datos se basa en cinco pilares fundamentales: Frescura, distribución, volumen, esquema y linaje. Juntos, estos pilares garantizan que los conductos de datos funcionen sin problemas y que los datos sigan siendo precisos, completos y fiables.
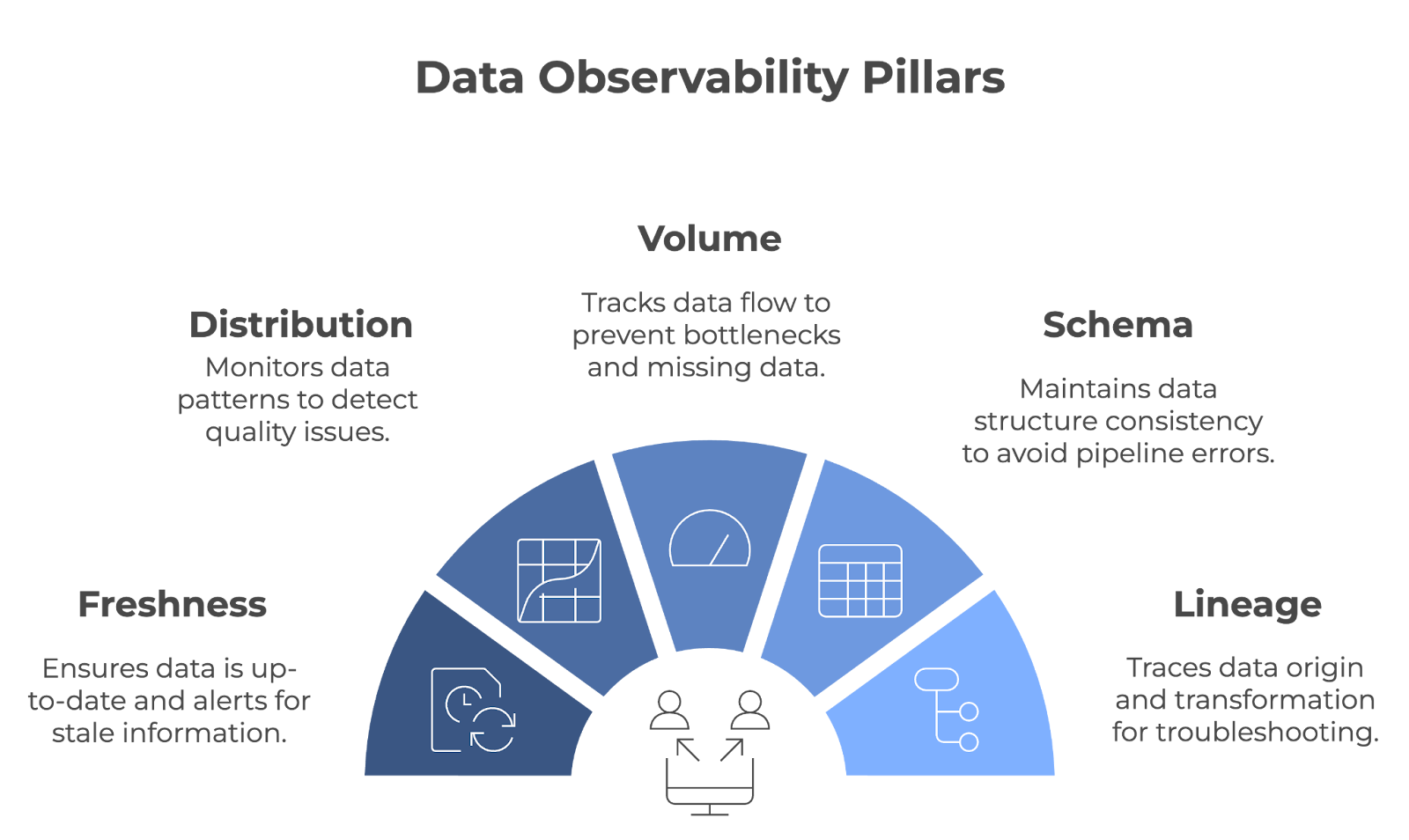
Los cinco pilares de la observabilidad de los datos. Imagen del autor (creada con napkin.ai)
¡Examinemos cada pilar en detalle!
La frescura te indica lo actualizados que están tus datos. Registra cuándo se actualizaron los datos por última vez y te avisa si se quedan obsoletos. Este pilar es importante para los equipos que dependen de datos en tiempo real o casi real para tomar decisiones.
La distribución se refiere al seguimiento de los patrones y valores específicos de tus datos (por ejemplo, media, mediana, desviación típica, etc.). Controlar estos valores ayuda a detectar cuando algo no parece correcto, lo que puede ser un signo de problemas de calidad de los datos. Las comprobaciones periódicas de la distribución garantizan que los datos permanezcan coherentes a lo largo del tiempo.
El volumen de datos se refiere a la cantidad de datos que fluyen por un sistema. Esta métrica se controla para garantizar que se está ingiriendo y procesando la cantidad de datos esperada, sin caídas ni picos inesperados. El volumen de datos se supervisa para detectar rápidamente problemas como la falta de datos o los cuellos de botella en las canalizaciones.
La observabilidad del esquema rastrea la estructura de los datos: es importante que permanezca constante a lo largo del tiempo. Cuando tu esquema cambia inesperadamente, puede romper tus canalizaciones de datos y provocar errores en el procesamiento.
Lineage provides una visión clara de dónde proceden tus datos, cómo se transforman y dónde acaban. Esto es clave para solucionar problemas y mantener la calidad de los datos en sistemas complejos. Cuando surgen problemas, el linaje te permite rastrear los puntos de datos a través de la tubería para encontrar el origen del problema.
A lo largo de este artículo, hemos aludido a la observabilidad de los datos supervisando activamente los conductos de datos, enviando alertas cuando surgen problemas y ayudando a los equipos a encontrar rápidamente la causa raíz de los problemas.
Exploremos cómo funciona cada componente en la práctica.
Las herramientas de observabilidad de datos detectan los errores mediante la supervisión constante de los conductos de datos. Pueden realizar el seguimiento de muchos aspectos de una cadena de datos, pero normalmente se configuran para centrarse en métricas específicas o en las áreas más críticas para las necesidades de la organización.
Estas herramientas a menudo se integran con tecnologías como Apache Kafka, Apache Airflow, o servicios basados en la nube como AWS Glue o Google Cloud Dataflow para recopilar información en varias fases del proceso. Por ejemplo:
¿Qué sentido tiene detectar rápidamente los problemas si nadie está informado? Las herramientas de observabilidad de datos alertan automáticamente a las personas adecuadas y, a veces, toman medidas basándose en configuraciones predefinidas.
Estas alertas suelen configurarse en función de umbrales o desencadenantes, como registros que faltan, cambios en el esquema o retrasos inesperados en los datos. Por ejemplo:
El análisis de la causa raíz es un proceso sistemático para identificar la razón fundamental de un problema o cuestión. En el contexto de la observabilidad de los datos, implica rastrear un problema de datos hasta su origen, en lugar de limitarse a tratar sus síntomas.
Las plataformas de observabilidad de datos a menudo proporcionan ricas capacidades de diagnóstico, integrándose con sistemas de gestión de registros como Elasticsearch o plataformas de monitorización como Prometheus y Grafana para sacar a la superficie detalles granulares. Por ejemplo:
A menudo, los ingenieros de datos implementan internamente las funciones de observabilidad. Sin embargo, hoy en día existen varias herramientas potentes que permiten a los equipos poner en práctica la observabilidad de los datos de forma eficaz. ¡Echemos un vistazo a los más populares!
Montecarlo es una potente plataforma de observabilidad de datos diseñada para ayudar a los equipos a mantener la salud de sus sistemas de datos. Creada por un equipo de antiguos ingenieros de empresas como LinkedIn y Facebook, la plataforma surgió del deseo de resolver el creciente problema del tiempo de inactividad de los datos. Proporciona:
Montecarlo se integra con herramientas como Snowflake, dbt y Looker, por lo que es ideal para los equipos que trabajan en ecosistemas de datos modernos.
Bigeye fue fundada en 2020 por un grupo de ingenieros de datos. Es una plataforma de observabilidad de datos diseñada para mantener la calidad y fiabilidad de los datos a lo largo de su ciclo de vida.
La plataforma se centra en la automatización de la supervisión de la calidad de los datos, la detección de anomalías y la resolución de problemas con los datos, para que los flujos de datos fluyan sin problemas y las partes interesadas puedan confiar en datos precisos para la toma de decisiones. Entre sus características se incluyen:
Databand es una plataforma de observabilidad de datos para gestionar de forma proactiva la salud de los datos, proporcionando visibilidad de las canalizaciones de datos. Fundada en 2019, Databand se creó para hacer frente a la creciente complejidad y escala del entorno de datos.
La plataforma se construyó para ayudar a los ingenieros de datos a detectar problemas en tiempo real, comprender el flujo de datos y garantizar la exactitud de los conjuntos de datos en toda la organización. Sus características son:
Datadog es una plataforma de monitorización y análisis basada en la nube que proporciona observabilidad en tiempo real. Fundada en 2010 por Olivier Pomel y Alexis Lê-Quôc, Datadog se creó para hacer frente a la complejidad de las aplicaciones modernas en la nube.
Datadog es ideal para empresas que necesitan una supervisión exhaustiva de varios sistemas. La plataforma es especialmente útil para empresas nativas de la nube o con sistemas distribuidos complejos. Entre sus características se incluyen:
|
Herramienta |
Áreas de interés |
Integraciones |
Ideal para |
|
Monte Carlo |
Calidad de datos, detección de anomalías, linaje de datos |
Copo de nieve, dbt, Looker |
Los ecosistemas de datos modernos necesitan una observabilidad automatizada |
|
Patudo |
Supervisión de la calidad de los datos, detección de anomalías, interfaz de usuario fácil de usar |
Slack, Jira, grandes lagos de datos y almacenes |
Industrias con grandes necesidades de fiabilidad de datos (por ejemplo, finanzas, sanidad) |
|
Banda de datos |
Supervisión de tuberías, análisis del impacto de los datos, alertas en tiempo real |
Apache Airflow, Spark, BigQuery, Kafka |
Equipos que gestionan flujos de datos complejos y de gran volumen |
|
Datadog |
Supervisión unificada, alertas en tiempo real, soporte nativo en la nube |
AWS, Google Cloud, Docker, Kubernetes |
Empresas con sistemas distribuidos o configuraciones nativas de la nube |
Para implantar eficazmente la observabilidad de los datos, céntrate en estas buenas prácticas:
Céntrate en supervisar primero los conductos de datos más críticos, los que tienen un impacto empresarial más significativo. Puedes mitigar el riesgo asegurándote de que estos pipelines están sanos mientras construyes gradualmente una estrategia de observabilidad más amplia en otros pipelines.
Unas métricas claramente definidas son la clave para evaluar la salud de los datos: debes saber qué aspecto tiene el éxito (y el fracaso). Estas métricas deben estar alineadas con los objetivos generales de la empresa para reflejar lo que realmente importa. Esta claridad te ayudará a mantenerte centrado y a evaluar sus progresos con eficacia.
Los sistemas de supervisión y alerta reducen la intervención manual y mejoran los tiempos de respuesta. Los sistemas automatizados pueden detectar problemas con antelación y activar acciones inmediatas para evitar el tiempo de inactividad de los datos. Haz de la automatización una prioridad.
Incorporar la observabilidad a tus procesos diarios te permite responder más rápida y eficazmente, haciendo que la gestión de datos sea más proactiva y menos reactiva.
La observabilidad de los datos es clave para construir canalizaciones de datos fiables y de alta calidad. Al supervisar continuamente los aspectos críticos de los datos, los equipos pueden identificar y abordar los problemas antes de que afecten a los resultados empresariales. A medida que los datos sigan impulsando las decisiones empresariales, la observabilidad seguirá siendo un elemento esencial para gestionar y optimizar los conductos de datos.
Para comprender plenamente la importancia de la observabilidad y aplicarla eficazmente, es necesario entender conceptos relacionados como la arquitectura, la gobernanza y la gestión de datos. Si buscas profundizar en tus conocimientos:
Por último, si eres nuevo en este campo, ¡Entender la Ingeniería de Datos es un gran punto de partida para explorar cómo se diseñan y mantienen los conductos de datos!
Aprende más sobre la gobernanza de datos con estos cursos
programa
Curso
Curso
blog
Tim Lu
12 min
blog
Javier Canales Luna
12 min
blog
Matt Crabtree
10 min
blog
Javier Canales Luna
14 min
blog
Matt Crabtree
15 min
blog
Javier Canales Luna
13 min


