
Lernpfad
Grundlagen der Data Governance
10 Std.
Die Beobachtbarkeit von Daten beruht auf fünf wichtigen Säulen: Frische, Verteilung, Volumen, Schema und Abstammung. Gemeinsam sorgen diese Säulen dafür, dass die Datenpipelines reibungslos funktionieren und dass die Daten genau, vollständig und zuverlässig bleiben.
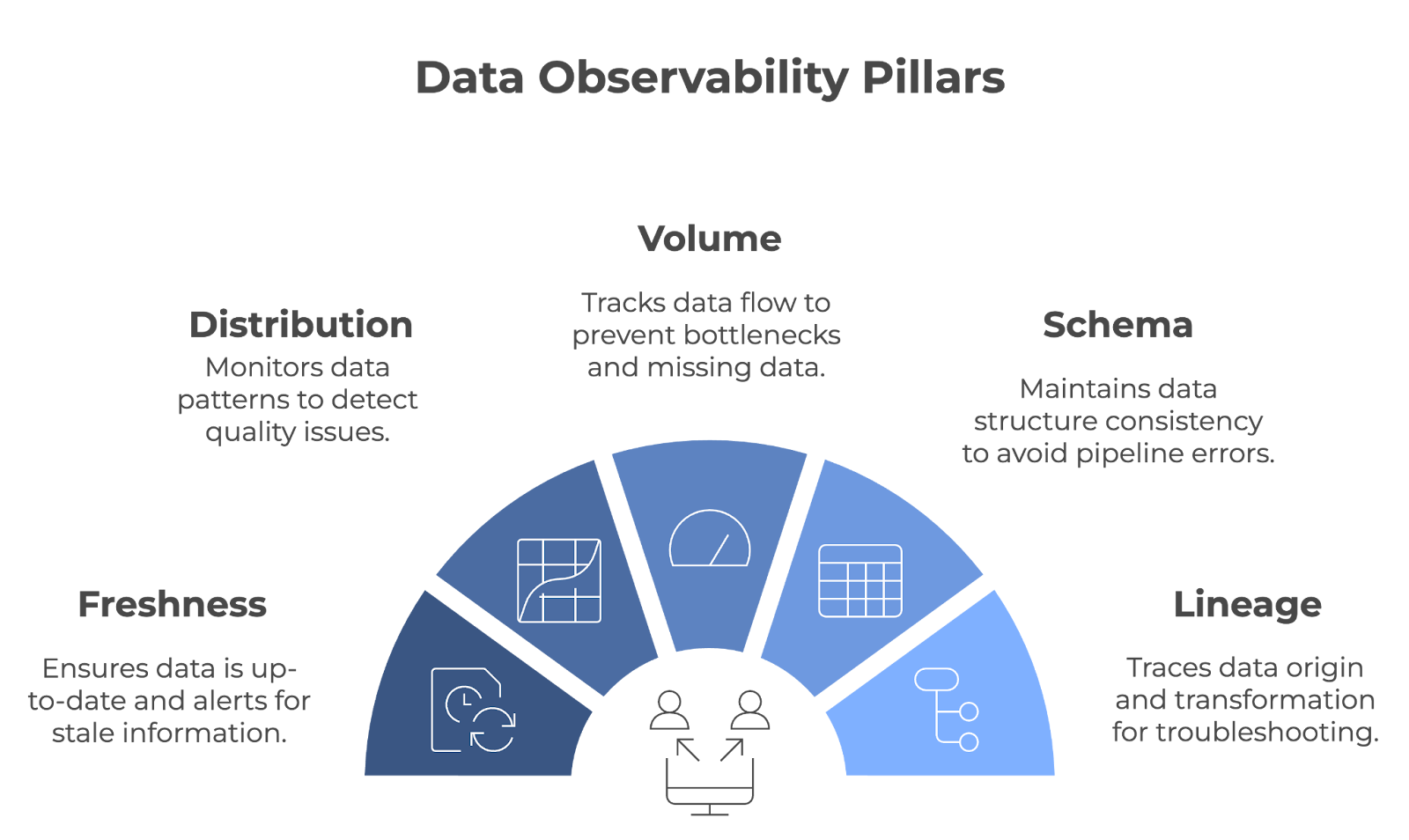
Die fünf Säulen der Beobachtbarkeit von Daten. Bild vom Autor (erstellt mit napkin.ai)
Schauen wir uns jede Säule im Detail an!
Die Freshness sagt dir, wie aktuell deine Daten sind. Der Lernpfad zeigt an, wann die Daten zuletzt aktualisiert wurden und warnt dich, wenn sie veraltet sind. Diese Säule ist wichtig für Teams, die bei ihren Entscheidungen auf Echtzeit- oder echtzeitnahe Daten angewiesen sind.
Die Verteilung bezieht sich auf die Verfolgung von Mustern und bestimmten Werten in deinen Daten (z. B. Mittelwert, Median, Standardabweichung usw.). Die Überwachung dieser Werte hilft dabei, zu erkennen, wenn etwas nicht stimmt, was ein Zeichen für Probleme mit der Datenqualität sein kann. Regelmäßige Überprüfungen der Verteilung garantieren, dass die Daten im Laufe der Zeit konsistent bleiben.
Das Datenvolumen bezieht sich auf die Menge der Daten, die durch ein System fließen. Dieser Lernpfad wird verfolgt, um sicherzustellen, dass die erwartete Datenmenge aufgenommen und verarbeitet wird, ohne dass es zu unerwarteten Einbrüchen oder Ausschlägen kommt. Das Datenvolumen wird überwacht, um Probleme wie fehlende Daten oder Engpässe in der Pipeline schnell zu erkennen.
Die Beobachtbarkeit des Schemas verfolgt die Struktur der Daten - es ist wichtig, dass sie im Laufe der Zeit konsistent bleibt. Wenn sich dein Schema unerwartet ändert, kann dies deine Datenpipelines unterbrechen und zu Fehlern bei der Verarbeitung führen.
Lineage provides einen klaren Überblick darüber, woher deine Daten kommen, wie sie umgewandelt werden und wo sie am Ende landen. Das ist der Schlüssel für die Fehlersuche und die Erhaltung der Datenqualität in komplexen Systemen. Wenn Probleme auftreten, kannst du die Datenpunkte durch die Pipeline zurückverfolgen, um die Ursache des Problems zu finden.
In diesem Artikel haben wir bereits angedeutet, dass die Datenbeobachtung Datenpipelines aktiv überwacht, bei Problemen Warnungen sendet und den Teams hilft, die Ursache von Problemen schnell zu finden.
Lass uns herausfinden, wie jede Komponente in der Praxis funktioniert!
Tools zur Datenbeobachtung erkennen Fehler, indem sie die Datenpipelines ständig überwachen. Sie können viele Aspekte einer Datenpipeline verfolgen, sind aber in der Regel so konfiguriert, dass sie sich auf bestimmte Kennzahlen oder Bereiche konzentrieren, die für die Bedürfnisse des Unternehmens am wichtigsten sind.
Diese Tools werden oft mit Technologien wie Apache Kafka, Apache Airflow oder Cloud-basierten Diensten wie AWS Glue oder Google Cloud Dataflow integriert, um in verschiedenen Phasen der Pipeline Erkenntnisse zu sammeln. Zum Beispiel:
Was nützt es, Probleme schnell zu erkennen, wenn niemand informiert wird? Tools zur Datenbeobachtung alarmieren automatisch die richtigen Leute und ergreifen manchmal Maßnahmen auf der Grundlage von vordefinierten Konfigurationen.
Diese Warnungen werden oft auf der Grundlage von Schwellenwerten oder Auslösern konfiguriert, z. B. bei fehlenden Datensätzen, Schemaänderungen oder unerwarteten Datenverzögerungen. Zum Beispiel:
Die Ursachenanalyse ist ein systematischer Prozess, um den grundlegenden Grund für ein Problem oder eine Frage zu ermitteln. Im Zusammenhang mit der Beobachtbarkeit von Daten geht es darum, ein Datenproblem bis zu seinem Ursprung zurückzuverfolgen, anstatt nur die Symptome zu bekämpfen.
Plattformen zur Datenbeobachtung bieten oft umfangreiche Diagnosefunktionen, die mit Log-Management-Systemen wie Elasticsearch oder Überwachungsplattformen wie Prometheus und Grafana integriert werden können, um granulare Details anzuzeigen. Zum Beispiel:
Oftmals implementieren Dateningenieure die Funktionen zur Beobachtung selbst. Heute gibt es jedoch mehrere leistungsstarke Tools, mit denen Teams die Datenbeobachtung effektiv umsetzen können. Werfen wir einen Blick auf die beliebtesten davon!
Monte Carlo ist eine leistungsstarke Plattform zur Datenbeobachtung, die Teams dabei hilft, den Zustand ihrer Datensysteme zu erhalten. Die Plattform wurde von einem Team aus ehemaligen Ingenieuren von Unternehmen wie LinkedIn und Facebook gegründet und entstand aus dem Wunsch heraus, das wachsende Problem der Datenausfallzeiten zu lösen. Es bietet:
Monte Carlo lässt sich mit Tools wie Snowflake, dbt und Looker integrieren und ist damit ideal für Teams, die in modernen Datenökosystemen arbeiten.
Bigeye wurde im Jahr 2020 von einer Gruppe von Dateningenieuren gegründet. Es ist eine Plattform zur Datenbeobachtung, die die Qualität und Zuverlässigkeit von Daten während ihres gesamten Lebenszyklus sicherstellt.
Die Plattform konzentriert sich auf die Automatisierung der Überwachung der Datenqualität, die Erkennung von Anomalien und die Lösung von Datenproblemen, damit die Datenpipelines reibungslos funktionieren und die Beteiligten sich bei ihren Entscheidungen auf genaue Daten verlassen können. Seine Funktionen umfassen:
Databand ist eine Plattform zur Datenbeobachtung, die proaktiv den Zustand der Daten verwaltet, indem sie Einblicke in die Datenpipelines gewährt. Databand wurde 2019 gegründet, um der zunehmenden Komplexität und Größe der Datenumgebung zu begegnen.
Die Plattform wurde entwickelt, um Dateningenieure dabei zu unterstützen, Probleme in Echtzeit zu erkennen, den Datenfluss zu verstehen und die Genauigkeit der Datensätze im gesamten Unternehmen zu gewährleisten. Seine Merkmale sind:
Datadog ist eine Cloud-basierte Überwachungs- und Analyseplattform, die Echtzeitbeobachtung ermöglicht. Datadog wurde 2010 von Olivier Pomel und Alexis Lê-Quôc gegründet, um die Komplexität moderner Cloud-Anwendungen zu bewältigen.
Datadog ist ideal für Unternehmen, die eine umfassende Überwachung über verschiedene Systeme hinweg benötigen. Die Plattform ist besonders nützlich für Cloud-native Unternehmen oder solche mit komplexen, verteilten Systemen. Seine Funktionen umfassen:
|
Tool |
Schwerpunktbereiche |
Integrationen |
Ideal für |
|
Monte Carlo |
Datenqualität, Erkennung von Anomalien, Datenreihenfolge |
Snowflake, dbt, Looker |
Moderne Datenökosysteme, die automatisierte Beobachtbarkeit benötigen |
|
Großaugen |
Überwachung der Datenqualität, Erkennung von Anomalien, benutzerfreundliche UI |
Slack, Jira, große Data Lakes und Lagerhäuser |
Branchen mit hohen Anforderungen an die Zuverlässigkeit der Daten (z. B. Finanzwesen, Gesundheitswesen) |
|
Databand |
Pipeline-Überwachung, Datenauswirkungsanalyse, Echtzeit-Warnungen |
Apache Airflow, Spark, BigQuery, Kafka |
Teams, die große, komplexe Datenströme verwalten |
|
Datadog |
Einheitliche Überwachung, Echtzeit-Alarmierung, Cloud-native Unterstützung |
AWS, Google Cloud, Docker, Kubernetes |
Unternehmen mit verteilten Systemen oder Cloud-Native-Setups |
Um die Datenbeobachtung effektiv umzusetzen, solltest du dich auf diese Best Practices konzentrieren:
Konzentriere dich zuerst auf die Überwachung der kritischsten Datenpipelines, also derjenigen mit den größten Auswirkungen auf das Geschäft. Du kannst das Risiko mindern, indem du sicherstellst, dass diese Pipelines gesund sind, während du schrittweise eine breitere Beobachtungsstrategie für andere Pipelines aufbaust.
Klar definierte Kennzahlen sind der Schlüssel zur Bewertung der Datenqualität - du musst wissen, wie Erfolg (und Misserfolg) aussieht. Diese Kennzahlen müssen mit den allgemeinen Unternehmenszielen übereinstimmen, damit sie das widerspiegeln, was wirklich wichtig ist. Diese Klarheit wird dir helfen, dich zu konzentrieren und ihre Fortschritte effektiv zu bewerten.
Überwachungs- und Warnsysteme reduzieren manuelle Eingriffe und verbessern die Reaktionszeiten. Automatisierte Systeme können Probleme frühzeitig erkennen und sofortige Maßnahmen einleiten, um Datenausfälle zu verhindern. Mach die Automatisierung zu einer Priorität.
Indem du die Beobachtbarkeit in deine täglichen Prozesse einbaust, kannst du schneller und effektiver reagieren und so das Datenmanagement proaktiver und weniger reaktiv gestalten.
Die Beobachtbarkeit von Daten ist der Schlüssel zum Aufbau hochwertiger, zuverlässiger Datenpipelines. Durch die kontinuierliche Überwachung kritischer Datenaspekte können Teams Probleme erkennen und beheben, bevor sie sich auf die Geschäftsergebnisse auswirken. Da Daten weiterhin die Grundlage für Geschäftsentscheidungen sind, wird die Beobachtbarkeit ein Kernelement für die Verwaltung und Optimierung von Datenpipelines bleiben.
Um die Bedeutung der Beobachtbarkeit vollständig zu erfassen und sie effektiv umzusetzen, ist es notwendig, verwandte Konzepte wie Datenarchitektur, Governance und Management zu verstehen. Wenn du dein Wissen auf vertiefen willst:
Wenn du neu auf dem Gebiet bist, ist Understanding Data Engineering ein großartiger Ausgangspunkt, um herauszufinden, wie Datenpipelines entworfen und gepflegt werden!
Erfahre mehr über Data Governance mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.