
Programa
Fundamentos da governança de dados
10 h
A observabilidade dos dados é construída sobre cinco pilares principais: Frescor, distribuição, volume, esquema e linhagem. Juntos, esses pilares garantem que os pipelines de dados funcionem sem problemas e que os dados permaneçam precisos, completos e confiáveis.
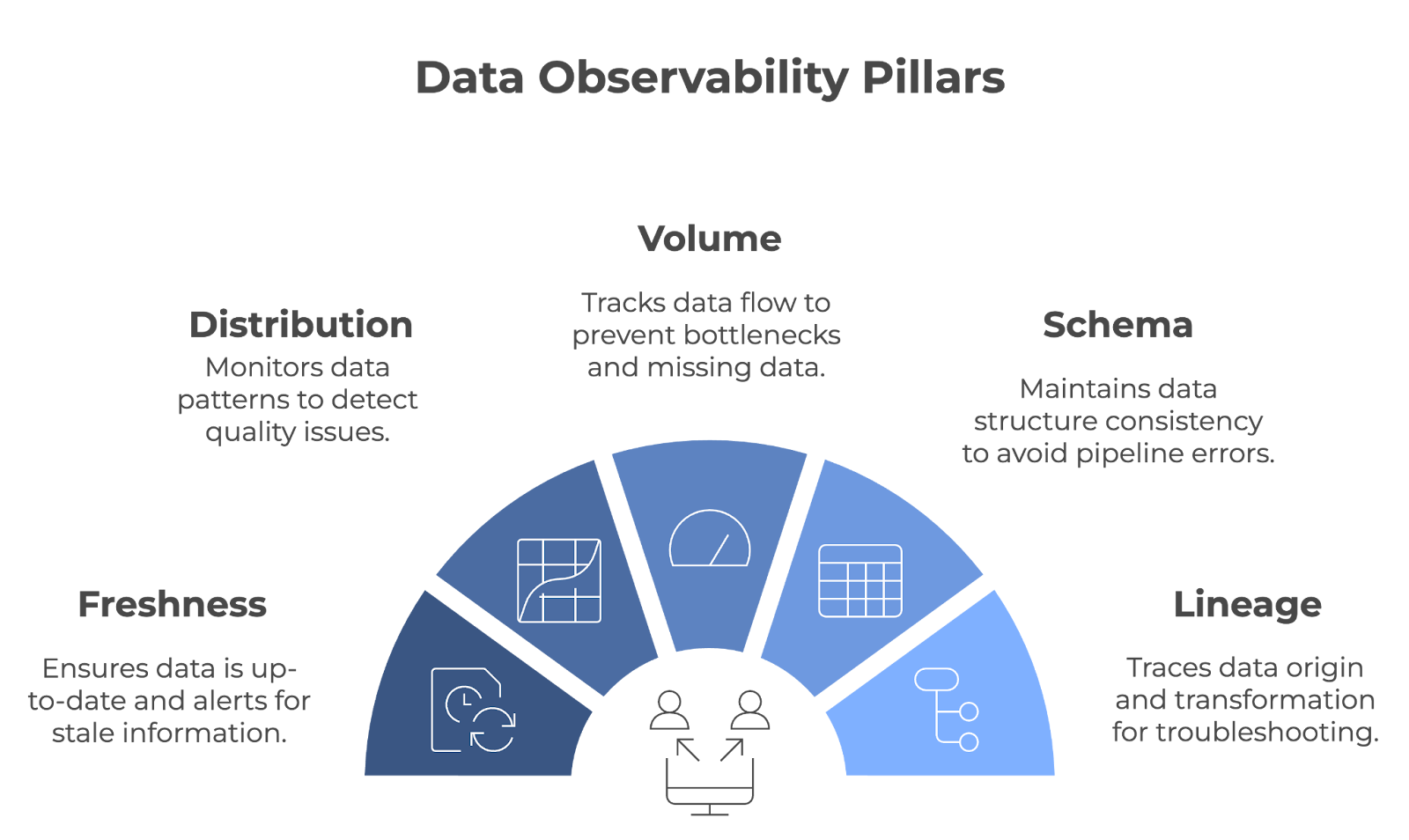
Os cinco pilares da observabilidade dos dados. Imagem do autor (criada com napkin.ai)
Vamos examinar cada pilar em detalhes!
O frescor informa a você o quanto seus dados estão atualizados. Ele rastreia quando os dados foram atualizados pela última vez e alerta você se eles se tornarem obsoletos. Esse pilar é importante para as equipes que dependem de dados em tempo real ou quase em tempo real para tomar decisões.
A distribuição refere-se ao rastreamento dos padrões e valores específicos em seus dados (por exemplo, média, mediana, desvio padrão, etc.). O monitoramento desses valores ajuda a identificar quando algo parece errado, o que pode ser um sinal de problemas de qualidade de dados. Verificações regulares de distribuição garantem que os dados permaneçam consistentes ao longo do tempo.
O volume de dados refere-se à quantidade de dados que flui por um sistema. Essa métrica é rastreada para garantir que a quantidade esperada de dados esteja sendo ingerida e processada sem quedas ou picos inesperados. O volume de dados é monitorado para detectar rapidamente problemas como dados ausentes ou gargalos no pipeline.
A observabilidade do esquema rastreia a estrutura dos dados - é importante que ela permaneça consistente ao longo do tempo. Quando o esquema muda inesperadamente, isso pode interromper os pipelines de dados e levar a erros no processamento.
Lineage provides uma visão clara de onde seus dados vêm, como são transformados e onde terminam. Isso é fundamental para solucionar problemas e manter a qualidade dos dados em sistemas complexos. Quando surgem problemas, a linhagem permite que você rastreie os pontos de dados no pipeline para encontrar a origem do problema.
Ao longo deste artigo, fizemos alusão à observabilidade dos dados, monitorando ativamente os pipelines de dados, enviando alertas quando surgem problemas e ajudando as equipes a encontrar rapidamente a causa raiz dos problemas.
Vamos explorar como cada componente funciona na prática!
As ferramentas de observabilidade de dados detectam erros por meio do monitoramento constante dos pipelines de dados. Eles podem rastrear muitos aspectos de um pipeline de dados, mas normalmente são configurados para se concentrar em métricas específicas ou nas áreas mais importantes para as necessidades da organização.
Essas ferramentas geralmente se integram a tecnologias como Apache Kafka, Apache Airflow ou serviços baseados em nuvem, como AWS Glue ou Google Cloud Dataflow, para coletar insights em vários estágios do pipeline. Por exemplo:
Qual é a vantagem de detectar problemas rapidamente se ninguém for informado? As ferramentas de observabilidade de dados alertam automaticamente as pessoas certas e, às vezes, tomam medidas com base em configurações predefinidas.
Esses alertas geralmente são configurados com base em limites ou acionadores, como registros ausentes, alterações de esquema ou atrasos inesperados nos dados. Por exemplo:
A análise de causa raiz é um processo sistemático para identificar o motivo fundamental por trás de um problema ou questão. No contexto da observabilidade dos dados, isso envolve o rastreamento de um problema de dados até a sua origem, em vez de apenas abordar seus sintomas.
As plataformas de observabilidade de dados geralmente oferecem recursos avançados de diagnóstico, integrando-se a sistemas de gerenciamento de logs, como o Elasticsearch, ou a plataformas de monitoramento, como o Prometheus e o Grafana, para exibir detalhes granulares. Por exemplo:
Em geral, os engenheiros de dados implementam recursos de observabilidade internamente. No entanto, há várias ferramentas poderosas disponíveis atualmente que permitem que as equipes implementem a observabilidade de dados pronta para uso de forma eficaz. Vamos dar uma olhada nos mais populares!
O Monte Carlo é uma poderosa plataforma de observabilidade de dados projetada para ajudar as equipes a manter a integridade de seus sistemas de dados. Criada por uma equipe de ex-engenheiros de empresas como LinkedIn e Facebook, a plataforma foi construída a partir do desejo de solucionar o crescente desafio do tempo de inatividade dos dados. Ele fornece:
O Monte Carlo se integra a ferramentas como Snowflake, dbt e Looker, tornando-o ideal para equipes que trabalham em ecossistemas de dados modernos.
A Bigeye foi fundada em 2020 por um grupo de engenheiros de dados. É uma plataforma de observabilidade de dados projetada para manter a qualidade e a confiabilidade dos dados durante todo o seu ciclo de vida.
A plataforma se concentra na automação do monitoramento da qualidade dos dados, na detecção de anomalias e na resolução de problemas de dados para manter os pipelines de dados fluindo sem problemas e garantir que as partes interessadas possam confiar em dados precisos para a tomada de decisões. Seus recursos incluem:
O Databand é uma plataforma de observabilidade de dados para gerenciar proativamente a integridade dos dados, fornecendo visibilidade dos pipelines de dados. Fundada em 2019, a Databand foi criada para lidar com a crescente complexidade e escala do ambiente de dados.
A plataforma foi criada para ajudar os engenheiros de dados a detectar problemas em tempo real, entender o fluxo de dados e garantir a precisão dos conjuntos de dados em toda a organização. Seus recursos são:
O Datadog é uma plataforma de monitoramento e análise baseada em nuvem que oferece observabilidade em tempo real. Fundada em 2010 por Olivier Pomel e Alexis Lê-Quôc, a Datadog foi criada para lidar com a complexidade dos aplicativos modernos em nuvem.
O Datadog é ideal para empresas que precisam de monitoramento abrangente em vários sistemas. A plataforma é especialmente útil para empresas nativas da nuvem ou com sistemas complexos e distribuídos. Seus recursos incluem:
|
Ferramenta |
Áreas de foco |
Integrações |
Ideal para |
|
Monte Carlo |
Qualidade de dados, detecção de anomalias, linhagem de dados |
Snowflake, dbt, Looker |
Ecossistemas de dados modernos que precisam de observabilidade automatizada |
|
Olho grande |
Monitoramento da qualidade dos dados, detecção de anomalias, interface de usuário amigável |
Slack, Jira, grandes lagos de dados e armazéns |
Setores com grandes necessidades de confiabilidade de dados (por exemplo, finanças, saúde) |
|
Banda de dados |
Monitoramento de pipeline, análise de impacto de dados, alertas em tempo real |
Apache Airflow, Spark, BigQuery, Kafka |
Equipes que gerenciam fluxos de dados complexos e de grande volume |
|
Datadog |
Monitoramento unificado, alertas em tempo real, suporte nativo da nuvem |
AWS, Google Cloud, Docker, Kubernetes |
Empresas com sistemas distribuídos ou configurações nativas da nuvem |
Para implementar efetivamente a observabilidade dos dados, concentre-se nestas práticas recomendadas:
Concentre-se em monitorar primeiro os pipelines de dados mais críticos - aqueles com o impacto comercial mais significativo. Você pode reduzir o risco certificando-se de que esses pipelines estejam saudáveis e, ao mesmo tempo, criando gradualmente uma estratégia de observabilidade mais ampla em outros pipelines.
Métricas claramente definidas são fundamentais para avaliar a integridade dos dados - você precisa saber o que é sucesso (e fracasso). Essas métricas devem estar alinhadas com as metas gerais da empresa para refletir o que realmente importa. Essa clareza ajudará você a manter o foco e a avaliar o progresso deles de forma eficaz.
Os sistemas de monitoramento e alerta reduzem a intervenção manual e melhoram os tempos de resposta. Os sistemas automatizados podem detectar problemas antecipadamente e acionar ações imediatas para evitar o tempo de inatividade dos dados. Faça da automação uma prioridade.
A incorporação da observabilidade em seus processos diários permite que você responda de forma mais rápida e eficaz, tornando o gerenciamento de dados mais proativo e menos reativo.
A observabilidade dos dados é fundamental para a criação de pipelines de dados confiáveis e de alta qualidade. Ao monitorar continuamente os aspectos críticos dos dados, as equipes podem identificar e resolver problemas antes que eles afetem os resultados comerciais. Como os dados continuam a orientar as decisões de negócios, a observabilidade continuará sendo um elemento essencial para gerenciar e otimizar os pipelines de dados.
Para compreender totalmente a importância da observabilidade e implementá-la de forma eficaz, é necessário entender conceitos relacionados, como arquitetura de dados, governança e gerenciamento. Se você deseja aprofundar seu conhecimento:
Por fim, se você é novo na área, Understanding Data Engineering é um ótimo ponto de partida para explorar como os pipelines de dados são projetados e mantidos!
Saiba mais sobre governança de dados com estes cursos!
Programa
Curso
Curso
blog
Javier Canales Luna
12 min
blog
Javier Canales Luna
14 min
blog
Christine Cepelak
15 min
blog
Matt Crabtree
15 min

