
Cursus
Fondamentaux de la gouvernance des données
10 h
L'observabilité des données repose sur cinq piliers essentiels : Fraîcheur, distribution, volume, schéma et lignée. Ensemble, ces piliers garantissent le bon fonctionnement des pipelines de données et l'exactitude, l'exhaustivité et la fiabilité des données.
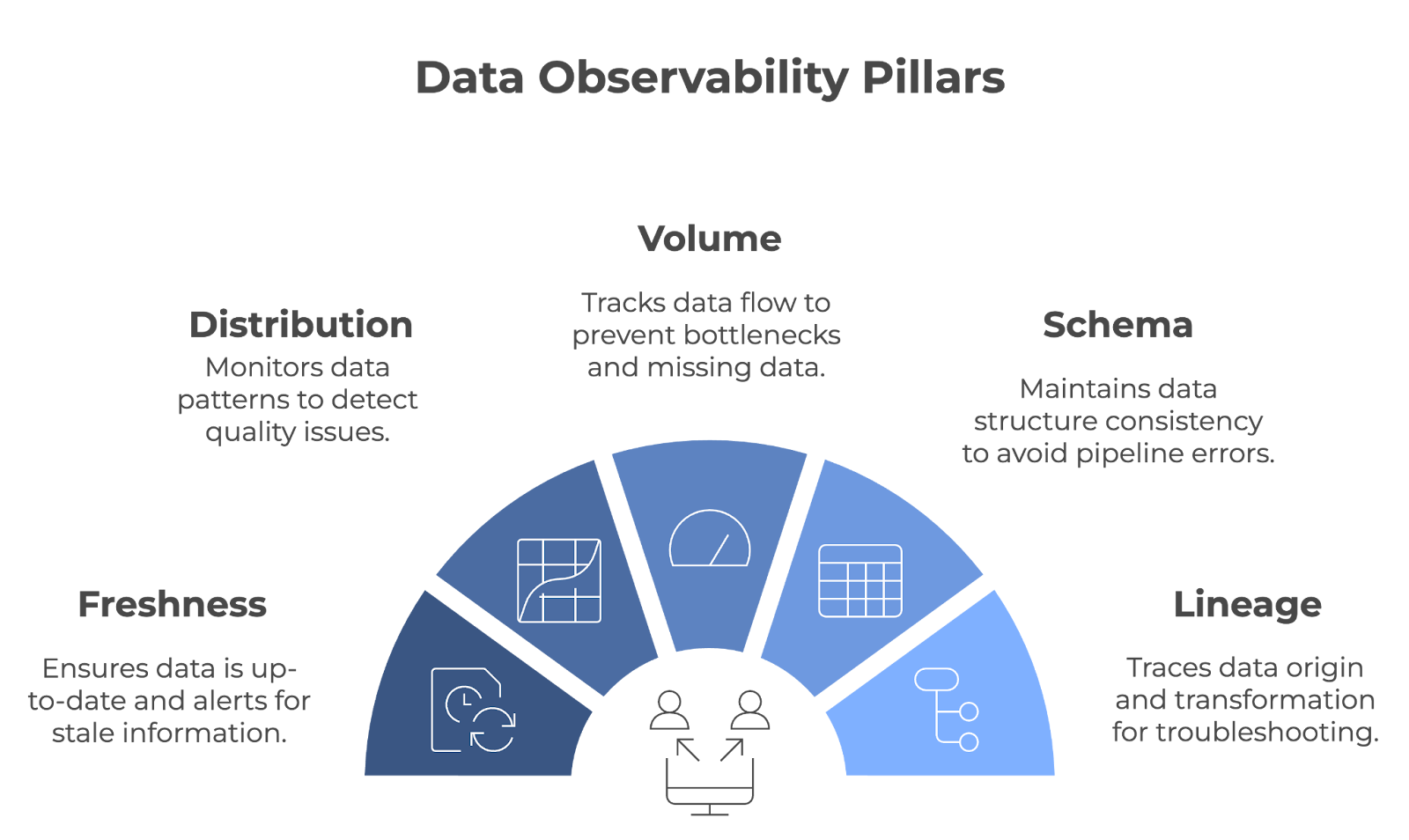
Les cinq piliers de l'observabilité des données. Image par l'auteur (créée avec napkin.ai)
Examinons chaque pilier en détail !
La fraîcheur vous indique dans quelle mesure vos données sont à jour. Il cursus la date de la dernière mise à jour des données et vous alerte si elles deviennent périmées. Ce pilier est important pour les équipes qui s'appuient sur des données en temps réel ou quasi réel pour prendre des décisions.
La distribution fait référence au cursus et aux valeurs spécifiques de vos données (par exemple, la moyenne, la médiane, l'écart type, etc.). Le contrôle de ces valeurs permet de repérer les anomalies, qui peuvent être le signe de problèmes de qualité des données. Des contrôles réguliers de la distribution garantissent la cohérence des données dans le temps.
Le volume de données fait référence à la quantité de données qui circulent dans un système. Ce paramètre fait l'objet d'un cursus afin de s'assurer que la quantité de données attendue est ingérée et traitée sans baisse ni pic inattendus. Le volume de données est contrôlé afin de détecter rapidement les problèmes tels que les données manquantes ou les goulets d'étranglement dans le pipeline.
L'observabilité du schéma permet de suivre la structure des données - il est important qu'elle reste cohérente dans le temps. Lorsque votre schéma change de manière inattendue, cela peut perturber vos pipelines de données et entraîner des erreurs de traitement.
Lineage provides une vision claire de l'origine de vos données, de leur transformation et de leur destination finale. Il s'agit d'un élément clé pour le dépannage et le maintien de la qualité des données dans des systèmes complexes. Lorsque des problèmes surviennent, le lignage vous permet de remonter les points de données à travers le pipeline pour trouver la source du problème.
Tout au long de cet article, nous avons fait allusion à l'observabilité des données en surveillant activement les pipelines de données, en envoyant des alertes en cas de problème et en aidant les équipes à trouver rapidement la cause première des problèmes.
Voyons comment chaque élément fonctionne en pratique !
Les outils d'observabilité des données détectent les erreurs en surveillant constamment les pipelines de données. Ils peuvent curer de nombreux aspects d'un pipeline de données, mais sont généralement configurés pour se concentrer sur des mesures spécifiques ou sur les domaines les plus critiques pour les besoins de l'organisation.
Ces outils s'intègrent souvent à des technologies comme Apache Kafka, Apache Airflow, ou à des services basés sur le cloud comme AWS Glue ou Google Cloud Dataflow pour recueillir des informations à différentes étapes du pipeline. Par exemple :
Quel est l'intérêt de détecter rapidement les problèmes si personne n'est informé ? Les outils d'observabilité des données alertent automatiquement les bonnes personnes et prennent parfois des mesures sur la base de configurations prédéfinies.
Ces alertes sont souvent configurées en fonction de seuils ou de déclencheurs, tels que des enregistrements manquants, des modifications de schéma ou des retards de données inattendus. Par exemple :
L'analyse des causes profondes est un processus systématique visant à identifier la raison fondamentale d'un problème ou d'une question. Dans le contexte de l'observabilité des données, il s'agit de remonter à l'origine d'un problème de données plutôt que de se contenter d'en traiter les symptômes.
Les plateformes d'observabilité des données offrent souvent de riches capacités de diagnostic, en s'intégrant à des systèmes de gestion des journaux comme Elasticsearch ou à des plateformes de surveillance comme Prometheus et Grafana pour faire apparaître des détails granulaires. Par exemple :
Souvent, les ingénieurs de données mettent en œuvre les fonctions d'observabilité en interne. Cependant, il existe aujourd'hui plusieurs outils puissants qui permettent aux équipes de mettre en œuvre efficacement l'observabilité des données prête à l'emploi. Jetons un coup d'œil aux plus populaires d'entre eux !
Monte Carlo est une puissante plateforme d'observabilité des données conçue pour aider les équipes à maintenir la santé de leurs systèmes de données. Créée par une équipe d'anciens ingénieurs d'entreprises telles que LinkedIn et Facebook, la plateforme est née de la volonté de résoudre le problème croissant de l'indisponibilité des données. Il prévoit :
Monte Carlo s'intègre à des outils tels que Snowflake, dbt et Looker, ce qui le rend idéal pour les équipes travaillant dans des écosystèmes de données modernes.
Bigeye a été fondée en 2020 par un groupe d'ingénieurs en données. Il s'agit d'une plateforme d'observabilité des données conçue pour maintenir la qualité et la fiabilité des données tout au long de leur cycle de vie.
La plateforme se concentre sur l'automatisation du contrôle de la qualité des données, la détection des anomalies et la résolution des problèmes liés aux données afin d'assurer la fluidité des flux de données et de veiller à ce que les parties prenantes puissent s'appuyer sur des données exactes pour prendre leurs décisions. Ses caractéristiques sont les suivantes :
Databand est une plateforme d'observabilité des données qui permet de gérer de manière proactive la santé des données en offrant une visibilité sur les pipelines de données. Fondée en 2019, Databand a été créée pour répondre à la complexité et à l'échelle croissantes de l'environnement de données.
La plateforme a été conçue pour aider les ingénieurs en données à détecter les problèmes en temps réel, à comprendre le flux de données et à garantir l'exactitude des ensembles de données dans l'ensemble de l'organisation. Ses caractéristiques sont les suivantes :
Datadog est une plateforme de surveillance et d'analyse basée sur le cloud qui offre une observabilité en temps réel. Fondée en 2010 par Olivier Pomel et Alexis Lê-Quôc, Datadog a été créée pour répondre à la complexité des applications cloud modernes.
Datadog est idéal pour les entreprises qui ont besoin d'une surveillance complète de différents systèmes. La plateforme est particulièrement utile pour les entreprises natives du cloud ou celles qui disposent de systèmes complexes et distribués. Ses caractéristiques sont les suivantes :
|
Outil |
Domaines d'intervention |
Intégrations |
Idéal pour |
|
Monte Carlo |
Qualité des données, détection des anomalies, lignage des données |
Snowflake, dbt, Looker |
Les écosystèmes de données modernes ont besoin d'une observabilité automatisée |
|
Bigeye |
Contrôle de la qualité des données, détection des anomalies, interface utilisateur conviviale |
Slack, Jira, les principaux lacs de données et entrepôts. |
Industries ayant des besoins importants en matière de fiabilité des données (par exemple, finance, soins de santé) |
|
Bande de données |
Surveillance du pipeline, analyse de l'impact des données, alertes en temps réel |
Apache Airflow, Spark, BigQuery, Kafka, etc. |
Équipes gérant des flux de données complexes et volumineux |
|
Datadog |
Surveillance unifiée, alertes en temps réel, prise en charge cloud-native. |
AWS, Google Cloud, Docker, Kubernetes, etc. |
Entreprises avec des systèmes distribués ou des configurations cloud-natives. |
Pour mettre en œuvre efficacement l'observabilité des données, concentrez-vous sur les meilleures pratiques suivantes :
Concentrez-vous d'abord sur la surveillance des pipelines de données les plus critiques, ceux dont l'impact sur l'entreprise est le plus important. Vous pouvez limiter les risques en veillant à ce que ces pipelines soient en bonne santé tout en mettant progressivement en place une stratégie d'observabilité plus large pour d'autres pipelines.
Des mesures clairement définies sont essentielles pour évaluer la santé des données - vous devez savoir à quoi ressemble le succès (et l'échec). Ces mesures doivent être alignées sur les objectifs généraux de l'entreprise afin de refléter ce qui compte vraiment. Cette clarté vous aidera à rester concentré et à évaluer efficacement leurs progrès.
Les systèmes de surveillance et d'alerte réduisent les interventions manuelles et améliorent les temps de réponse. Les systèmes automatisés peuvent détecter les problèmes à un stade précoce et déclencher des actions immédiates pour éviter l'interruption des données. Faites de l'automatisation une priorité.
L'intégration de l'observabilité dans vos processus quotidiens vous permet de réagir plus rapidement et plus efficacement, rendant ainsi la gestion des données plus proactive et moins réactive.
L'observabilité des données est essentielle pour créer des pipelines de données fiables et de haute qualité. En surveillant en permanence les aspects critiques des données, les équipes peuvent identifier et traiter les problèmes avant qu'ils n'aient un impact sur les résultats de l'entreprise. Alors que les données continuent de guider les décisions des entreprises, l'observabilité restera un élément essentiel de la gestion et de l'optimisation des pipelines de données.
Pour bien saisir l'importance de l'observabilité et la mettre en œuvre efficacement, il est nécessaire de comprendre des concepts connexes tels que l'architecture, la gouvernance et la gestion des données. Si vous cherchez à approfondir vos connaissances :
Enfin, si vous êtes nouveau dans le domaine, Comprendre l'ingénierie des données est un excellent point de départ pour explorer la façon dont les pipelines de données sont conçus et maintenus !
Apprenez-en plus sur la gouvernance des données avec ces cours !
Cursus
Cours
Cours