
Track
Data Governance Fundamentals
10 hr
Data observability is built upon five key pillars: Freshness, distribution, volume, schema, and lineage. Together, these pillars ensure data pipelines run smoothly and that data remains accurate, complete, and reliable.
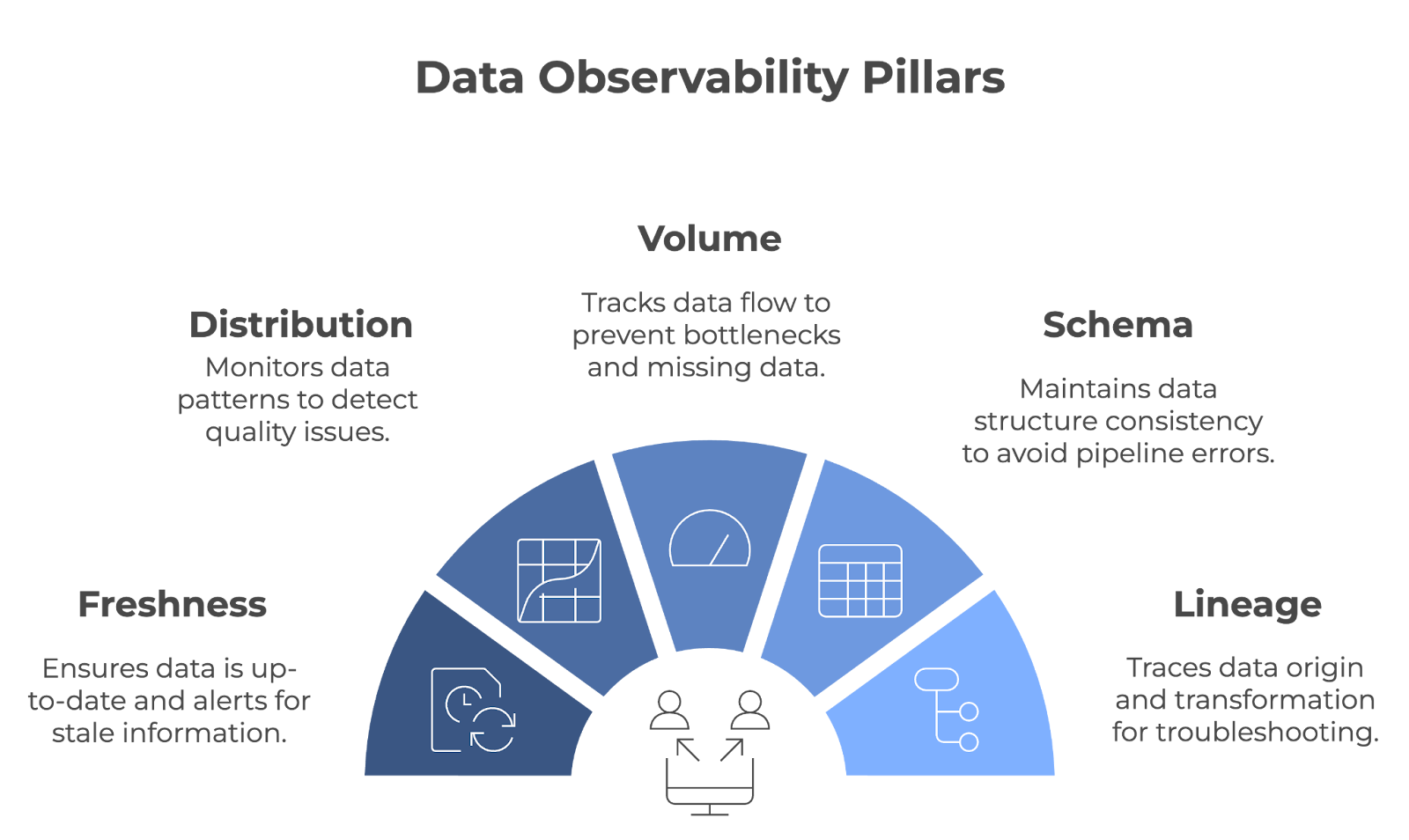
The five pillars of data observability. Image by Author (created with napkin.ai)
Let’s examine each pillar in detail!
Freshness tells you how up-to-date your data is. It tracks when data was last updated and alerts you if it becomes stale. This pillar is important for teams relying on real-time or near-real-time data to make decisions.
Distribution refers to tracking the patterns and specific values in your data (e.g., mean, median, standard deviation, etc.). Monitoring these values helps to spot when something looks off, which may be a sign of data quality issues. Regular distribution checks guarantee data remains consistent over time.
Data volume refers to the amount of data flowing through a system. This metric is tracked to ensure the expected amount of data is being ingested and processed without any unexpected drops or spikes. Data volume is monitored to detect issues like missing data or pipeline bottlenecks quickly.
Schema observability tracks the structure of the data—it’s important that it remains consistent over time. When your schema changes unexpectedly, it can break your data pipelines and lead to errors in processing.
Lineage provides a clear view of where your data comes from, how it’s transformed, and where it ends up. This is key for troubleshooting and maintaining data quality in complex systems. When issues arise, lineage allows you to trace data points back through the pipeline to find the source of the problem.
Throughout this article, we have alluded to data observability actively monitoring data pipelines, sending alerts when issues arise, and helping teams quickly find the root cause of problems.
Let’s explore how each component works in practice!
Data observability tools notice errors by constantly monitoring the data pipelines. They can track many aspects of a data pipeline but are typically configured to focus on specific metrics or areas most critical to the organization’s needs.
These tools often integrate with technologies like Apache Kafka, Apache Airflow, or cloud-based services such as AWS Glue or Google Cloud Dataflow to gather insights at various stages of the pipeline. For example:
What is the point of detecting issues fast if nobody is informed? Data observability tools automatically alert the right people and sometimes take action based on predefined configurations.
These alerts are often configured based on thresholds or triggers, such as missing records, schema changes, or unexpected data delays. For instance:
Root cause analysis is a systematic process to identify the fundamental reason behind a problem or issue. In the context of data observability, it involves tracing a data problem back to its origin rather than just addressing its symptoms.
Data observability platforms often provide rich diagnostic capabilities, integrating with log management systems like Elasticsearch or monitoring platforms like Prometheus and Grafana to surface granular details. For example:
Often, data engineers implement observability features in-house. However, several powerful tools are available today that enable teams to implement out-of-the-box data observability effectively. Let’s take a look at the most popular ones!
Monte Carlo is a powerful data observability platform designed to help teams maintain the health of their data systems. Created by a team of former engineers from companies like LinkedIn and Facebook, the platform was built out of a desire to solve the growing challenge of data downtime. It provides:
Monte Carlo integrates with tools like Snowflake, dbt, and Looker, making it ideal for teams working in modern data ecosystems.
Bigeye was founded in 2020 by a group of data engineers. It's a data observability platform designed to maintain the quality and reliability of data throughout its lifecycle.
The platform focuses on automating data quality monitoring, anomaly detection, and data issue resolution to keep data pipelines flowing smoothly and ensure that stakeholders can rely on accurate data for their decision-making. Its features include:
Databand is a data observability platform to proactively manage data health by providing visibility into data pipelines. Founded in 2019, Databand was created to address the data environment's increasing complexity and scale.
The platform was built to help data engineers detect issues in real time, understand the flow of data, and guarantee the accuracy of datasets across the organization. Its features are:
Datadog is a cloud-based monitoring and analytics platform that provides real-time observability. Founded in 2010 by Olivier Pomel and Alexis Lê-Quôc, Datadog was created to address the complexity of modern cloud applications.
Datadog is ideal for companies that need comprehensive monitoring across various systems. The platform is especially useful for cloud-native companies or those with complex, distributed systems. Its features include:
|
Tool |
Focus areas |
Integrations |
Ideal for |
|
Monte Carlo |
Data quality, anomaly detection, data lineage |
Snowflake, dbt, Looker |
Modern data ecosystems needing automated observability |
|
Bigeye |
Data quality monitoring, anomaly detection, user-friendly UI |
Slack, Jira, major data lakes, and warehouses |
Industries with high data reliability needs (e.g., finance, healthcare) |
|
Databand |
Pipeline monitoring, data impact analysis, real-time alerts |
Apache Airflow, Spark, BigQuery, Kafka |
Teams managing high-volume, complex data streams |
|
Datadog |
Unified monitoring, real-time alerting, cloud-native support |
AWS, Google Cloud, Docker, Kubernetes |
Companies with distributed systems or cloud-native setups |
To effectively implement data observability, focus on these best practices:
Focus on monitoring the most critical data pipelines first—those with the most significant business impact. You can mitigate risk by making sure these pipelines are healthy while gradually building a broader observability strategy across other pipelines.
Clearly defined metrics are key to evaluating data health—you must know what success (and failure) looks like. These metrics must be aligned with the overall company goals to reflect what truly matters. This clarity will help you stay focused and evaluate their progress effectively.
Monitoring and alerting systems reduce manual intervention and improve response times. Automated systems can detect issues early and trigger immediate actions to prevent data downtime. Make automation a priority.
Embedding observability into your daily processes enables you to respond faster and more effectively, thus making data management more proactive and less reactive.
Data observability is key for building high-quality, reliable data pipelines. By continuously monitoring critical aspects of data, teams can identify and address issues before they impact business outcomes. As data continues to drive business decisions, observability will remain a core element for managing and optimizing data pipelines.
To fully grasp the importance of observability and effectively implement it, it’s necessary to understand related concepts like data architecture, governance, and management. If you're looking to deepen your knowledge:
Finally, if you’re new to the field, Understanding Data Engineering is a great starting point to explore how data pipelines are designed and maintained!
Learn more about data governance with these courses!
Track
Course
Course
blog
Kurtis Pykes
15 min
blog
Andrea Valenzuela
12 min
blog
Kevin Babitz
7 min
blog
Srujana Maddula
9 min
blog
Tim Lu
15 min
Tutorial
Anneleen Rummens

