
Curso
Trabajar con la API de OpenAI
3 h
141.6K
OpenAI acaba de publicar GPT-4.1, una nueva familia de modelos creados específicamente para tareas de codificación. Estoy tan confuso como todos los demás sobre el salto de denominación de GPT-4.5 a GPT-4.1, pero por suerte, los puntos de referencia no retroceden también, al contrario.
El despliegue comenzó el 14 de abril con acceso exclusivo a la API. Después, el 14 de mayo, OpenAI empezó a introducir GPT-4.1 en la aplicación ChatGPT. Los usuarios de Free-tier no podrán elegir manualmente la GPT-4.1, pero ahora se benefician de la GPT-4.1 Mini como nueva opción por defecto, que sustituye a la GPT-4o Mini.
GPT-4.1 está disponible en tres tamaños: GPT-4.1, GPT-4.1 Mini y GPT-4.1 Nano. Los tres admiten hasta 1 millón de tokens de contexto y aportan notables mejoras en la codificación, el seguimiento de instrucciones y la comprensión de textos largos. También son más baratos y rápidos que los anteriores.
En este artículo, te explicaré qué puede hacer cada modelo, cómo se compara con la GPT-4o y la GPT-4.5, y cuál es su posición en las pruebas de rendimiento y en el uso en el mundo real.
Mantenemos a nuestros lectores al día de lo último en IA enviándoles The Median, nuestro boletín gratuito de los viernes que desglosa las noticias clave de la semana. Suscríbete y mantente alerta en sólo unos minutos a la semana:
El conjunto de modelos GPT-4.1 consta de tres modelos: GPT-4.1, GPT-4.1 Mini y GPT-4.1 Nano. Están dirigidos a programadores que necesitan un mejor rendimiento, un contexto más largo y un seguimiento de las instrucciones más predecible. Cada modelo admite hasta 1 millón de tokens de contexto, un gran salto desde el límite de 128K de versiones anteriores como GPT-4o.
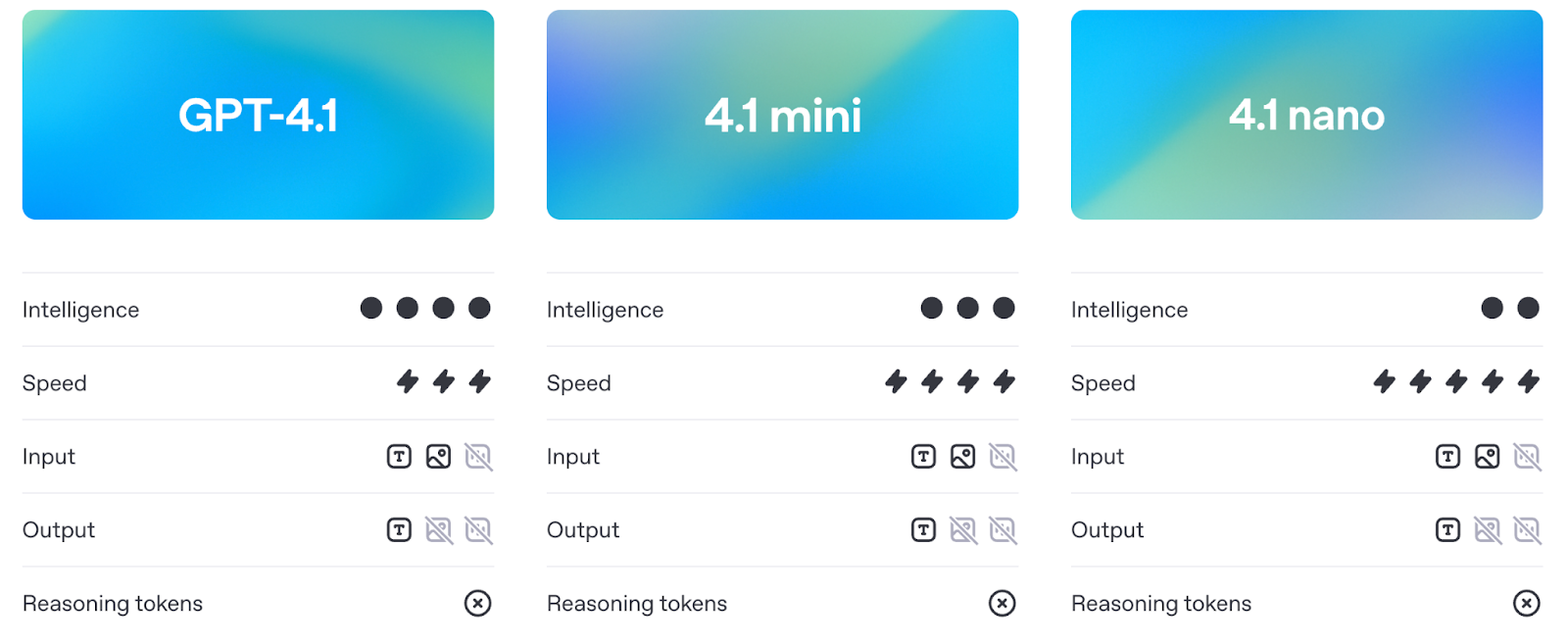
Fuente: OpenAI
A pesar de la arquitectura compartida, cada versión está adaptada a casos de uso diferentes. Exploremos cada uno de ellos con más detalle.
Este es el modelo estrella. Si quieres el mejor rendimiento global en tareas de codificación, seguimiento de instrucciones y contexto largo, éste es el que debes utilizar. Está diseñado para gestionar flujos de trabajo de codificación complejos o procesar grandes documentos con una sola solicitud.
En las pruebas comparativas, supera a GPT-4o en ingeniería de software del mundo real (SWE-bench), seguimiento de instrucciones (MultiChallenge) y razonamiento de contexto largo (MRCR, Graphwalks). También respeta mucho mejor la estructura y el formato: piensa en respuestas XML, instrucciones ordenadas y restricciones negativas como "no respondas a menos que...".
También puedes ajustar GPT-4.1 desde el día de su lanzamiento, lo que lo abre a más casos de uso en producción en los que importa el control sobre el tono, el formato o el conocimiento del dominio.
GPT-4.1 Mini es la opción intermedia, que ofrece casi las mismas capacidades que el modelo completo, pero con menor latencia y coste. Iguala o supera a GPT-4o en muchos puntos de referencia, como el seguimiento de instrucciones y el razonamiento basado en imágenes.
Es probable que se convierta en la opción por defecto para muchos casos de uso: lo bastante rápido para las herramientas interactivas, lo bastante inteligente para seguir instrucciones detalladas y bastante más barato que el modelo completo.
Al igual que la versión completa, admite 1 millón de tokens de contexto y ya está disponible para su ajuste.
Nano es el más pequeño, rápido y barato de todos. Está pensado para tareas como autocompletar, clasificar y extraer información de grandes documentos. A pesar de ser ligero, sigue soportando la ventana contextual completa de 1 millón de tokens.
También es el modelo más pequeño, rápido y barato de OpenAI, con sólo unos 10 céntimos por millón de tokens. No tienes toda la capacidad de razonamiento y planificación de los modelos más grandes, pero para determinadas tareas, eso no es lo importante.
Antes de entrar en los puntos de referencia (que trataremos en detalle en la siguiente sección), merece la pena comprender en qué se diferencia en la práctica la GPT-4.1 de la GPT-4o y de la GPT-4.5.
GPT-4.1 mejora las capacidades de GPT-4o, manteniendo la latencia más o menos en el mismo rango. En la práctica, significa que los programadores obtienen ahora un mayor rendimiento sin pagar un coste en capacidad de respuesta.
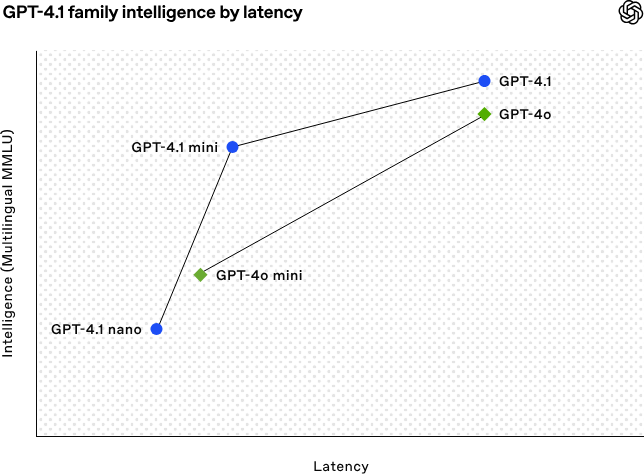
Fuente: OpenAI
Desglosemos el gráfico anterior:
La GPT-4.5, en cambio, siempre se posicionó como un avance de investigación. Aunque tenía un razonamiento y una calidad de escritura sólidos, conllevaba más gastos generales. La GPT-4.1 ofrece resultados similares o mejores en pruebas de referencia clave, pero es más barata y responde mejor, lo suficiente como para que OpenAI planee retirar por completo la 4.5 a mediados de julio para liberar más GPU.
Los tres modelos de GPT-4.1 -estándar, Mini y Nano- admiten hasta 1 millón de fichas de contexto. Eso es más de 8 veces lo que ofrecía GPT-4o.
Esta capacidad de contexto largo permite casos de uso prácticos como procesar registros enteros, indexar repositorios de código, gestionar flujos de trabajo jurídicos multidocumento o analizar transcripciones largas, todo ello sin necesidad de trocear o resumir previamente.
La GPT-4.1 también marca un cambio en la fiabilidad con la que los modelos siguen las instrucciones. Maneja preguntas complejas que implican pasos ordenados, restricciones de formato y condiciones negativas (como negarse a responder si el formato es incorrecto).
En la práctica, eso significa dos cosas: menos tiempo dedicado a elaborar avisos, y menos tiempo limpiando el resultado después.
La GPT-4.1 muestra progresos en cuatro áreas fundamentales: codificación, seguimiento de instrucciones, comprensión de textos largos y tareas multimodales.
En SWE-bench Verified -una prueba que introduce el modelo en un código real y le pide que complete los problemas de extremo a extremo-, GPT-4.1 obtiene una puntuación del 54,6%. Esto supone un aumento del 33,2% para la GPT-4o y del 38% para la GPT-4,5. También es muy impresionante que GPT-4.1 obtenga mejores resultados que o1 y o3-mini.
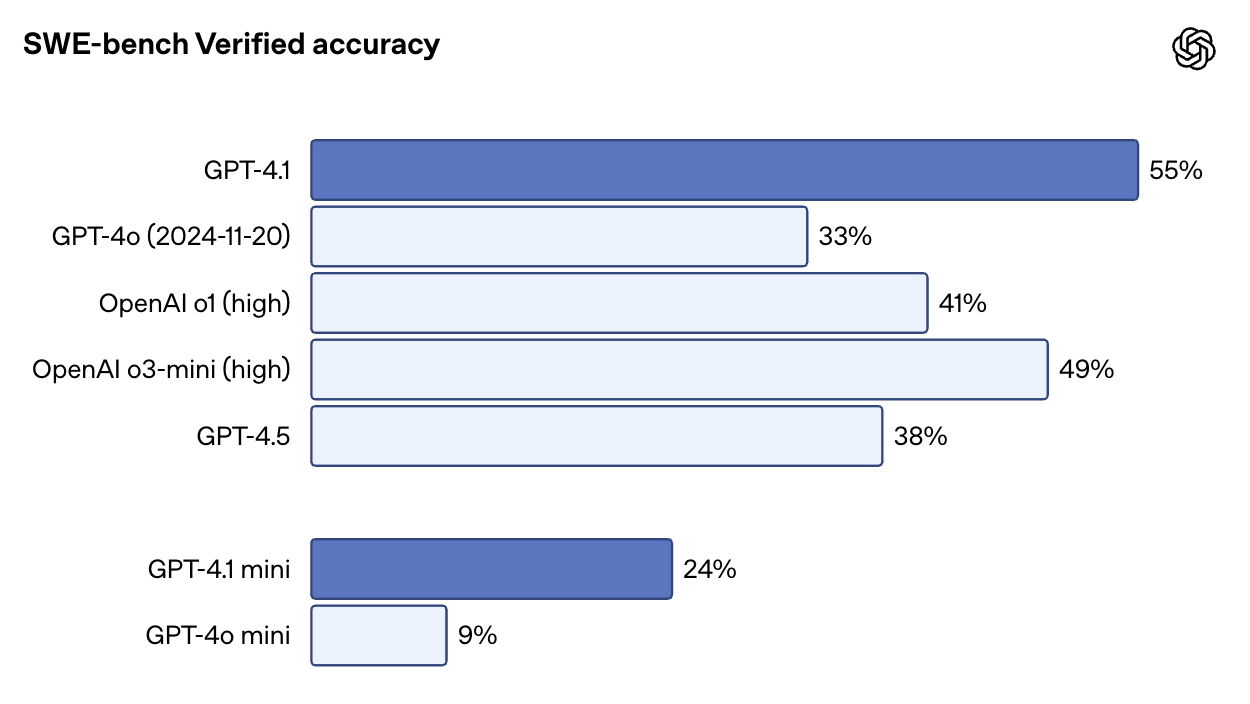
Fuente: OpenAI
También duplica con creces el rendimiento de GPT-4o en la prueba comparativa de diferencias políglota de Aider, alcanzando un 52,9% de precisión en las diferencias de código en múltiples lenguajes y formatos. GPT-4.5 obtuvo un 44,9% en la misma tarea. La GPT-4.1 también es más precisa: en las evaluaciones internas, las ediciones de código extrañas bajaron del 9% (GPT-4o) a sólo el 2%.
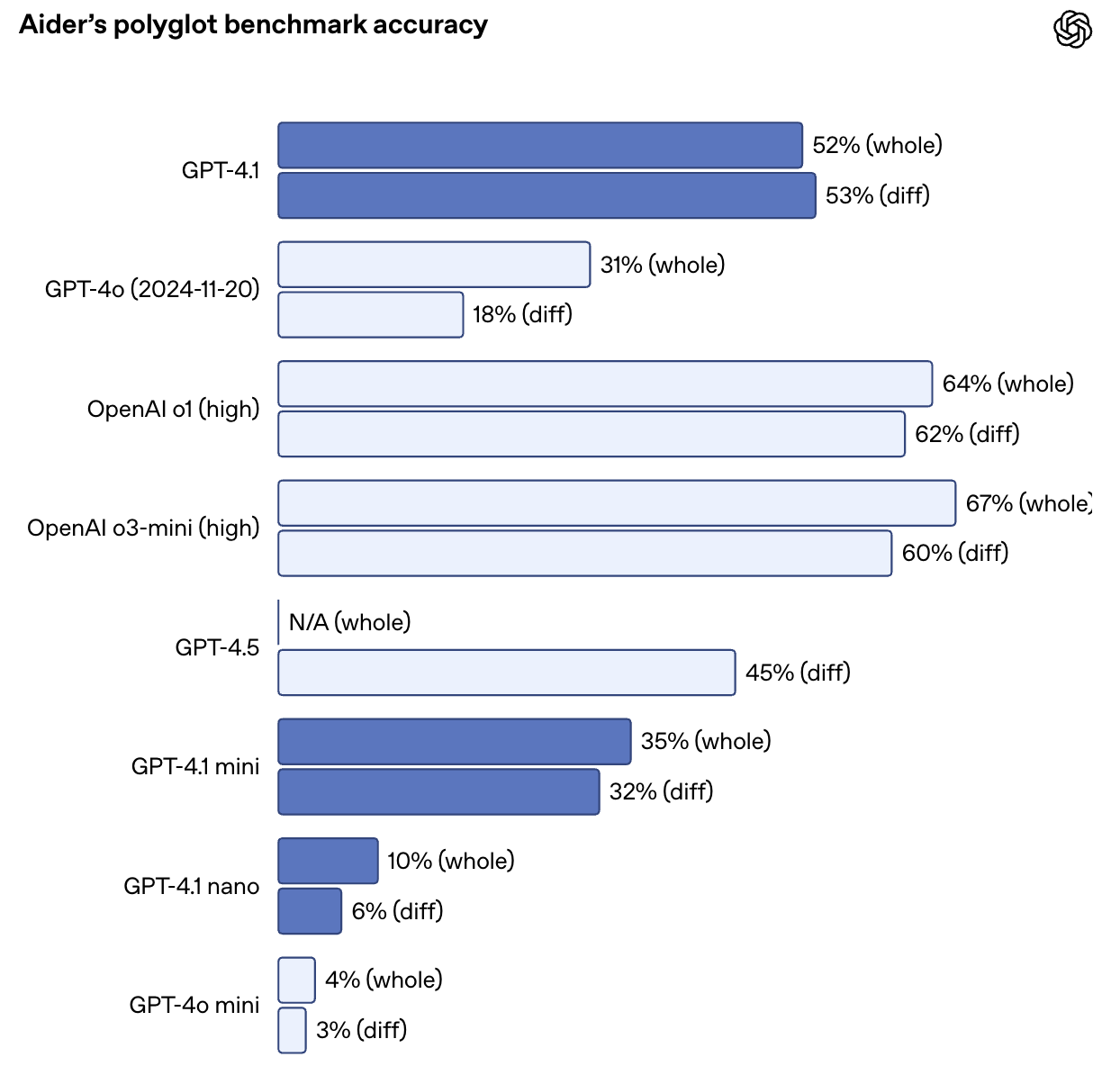
Fuente: OpenAI
Aparte de las puntuaciones de los bancos de pruebas, la demostración de codificación del frontend que ofreció OpenAI es un buen ejemplo visual del rendimiento superior de GPT-4.1. El equipo de OpenAI pidió a ambos modelos que crearan la misma aplicación de flashcards, y los evaluadores humanos prefirieron el resultado de GPT-4.1 el 80% de las veces.
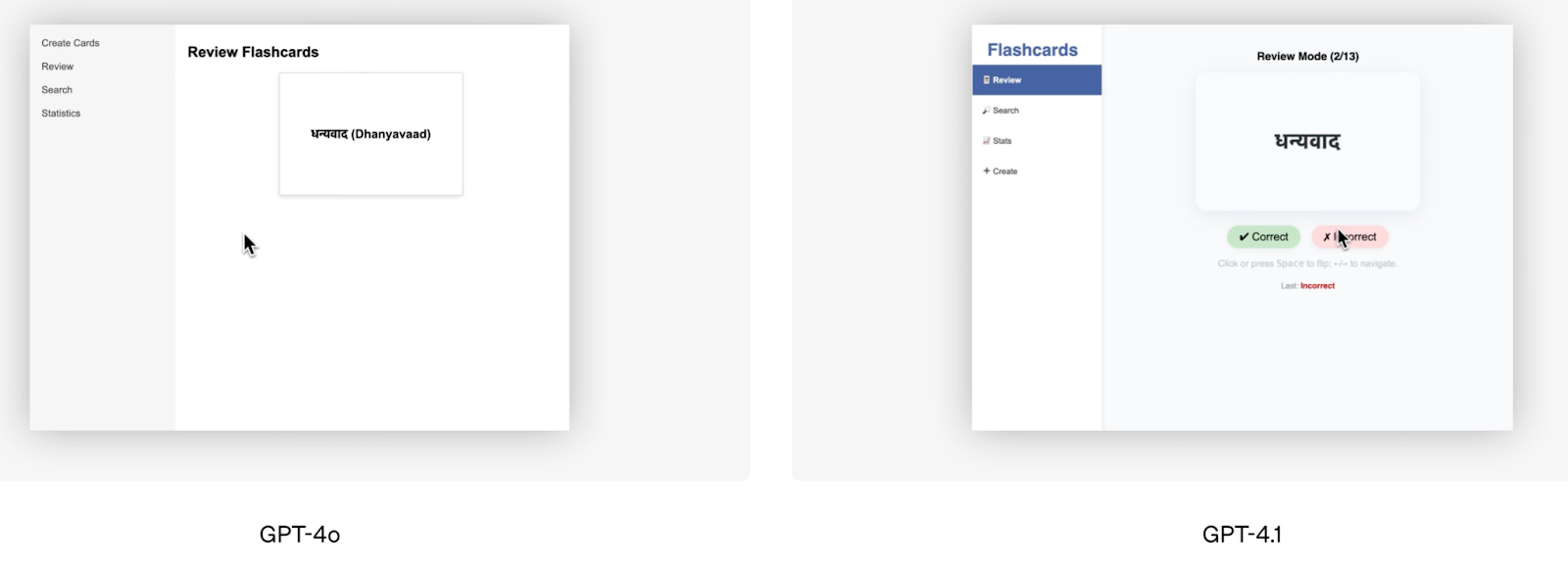
Fuente: OpenAI
Windsurf, uno de los probadores alfa, informó de una mejora del 60% en su propio punto de referencia interno de codificación. Otra empresa, Qodo, probó GPT-4.1 en pull requests reales de GitHub y descubrió que producía mejores sugerencias el 55% de las veces, con menos ediciones irrelevantes o demasiado verbosas.
La GPT-4.1 es más literal -y más fiable- cuando se trata de seguir instrucciones, especialmente en tareas que implican varios pasos, reglas de formato o condiciones. En la evaluación interna de seguimiento de instrucciones de OpenAI (subconjunto duro), GPT-4.1 obtuvo una puntuación del 49,1%, frente a sólo el 29,2% de GPT-4o. GPT-4.5 está ligeramente por delante aquí con un 54%, pero la diferencia entre 4.1 y 4o es significativa.

Fuente: OpenAI
En el Desafío Múltiple, que comprueba si un modelo puede seguir instrucciones de varios giros y recordar restricciones introducidas anteriormente en la conversación, GPT-4.1 obtiene un 38,3%, frente al 27,8% de GPT-4o. Y en IFEval, que comprueba el cumplimiento de unos requisitos de salida claramente especificados, GPT-4.1 alcanza el 87,4%, una sólida mejora sobre el 81% de GPT-4o.
En la práctica, esto significa que GPT-4.1 se ciñe mejor a los pasos ordenados, rechaza entradas malformadas y responde en el formato que le pediste, especialmente en salidas estructuradas como XML, YAML o markdown. Esto también facilita la creación de flujos de trabajo de agentes fiables, sin muchos reintentos puntuales.
Los tres modelos de GPT-4.1 -estándar, Mini y Nano- admiten hasta 1 millón de fichas de contexto. Esto supone un aumento de 8 veces respecto a la GPT-4o, que alcanzaba un máximo de 128K. Igual de importante: no hay ningún coste adicional por utilizar esa ventana contextual. Tiene el mismo precio que cualquier otro aviso.
Pero, ¿pueden los modelos utilizar realmente todo ese contexto? En la evaluación de la aguja en un pajar de OpenAI, GPT-4.1 encontró con fiabilidad contenido insertado en cualquier punto -inicio, medio o final- dentro de la entrada completa de 1M de tokens.
Fuente: OpenAI
Graphwalks, un punto de referencia que pone a prueba el razonamiento multisalto en contextos largos, sitúa a GPT-4.1 en el 61,7%, un sólido salto desde el 41,7% de GPT-4o, aunque todavía por debajo de GPT-4.5, con un 72,3%.
Estas mejoras también se aprecian en las pruebas reales. Thomson Reuters experimentó un aumento del 17 en el análisis jurídico multidocumento utilizando GPT-4.1, mientras que Carlyle informó de una mejora del 50% en la extracción de datos granulares de densos informes financieros.
En las tareas multimodales, GPT-4.1 también progresa. Obtuvo un 72,0% en la prueba Video-MME, que consiste en responder a preguntas sobre vídeos de 30-60 minutos sin subtítulos, frente al 65,3% de la GPT-4o.
En puntos de referencia con muchas imágenes, como MMMU, alcanzó el 74,8%, frente al 74,8% de MMMU. 68,7% para la GPT-4o. En MathVista, que incluye tablas, gráficos y visuales matemáticos, GPT-4.1 alcanzó el 72,2%.
Una sorpresa: GPT-4.1 Mini funciona casi tan bien como la versión completa en algunas de estas pruebas. En MathVista, por ejemplo, superó ligeramente a GPT-4.1 con un 73,1%. Eso lo convierte en una opción convincente para casos de uso que combinan velocidad con avisos con mucha visión.
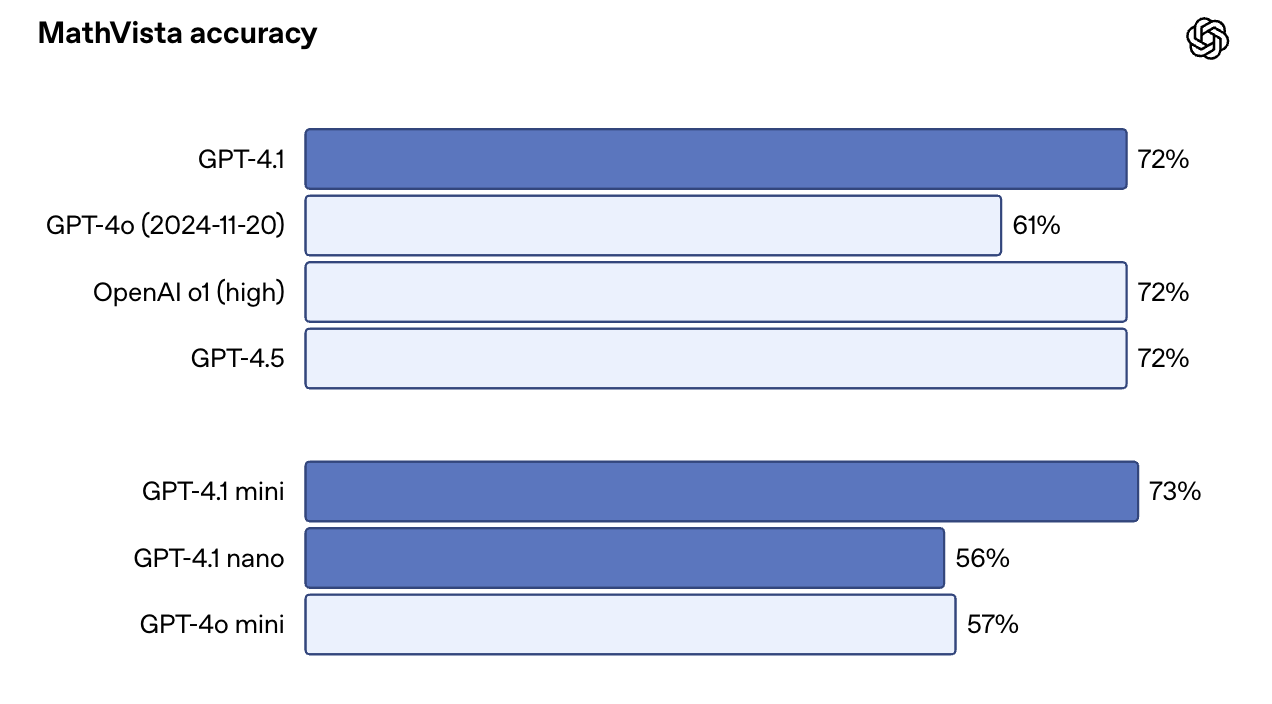
Fuente: OpenAI
Ahora puedes acceder a GPT-4.1 y GPT-4.1 Mini directamente en la aplicación ChatGPT, no sólo a través de la API. Los suscriptores Plus, Pro y Team pueden seleccionar manualmente GPT-4.1 en el menú del modelo, mientras que los usuarios gratuitos vuelven automáticamente a GPT-4.1 Mini, sustituyendo a GPT-4o Mini como predeterminado entre bastidores. Se espera que los planes de Empresa y Educación reciban acceso en las próximas semanas.
Para los programadores, la API de OpenAI y Playground siguen siendo compatibles con las tres variantes: GPT-4.1, GPT-4.1 Mini y GPT-4.1 Nano. Ésta sigue siendo la mejor forma de probar los avisos, explorar el comportamiento en contextos largos y comparar modelos antes de integrarlos en la producción.
Si trabajas con documentos largos -piensa en registros, PDF, expedientes legales o artículos académicos- puedes enviar hasta 1 millón de tokens en una sola llamada, sin necesidad de parámetros especiales. Tampoco hay un aumento de precios por contexto largo: los costes de los tokens son fijos, independientemente del tamaño de la entrada.
Puedes ajustar con precisión las tres variantes de GPT-4.1. Eso abre la puerta a instrucciones personalizadas, vocabulario específico del dominio o salidas específicas del tono. Observa que el ajuste fino tiene una prización ligeramente mayor:
|
Modelo |
Entrada |
Entrada en caché |
Salida |
Formación |
|
GPT-4.1 |
3,00 $ / 1M de fichas |
0,75 $ / 1M de fichas |
12,00 $ / 1M de fichas |
25,00 $ / 1M de fichas |
|
GPT-4.1 Mini |
0,80 $ / 1M de fichas |
0,20 $ / 1M de fichas |
3,20 $ / 1M de fichas |
5,00 $ / 1M de fichas |
|
GPT-4.1 Nano |
0,20 $ / 1M de fichas |
0,05 $ / 1M de fichas |
0,80 $ / 1M de fichas |
1,50 $ / 1M de fichas |
Si yhas ajustado previamente los modelos GPT-3.5 o GPT-4, el proceso sigue siendo prácticamente el mismo: sólo tienes que elegir la base más nueva. Si quieres saber más, te recomiendo este tutorial sobre ajuste fino de GPT-4o mini.
Una de las novedades más bienvenidas de la GPT-4.1 es que no sólo es más inteligente, sino también más barata. OpenAI dice que el objetivo era hacer que estos modelos fueran más utilizables en flujos de trabajo más reales, y eso se nota en cómo está estructurado el precio.
He aquí cómo se valoran los tres modelos para la inferencia:
|
Modelo |
Entrada |
Entrada en caché |
Salida |
Blended Avg. Coste |
|
GPT-4.1 |
2,00 $ / 1M de fichas |
0,50 $ / 1M de fichas |
8,00 $ / 1M de fichas |
$1.84 |
|
GPT-4.1 Mini |
0,40 $ / 1M de fichas |
0,10 $ / 1M de fichas |
1,60 $ / 1M de fichas |
$0.42 |
|
GPT-4.1 Nano |
0,10 $ / 1M de fichas |
0,025 $ / 1M de fichas |
0,40 $ / 1M de fichas |
$0.12 |
*La cifra "mixta" se basa en la suposición de OpenAI de los ratios típicos de entrada/salida.
GPT-4.1 viene con una generación de código más fiable, mejor seguimiento de instrucciones, verdadero procesamiento de contexto largo e iteración más rápida.
La denominación puede resultar confusa, pero los modelos en sí son claramente más capaces que los anteriores. También son más asequibles -y más utilizables-, especialmente en entornos de producción donde la latencia, el coste y la previsibilidad son importantes.
Si hoy trabajas con GPT-4o, merece la pena que pruebes GPT-4.1.
Aprende IA con estos cursos
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Abid Ali Awan
9 min
blog
Josep Ferrer
8 min
Tutorial
Arunn Thevapalan
Tutorial
Moez Ali
Tutorial
Zoumana Keita


