
Kurs
Arbeiten mit der OpenAI-API
3 Std.
141.6K
OpenAI hat vor kurzem GPT-4.1 veröffentlicht, eine neue Familie von Modellen, die speziell für Codieraufgaben entwickelt wurden. Ich bin genauso verwirrt wie alle anderen über den Namenssprung von GPT-4.5 zu GPT-4.1, aber zum Glück gehen die Benchmarks auch nicht zurück - im Gegenteil.
Der Rollout begann am 14. April mit einem reinen API-Zugang. Am 14. Mai begann OpenAI damit, GPT-4.1 in die ChatGPT-App zu integrieren. Free-Tier-Nutzer können GPT-4.1 nicht manuell auswählen, aber sie profitieren jetzt von GPT-4.1 Mini als neuem Standardfallback, der GPT-4o Mini ersetzt.
GPT-4.1 gibt es in drei Größen: GPT-4.1, GPT-4.1 Mini und GPT-4.1 Nano. Alle drei unterstützen bis zu 1 Million Kontext-Token und bringen bemerkenswerte Verbesserungen beim Kodieren, Befolgen von Anweisungen und Verstehen von langen Kontexten. Sie sind auch billiger und schneller als frühere Versionen.
In diesem Artikel erkläre ich dir, was die einzelnen Modelle können, wie sie im Vergleich zu GPT-4o und GPT-4.5 abschneiden und wo sie in Benchmarks und im realen Einsatz stehen.
Wir halten unsere Leserinnen und Leser mit dem kostenlosen FreitagsnewsletterThe Medianauf dem Laufenden , in dem wir die wichtigsten Themen der Woche aufschlüsseln. Melde dich an und bleibe in nur ein paar Minuten pro Woche auf dem Laufenden:
Die GPT-4.1-Modellreihe besteht aus drei Modellen: GPT-4.1, GPT-4.1 Mini und GPT-4.1 Nano. Sie richten sich an Entwickler, die eine bessere Leistung, einen längeren Kontext und eine vorhersehbarere Befehlsfolge benötigen. Jedes Modell unterstützt bis zu 1 Million Kontext-Token, ein großer Sprung gegenüber der 128K-Grenze in früheren Versionen wie GPT-4o.
Quelle: OpenAI
Trotz der gemeinsamen Architektur ist jede Version auf unterschiedliche Anwendungsfälle abgestimmt. Schauen wir uns die einzelnen Punkte genauer an.
Dies ist das Flaggschiff-Modell. Wenn du die beste Gesamtleistung beim Codieren, Befolgen von Anweisungen und bei Aufgaben mit langem Kontext erzielen willst, ist dies die richtige Wahl. Sie ist für komplexe Codierungs-Workflows oder die Bearbeitung großer Dokumente in einer einzigen Eingabeaufforderung konzipiert.
In Benchmarks übertrifft er GPT-4o in der realen Softwareentwicklung (SWE-Bench), beim Verfolgen von Anweisungen (MultiChallenge) und beim Long-Context-Reasoning (MRCR, Graphwalks). Es ist auch deutlich besser darin, Struktur und Formatierung zu beachten - denk an XML-Antworten, geordnete Anweisungen und negative Einschränkungen wie "Antworte nur, wenn...".
Du kannst auch GPT-4.1 feinabstimmen ab dem Tag der Markteinführung anpassen, was es für mehr Anwendungsfälle in der Produktion öffnet, bei denen die Kontrolle über Ton, Format oder Fachwissen wichtig ist.
GPT-4.1 Mini ist die mittlere Variante, die fast die gleichen Funktionen wie das Vollmodell bietet, aber mit geringerer Latenz und geringeren Kosten. Er erreicht oder übertrifft den GPT-4o in vielen Benchmarks, z. B. beim Folgen von Anweisungen und beim bildbasierten Denken.
Es wird wahrscheinlich die Standardwahl für viele Anwendungsfälle werden: schnell genug für interaktive Tools, intelligent genug, um detaillierte Anweisungen zu befolgen, und deutlich günstiger als das Vollmodell.
Wie die Vollversion unterstützt sie 1 Million Kontext-Token und ist bereits für die Feinabstimmung verfügbar.
Der Nano ist der kleinste, schnellste und billigste unter ihnen. Sie ist für Aufgaben wie Autovervollständigung, Klassifizierung und Extraktion von Informationen aus großen Dokumenten konzipiert. Obwohl es leichtgewichtig ist, unterstützt es dennoch das volle Kontextfenster mit 1 Million Token.
Es ist außerdem das kleinste, schnellste und billigste Modell von OpenAI, das nur etwa 10 Cent pro Million Token kostet. Du hast nicht die volle Denk- und Planungsfähigkeit der größeren Modelle, aber für bestimmte Aufgaben ist das auch nicht wichtig.
Bevor wir uns den Benchmarks zuwenden (die wir im nächsten Abschnitt im Detail behandeln), sollten wir verstehen, wie sich GPT-4.1 in der Praxis von GPT-4o und GPT-4.5.
GPT-4.1 verbessert die Fähigkeiten von GPT-4o, während die Latenz in etwa gleich bleibt. In der Praxis bedeutet das, dass Entwickler jetzt eine bessere Leistung erhalten, ohne dafür einen Preis in der Reaktionsfähigkeit zu zahlen.
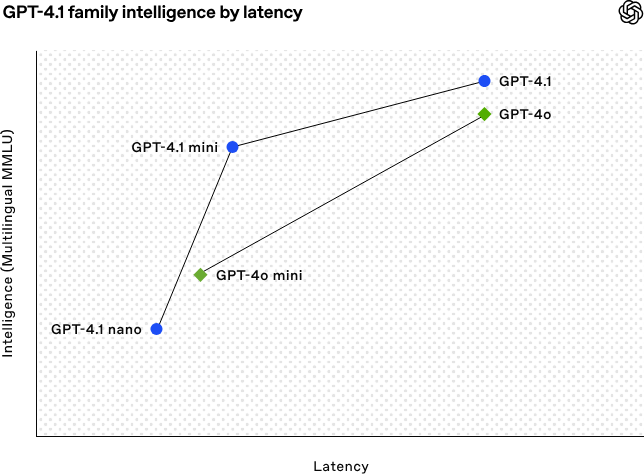
Quelle: OpenAI
Schauen wir uns die Grafik oben an:
Das GPT-4.5 hingegen war immer als Forschungsvorschau gedacht. Die Argumentation und die Qualität der Texte waren zwar gut, aber es gab auch mehr Aufwand. GPT-4.1 liefert ähnliche oder bessere Ergebnisse bei wichtigen Benchmarks, ist aber billiger und reaktionsschneller - so sehr, dass OpenAI plant, 4.5 bis Mitte Juli komplett aus dem Verkehr zu ziehen, um mehr GPUs freizusetzen.
Alle drei GPT-4.1-Modelle - Standard, Mini und Nano - unterstützen bis zu 1 Million Token an Kontext. Das ist mehr als das 8-fache von dem, was GPT-4o bietet.
Diese Kapazität für lange Kontexte ermöglicht praktische Anwendungsfälle wie die Verarbeitung ganzer Logs, die Indizierung von Code-Repositories, die Bearbeitung von juristischen Workflows mit mehreren Dokumenten oder die Analyse langer Protokolle - alles ohne vorheriges Chunking oder Zusammenfassen.
Mit GPT-4.1 ändert sich auch, wie zuverlässig die Modelle den Anweisungen folgen. Sie kann komplexe Aufforderungen mit geordneten Schritten, Formatierungseinschränkungen und negativen Bedingungen (z. B. Verweigerung der Antwort bei falscher Formatierung) verarbeiten.
In der Praxis bedeutet das zwei Dinge: weniger Zeit für die Erstellung von Prompts und weniger Zeit für die anschließende Bereinigung der Ausgabe.
Das GPT-4.1 zeigt Fortschritte in vier Kernbereichen: Kodieren, Befolgen von Anweisungen, Verstehen langer Zusammenhänge und multimodale Aufgaben.
Im SWE-Bench Verified - einem Benchmark, bei dem das Modell in eine reale Codebasis eingesetzt und aufgefordert wird, Aufgaben von Anfang bis Ende zu lösen - erreicht GPT-4.1 54,6 %. Das sind mehr als 33,2 % bei GPT-4o und 38 % bei GPT-4.5. Es ist auch sehr beeindruckend, dass GPT-4.1 besser abschneidet als o1 und o3-mini.
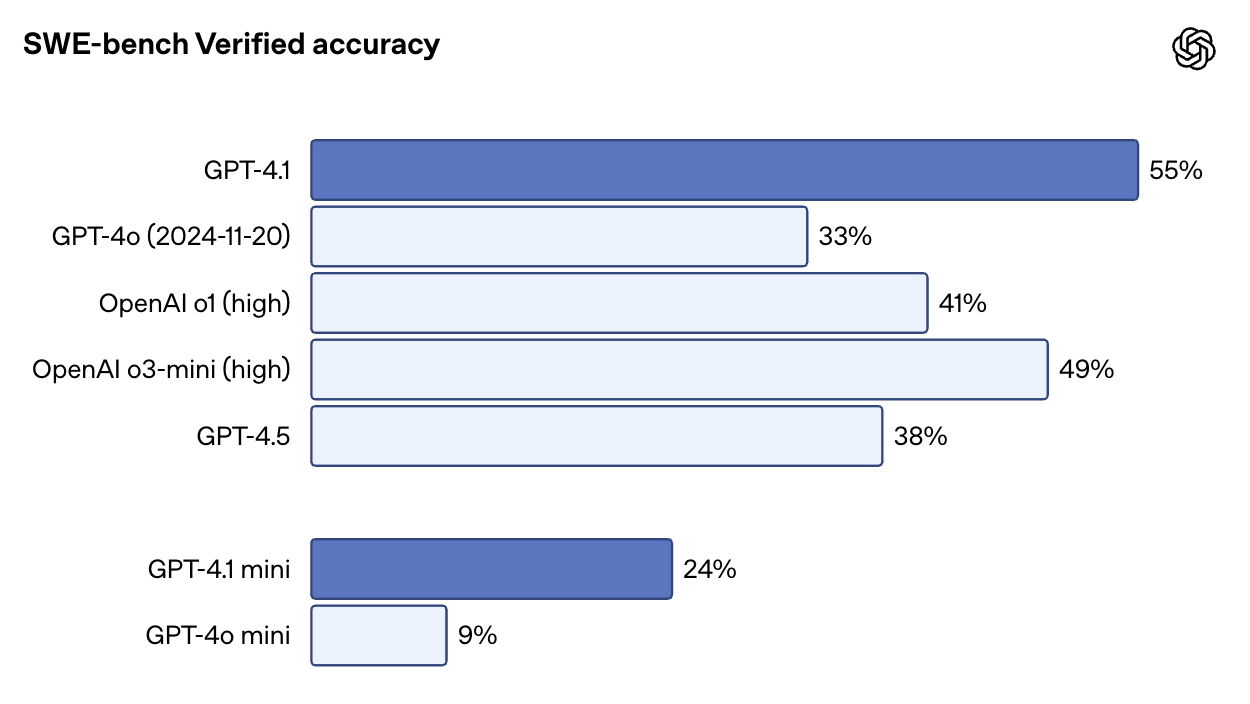
Quelle: OpenAI
Auch beim Aider Polyglot Diff Benchmark hat GPT-4o seine Leistung mehr als verdoppelt und erreicht eine Genauigkeit von 52,9 % bei Code-Diffs über mehrere Sprachen und Formate hinweg. GPT-4.5 erzielte bei der gleichen Aufgabe 44,9 %. GPT-4.1 ist auch präziser: Bei internen Prüfungen sank die Zahl der fremden Code-Edits von 9% (GPT-4o) auf nur 2%.
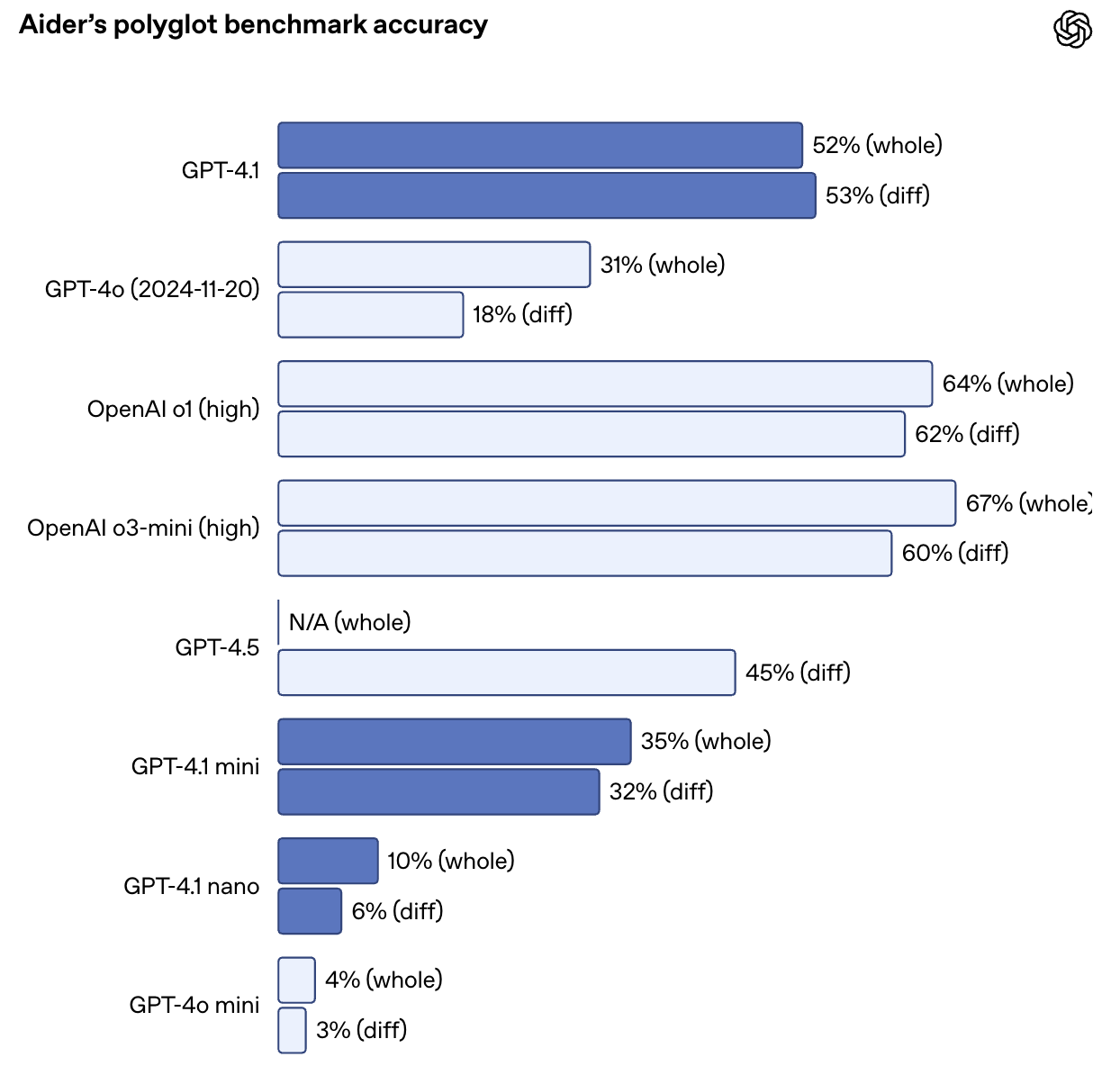
Quelle: OpenAI
Abgesehen von den Benchmark-Ergebnissen ist die Frontend-Coding-Demo, die OpenAI angeboten hat, ein gutes visuelles Beispiel für die überlegene Leistung des GPT-4.1. Das Team von OpenAI hat beide Modelle gebeten, dieselbe Karteikarten-App zu erstellen, und die menschlichen Bewerter bevorzugten in 80 % der Fälle das Ergebnis von GPT-4.1.
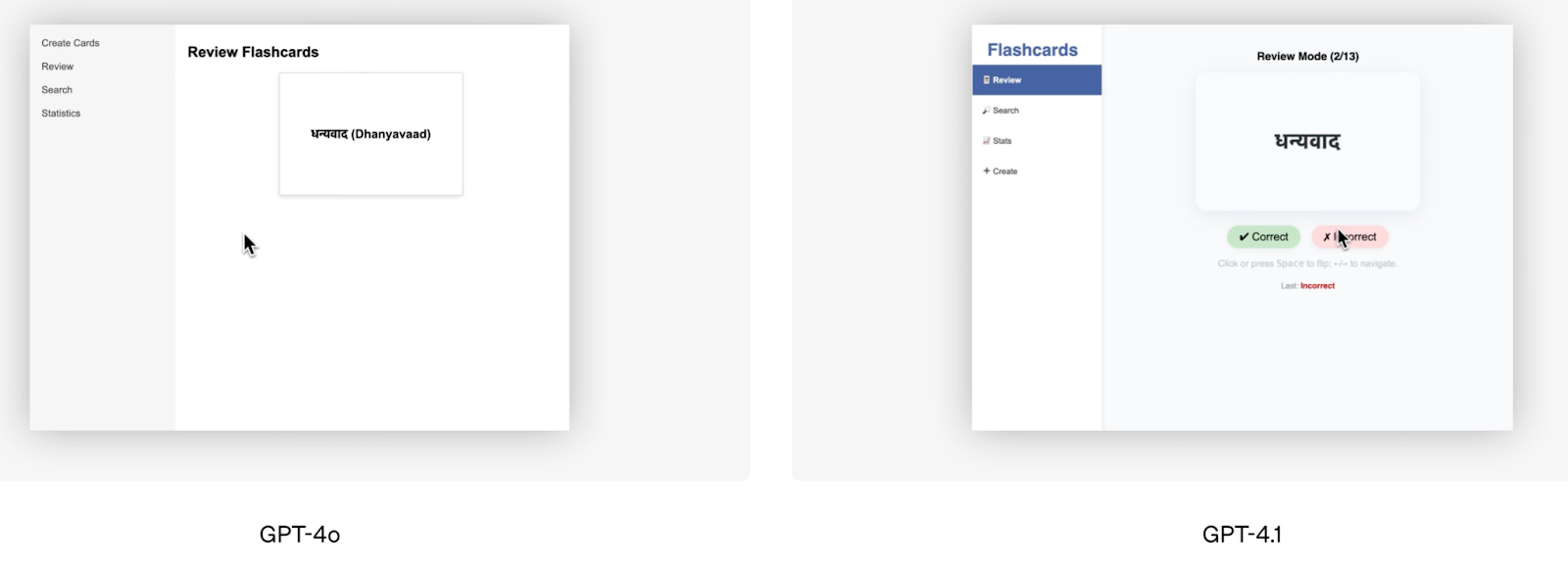
Quelle: OpenAI
Windsurf, einer der Alphatester, meldete eine Verbesserung von 60 % im Vergleich zu seinem eigenen internen Code-Benchmark. Ein anderes Unternehmen, Qodo, testete GPT-4.1 an echten GitHub-Pull-Requests und stellte fest, dass es in 55 % der Fälle bessere Vorschläge lieferte und weniger irrelevante oder übermäßig ausführliche Änderungen vornahm.
GPT-4.1 ist wortgetreuer - und zuverlässiger - wenn es darum geht, Anweisungen zu befolgen, besonders bei Aufgaben, die mehrere Schritte, Formatierungsregeln oder Bedingungen beinhalten. Bei OpenAIs internem Befehlsfolgetest (Hard Subset) erreichte GPT-4.1 49,1 %, GPT-4o dagegen nur 29,2 %. GPT-4.5 liegt hier mit 54% leicht vorne, aber der Abstand zwischen 4.1 und 4o ist erheblich.

Quelle: OpenAI
Bei der MultiChallenge, bei der getestet wird, ob ein Modell Anweisungen mit mehreren Drehungen befolgen und sich an zuvor in der Konversation eingeführte Einschränkungen erinnern kann, erreicht GPT-4.1 38,3% - gegenüber 27,8% bei GPT-4o. Und im IFEval-Test, der die Einhaltung klar definierter Leistungsanforderungen prüft, erreicht der GPT-4.1 87,4 %, eine solide Verbesserung gegenüber dem GPT-4o von 81 %.
In der Praxis bedeutet das, dass GPT-4.1 besser in der Lage ist, geordnete Schritte einzuhalten, fehlerhafte Eingaben abzulehnen und in dem von dir gewünschten Format zu antworten - vor allem bei strukturierten Ausgaben wie XML, YAML oder Markdown. Das macht es auch einfacher, zuverlässige Agenten-Workflows ohne viele Wiederholungsversuche zu erstellen.
Alle drei GPT-4.1-Modelle - Standard, Mini und Nano - unterstützen bis zu 1 Million Token an Kontext. Das ist eine 8-fache Steigerung im Vergleich zum GPT-4o, der bei 128K endete. Genauso wichtig: Die Nutzung des Kontextfensters kostet nichts extra. Der Preis ist wie bei jeder anderen Aufforderung.
Aber können die Modelle tatsächlich all diesen Kontextnutzen? In OpenAIs "Needle-in-a-Haystack"-Prüfung fand GPT-4.1 zuverlässig eingefügte Inhalte an jedem beliebigen Punkt - Anfang, Mitte oder Ende - innerhalb der gesamten 1-Millionen-Token-Eingabe.
Quelle: OpenAI
Graphwalks, ein Benchmark, der Multi-Hop-Reasoning in langen Kontexten testet, bewertet GPT-4.1 mit 61,7 % - ein solider Sprung von GPT-4o (41,7 %), aber immer noch unter GPT-4.5 (72,3 %).
Diese Verbesserungen zeigen sich auch im Praxistest. Thomson Reuters verzeichnete eine 17%ige Steigerung bei der juristischen Analyse mehrerer Dokumente mit GPT-4.1, während Carlyle eine 50-prozentige Verbesserung bei der Extraktion granularer Daten aus dichten Finanzberichten verzeichnete.
Auch bei multimodalen Aufgaben macht der GPT-4.1 Fortschritte. Beim Video-MME-Benchmark, bei dem es um die Beantwortung von Fragen zu 30-60-minütigen Videos ohne Untertitel geht, erreichte er 72,0 % - gegenüber 65,3 % beim GPT-4o.
Bei bildlastigen Benchmarks wie MMMU erreichte sie 74,8 %. 68,7% für GPT-4o. Bei MathVista, das Diagramme, Grafiken und mathematische Darstellungen enthält, erreichte GPT-4.1 72,2%.
Eine Überraschung: GPT-4.1 Mini schneidet bei einigen dieser Benchmarks fast genauso gut ab wie die Vollversion. Bei MathVista zum Beispiel übertraf er GPT-4.1 mit 73,1 % leicht. Das macht sie zu einer überzeugenden Wahl für Anwendungsfälle, die Geschwindigkeit mit visuellen Aufforderungen kombinieren.
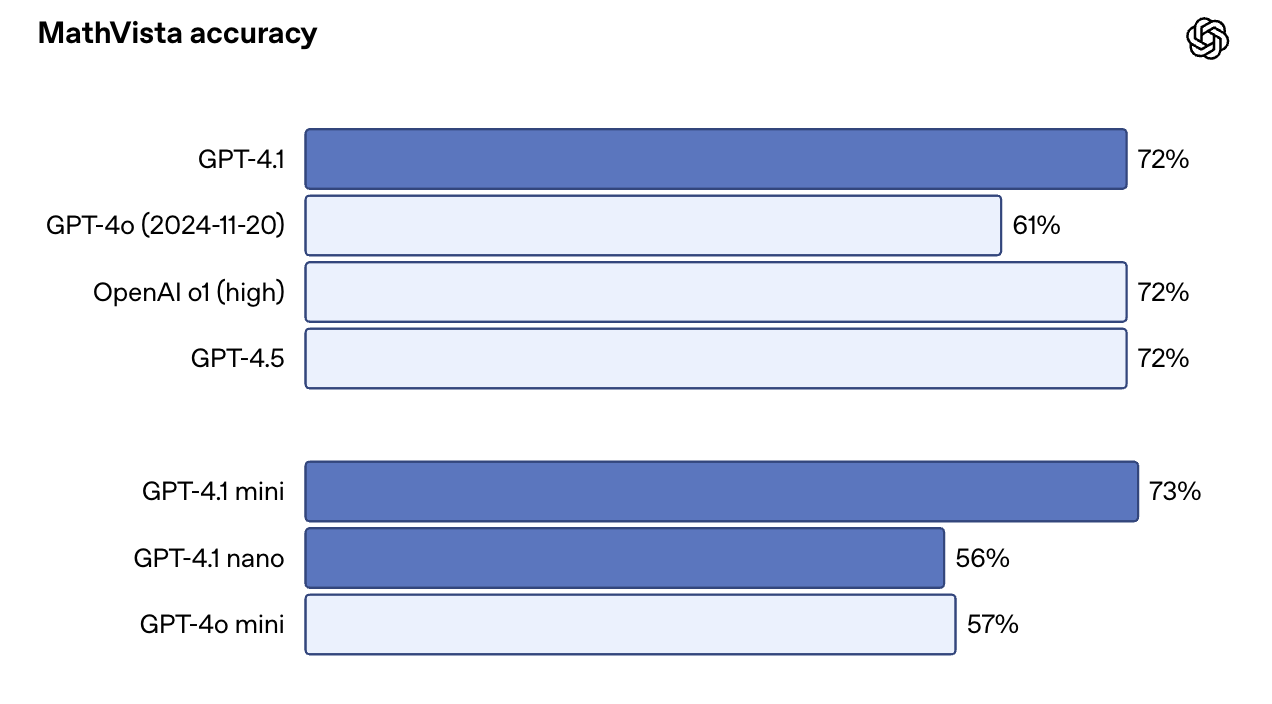
Quelle: OpenAI
Du kannst jetzt direkt in der ChatGPT-App auf GPT-4.1 und GPT-4.1 Mini zugreifen, nicht nur über die API. Plus-, Pro- und Team-Abonnenten können GPT-4.1 manuell aus dem Modellmenü auswählen, während kostenlose Nutzer automatisch auf GPT-4.1 Mini zurückgreifen und damit GPT-4o Mini als Standard hinter den Kulissen ersetzen. Die Pläne für Unternehmen und Bildung werden voraussichtlich in den nächsten Wochen freigeschaltet.
Für Entwickler ist die OpenAI API und Playground weiterhin alle drei Varianten - GPT-4.1, GPT-4.1 Mini und GPT-4.1 Nano - unterstützen. Dies ist nach wie vor der beste Weg, um Prompts zu testen, das Verhalten in langen Kontexten zu untersuchen und Modelle zu vergleichen, bevor sie in die Produktion integriert werden.
Wenn du mit langen Dokumenten arbeitest - z. B. Protokollen, PDFs, Rechtsakten oder wissenschaftlichen Artikeln - kannst du bis zu 1 Million Token in einem einzigen Aufruf senden, ohne dass spezielle Parameter erforderlich sind. Es gibt auch keinen Preisanstieg für einen langen Kontext: Die Token-Kosten sind unabhängig von der Größe des Inputs gleich.
Du kannst alle drei GPT-4.1-Varianten feinjustieren. Das öffnet die Tür für benutzerdefinierte Anweisungen, domänenspezifisches Vokabular oder tonartspezifische Ausgaben. Beachte, dass die Feinabstimmung einen etwas größeren pricing hat:
|
Modell |
Eingabe |
Zwischengespeicherte Eingabe |
Ausgabe |
Ausbildung |
|
GPT-4.1 |
$3.00 / 1M Token |
0,75 $ / 1 Mio. Token |
$12.00 / 1M Token |
$25.00 / 1M Token |
|
GPT-4.1 Mini |
0,80 $ / 1 Mio. Token |
0,20 $ / 1M Token |
3,20 $ / 1 Mio. Token |
$5.00 / 1M Token |
|
GPT-4.1 Nano |
0,20 $ / 1M Token |
0,05 $ / 1M Token |
0,80 $ / 1 Mio. Token |
1,50 $ / 1 Mio. Token |
Wenn dubereits GPT-3.5- oder GPT-4-Modelle feinabgestimmt hast, bleibt der Prozess größtenteils derselbe - wähle einfach die neuere Basis. Wenn du mehr erfahren willst, empfehle ich dir dieses Tutorial über Feinabstimmung des GPT-4o mini.
Eine der willkommenen Neuerungen von GPT-4.1 ist, dass es nicht nur intelligenter, sondern auch billiger ist. OpenAI sagt, das Ziel war es, diese Modelle für mehr reale Arbeitsabläufe nutzbar zu machen, und das zeigt sich in der Preisgestaltung.
Hier siehst du, wie die drei Modelle für die Inferenz bewertet werden:
|
Modell |
Eingabe |
Zwischengespeicherte Eingabe |
Ausgabe |
Blended Avg. Kosten* |
|
GPT-4.1 |
$2.00 / 1M Token |
0,50 $ / 1M Token |
$8.00 / 1M Token |
$1.84 |
|
GPT-4.1 Mini |
0,40 $ / 1M Token |
0,10 $ / 1M Token |
1,60 $ / 1 Mio. Token |
$0.42 |
|
GPT-4.1 Nano |
0,10 $ / 1M Token |
0,025 $ / 1 Mio. Token |
0,40 $ / 1M Token |
$0.12 |
*Die "gemischte" Zahl basiert auf den von OpenAI angenommenen typischen Input/Output-Verhältnissen.
GPT-4.1 bietet eine zuverlässigere Codegenerierung, eine bessere Befehlsverfolgung, echte Langkontextverarbeitung und eine schnellere Iteration.
Die Namensgebung mag verwirrend sein, aber die Modelle selbst sind deutlich leistungsfähiger als ihre Vorgänger. Sie sind auch erschwinglicher und besser nutzbar - vor allem in Produktionsumgebungen, in denen Latenz, Kosten und Vorhersagbarkeit eine Rolle spielen.
Wenn du heute mit GPT-4o arbeitest, lohnt es sich, GPT-4.1 zu testen.
Lerne KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Tutorial
Matt Crabtree
Tutorial
Abid Ali Awan
Tutorial
Aditya Sharma