Course
Working with the OpenAI API
3 hr
141.6K
OpenAI recently released GPT-4.1, a new family of models built specifically for coding tasks. I’m just as confused as everyone else about the naming jump from GPT-4.5 to GPT-4.1, but thankfully, the benchmarks don’t also go backward—on the contrary.
The rollout began on April 14 with API-only access. Then, on May 14, OpenAI started bringing GPT-4.1 into the ChatGPT app. Free-tier users won’t be able to pick GPT-4.1 manually, but they now benefit from GPT-4.1 Mini as the new default fallback, replacing GPT-4o Mini.
GPT-4.1 comes in three sizes: GPT-4.1, GPT-4.1 Mini, and GPT-4.1 Nano. All three support up to 1 million tokens of context and bring notable improvements in coding, instruction following, and long-context comprehension. They’re also cheaper and faster than previous releases.
In this article, I’ll walk you through what each model can do, how it compares to GPT-4o and GPT-4.5, and where it stands in benchmarks and real-world use.
We keep our readers updated on the latest in AI by sending out The Median, our free Friday newsletter that breaks down the week’s key stories. Subscribe and stay sharp in just a few minutes a week:
The GPT-4.1 model suite consists of three models: GPT-4.1, GPT-4.1 Mini, and GPT-4.1 Nano. They are aimed at developers who need better performance, longer context, and more predictable instruction following. Each model supports up to 1 million tokens of context, a big leap from the 128K limit in previous versions like GPT-4o.
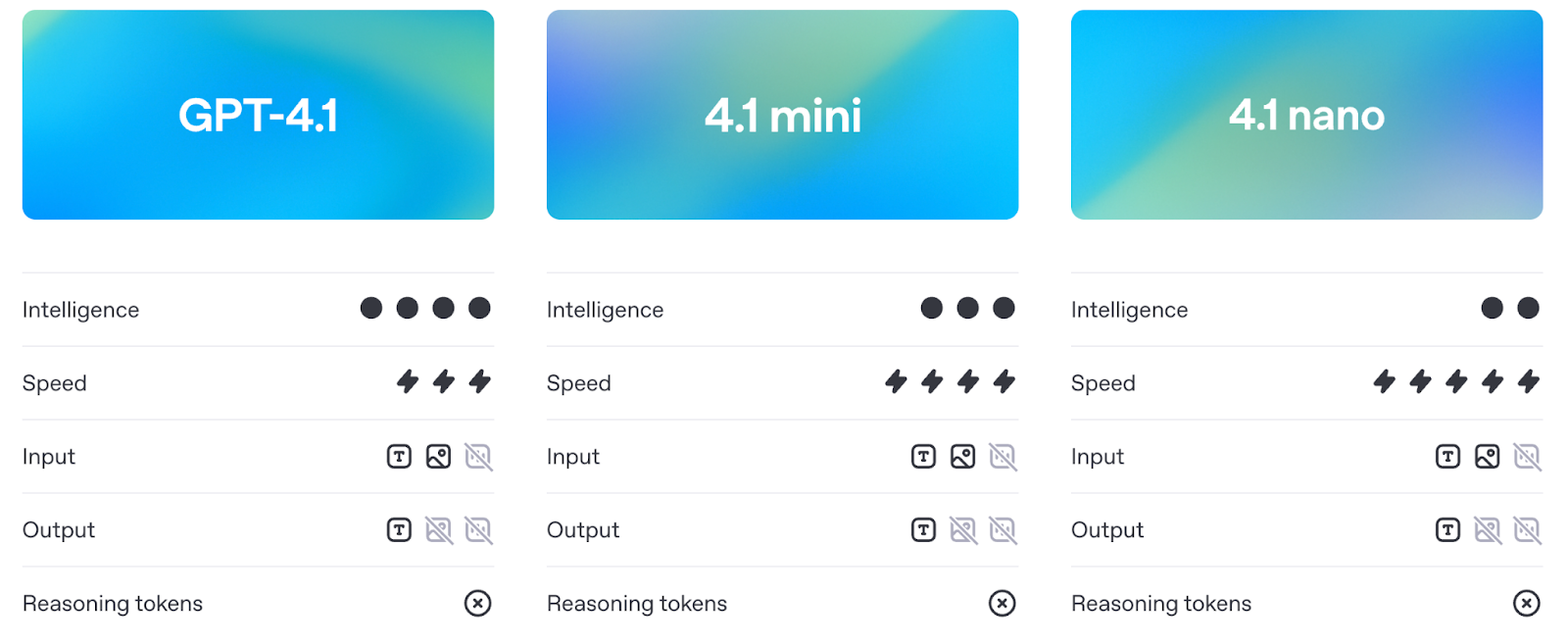
Source: OpenAI
Despite the shared architecture, each version is tuned for different use cases. Let’s explore each in more detail.
This is the flagship model. If you want the best overall performance across coding, instruction following, and long-context tasks, this is the one to use. It’s built to handle complex coding workflows or process large documents in a single prompt.
In benchmarks, it outperforms GPT-4o in real-world software engineering (SWE-bench), instruction following (MultiChallenge), and long-context reasoning (MRCR, Graphwalks). It’s also noticeably better at respecting structure and formatting—think XML responses, ordered instructions, and negative constraints like “don’t answer unless…”.
You can also fine-tune GPT-4.1 as of launch day, which opens it up to more production use cases where control over tone, format, or domain knowledge matters.
GPT-4.1 Mini is the mid-tier option, offering nearly the same capabilities as the full model but with lower latency and cost. It matches or beats GPT-4o in many benchmarks, including instruction following and image-based reasoning.
It’s likely to become the default choice for many use cases: fast enough for interactive tools, smart enough to follow detailed instructions, and significantly cheaper than the full model.
Like the full version, it supports 1 million tokens of context and is already available for fine-tuning.
Nano is the smallest, fastest, and cheapest of the bunch. It’s built for tasks like autocomplete, classification, and extracting information from large documents. Despite being lightweight, it still supports the full 1 million-token context window.
It’s also OpenAI’s smallest, fastest, and cheapest model ever, at just about 10 cents per million tokens. You don’t get the full reasoning and planning ability of the larger models, but for certain tasks, that’s not the point.
Before we get into the benchmarks (which we’ll cover in detail in the next section), it’s worth understanding how GPT-4.1 differs in practice from GPT-4o and GPT-4.5.
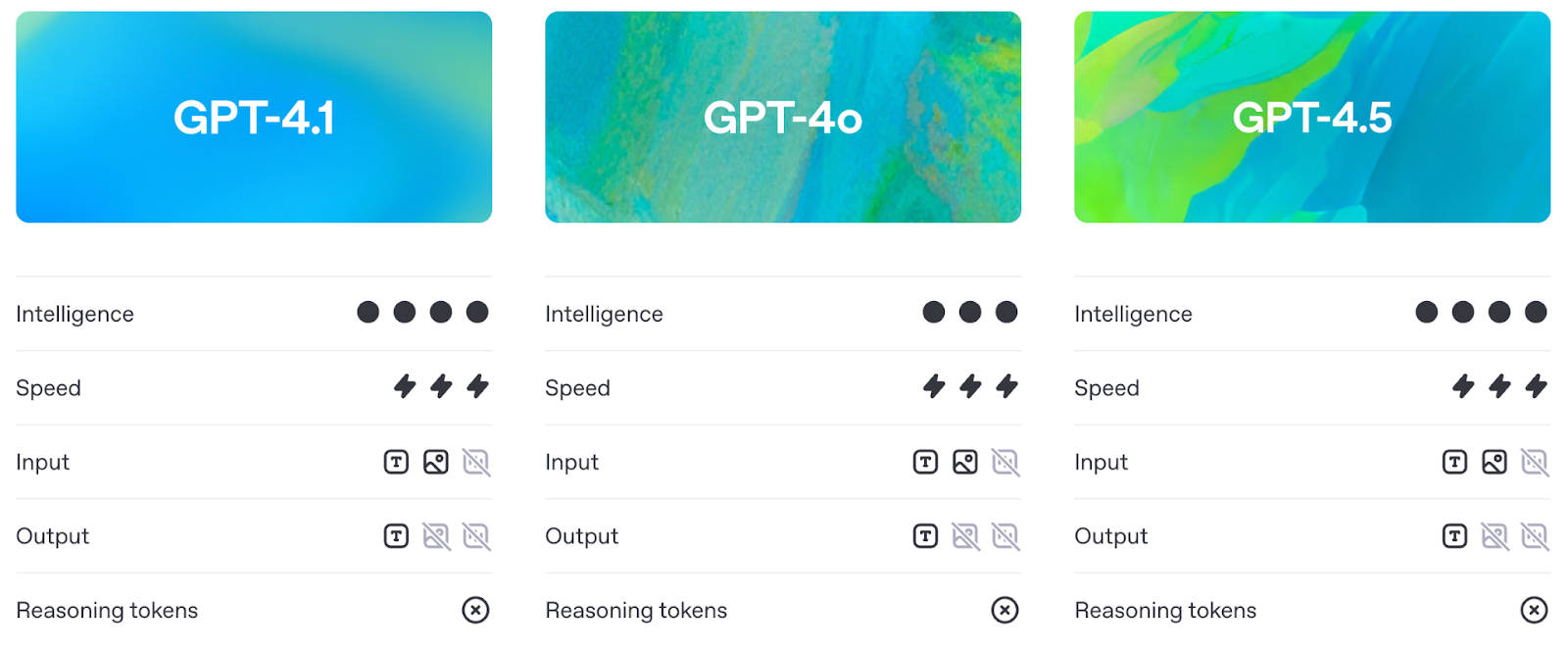
GPT-4.1 improves on GPT-4o’s capabilities while keeping latency in roughly the same range. In practice, it means developers now get better performance without paying a cost in responsiveness.
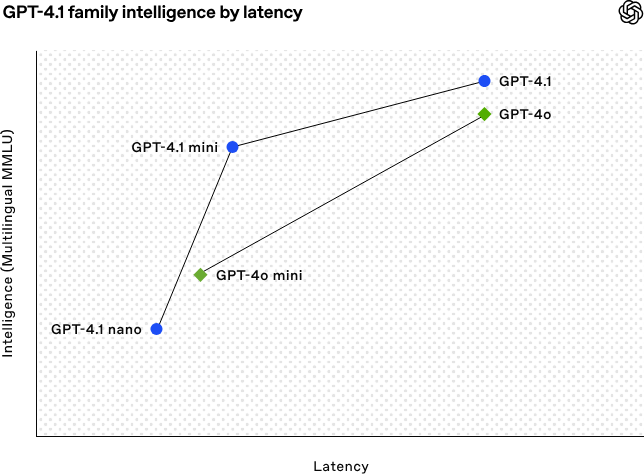
Source: OpenAI
Let’s break down the graph above:
GPT-4.5, on the other hand, was always positioned as a research preview. While it had strong reasoning and writing quality, it came with more overhead. GPT-4.1 delivers similar or better results on key benchmarks but is cheaper and more responsive—enough that OpenAI plans to retire 4.5 entirely by mid-July to free up more GPUs.
All three GPT-4.1 models—standard, Mini, and Nano—support up to 1 million tokens of context. That’s more than 8x what GPT-4o offered.
This long-context capacity enables practical use cases like processing entire logs, indexing code repositories, handling multi-document legal workflows, or analyzing long transcripts—all without needing to chunk or summarize beforehand.
GPT-4.1 also marks a shift in how reliably the models follow instructions. It handles complex prompts involving ordered steps, formatting constraints, and negative conditions (like refusing to answer if formatting is wrong).
In practice, that means two things: less time spent crafting prompts, and less time cleaning up the output afterward.
GPT-4.1 shows progress across four core areas: coding, instruction following, long-context comprehension, and multimodal tasks.
On SWE-bench Verified—a benchmark that drops the model into a real codebase and asks it to complete issues end-to-end—GPT-4.1 scores 54.6%. That’s up from 33.2% for GPT-4o and 38% for GPT-4.5. It’s also very impressive that GPT-4.1 scores higher than o1 and o3-mini.
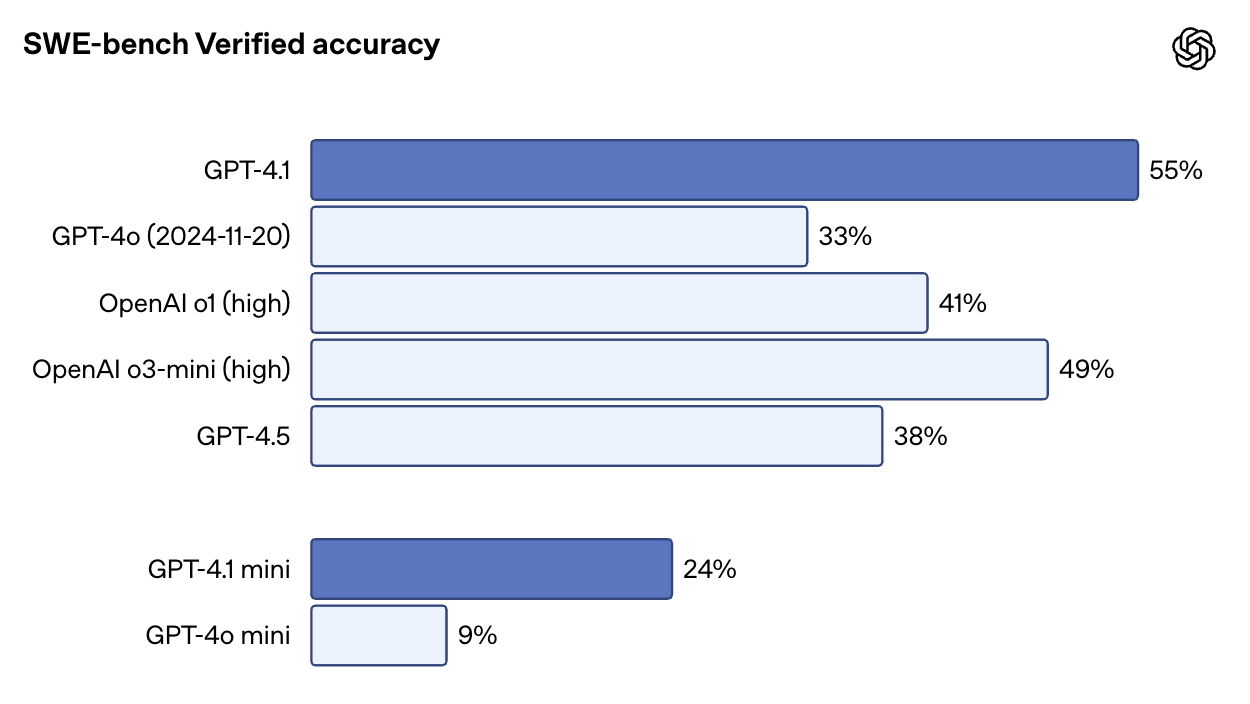
Source: OpenAI
It also more than doubles GPT-4o’s performance on Aider’s polyglot diff benchmark, reaching 52.9% accuracy on code diffs across multiple languages and formats. GPT-4.5 scored 44.9% on the same task. GPT-4.1 is also more precise: in internal evals, extraneous code edits dropped from 9% (GPT-4o) to just 2%.
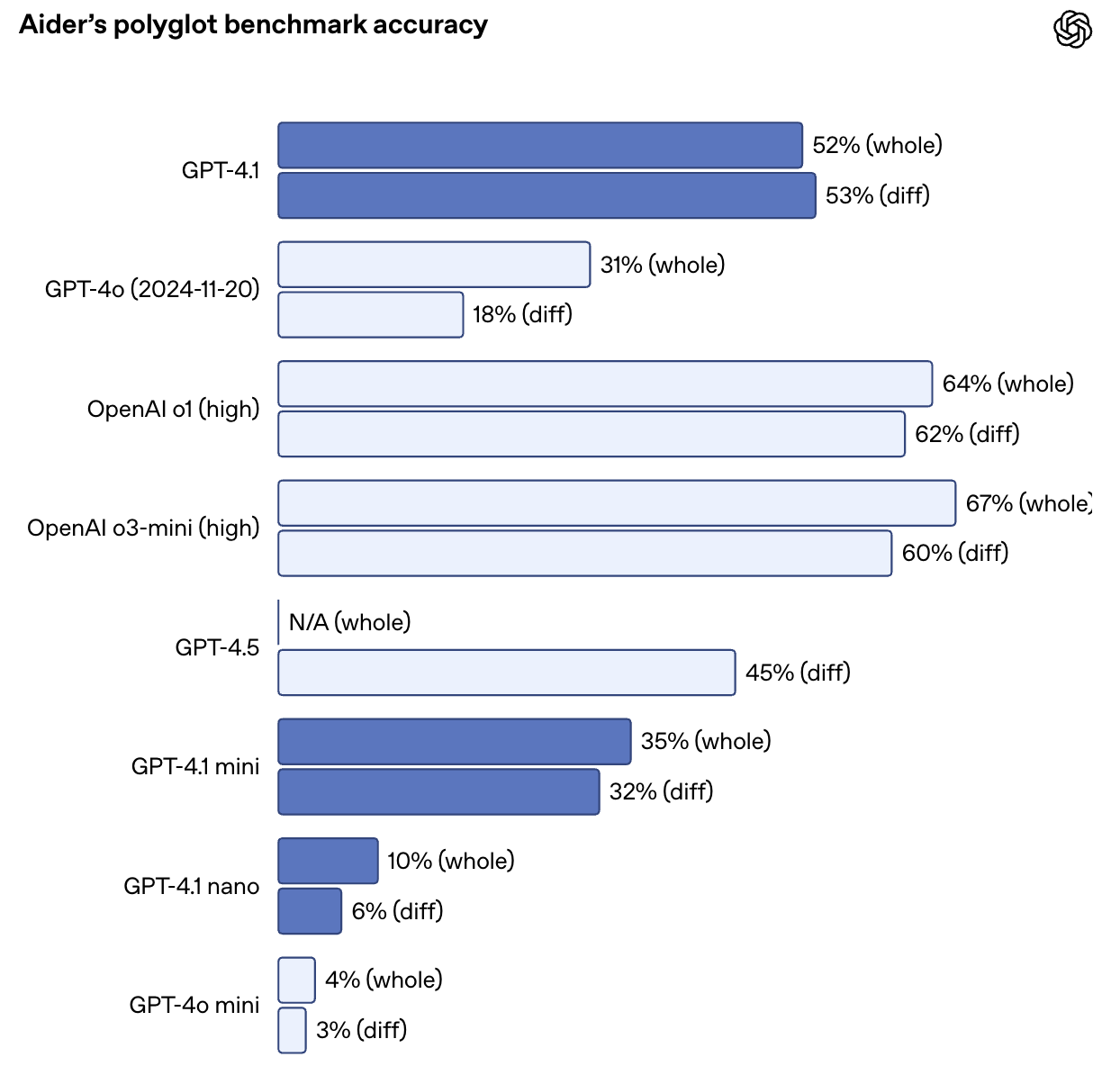
Source: OpenAI
Outside of benchmark scores, the frontend coding demo OpenAI offered is a good visual example of GPT-4.1’s superior performance. OpenAI’s team asked both models to build the same flashcard app, and human raters preferred GPT-4.1’s output 80% of the time.
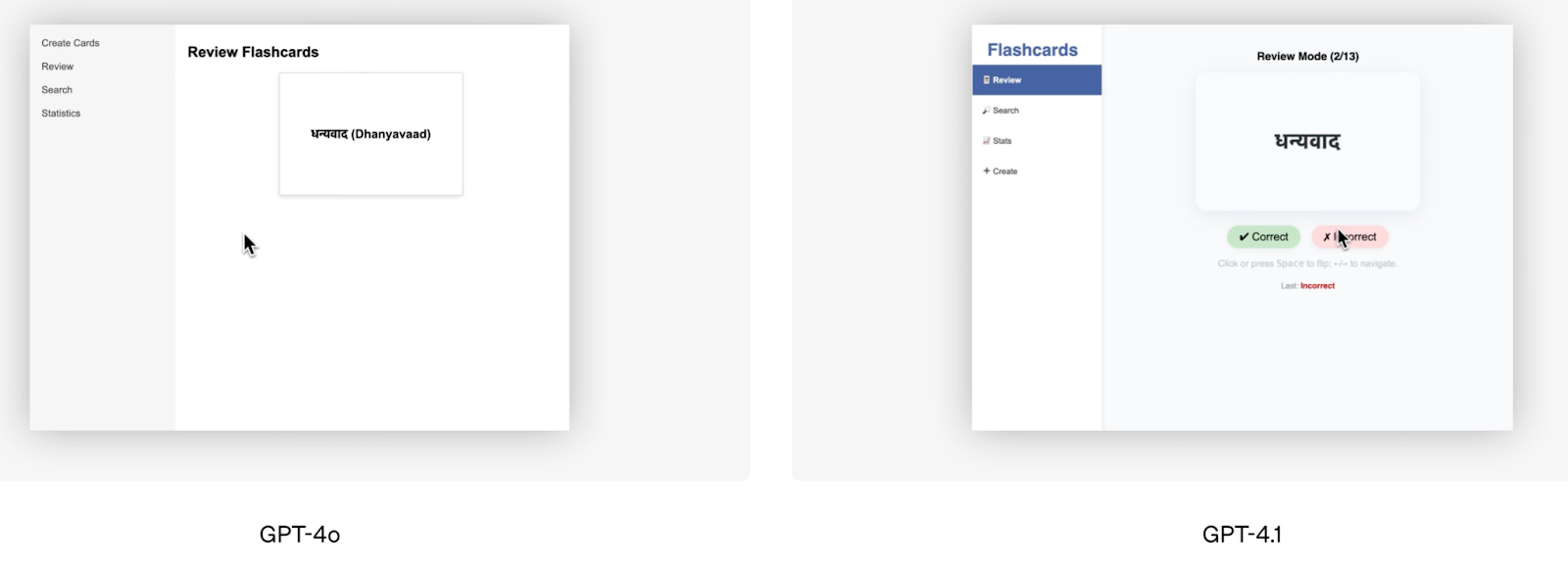
Source: OpenAI
Windsurf, one of the alpha testers, reported a 60% improvement on their own internal coding benchmark. Another company, Qodo, tested GPT-4.1 on real GitHub pull requests and found it produced better suggestions 55% of the time, with fewer irrelevant or overly verbose edits.
GPT-4.1 is more literal—and more reliable—when it comes to following instructions, especially for tasks involving multiple steps, formatting rules, or conditions. On OpenAI’s internal instruction following eval (hard subset), GPT-4.1 scored 49.1%, compared to just 29.2% for GPT-4o. GPT-4.5 is slightly ahead here at 54%, but the gap between 4.1 and 4o is significant.

Source: OpenAI
On MultiChallenge, which tests whether a model can follow multi-turn instructions and remember constraints introduced earlier in the conversation, GPT-4.1 scores 38.3%—up from 27.8% for GPT-4o. And on IFEval, which tests compliance with clearly specified output requirements, GPT-4.1 hits 87.4%, a solid improvement over GPT-4o’s 81%.
In practice, this means GPT-4.1 is better at sticking to ordered steps, rejecting malformed inputs, and responding in the format you asked for—especially in structured outputs like XML, YAML, or markdown. That also makes it easier to build reliable agent workflows without lots of prompt retries.
All three GPT-4.1 models—standard, Mini, and Nano—support up to 1 million tokens of context. That’s an 8x increase over GPT-4o, which topped out at 128K. Just as important: there’s no extra cost for using that context window. It’s priced like any other prompt.
But can the models actually use all that context? In OpenAI’s needle-in-a-haystack eval, GPT-4.1 reliably found inserted content placed at any point—start, middle, or end—within the full 1M-token input.
Source: OpenAI
Graphwalks, a benchmark that tests multi-hop reasoning in long contexts, puts GPT-4.1 at 61.7%—a solid jump from GPT-4o’s 41.7%, though still below GPT-4.5 at 72.3%.
These improvements show up in real-world tests, too. Thomson Reuters saw a 17% boost in multi-document legal analysis using GPT-4.1, while Carlyle reported a 50% improvement in extracting granular data from dense financial reports.
On multimodal tasks, GPT-4.1 also makes progress. It scored 72.0% on the Video-MME benchmark, which involves answering questions about 30–60 minute videos with no subtitles—up from 65.3% with GPT-4o.
On image-heavy benchmarks like MMMU, it reached 74.8% vs. 68.7% for GPT-4o. On MathVista, which includes charts, graphs, and math visuals, GPT-4.1 hit 72.2%.
One surprise: GPT-4.1 Mini performs almost as well as the full version on some of these benchmarks. On MathVista, for instance, it slightly outscored GPT-4.1 at 73.1%. That makes it a compelling choice for use cases that combine speed with vision-heavy prompts.
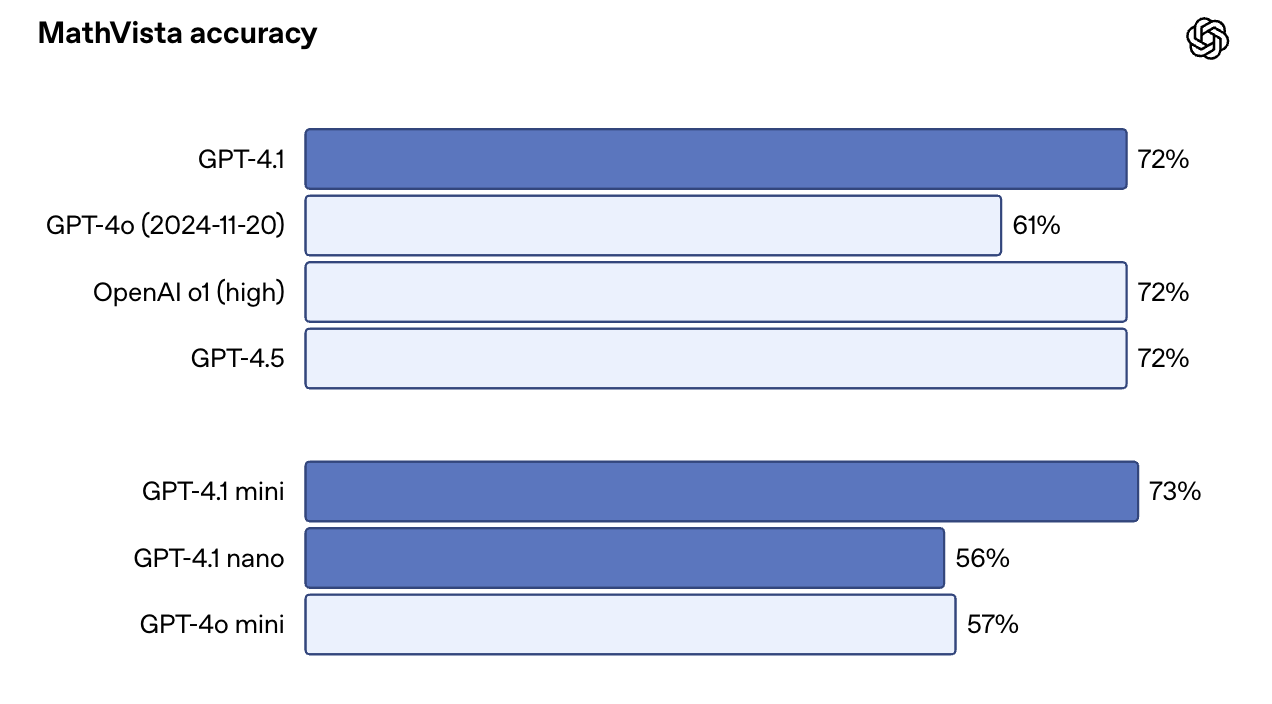
Source: OpenAI
You can now access GPT-4.1 and GPT-4.1 Mini directly in the ChatGPT app, not just through the API. Plus, Pro, and Team subscribers can manually select GPT-4.1 from the model menu, while free users automatically fall back to GPT-4.1 Mini—replacing GPT-4o Mini as the default behind the scenes. Enterprise and Education plans are expected to receive access in the coming weeks.
For developers, the OpenAI API and Playground continue to support all three variants—GPT-4.1, GPT-4.1 Mini, and GPT-4.1 Nano. This remains the best way to test prompts, explore long-context behavior, and compare models before integrating them into production.
If you’re working with long documents—think logs, PDFs, legal records, or academic articles—you can send up to 1 million tokens in a single call, no special parameter needed. There’s also no pricing bump for long context: token costs are flat, regardless of input size.
You can fine-tune all three GPT-4.1 variants. That opens the door for custom instructions, domain-specific vocabulary, or tone-specific outputs. Note that fine-tuning has a slightly larger pricing:
|
Model |
Input |
Cached Input |
Output |
Training |
|
GPT-4.1 |
$3.00 / 1M tokens |
$0.75 / 1M tokens |
$12.00 / 1M tokens |
$25.00 / 1M tokens |
|
GPT-4.1 Mini |
$0.80 / 1M tokens |
$0.20 / 1M tokens |
$3.20 / 1M tokens |
$5.00 / 1M tokens |
|
GPT-4.1 Nano |
$0.20 / 1M tokens |
$0.05 / 1M tokens |
$0.80 / 1M tokens |
$1.50 / 1M tokens |
If you’ve previously fine-tuned GPT-3.5 or GPT-4 models, the process remains mostly the same—just pick the newer base. If you want to learn more, I recommend this tutorial on fine-tuning GPT-4o mini.
One of the more welcome updates with GPT-4.1 is that it’s not just smarter—it’s also cheaper. OpenAI says the goal was to make these models more usable across more real-world workflows, and that shows in how pricing is structured.
Here’s how the three models are priced for inference:
|
Model |
Input |
Cached Input |
Output |
Blended Avg. Cost* |
|
GPT-4.1 |
$2.00 / 1M tokens |
$0.50 / 1M tokens |
$8.00 / 1M tokens |
$1.84 |
|
GPT-4.1 Mini |
$0.40 / 1M tokens |
$0.10 / 1M tokens |
$1.60 / 1M tokens |
$0.42 |
|
GPT-4.1 Nano |
$0.10 / 1M tokens |
$0.025 / 1M tokens |
$0.40 / 1M tokens |
$0.12 |
*The “blended” number is based on OpenAI’s assumption of typical input/output ratios.
GPT-4.1 comes with more reliable code generation, better instruction following, true long-context processing, and faster iteration.
The naming might be confusing, but the models themselves are clearly more capable than what came before. They’re also more affordable—and more usable—especially in production environments where latency, cost, and predictability matter.
If you’re working with GPT-4o today, it’s worth testing GPT-4.1.
Learn AI with these courses!
Course
Course
Course
blog
Alex Olteanu
8 min
blog
Abid Ali Awan
9 min
blog
Ryan Ong
8 min
blog
Alex Olteanu
8 min
blog
Alex Olteanu
8 min
blog
Abid Ali Awan
9 min