
Curso
Trabalhar com a API da OpenAI
3 h
141.6K
A OpenAI lançou recentemente o GPT-4.1, uma nova família de modelos criados especificamente para tarefas de codificação. Estou tão confuso quanto todo mundo em relação à mudança de nome de GPT-4.5 para GPT-4.1, mas, felizmente, os benchmarks não retrocederam - pelo contrário.
A implementação começou em 14 de abril com acesso somente à API. Então, em 14 de maio, a OpenAI começou a trazer o GPT-4.1 para o aplicativo ChatGPT. Os usuários de nível gratuito não poderão escolher o GPT-4.1 manualmente, mas agora eles se beneficiam do GPT-4.1 Mini como o novo fallback padrão, substituindo o GPT-4o Mini.
O GPT-4.1 vem em três tamanhos: GPT-4.1, GPT-4.1 Mini e GPT-4.1 Nano. Todos os três suportam até 1 milhão de tokens de contexto e trazem melhorias notáveis na codificação, no acompanhamento de instruções e na compreensão de textos longos. Eles também são mais baratos e mais rápidos do que as versões anteriores.
Neste artigo, mostrarei a você o que cada modelo pode fazer, como ele se compara ao GPT-4o e ao GPT-4.5 e qual é a sua posição em relação aos benchmarks e ao uso no mundo real.
Mantemos nossos leitores atualizados sobre as últimas novidades em IA enviando o The Median, nosso boletim informativo gratuito de sexta-feira que analisa as principais histórias da semana. Inscreva-se e fique atento em apenas alguns minutos por semana:
O conjunto de modelos GPT-4.1 consiste em três modelos: GPT-4.1, GPT-4.1 Mini e GPT-4.1 Nano. Eles são destinados a desenvolvedores que precisam de melhor desempenho, contexto mais longo e acompanhamento de instruções mais previsível. Cada modelo suporta até 1 milhão de tokens de contexto, um grande salto em relação ao limite de 128K das versões anteriores, como o GPT-4o.
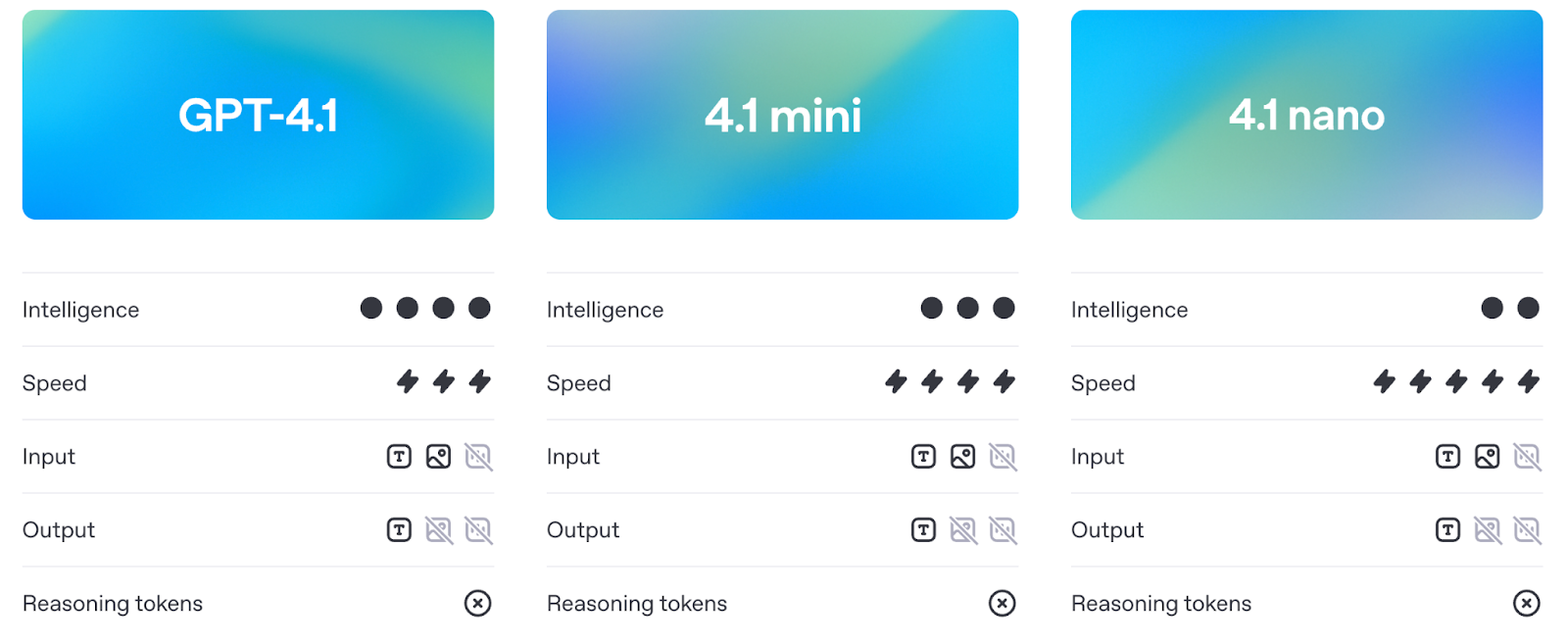
Fonte: OpenAI
Apesar da arquitetura compartilhada, cada versão é ajustada para diferentes casos de uso. Vamos explorar cada um deles com mais detalhes.
Esse é o modelo principal. Se você deseja obter o melhor desempenho geral em tarefas de codificação, de acompanhamento de instruções e de contexto longo, essa é a opção a ser usada. Ele foi desenvolvido para lidar com fluxos de trabalho de codificação complexos ou processar documentos grandes em um único prompt.
Em benchmarks, ele supera o GPT-4o na engenharia de software do mundo real (SWE-bench), no acompanhamento de instruções (MultiChallenge) e no raciocínio de contexto longo (MRCR, Graphwalks). Ele também é visivelmente melhor em respeitar a estrutura e a formatação - pense em respostas XML, instruções ordenadas e restrições negativas como "não responda a menos que...".
Você também pode ajustar o GPT-4.1 a partir do dia do lançamento, o que o abre para mais casos de uso de produção em que o controle sobre o tom, o formato ou o conhecimento do domínio é importante.
O GPT-4.1 Mini é a opção intermediária, oferecendo praticamente os mesmos recursos que o modelo completo, mas com menor latência e custo. Ele iguala ou supera o GPT-4o em muitos benchmarks, incluindo o seguimento de instruções e o raciocínio baseado em imagens.
É provável que ele se torne a opção padrão para muitos casos de uso: rápido o suficiente para ferramentas interativas, inteligente o suficiente para seguir instruções detalhadas e significativamente mais barato do que o modelo completo.
Assim como a versão completa, ele suporta 1 milhão de tokens de contexto e já está disponível para ajuste fino.
O Nano é o menor, o mais rápido e o mais barato de todos. Ele foi desenvolvido para tarefas como preenchimento automático, classificação e extração de informações de documentos grandes. Apesar de ser leve, ele ainda suporta a janela de contexto completa de 1 milhão de tokens.
É também o menor, mais rápido e mais barato modelo da OpenAI, com apenas cerca de 10 centavos por milhão de tokens. Você não tem toda a capacidade de raciocínio e planejamento dos modelos maiores, mas, para determinadas tarefas, esse não é o ponto.
Antes de entrarmos nos benchmarks (que abordaremos em detalhes na próxima seção), vale a pena entender como o GPT-4.1 difere na prática do GPT-4o e do GPT-4.5.
O GPT-4.1 aprimora os recursos do GPT-4o, mantendo a latência praticamente na mesma faixa. Na prática, isso significa que os desenvolvedores agora obtêm melhor desempenho sem pagar um custo em termos de capacidade de resposta.
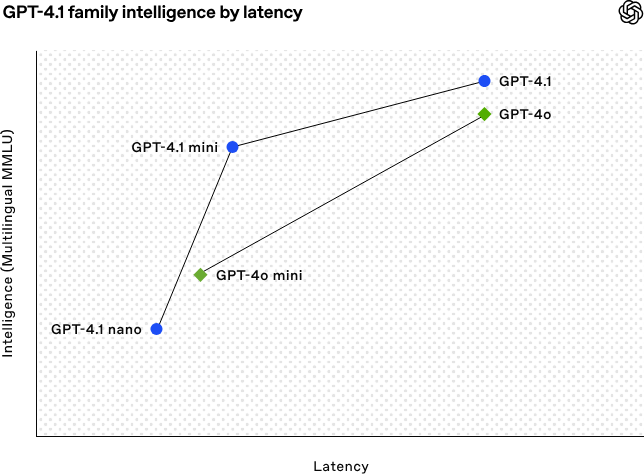
Fonte: OpenAI
Vamos analisar o gráfico acima:
O GPT-4.5, por outro lado, sempre foi posicionado como uma prévia de pesquisa. Apesar de ter um raciocínio e uma qualidade de escrita sólidos, ele tinha mais despesas gerais. A GPT-4.1 oferece resultados semelhantes ou melhores nos principais benchmarks, mas é mais barata e mais ágil - o suficiente para que a OpenAI planeje retirar totalmente a 4.5 até meados de julho para liberar mais GPUs.
Todos os três modelos GPT-4.1 - padrão, Mini e Nano - suportam até 1 milhão de tokens de contexto. Isso é mais de 8 vezes o que o GPT-4o oferecia.
Essa capacidade de contexto longo permite casos de uso práticos, como o processamento de registros inteiros, a indexação de repositórios de código, a manipulação de fluxos de trabalho jurídicos com vários documentos ou a análise de transcrições longas, tudo isso sem a necessidade de dividir ou resumir previamente.
O GPT-4.1 também marca uma mudança na confiabilidade com que os modelos seguem as instruções. Ele lida com prompts complexos que envolvem etapas ordenadas, restrições de formatação e condições negativas (como recusar-se a responder se a formatação estiver errada).
Na prática, isso significa duas coisas: menos tempo gasto na criação de prompts e menos tempo para limpar o resultado depois.
O GPT-4.1 mostra progresso em quatro áreas principais: codificação, acompanhamento de instruções, compreensão de contextos longos e tarefas multimodais.
No SWE-bench Verified, um benchmark que coloca o modelo em uma base de código real e solicita que ele conclua os problemas de ponta a ponta, o GPT-4.1 obteve 54,6% de pontuação. Isso representa um aumento de 33,2% para o GPT-4o e 38% para o GPT-4.5. Também é impressionante que o GPT-4.1 tenha uma pontuação mais alta do que o o1 e o3-mini.
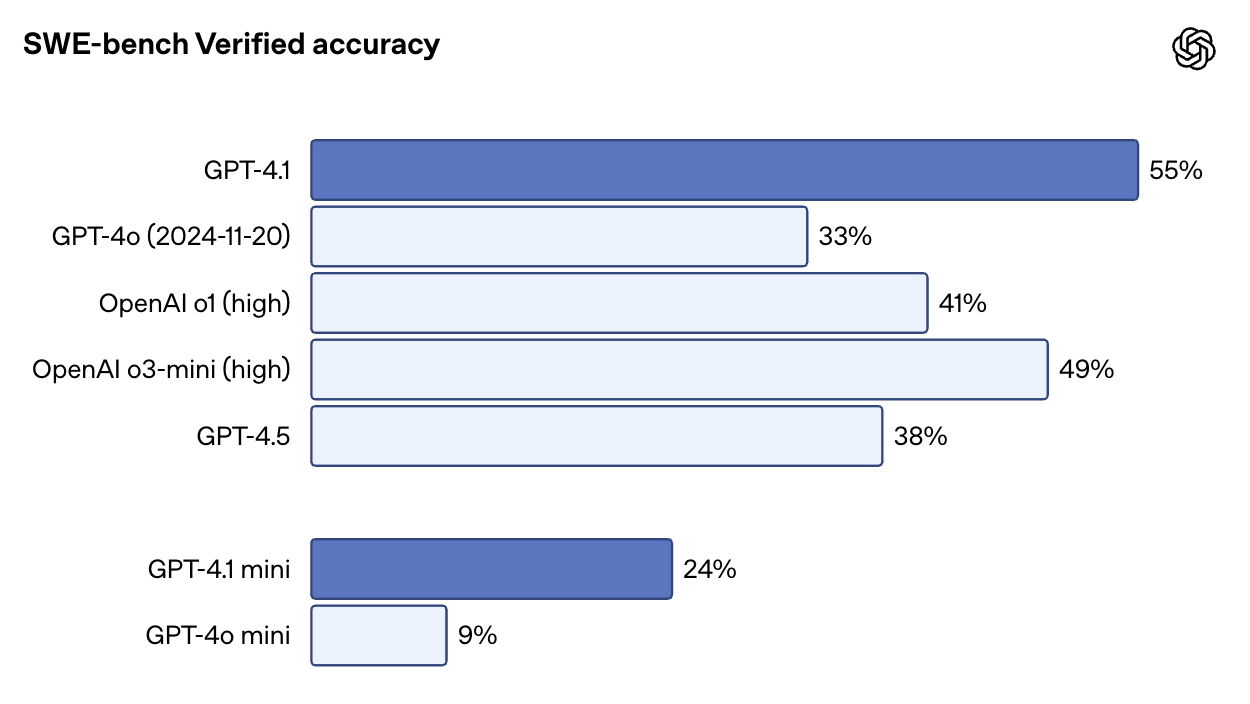
Fonte: OpenAI
Ele também mais que dobra o desempenho do GPT-4o no benchmark de diferenças poliglotas da Aider, atingindo 52,9% de precisão em diferenças de código em vários idiomas e formatos. O GPT-4.5 obteve 44,9% de pontuação na mesma tarefa. O GPT-4.1 também é mais preciso: nas avaliações internas, as edições de códigos estranhos caíram de 9% (GPT-4o) para apenas 2%.
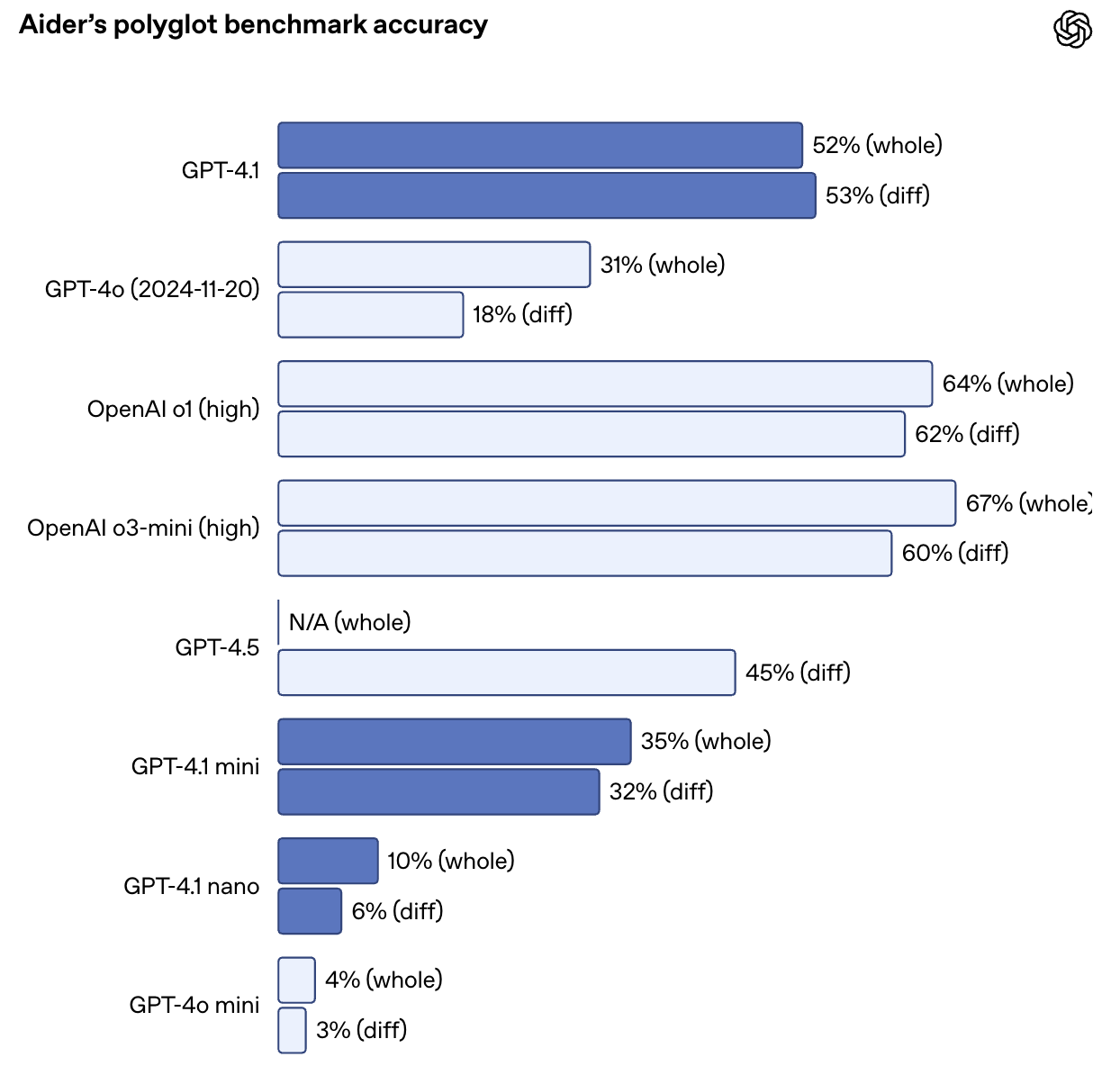
Fonte: OpenAI
Além das pontuações de benchmark, a demonstração de codificação de front-end oferecida pela OpenAI é um bom exemplo visual do desempenho superior do GPT-4.1. A equipe da OpenAI pediu aos dois modelos que criassem o mesmo aplicativo de cartões de memória, e os avaliadores humanos preferiram o resultado do GPT-4.1 em 80% das vezes.
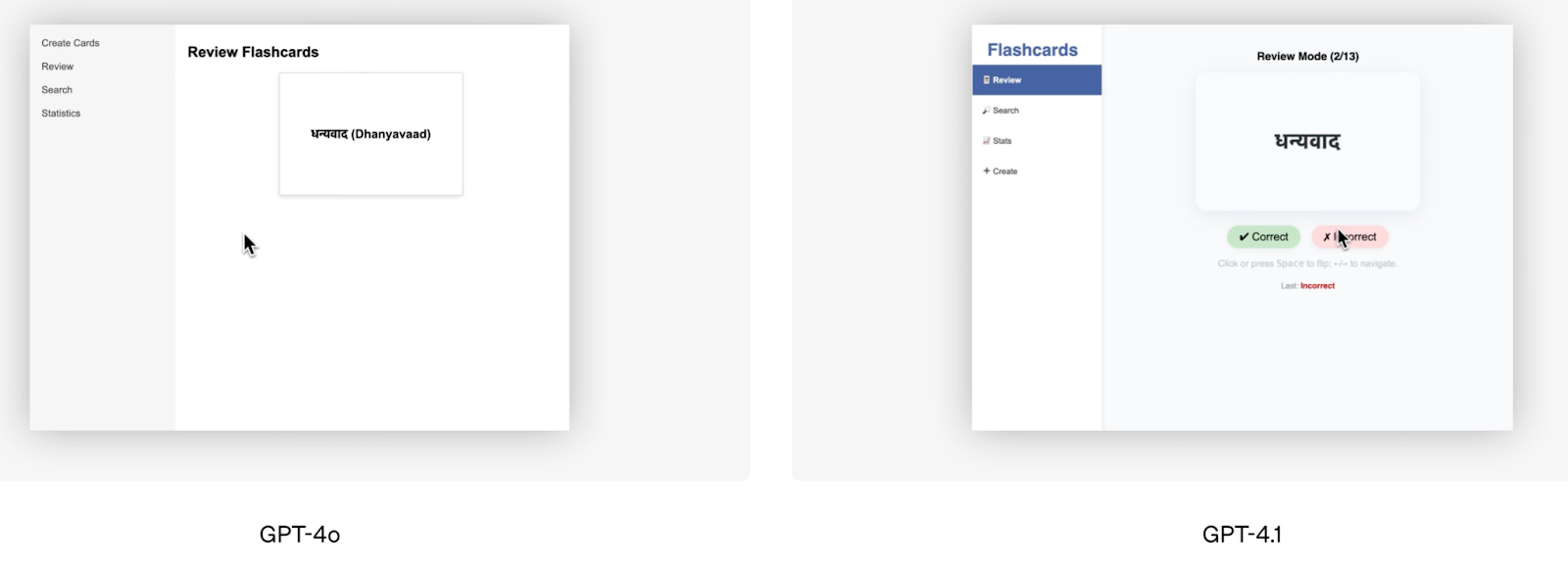
Fonte: OpenAI
A Windsurf, um dos testadores alfa, relatou uma melhoria de 60% em seu próprio benchmark interno de codificação. Outra empresa, a Qodo, testou o GPT-4.1 em pull requests reais do GitHub e descobriu que ele produzia sugestões melhores em 55% das vezes, com menos edições irrelevantes ou excessivamente detalhadas.
O GPT-4.1 é mais literal - e mais confiável - quando se trata de seguir instruções, especialmente em tarefas que envolvem várias etapas, regras de formatação ou condições. Na instrução interna da OpenAI que segue a avaliação (subconjunto rígido), o GPT-4.1 obteve 49,1%, em comparação com apenas 29,2% do GPT-4o. O GPT-4.5 está ligeiramente à frente aqui, com 54%, mas a diferença entre o 4.1 e o 4o é significativa.

Fonte: OpenAI
No MultiChallenge, que testa se um modelo pode seguir instruções de várias voltas e se lembrar de restrições introduzidas anteriormente na conversa, o GPT-4.1 obteve uma pontuação de 38,3%, contra 27,8% do GPT-4o. E no IFEval, que testa a conformidade com requisitos de saída claramente especificados, o GPT-4.1 atinge 87,4%, uma melhoria sólida em relação aos 81% do GPT-4o.
Na prática, isso significa que o GPT-4.1 é melhor em seguir etapas ordenadas, rejeitar entradas malformadas e responder no formato que você solicitou, especialmente em saídas estruturadas como XML, YAML ou markdown. Isso também facilita a criação de fluxos de trabalho de agentes confiáveis, sem muitas tentativas imediatas.
Todos os três modelos GPT-4.1 - padrão, Mini e Nano - suportam até 1 milhão de tokens de contexto. Isso representa um aumento de 8x em relação ao GPT-4o, que tinha como limite máximo 128K. Igualmente importante: não há custo adicional para você usar essa janela de contexto. O preço é igual ao de qualquer outro prompt.
Mas será que os modelos podem realmente usar todo esse contexto? Na avaliação de agulha no palheiro da OpenAI, o GPT-4.1 encontrou de forma confiável o conteúdo inserido em qualquer ponto - início, meio ou fim - dentro da entrada completa de 1 milhão de tokens.
Fonte: OpenAI
O Graphwalks, um benchmark que testa o raciocínio de múltiplos saltos em contextos longos, coloca o GPT-4.1 em 61,7% - um salto sólido em relação aos 41,7% do GPT-4o, embora ainda abaixo dos 72,3% do GPT-4.5.
Essas melhorias também aparecem em testes reais. A Thomson Reuters observou um aumento de 17% na análise jurídica de vários documentos usando o GPT-4.1, enquanto a Carlyle relatou uma melhoria de 50% na extração de dados granulares de relatórios financeiros densos.
Em tarefas multimodais, o GPT-4.1 também faz progressos. Ele obteve 72,0% no benchmark Video-MME, que envolve a resposta a perguntas sobre vídeos de 30 a 60 minutos sem legendas - acima dos 65,3% obtidos com o GPT-4o.
Em benchmarks com muitas imagens, como o MMMU, ele alcançou 74,8% em comparação com o índice de qualidade de imagem. 68,7% para GPT-4o. No MathVista, que inclui tabelas, gráficos e recursos visuais de matemática, o GPT-4.1 atingiu 72,2%.
Uma surpresa: O GPT-4.1 Mini tem um desempenho quase tão bom quanto a versão completa em alguns desses benchmarks. No MathVista, por exemplo, ele superou ligeiramente o GPT-4.1, com 73,1%. Isso o torna uma opção atraente para casos de uso que combinam velocidade com prompts com muita visão.
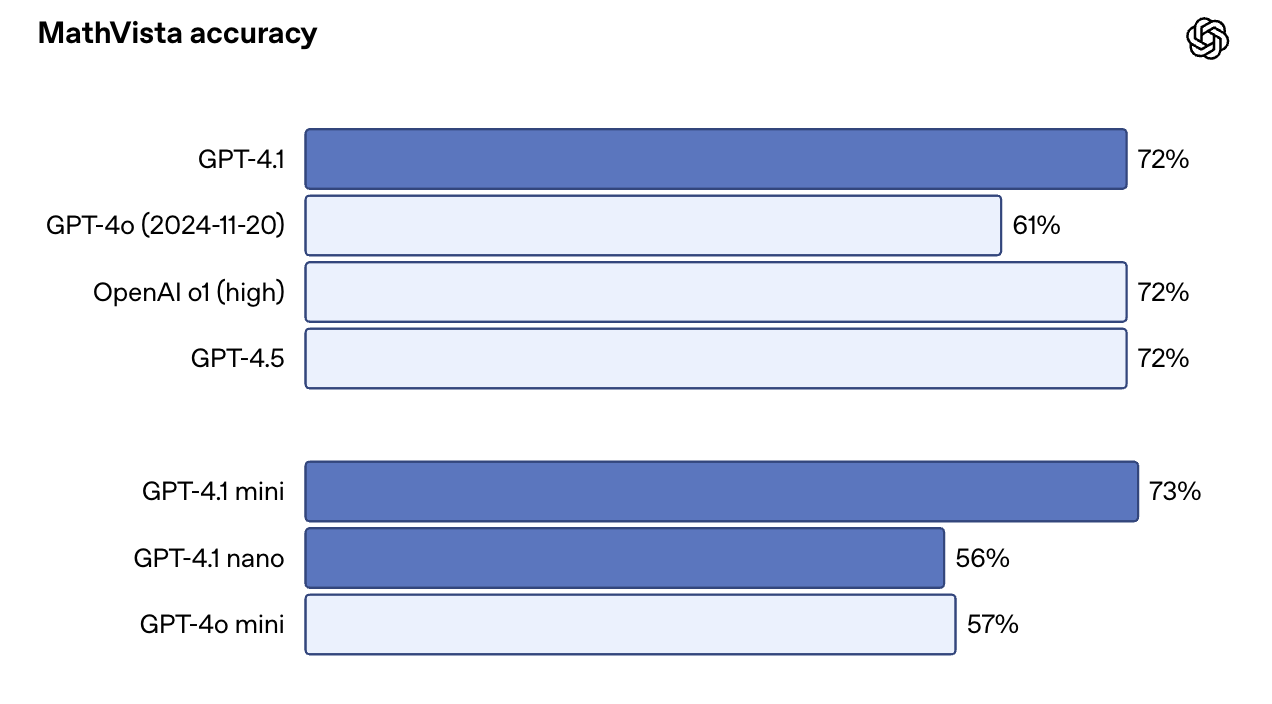
Fonte: OpenAI
Agora você pode acessar o GPT-4.1 e o GPT-4.1 Mini diretamente no aplicativo ChatGPT, e não apenas por meio da API. Os assinantes Plus, Pro e Team podem selecionar manualmente o GPT-4.1 no menu do modelo, enquanto os usuários gratuitos voltam automaticamente para o GPT-4.1 Mini, substituindo o GPT-4o Mini como padrão nos bastidores. Espera-se que os planos Enterprise e Education recebam acesso nas próximas semanas.
Para os desenvolvedores, a API OpenAI e o Playground continuam a oferecer suporte a todas as três variantes: GPT-4.1, GPT-4.1 Mini e GPT-4.1 Nano. Essa continua sendo a melhor maneira de testar prompts, explorar o comportamento de contextos longos e comparar modelos antes de integrá-los à produção.
Se você estiver trabalhando com documentos longos, como logs, PDFs, registros legais ou artigos acadêmicos, poderá enviar até 1 milhão de tokens em uma única chamada, sem necessidade de parâmetro especial. Também não há aumento de preço para contextos longos: os custos de tokens são fixos, independentemente do tamanho da entrada.
Você pode fazer o ajuste fino de todas as três variantes do GPT-4.1. Isso abre a porta para instruções personalizadas, vocabulário específico do domínio ou saídas específicas do tom. Observe que o ajuste fino tem um pricing um pouco maior:
|
Modelo |
Entrada |
Entrada em cache |
Saída |
Treinamento |
|
GPT-4.1 |
US$ 3,00 / 1 milhão de tokens |
US$ 0,75 / 1 milhão de tokens |
US$ 12,00 / 1 milhão de tokens |
US$ 25,00 / 1 milhão de tokens |
|
GPT-4.1 Mini |
US$ 0,80 / 1 milhão de tokens |
US$ 0,20 / 1 milhão de tokens |
US$ 3,20 / 1 milhão de tokens |
US$ 5,00 / 1 milhão de tokens |
|
GPT-4.1 Nano |
US$ 0,20 / 1 milhão de tokens |
US$ 0,05 / 1 milhão de tokens |
US$ 0,80 / 1 milhão de tokens |
US$ 1,50 / 1 milhão de tokens |
Se você já tiver feito o ajuste fino dos modelos GPT-3.5 ou GPT-4 anteriormente, o processo permanece praticamente o mesmo - basta escolher a base mais recente. Se você quiser saber mais, recomendo este tutorial sobre ajuste fino do GPT-4o mini.
Uma das atualizações mais bem-vindas do GPT-4.1 é que ele não é apenas mais inteligente, mas também mais barato. A OpenAI diz que o objetivo era tornar esses modelos mais utilizáveis em mais fluxos de trabalho do mundo real, e isso se mostra na forma como os preços são estruturados.
Veja como os três modelos são precificados para inferência:
|
Modelo |
Entrada |
Entrada em cache |
Saída |
Média combinada Custo* |
|
GPT-4.1 |
US$ 2,00 / 1 milhão de tokens |
US$ 0,50 / 1 milhão de tokens |
US$ 8,00 / 1 milhão de tokens |
$1.84 |
|
GPT-4.1 Mini |
US$ 0,40 / 1 milhão de tokens |
US$ 0,10 / 1 milhão de tokens |
US$ 1,60 / 1 milhão de tokens |
$0.42 |
|
GPT-4.1 Nano |
US$ 0,10 / 1 milhão de tokens |
US$ 0,025 / 1 milhão de tokens |
US$ 0,40 / 1 milhão de tokens |
$0.12 |
*O número "combinado" é baseado na suposição da OpenAI de proporções típicas de entrada/saída.
O GPT-4.1 vem com geração de código mais confiável, melhor acompanhamento de instruções, processamento real de contexto longo e iteração mais rápida.
A nomenclatura pode ser confusa, mas os modelos em si são claramente mais capazes do que os anteriores. Eles também são mais econômicos e mais úteis, especialmente em ambientes de produção em que a latência, o custo e a previsibilidade são importantes.
Se você estiver trabalhando com o GPT-4o hoje, vale a pena testar o GPT-4.1.
Aprenda IA com estes cursos!
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Richie Cotton
7 min
blog
Josep Ferrer
8 min
blog
Nisha Arya Ahmed
10 min
Tutorial
Arunn Thevapalan
Tutorial
Moez Ali




