Programa
ChatGPT Fundamentos
3 h
O GPT-4o mini é derivado do modelo maior GPT-4o por meio de um processo de destilação. Esse processo envolve o treinamento de um modelo menor para imitar o comportamento e o desempenho do modelo maior e mais complexo, resultando em uma versão econômica e altamente capaz do original.
O GPT-4o mini concorre com modelos como Llama 3 8BGemini 1.5 Flash e Claude Haiku, bem como o GPT-3.5 Turbo da OpenAI. Esses modelos oferecem funcionalidades semelhantes, mas geralmente têm custos mais altos ou métricas de desempenho menos avançadas.
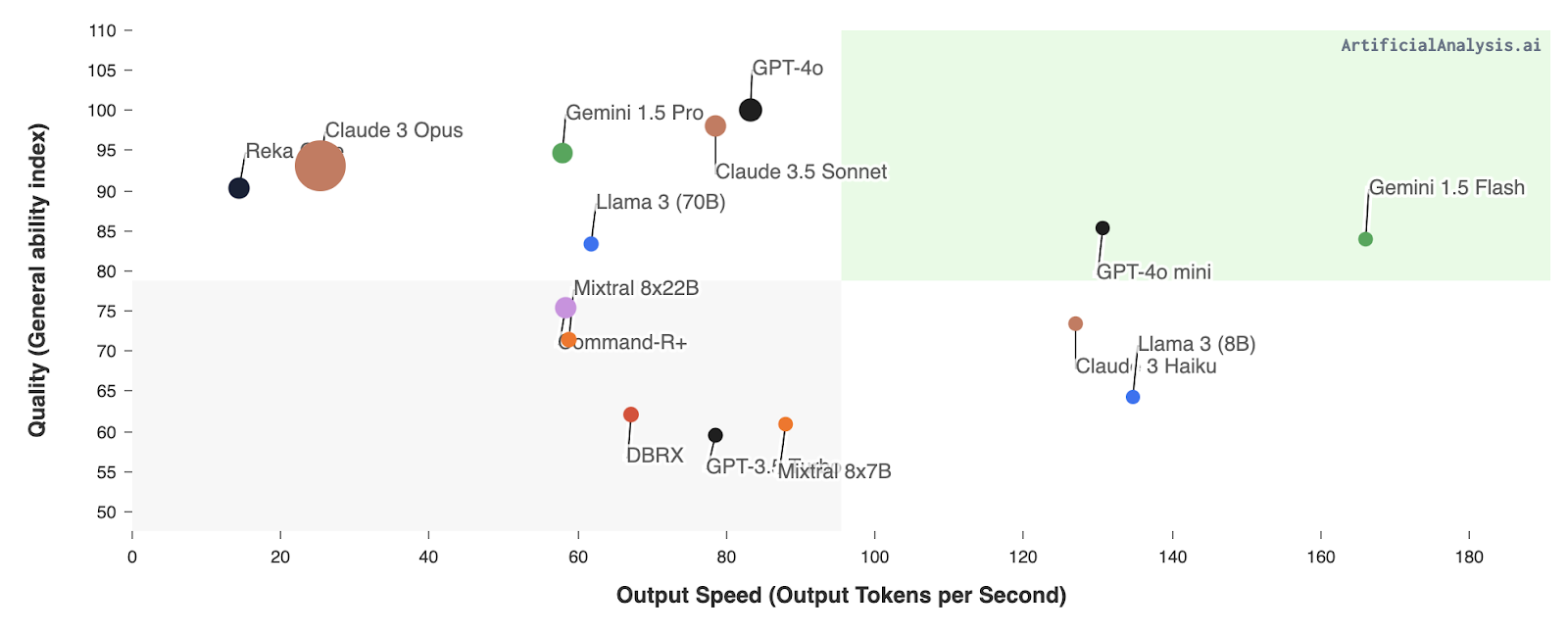
Fonte: Análise Artificial
O GPT-4o mini alcança seu equilíbrio de desempenho e eficiência por meio de um processo conhecido como destilação modelo. Em essência, isso envolve o treinamento de um modelo menor e mais simplificado (o "aluno") para imitar o comportamento e o conhecimento de um modelo maior e mais complexo (o "professor").
O modelo maior, neste caso, o GPT-4o, foi pré-treinado em grandes quantidades de dados e possui uma compreensão profunda dos padrões de linguagem, da semântica e até mesmo das habilidades de raciocínio. No entanto, seu tamanho o torna computacionalmente caro e menos adequado para determinados aplicativos.
A destilação de modelos resolve esse problema transferindo o conhecimento e os recursos do modelo GPT-4o maior para o GPT-4o mini menor. Normalmente, isso é feito fazendo com que o modelo menor aprenda a prever os resultados do modelo maior em um conjunto diversificado de dados de entrada. Por meio desse processo, o GPT-4o mini "destila" efetivamente os conhecimentos e as habilidades mais importantes de sua contraparte maior.
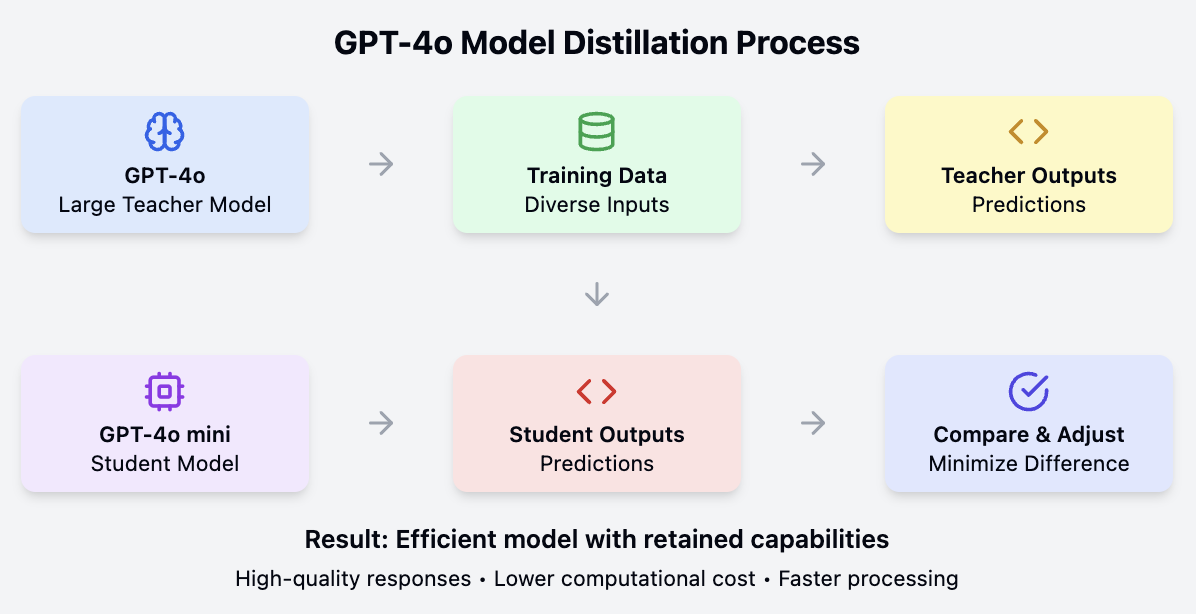
O resultado é um modelo que, embora menor e mais eficiente, mantém grande parte do desempenho e dos recursos do original. O GPT-4o mini pode lidar com tarefas de linguagem complexas, entender o contexto e gerar respostas de alta qualidade, tudo isso consumindo menos recursos computacionais. Isso o torna uma solução prática e econômica para uma ampla gama de aplicações, especialmente aquelas em que a velocidade e o custo-benefício são importantes.
O GPT-4o mini apresenta um desempenho impressionante em vários benchmarks. Eu criei Artefatos do Claude para cada benchmark para explicar o que é cada benchmark do LLM e o que ele mede.
Para tarefas de raciocínio, avaliamos o GPT-4o mini da seguinte forma:
O MMLU (Massive Multitask Language Understanding) é um benchmark que testa modelos com perguntas de múltipla escolha em 57 assuntos diferentes, incluindo STEM, humanidades e ciências sociais. As perguntas variam em dificuldade, de básicas a avançadas. Ele mede quantas respostas estão corretas e exige correspondências exatas. O GPT-4o Mini obteve 82,0% de pontuação, superando concorrentes como o Gemini Flash (77,9%) e o Claude Haiku (73,8%).

O GPQA (Google-Proof Q&A Benchmark) é um conjunto de dados difícil com perguntas elaboradas por especialistas para desafiar quem não é especialista e, ao mesmo tempo, ser gerenciável para especialistas. As perguntas são cuidadosamente validadas quanto à dificuldade e à precisão em várias rodadas para reduzir os riscos de contaminação.

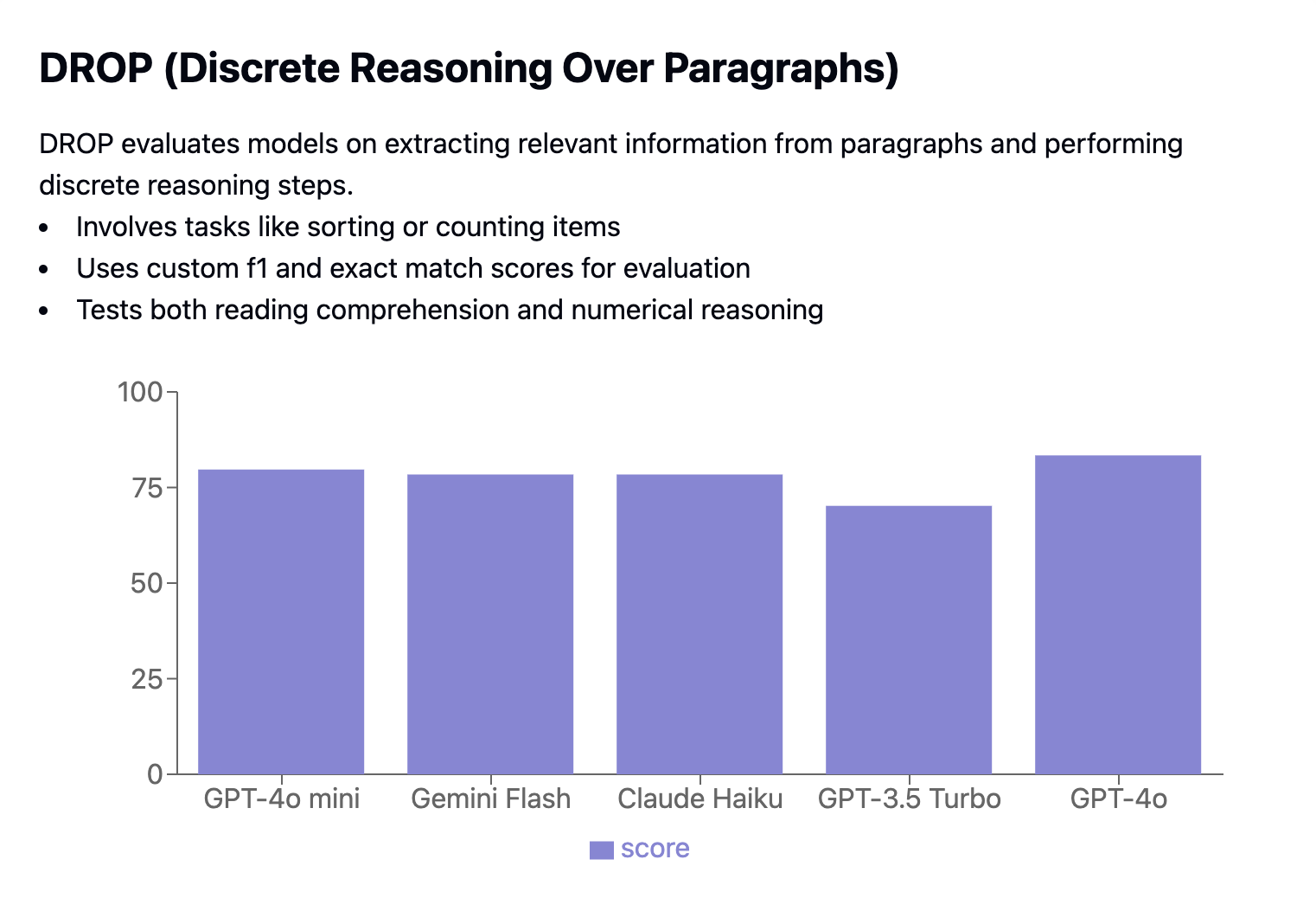
O DROP (Discrete Reasoning Over Paragraphs) testa a capacidade dos modelos de extrair informações relevantes de parágrafos e realizar tarefas de raciocínio, como classificação ou contagem. O desempenho é avaliado usando pontuações personalizadas de F1 e de correspondência exata.
O MGSM benchmark inclui 250 problemas de matemática da escola primária traduzidos em 10 idiomas, testando as habilidades de raciocínio multilíngue.

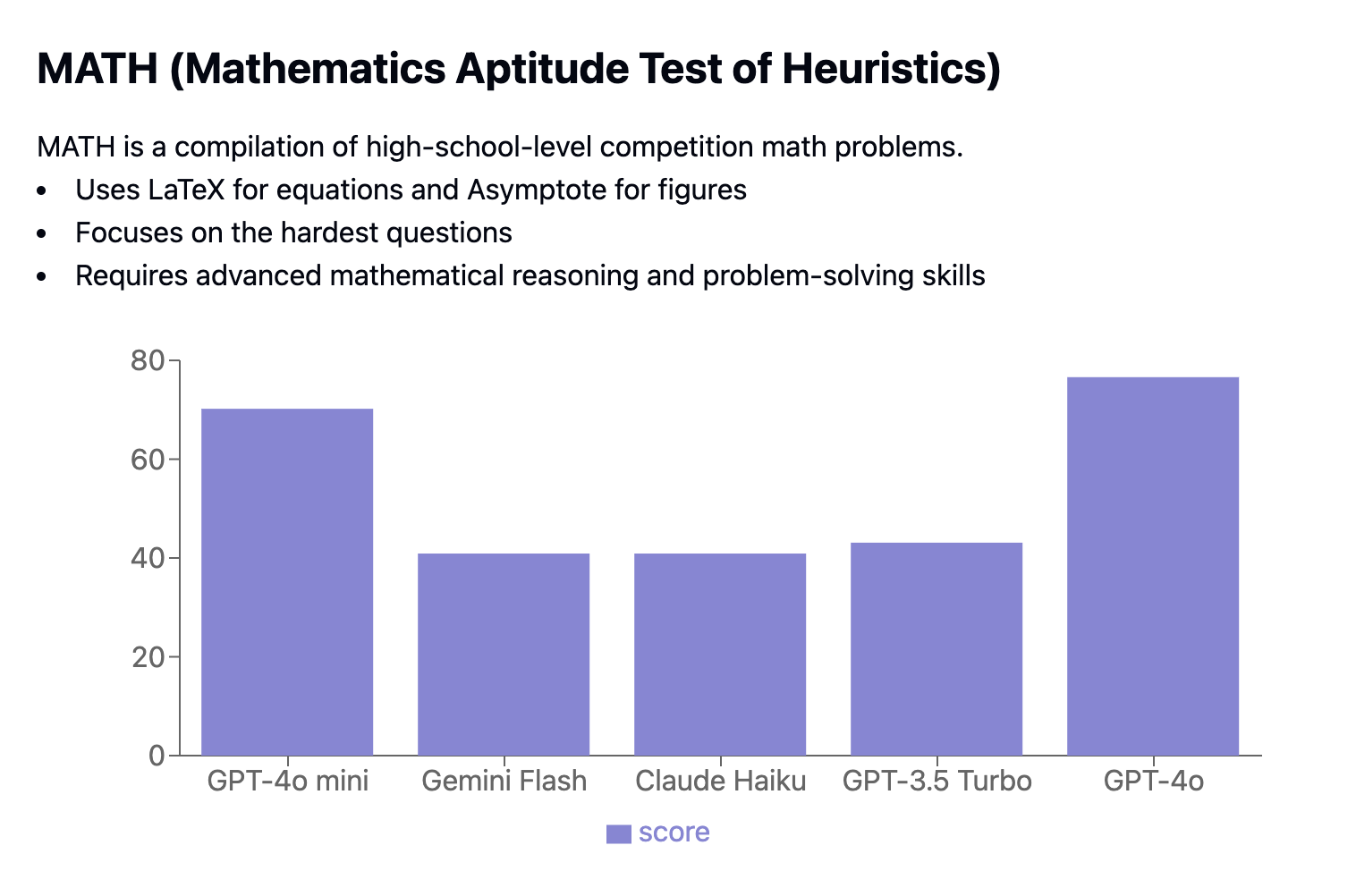
O Mathematics Aptitude Test of Heuristics (MATH) apresenta problemas de competição em nível de ensino médio. Ele avalia os modelos quanto à sua capacidade de resolver problemas matemáticos complexos formatados em Latex e Asymptote, concentrando-se nas perguntas mais desafiadoras.
O benchmark HumanEval mede o desempenho da geração de código, avaliando se o código gerado passa em testes de unidade específicos. Ele usa a métrica pass@k para determinar a probabilidade de que pelo menos uma das k soluções para um problema de codificação passe nos testes.

O benchmark Massive Multitask Language Understanding (MMLU) testa a amplitude de conhecimento de um modelo, a profundidade da compreensão da linguagem natural e as habilidades de solução de problemas. Ele apresenta mais de 15.000 perguntas de múltipla escolha que abrangem 57 assuntos, desde conhecimentos gerais até campos especializados. O MMLU avalia os modelos em configurações de poucos disparos e zero disparos, medindo a precisão entre os sujeitos e calculando a média dos resultados para obter uma pontuação final.

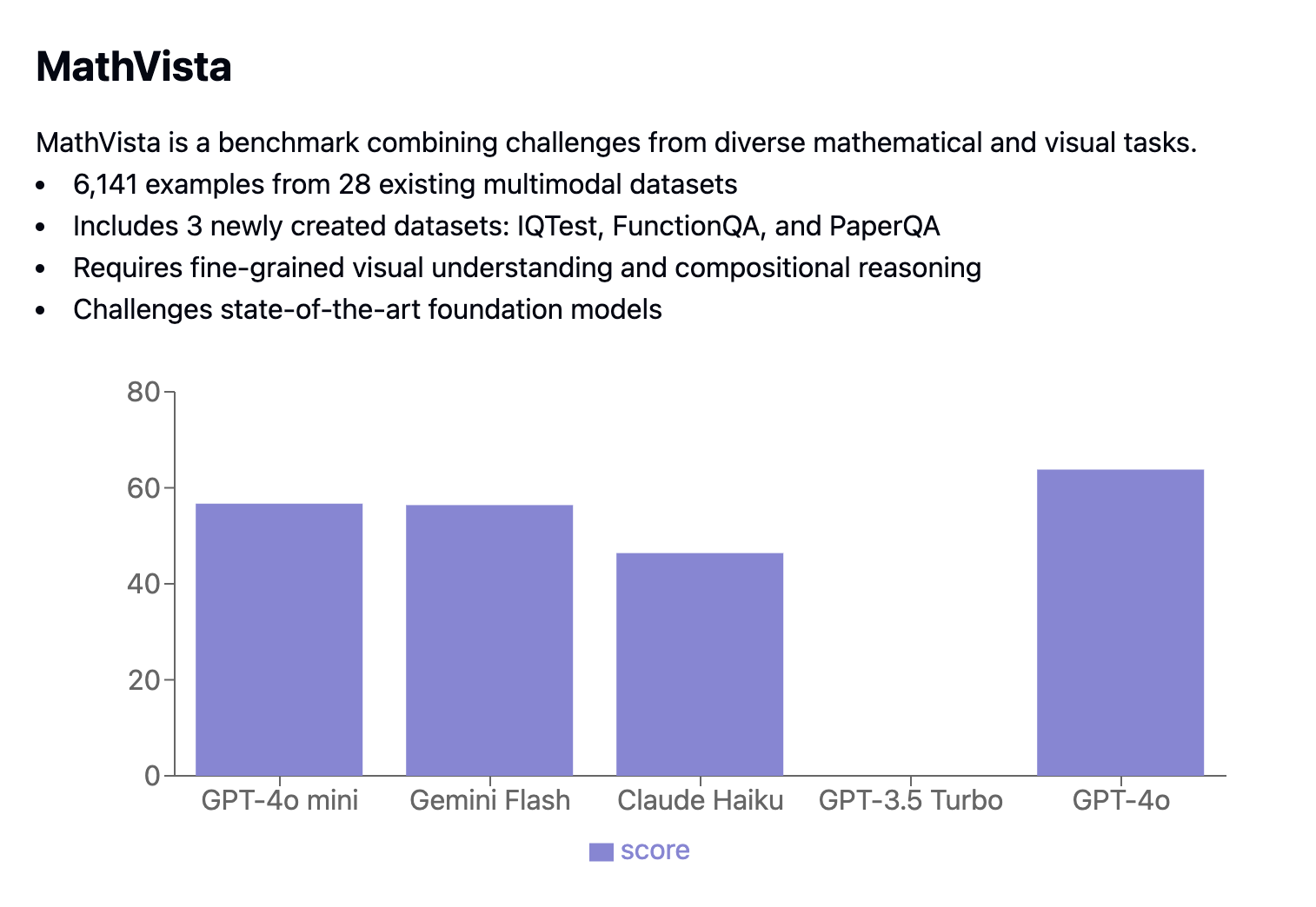
O benchmark MathVista combina tarefas matemáticas e visuais, apresentando 6.141 exemplos extraídos de 28 conjuntos de dados multimodais existentes e 3 conjuntos de dados recém-criados (IQTest, FunctionQA e PaperQA). Ele desafia os modelos com tarefas que exigem compreensão visual avançada e raciocínio de composição complexo.
O tamanho pequeno, o baixo custo e o forte desempenho do GPT-4o mini o tornam perfeito para uso em dispositivos pessoais, prototipagem rápida e em ambientes com recursos limitados. Além disso, sua capacidade de resposta em tempo real melhora os aplicativos interativos. Veja como o GPT-4o mini pode ser usado de forma eficaz:
|
Categoria de caso de uso |
Benefícios |
Exemplos de aplicativos |
|
IA no dispositivo |
O tamanho menor permite o processamento local em laptops, smartphones e servidores de borda, reduzindo a latência e melhorando a privacidade. |
Aplicativos de aprendizagem de idiomas, assistentes pessoais, ferramentas de tradução off-line |
|
Prototipagem rápida |
A iteração mais rápida e os custos mais baixos permitem a experimentação e o refinamento antes de você escalar para modelos maiores. |
Testar novas ideias de chatbot, desenvolver protótipos com tecnologia de IA, experimentar diferentes recursos de IA de forma econômica |
|
Aplicativos em tempo real |
O tempo de resposta rápido aprimora as experiências interativas. |
Chatbots, assistentes virtuais, tradução de idiomas em tempo real, narrativa interativa em jogos e realidade virtual |
|
Uso educacional |
Acessível e de baixo custo para instituições educacionais, proporcionando experiência prática com IA. |
Sistemas de tutoria com tecnologia de IA, plataformas de aprendizado de idiomas, ferramentas de prática de codificação |
Você pode usar o GPT-4o Mini por meio da API OpenAIque inclui opções como a API de assistentes, a API de conclusões de bate-papo e a API de lote. Aqui está um guia simples sobre como usar o GPT-4o Mini com a API OpenAI.
Primeiro, você precisará se autenticar usando sua chave de API - substitua your_api_key_here pela sua chave de API real. Depois de configurado, você pode começar a gerar texto com o GPT-4o Mini:
from openai import OpenAI
MODEL="gpt-4o-mini"
## Set the API key
client = OpenAI(api_key="your_api_key_here")
completion = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a helpful assistant that helps me with my math homework!"},
{"role": "user", "content": "Hello! Could you solve 20 x 5?"}
]
)Para obter mais detalhes sobre como configurar e usar a API OpenAI, confira o Tutorial da API do GPT-4o.
Saiba mais sobre o GPT!
Programa
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Richie Cotton
7 min
blog
Nisha Arya Ahmed
10 min
Tutorial
Arunn Thevapalan
Tutorial
Moez Ali




